無序集合
Redis 源碼版本:Redis-6.0.9,本篇文章無序集合的代碼均在
intset.h / intset.c文件中。
Redis 通常使用字典結構保存用戶集合數據,字典鍵存儲集合元素,字典值為空。如果一個集合全是整數,則使用字典國語浪費內存。為此,Redis 設計了 intset 數據結構,專門用來保存整數集合數據。
定義
typedef struct intset {uint32_t encoding; // 編碼格式,intset 中所有元素必須是同一種編碼格式uint32_t length; // 集合中元素的數量int8_t contents[]; // 存儲元素數據,元素必須排序,并且無重復
} intset;
encoding 格式如下表所示:
| 定義 | 存儲類型 |
|---|---|
INTSET_ENC_INT16 | int16_t |
INTSET_ENC_INT32 | int32_t |
INTSET_ENC_INT64 | int64_t |
intset 編碼格式存在不同的級別。上表中編碼格式的級別由低到高排序:
I N T S E T _ E N C _ I N T 16 < I N T S E T _ E N C _ I N T 32 < I N T S E T _ E N C _ I N T 64 \rm INTSET\_ENC\_INT16 \lt INTSET\_ENC\_INT32 \lt INTSET\_ENC\_INT64 INTSET_ENC_INT16<INTSET_ENC_INT32<INTSET_ENC_INT64
intsetAdd
- 函數功能:向
intset中插入一個元素。 - 參數:
intset *is:插入到指定的intset中。int64_t value:插入指定的元素。uint8_t *success:是否插入成功。
- 返回值: 返回該
intset,因為在該函數中可能會修改原intset的地址。
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {uint8_t valenc = _intsetValueEncoding(value); // 判斷 val 值對應的 intset 編碼uint32_t pos;if (success) *success = 1; // 如果 success != NULL 默認 Add 成功/* Upgrade encoding if necessary. If we need to upgrade, we know that* this value should be either appended (if > 0) or prepended (if < 0),* because it lies outside the range of existing values. */// 如果參數 value 對應的編碼大于 intset 中元素的編碼。 intrev32ifbe 函數用于轉換字節序if (valenc > intrev32ifbe(is->encoding)) { /* This always succeeds, so we don't need to curry *success. */return intsetUpgradeAndAdd(is,value); // 升級 intset 的編碼,然后插入數據} else {/* Abort if the value is already present in the set.* This call will populate "pos" with the right position to insert* the value when it cannot be found. */if (intsetSearch(is,value,&pos)) { // 如果 intset 中已經存在與 value 相同的值if (success) *success = 0; // 那么插入失敗return is;}// 走到這里說明 intset 中不存在與 value 相同的值,并且不用調整原 intset 的編碼is = intsetResize(is,intrev32ifbe(is->length)+1); // 只需要調整 intset 的大小就行啦// 這個 if 判斷幾乎不可能判斷失敗的,但是為什么這么做,懂得都懂if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); // 將原 intset pos 位置及其之后的元素全部后移一個下標}_intsetSet(is,pos,value); // 將 value 插入到 pos 位置處is->length = intrev32ifbe(intrev32ifbe(is->length)+1); // 更新 intset 的 length 屬性return is;
}
_intsetValueEncoding
- 函數功能:根據整數的大小判斷其在
