文章目錄
- 1.云計算基礎知識
- 1.1 基本概念
- 1.2 云計算分類
- 2.大數據處理基礎知識
- 2.1 基礎知識
- 2.3 大數據處理技術
1.云計算基礎知識
1.1 基本概念
云計算是一種提供資源的網絡,使用者可以隨時獲取“云”上的資源,按需求量使用,并且可以看成是無限擴展的,只要按使用量付費就可以。
云計算是與信息技術、軟件、互聯網相關的一種服務,把許多計算資源集合起來,通過軟件實現自動化管理,只需要很少的人參與,就能讓資源被快速提供。
云計算是以一種方便的使用方式和服務模式,通過互聯網按需訪問資源池模型(例如網絡、服務器、存儲、應用程序和服務),以快速和最少的管理工作為用戶提供服務。采用“量入為出”的計費方式,即根據用戶使用云服務情況收費。
整體而言,云計算時一種將可伸縮、彈性、共享的物理和虛擬資源池以按需自服務的方式供應和管理,并提供網絡訪問的模式。
按照ISO/EG17788標準,云計算的關鍵特征有:廣泛的網絡接入、可測量的服務、多租戶、按需自服務、快速的彈性和可擴展性、資源池化。
- 廣泛的網絡接入。用戶可以通過網絡,采用標準機制訪問云中的物理和虛擬資源的特性。標準機制有助于用戶通過異構平臺使用資源。用戶可以在任何有網絡的地方,利用各種不同類型的客戶端,如手機、電腦、工作站等設備,方便地訪問云中的資源。
- 可測量的服務。通過可計量的服務交付使得服務使用情況可監控、控制和計費的特性。這個特性強調用戶只為自己使用的服務付費,降低用戶成本,為用戶帶來價值。
- 多租戶。通過對物理或虛擬資源的分配保證多個租戶以及他們的計算和數據彼此隔離和不可訪問的特性。
- 按需自服務。客戶能夠根據自身的實際需求,自動或在最少交互的情況下,配置計算能力的特性。該特性降低了用戶的時間成本和操作成本,實現了企業業務的快速實現、部署與應用,降低了企業信息系統的運維成本,提高了企業快速響應市場的能力。
- 快速的彈性和可擴展性。物理或虛擬資源能夠快速、彈性,有時是自動化地供應,以達到快速增減資源目的的特性。
- 資源池化。將云服務提供者的物理或虛擬資源進行集成,以便服務于一個或多個云服務客戶的特性。 該特性通過抽象對用戶屏蔽了資源處理和分配的復雜性,用戶無需知道資源是如何分布,如何分配的。
其他關鍵特征:虛擬化技術(應用虛擬和資源虛擬)、可靠性高、性價比高。
1.2 云計算分類
1)根據云部署模式和云應用范圍分類
云計算常見的部署模式有公有云、社區云、私有云和混合云。
- 公有云。云的基礎設施一般是被一個云計算服務提供商所擁有,該組織將云計算服務銷售給公眾,公有云通常在遠離客戶建筑物的地方托管(一般為云計算服務提供商建立的數據中心),可實現靈活的擴展,提供一種降低客戶風險和成本的方法。
- 社區云。云的基礎設施被一些組織共享,并為一個有共同關注點的社區服務(例如任務、安全要求、政策和遵守的考慮)。可以是該組織或某個第三方負責管理。
- 私有云。云的基礎設施是為一個客戶單獨使用而構建的,因而提供對數據、安全性和服務質量的最有效控制。私有云可部署在企業數據中心中,也可部署在一個主機托管場所,被一個單一的組織擁有或租用。
