🎬個人簡介:一個全棧工程師的升級之路!
📋個人專欄:pytorch深度學習
🎀CSDN主頁?發狂的小花
🌄人生秘訣:學習的本質就是極致重復!
《PyTorch深度學習實踐》完結合集_嗶哩嗶哩_bilibili?
目錄
1 全連接
2 矩陣乘法的本質
3 循環神經網絡(RNN)
3.1 引入RNN的前言
3.2 RNN
3.3 RNN cell
1 全連接
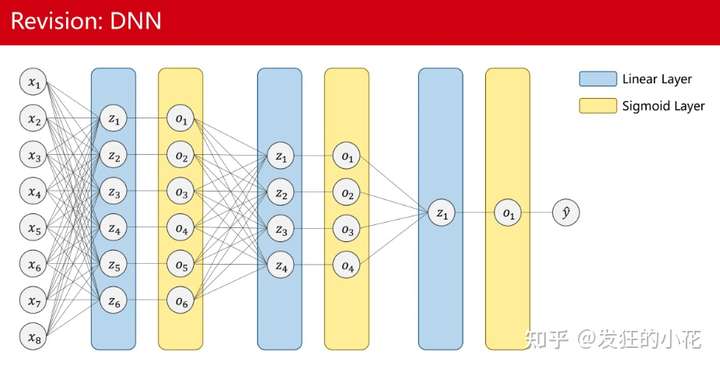
FC,也加Linear Layer,Dense Layer。在全連接層中,每個神經元與前一層的每個神經元都有連接,每一個連接都有一個權重,形成一個完全連接的網絡結構。
獲得全局視野,放在神經網絡的最后,用來做分類,完成全部特征的信息共享和特征融合,將隱層特征空間逐步映射到樣本空間,比如ResNet50會輸出1000個特征的得分值,這1000個特征的得分值,遍可以對應到圖像的分類。
由于全連接需要當前的每一個神經元與前一層的每一個神經元相連,這樣需要的權重參數是巨大的。
 ?
?
2 矩陣乘法的本質
資源的整合和再創。
假設有金酒、利口酒、檸檬汁、可樂四種原料,可以用來調制雞尾酒。
自由古巴: 0.2 x 金酒+ 0.45 x 利口酒 + 0.1 x 檸檬汁 + 0.25 x 可樂
長島冰茶: 0.6 x 金酒+ 0.3 x 利口酒 + 0.05 x 檸檬汁 + 0.05 x 可樂
龍舌蘭日出:0.3 x 金酒+ 0.1 x 利口酒 + 0.3 x 檸檬汁 + 0.3 x 可樂
可以用矩陣乘法來表示,中間的是權重矩陣。
 ?
?
左矩陣是1行4列,代表原料。右矩陣是4行3列,每一列代表對應雞尾酒的原料配比。
按照矩陣乘法的規則,他們的結果應該是一個1行3列的矩陣,分別代表調配出的三種雞尾酒。 由此可以清晰的看出矩陣乘法的對資源的整合和再創。對應在深度學習中,我們得到多張Feature Map后轉到1維后,就是得到了圖像的多種尺度下的各個特征,然后進行全連接時,我們利用權重矩陣與之相乘后相加,就是對各個特征進行了整合和再創,最后按照分類的數量來輸出。
?
3 循環神經網絡(RNN)
3.1 引入RNN的前言
- 為什么不用全連接處理序列數據?
看這個連接
理解RNN的結構+特點+計算公式_rnn結構-CSDN博客
比如預測天天氣,就需要知道之前幾天的數據,每一天的數據都包含若個特征,需要若干天的數據作為輸入
假設現在取前3天,每一天有3個特征
把x1,x2,x3拼成有9個維度的長向量,然后去訓練最后一天是否有雨
 ?
?
用全連接進行預測,如果輸入的序列很長,而且每一個序列維度很高的話,對網絡的訓練有很大挑戰,全連接層需要的權重很多,這點我們上面已經說過。
- 為什么卷積神經網絡的權重比較少呢?