intset中的編碼。 - 參數:
int64_t v):待判斷編碼的整數。
- 返回值:該整數的編碼。
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))static uint8_t _intsetValueEncoding(int64_t v) {if (v < INT32_MIN || v > INT32_MAX)return INTSET_ENC_INT64;else if (v < INT16_MIN || v > INT16_MAX)return INTSET_ENC_INT32;elsereturn INTSET_ENC_INT16;
}
intsetUpgradeAndAdd
- 函數功能:升級
intset的編碼格式,并將指定的value值插入到intset。 - 參數:
intset *is:需要升級編碼和插入元素的intset。int64_t value:待插入的value。
- 返回值:升級之后的
intset。
/* Upgrades the intset to a larger encoding and inserts the given integer. */
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {uint8_t curenc = intrev32ifbe(is->encoding); // 當前 intset 的編碼格式uint8_t newenc = _intsetValueEncoding(value); // 升級之后 intset 的編碼格式int length = intrev32ifbe(is->length); // 當前 intset 中元素的個數int prepend = value < 0 ? 1 : 0; // 判斷下標的偏移/* First set new encoding and resize */is->encoding = intrev32ifbe(newenc); // 修改 intset 的編碼is = intsetResize(is,intrev32ifbe(is->length)+1); // 調整 intset 的大小,+1 是因為等會兒要插入一個新元素嘛// _intsetGetEncoded(is,length,curenc) 將原來的 intset 的數據獲取出來,從后向前獲取的哇// _intsetSet 將 _intsetGetEncoded 直接插入到新的 intset 中,從后向前插入// length+prepend 如果 value 小于 0 prepend 就是 1,因為負數是插入到柔性數組下標為 0 的位置,下標在數值上就會向后偏移一個。// 如果 value >= 0 prepend 就是 0 直接插入到柔性數組末尾就行了,下標在數值上就不會偏移了while(length--)_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));/* Set the value at the beginning or the end. */// [1](見注解1)if (prepend)_intsetSet(is,0,value); // 如果 value < 0 將新插入的值設置到柔性數組下標為 0 的位置else_intsetSet(is,intrev32ifbe(is->length),value); // 如果 value >= 0 將新插入的值設置到柔性數組末尾哈is->length = intrev32ifbe(intrev32ifbe(is->length)+1); // 更新 intset 的 length 屬性 (集合中元素的個數)return is;
}
-
intset雖說是用來實現無序集合的,但是其內部數據在柔性數組中的排列其實是有序的!下面我們來看看intset內部數據有序的必要性:-
提升查找效率:有序數組允許使用二分查找算法,而二分查找的時間復雜度是 O ( l o g ? n ) \rm O(log?n) O(log?n)。相比于無序數組的線性查找 O ( n ) \rm O(n) O(n),二分查找能夠顯著提升查找操作的性能。當集合中的元素數量增加時,這種性能差異尤其明顯。
-
簡化重復元素檢測:在插入新元素時,有序數組可以通過二分查找快速確定元素是否已經存在于集合中。如果元素已經存在,則直接返回,避免重復插入。這樣的實現方式比起無序數組需要遍歷整個數組來檢查重復元素更加高效。
-
優化內存管理:有序數組在進行插入和刪除操作時,可以通過簡單的內存移動來保持數組的有序性,而不需要像哈希表那樣復雜的重哈希和沖突解決機制。對于小型整數集合,
intset的內存占用也更為緊湊和高效。 -
簡化編碼和實現:有序數組的實現相對簡單,操作邏輯容易理解和維護。保持有序性可以使許多操作在實現上更加直觀,比如插入和查找操作。
無序集合的另一種實現方式就是使用
dict這種實現方式下自然就不能保證數據的有序性啦!回到插入數據的這條語句:使用該函數插入數據,已經明確了插入的數據超出了原
