
提示:
文章目錄
- 前言
- 一、InFusion:擴散模型助力,效率提高20倍!(2024)
- 1. 摘要
- 2. 算法
- 3. 效果
- 二、2D Gaussian Splatting
- 三、Bootstrap 3D:從擴散模型引導三維重建
- 1.摘要
- 2.相關工作
- 3.方法
- 1.Boostrapping by Diffusion 通過擴散模型促進
- 2.梯度方向和 Diffusion
- 4.實驗
- 補充材料
- 四、GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
- 五、Gaussian Grouping:分割和編輯任何高斯
- 1.摘要
- 2.任何掩碼輸入和一致性
- 3.三維高斯渲染和分組
- 4.局部高斯編輯
- 5.實驗
- 六、InstantSplat:無界稀疏視圖的40秒無位姿高斯潑濺
- 總結
前言
??
??
??
提示:以下是本篇文章正文內容,下面案例可供參考
一、InFusion:擴散模型助力,效率提高20倍!(2024)

項目主頁: https://johanan528.github.io/Infusion/
代碼倉庫: https://github.com/ali-vilab/infusion
機構單位: 中科大,港科大,螞蟻,阿里巴巴
1. 摘要
??本工作研究了3D GS編輯能力,特別著重于補全任務, 旨在為不完整的3D場景補充高斯,以實現視覺上更好的渲染效果。與2D圖像補全任務相比,補全3D高斯模型的關鍵是要確定新增點的相關高斯屬性,這些屬性的優化很大程度上受益于它們初始的3D位置。為此,我們提出 使用一個圖像指導的深度補全模型來指導點的初始化 ,該模型基于2D圖像直接恢復深度圖。這樣的設計使我們的模型能夠以與原始深度對齊的比例填充深度值,并且利用大規模擴散模型的強大先驗。得益于更精確的深度補全,我們的方法,稱為InFusion,在各種復雜場景下以足夠更好的視覺保真度和效率(約快20倍)超越現有的替代方案。并且 具有符合用戶指定紋理 或 插入新穎物體 的補全能力。

(a)InFusion 無縫刪除 3D 對象,以用戶友好的方式進行紋理編輯和對象插入。
(b)InFusion 通過 擴散先驗學習深度補全,顯著提高深度修復質量。
??現有方法對3D高斯的補全,通常使用對不同角度的渲染圖象進行圖像層次的補全,作為3D GS新的訓練數據。但是,這種方法往往會因生成過程中的不一致而產生模糊的紋理,且速度緩慢。
??值得注意的是,當初始點在3D場景中精確定位時,高斯模型的訓練質量會顯著提高。因此一個實際的解決方案是將需要補全位置的高斯設置到正確的初始點,從而簡化整個訓練過程。因此,在為需補全高斯分配初始高斯點時,進行深度補全是關鍵的,將修復后的深度圖投影回3D場景能夠實現向3D空間的無縫過渡。本文利用預訓練的擴散模型先驗,訓練了一個深度補全模型。該模型在與未修復區域的對齊以及重構物體深度方面展現了顯著的優越性。這種增強的對齊能力確保了補全高斯和原3D場景的無縫合成。此外,為了應對涉及大面積遮擋的挑戰性場景, InFusion可以通過漸進的補全方式,體現了它解決此類復雜案例的能力。
??
2. 算法

??整體流程如下:
??1)場景編輯初始化:首先,根據編輯需求和提供的mask,構造殘缺的高斯場景。
??2)深度補全:選擇一個視角,渲染得到的利用圖像修復模型如(Stable Diffusion XL Inpainting )進行,修復單張RGB圖像。再利用深度補全模型(基于觀測圖像)預測出缺失區域的深度信息,生成補全的深度圖。具體來說,深度補全模型接受三個輸入:從3D高斯渲染得到的深度圖、相應的修復后彩色圖像和一個掩碼,其中掩碼定義了需要補全的區域。先使用變分自編碼器(VAE)將深度圖和彩色圖像編碼到潛在空間中。其中通過將深度圖重復使其適合VAE的輸入要求,并應用線性歸一化,使得深度值主要位于[-1, 1]區間內。后將編碼后的深度圖加噪得到的近高斯噪聲,將掩碼區域設置為0的編碼后的深度圖,編碼后的RGB指導圖像,以及掩碼圖像,在channel維度進行連接,輸入到U-Net網絡進行去噪,逐步從噪聲中恢復出干凈的深度潛在表示。再次通過VAE解碼得到補全后的深度圖。
??3)3D點云構建:使用補全的深度圖和對應的彩色圖,通過3D空間中的反投影操作,將2D圖像點轉換為3D點云,這些點云隨后與原始的3D高斯體集合合并。
??4)Gaussian模型優化:合并后的3D點云通過進一步迭代優化和調整,以確保新補全的高斯體與原始場景在視覺上的一致性和平滑過渡。
??
??
3. 效果
??1.Infusion表現出保持 3D 連貫性的清晰紋理,而基線方法通常會產生模糊的紋理,尤其是復雜場景下