卷積使用了權重共享,整張圖像的卷積核是共享的,并不是圖像的每一個像素要和下一層的Feature Map建立連接,權重少。
3.2 RNN
用于處理一些具有前后關系的序列問題。
循環神經網絡(Recurrent Neural Network, RNN)是一類以序列數據為輸入,在序列的演進方向進行遞歸且所有節點(循環單元)按鏈式連接的遞歸神經網絡。常見的循環神經網絡包括雙向循環神經網絡(Bidirectional RNN, Bi-RNN)和長短期記憶網絡(Long Short-Term Memory networks,LSTM)。循環神經網絡的真正形式是左邊這種,但是也常表現為右邊這種,一般隱藏層初始狀態為0,當輸入x1后,計算出下一個狀態h1,當輸入x2時,隱藏層狀態輸入變為h1,這時再輸出一個新的狀態h2,依次類推。
RNN專門用來處理帶有序列模式的數據,也使用權重共享減少需要訓練的權重的數量
我們把x1,x2,x3,xn看成是一個序列,不僅考慮x1,x2之間的連接關系,還考慮x1,x2的時間上的先后順序
x2依賴于x1,x3依賴于x2,下一天的天氣狀況部分依賴于前一天的天氣狀況,RNN主要處理這種具有序列連接的
天氣,股市,金融,自然語言處理都是序列數據
3.3 RNN cell
本質上是一個線性層,把一個維度映射到另一個維度。
RNN cell作為線性層是共享的,展開是后面,RNN cell可以依據不同的輸入和輸出循環調用。
運算過程:
h0和x1經過某種運算將他們拼接在一起,即:分別做線性變換,然后求和,生成h1。然后把h1,作為輸出送到下一次RNN cell計算中,這次輸入變成x2,x2和h1合在一起運算,生成h2等。
?
 ?
?
 ?
?
具體計算過程:
輸入xt先做線性變換,h t-1也是,xt的維度是input_size,h t-1的維度是hidden_size,輸出ht的維度是hidden_size,我們需要先把xt的維度變成hidden_size,所以Wih應該是一個 hidden_size*input_size的矩陣,Wih * xt得到一個 hidden_size*1的矩陣(就是維度為hidden_size的向量),bih是偏置。輸入權重矩陣Whh是一個hidden_size* hidden_size的矩陣。
whhHt-1+bhh和WihXt+bih都是維度為hidden_size的向量,兩個向量相加,就把信息融合起來了,融合之后用tanh做激活,循環神經網絡的激活函數用的是tanh,因為tanh的取值在-1到+1之間,算出結果得到隱藏層輸出ht。
把RNN Cell以循環的方式把序列(x1,x2,…)一個一個送進去,然后依次算出隱藏層(h1,h2…)的過程,每一次算出來的h會作為下一個RNN Cell的輸入,這就叫循環神經網絡 。
RNN 和RNN cell:
【PyTorch學習筆記】21:nn.RNN和nn.RNNCell的使用-CSDN博客?
(1)RNN cell
 ?
?
?
 ?
?
每次向網絡中輸入batch個樣本,每個時刻處理的是該時刻的batch個樣本。例如,輸入3句話,每句話包含10個單詞,每個單詞用100維向量表示,那么 seq_len = 10,batch = 3,feature_len = 100
 ?
?
import torch
batch_size=1
seq_len=3
input_size=4
hidden_size=2Cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)#初始化,構建RNNCelldataset=torch.randn(seq_len,batch_size,input_size)#設置dataset的維度
print(dataset)hidden=torch.zeros(batch_size,hidden_size)#隱層的維度:batch_size*hidden_size,先把h0置為0向量for idx,input in enumerate(dataset):print('='*10,idx,'='*10)print('Input size:',input.shape)hidden=Cell(input,hidden)print('Outputs size:',hidden.shape)print(hidden) ?
?
(2)RNN構造
 ?
?
 ?
?
 ?
?
?
import torch
batch_size=1
seq_len=3
input_size=4
hidden_size=2
num_layers=1
cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
#構造RNN時指明輸入維度,隱層維度以及RNN的層數
inputs=torch.randn(seq_len,batch_size,input_size)
hidden=torch.zeros(num_layers,batch_size,hidden_size)
out,hidden=cell(inputs,hidden)
print('Output size:',out.shape)
print('Output:',out)
print('Hidden size:',hidden.shape)
print('Hidden',hidden) ?
?
4 RNN 訓練hello 轉換到ohlol
?
 ?
?
?
 ?
?
 ?
?
?
