在信息時代,我們常常希望人工智能能夠學到更多的知識,變得更加智能。但你是否想過,有時候讓機器"忘記"一些它學到的東西,也是一件很重要的事?
隨著用戶隱私保護意識的提高和相關法律法規的出臺,用戶有權要求企業或機構刪除其個人數據。對于使用機器學習方法的應用來說,這就意味著需要讓訓練好的模型"忘掉"某些用戶的數據,讓模型"機器遺忘"。但是,對已經訓練好的模型進行"減法"遠比"加法"困難。因為在機器學習的過程中,每個樣本對模型的影響是交織在一起的,很難精準地"剔除"某個數據的影響。
除了保護隱私,機器遺忘在修正有偏見的模型、提高模型魯棒性等方面也有重要作用。本文將帶您全面了解"機器遺忘"這一嶄新的研究方向,介紹其主要挑戰和代表性的技術方法。讓我們一起探索這一有趣而又充滿潛力的領域,了解"忘記"也是人工智能需要學習的一門學問。
論文標題:
Machine Unlearning: A Comprehensive Survey
論文鏈接:
https://arxiv.org/pdf/2405.07406
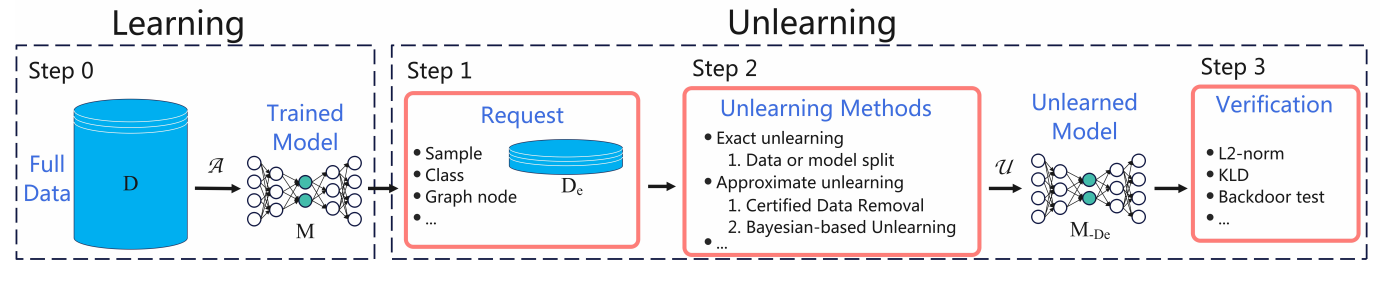
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
在信息爆炸的時代,機器學習模型變得越來越強大,但也面臨著新的挑戰——如何"忘記"不再需要的數據和知識。本文將帶你探索"機器遺忘"這一前沿研究方向。
讓機器學會"忘記"有多難?
傳統的機器學習模型就像一個"海綿",不斷吸收數據,但卻不知道如何"擠壓"出不需要的部分。當用戶要求刪除個人數據時,簡單地從訓練集中移除這些數據是不夠的,因為模型已經從這些數據中學到了知識,形成了某種"記憶"。

要讓模型真正"忘記"某些數據,面臨三大挑戰:
-
訓練過程的隨機性(Stochasticity of training):模型訓練過程中引入的隨機性(如隨機初始化、數據采樣、mini-batch梯度下降等),導致每次訓練的結果都不完全相同,給"遺忘"某些數據帶來困難。即便使用相同的訓練數據,重新訓練得到的模型也可能與之前的模型有差異。
-
訓練過程的增量性(Incrementality of training):模型通過增量方式不斷學習新數據,每個數據對模型的影響相互交織。前面學習的數據會影響后續數據對模型的作用。當要"遺忘"某些數據時,很難準確估計和剝離這些數據對模型的影響,因為它們已經間接地影響了其他數據的學習過程。
-
災難性遺忘(Catastrophic forgetting):當要"遺忘"的數據量較大時,通過各種機器遺忘技術得到的新模型性能可能大幅下降,其效果遠遜于重新訓練的模型。這種令人驚訝的性能下降被稱為"災難性遺忘"。如何在避免隱私泄露的同時,盡量減輕機器遺忘帶來的副作用也是一大挑戰。

