目錄
- 1.什么是內聯函數
- 2.內聯函數與宏
- 3.編譯器對內聯函數的處理
- 4.參考文獻
1.什么是內聯函數
很多人都會知道,可以將比較小的函數寫成內聯函數的形式,這樣會節省函數調用的開銷,具體是什么樣的開銷呢?
一個函數在執行過程中,如果需要調用其他函數,則一般會執行下面的過程。
- 保存當前函數現場
- 跳到調用函數執行
- 恢復當前函數現場
- 繼續執行當前函數
一個C語言程序,在main()函數中對某些數據進行處理,運算結果暫時保存在R0寄存器中。接著調用另一個函數call_fun(),調用結束后,返回main()函數繼續執行。如果我們在call_fun()函數中要用到R0寄存器,就會改變R0中的值,當我們返回main()中繼續執行程序的時候,就會出現錯誤的計算。
處理辦法很簡單,就是在跳到call_fun()之前,先將R0中的值保存到對戰中,調用結束后,再將其值取出來,這樣就可以順利地執行main()函數了。這就是所謂的現場保存和恢復。
對于一般的函數調用,當然沒有什么問題,但如果需要調用的函數本來就很小(指令和數據都不多),這個時候如果頻繁地調用,就會出現頻繁地保存現場,恢復現場,降低了程序的執行效率,這個時候就可以將call_fun()改寫為內聯函數,簡單高效。