#使用RNN
import torchinput_size=4
hidden_size=4
num_layers=1
batch_size=1
seq_len=5
# 準備數據
idx2char=['e','h','l','o'] # 0 1 2 3
x_data=[1,0,2,2,3] # hello
y_data=[3,1,2,3,2] # ohlol# e h l o
one_hot_lookup=[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]] #分別對應0,1,2,3項
x_one_hot=[one_hot_lookup[x] for x in x_data] # 組成序列張量
print('x_one_hot:',x_one_hot)# 構造輸入序列和標簽
inputs=torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
print(inputs)
labels=torch.LongTensor(y_data) #labels維度是: (seqLen * batch_size ,1)
print(labels)# design model
class Model(torch.nn.Module):def __init__(self,input_size,hidden_size,batch_size,num_layers=1):super(Model, self).__init__()self.num_layers=num_layersself.batch_size=batch_sizeself.input_size=input_sizeself.hidden_size=hidden_sizeself.rnn=torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)def forward(self,input):hidden=torch.zeros(self.num_layers,self.batch_size,self.hidden_size)out, _=self.rnn(input,hidden)# 為了能和labels做交叉熵,需要reshape一下:(seqlen*batchsize, hidden_size),即二維向量,變成一個矩陣return out.view(-1,self.hidden_size)net=Model(input_size,hidden_size,batch_size,num_layers)# loss and optimizer
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(), lr=0.05)# train cycle
for epoch in range(20):optimizer.zero_grad()#inputs維度是: (seqLen, batch_size, input_size) labels維度是: (seqLen * batch_size * 1)#outputs維度是: (seqLen, batch_size, hidden_size)outputs=net(inputs)loss=criterion(outputs,labels)loss.backward()optimizer.step()_, idx=outputs.max(dim=1)idx=idx.data.numpy()print('Predicted: ',''.join([idx2char[x] for x in idx]),end='')print(',Epoch [%d/20] loss=%.3f' % (epoch+1, loss.item()))- Embeding 嵌入層
one-hot編碼是稀疏的編碼方式,轉換為稠密的
獨熱編碼向量維度過高;
獨熱編碼向量稀疏,每個向量是一個為1其余為0;
獨熱編碼是硬編碼,編碼情況與數據特征無關;
采用一種低維度的、稠密的、可學習數據的編碼方式:Embedding。
Embedding把一個高維的稀疏的樣本映射到一個稠密的低維的空間里面,也就是數據的降維。
?
理解RNN的結構+特點+計算公式_rnn結構-CSDN博客
 ?
?
查詢
 ?
?
輸入為2,就表示是第二個字符的索引(索引從0開始),找到第2行,把這個向量輸出,這就叫embedding
?
 ?
?
輸入層必須是長整型張量,輸出是(seqlen,4)
 ?
?
embedding初始化:
num_bedding: input 獨熱向量的維度
num_bedding() 和 embedding_dim()構成矩陣的寬度和高度
輸入層必須是長整型張量,輸出是(input shape,embedding_shape)
 ?
?
#Embedding編碼方式
import torchinput_size = 4
num_class = 4
hidden_size = 8
embedding_size = 10
batch_size = 1
num_layers = 2
seq_len = 5idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 2, 3]# inputs 維度為(batchsize,seqLen)
inputs = torch.LongTensor(x_data)
# labels 維度為(batchsize*seqLen)
labels = torch.LongTensor(y_data)class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()#告訴input大小和 embedding大小 ,構成input_size * embedding_size 的矩陣self.emb = torch.nn.Embedding(input_size, embedding_size)self.rnn = torch.nn.RNN(input_size=embedding_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True)# batch_first=True,input of RNN:(batchsize,seqlen,embeddingsize) output of RNN:(batchsize,seqlen,hiddensize)self.fc = torch.nn.Linear(hidden_size, num_class) #從hiddensize 到 類別數量的 變換def forward(self, x):hidden = torch.zeros(num_layers, x.size(0), hidden_size)x = self.emb(x) # 進行embedding處理,把輸入的長整型張量轉變成嵌入層的稠密型張量x, _ = self.rnn(x, hidden)x = self.fc(x)return x.view(-1, num_class) #為了使用交叉熵,變成一個矩陣(batchsize * seqlen,numclass)net = Model()criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)for epoch in range(15):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted string: ', ''.join([idx2char_1[x] for x in idx]), end='')print(", Epoch [%d/15] loss = %.3f" % (epoch + 1, loss.item())🌈我的分享也就到此結束啦🌈
如果我的分享也能對你有幫助,那就太好了!
若有不足,還請大家多多指正,我們一起學習交流!
📢未來的富豪們:點贊👍→收藏?→關注🔍,如果能評論下就太驚喜了!
感謝大家的觀看和支持!最后,?祝愿大家每天有錢賺!!!歡迎關注、關注!
)


)

)








)
)