- 混合云。基礎設施是由兩種或兩種以上的云(私有、社區或公有)組成,每種云仍然保持獨立,但用標準的或專有的技術將它們組合起來,具有數據和應用程序的可移植性(例如,可以用來處理突發負載),混合云有助于提供按需和外部供應方面的擴展。
2)根據云計算的服務層次和服務類型分類
根據云計算的服務類型可將云分為三層:基礎設施即服務、平臺即服務和軟件即服務。
- 基礎設施即服務(Infrastructure as a Service, Iaas),提供虛擬化計算資源,如虛擬機、存儲、網絡和操作系統。
- 平臺即服務(Platform as a Service, PaaS),為開發人員提供通過全球互聯網構建應用程序和服務的平臺。Paas為開發、測試和管理軟件應用程序提供按需開發環境。其核心技術是分布式并行計算。
- 軟件即服務(Software as a Service, SaaS),通過互聯網提供按需軟件付費應用程序,云計算提供商托管和管理軟件應用程序,并允許其用戶連接到應用程序并通過互聯網訪問應用程序。
3)云關鍵技術
云核心的關鍵技術有虛擬化技術、分布式數據存儲、并行計算、運營支撐管理等。
- 虛擬化或虛擬技術(Virtualization)是一種資源管理技術,是將計算機的各種實體資源(CPU、內存、磁盤空間、網絡適配器等)予以抽象、轉換后呈現出來,并可供分割、組合為一個或多個電腦配置環境。云計算中的虛擬化往往指的是系統虛擬化。
- 分布式數據存儲技術包含非結構化數據存儲和結構化數據存儲。其中,非結構化數據存儲主要采用文件存儲和對象存儲技術,而結構化數據存儲主要采用分布式數據庫技術,特別是NOSQL數據庫。
- 并行計算,海量數據分布到多個結點上,將計算并行化,利用多機的計算資源,加快數據處理的速度。關鍵問題有
任務劃分、任務調度和自動容錯處理機制。 - 運營支撐管理,支持規模巨大的云計算環境,需要成千上萬臺服務器來支撐,那就需要運營支撐管理。注意因素有負載管理和監控、計量計費。
2.大數據處理基礎知識
2.1 基礎知識
大數據定義:大數據是具有數量巨大、來源多樣、生成極快且多變等特征且難以使用傳統數據體系結構有效處理的包含大量數據集的數據。
大數據的5V特征:
- Variet,多樣性。數據類型繁多,除了結構化數據外,還包括種類繁多的非結構化數據,例如文本、音頻、視頻、文件記錄等,也包括半結構化數據,例如 Email、word、ppt 文檔等。
- Velocity,速度。一方面是數據的增長速度快,另一方面是要求數據訪問、處理、交付的速度快,通常要求具有時效性。
- Volume,數量。聚合在一起供分析的數據規模非常龐大。各種業務系統產生的數據量急劇增長。
- Value,價值。從海量低價值密度的數據中挖掘出具有高價值的數據。本質是獲取數據價值,關鍵在于商業價值,即如何有效利用好數據。
- Veracity,真實性。一方面,對于虛擬網絡環境下如此大量的數據需要采取措施確保其真實性、客觀性,這是大數據技術與業務發展的迫切需求;另一方面,通過大數據分析,真實地還原和預測事物的本來面目也是大數據未來發展的趨勢。
2.3 大數據處理技術
大數據處理的基本流程包括:數據采集、數據分析和數據解釋。
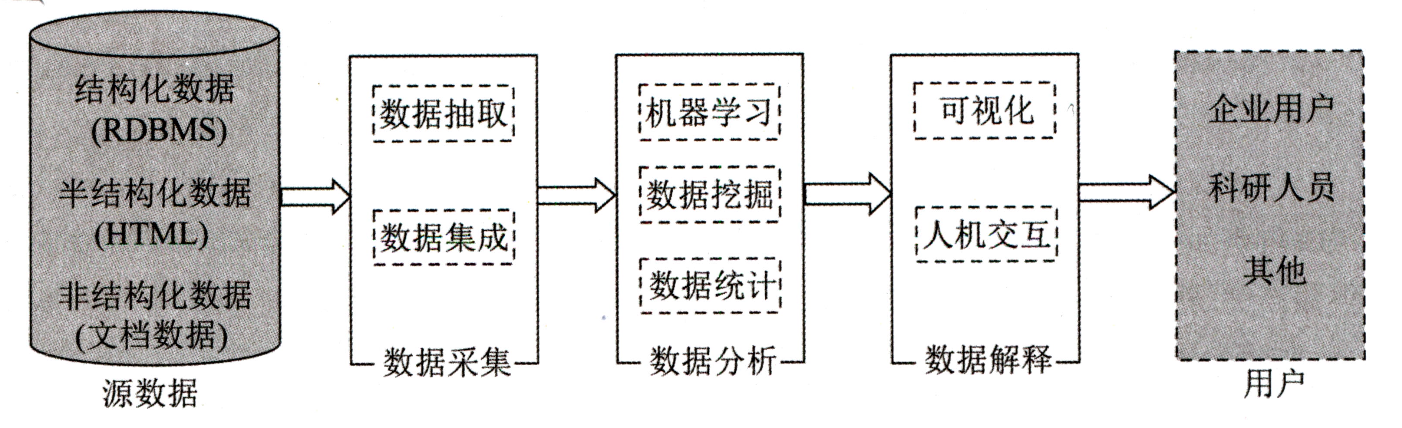
