????????在C++中,哈希表是一種常用的數據結構,用于實現快速的插入、刪除和查找操作。
哈希表的核心在于哈希函數,它將輸入的關鍵字轉換為一個數組索引。然而,不同的關鍵字可能映射到相同的索引,這種情況稱為哈希沖突。
有效地解決哈希沖突是確保哈希表性能的關鍵。
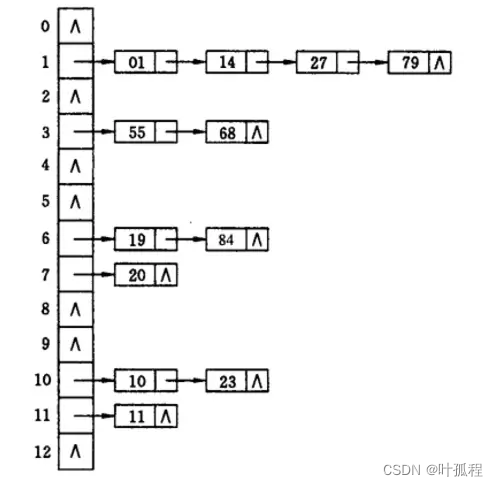
1. 開放地址法
概念:開放地址法是指當一個關鍵字映射的位置已經被占用時,會尋找下一個空閑的位置進行存放。查找時,若原位置沒有找到,則按照同樣的規則繼續查找下一個可能的位置。
優點:實現簡單,無需額外的數據結構。
缺點:可能會導致某些區域過于密集,影響性能;刪除操作復雜。
代碼示例:
#include <iostream>
#include <vector>class OpenAddressingHashTable {
public:explicit OpenAddressingHashTable(size_t size) : table(size, -1), used(size, false) {}void insert(int key) {size_t index = key % table.size();while (used[index]) {index = (index + 1) % table.size(); // 線性探測法}table[index] = key;used[index] = true;}bool search(int key) {size_t index = key % table.size();while (used[index]) {if (table[index] == key) return true;index = (index + 1) % table.size();}return false;}private:std::vector<int> table;std::vector<bool> used;
};2. 鏈地址法(哈希桶)
概念:鏈地址法是在每個數組位置上掛接一個鏈表,所有映射到該位置的元素都存儲在這個鏈表中。
優點:沖突少時效率高,支持動態擴容,刪除操作簡單。
缺點:鏈表過長時,查找效率降低。
代碼示例(基于之前提供的哈希桶示例):
#include <iostream>
#include <list>
#include <vector>class HashBucket {
public:explicit HashBucket(size_t size = 10) : buckets(size) {}void insert(int key, std::string value) {size_t index = hashFunction(key);buckets[index].push_back({key, value});}std::string search(int key) {size_t index = hashFunction(key);for (const auto& pair : buckets[index]) {if (pair.first == key) {return pair.second;}}return "Not Found";}void remove(int key) {size_t index = hashFunction(key);auto& bucket = buckets[index];bucket.erase(std::remove_if(bucket.begin(), bucket.end(),[key](const auto& p){ return p.first == key; }),bucket.end());}private:std::size_t hashFunction(int key) const {return key % buckets.size(); // 簡單的取模哈希函數}std::vector<std::list<std::pair<int, std::string>>> buckets;
};int main() {HashBucket hashTable;hashTable.insert(10, "Apple");hashTable.insert(25, "Banana");hashTable.insert(20, "Cherry");std::cout << "Search 10: " << hashTable.search(10) << std::endl; // 應輸出 Applestd::cout << "Search 30: " << hashTable.search(30) << std::endl; // 應輸出 Not FoundhashTable.remove(20);std::cout << "Search 20 after removal: " << hashTable.search(20) << std::endl; // 應輸出 Not Foundreturn 0;
}3. 再哈希法
概念:當發生沖突時,使用第二個哈希函數計算另一個位置,如果仍沖突,則繼續使用第三個或更多哈希函數,直到找到空位。
優點:可以減少聚集現象。
缺點:需要設計多個哈希函數,增加了實現復雜度。
代碼示例(簡略示例):
class RehashHashTable {
public:void insert(int key) {size_t index = primaryHash(key);if (isOccupied(index)) {index = secondaryHash(key); // 假設這是第二個哈希函數// 可能需要更多的檢查和重哈希直到找到空位}// 實際插入邏輯省略}private:size_t primaryHash(int key) { /* 主哈希函數實現 */ }size_t secondaryHash(int key) { /* 輔助哈希函數實現 */ }bool isOccupied(size_t index) { /* 檢查位置是否已被占用 */ }
};4. 建立公共溢出區(使用率低)
概念:當主表滿時,額外分配一塊區域作為溢出區,所有沖突的元素都放入這個區域,并以某種順序(如鏈表)鏈接起來。
優點:實現簡單。
缺點:查找效率較低,因為可能需要遍歷整個溢出區。
????????解決哈希沖突的策略各有優劣,選擇哪種方法取決于具體的應用場景和性能要求。開放地址法適合內存有限且數據量不大的情況;鏈地址法則更適合數據量大且需要頻繁插入刪除的場景;再哈希法和建立公共溢出區則是針對特定需求的解決方案,可能在某些特殊場景下更為合適。
????????在實際應用中,還需要考慮哈希函數的設計、哈希表的動態擴容機制等因素,以進一步優化性能。C++標準庫中的std::unordered_map和std::unordered_set就是使用了類似鏈地址法的實現,結合了動態擴容機制,提供了高效的哈希表操作接口。














)


|哪些函數不能實現成虛函數和虛析構函數的理解)