??2.同時通過與廣泛使用的其他基線方法的比較,以及相應的點云可視化。比較清楚地表明,我們的方法成功地能夠補出與現有幾何形狀對齊的正確形狀。
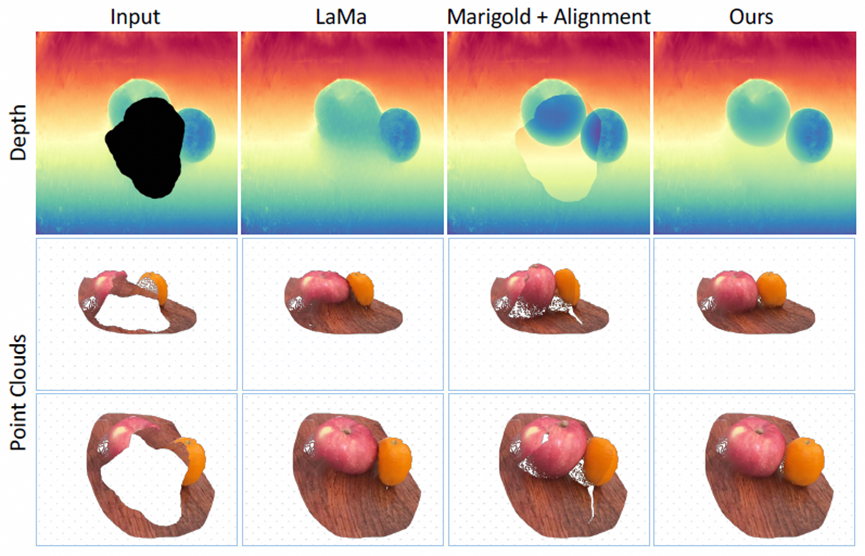
??3.Infusion可以通過迭代的方式,對復雜的殘缺gaussian進行補全。

??5.得益于Infusion補全3d高斯點的空間準確性,用戶可以修改補全區域的外觀和紋理。

??6.通過編輯單個圖像,用戶可以將物體投影到真實的三維場景中。此過程將虛擬對象無縫集成到物理環境中,為場景定制提供直觀的工具

二、2D Gaussian Splatting
標題:2D Gaussian Splatting for Geometrically Accurate Radiance Fields
代碼:https://github.com/hbb1/2d-gaussian-splatting
論文:https://arxiv.org/abs/2403.17888
三、Bootstrap 3D:從擴散模型引導三維重建

標題:Bootstrap 3D Reconstructed Scenes from 3D Gaussian Splatting
來源:電子科技大學;深圳先進技術研究院;中科院
1.摘要
??3D高斯噴濺(3D-GS),已經為神經渲染技術的質量和速度設置了新的基準。然而,3D-GS的局限在合成新視角,特別是偏離訓練中的視角。此外,當放大或縮小時,也會出現膨脹和混疊( dilation/aliasing)等問題。 這些挑戰都可以追溯到一個潛在的問題:抽樣不足。本論文提出了一個自舉方法:采用一個擴散模型,利用訓練后的3D-GS增強新視圖的渲染,從而簡化訓練過程。該方法是通用的,并且可以很容易地集成。

2.相關工作
??擴散模型。其預測過程可公式化如下:

??此過程中,時間步0的原始分布從時間步t的分布中逐漸恢復,通過優化負對數似然的通常變分界進行訓練。若所有的條件都被建模為具有可訓練均值函數和固定方差的高斯模型,訓練目標為:
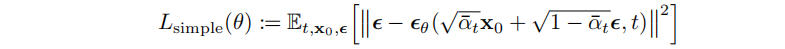
??圖像到圖像的生成。這是擴散模型的一個實際應用。本文專門討論了一種獨特的生成形式,其中輸入圖像由擴散模型再生, 利用一個定義的破損強度 s r s_r sr? 來促進可控的生成。 s r s_r sr? 的大小直接影響輸出圖像與原始圖像的偏差程度,值越大,變化就越大 。給定一個輸入圖像 I I I,在編碼到潛在空間 x I x^I xI時,我們認為xI 是基于 s r s_r sr? 的 T個時間步之一。 例如 s r s_r sr? = 0.1和T = 1000,反向擴散過程中,在擴散的時間步長 T T T × s r s_r sr? = 100處 直接應用 p θ ( x I ) p_θ(x^I) pθ?(xI),只執行反向擴散過程的最后100個時間步長來進行部分再生。
??
3.方法
1.Boostrapping by Diffusion 通過擴散模型促進
??在3D-GS的優化過程中,從稀疏的COLMAP [19,20]點集開始,通過分裂或克隆產生額外的點,最終得到數百萬個小而密集的三維高斯模型。由于最大點的大小(分裂)和梯度的積累(克隆)閾值是需要調整的超參數,我們主要關注梯度的方向,這將顯著影響新點生成的位置和方式。
??因為訓練數據集之外,存在一些看不見的部分,訓練過的3DGS合成的新視圖 I I I,可能不能準確地反映GT圖像。我們將 I I I 視為 I ′ I' I′ 的“部分退化版本”。可以利用擴散模型,實現對 I I I 的 image-to-image integration,得到image density I ′ I' I′ 。 I ′ I' I′ 可以表示為添加到合成圖像 I I I 中的噪聲集合。