此外,機器遺忘還面臨如何衡量遺忘效果的問題。傳統的模型評估指標(如準確率)無法直接度量隱私泄露風險。需要新的評估指標來權衡模型性能和隱私保護強度,這也是一個亟待探索的方向。
綜上,讓機器學會"忘記"絕非易事。研究者們需要攻克隨機性、增量性、災難性遺忘等難題,并設計出科學的評估指標,才能實現高質量的機器遺忘。這需要機器學習、隱私保護、安全等多個領域的交叉探索和創新。
機器遺忘技術大比拼
面對機器遺忘的重重挑戰,研究者們提出了多種解決方案。總的來說,主流的機器遺忘技術可分為兩大類:精準遺忘和近似遺忘。
精準遺忘:給記憶"做減法"
精準遺忘的核心思想是:與其在完整模型上直接"遺忘",不如先把模型"分解"成多個部分,再在局部進行遺忘,最后再把它們"組裝"起來。這樣可以在一定程度上規避隨機性和增量性帶來的影響。
以SISA(Sharded, Isolated, Sliced, and Aggregated)訓練方法為例,它將訓練數據分成多個獨立的"碎片",并在每個碎片上訓練一個獨立的子模型。當需要遺忘某些數據時,只需找到對應的碎片,重新訓練該碎片上的子模型,而其他子模型不受影響。最后,再將各個子模型聚合起來,得到完整的"遺忘后"模型。

類似地,一些研究將模型劃分為多個獨立的模塊,每個模塊只學習一部分數據的特征。遺忘時只需重新訓練相應的模塊即可。還有一些工作利用決策樹、隨機森林等易于分解的模型結構,實現高效的機器遺忘。
近似遺忘:估計并抵消"記憶"影響
近似遺忘則試圖直接從已訓練好的完整模型入手,估計要遺忘的數據對模型的影響,并從模型中"減去"這種影響。由于這種方法只需操作一個完整模型,因此往往更簡單和高效。但另一方面,由于很難準確估計出某些數據對模型的精確影響,遺忘的效果可能沒有精準遺忘那么"干凈利落"。
下圖展示了在分類模型中添加或移除一個數據點時的變化情況。當一個有影響力的數據點出現時,它通常會推動分類線向前移動,以識別該數據點,如圖(b)所示。當需要移除這個有影響力的數據點時,機器遺忘機制必須將模型恢復到未訓練該特定數據點的原始狀態,如圖(c)所示。然而,當僅遺忘一個幾乎沒有影響力的數據點時,該數據點可能對模型幾乎沒有影響,在這種情況下,遺忘后的模型可能與原始訓練的模型相比沒有變化,如圖(d)所示。

常見的近似遺忘方法包括:基于影響函數的方法,它們估計每個訓練數據對模型的貢獻,并在遺忘時對這些貢獻進行反向操作;基于梯度的方法,它們將遺忘目標表示為一個約束優化問題,通過特定的梯度更新策略來不斷"消除"某些數據的影響;還有一些工作利用黑塞矩陣或Fisher信息矩陣來近似每個數據的影響。
近似遺忘要解決的核心問題是:如何在高效地遺忘的同時,盡量控制遺忘導致的性能損失。一些改進方法包括:調節遺忘力度的平衡因子、設定遺忘數據比例的上限、通過特殊的正則化項限制遺忘過程中的模型"跳變"等。這有點類似"調藥方",即根據病情和副作用來動態調整藥量。
差分隱私:從"源頭"上防止隱私泄露
除了在事后通過機器遺忘來"擦除"模型中的隱私數據,另一種思路是從一開始就訓練出"隱私保護友好"的模型。差分隱私(Differential Privacy)正是這樣一種理念,它通過在模型訓練時引入隨機噪聲,使得模型輸出對于有無某條數據變得不敏感,從而從源頭上防止隱私泄露。

差分隱私的核心思想是,如果一個模型在訓練時滿足差分隱私,那么攻擊者通過觀察模型的輸出,將無法判斷某個特定的數據點是否在訓練集中。形式化地說,一個機器學習算法𝑀滿足(𝜖,𝛿)-差分隱私,當且僅當對于任意兩個相鄰數據集𝐷和𝐷′(即只相差一條數據),它們的輸出分布𝑀(𝐷)和𝑀(𝐷′)是𝜖-相似的,且這種相似性以至少1?𝛿的概率成立。直觀地說,𝜖越小隱私保護強度越大。
為了實現差分隱私,常用的方法是在訓練過程中加入Laplace噪聲或高斯噪聲,以掩蓋個體數據點的影響。還有一些工作利用梯度裁剪、模型壓縮等技術,在保證隱私的同時盡量降低噪聲對模型性能的影響。
一些研究嘗試將差分隱私與機器遺忘相結合,用差分隱私的隨機噪聲取代需要遺忘的數據,從而避免了復雜的遺忘步驟。例如可以在模型訓練時對梯度引入差分隱私噪聲,這樣訓練得到的模型對于某些數據天然具有"遺忘性"。還可以利用差分隱私的思想來指導遺忘過程,通過隱私預算來控制遺忘對模型的影響。總的來說,差分隱私為機器遺忘提供了新的視角和方法。

