接上篇繼續:
Python零基礎-上【詳細】-CSDN博客
目錄
十、函數式編程
1、匿名函數lambda表達式
(1)匿名函數理解
(2)lambda表達式的基本格式
(3)lambda表達式的使用場景
(4)def 與 lambda 函數對比
2、map函數
(1)map的基本格式
(2)示例
(3)函數中帶兩個參數的map函數格式
3、reduce函數
(1)reduce函數的基本格式
(2)示例
4、filter函數
(1)filter理解
(2)filter函數基本格式
(3)filter函數使用
5、sorted函數
(1)sorted理解
(2)sorted函數基本格式
(3)應用
# 對序列做升序排序
# 對序列做降序排序
# 對存儲多個列表的序列做排序
6、閉包
7、閉包經典問題
8、裝飾器
(1)裝飾器理解
(2)示例
十一、Python核心知識點
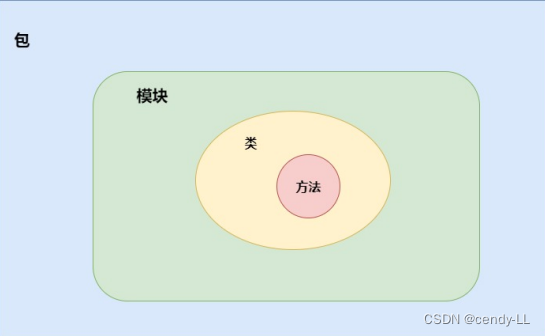
1、Python工程組織結構之包、模塊
(1)模塊
(2)包
(3)包與子包
2、命名空間
(1)命名空間理解
(2)命名空間查找順序
(3)當函數嵌套時的查找規則
(4)命名空間的生命周期
(5)命名空間的訪問
# 局部命名空間的訪問
# 全局命名空間的訪問
(6)locals 與 globals 之間的區別
3、在Python工程中導入模塊
4、在Python工程中導入變量
(1)導入一個變量
(2)導入多個變量
5、python中的導包機制
(1)Python導入機制
(2)模塊導入示例
6、__init__.py的作用及用法
(1)作用
(2)用法
7、__all__、 __name__的作用及其用法
(1)__all__ 的作用及其用法
(2)__name__ 的作用及其用法
十二、錯誤處理
1、Python中異常的捕獲與處理
(1)錯誤
(2)異常
(3)警告
(4)異常處理
2、自定義異常與異常的拋出
(1)自定義異常
(2)異常拋出
3、如何通過debug分析問題
(1)簡單問題分析
(2)復雜問題分析
4、為代碼編寫單元測試
(1)什么是單元測試
(2)單元測試的優缺點
(3)如何編寫單元測試
十三、IO操作
1、輸入輸出
2、文件的讀取
(1)打開文件
(2)讀取文件
3、文件內容的寫入
4、操作文件夾
(1)創建文件夾
(2)創建多層級文件夾
(3)獲取當前所在目錄
(4)改變當前的工作目錄
(5)刪除空文件夾
(6)刪除多層空文件夾
5、操作文件夾示例
(1)文件夾下僅有文件的刪除
(2)文件夾下有子文件夾的刪除
6、StringIO和BytesIO
(1)理解
(2)用法
十四、面向對象編程
1、面向對象及其三大特性
(1)面向對象理解
(2)面向對象的三大特性
2、類和對象
(1)類和對象的理解
(2)類和對象的關系
(3)定義類以及實例化對象
3、類的構造函數
(1)什么是構造函數
(2)構造函數的用途
4、類變量與實例變量
(1)類變量
(2)實例變量
(3)訪問實例變量和類變量
(4)修改實例變量和類變量的值
(5)實例變量查找規則
(6)類變量存儲
5、實例方法與self關鍵字
(1)實例方法
(2)self關鍵字作用
(3)self名稱統一
6、類方法與靜態方法
(1)類方法
(2)靜態方法
7、Python中的訪問限制
8、打破Python中的訪問限制
十五、面向對象高級特性
1、python中的繼承
(1)繼承的理解
(2)python中如何繼承
2、super的作用及其用法
(1)super函數理解
(2)super函數的基本語法
(3)super函數應用
3、抽象方法與多態
(1)抽象方法理解
(2)定義抽象類
(3)多態理解
(4)多態的好處
4、python中的多重繼承
5、多重繼承所帶來的的問題
(1)新式類和舊式類
(2)菱形繼承(鉆石繼承)
(3)解決菱形繼承問題
6、枚舉類
(1)枚舉理解
(2)枚舉實例
(3)枚舉訪問
(4)枚舉類的特性
(5)枚舉成員的比較
十、函數式編程
1、匿名函數lambda表達式
(1)匿名函數理解
匿名函數,即沒有名字的函數,在程序中不用使用 def 進行定義,可以直接使用 lambda 關鍵字編寫簡單的代碼邏輯,lambda 本質上是一個函數對象,可以將其賦值給另一個變量,再由該變量來調用函數,也可以直接使用
(2)lambda表達式的基本格式
lambda入參:表達式入參可有多個,如下:
power = lambda x, n: x ** n
print('%d的%d次方的結果是:%d' % (2, 3, power(2, 3)))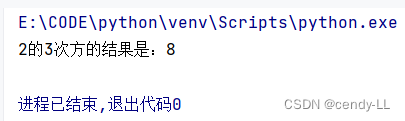
(3)lambda表達式的使用場景
一般適用于創建一些臨時性的、小巧的函數,比如上面的power函數,我們可以使用 def 來定義,但使用 lambda 來創建會顯得很間接,尤其是在高階函數的使用中
(4)def 與 lambda 函數對比
示例:定義一個函數,傳入一個list,將list每個元素的值加1(另一個地方調用將所有元素的值加2)
# 定義函數,把需要增加的地方抽出來,讓調用者自己傳
def add(func, l=[]):return [func(x) for x in l]def add1(x):return x + 1def add2(x):return x + 2print(add(add1, [1, 2, 3]))
print(add(add2, [1, 2, 3]))
# 直接使用lambda函數調用
def add(func, l=[]):return [func(x) for x in l]print(add(lambda x: x + 1, [1, 2, 3]))
print(add(lambda x: x + 2, [1, 2, 3]))
2、map函數
(1)map的基本格式
map() 函數接收兩個以上的參數,開頭是一個函數,剩下的是序列,將傳入的函數依次作用到序列的每個元素,并把結果作為新的序列返回,也就是類似于 map(func,[1,2,3])
map(func, *iterables)(2)示例
這里還是以列表值+1為例:傳入一個list,將list每個元素的值加1
# 定義函數,然后使用map()調用
def add(x):return x + 1result = map(add, [1, 2, 3, 4])
print(type(result))
print(list(result))
# 使用 lambda表達式簡化操作
result = map(lambda x: x + 1, [1,2,3,4])
print(type(result))
print(list(result))
(3)函數中帶兩個參數的map函數格式
使用map()函數,將兩個序列的數據對應位置求和,之后返回,也就是對[1,2,3]、[4,5,6]兩個序列進行操作之后,返回結果[5,7,9],如下:
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5, 6])))
若對于兩個序列元素個數不一樣的,序列各元素想加,查看返回結果,結果以個數少的為準
print(list(map(lambda x, y: x + y, [1, 2, 3], [4, 5])))
3、reduce函數
(1)reduce函數的基本格式
reduce把一個函數作用在一個序列上,這個函數必須接收兩個參數,reduce函數把結果繼續和序列的下一個元素做累積計算,和遞歸類似,reduce函數會被上一個計算結果應用到本次計算中
reduce(function, sequence, initial=None)reduce(func, [1, 2, 3]) = func(func(1, 2), 3)(2)示例
# 使用reduce函數,計算一個列表的乘積
from functools import reducedef func(x, y):return x * yprint(reduce(func, [1, 2, 3, 4]))
# 使用lambda表達式,計算一個列表的乘積
from functools import reduceprint(reduce(lambda x, y: x * y, [1, 2, 3, 4]))
4、filter函數
(1)filter理解
filter顧名思義是過濾的意思,不需要的數據經過filter處理之后,就被過濾掉
(2)filter函數基本格式
filter()接收一個函數和一個序列,把傳入的函數依次作用于每個元素,然后根據返回值是 True 還是 False 決定保留還是丟棄該元素
filter(functin_or_None, iterable)(3)filter函數使用
使用filter函數對給定序列進行操作,最后返回序列中所有偶數
print(list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5])))
5、sorted函數
(1)sorted理解
sorted 從字面意思就可以看出這是一個用來排序的函數,sorted 可以對所有可迭代的對象進行排序操作
(2)sorted函數基本格式
sorted(iterable, key=None, reverse=False)- iterable:可迭代對象
- key:主要是用來進行比較的元素,只有一個參數,具體函數的參數就是取自于可迭代對象中,指定可迭代對象中的一個元素來進行排序
- reverse:排序規則,reverse = True 降序 ; reverse = False 升序(默認)
(3)應用
# 對序列做升序排序
print(sorted([1, 6, 4, 5, 9]))
# 對序列做降序排序
print(sorted([1, 6, 4, 5, 9],reverse=True))
# 對存儲多個列表的序列做排序
data = [["Python", 99], ["c", 88]]
print(sorted(data, key=lambda item: item[1]))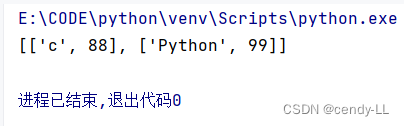
6、閉包
在萬物皆對象的Python中,函數也可作為函數的返回值進行返回
def my_power():n = 2def power(x):return x ** nreturn powerp = my_power()
print(p(4))
從下面的代碼段可以看出:my_power函數在返回的時候,也將其引用的值(n)一同帶回,n 的值被新的函數所使用,這種情況被稱為閉包