??然而,在實踐中實現這種理想的情況是非常困難的。這不僅是因為 1.目前可用的開源擴散模型不能很好地生成所有場景中的部分圖像 ,而且還因為 2.許多場景本身都是復雜和獨特的 。此外, 3.引導(bootstrap)的過程也引入了一定程度的不確定性 。理想情況下,構建的3D場景在所有角度都保持一致。然而,擴散模型引入的可變性使得保證擴散模型從一個新視角重新生成的場景與來自另一個新視角的場景無縫對齊具有挑戰性。另外, 4.并不是合成的新視圖圖像的所有部分都應該被再生 ,如果我們將擴散過程應用到整個圖像中,一些已經訓練良好的部分會在一定程度上被扭曲。本文探索了一種更通用、更穩定的方法。
??
2.梯度方向和 Diffusion
?? 引入Bootstrapping 的時機 。對于整體場景一致性的問題,需要從一個相對完整的階段開始引導。對于通過擴散模型再生的新視圖圖像,如果周圍的上下文相似且 homogeneous (應該翻譯為同類或同質),這種環境下再生的內容往往變化不大。差異程度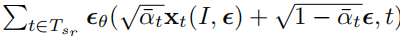
部分是有限的,不僅僅是由于初始上下文的相似性,還因為擴散過程只應用在最后幾個時間步(t越接近0,t時刻引入的噪聲越小)。
??在3D-GS模型構建一個相對完整的場景后,對每個訓練圖像進行bootstrap。為了從訓練圖像 I t I_t It? 中獲得新圖像 I n t I_n^t Int?,稍微改變訓練相機的 q v e c qvec qvec 和 t v e c tvec tvec,以獲得新的視圖相機。然后通過擴散模型D,重新生成 I d t I_d^t Idt?=D( I n t I_n^t Int?)。實踐中,從每個訓練像機中生成多個新視圖。
?? 可控的擴散方向。 重新生成的內容分為兩個部分: 一個包含了對場景的忠實表示,但隨著改變而改變,另一個顯示了被擴散模型修改的場景的新的表示 。通過管理原始訓練部分和bootstrap部分相關的損失比值,我們可以實現3D-GS模型的全局穩定訓練過程。
??bootstrap損失: L b L_b Lb?= || I d t I_d^t Idt? - I n t I_n^t Int?||;對每個訓練像機,使用混合損失:
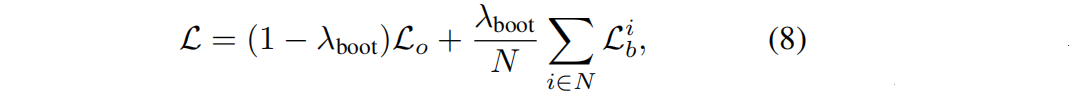
?? L o L_o Lo?是GT圖像的原始3D-GS損失, ∑ i ∈ N L b i \sum_{i∈N}L_b^i ∑i∈N?Lbi? 是基于該訓練攝像機及其周圍像機的所有新視圖變體引入的引導損失的和,N是總變體數。例如,如果訓練攝像機有周圍攝像機的兩側,并且我們用它的2個變體來引導每個攝像機,那么N是6。這種設計選擇是由于大多數三維重建數據集[83–85]的共同特征,其中位于近距離的攝像機通常會捕捉相鄰的場景.
??對于訓練中不可見的視角,渲染明顯無序或缺乏細節,bootstrap足以在多個視點中進行一致的更改。在我們的方法中,當引導場景涉及到損失項設置中的相同部分時,我們會對這些公共區域的值進行平均(這些部分通常被合成了很多次),這確保了不同引導場景中的元素被規范化。
??稠密化過程中,點被分裂或克隆。不完美部分的周圍點被 initially flattened,以補償重生的新視圖渲染中的不一致性。經過多次迭代的積累,大點被分割成小點,小點沿著梯度方向被克隆(這是主要焦點,代表場景中的細粒度)。實際應用中,大的點可以被認為是較小的高斯分布的粗聚集。
??補償過程往往是不穩定的,因為渲染甚至在同一場景部分也發生變化。 然而,本文利用多個重新生成的新視圖,來訓練單個視圖 。對于這些渲染,如果其中的細節不沖突,那么它們能表示看不見的細節,或可以自由修改的粗糙建模;如果它們之間存在沖突,則選擇最普遍適用的方法來對齊。給定一個受到不同梯度方向更新的點,稱為 ∑ i ∈ m ? g m \sum_{i∈m}?g_m ∑i∈m??gm?。 m m m 為不同梯度方向的總數, ? g m ?g_m ?gm?為對應的梯度。如果我們將這些高維梯度方向抽象成簡單的二維方向,我們就可以進一步簡化這個問題。
??假設二維xy平面上的每個梯度只包含兩個方向,正y指向GT,x表示偏差,為了簡單起見,我們將每個方向分離成一個累積形式。我們假設擴散模型通常產生的圖像與背景一致,但細節有所不同。然后通過建立一個適當的梯度積累幅度閾值,并將其與我們在等式8中概述的優化策略相結合,可以達到所期望的優化結果,如圖3所示。