1)數據采集
數據采集階段的主要任務就是獲取各個不同數據源的各類數據,按照統一的標準進行數據的轉換、清洗等工作,以形成后續數據處理的符合標準要求的數據集。
ETL(Extract Transform Load)用來描述將數據從來源端經過抽取 (extract)、轉換 (transform)、加載(load)至目的端的過程。目的是將企業中的分散、零亂、標準不統一的數據整合到一起,為企業的決策提供分析依據。
常用的ETL工具有三種:DataStage、Informatica PowerCenter和Kettle。
- DataStage: IBM公司的DataStage是一種數據集成軟件平臺,專門針對多種數據源的ETL過程進行了簡化和自動化,同時提供圖形框架,用戶可以使用該框架來設計和運行用于變換和清理、加載數據的作業。它能夠處理的數據源有主機系統的大型數據庫、開發系統上的關系數據庫和普通的文件系統。
- Informatica PowerCenter: Informatica公司開發的為滿足企業級需求而設計的企業數據集成平臺。可以支持各類數據源,包括結構化、半結構化和非結構化數據。提供豐富的數據轉換組件和工作流支持。
- Kettle: Kettle是一款國外開源的ETL工具,純Java編寫,可以在 Windows、Linux、UNIX 上運行,數據抽取高效穩定。管理來自不同數據庫的數據,提供圖形化的操作界面,提供工作流支持。
爬蟲技術也稱為數據采集階段的一個主要基礎性的技術。網絡爬蟲(又稱為網頁蜘蛛,網絡機器人),是一種按照一定的規則,自動地抓取互聯網信息的程序或者腳本。

爬蟲調度器主要負責統籌其他四個模塊的協調工作。URL管理器負責管理URL鏈接,維護已經爬取的URL集合和未爬取的URL集合,提供獲取新URL鏈接的接口。HTML下載器用于從URL管理器中獲取未爬取的URL鏈接并下載HTML網頁。HTML解析器用于從HTML下載器中獲取已經下載的HTML網頁,并從中解析出新的URL鏈接交給URL管理器,解析出有效數據交給數據存儲器。
網絡爬蟲大致可以分為通用網絡爬蟲、聚焦網絡爬蟲、深層網絡(Deep Web)爬蟲:
- 通用網絡爬蟲,爬行對象從一些種子URL擴充到整個Web,主要為門戶站點搜索引擎和大型Web服務提供商采集數據。
- 聚焦網絡爬蟲,是指選擇性地爬行那些與預先定義好的主題相關頁面的網絡爬蟲。
- 深層網絡爬蟲用于專門爬取那些大部分內容不能通過靜態鏈接獲取的、隱藏在搜索表單后的,只有用戶提交一些關鍵詞才能獲得的Web頁面。
常見的爬蟲工具:
- Nutch:一個開源Java實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬蟲。Nutch有Hadoop支持,可以進行分布式抓取、存儲和索引。Nutch采用插件結構設計,高度模塊化,容易擴展。
- Scrapy:是Python開發的一個快速、高層次的屏幕抓取和Web抓取框架,用于抓取Web站點并從頁面中提取結構化的數據。
- Larbin:Larbin是一種開源的網絡爬蟲/網絡蛛,用C++語言實現。Larbin目的是能夠跟蹤頁面的URL進行擴展的抓取,最后為搜索引擎提供廣泛的數據來源。
