在復雜分布式系統中,往往需要對大量的數據和消息進行唯一標識。如在美團點評的金融、支付、餐飲、酒店、貓眼電影等產品的系統中,數據日漸增長,對數據分庫分表后需要有一個唯一 ID 來標識一條數據或消息,數據庫的自增 ID 顯然不能滿足需求;特別一點的如訂單、騎手、優惠券也都需要有唯一 ID 做標識。此時一個能夠生成全局唯一ID 的系統是非常必要的。
Leaf——美團點評分布式ID生成系統
本文主要介紹一些常見的分布式唯一 ID 生成方案。
UUID(通用唯一識別碼)
UUID 是 Universally Unique Identifier 的縮寫,其目的是為了滿足在分布式系統中,各個節點可以獨立的生成唯一標識符,不需要依賴一個中心化的服務來分配 ID。相關設計最早在 1980 年代就已經提出,最終 2005 年在 RFC4122 中被完整定義。2024 年最新的 RFC 9562 發布,新增了 3 個新版本的 UUID 生成算法,取代了 RFC4122。
UUID 本身是一個長度為 128bit 的數字,通常用 32 位長度的 16 進制數字表示。因此其理論上的總數為 2^128,約等于 3.4 x 10^38。也就是說如果每納秒生成一萬個 UUID(每秒 10 萬億個),在完全隨機版本下,需要 1700 萬億年才能生成完所有的 UUID,妥妥的直到宇宙盡頭(宇宙預測壽命為 138 億年)。
在實際使用中,生成的 UUID 由 32 個字符和 4 個連字符表示,格式為 8-4-4-4-12,我們一般會在生成后將 - 給替換掉 UUID.randomUUID().toString().replaceAll("-","")。
RFC 4122 中定義了 5 個版本的 UUID,每個版本的算法不同,應用范圍也不同,分別為:
-
Time-based UUID:基于時間的 UUID。通過本機 MAC 地址、時間戳以及a隨機數計算出 UUID,格式為timestamp(60bit)-clock_seq(14bit)-MAC(48bit),另外還有 4bit 的 version 字段和 2 bit 的 variant 字段。因為使用了 MAC 地址,因此理論上絕對唯一,但 UUID 暴露了 MAC 地址,私密性不夠好。 -
DCE Security UUID:DCE安全的UUID。和版本一類似,但會將時間戳的前 4 位替換為 POSIX 的 UID 或 GID,實際很少使用。 -
UUID from names(MD5):基于名字的 UUID,通過 MD5(命名空間ID + 名稱) 計算出哈希值,該版本可以保證相同輸入產生相同輸出,但目前 MD5 已經不再安全,容易受到碰撞攻擊,現在推薦用 UUIDv5 替代。 -