def my_power():n = 2def power(x):return x ** nreturn powern = 3
p = my_power()
print(p(4))
print(p.__closure__)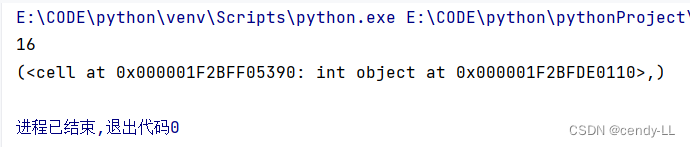
下面的例子:不是閉包,未返回環境變量,只返回了函數
n = 2def my_power():def power(x):return x ** nreturn powern = 3
p = my_power()
print(p(4))
print(p.__closure__)
7、閉包經典問題
下面的程序不是閉包,且執行報錯,閉包在引用變量時,不能直接修改引用變量的值
def my_power():n = 2def power(x):n += 1return x ** nreturn powerp = my_power()
print(p(3))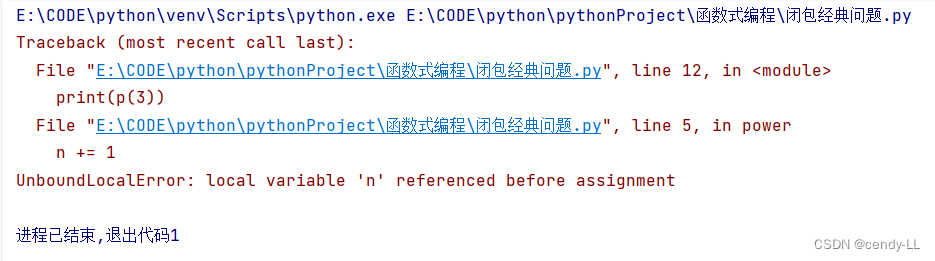
將上面的程序修改為閉包,如下:
def my_power():n = 2def power(x):nonlocal nn += 1return x ** nreturn powerp = my_power()
print(p(3))
print(p.__closure__)
Python函數只有在執行時,才會去找函數體里的變量的值,形參不確定,目標i的值就不確定;在形參未確定前,Python就只會記住最后一個值,因此i都等于2
def my_power():n = 2L = []for i in range(1, 3):def power():return i ** nL.append(power)return Lf1, f2 = my_power()
print(f1())
print(f2())
print('-----------------')
print(f1.__closure__[0].cell_contents)
print(f1.__closure__[1].cell_contents)
print(f2.__closure__[0].cell_contents)
print(f2.__closure__[1].cell_contents)
8、裝飾器
(1)裝飾器理解
裝飾器允許想一個現有對象添加新的功能,同時又不改變其結構,這種類型的設計模式屬于結構型模式,它是作為現有的類的一個包裝
這種模式創建了一個裝飾類,用來包裝原有的類,并在保持類方法簽名完整性的前提下,提供了額外的功能
import time
start = time.time()
time.sleep(4)
end = time.time()
print(end - start)(2)示例
打印【這是一個函數】
def my_fun():print("這是一個函數")my_fun()
如果想要獲取函數執行的時間,這里改動到了原來的函數,則如下
import timedef my_fun():begin = time.time()time.sleep(2) # 這里讓結果看起來更直觀點,睡眠了2秒print("這里一個函數")end = time.time()print(end - begin)my_fun()

若不想修改原有函數,想要獲取函數執行的時間,如下(第二種):
第一種:該方法不可取,因為要增加功能會導致所有的業務調用方都得進行修改
import timedef my_fun():print("這是一個函數")def my_time(func):begin = time.time()time.sleep(2)func()end = time.time()print(end - begin)my_time(my_fun)第二種:
import timedef print_cost(func):def wrapper():begin = time.time()time.sleep(2)func()end = time.time()print(end - begin)return wrapper@print_cost
def my_fun():print("這里一個函數")my_fun()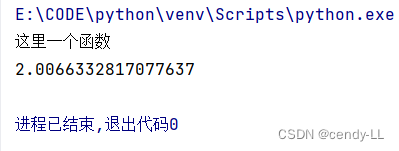
十一、Python核心知識點
1、Python工程組織結構之包、模塊
(1)模塊
當我們新建一個python file,這個時候形成一個 .py 后綴的文件,這個文件就稱之為模塊
(2)包
在pycharm中,我們右鍵可以創建一個目錄,也可以創建一個包,兩者看起來差不多,唯一的區別在于,創建包的時候,包下面會有一個__init__.py的文件,這也是python為了區分目錄和包所做出的界定
(3)包與子包
包下面,還能新建包,稱之為子包
2、命名空間
(1)命名空間理解
命名空間是變量到對象的映射集合,一般都是通過字典來實現的。主要可以分為三類:
- 每個函數都有著自已的命名空間,叫做局部命名空間,它記錄了函數的變量,包括函數的參數和局部定義的變量
- 每個模塊擁有它自已的命名空間,叫做全局命名空間,它記錄了模塊的變量,包括函數、類、其它導入的模塊、模塊級的變量和常量
- 內置命名空間,任何模塊均可訪問它,它存放著內置的函數和異常
通俗點講:命名空間就是為了確定全局的唯一,比如模塊A中有變量c,模塊B中也有一個變量c,此時,通過A.c來確定引用A中的變量c,比如在class2模塊中要引用class1中的變量a,在導入class1模塊之后,可以使用class1.a訪問class1中的變量
(2)命名空間查找順序
當一行代碼要使用變量 x 的值時,Python 會到所有可用的命名空間去查找變量,按照如下順序:
- 局部命名空間:特指當前函數或類的方法,如果函數定義了一個局部變量 x,或一個參數x,Python 將使用它,然后停止搜索
- 全局命名空間:特指當前的模塊,如果模塊定義了一個名為 x 的變量、函數或類,Python將使用它然后停止搜索
- 內置命名空間:對每個模塊都是全局的,作為最后的嘗試,Python 將假設 x 是內置函數或變量
- 如果 Python 在這些命名空間找不到 x,它將放棄查找并引發一個 NameError 異常,如 NameError: name 'xxx' is not defined
(3)當函數嵌套時的查找規則
- 先在當前 (嵌套的或 lambda) 函數的命名空間中搜索
- 然后是在父函數的命名空間中搜索
- 接著是模塊命名空間中搜索
- 最后在內置命名空間中搜索
def my_func():name = "小北 "def func_son():name = "小南 " # 此處的name變量,覆蓋了父函數的name變量print(name)# 調用內部函數func_son()print(name)my_func()
(4)命名空間的生命周期
- 內置命名空間在 Python 解釋器啟動時創建,會一直保留,不被刪除
- 模塊的全局命名空間在模塊定義被讀入時創建,通常模塊命名空間也會一直保存到解釋器退出
- 當函數被調用時創建一個局部命名空間,當函數返回結果或拋出異常時,被刪除,每一個遞歸調用的函數都擁有自己的命名空間
a = 1def my_func(str):if a == 1:print(str)a = 24my_func("file")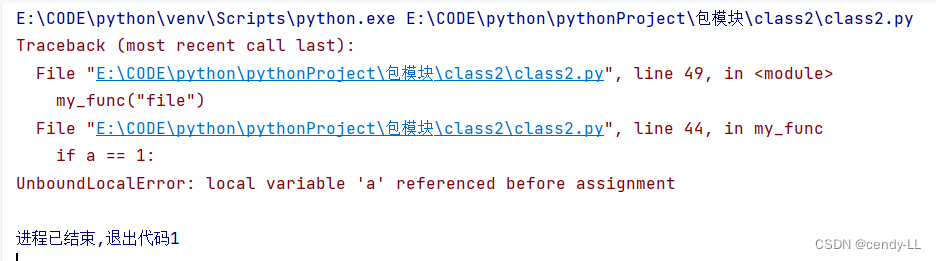
上面的程序會報錯,在python的函數中和全局同名的變量,如果你有修改變量的值就會變成局部變量,在修改之前對該變量的引用自然就會出現沒定義這樣的錯誤了,如果確定要引用全局變量,并且要對它修改,就必須加上global關鍵字,如下:
a = 1def my_func(str):global aif a == 1:print(str)a = 24my_func("file")
print(a)
(5)命名空間的訪問
# 局部命名空間的訪問
局部命名空間可以用 locals() 來訪問
def my_func():a = 1b = 2print(locals())my_func()
locals 返回一個名字/值對的 dictionary ,這個?dictionary 的鍵是字符串形成的變量名字,dictionary 的值是變量的實際值
# 全局命名空間的訪問
全局命名空間可以通過 globals() 來訪問
a = 1
b = 2print(globals())
(6)locals 與 globals 之間的區別
locals 是只讀的,但 globals 是可讀寫的
def my_func():x = 123print(locals())locals()["x"] = 456print("x=", x)y = 123
my_func()
globals()["y"] = 111
print("y=", y)
3、在Python工程中導入模塊
在平時的開發中,一般會有多模塊,為了軟件的復用性,我們通常在模塊之間相互引用,以達到復用的目的
在Python中,可以使用 import 關鍵字進行模塊的導入,語法如下:
import module_name例如,在模塊 class3 中要引用同目錄下 test 中的變量 a ,此時可以如下:
import testprint(test.a)
這個時候,需要使用命名空間來訪問相應的變量,這個導入似乎很輕松,但是如果模塊名太長,代碼寫起來就顯得非常拖沓,這個時候想讓代碼看起來簡短些,就可以使用別名,uti語法如下:
import module_name as aliasimport 導入時,要做的操作:
- 查找一個模塊,如果有必要還會加載并初始化模塊
- 在局部命名空間中為 import 語句位置所處的作用域定義一個或多個名稱
當一個模塊首次被導入時,Python 會搜索該模塊,如果找到就創建一個 module 對象并初始化它;如果置頂名稱的模塊未找到,則會引發 ModuleNotFoundError ,當發起調用導入機制時,Python 會實現多種策略來搜索指定名稱的模塊
注意:當模塊首次被導入時,會執行模塊里面的代碼
使用 import 關鍵字導入模塊是最常用的方式,但是還有另外的方法可以導入模塊,即使用 importlib 模塊進行導入,基本語法如下:
import importlib
importlib.import_module("module_name")若想要導入另一個包中的模塊,語法如下:
from package import module示例:
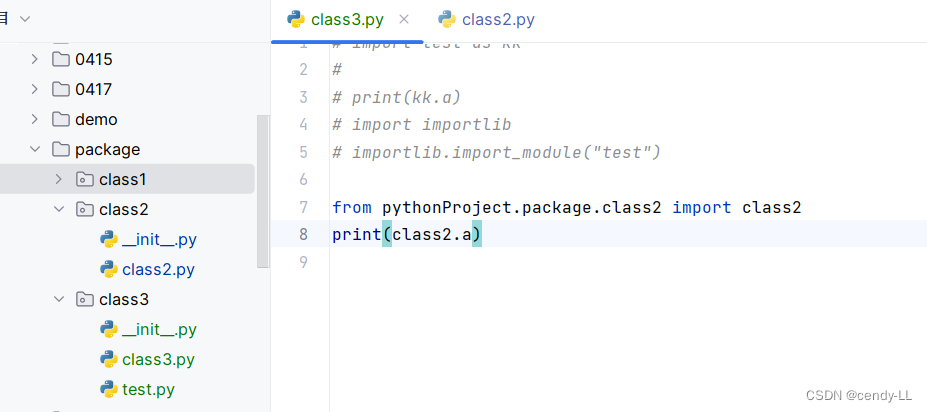
from pythonProject.package.class2 import class2
print(class2.a)
若想要導入多層包中的模塊,語法如下(可參考上面示例):
from package.son import module# 【package.son】是多層包路徑4、在Python工程中導入變量
(1)導入一個變量
導入一個變量時,基本語法如下:
from module import variable示例:從 test 中導入變量 a
from test import aprint(a)
注意:當模塊首次被調用時,會執行模塊里面的代碼
修改 test 中的內容,再次運行 class4 文件,就會發現,先輸出 hello world ,再打印 a 的值
a = 1111
print("hello world")
(2)導入多個變量
如果要導入多個變量,可以使用逗號分隔
from class3 import a, b
print(a)
print(b)
若要導入的變量非常多,則可以使用【*】進行導入
from test import *
print(a)
print(b)
print(c)
注意:雖然支持【*】通配符進行導入,但是不建議過多使用,因為使用【*】導入,閱讀代碼時會難以理清其含義
5、python中的導包機制
(1)Python導入機制
導入期間,會在 sys.modules 查找模塊名稱,如存在則其關聯的值就是需要導入的模塊,導入過程完成,如果值為 None ,則會引發 ModuleNotFoundError;如果找不到指定
模塊名稱,Python 將繼續搜索該模塊
如果指定名稱的模塊在 sys.modules 找不到,則將發起調用 Python 的導入協議以查找和加載該模塊。此協議由兩個概念性模塊構成,即查找器和加載器
- 查找器的任務是確定是否能使用其所知的策略找到該名稱的模塊
- 同時實現這兩種接口的對象稱為導入器,它們在確定能加載所需的模塊時會返回其自身
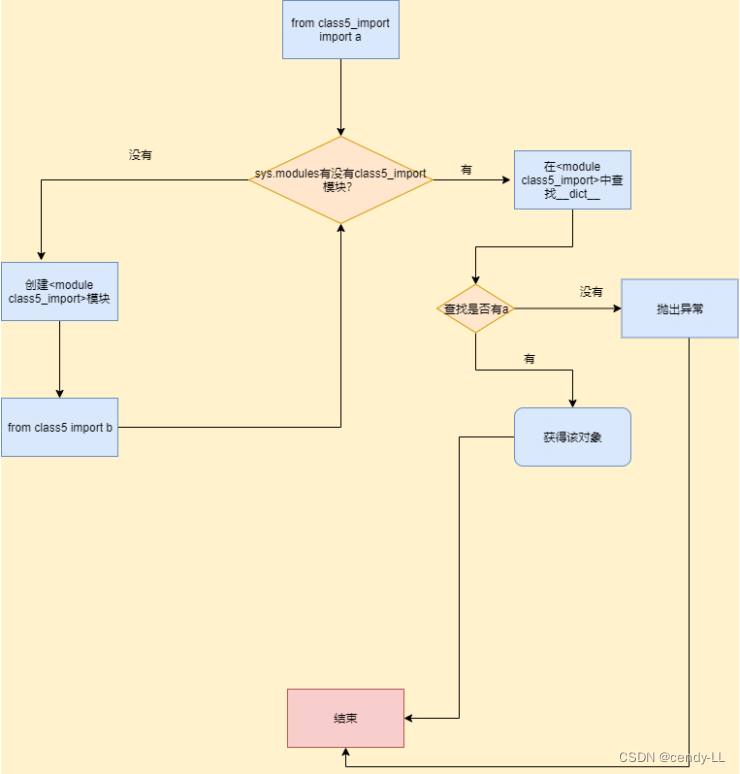
以【from class5_import import a】為例,來理解Python導入機制:
在sys.modules中查找符號"class5_import"
# 如果符號存在,則獲得符號class5_import對應的module對象<module class5_import>
?? ?@ 從<module class5_import>的dict中獲得符號"a"對應的對象,如果"a"不存在,則拋出異常
# 如果符號class5_import不存在,則創建一個新的module對象<module class5_import>,注意,這時,module對象的dict為空
# 執行class5_import.py中的表達式,填充<module class5_import>的dict
# 從<module class5_import>的dict中獲得"a"對應的對象,如果"a"不存在,則拋出異常
(2)模塊導入示例
【模塊 class5.py】
from class5_import import ab = 22
print(a)【模塊 class5_import.py】
from class5 import ba = 11執行過程如下:
class5.py會執行報錯
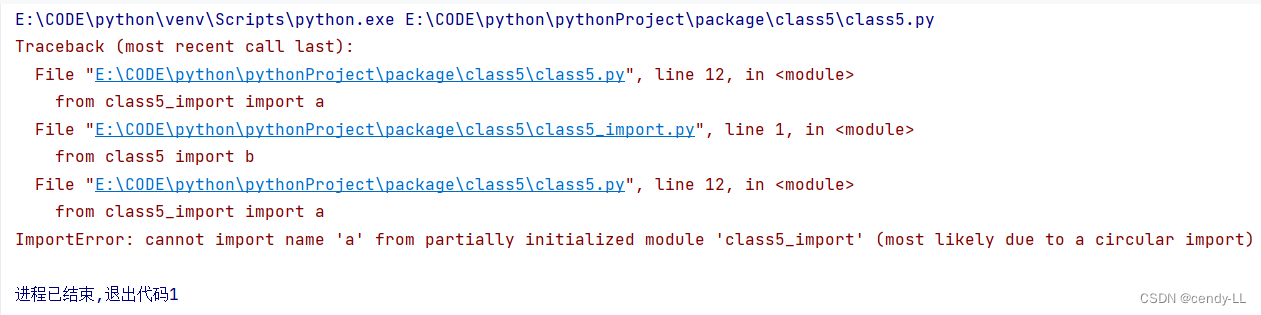
# 執行class5.py中的from class5_import import a,由于是執行的python class5.py,所以在sys.modules中并沒有<module class5_import>存在,首先為B.py創建一個module對象(<module class5_import>),【注意,這時創建的這個module對象是空的,里邊啥也沒有】,在Python內部創建了這個module對象之后,就會解析執行class5_import.py,其目的是填充<module class5_import>這個dict
# 執行class5_import.py中的 from class5 import b,在執行class5_import.py的過程中,會碰到這一句,首先檢查sys.modules這個module緩存中是否已經存在<module class5>了,由于這時緩存還沒有緩存<module class5>,所以類似的,Python內部會為class5.py創建一個module對象(<module class5>),然后,同樣地,執行class5.py中的語句
# 再次執行class5.py中的from class5_import import a,這時,由于在第1步時,創建的<module class5_import>對象已經緩存在了sys.modules中,所以直接就得到了<module class5_import>【注意,從整個過程來看,我們知道,這時<module class5_import>還是一個空的對象,里面啥也沒有】,所以從這個module中獲得符號"a"的操作就會拋出異常;如果這里只是import class5_import,由于"class5_import"這個符號在sys.modules中已經存在,所以是不會拋出異常的
流程圖如下:
6、__init__.py的作用及用法
(1)作用
- 標志所在目錄是一個模塊包
- 本身也是一個模塊
- 可用于定義模糊導入時要導入的內容
(2)用法
我們使用【from package import *】時會報錯誤,如果想使用該語法不報錯,可以在__init__.py 中定義要導入的模塊,即使用 __all__=['module_name1','module_name2'] 定義【*】號匹配時要導入的模塊,之后再導入的時候,就可以使用【*】通配符進行模糊導入
- 導入一個包的時候,包下的 __init__.py 中的代碼會自動執行
- 用于批量導入模塊
當我們的許多模塊匯總,都需要導入某些公共的模塊,此時可以在__init__.py 中進行導入,之后直接導入該包即可
7、__all__、 __name__的作用及其用法
(1)__all__ 的作用及其用法
__all__是list的結構,其作用如下:
- 在普通模塊中使用時,表示一個模塊中允許哪些屬性可以被導入到別的模塊中
- 在包下的__init__.py中,可用于標識模糊導入時的模塊
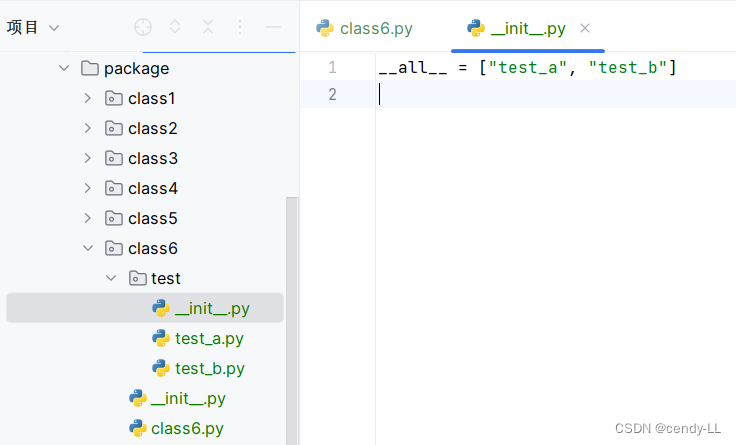
在class6.py中導入包test,即可調用test包下的內容
class6.pyfrom pythonProject.package.class6.test import *
print(test_a.a)(2)__name__ 的作用及其用法
- __name__這個系統變量顯示了當前模塊執行過程中的名稱,如果當前程序運行在這個模塊中,__name__ 的名稱就是__main__,如果不是,則為這個模塊的名稱
- __main__一般作為函數的入口,類似于C語言,尤其在大型工程中,常常有【if __name__ == "__main__"】來表明整個工程開始運行的入口
示例:
def my_fun():if __name__ == "__main__":print("this is main")else:print(__name__)my_fun()
十二、錯誤處理
1、Python中異常的捕獲與處理
(1)錯誤
即還沒開始運行,在語法解析的時候就發現語法存在問題,這個時候就是錯誤,例如:
print("hello world"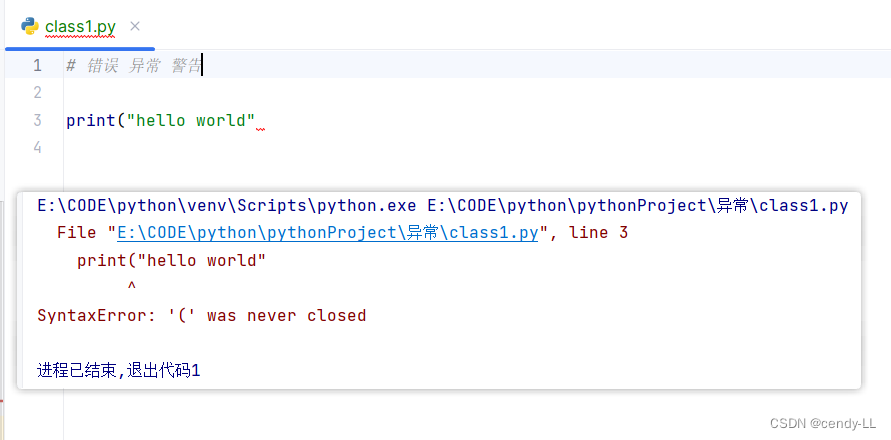
上面這句少了個括號,這個時候編輯器已經告訴我們這句語法有問題,如果繼續運行,就會報相應的錯誤
(2)異常
代碼寫好之后,無明顯語法錯誤(編輯器不知道有錯,語法解析時也不知道有錯),但是運行的時候會發生錯誤,這個時候稱之為異常,例如:
print(10 / 0)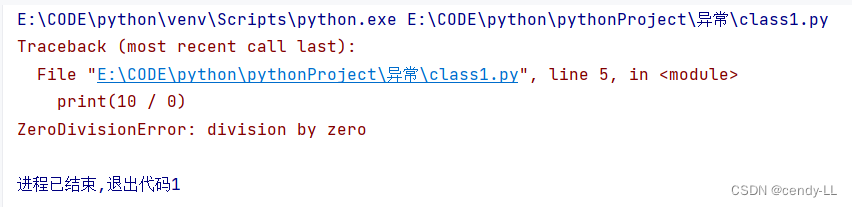
(3)警告
import warningsdef fxn():print("hello")warnings.warn("deprecated", DeprecationWarning)fxn()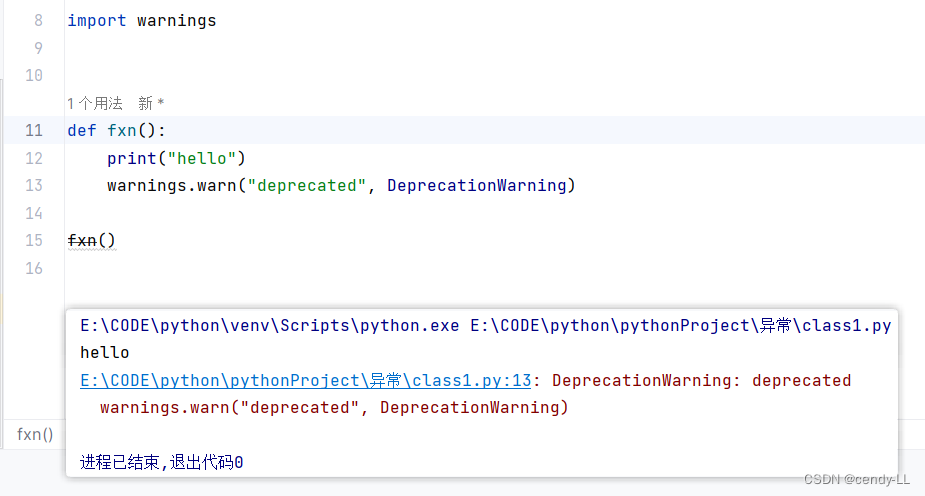
(4)異常處理
異常的處理格式如下:
try:你要做的可能會發生異常的事
except 可能會發生的異常:發生異常之后要做的事
except 可能會發生的異常2:發生異常之后要做的事2
finally:最終要做的事情示例如下:
try:print(10 / 0)
except ZeroDivisionError:print("除數不能為0")
在平時的開發中,也會使用預定義清理的操作,來避免因為異常而導致程序崩潰,比如在進行IO操作的時候,可以使用如下代碼,這樣一旦運行時發生異常,程序會自動幫你關閉文件,避免整程序崩潰
with open("myfile.txt") as f:for line in f:print(line, end="")2、自定義異常與異常的拋出
(1)自定義異常
雖然Python中提供了非常多的內置異常類,但是在平時開發中,針對特定業務,可能需要自定義異常,此時通過自定義集成Exception類的類,可以實現異常的自定義
class MyException(Exception):def __init__(self, parameter):err = '非法入參{0},分母不能為0'.format(parameter)Exception.__init__(self, err)self.parameter = parameter(2)異常拋出
當我們代碼中碰到某種特殊業務情況,需要向調用方拋出自定義異常,可以使用【raise】關鍵字
from class12.my_exception import MyExceptiondef my_fun(x):if x == 0:raise MyException(x)return 12 / xprint(my_fun(0))
我們在捕獲異常后,也可直接將異常拋出,此時直接使用【raise】關鍵字即可
