- 清華深&港科&深先進&Tencent AAAI24
- https://github.com/mayuelala/FollowYourPose
- 問題引入
- 本文的任務是根據文本來生成高質量的角色視頻,并且可以通過pose來控制任務的姿勢;
- 當前缺少video-pose caption數據集,所以提出一個兩階段的訓練,可以利用image-pose數據和pose free video數據;
- 第一階段首先使用pose-image pair來訓練pose encoder,第二階段使用pose free video來訓練時序模塊;
- methods
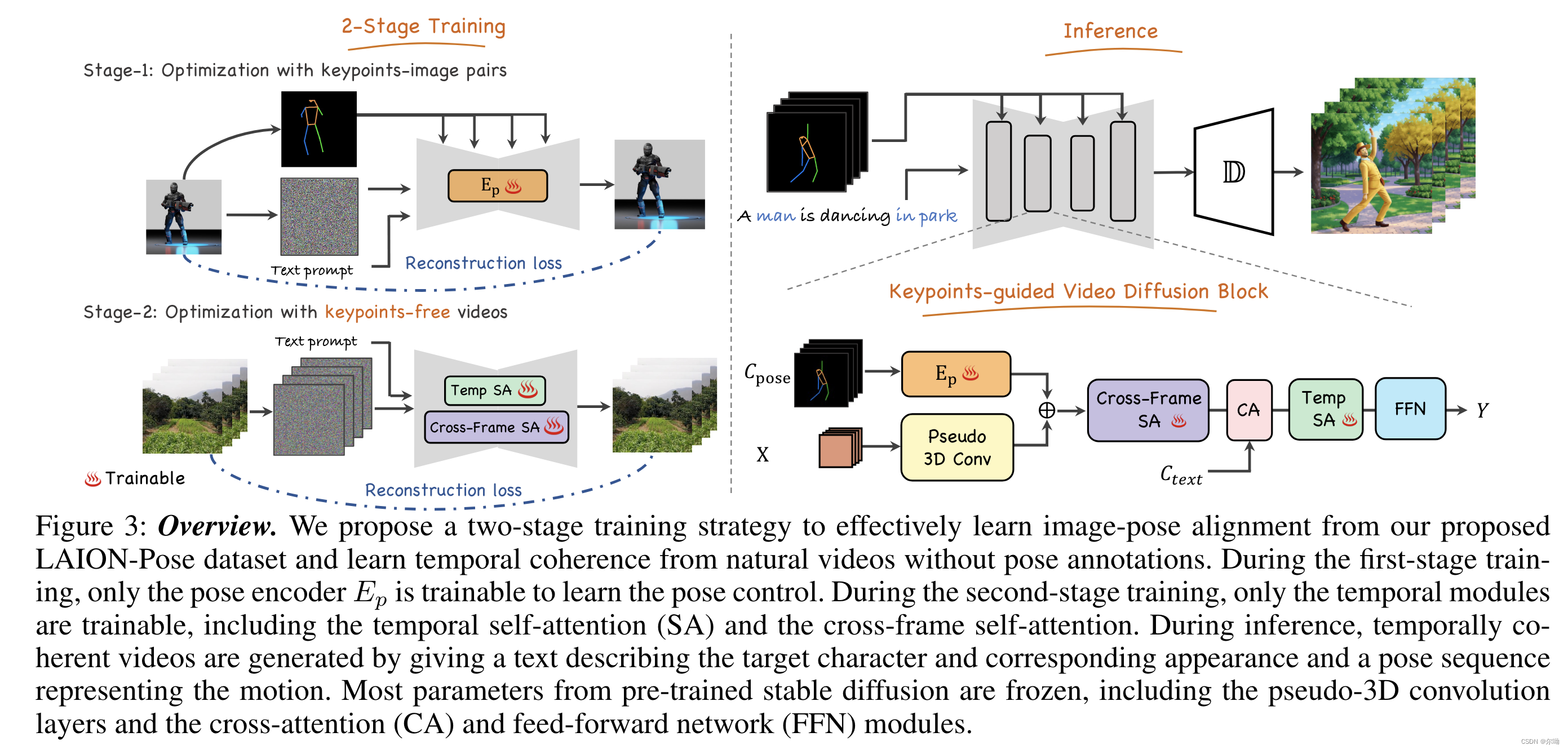
- 將任務分解為兩個子問題,首先image-pose pair數據來實現pose控制,視頻數據來實現幀間的一致性;
- 訓練階段1Pose-Controllable Text-to-Image Generation:pose encoder模塊 E p E_p Ep?
- 訓練階段2Video Generation via Pose-free Videos:時序模塊;
- 實驗
- Laion-Pose訓練第一階段,HDVILA第二階段;












)
)
入門)