intset編碼的數值范圍,其在原intset中要么是最大值,要么是最小值。因此,只需要判斷這個數的正負選擇是尾插還是頭插就行了!這樣就保證了intset內部數據的有序性啦! -
intsetResize
- 函數功能:調整
intset的大小。 - 參數:
intset *is:需要調整大小的intset。uint32_t len:intset中元素的個數。
- 返回值:調整大小之后的
intset。
/* Resize the intset */
static intset *intsetResize(intset *is, uint32_t len) {uint32_t size = len*intrev32ifbe(is->encoding); // 新的柔性數組的大小is = zrealloc(is,sizeof(intset)+size); // intset 擴容return is;
}
_intsetSet
- 函數功能:將一個
value值設置到intset的指定位置。 - 參數:
intset *is:設置value的intset。int pos:設置value的位置。柔性數組的下標。int64_t value:待設置的值。
- 返回值:無。
/* Set the value at pos, using the configured encoding. */
static void _intsetSet(intset *is, int pos, int64_t value) {uint32_t encoding = intrev32ifbe(is->encoding);if (encoding == INTSET_ENC_INT64) {((int64_t*)is->contents)[pos] = value; // 將值設置到指定的位置memrev64ifbe(((int64_t*)is->contents)+pos); // 轉化字節序} else if (encoding == INTSET_ENC_INT32) {((int32_t*)is->contents)[pos] = value;memrev32ifbe(((int32_t*)is->contents)+pos);} else {((int16_t*)is->contents)[pos] = value;memrev16ifbe(((int16_t*)is->contents)+pos);}
}
_intsetGetEncoded
- 函數功能:根據指定的
encoding編碼獲取指定位置下該編碼的value。 - 參數:
intset *is:獲取value的intset。int pos:指定value的起始位置。uint8_t enc:指定獲取數據的編碼。
- 返回值:獲取到的
value值。
/* Return the value at pos, given an encoding. */
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {int64_t v64;int32_t v32;int16_t v16;if (enc == INTSET_ENC_INT64) {memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); // 獲取值memrev64ifbe(&v64); // 轉化字節序return v64; // 返回結果} else if (enc == INTSET_ENC_INT32) {memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));memrev32ifbe(&v32);return v32;} else {memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));memrev16ifbe(&v16);return v16;}
}
intsetSearch
- 函數功能:在
intset中查找一個整數。 - 參數:
intset *is:一個intset。int64_t value:待查找的值。uint32_t *pos:當pos != NULL時:- 如果返回值為 1:表示
intset中已經存在這個value,*pos為該值在intset中的下標。 - 如果返回值為 0:表示
intset中不存在這個value,*pos為其應該插入到intset中的下標。
- 如果返回值為 1:表示
- 返回值:
intset中是否已經存在相同的value。- 1:已經存在。
- 0:不存在。
/* Search for the position of "value". Return 1 when the value was found and* sets "pos" to the position of the value within the intset. Return 0 when* the value is not present in the intset and sets "pos" to the position* where "value" can be inserted. */