當然,在引入噪聲的同時保證模型的效用仍然是一個挑戰。如何權衡隱私保護強度和模型性能,如何設計更加智能、自適應的噪聲機制,如何在聯邦學習、在線學習等復雜場景下實現差分隱私,都是值得進一步探索的問題。此外,差分隱私雖然提供了強大的隱私保護,但并非對所有攻擊都是"免疫"的。研究者們仍在不斷探索差分隱私的邊界,并設計更加安全、魯棒的機器學習框架。
"機器遺忘"實驗室
為了驗證機器遺忘的有效性,研究者們在多個基準數據集和實際任務上進行了廣泛的實驗。
在圖像分類任務上,研究者們使用了MNIST手寫數字數據集、CIFAR-10/100小型圖像數據集、ImageNet大型圖像數據集等。通過隨機選取一部分訓練樣本作為需要遺忘的數據,然后對比原始模型、重新訓練的模型和機器遺忘的模型在測試集上的準確率,可以評估機器遺忘的有效性。一般來說,重新訓練的模型可以視為"完美遺忘"的參照。實驗結果表明,許多機器遺忘方法都能在保持較高準確率的同時,有效地"忘記"指定的訓練數據,其性能接近重新訓練的模型。

在自然語言處理任務上,研究者們使用了情感分析、文本分類、問答系統等數據集。對于一些涉及用戶隱私的文本數據,機器遺忘可以在保護隱私的同時,避免模型"忘記"過多有用的語言知識。通過精心設計的實驗,研究者們驗證了機器遺忘在文本領域的適用性和有效性。
除了這些經典的基準數據集,研究者們還在一些實際應用中測試了機器遺忘的效果。例如,在推薦系統中,當用戶刪除某些歷史記錄時,需要同時從推薦模型中"遺忘"這些記錄對用戶畫像的影響。在異常檢測任務中,當發現某些數據點可能是噪聲或對抗樣本時,需要動態地從模型中"遺忘"這些異常點的影響,以保證模型的魯棒性。實驗結果表明,機器遺忘可以在這些場景中發揮重要作用,在提升系統性能的同時satisfying隱私和安全需求。

當然,不同的機器遺忘技術在實驗中的表現也有一定差異。一些方法可能在特定數據集或任務上表現得更好,而另一些方法可能具有更好的通用性。此外,機器遺忘的效果也依賴于多種因素,如遺忘數據的規模、模型的復雜度、超參數的選擇等。因此,在實踐中應用機器遺忘時,需要根據具體情況進行適當的選擇和調優。
通過大量實驗,研究者們證明了機器遺忘技術在各種數據集和任務上的有效性。這些實驗結果不僅驗證了已有方法的可行性,也為未來的研究指明了方向。隨著機器遺忘在更多實際場景中的應用,其潛力和價值必將得到進一步的發掘和印證。
忘記,才能更好地前行
在本文中我們探討了機器遺忘這一嶄新的研究領域。從技術挑戰到解決方案,從理論探索到實踐應用,機器遺忘展現出了廣闊的前景和無限的可能。
遺忘是智慧的一種體現。正如人類需要遺忘瑣事以專注于重要的事情,機器也需要學會遺忘,以適應日新月異的環境和需求。通過選擇性地遺忘過時、無用或有害的信息,機器學習模型可以保持靈活、高效、健壯,并不斷進化以應對新的挑戰。
同時,機器遺忘也是實現可信AI的重要一環。隨著隱私保護和數據安全愈發受到重視,賦予用戶"被遺忘權"已成為大勢所趨。機器遺忘技術為數據管理和隱私合規提供了新的解決思路,有助于構建更加安全、透明、可控的人工智能生態。
展望未來,機器遺忘必將在人工智能的發展歷程中扮演越來越重要的角色。它不僅是一種技術,更是一種智慧;不僅是一種手段,更是一種哲學。遺忘不是對過去的否定,而是為了更好地前行。唯有卸下包袱,方能走得更遠!


)
)











)

)
)


】繼承)