truly random UUID:完全隨機 UUID。根據隨機數或者偽隨機數生成 UUID,這是使用最廣泛的版本,JDK 中實現的就是這個版本。 -
UUID from names(SHA1):UUIDv3 的升級版,通過 SHA1(命名空間ID + 名稱) 計算出哈希值,該版本可以保證相同輸入產生相同輸出,安全性相對較高。
RFC9562 又提出了三個新的版本,分別是:
-
Time-based UUID:對 UUIDv1 的升級,對時間戳進行了重排,將時間戳從高到低位有序排列,從而提高了數據庫索引性能。 -
Unix Epoch-based UUID:基于 Unix 時間戳的 UUID,使用當前時間戳(自 1970 年 1 月 1 日以來的毫秒數)作為 UUID 的前 48 位,整體格式為timestamp(48bit)-version(4bit)-randomA(12bit)-variant(2bit)-randomB(62bit)。 Version7 是專為現代數據庫和分布式系統設計的、基于時間的 UUID 格式。它結合了時間戳和高質量的隨機數,從而實現了優秀的排序性和唯一性。如果開發者使用的語言生態已經支持 Version7,應該優先使用該版本。以筆者熟悉的 Java 和 Golang 為例,JDK 尚不支持 Version7,但已經有 uuid-creator和 java-uuid-generator 開源庫支持;Golang 方面 Google 官方的uuid 庫已經支持。
-
Custom UUID:自定義 UUID,一種實驗性質或供應商特定用途的 UUID,除了 version 和 variant 字段外,其余 122bit 可以自由定義。
下面是使用 Java 和 Golang 生成的 Version4 和 Version7 版本的 UUID 示例:
- Golang 示例
package mainimport "github.com/google/uuid"func main() {uuidv4 := uuid.New()println("UUIDv4: " + uuidv4.String())uuidv7, _ := uuid.NewV7()println("UUIDv7: " + uuidv7.String())
}
輸出結果如下
UUIDv4: 496a53aa-e690-4d8f-bf77-316d294e2f81
UUIDv7: 01989e87-e56c-729b-a341-5faa691e4b24
- Java 示例
import java.util.UUID;public class UUIDDemo {public static void main(String[] args) {//默認是版本 4,完全隨機 IDUUID uuid = UUID.randomUUID();// 替換 -System.out.println(uuid.toString().replaceAll("-",""));}