??經過幾輪分裂后,點將足夠小,在這些點上只會出現少量的梯度(即使沒有,λboot也足夠小)。為了進一步克隆,只有這些恰好指向一個方向的梯度和較小的偏差才有可能超過這個閾值,然后我們得到一個相對可靠的bootstrap克隆點,構成了該場景中的細節。
4.實驗
??數據集。數據集包括Mip-NeRF360 [83]的7個場景,兩個來自 Tanks&Temples[84]的場景,兩個場景來自 DeepBlending[85]的場景。
??Baseline。原始3D-GS [1], Mip-NeRF360 [83],
iNGP [10] 和 Plenoxels [9],以及最近的 Scaffold-GS。
??設置。對于bootstrap部分,使用 Stable Diffusion (SD) 2v.1模型 [30]及其精調模型作為初始擴散模型。共進行了4個階段的實驗,其中何時和如何應用bootstrap是不同的。實驗初始階段,以特定的時間間隔執行bootstrap,為每個引導跨度提供1000次迭代。在這1000次迭代間隔中,我們在前500次迭代中將 λ b o o t λ_{boot} λboot?設置為 0.15,在剩下的500次迭代中將其降低為 0.05。在配置擴散模型時,我們采用了一個逐步降低的圖像破損強度 s r s_r sr?,范圍從0.05到0.01,跨越100個DDIM [28]采樣的時間步長。不同的數據集,有不同的策略來創建新的視圖像機(隨機或連續)。引導重新生成的圖像將使用原始的SD2.1v模型來執行。在第二階段的實驗中,SD2.1v模型分別對每個訓練數據集進行細化,同時保持其他配置不變。調整SD2.1v模型,結果有顯著的波動:一些場景在指標上顯示了明顯的進展,而另一些場景表現出明顯的退化,4.2節會討論到。
??在對每個場景的模型進行微調之后,為進一步解鎖bootstrap的潛力,在第三階段實驗中,將擴散破損強度 s r s_r sr?從0.15調整到0.01,每個場景的所有bootstrap圖像都設置為隨機。雖然最初三個階段的實驗已經證明了比最初的3D-GS有相當大的改進,但在渲染特定視圖方面仍然存在挑戰。因此,在第四階段實驗中,使用了一個upscale的擴散模型來進行bootstrap再生。
??結果分析。bootstrap方法的有效性已經在各種場景中得到了證明,特別是在具有無紋理表面和觀察不足的具有挑戰性的環境中。此外,該方法還顯示了其在改變相機進行新視圖渲染時的適應性,突出了其在捕捉均勻細微差別方面的熟練程度,如圖4。

??指標對比。與原始3D-GS相比,僅應用一個interval的bootstrap后,質量指標的改進可以追溯到7k次迭代。即使第一階段實驗中簡單地應用SD2.1v模型,與原始3D-GS相比也有著顯著進展。此外,在對每個場景的SD2.1v模型進行微調后,在所有數據集和指標上都取得了最好的結果,在它們自己的數據集上的性能甚至超過了Mip-NeRF 360。鑒于第三階段實驗的總體性能指標與第二階段相似,在補充材料中提供第三階段實驗的詳細報告。

??新視角偽影的緩解。除了指標,我們還解決了在改變相機變焦或渲染視圖時出現的一些問題(一定程度上明顯偏離了訓練集)。通過生成如圖5所示的偽細節,bootstrap減輕了在原始3D-GS中觀察到的偽影。通過第三階段實驗,在特定視圖中出現的偽影確實可以在保持強性能指標的同時得到緩解。第四階段實驗將主要集中于進一步減輕這些偽影(見附錄說明)。從圖1和圖6中可以看出,第四階段,在欠采樣視圖中觀察到的失真和表下的混亂質量已經被大大修改。基于Mip-NeRF 360數據集的第四階段實驗表明,upscale擴散模型的應用在包含許多看不見的視圖的開放場景中特別有效(可能是因為我們沒有對它進行微調)。對于大多數室內場景,通過高upscale散模型引入顯著的噪聲往往會對性能指標產生實質性的負面影響。