def my_func():try:print(10 / 0)except ZeroDivisionError:print("除數不能為0")# 此處直接將捕獲的異常拋出raisemy_func()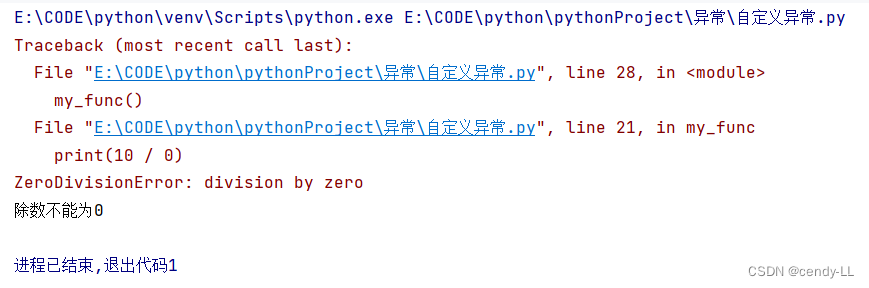
3、如何通過debug分析問題
(1)簡單問題分析
首先,我們編寫一個函數,有兩入參 x,y,函數的返回值是 x/y 的值
def my_fun(x, y):result = x / yreturn resultprint(my_fun(12, 0))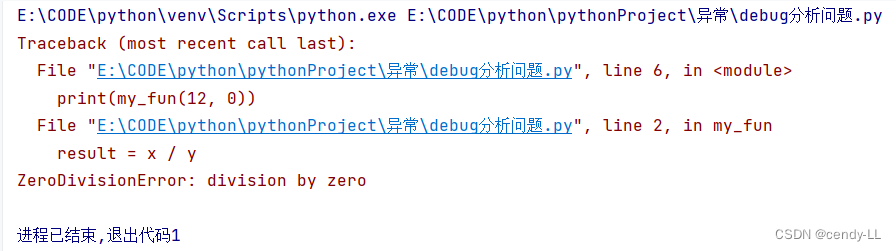
如上圖,當入參變成[12,0]的時候,就會發生異常,這時候去定位問題:
- 看錯誤信息,提取關鍵部分
- 看錯誤發生的地方,并找出對應的位置(PyCharm中有行數顯示)
這個時候可以看到,這個錯誤發生的地方是在第2行,當第6行調用第2行時發生錯誤,對于這種問題結合上面的推斷,就可以解決問題了
(2)復雜問題分析
第一步:在對應出錯的地方打下斷點
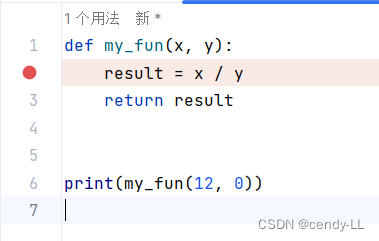
第二步:右鍵選擇debug

此時,程序運行至斷點處就會停住,在下面的控制臺可以看到此時對應的值,至此,可以確定異常產生的原因,從而解決問題
4、為代碼編寫單元測試
(1)什么是單元測試
單元測試(英語:Unit Testing)又稱為模塊測試,是針對程序模塊(軟件設計的最小單位)來進行正確性檢驗的測試工作。程序單元是應用的最小可測試部件,在過程化編程中,一個單元就是單個程序、函數、過程等;對于面向對象編程,最小單元就是方法,包括基類(超類)、抽象類、或者派生類(子類)中的方法。
簡而言之:就是寫一段代碼,用來驗證另一段代碼在特定情況下的正確性
(2)單元測試的優缺點
- 好處:減少bug、提高代碼質量、可以放心重構(在未來修改實現的時候,可以保證代碼的行為仍舊是正確的)
- "壞處":占用開發時間,尤其是在起步階段
(3)如何編寫單元測試
第一步:新建Python文件,編寫具體業務代碼
class MyTest():def my_add(self, a, b):return a + b第二步:右鍵類名,選擇【Go To】---> 【test】,或者直接【ctrl+shift+t】
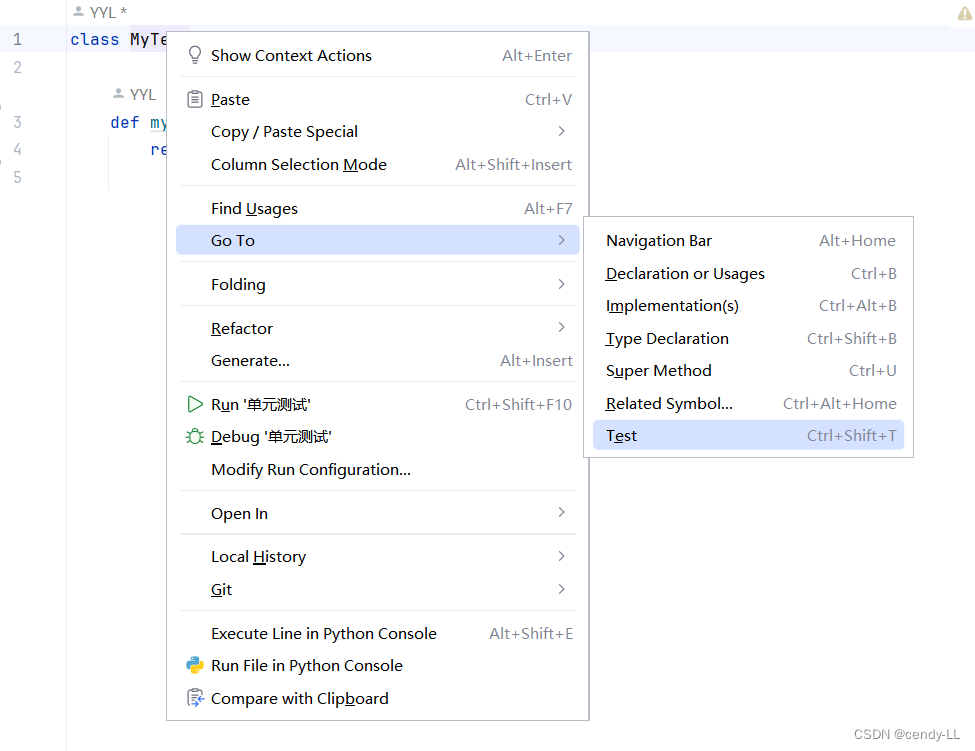
第三步:填寫相應的模塊名及測試類名,點擊OK,此時PyCharm 會幫我們自動創建測試模塊及類
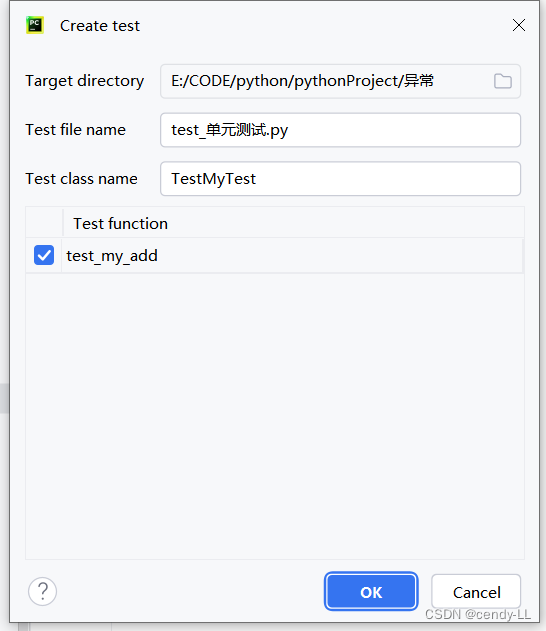
第四步:編寫測試代碼,并執行單元測試
import unittest
from unittest import TestCase
from pythonProject.異常.單元測試 import MyTestclass TestMyTest(TestCase):def test_add(self):s = MyTest()self.assertEqual(s.my_add(1, 5), 6)if __name__ == "__main__":unittest.main()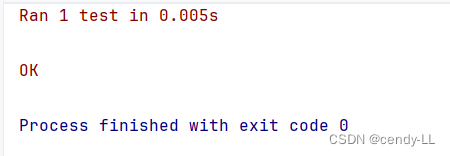

十三、IO操作
1、輸入輸出
Python提供了 input() 內置函數從標準輸入讀入一行文本,默認的標準輸入是鍵盤
print("用戶輸入的內容是:",input())當用戶在控制臺輸入內容之后按回車,此時我們可以看到控制臺輸出如下:

優化內容,實現用戶的友好交互,如下:
print("請輸入內容,按回車結束:")
str = input()
print("用戶輸入的內容是:", str)
2、文件的讀取
(1)打開文件
在Python中,可以使用 open 函數來打開文件,具體語法如下:
open(filename, mode)- filename:文件名,一般包括該文件所在的路徑
- mode:模式,如果讀取時讀取中文文本,需要在打開文件的時候使用 encoding 指定字符編碼為 utf-8
常見的打開文件的模式如下:
| 模式 | 描述 |
| t | 文本模式(默認) |
| x | 寫模式,新建一個文件,如果該文件已存在則會報錯 |
| b | 二進制模式 |
| + | 打開一個文件進行更新(可讀可寫) |
| r | 以只讀方式打開文件,文件的指針將會放在文件的開頭,這是默認模式 |
| rb | 以二進制格式打開一個文件用于只讀,文件指針將會放在文件的開頭,這是默認模式,一般用于非文本文件如圖片等 |
| r+ | 打開一個文件用于讀寫,文件指針將會放在文件的開頭 |
| rb+ | 以二進制格式打開一個文件用于讀寫,文件指針將會放在文件的開頭,這是默認模式,一般用于非文本文件如圖片等 |
| w | 打開一個文件只用于寫入,如果該文件已存在則打開文件,并從頭開始編輯,即原有內容會被刪除;如果該文件不存在,則創建新文件 |
| wb | 以二進制格式打開一個文件只用于寫入,如果該文件已存在則打開文件,并從開頭開始編輯,即原有內容會被刪除。如果該文件不存在,創建新文件。一般用于非文本文件如圖片等 |
| w+ | 打開一個文件用于讀寫,如果該文件已存在則打開文件,并從開頭開始編輯,即原有內容會被刪除。如果該文件不存在,創建新文件 |
| wb+ | 以二進制格式打開一個文件用于讀寫,如果該文件已存在則打開文件,并從開頭開始編輯,即原有內容會被刪除。如果該文件不存在,創建新文件。一般用于非文本文件如圖片等 |
| a | 打開一個文件用于追加。如果該文件已存在,文件指針將會放在文件的結尾。也就是說,新的內容將會被寫入到已有內容之后。如果該文件不存在,創建新文件進行寫入 |
| ab | 以二進制格式打開一個文件用于追加。如果該文件已存在,文件指針將會放在文件的結尾。也就是說,新的內容將會被寫入到已有內容之后。如果該文件不存在,創建新文件進行寫入 |
| a+ | 打開一個文件用于讀寫。如果該文件已存在,文件指針將會放在文件的結尾。文件打開時會是追加模式。如果該文件不存在,創建新文件用于讀寫 |
| ab+ | 以二進制格式打開一個文件用于追加。如果該文件已存在,文件指針將會放在文件的結尾。如果該文件不存在,創建新文件用于讀寫 |
(2)讀取文件
讀取文件的內容,使用 read 相關方法
使用 read 方法,讀取文件的全部內容(如果文件較大,一次性讀取可能會導致內存不足,此時需要進行行數指定)
使用 readline() 方法,讀取文件的一行
使用 readlines() 方法,一次讀取所有內容并按行返回 list
示例:
file = open("E:\\Desktop\\test.txt", "r", encoding="utf-8")
print(file.readline())
print(file.read())特別注意:
每次打開文件完成相應操作之后,都必須關閉該文件,且因為文件在讀寫過程中可能會出現 IOError 而導致文件不能正常關閉,所以每次讀寫文件時,必須使用 try finally 語法包裹,使其最終都能正常關閉文件
try:file = open("E:\\Desktop\\test.txt", "r", encoding="utf-8")print(file.readline())print(file.read())
finally:file.close()
如果覺得 try finally 語法有點繁瑣,也可以使用 Python 提供的另外一種方式:
with open("E:\\Desktop\\test.txt", "r", encoding="utf-8") as file:print(file.readline())print(file.read())
使用 with 這種方式,無須顯示去關閉文件,該語法在使用完文件后,會自動幫我們關閉文件
3、文件內容的寫入
寫入文件內容時,需要使用 open 打開文件,相應的 mode 指定為追加寫入,之后可以使用 write 函數進行文件的寫入
try:file = open("E:\\Desktop\\test.txt", "a", encoding="utf-8")file.write("hello world123")finally:file.close()4、操作文件夾
(1)創建文件夾
可以使用 os.mkdir(dir_name) 來在當前目錄下創建一個目錄
import osos.mkdir("test")(2)創建多層級文件夾
import osos.makedirs("test\\my")(3)獲取當前所在目錄
import osprint(os.getcwd())(4)改變當前的工作目錄
import osos.chdir("test")
print(os.getcwd())(5)刪除空文件夾
import osos.rmdir("test")(6)刪除多層空文件夾
import osos.removedirs("test\\my")5、操作文件夾示例
(1)文件夾下僅有文件的刪除
問題:如果一個文件夾下僅有文件,自定義一個函數,用于刪除整個文件夾
思路:獲取文件夾中所有的文件,遍歷刪除,之后刪除空的文件夾
import osdef my_rmdir(dir):files = os.listdir(dir)os.chdir(dir)# 刪除文件夾中所有的文件for file in files:os.remove(file)print("刪除成功!", file)# 刪除空的文件夾os.chdir("..")os.rmdir(dir)my_rmdir("E:\Desktop")def remove_dir(dir):dir = dir.replace('\\', '/')if (os.path.isdir(dir)):for p in os.listdir(dir):remove_dir(os.path.join(dir, p))if (os.path.exists(dir)):os.rmdir(dir)else:if (os.path.exists(dir)):os.remove(dir)
(2)文件夾下有子文件夾的刪除
問題:如果一個文件夾下有子文件夾,自定義一個函數,用于刪除整個文件夾
思路:獲取文件夾下所有文件及文件夾,文件刪除,文件夾遞歸處理