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;int64_t cur = -1;/* The value can never be found when the set is empty */if (intrev32ifbe(is->length) == 0) { // 如果當前的 intset 中沒有元素if (pos) *pos = 0; // 如果 pos 不為 NULL 那么將 value 的下標保存到 *posreturn 0;} else {/* Check for the case where we know we cannot find the value,* but do know the insert position. */// 比較 value 與柔性數組的兩端元素的大小關系,嘗試確定 value 的位置if (value > _intsetGet(is,max)) { // 如果比柔性數組中最大的元素還大,那么插入位置確定if (pos) *pos = intrev32ifbe(is->length); // 如果 pos 不為 NULL 那么將 value 的下標保存到 *posreturn 0;} else if (value < _intsetGet(is,0)) { // 如果比柔性數組中最小的元素還小,那么插入位置確定if (pos) *pos = 0; // 如果 pos 不為 NULL 那么將 value 的下標保存到 *posreturn 0;}}// 下面進行二分查找while(max >= min) {mid = ((unsigned int)min + (unsigned int)max) >> 1;cur = _intsetGet(is,mid); // 獲取 mid 下標對應的值if (value > cur) { // 縮小查找的區間min = mid+1;} else if (value < cur) {max = mid-1;} else { // 找到了,直接退出循環break;}}if (value == cur) { // 如果找到了 valueif (pos) *pos = mid; // 如果 pos 不為 NULL 那么將與 value 值相同元素的下標保存到 *posreturn 1;} else { // 沒有找到if (pos) *pos = min; // 如果 pos 不為 NULL 那么將 value 應在的下標保存到 *posreturn 0;}
}
_intsetGet
- 函數功能:獲取
intset中指定下標的元素。 - 參數:
intset *is:指定的intset。int pos:指定的下標。
- 返回值:獲取到的
value。
/* Return the value at pos, using the configured encoding. */
static int64_t _intsetGet(intset *is, int pos) {return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
}
intsetMoveTail
- 函數功能:將
intset中指定下標及其之后的所有元素移動到指定位置處。 - 參數:
intset *is:數據所在的intset。uint32_t from:從from下標開始及其之后的所有元素均需要移動。uint32_t to:移動到to下標處。
- 返回值:
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {void *src, *dst;uint32_t bytes = intrev32ifbe(is->length)-from; // 需要移動的元素個數uint32_t encoding = intrev32ifbe(is->encoding); // intset 的編碼// 根據編碼確定 memmove 函數的起始地址和目標地址,計算需要移動多少字節if (encoding == INTSET_ENC_INT64) {src = (int64_t*)is->contents+from;dst = (int64_t*)is->contents+to;bytes *= sizeof(int64_t);} else if (encoding == INTSET_ENC_INT32) {src = (int32_t*)is->contents+from;dst = (int32_t*)is->contents+to;bytes *= sizeof(int32_t);} else {src = (int16_t*)is->contents+from;dst = (int16_t*)is->contents+to;bytes *= sizeof(int16_t);}memmove(dst,src,bytes); // 移動元素