2.內聯函數與宏
內聯函數和宏的功能差不多,為什么不直接定義一個宏,而去定義一個內聯函數呢?二者又有什么不同呢?
與宏相比,內聯函數具有以下優勢。
- 參數類型檢查:內聯函數具有宏的展開特性,但本質仍是函數,在編譯過程中,編譯器仍然可以對其進行參數檢查,而宏不具備此功能。
- 便于調試:函數支持豐富的斷點調試功能,而宏定義不支持,這樣便于軟件的調試和開發。
- 接口封裝:有些內聯函數可以用來封裝一個接口,而宏并無此特性。
3.編譯器對內聯函數的處理
眾所周知,并不是在函數前添加了inline關鍵字,程序在執行過程中就會乖乖執行內聯展開,這與開發者和計算機都有關系。
而若要得知函數是否真正進行了內聯展開,則需要深入底層,從匯編程序中得知。
尺有所短,寸有所長,內聯函數也有缺點。內聯函數會增大程序的體積,如果在一個文件中多次調用內聯函數,多次展開,則整個函數的體積就會變大,降低了代碼的執行效率。這與函數的設計初衷相悖(函數的作用之一就是提高代碼的復用性)。
編譯器在對內聯函數做展開時,除了檢測用戶定義的內聯函數是否有指針、循環、遞歸,還會在函數執行效率和函數調用開銷之間進行權衡。一般來說,從程序員角度來說,主要考慮以下因素。