??時間消耗比較見表2。一般來說,擴散時間步長的增加,這與破損強度 s r s_r sr?有關,以及在我們的第四階段實驗中使用的upscale擴散模型,顯著增加了額外的訓練時間。
??特征分析。比較了四個階段的實驗中的渲染細節。 在最初的兩個階段,如果我們僅僅根據生成質量進行評估,而不考慮地面真相,那么當用肉眼觀察時,它們的質量似乎有最小的差異。在對每個特定場景進行微調后,我們觀察到在特定環境細節方面取得了顯著進展。例如,在圖4的房間中,考慮了門上方的封閉攝像頭。在我們的第一階段實驗中,相機只以一種類似于相機的基本形式表示。然而,在我們的第二階段實驗中,攝像機顯示出與地面真相相似的曲線。第三階段實驗中,雖然由于DDIM采樣步驟的增加,細節發生了改變和改進,如圖5所示,但這些改變并不能完全彌補場景中存在的實質性缺陷。此外,這些產生的細節往往發生在低頻率,這與我們的損失項密切相關。由于我們的方法強調增強相互協調而不是相互沖突的細節,由擴散模型產生的高頻細節往往表現出可變性。最終,第四階段實驗能夠顯著地修改看不見的內容
??消融實驗。表3評估了擴散模型的超參數,只有破損強度 s r s_r sr?和減重 λ b o o t λ_{boot} λboot?是重要的。 常見的超參數通常會影響傳統文本到圖像生成的結果,如文本提示、文本提示比例和[30]中描述的eta,在我們的實驗設置中影響很小。我們只在特定的時間間隔內應用bootstrap技術(第6000次迭代后進行連續的bootstrap),但發現這種方法導致不穩定性。當過度使用時,連續的引導往往會生成完全脫離上下文的場景。即使是專門對每個場景的擴散模型進行微調,它的不穩定性仍然是一個重要的問題。在第二階段的設置中,通過連續引導獲得的最高結果偶爾會超過我們的最佳記錄。然而,實現這些優越的結果是相當具有挑戰性的,所需的訓練時間大約是我們的第三階段實驗的訓練時間的2.5倍。這種時間和精力的顯著增加突出了連續bootstrap的低效率,盡管它有可能實現稍微更好的性能指標。請注意,其他基礎消融研究都是在第一階段實驗的配置上進行測試的。
補充材料
??1.Bootstrapping 視角的創建。COLMAP中,相機內參在給定的場景中保持一致, 外參包括qvec和tvec(柵格化中必不可少的),引入兩種類型的視圖Bootstrap:隨機的,和連續的 。對于隨機視圖的創建,在qvec和tvec中加入正態分布噪聲,比例因子分別為0.1和0.2,然后對qvec進行歸一化。對于連續法,將間隔均勻地插入后續攝像機的qvec和tvec中,然后對qvec進行歸一化。
??對 s r s_r sr?和 λ b o o t λ_{boot} λboot?的解釋, s r s_r sr?的遞減設置相對容易理解。隨著訓練過程的進展,模型逐步改善了其對重建的三維場景的表示,因此需要更少的修改。在對SD2.1v模型進行微調后,我們建議通過微調的模型所做的改變應該更好地與GT一致。因此,我們可以在早期的迭代中應用更大的 s r s_r sr?,以確保初始修正更有影響力。 λ b o o t λ_{boot} λboot?設置為兩階段方法:第一階段,使用一個更大的 λ b o o t λ_{boot} λboot?來補償偽影。這是通過使用擴散模型生成更多的上下文一致渲染來實現的,有助于穩定初始輸出,后續階段進一步細化。
??Bootstrap間隔。對于共30k次迭代,Bootstrap僅應用于第6000、9000、15000、15000、18000、21000、24000、27000和29000次迭代,每次持續1000次迭代。這個時間與3,000個迭代周期相一致,其中3D-GS模型的占用率被重置。通過將Bootstrap干預與這些重置點同步,有效地實現理想的更改變得更容易,因為由于占用變量的重置(reset of occupancy variables),模型處于更容易接受修改的狀態。另一方面,1000次迭代的Bootstrap間隔,與3000次迭代周期很一致,提供了一種平衡的方法來合并新的細節而不超載系統。這個間隔是最優的,因為擴散模型產生的細節可能會相互沖突,因此沒有必要連續運行完整的訓練周期。此外,Bootstrap損失的計算,如等式8中所述、是資源密集型的,顯著減慢了整體的訓練速度。
??SD策略:我們認為新視圖渲染圖是“beoken”的,它們可以被擴散模型修正和增強。因此,選擇用于微調的圖像應該代表這些破碎的渲染圖及其相應的GT。微調擴散模型的方法:利用一半的訓練集來訓練3D-GS模型。然后,我們在6000個迭代標記處使用模型來渲染訓練集的剩余一半,由于潛在的差異和偽影,將這些渲染識別為“beoken的”渲染。這個過程對訓練集的每一半重復兩次,使我們能夠生成數百張微調圖像。此外,在4,000個迭代checkpoint處的原始3D-GS模型也適合使用,因為它為我們的目的顯示了適當的缺陷水平。這個特定的checkpoint可以用來獲得額外的微調渲染。
??Upscale 擴散模型的實現。 Upscale diffusion 專門設計來解決重要的偽影,如distortion和 jumbled masses,我們認為這是廣泛的“破壞”方面的渲染。為了緩解這些問題,首先使用微調的SD2.1v模型采用了一個再生過程。隨后,為了進一步細化輸出,我們應用一個isothermal 西格瑪值為3的二維高斯模糊核來模糊圖像。這個模糊的步驟有助于消除缺陷和減少噪音。在模糊后,我們將圖像縮小了3倍;然后利用Upscale 擴散模型將圖像放大四倍,其中采用強噪聲增強來提高圖像的質量和細節,如圖7所示。我們實現了從第6000次迭代到第18000次迭代的模糊和升級過程,并結合了基本的引導技術。需要注意的是,圖7中描述的情況只代表了第6000次迭代時的場景。隨著引導通過這些迭代的繼續,圖像中的細節變得越來越細粒度和自然。Upscale擴散模型是原始的SD-x4-upscaling,沒有進一步的微調。