}
僅以
intsetAdd函數分析intset的結構,其余函數都比較簡單。
編碼
無序集合類型有 OBJ _ENCODING_HT 和 OBJ _ENCODING_INTSET 兩種編碼,使用 dict 或 intset 存儲數據。使用
OBJ _ENCODING_HT 時,鍵存儲集合元素,值為空。 使用 OBJ_ENCODINGINTSET 編碼需滿足以下條件:
- 集合中只存在整數型元素。
- 集合元素數量小于或等于
server.set_max_intset_entries,該值可通過set-max-intset-entries配置項調整。

有序集合
有序集合即數據都是有序的。存儲一組有序的數據,最簡單的是一下兩種結構:
- 數組,可以通過二分查找法查找數據,但插入數據的復雜度為 O ( N ) \rm O(N) O(N)。
- 鏈表,可以快速插入數據,但是無法使用二分查找,查找數據的復雜度為 O ( N ) \rm O(N) O(N)。
定義
William Pugh 發布的跳表論文
skiplist 是一個多層級的鏈表結構,具有如下特點:
- 上層鏈表是相鄰下層鏈表的子集。
- 頭結點層數不小于其他節點的層數。
- 每個節點 (除了頭結點) 都有一個隨機的層數。
如下圖就是一個跳表結構:

假設 skiplist 中 k 層節點的數量是 k+1 層節點的 p 倍,那么 skiplist 可以看成一棵平衡的 p 叉樹,從頂層開始查找某個節點需要的時間是 O ( l o g p N ) \rm O(logpN) O(logpN)。注意,skiplist 中的每個節點都有一個隨機的層數,它使用的是一種概率平衡而不是精準平衡。
在 skiplist 中查找數據,需要從最高層開始查找。如果某一層后驅節點元素已經大于目標元素(或者不存在后驅節點),則下降一層,從下一層當前位置繼續查找。
在下圖中,假設我們要找值為 19 的節點,他的搜索路徑如下圖所示:

查找步驟如下:
- 從鏈表頭結點的最高層
level3開始查找,找到節點 6。 - 本層節點沒有后驅節點 (后驅節點為
NULL),下降一層,即levle2 - 節點 6
level2的下一個節點值為 25,大于節點 19,下降一層,即level1。 - 節點 6
level1的下一個節點值為 9,小于節點 19,向右找到本層的下一個節點,即節點 9。 - 節點 9
level1的下一個節點值為 25,大于節點 19,下降一層,即level0。 - 節點 9
level0的下一個節點值為 12,小于節點 19,向右找到本層的下一個節點,即節點 12。 - 節點 12
level0的下一個節點值為 19,等于節點 19,找到 19 這個節點,可以返回啦。
在上面的例子中,假設查找的是值為 18 的節點會在找到 19 這個節點之后下降一層,但是 level0 已經是最底層了。就會導致查找失敗。
在高層查找時,每向后移動一個節點,實際上會跨越低層多個節點,這樣便大大提升了查找效率,最終達到二分查找的效率。
在 Redis 中,skiplist 節點 (server.h/zskiplistNode) 的定義如下:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele; // 節點值double score; // 分數,用于排序節點struct zskiplistNode *backward; // 指向前驅節點,一個節點只有第一層有前驅節點指針。因此,skiplist 的第一層鏈表是一個雙向鏈表struct zskiplistLevel {struct zskiplistNode *forward; // 指向本層的后驅節點指針unsigned long span; // 本層后驅節點跨越了多少個第一層節點,用于計算節點的索引值} level[];
} zskiplistNode;
skiplist 的定義如下:
typedef struct zskiplist {struct zskiplistNode *header, *tail; // 指向頭,尾節點的指針unsigned long length; // 節點數量int level; // skiplist 最大的層數,最多為 ZSKIPLIST_MAXLEVEL(32) 層
} zskiplist;
根據 Redis 中 skiplist 節點的定義,我們不難畫出其邏輯圖:

Redis 源碼版本:Redis-6.0.9,下面的內容涉及到的代碼均在
t_zset.c文件中。
zslGetElementByRank
- 函數功能:查找指定
rank的節點。 - 參數:
zskiplist *zsl:查找的skiplist。unsigned long rank:查找的rank值。其中rank的范圍是 1 ~ s k i l p l i s t 中節點的數量 \rm 1\sim skilplist \space 中節點的數量 1~skilplist?中節點的數量 (1 表示skiplist的第一個節點)。