2)數據分析
機器學習一般分為監督學習和非監督學習(或無監督學習)。
監督學習是指利用一組已知類別的樣本調整分類器的參數,使其達到所要求性能的過程,也稱為監督訓練,是從標記的訓練數據來推斷一個功能的機器學習任務。根據訓練集中的標識是連續的還是離散的,可以將監督學習分為回歸和分類。
- 回歸是研究一個或一組隨機變量對一個或一組屬性變量的相依關系的統計分析方法。線性回歸模型是假設自變量和因變量滿足線性關系。Logistic 回歸一般用于分類問題,而其本質是線性回歸模型,只是在回歸的連續值結果上加了一層函數映射。
- 分類是機器學習中的一個重要問題,其過程也是從訓練集中建立因變量和自變量的映射過程,與回歸問題不同的是,分類問題中因變量的取值是離散的,根據因變量的取值范圍,可將分類問題分為二分類問題、三分類問題和多分類問題。根據分類采用的策略和思路的不同,分類算法大致包括:
- 基于示例的分類方法,如K最近鄰(K-Nearest Neighbor,KNN)方法;
- 基于概率模型的分類方法,如樸素貝葉斯、最大期望算法EM等;
- 基于線性模型的分類方法,如SVM;基于決策模型的分類方法,如C4.5、AdaBoost、隨機森林等。
無監督學習是根據類別未知(沒有被標記)的訓練樣本解決模式識別中的各種問題。常見的算法有:關聯規則挖掘,是從數據背后發現事物之間可能存在的關聯或聯系。比如數據挖掘領域著名的“啤酒-尿不濕”的故事。K-means算法,基本思想是兩個對象的距離越近,其相似度越大;相似度接近的若干對象組成一個簇;算法的目標是從給定數據集中找到緊湊且獨立的簇。
深度學習算法是基于神經網絡發展起來的,包括BP神經網絡、深度神經網絡。
- BP神經網絡是一種反向傳播的前饋神經網絡,所謂前饋神經網絡就是指各神經元分層排列,每個神經元只與前一層的神經元相連,接收前一層的輸出,并輸出給下一層。所謂反向傳 播是指從輸出層開始沿著相反的方向來逐層調整參數的過程。BP神經網絡由輸入層、隱含層和輸出層組成。
- 深度神經網絡主要包括卷積神經網絡(Convolutional Neural Network,CNN)、循環神經網絡(Recurrent Neural Network,RNN)等。
3)數據解釋
數據解釋的主要工作是對大數據處理后產生的輸出數據進行處理,采用合理合適的人機交互方式將結果展現給用戶,幫助用戶做出相應的決策。
信息可視化是指對抽象數據使用計算機支持的、交互的、可視化的表示形式以增強認知能力。為了清晰有效地傳遞信息,數據可視化使用統計圖形、圖表、信息圖表和其他工具。可以使用點、線或條對數字數據進行編碼,以便在視覺上傳達定量信息。有效的可視化可以幫助用戶分析和推理數據和證據。它使復雜的數據更容易理解和使用。用戶可能有特定的分析任務 (如進行比較或理解因果關系),以及該任務要遵循的圖形設計原則。
常見的大數據可視化工具主要分為三類:底層程序框架,如OpenGL、Java2D等;第三方庫,如D3、ECharts、HighCharts、Google ChartAPI等;軟件工具,如Tableau、Gephi等。
)
)













)

選擇IDE和配置環境)