??在高檔擴散模型中加入顯著的噪聲增強確實可以導致已經訓練良好的部分圖像的改變;為防止這些改變可能導致的質量下降,訓練過程中,等式8將項N的數量調整為8。該調整包含了6張由SD2.1v生成的Bootstrap圖像,并添加了2個由高檔擴散模型生成的額外圖像。
四、GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
??GauStudio,一種新的模塊化框架,用于建模3D高斯濺射(3DGS),為用戶提供標準化的、即插即用的組件,以輕松地定制和實現3DGS管道。是一種具有前景和skyball背景模型的混合高斯表示方法。實驗表明,這種表示法減少了無界戶外場景中的偽影,并改進了新的視圖合成。最后,我們提出了高斯濺射表面重建(GauS),這是一種新的渲染然后融合方法,用于3DGS輸入的高保真網格重建,不需要微調。總的來說,我們的GauStudio框架、混合表示和GauS方法增強了3DGS建模和渲染能力,實現了更高質量的新視圖合成和表面重建。
??
五、Gaussian Grouping:分割和編輯任何高斯

1.摘要
??Gaussian Splatting實現了高質量和實時的三維場景合成,但它只專注于外觀和幾何建模,而缺乏對細粒度的對象級場景的理解。Gaussian Grouping擴展了GS,在開放世界的三維場景中聯合重建和分割任何東西:用一個緊湊的ID編碼增強每個GS,根據它們的對象實例/隸屬度進行分組,具體是利用SAM的二維mask預測,并引入三維空間一致性正則化,在可微渲染過程中監督ID編碼。與隱式NeRF表示相比,離散的三維高斯模型具有高視覺質量、高粒度和高效率。在高斯分組的基礎上,進一步提出了一種局部高斯編輯方案,該方案在三維對象去除、inpaint、著色和場景重構等多功能場景編輯應用中顯示出了良好的效果。
??高斯分組繼承了SAM強大的zero shot二維場景理解能力,并通過產生一致的新視圖合成和分割,將其擴展到三維空間。為進一步提高分組精度,引入了一種利用三維空間一致性的非監督三維正則化損失:使最近個k的三維高斯的ID編碼,在特征距離上非常接近。這有助于三維物體內部的高斯分布或嚴重遮擋在渲染時更充分的監督。
??
2.任何掩碼輸入和一致性
??保留了高斯模型的所有屬性(如它們的數量、顏色、不透明度和大小),同時添加了新的身份編碼參數(類似于顏色建模的格式)。這允許每個高斯分布被分配給其在3D場景中所表示的實例或東西。
??為了模擬開放世界場景,我們采取了一組多視圖捕獲,以及由SAM自動生成的二維分割,以及通過SfM [40]校準的相應相機。

??為了實現跨視圖的二維mask的一致性,我們使用了一個訓練有素的zero-shot tracker[7]來傳播和關聯mask。這還提供了3D場景中的mask id 的總數。圖2 (b)可視化了關聯起來的2D mask標簽。相比于[39]提出的基于cost的線性分配方法,簡化了訓練難度,同時避免了每次渲染迭代中重復計算匹配關系,加速超過60×,并具備更好的性能,特別是在SAM的密集和重疊mask下。
??
??
3.三維高斯渲染和分組
??ID 編碼。為了將屬于同一實例的三維高斯分組,除了現有的高斯性質,我們還在每個高斯分布中引入了一個新的參數:身份編碼是一個長度為16的可學習的、緊湊的向量,足以以計算效率區分場景中的不同對象/部分。與場景的依賴于視圖的外觀建模不同,實例ID在各種渲染視圖中是一致的。因此,我們將身份編碼的SH degree設置為0,只對其 direct-current component進行建模。
??通過渲染來分組。為了優化ID編碼,圖2(c)將ID 向量以可微的方式渲染為二維圖像。從原始GS中提取可微的三維高斯渲染器,并將渲染過程類似于gs中的顏色(SH系數)優化。
??GS采用神經點的 α ′ α' α′ 渲染[18,19],進行深度]排序和混合N個與像素重疊的有序點,計算所有高斯分布對單個位置像素的影響:

其中,每個像素的最終二維mask身份特征 E i d E_{id} Eid? 是,每個高斯長度16的身份編碼 e i e_i ei? 的加權和,由該像素上的高斯影響因子 α i ′ α_i' αi′?加權。參考[55],通過測量二維高斯的協方差 Σ 2 D Σ^{2D} Σ2D,乘以每個點學習到的不透明度 α i α_i αi?,來計算 α i ′ α_i' αi′?;其中 Σ 3 D Σ^{3D} Σ3D為三維協方差矩陣, Σ 2 D Σ^{2D} Σ2D為平面2D版本。J是3D-2D投影的仿射近似的雅可比矩陣,W是 world-to-camera的變換矩陣。
??
??group損失:
??1.二維ID損失。給定公式1中渲染的2D特性 E i d E_{id} Eid?作為輸入,使用一個線性層 f f f,將特征維數恢復到K+1,然后取 s o f t m a x softmax softmax( f f f( E i d E_{id} Eid?))進行ID分類(K是3D場景中的mask總數),采用標準的交叉熵損失 L 2 d L_{2d} L2d?進行K+1類別分類。
??2.三維正則化損失。除了間接的二維監督,還引入無監督的三維正則化損失來約束ID編碼 e i e_i ei?的學習:利用三維空間一致性,通過最近的 k個三維高斯分布的ID編碼與其特征距離拉近。這允許3D對象內部的三維高斯分布,或在基于點的渲染期間被嚴重遮擋(在幾乎所有的訓練視圖中都不可見)得到更充分的監督。公式3的 F F F表示為與線性層(在計算二維身份損失時共享)相結合的softmax操作。用m個采樣點將KL散度損失形式化為:
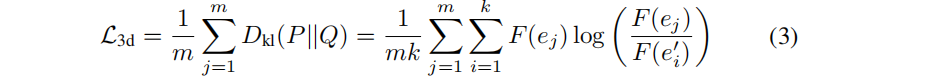 其中P包含三維高斯分布的ID編碼 e e e,集合Q={ e 1 ′ e_1' e1′?, e 2 ′ e_2' e2′?,…, e k ′ e_k' ek′?}是三維空間中的k個最近鄰。結合原始GS的損失 L o r i L_{ori} Lori?,總損失為:
其中P包含三維高斯分布的ID編碼 e e e,集合Q={ e 1 ′ e_1' e1′?, e 2 ′ e_2' e2′?,…, e k ′ e_k' ek′?}是三維空間中的k個最近鄰。結合原始GS的損失 L o r i L_{ori} Lori?,總損失為:
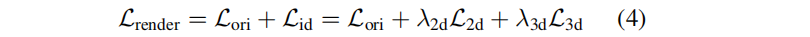
4.局部高斯編輯
??圖3用分組的三維高斯,來表示整個三維場景。基于解耦的場景表示,凍結大多數訓練好的高斯,只調整相關的或新添加的高斯。對于三維對象的去除,只需刪除編輯目標的三維高斯分布;對于三維場景的重新組合,在兩個高斯群之間交換三維位置。過程沒有參數調優。
??對于三維inpaint,先刪除高斯,然后添加新高斯,渲染由LAMA [41]的二維inpaint結果監督。對于三維對象著色或風格遷移,只調整相應高斯群的顏色(SH)參數,同時固定它們的三維位置和大小,以保留學習到的三維場景幾何