- 返回值:查找成功返回該節點,查找失敗返回
NULL。
/* Finds an element by its rank. The rank argument needs to be 1-based. */
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {zskiplistNode *x; // 當前已經遍歷到的節點unsigned long traversed = 0; // 遍歷了多少個有效節點了int i;x = zsl->header; // 初始指向 skiplist 的頭結點,skiplist 的 head 節點不存儲有效數據的for (i = zsl->level-1; i >= 0; i--) { // zsl->level 是所有節點中的最大層數,從最高層到最底層的遍歷順序嘛// 當遍歷過的有效節點數 <= 指定的 rank,循環執行while (x->level[i].forward && (traversed + x->level[i].span) <= rank){// span 記錄遍歷到 x 指向的節點跨越了多少個有效節點,即 x 及其之前有效節點的數量traversed += x->level[i].span; // 更新 xx = x->level[i].forward;}// 當遍歷過的節點數恰好是查找的 rank,說明就找到該索引的節點啦!例如:假設我們要獲取 rank 為 3 的節點,遍歷過了 3 個節點說明 x 指向的就是第三個有效節點if (traversed == rank) {return x; // 返回查找 }}// 走到這里說明沒有找到哈return NULL;
}
zslInsert
- 函數功能:向
skiplist中插入一個新節點。 - 參數:
zskiplist *zsl:指定插入的skiplist。double score:插入節點的score部分決定了插入到skiplist的位置。sds ele:插入的數據。
- 返回值:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements *//* Insert a new node in the skiplist. Assumes the element does not already* exist (up to the caller to enforce that). The skiplist takes ownership* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // update 記錄插入節點的前驅節點unsigned int rank[ZSKIPLIST_MAXLEVEL]; // 前驅節點的索引int i, level;serverAssert(!isnan(score)); // 這條語句不重要x = zsl->header; // 指向頭結點// zsl->level 是所有節點中的最大層數,從最高層到最底層的遍歷順序嘛for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */// 如果 i == (zsl->level - 1) 即最高層, rank[i] 初始化為 0// 如果 i != (zsl->level - 1) 即非最高層,rank[i] 初始化為上一層跨越的節點數rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];// x 節點的當前層有后驅節點 && (x 節點的 score 小于插入 score || 他倆 score 相等但是 x 的 sds 小于插入的 sds)while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span; // 加上從 x 節點當前層的下一個節點跳躍的節點數,更新索引x = x->level[i].forward; // 更新 x}update[i] = x; // 記錄插入節點第 i 層的前驅節點}/* we assume the element is not already inside, since we allow duplicated* scores, reinserting the same element should never happen since the* caller of zslInsert() should test in the hash table if the element is* already inside or not. */level = zslRandomLevel(); // 生成一個隨機的層數// 如果新節點生成的隨機層數大于原 skiplist 的最大層數,添加更高層的前驅節點和前驅節點的索引// 創建 skiplist 