import osdef my_rmdir(dir):# 判斷是不是文件夾,如果是,遞歸調用my_rmdirif (os.path.isdir(dir)):for file in os.listdir(dir):my_rmdir(os.path.join(dir, file))# 如果是空的文件夾,直接刪除if (os.path.exists(dir)):os.rmdir(dir)print("刪除文件夾成功===>", dir)# 只是文件,直接刪除else:if (os.path.exists(dir)):os.remove(dir)print("刪除文件成功===>", dir)my_rmdir("E:\\Desktop")
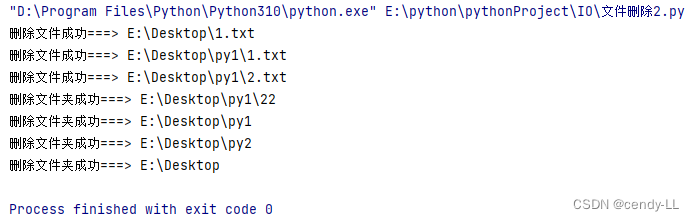
其實刪除文件夾,直接調用 python 提供的 api即可
import shutilshutil.rmtree("E:\\Desktop")6、StringIO和BytesIO
(1)理解
在前面,我們更多接觸到IO操作,都是在文件層面上進行操作,但是,在平時的開發中,某些場景下,我們只是要緩存相應的文本內容,方便后續處理,這時候我并不需要新建文件并寫入,我只想直接在內存中緩存這些文本,此時StringIo,BytesIo就派上用場了
StringIo,BytesIo均屬于io包下(3.7環境),類似于操作文件,臨時在內存中緩存文本,兩者api與直接進行文件io的操作相似,StringIO跟ByteIo的區別在于前者寫入字符串,后者寫入二進制
(2)用法
from io import StringIOstr_io = StringIO("hello world")
print(str_io.readline())
str_io.close()from io import StringIOstr_io = StringIO()
str_io.write("hello")
str_io.write(" world")
print(str_io.getvalue())
str_io.close()from io import StringIOwith StringIO() as str_io:str_io.write("hello")str_io.write(" world")print(str_io.getvalue())
十四、面向對象編程
1、面向對象及其三大特性
(1)面向對象理解
面向對象程序設計(Object Oriented Programming)作為一種新方法,其本質是以建立模型體現出來的抽象思維過程和面向對象的方法。模型是用來反映現實世界中事物特征的,任何一個模型都不可能反映客觀事物的一切具體特征,只能對事物特征和變化規律的一種抽象,且在它所涉及的范圍內更普遍、更集中、更深刻地描述客體的特征。通過建立模型而達到的抽象是人們對客體認識的深化。
(2)面向對象的三大特性
面向對象的三大特性分別為封裝、繼承和多態
- 封裝:把對象的屬性私有化,同時提供可以被外界訪問這些屬性的方法
- 繼承:使用已存在的類的定義,作為建立新類的基礎技術,新類可以增加新的屬性或新的方法,也可以用父類的功能,但不能選擇性的繼承;通過使用繼承,能夠非常方便的復用這些代碼
- 多態:python中的多態,本質也是通過繼承獲得多態的能力(不同的子類調用相同的父類方法,產生不同的執行結果,可以增加代碼的外部調用靈活度)
2、類和對象
(1)類和對象的理解
類和對象(class)是兩種以計算機為載體的計算機語言的合稱。對象是對客觀事物的抽象,類是對對象的抽象,類是一種抽象的數據類型
客觀事物:張三、李四、王五這幾個同事,都是客觀存在的,可抽象成對象,將這些對象進一步抽取共同特征:名字、性別、年齡,就形成了類
(2)類和對象的關系
類就像工廠里生產產品的模具,它負責對象的創建,決定了對象將被塑造成什么樣,有什么屬性、做出來之后能做什么
比如:有個女媧造人的模具(類),定義了名字、性別、身高(屬性),能自我介紹(方法)
(3)定義類以及實例化對象
# 定義person類
class Person():# 所有類方法,無論是否要用到,都必須有self參數def introduce_self(self):print("my name is cendy")# 實例化對象的時候 使用類名(),即可完成實例化
person = Person()
# 調用對象方法可以使用對象名.方法名()
person.introduce_self()
注意:定義類的時候,類名需使用駝峰的命名方式(即單詞首字母大寫,如果類名由多個單詞組成,同樣每個單詞的首字母都大寫)
雖然說都是通過同一個模板(類)刻出來來的(多個對象),但是,每個對象都是獨立的個體,都不一樣,如下:person跟person2看起來幾乎一樣,但是,通過id函數可以很明確的知道,兩者不同
# 定義Person類
class Person():# 所有類方法,無論是否要用到,都必須有self參數def introduce_self(self):print("my name is cendy")# 實例化多個對象
person = Person()
person2 = Person()
# 通過id函數證明實例化出來的兩個對象都是不同的
print("person對象的ID值為:", id(person))
print("person2對象的ID值為:", id(person2))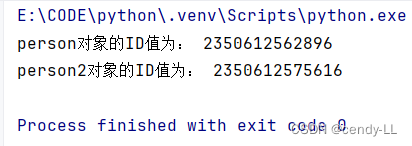
3、類的構造函數
(1)什么是構造函數
構造函數,是一種特殊的方法,主要用來在創建對象的時候去初始化對象,即為對象成員變量賦初始值
注意:python中不支持多個構造函數
在python中,使用__init__作為構造函數,如果不顯式寫構造函數,python會自動創建一個什么也不干的默認構造函數,如下:
# 定義person類
class Person():pass# 實例化對象的時候,使用類名(),即可完成實例化
person = Person()
person1 = Person()
person2 = Person()每次實例化對象的時候,均會幫我們自動執行構造函數里面的代碼,如下:
# 定義Person類
class Person():def __init__(self):print("hello world")# 實例化對象的時候 使用類名(),即可完成實例化
person = Person()
person1 = Person()
person2 = Person()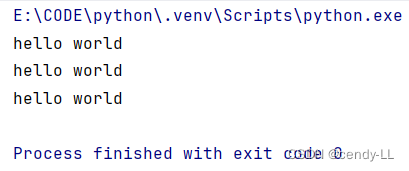
(2)構造函數的用途
# 定義person類
class Person():# 作為模板,在構造函數中,為必須的屬性綁定對應的值def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightdef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))# 實例化對象的時候 使用類名(),即可完成實例化
person = Person('cendy', 25, 175)
# 訪問對象屬性可以使用對象實例.屬性名的方式為屬性賦值# 調用對象方法可以使用對象名.方法名()
person.introduce_self()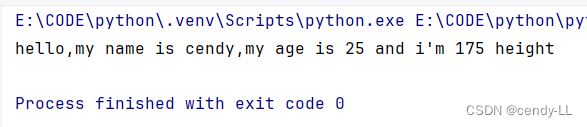
特別注意:當使用了構造函數,且構造函數式帶參的且無默認參數,此時,實例化對象的時候,必須顯式入參,否則會報錯。若要避免錯誤,可以在構造函數使用默認參數
# 定義person類
class Person():# 作為模板,在構造函數中,為必須的屬性綁定對應的值def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightdef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))# 實例化對象的時候 使用類名(),即可完成實例化
person = Person()
# 訪問對象屬性可以使用對象實例.屬性名的方式為屬性賦值# 調用對象方法可以使用對象名.方法名()
person.introduce_self()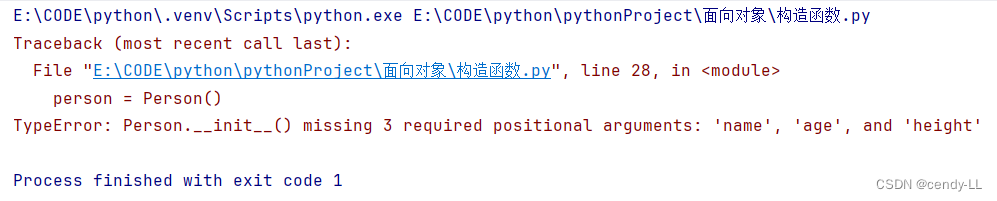
4、類變量與實例變量
(1)類變量
類變量定義在類中且在函數體之外,類變量通常不作為實例變量使用;類變量在整個實例化的對象中是公用的
(2)實例變量
實例變量是定義在方法中的變量,用 self 綁定到實例上,只作用于當前實例的類
(3)訪問實例變量和類變量
訪問實例變量可以使用【對象名.屬性】,訪問類變量可以使用【類名.屬性】
# 定義person類
class Person():total = 0def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightperson = Person('cendy', 25, 175)
# 訪問實例變量
print(person.name)
# 訪問類變量
print(Person.total)
(4)修改實例變量和類變量的值
如果要修改實例變量的值,可以使用【對象名.屬性=新值】的方式進行賦值;
如果要修改類變量的值,可以使用【類名.屬性=新值】的方式進行賦值,在實例方法里,可以使用 self.__class__
# 定義person類
class Person():total = 0def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightperson = Person('cendy', 25, 175)
# 修改實例變量的值
person.name = 'summer'
# 訪問實例變量
print(person.name)
# 修改類變量的值
Person.total = 1
# 訪問類變量
print(Person.total)
下面的代碼段顯示如下:該代碼不會報錯,實例變量的查找規則優先從實例對象中查找,若找不到會去類變量里查找
# 定義person類
class Person():total = 0def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightperson = Person('cendy', 25, 175)
print(person.total)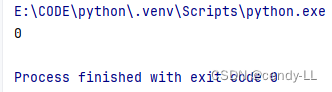
(5)實例變量查找規則
先從實例變量里面找,找不到的話再看看類變量,若沒有,就去父類找,如果還是找不到,就報錯