5.實驗
??數據集。實驗改進了現有的 LERF-Localization[14]評估數據集,并提出了LERF-Mask數據集,在該數據集中,我們使用精確的掩模手動注釋了LERF本地化中的三個場景,而不是使用粗糙的邊界框。對于每個3D場景,我們平均提供了7.7個文本查詢和相應的GT mask標簽。
??定性評估。在Mip-Nerf360中部9組場景中的7組上進行了高斯分組測試,LLFF [28]、Tanks&Temples[16]和Instruct-NeRF2NeRF[10]中獲取了不同的3D場景案例來進行視覺比較。還采用了邊界度量mBIoU來更好地進行分割質量測量。
??實施細節。ID編碼為16維,實現了類似于rgb特征的前向和后向的cuda柵格化。分類線性層有16個輸入信道和256個輸出信道。訓練中, λ 2 d λ_{2d} λ2d? = 1.0和 λ 3 d λ_{3d} λ3d? = 2.0。Adam優化器,ID編碼的習率為0.0025;線性層學習率為0.0005。三維正則化損失的k = 5和m = 1000。A100 GPU上進行30K迭代訓練。
??三維對象的刪除,我們得到了對所選實例id進行分類的三維高斯分布。后處理包括首先去除異常值,然后使用凸包得到與刪除對象對應的所有高斯函數。三維對象的inpaint,在刪除區域附近初始化高斯分布,使用與SPIn-NeRF相同的LPIPS損失微調。
??與現有的開放詞匯表三維分割方法的對比,如LERF [14]。見表1,以及圖5(我們的方法的分割預測具有清晰的邊界,而基于LERF的相似度計算方法只提供了一個粗略的定位區域)。由于SAM不支持語言提示,我們采用Grounding DINO ]先識別2D圖像中的框,然后根據框選擇相應的掩碼(右邊第二列)。
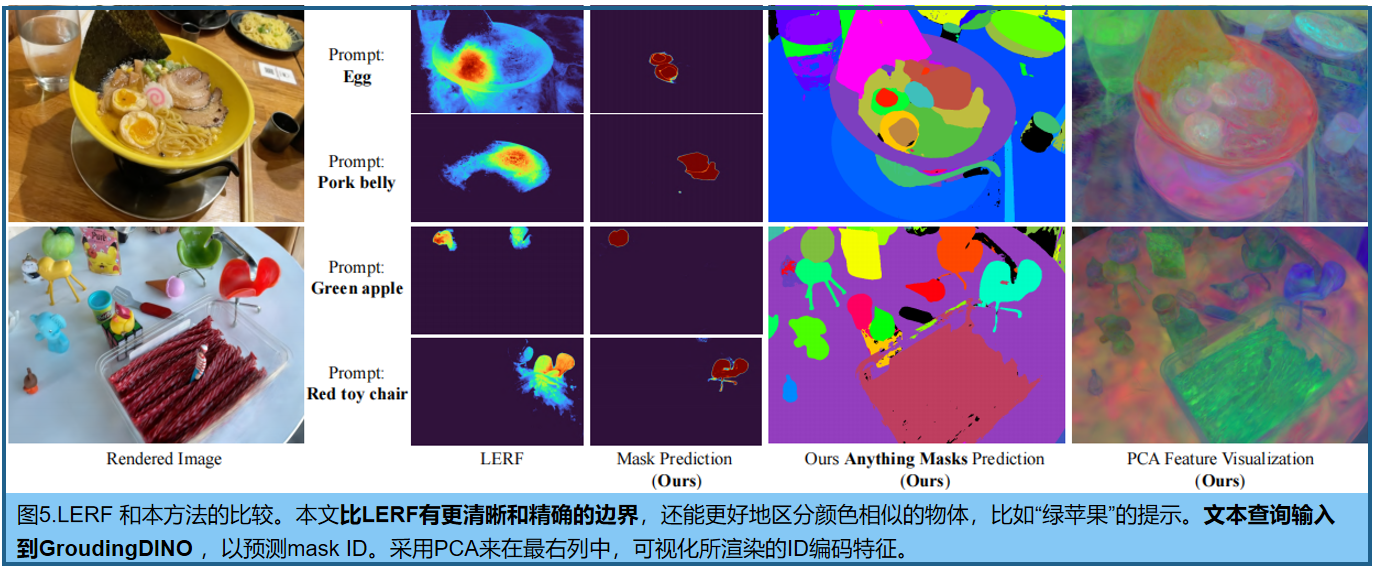

??3D對象刪除是從3D場景中完全刪除一個對象,其中刪除的實例/東西后面的背景可能會有噪聲或因為沒有觀察而有一個洞。圖6比較了GaussianGroup與蒸餾特征場(DFFs)[17]的去除效果。對于具有大對象的挑戰性場景案例,我們的方法可以清晰地將三維對象從背景場景中分離出來。而DFFs的性能受到其clip蒸餾特性的質量的限制,這導致了完整的前景去除(列車箱)或不準確的區域去除與明顯的偽影(卡車箱)

??3D對象inpaint在物體去除的基礎上,要進一步填充由于缺少觀測值而導致的“空洞”,使其成為一個逼真的、視覺一致的自然三維場景。我們首先檢測刪除后所有視圖中不可見的區域,然后在內部繪制這些“不可見區域”,而不是整個“二維對象區域”。在每個渲染視圖中,我們采用二維inpaint圖像來指導新引入的三維高斯圖像的學習。在圖7中,與SPIn-NeRF [31]相比,更好地保留了空間細節和多視圖相干性。

六、InstantSplat:無界稀疏視圖的40秒無位姿高斯潑濺
標題:《InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds》
作者:得克薩斯大學、英偉達研究院、廈門大學、格魯吉亞理工學院
d \sqrt{d} d? 1 0.24 \frac {1}{0.24} 0.241? x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ? \epsilon ?
? \phi ?
該處使用的url網絡請求的數據。
總結
提示:這里對文章進行總結:
例如:以上就是今天要講的內容,本文僅僅簡單介紹了pandas的使用,而pandas提供了大量能使我們快速便捷地處理數據的函數和方法。














)


——A survey of uncertainty in deep neural networks)