- 函數體積小。
- 函數體內無指針賦值、遞歸、循環等語句。
- 調用頻繁。
下面的例子,我們用一個簡單的程序實現了某個數的階乘。
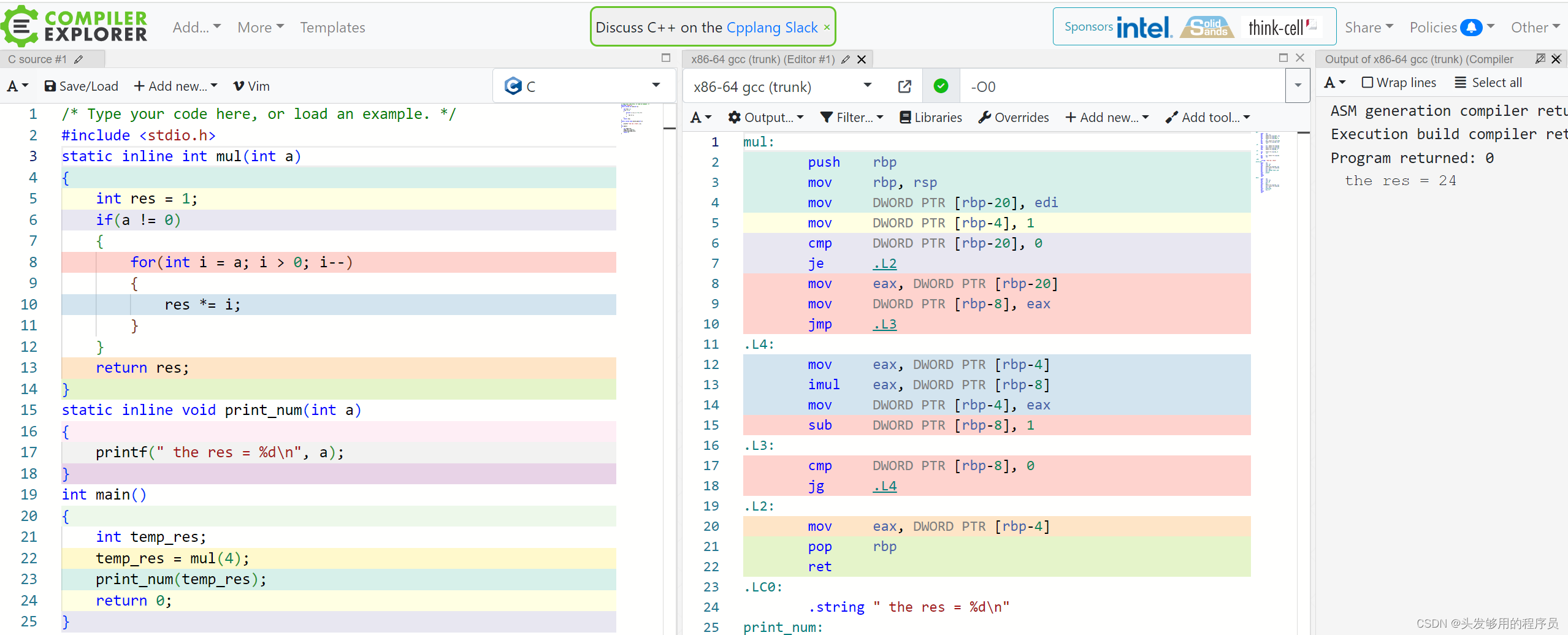
我們封裝了兩個函數,都含有linline關鍵字,而從編譯后的匯編程序可以看出,一個函數進行了內聯展開,而另一個可能考慮到了函數并不是很精簡,并未對其進行內聯展開。
然后將優化等級調到了1,再看看結果:
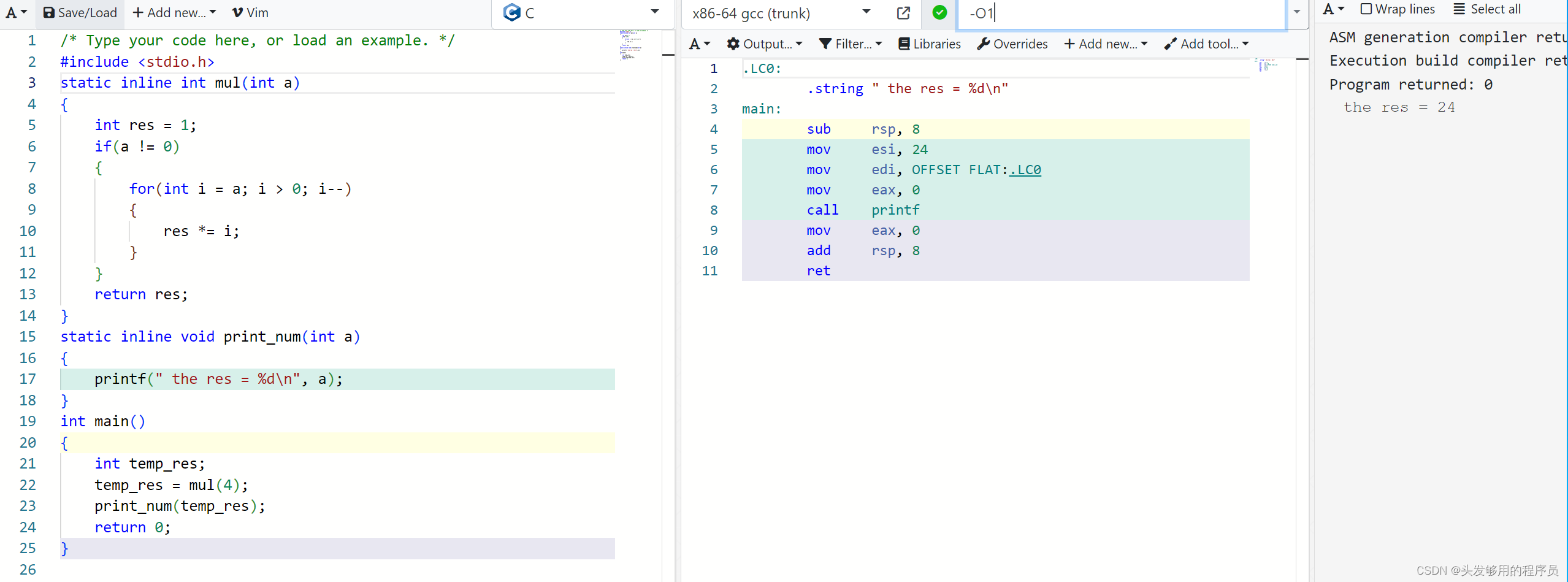
可以看到,將兩個函數都進行了內聯展開。輸出結果仍然是24,保持不變。
接下來我們使用GCC編譯器提供的特性__attribute__來實現強制內聯:
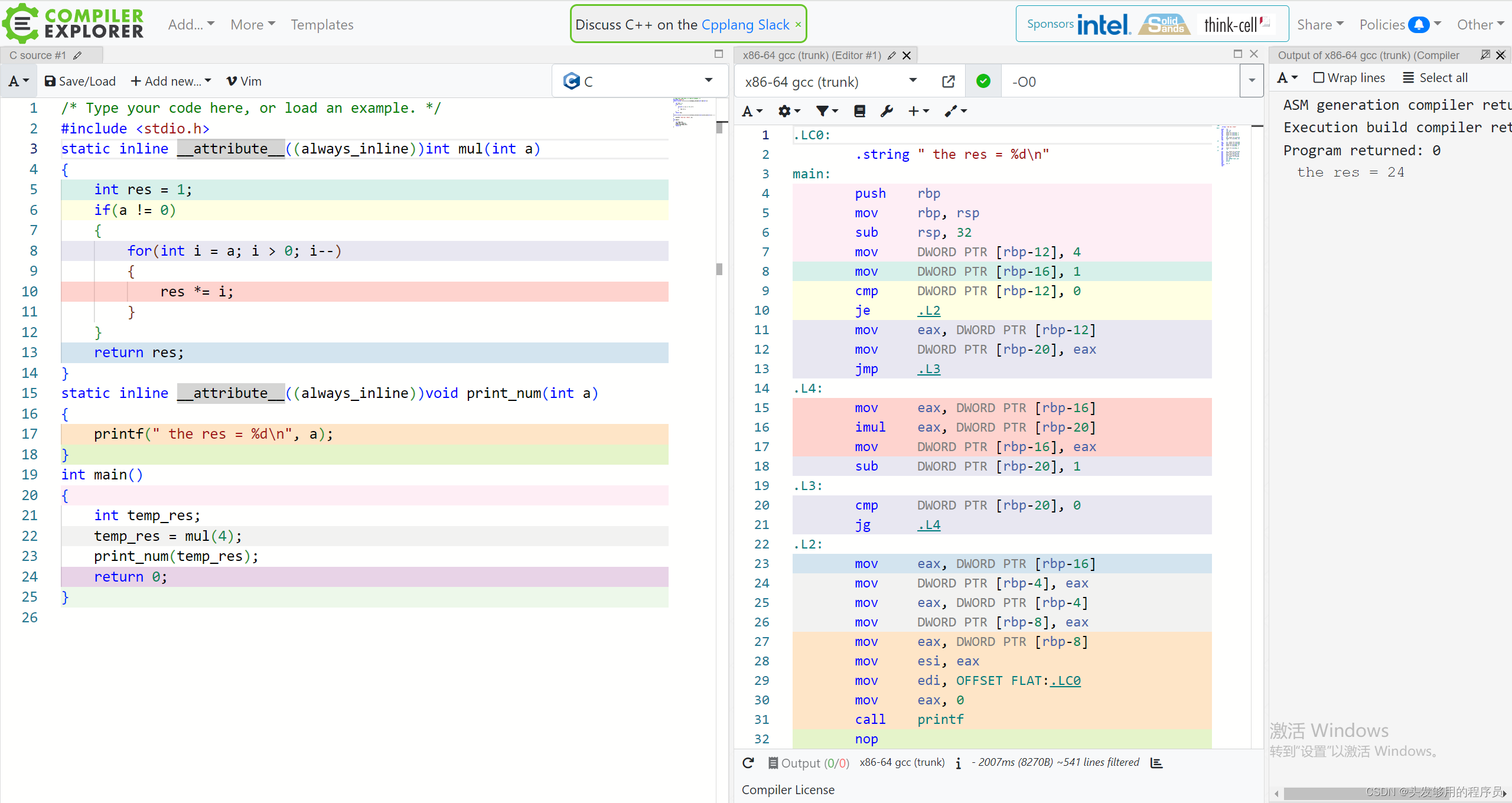
可以看到,此時即使關閉了優化等級,編譯器還是對兩個內聯函數進行了內聯展開。程序的運行結果也不會受影響。
此次我們采用了在線的編譯工具,感覺還不錯,喜歡的同學可以試試。
Compiler Explorer
4.參考文獻
《嵌入式C語言自我修養》
)











)

)
)


】繼承)