在對象里,有一個__dict__對象,存儲著對象相關的屬性
# 定義person類
class Person():name = 0def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightperson = Person('cendy', 25, 175)
print(person.name)
print(person.__dict__)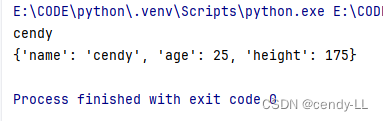
(6)類變量存儲
類也有對應的__dict__,存儲著與類相關的信息
# 定義person類
class Person():total = 0def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightperson = Person('cendy', 25, 175)
print(Person.__dict__)
案例:定義一個動物類,有name、age的屬性,動物有eat的行為,每次調用該行為,直接打印具體動物 is eating,如 老虎 is eating
class Animal():def __init__(self, name, age):self.name = nameself.age = agedef eat(self):print(self.name, "is eating")animal = Animal("dog", 5)
animal.eat()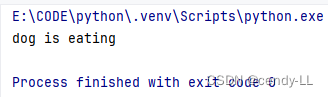
5、實例方法與self關鍵字
(1)實例方法
與實例變量類似,屬于實例化之后的對象,定義實例方法至少要有一個self入參,由實例對象調用
(2)self關鍵字作用
self指向實例本身,我們在實例方法中藥訪問實例變量,必須使用【self.變量名】的形式
(3)self名稱統一
self名稱不是必須的,在python中,self不是關鍵字,你可以定義成 a 或者 b 或者其他名字都可以,但是約定俗成,為了和其他編程語言統一,減少理解難度,最好還是不要另起名稱
# 定義person類
class Person():total = 0# 構造函數,用于為成員變量賦初始值def __init__(aa, name, age, height):aa.name = nameaa.age = ageaa.height = heightdef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))# 實例化對象的時候 使用類名(),即可完成實例化
person = Person('cendy', 25, 175)
person.introduce_self()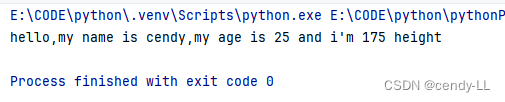
在實例方法中,如果不使用【self.屬性名】的方式去訪問對應的屬性,會發生報錯
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, nick, age, height):self.name = nickself.age = ageself.height = height# 不使用self.屬性名的方式去訪問對應的屬性print(name)def introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))# 實例化對象的時候 使用類名(),即可完成實例化
person = Person('cendy', 25, 175)
person.introduce_self()
如果不實例化對象,直接使用【類名.實例方法名】的方式調用方法,則會報錯
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, nick, age, height):self.name = nickself.age = ageself.height = heightdef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))Person.introduce_self()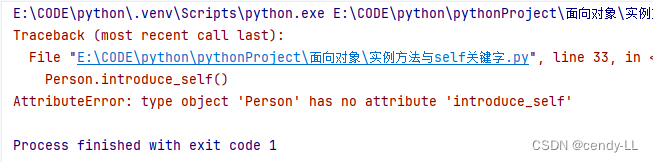
6、類方法與靜態方法
(1)類方法
類方法使用裝飾器@classmethod。第一個參數必須是當前類對象,該參數名一般約定為“cls”(不是cls也沒關系,但是,約定俗成的東西不建議變動),通過它來傳遞類的屬性和方法(不能傳實例的屬性和方法);其調用對象可以是實例對象和類
# 定義Person類
class Person():total = 1@classmethoddef print_total(cls):cls.total += 1print(cls.total)# 類調用
Person.print_total()
# 實例對象調用(不建議)
person = Person()
person.print_total()
(2)靜態方法
使用裝飾器@staticmethod。參數隨意,沒有“self”和“cls”參數,但是方法體中不能使用類或實例的任何屬性和方法
靜態方法是類中的函數,不需要實例,靜態方法主要是用來存放邏輯性的代碼,邏輯上屬于類,但是和類本身沒有關系,也就是說在靜態方法中,不會涉及到類中的屬性和方法的操作,可以理解為:靜態方法是個獨立的、單純的函數,它僅僅托管于某個類的名稱空間中,便于使用和維護
# 定義person類
class Person():@staticmethoddef print_hello():print("hello world")Person.print_hello()
小總結:
實例方法:與具體實例相關,用于操作實例變量
類方法:與類相關,用于操作類變量,雖然實例可以直接調用,但是不建議通過實例調用
靜態方法:與類和具體的實例無關,相當于一個獨立的函數,只是依托于類的命名空間內
7、Python中的訪問限制
如下我們定義了一個類,實例化了一個對象,給其年齡賦值-1,程序正確運行,但是,這不符合現實生活中的場景,當我們不加限制的將屬性暴露出去,也就是意味著我們的類失去了安全性
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.age = ageself.height = heightdef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name, self.age, self.height))person = Person("cendy", 25, 175)
person.age = -1
person.introduce_self()
當我們不希望外部可以隨意更改類內部的數據,可以將變量定義為私有變量,并提供相應的操作方法,為了保證外部不可以隨意更改實例內部的數據,可以在構造函數中,在屬性的名稱前加上兩個下劃線__,這樣該屬性就變成了一個私有變量,只有內部可以訪問,外部不能訪問
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.__age = ageself.height = heightdef set_age(self, age):if age < 0 or age > 150:raise Exception("非法入參,年齡不合法")self.__age = agedef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))person = Person("cendy", 25, 175)
print(person.age)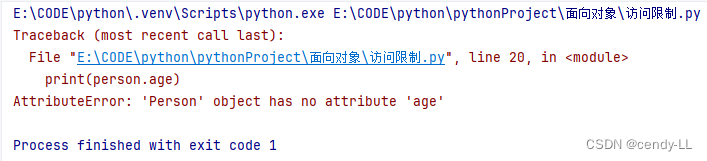
方法私有化,同樣也是在方法名前面加上__
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.__age = ageself.height = heightdef set_age(self, age):if age < 0 or age > 150:raise Exception("非法入參,年齡不合法")self.__age = agedef __introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))person = Person("cendy", 25, 175)
person.__introduce_self()
8、打破Python中的訪問限制
問題1:下面的程序依舊可以運行,可以打印實例的__dict__來看下:我們可以看到,在實例里面,自動幫我們整了一個__age的屬性
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.__age = ageself.height = heightdef set_age(self, age):if age < 0 or age > 150:raise Exception("非法入參,年齡不合法")self.__age = agedef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))person = Person("cendy", 25, 175)
person.__age = -1
print(person.__age)
print(person.__dict__)
問題2:在python中,僅屬性或方法前面加上__時,表示私有;如果后面再加上__,此時含義就發生改變,變成了普通的屬性或方法
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.__age__ = ageself.height = heightdef set_age(self, age):if age < 0 or age > 150:raise Exception("非法入參,年齡不合法")self.__age__ = agedef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" %(self.name, self.age, self.height))person = Person("cendy", 25, 175)
print(person.__age__)