時已經為頭結點預先分配了 ZSKIPLIST_MAXLEVEL 層的內存大小,這里就不需要再重新分配內存了if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0; // 高出 zsl->level 的前驅節點索引一定是 0update[i] = zsl->header; // 高出 zsl->level 的前驅節點一定是 zsl->headerupdate[i]->level[i].span = zsl->length; // 初始化高出 zsl->level 層的 span}zsl->level = level; // 更新 zsl->level}x = zslCreateNode(level,score,ele); // 創建一個新的 skiplistNode 準備插入for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward; // 讓新節點指向插入位置的當前層的后驅節點update[i]->level[i].forward = x; // 插入位置的當前層的前驅指針指向新插入的節點/* update span covered by update[i] as x is inserted here */// [1](見注解1)x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}/* increment span for untouched levels */// 這里更新的是哪些節點的 span 字段呢?其實就是那些節點的層數比新插入節點層數高的并且在新插入節點前面的那些節點for (i = level; i < zsl->level; i++) {update[i]->level[i].span++; // 插入了一個新的節點,當前層到后驅節點跨越的節點熟練自然要加 1 }// 設置新插入節點的 backward 字段,如果插入節點的索引值為 1 backward 字段設置為 NULL,否則指向第一層的前驅節點就行了x->backward = (update[0] == zsl->header) ? NULL : update[0];// 如果新插入的節點不是 skiplist 的最后一個節點,自然也要更新后驅節點的 backward 字段啦if (x->level[0].forward)x->level[0].forward->backward = x;else // 否則呢,就需要更新 skiplist 的 tail 字段啦!zsl->tail = x;zsl->length++; // skiplist 中節點的數量加 1 return x; // 返回新插入的節點
}
-
我們來看看這兩條語句是怎么更新新節點每一層的
span和 前驅節點每一層的span的哈!如下圖,我們在一個skiplist中插入一個新的節點,其中節點 1 并不表示skiplist的頭節點哈! (下面的這個圖用來舉例似乎有點特殊,更加一般的情況需要單獨想想啦!)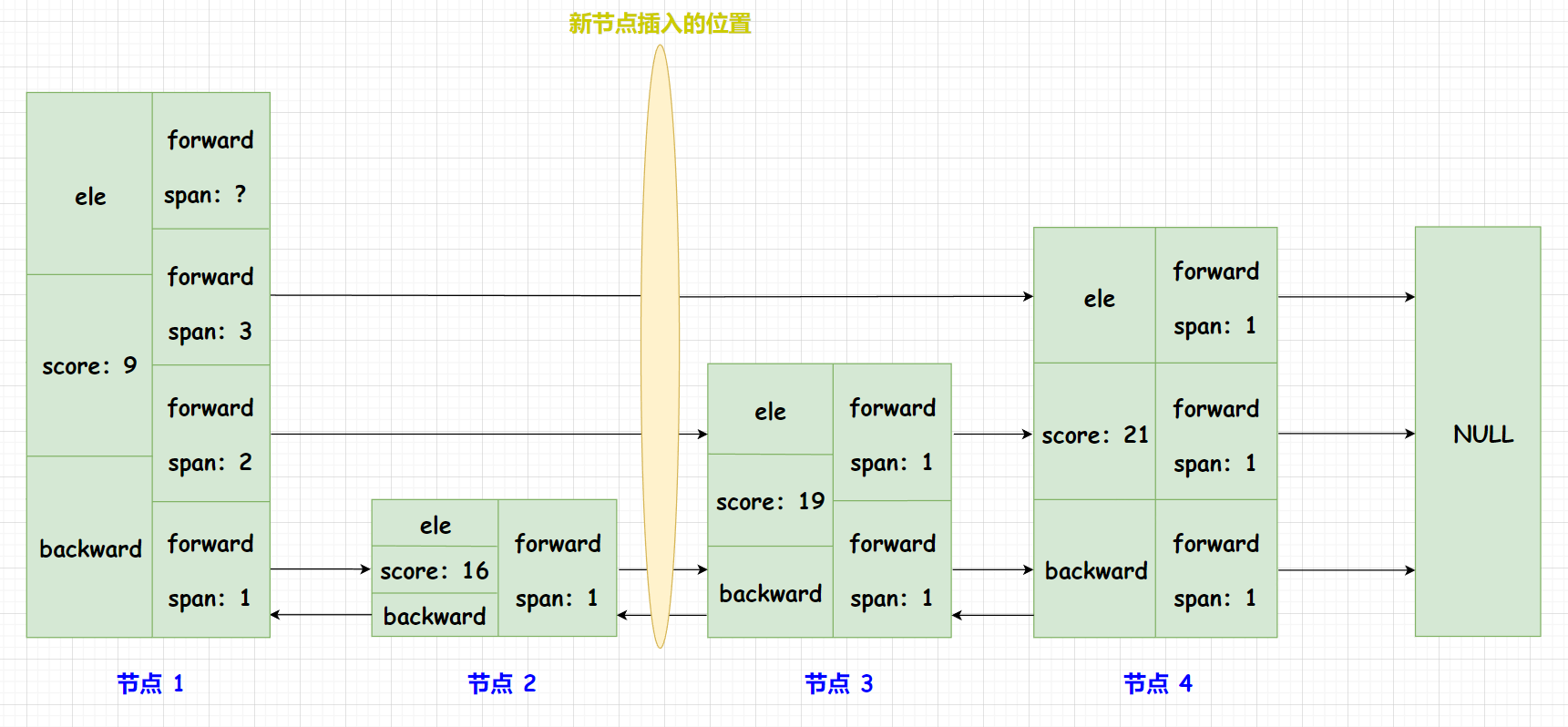
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]):rank[0]:表示第 0 層前驅節點的索引,也就是節點 2 及其之前所有有效節點的個數 (頭結點不存數據,不是有效節點)。rank[i]:表示第 i 層前驅節點的索引。例如:當我們更新第一層的span時,其為rank[1],如圖表示節點 1 及其之前所有有效節點的個數。(rank[0] - rank[i])表示的是新插入節點當前層的前驅節點到新插入節點之間的節點數量 (不包括前驅節點)。update[i]->level[i].span:表示的是新插入節點當前層的前驅節點到當前層后驅節點跨越的節點數量。x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]):就能計算出新插入節點到當前層的后驅節點跨越的節點數量啦!
update[i]->level[i].span = (rank[0] - rank[i]) + 1;:(rank[0] - rank[i])表示的是新插入節點當前層的前驅節點到新插入節點之間的節點數量 (不包括前驅節點)。加上新插入的節點,自然就是前驅節點的span啦!
zslRandomLevel
- 函數功能:生成一個隨機的節點層數
- 參數:無。
- 返回值:生成的隨機層數。
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */int zslRandomLevel(void) {int level = 1;// [1](見注解1)while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; // 如果生成的節點層數小于 32 直接返回即可,否則直接返回 32
}
-
這個代碼塊就是生成隨機層數的核心代碼啦!