}輸出結果如下
676a8fee6c1b48028dfc86e2bc35e4fe
數據庫自增 ID
一般在設計數據庫表時,一定會有一個 AUTO_INCREMENT=1 的 ID 字段,其本身就是一個表范圍的全局唯一 ID。但如果數據量達到一定量級,需要分庫分表時,生成的 ID 就會重復,此時一般需要設置自增 ID 的起始值和增長步長,比如 MySQL 提供了兩個字段進行設置:
auto_increment_offset:自增 ID 的起始值,默認是 1。auto_increment_increment:自增 ID 的增長步長,默認是 1。
比如當通過分庫分表拆分為三個數據庫時,可以設置如下起始值和步長來實現全局自增 ID 唯一:
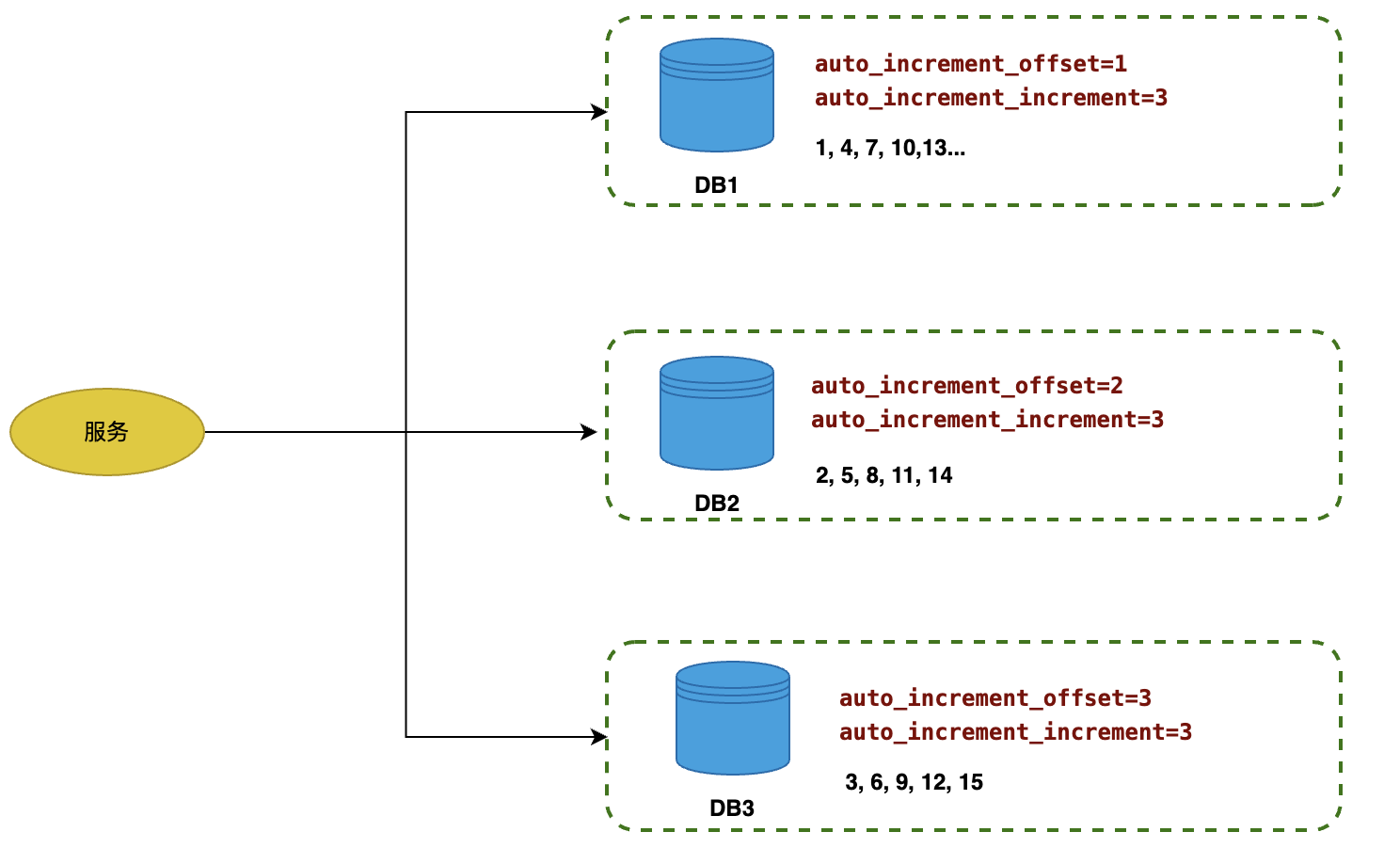
像數據庫的自增 ID、Redis 的 INCR 和 INCRBY 命令,Zookeeper 的 Sequential 節點,都帶有自增屬性,因此都可以用來實現分布式唯一ID,但這些方案都會對中間件產生依賴。無論是使用的編碼復雜度,還是對中間件的高可用性要求,相比其他方案都會有一定的劣勢。
雪花算法
Snowflake(雪花算法) 是由 Twitter 提出的分布式唯一 ID 生成方案。其核心思想是將時間戳、機器 ID 和序列號結合在一起,生成一個 64 位的唯一 ID。
雪花算法的 ID 結構如下:
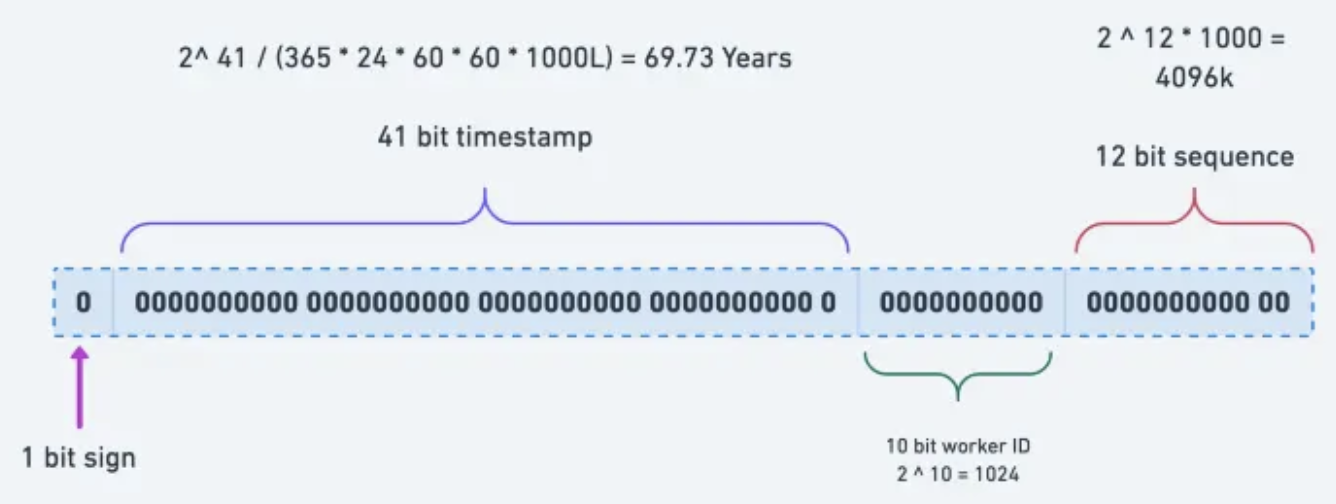
- 1 個保留位,始終為 0。
- 41 位時間毫秒時間戳,其可用年限大約為 69 年。
- 10 位機器 ID,支持 1024 臺機器。還可以繼續細分, 5 位給 IDC,5 位給工作機器。
- 12 位序列號,可以表示 2^12 = 4096 個數。因此雪花算法最大支持每毫秒生成 4096 個 ID。
基于以上字段分布,雪花算法可以每毫秒在一個數據中心的一臺機器上產生4096個有序的不重復的ID。
不過因為是時間戳的原因,雪花算法在生成 ID 時需要考慮時鐘回撥的問題。如果系統時間發生回撥,可能會導致生成的 ID 重復。因此在使用雪花算法時,需要確保系統時間的準確性。Twitter 的官方實現并沒有對其做明確處理,只是簡單的報錯,這樣會導致分布式ID服務短期內不可用。后續的開源方案,像美團的 Leaf,百度的 UidGenerator 都對其做了優化,這也是比較常用的兩個開源庫,在實際工程中如果需要,可以在詳細調研后進行選型。


)
——進程管理和計劃任務管理)











)