問題3:通過問題1,我們看出對象的__dict__打印出來的結果,多了個_Person__age,其值剛好對應私有屬性的值,因此,可以如下訪問:
# 定義person類
class Person():# 構造函數,用于為成員變量賦初始值def __init__(self, name, age, height):self.name = nameself.__age = ageself.height = heightdef set_age(self, age):if age < 0 or age > 150:raise Exception("非法入參,年齡不合法")self.__age = agedef introduce_self(self):print("hello,my name is %s,my age is %d and i'm %d height" % (self.name,self.age, self.height))person = Person("cendy", 25, 175)
#打破訪問限制
print(person._Person__age)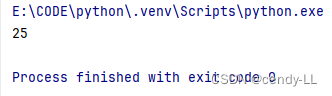
十五、面向對象高級特性
1、python中的繼承
(1)繼承的理解
繼承可以使得子類具有父類的屬性和方法或者重新定義、追加屬性和方法等
(2)python中如何繼承
# 子類直接繼承
# 定義animal類
class Animal():def __init__(self, name):self.name = namedef walk(self):print(self.name + " is walking")# Dog繼承animal
class Dog(Animal):pass# cat繼承animal
class Cat(Animal):pass# Dog和cat均因為繼承animal而獲得walk的能力和屬性
dog = Dog("Dog")
dog.walk()
print('當前的小動物是:', dog.name)
print('---------------------')
cat = Cat("Cat")
cat.walk()
print('當前的小動物是:', cat.name)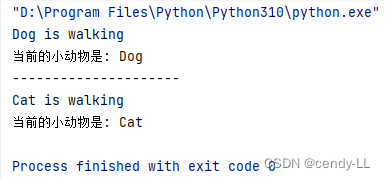
# 子類可以有自己的屬性與方法
# 定義animal類
class Animal():def __init__(self, name):self.name = namedef walk(self):print(self.name + " is walking")# Dog繼承animal
class Dog(Animal):# Dog有吠叫的功能def bark(self):print(self.name + " is bark")dog = Dog("Dog")
print(dog.name)
dog.walk()
dog.bark()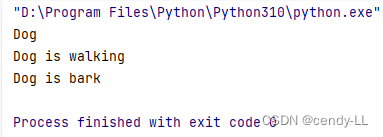
# 子類具備父類所有的屬性與功能,但是父類并不具備子類的屬性與功能
# 定義animal類
class Animal():def __init__(self, name):self.name = namedef walk(self):print(self.name + " is walking")# Dog繼承animal
class Dog(Animal):def bark(self):print(self.name + " is bark")animal = Animal("animal")
dog = Dog("Dog")
print(isinstance(dog, Animal))
print(isinstance(animal, Dog))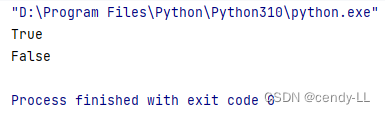
# 當子類有自己的構造方法時,將會覆蓋父類的構造方法
# 定義animal類
class Animal():def __init__(self):print("Animal")# Dog繼承animal
class Dog(Animal):def __init__(self):print("Dog")dog = Dog()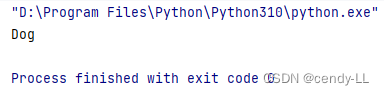
# 子類重寫父類方法
# 定義animal類
class Animal():def __init__(self):print("Animal")def eat(self, name):print("Animal is eating")# Dog繼承animal
class Dog(Animal):def __init__(self):print("Dog")def eat(self, name):print("Dog is eating \n" + "it's name is:" + name)dog = Dog()
dog.eat("aimy")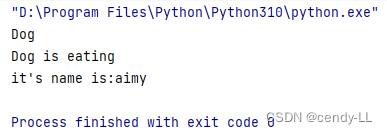
注意:當且僅當子類方法與父類同名,入參相同,才可稱之為重寫父類的方法
不要為了獲得某些屬性或功能而繼承,比如:因為在Dog類中寫了一個 eat 方法,覺得 Person 也該有這樣的方法,就直接繼承 Dog,這種不可取
問題:如下所示,程序會報錯
原因:之所以會報錯,是因為子類自己寫了init方法,程序運行的時候就不會去調用父類的構造方法,所以,實例中就不存在name這樣一個屬性
# 定義animal類
class Animal():def __init__(self,name):self.name = name# Dog繼承animal
class Dog(Animal):def __init__(self):print("Dog")dog = Dog()
print(dog.name)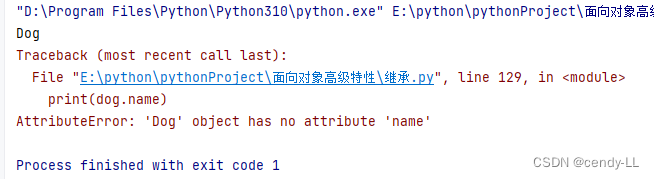
2、super的作用及其用法
(1)super函數理解
super() 函數是用于調用父類(超類)的一個方法,一般是用來解決多重繼承問題的,直接用類名調用父類方法在使用單繼承的時候沒問題,但是如果使用多繼承,會涉及到查找順序(MRO)、重復調用(鉆石繼承)等種種問題
(2)super函數的基本語法
在python3中,可以直接使用super() 而無需任何參數來調用父類
super(類名, self)(3)super函數應用
第一節出現一個問題,子類自己寫了init方法,因此無法調用父類init方法中的name屬性,如果想要調用父類的該屬性,有兩種方法:
方法1:直接通過父類名.__init__來調用,雖然可以達到目的,但是不建議直接通過類名去調用
# 定義animal類
class Animal():def __init__(self, name):self.name = name# Dog繼承animal
class Dog(Animal):def __init__(self, name):Animal.__init__(self, name)print("Dog")dog = Dog("tomcat")
print(dog.__dict__)
print(dog.name)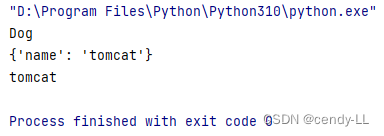
方法2:通過super去進行調用
# 定義animal類
class Animal():def __init__(self, name):self.name = name# Dog繼承animal
class Dog(Animal):def __init__(self, name):super(Dog, self).__init__(name)print("Dog")dog = Dog("tomcat")
print(dog.__dict__)
print(dog.name)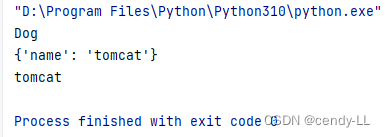
3、抽象方法與多態
(1)抽象方法理解
在面向對象編程語言中抽象方法指一些只有方法聲明,而沒有具體方法體的方法;抽象方法一般存在于抽象類或接口中,抽象類的一個特點是它不能直接被實例化,子類要么是抽象類,要么必須實現父類抽象類里定義的抽象方法
在python3中可以通過使用abc模塊輕松的定義抽象類
(2)定義抽象類
from abc import ABCMeta, abstractmethod# 定義抽象類時,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):@abstractmethoddef eat(self):passclass Dog(Animal):def eat(self):print("dog is eating")dog = Dog()
dog.eat()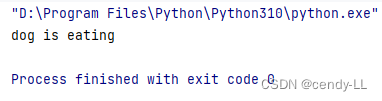
抽象類的子類必須實現抽象類中所定義的所有方法,否則,程序不能正確運行
from abc import ABCMeta, abstractmethod# 定義抽象類時,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):@abstractmethoddef eat(self):passclass Dog(Animal):passdog = Dog()
即使是實現部分抽象方法也是不行的
class Animal(metaclass=ABCMeta):@abstractmethoddef eat(self):pass@abstractmethoddef run(seft):passclass Dog(Animal):def eat(self):print("Dog is eating")dog = Dog()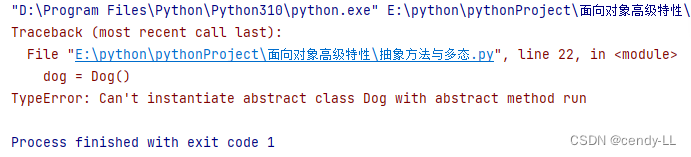
(3)多態理解
不同的子類對象調用相同的父類方法,產生不同的執行結果,可以增加代碼的外部調用靈活度
# 定義animal類
from abc import ABCMeta, abstractmethod# 定義抽象類時,使用metaclass=ABCMeta