(random()&0xFFFF):相當于random() % 0x010000只是位運算的速度比取模運算更快!經過取模運算該表達式計算出的值就會在區間 [ 0 , 0 x F F F F ] \rm [0, 0xFFFF] [0,0xFFFF] 隨機分布。(ZSKIPLIST_P * 0xFFFF):ZSKIPLIST_P是一個固定的概率,Redis中取的是 0.25。(random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF):根據計算結果可得,該表達式為true的概率只有 0.25。
根據這個代碼塊的邏輯,我們可以輕易計算生成 x 層節點的概率。設
ZSKIPLIST_P為p,而非一個具體的數字。x == 1時:概率為 ( 1 ? p ) (1-p) (1?p)。x == 2時:概率為 p × ( 1 ? p ) p \times (1-p) p×(1?p)。x == 3時:概率為 p 2 × ( 1 ? p ) p^2 \times (1-p) p2×(1?p)。- ···
- 生成
x層節點的概率為 p x ? 1 × ( 1 ? p ) p^{x-1} \times (1-p) px?1×(1?p)。
從概率上來講,
Redis的skiplist可以看成是一顆四叉樹。
x 層與? x ? 1 層出現概率的比值為: p x ? 1 × ( 1 ? p ) p x ? 2 × ( 1 ? p ) = p = 0.25 x \space 層與\space x - 1\space層出現概率的比值為:\frac{p^{x-1} \times (1-p)}{p^{x-2} \times (1-p)} = p = 0.25 x?層與?x?1?層出現概率的比值為:px?2×(1?p)px?1×(1?p)?=p=0.25
其他的函數這里就不做分析了,跳表的函數實現起來還是比較簡單的!
紅黑樹也常用于維護有序數據,為什么 Redis 使用 skiplist 而不使用紅黑樹呢?
- 實現和維護的簡單性:跳表的實現和維護相對較為簡單。跳表通過多層級鏈表實現,代碼邏輯較為直觀,插入、刪除和查找操作相對容易理解和實現。而紅黑樹是一種自平衡二叉搜索樹,涉及復雜的旋轉操作和顏色屬性的維護,代碼實現和調試相對更為復雜。
- 平均性能:雖然紅黑樹在最壞情況下可以保證 O(log N) 的時間復雜度,但在平均情況下,跳表的性能也能達到 O(log N)。對于 Redis 的典型工作負載和數據訪問模式,跳表的平均性能表現足夠好,并且實現更為簡單,因此成為一個合理的選擇。
- 順序操作的性能:跳表在處理范圍查詢和順序遍歷時,性能優于紅黑樹。跳表的結構使得它在多層級上進行線性掃描更加高效,對于需要大量范圍查詢的應用場景(如有序集合的范圍操作),跳表提供了較好的性能支持。
- 內存使用:跳表在內存使用上較為靈活,可以通過調整跳表的層數來控制內存的使用量。雖然紅黑樹的內存使用較為緊湊,但對于 Redis 來說,跳表的靈活性在某些場景下更具優勢。
- 代碼復雜性和調試:跳表的代碼實現相對簡潔,對于開源項目和社區開發來說,更易于理解、維護和調試。簡潔的代碼邏輯也減少了潛在的bug和維護成本。
- 歷史因素:跳表的引入與 Redis 的歷史開發背景有關。最初,Redis 的開發者選擇了跳表,之后隨著 Redis 的演進和成熟,跳表的表現一直足夠令人滿意,因此沒有必要更換為紅黑樹。
編碼
有序集合類型有 OBJ_ENCODING_ZIPLIST 和 OBJ_ENCODING_SKIPLIST 兩種編碼,使用 ziplist、skiplist 存儲數據。
使用 OBJ_ENCODING_ZIPLIST 編碼需滿足以下條件:
- 有序集合元素數量小于或等于
serverzset_max_ziplist_entries,該值可通過zset-max-ziplist-entries配置項調整。 - 有序集合所有元素長度都小于或于
server.zset_max_ziplist_value,該值可通過zset-max-ziplist-value配置項調整。

總結:
Redis設計了intset數據結構,專門用來保存整數集合數據。Redis使用skiplist結構存儲有序集合數據,skiplist通過概率平衡實現近似平衡p叉樹的數據存取效率。- 集合類型的編碼格式可以為
OBJ_ENCODING HT、OBJ ENCODING INTSET。 - 有序集合的編碼格式可以為
OBJ ENCODING ZIPLIST、OBJ ENCODING SKIPLIST。

)
)


】繼承)




)


容器(4)ApplicationContextAware)