class Animal(metaclass=ABCMeta):@abstractmethoddef eat(self):pass@abstractmethoddef run(seft):passdef activity(self):self.eat()self.run()class Dog(Animal):def eat(self):print("Dog is eating")def run(self):print("dog is running")class Cat(Animal):def eat(self):print("cat is eating")def run(self):print("cat is running")# 不同的子類對象,調用父類的activity方法,產生不同的執行結果
dog = Dog()
cat = Cat()
dog.activity()
cat.activity()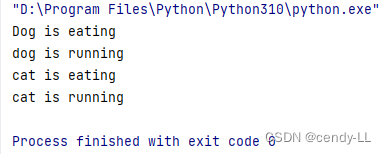
(4)多態的好處
- 增加了程序的靈活性
- 增加了程序的可擴展性
4、python中的多重繼承
python里面支持多重繼承,也就是一個子類能有多個父類
class Father:def power(self):print("擁有很大的力氣")class Mother:def sing(self):print("唱歌")class Me(Father, Mother):passme = Me()
me.power()
me.sing()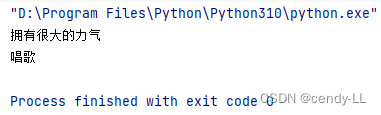
當繼承多個父類時,如果父類中有相同的方法,那么子類會優先使用最先被繼承的方法
class Father:def power(self):print("擁有很大的力氣")def sing(self):print("唱草原歌")class Mother:def sing(self):print("唱情歌")# 改變繼承的順序
class Me(Mother, Father):passme = Me()
me.power()
me.sing()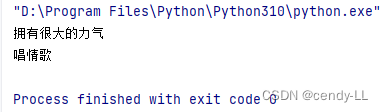
5、多重繼承所帶來的的問題
(1)新式類和舊式類
新式類都從object繼承(python3中,默認都繼承自object),經典類不需要
新式類的MRO(method resolution order 基類搜索順序)算法采用C3算法廣度優先搜索,而舊式類的MRO算法是采用深度優先搜索
新式類相同父類只執行一次構造函數,經典類重復執行多次
class Father:def my_fun(self):print("Father")class Son1(Father):def my_fun(self):print("Son1")class Son2(Father):def my_fun(self):print("Son2")class Grandson(Son1, Son2):def my_fun(self):print("Grandson")d = Grandson()
d.my_fun()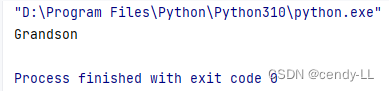
(2)菱形繼承(鉆石繼承)
之前學習繼承的時候說過,要執行父類構造方法有兩種方式,一種是直接使用父類名字調用構造,一種是使用super(),普通的繼承中,這兩種方法沒啥大問題,但是,如果在多重繼承里,使用父類名字調用構造可能會發生問題
class Father:def __init__(self):print("this is Father")def my_fun(self):print("Father")class Son1(Father):def __init__(self):Father.__init__(self)def my_fun(self):print("Son1")class Son2(Father):def __init__(self):Father.__init__(self)def my_fun(self):print("Son2")class Grandson(Son1, Son2):def __init__(self):Son1.__init__(self)Son2.__init__(self)def my_fun(self):print("Grandson")d = Grandson()
d.my_fun()
(3)解決菱形繼承問題
要解決菱形繼承多次調用構造的問題,可以使用super()
class Father:def __init__(self):print("this is Father")def my_fun(self):print("Father")class Son1(Father):def __init__(self):print("Son1 init")super().__init__()def my_fun(self):print("Son1")class Son2(Father):def __init__(self):print("son2 init")super().__init__()def my_fun(self):print("Son2")class Grandson(Son1, Son2):def __init__(self):super().__init__()def my_fun(self):print("Grandson")d = Grandson()
d.my_fun()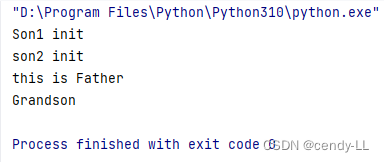
6、枚舉類
(1)枚舉理解
在數學和計算機科學理論中,一個集的枚舉是列出某些有窮序列集的所有成員的程序,或者是一種特定類型對象的計數。這兩種類型經常(但不總是)重疊
(2)枚舉實例
假設現在開發一個程序,大概內容是記錄車子在通過路口時紅綠燈的顏色,并判斷司機是否違規,程序普通的寫法如下:
# 1 紅色 2:黃 3:綠
def judge(color):if color == 1 or color == 2:print("司機闖紅燈")else:print("司機正常行駛")judge(1)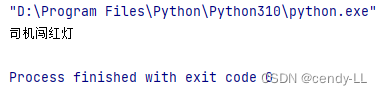
上面的程序存在一個很明顯的問題,程序是自己寫的,自己能理解。但是,如果別人來看我的程序,會無法理解1跟2這兩個數字的意義,這里有注釋還好,但是還有一個問題,可能另外的同事1是表示綠燈,這個時候雙方理解就會產生很大的問題。
這個時候,我希望在系統里統一一下這些定義,枚舉類的的作用就提現出來了,在枚舉類里將有限個可能取值都列出來,大家統一用枚舉類里的定義,如下:
from enum import Enumclass TrafficLight(Enum):RED = 1YELLOW = 2GREEN = 3def judge(color):if color == TrafficLight.RED or color == TrafficLight.YELLOW:print("司機闖紅燈")else:print("司機正常行駛")judge(TrafficLight.GREEN)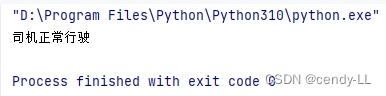
在枚舉類中, RED = 1 這樣的是枚舉成員, RED 是名字, 1 是值
(3)枚舉訪問
#?通過名字獲取枚舉成員
from enum import Enumclass TrafficLight(Enum):RED = 1YELLOW = 2GREEN = 3print(TrafficLight.RED)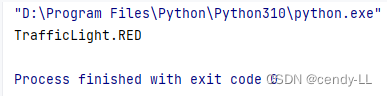
#?通過枚舉成員獲取名字以及值
from enum import Enumclass TrafficLight(Enum):RED = 1YELLOW = 2GREEN = 3# 通過枚舉成員獲取名字
print(TrafficLight.RED.name)
# 通過枚舉成員獲取值
print(TrafficLight.RED.value)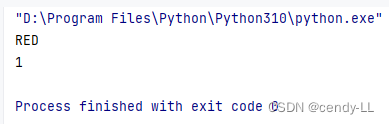
#?通過值獲取枚舉成員
from enum import Enumclass TrafficLight(Enum):RED = 1YELLOW = 2GREEN = 3# 通過枚舉成員獲取名字
print(TrafficLight(1))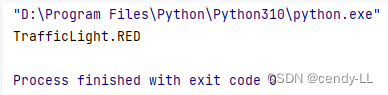
(4)枚舉類的特性
#?定義枚舉時,其枚舉成員的名稱不允許相同
from enum import Enum, uniqueclass TrafficLight(Enum):RED = 0RED = 1YELLOW = 2GREEN = 3# 1 紅色 2:黃 3:綠
def judge(color):if color == TrafficLight.YELLOW or color == TrafficLight.RED:print("司機闖紅燈")else:print("司機正常行駛")judge(TrafficLight.YELLOW)
默認情況下,不同的成員值允許相同。但是兩個相同值的成員,其第二個成員名稱是第一個成員名稱的別名;因此在訪問枚舉成員時,只能獲取第一個成員
from enum import Enum, uniqueclass TrafficLight(Enum):RED = 1BLACK = 1YELLOW = 2GREEN = 3print(TrafficLight(1))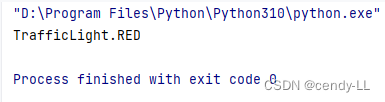
如果要限定枚舉里面所有的值必須唯一,可以在定義枚舉類時,加上@unique
from enum import Enum, unique@unique
class TrafficLight(Enum):RED = 1BLACK = 1YELLOW = 2GREEN = 3print(TrafficLight(1))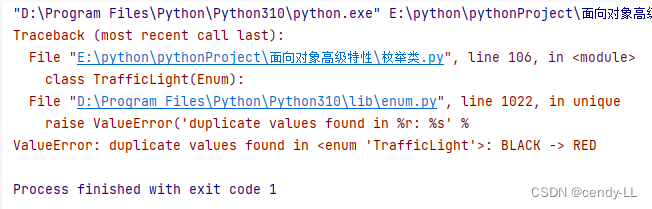
(5)枚舉成員的比較
from enum import Enumclass TrafficLight(Enum):RED = 1YELLOW = 2GREEN = 3# 通過名字獲取枚舉成員
print(TrafficLight.RED == 1)
# 通過枚舉成員獲取值
print(TrafficLight.RED.value == 1)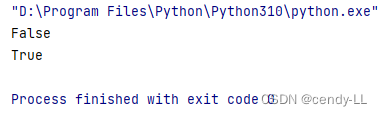











)







