面對 Kafka 規模快速增長帶來的成本、效率和穩定性挑戰時,小紅書大數據存儲團隊采取云原生架構實踐:通過引入冷熱數據分層存儲、容器化技術以及自研的負載均衡服務「Balance Control」,成功實現了集群存儲成本的顯著降低、分鐘級的集群彈性遷移、高性能的數據訪問策略和自動化的資源調度。
這些技術革新不僅極大提升了 Kafka 集群的運維效率,還為小紅書業務帶來了更優質的服務體驗,同時為未來在存算分離、多活容災等方向的進一步優化奠定了基礎。

1.1 小紅書 Kafka 的發展現狀
小紅書 Kafka 集群規模伴隨著公司業務的蓬勃發展而顯著擴張。目前,集群的峰值吞吐量已經達到 TB 級別,并且隨著 AI 大模型和大數據技術的持續擴展,數據量仍在快速增長。
盡管經典的 Apache Kafka 架構在提供高吞吐、高性能數據傳輸方面表現出色,但也逐漸暴露出了一些弊端。一方面,基于多副本和云盤/SSD 的模式,Apache Kafka 的存儲成本居高不下,難以滿足業務長期存儲數據的需要;另一方面,數據與計算節點之前的強綁定關系,嚴重阻礙了集群的擴縮容效率,在彈性和調度能力方面受到了很大的挑戰。
1.2 面臨的問題

隨著小紅書 Kafka 集群規模的持續擴大,一系列挑戰也隨之而來,涉及成本、能效、運維和系統穩定性等多個方面:
-
成本:
-
存儲成本昂貴:Kafka 的存儲成本較高,按當前內部機器規格配比,在充分利用帶寬的情況下,數據存儲的生命周期非常有限。
-
算力資源浪費:Kafka 的性能瓶頸主要集中在 IO 操作上,存在大量的 CPU 資源處于閑置狀態。加之現有的虛擬機部署方式在資源共享和隔離方面表現不佳,進一步限制了 CPU 資源的有效分配。
-
-
效率:
-
集群運維耗時長:因磁盤和節點綁定,Kafka 集群的擴縮容需要搬遷海量數據,這不僅速度緩慢,而且耗時可能從數天到數周不等。
-
調度能力弱:因虛機部署,缺乏靈活的資源調度能力,一旦壞機,補貨效率低。
-
-
穩定性:
-
應急能力差:緩慢的擴縮容速度導致性能指標在高負載下顯著下降,請求響應時間可能延長至正常情況的兩倍,影響整體服務質量。
-
追趕讀期間穩定性受損:在追趕讀操作期間,系統資源的大量消耗會使得資源使用率飆升,從而影響到實時讀寫任務的穩定性
-
綜上所述,Kafka 集群面臨的主要痛點可歸納為兩個核心問題:存算一體化架構的局限性,以及虛擬機部署方式帶來的運維和資源調度難題。解決這些問題,對于提升 Kafka 集群的整體性能和運維效率,具有重要意義。
1.3 解決方案
1.3.1 如何解決“存算一體化”帶來的問題?
為了解決存算一體化架構弊端,我們需要引入「Cloud-Native」彈性架構模式,來解耦存儲與計算,下述為方案對比:
1)自研存算分離(on ObjectStore):

該方案通過對象存儲作為統一的存儲基礎,實現了計算層與數據綁定關系的解耦。存儲層利用對象存儲的糾刪碼技術和規模經濟效應,能同時獲得秒級彈性與成本兩大收益,是較為理想的解決方案。
然而,對象存儲本身延遲較高,想要達到整體較高的性能,需要有獨立的讀寫加速層配合,這一部分也需要考慮彈性化的架構設計。整體架構復雜度較高,因此方案研發周期會比較長。
2)冷熱分層存儲(on ObjectStore):
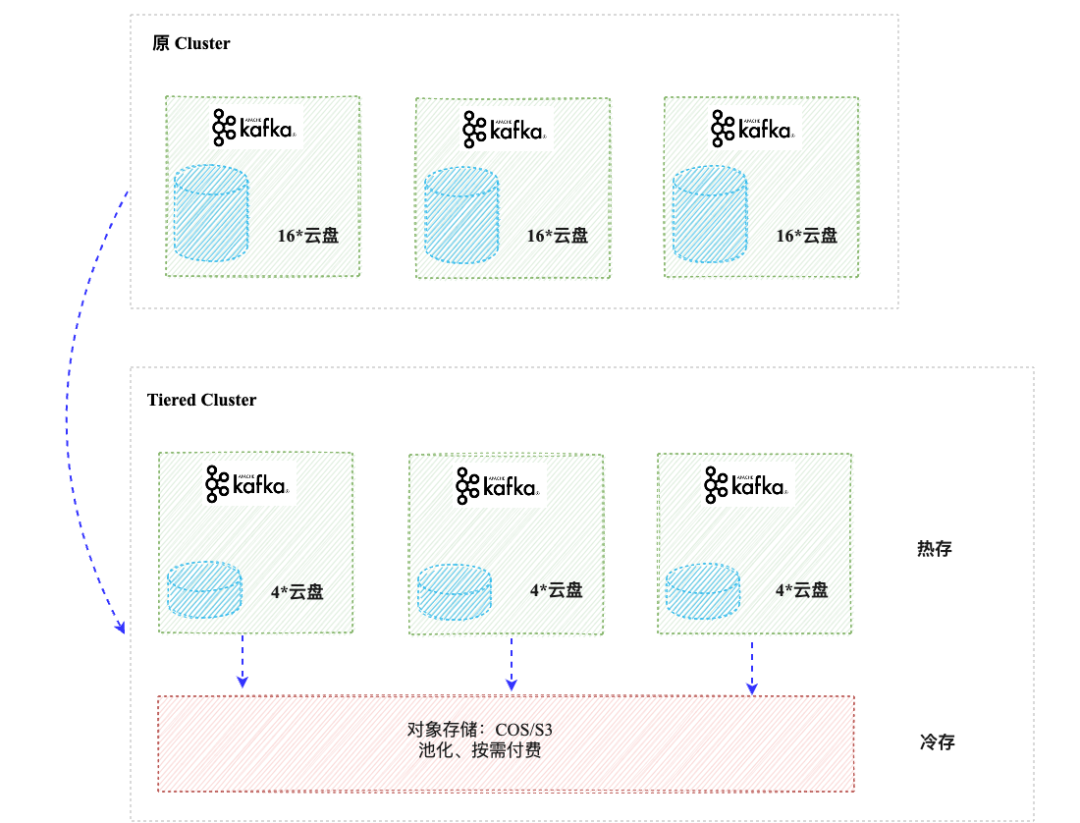
冷熱分層的概念,即為本地僅保留少量的熱數據,將大部分冷數據卸載到較為便宜的對象存儲中,以實現成本節約。Kafka 和其他 MQ 類社區,近年來陸續提出該概念并進行發展。
此架構不改變數據核心的寫入流程和高可用性(HA)機制,而是異步卸載數據以減少對核心架構的改動,實現難度較低。不過弊端也正是因為沒有觸動核心的副本機制,數據與計算節點之間仍然存在部分的耦合,在彈性能力方面稍遜一籌。
3)Apache Pulsar

Apache Pulsar 是近年來非常火熱的一款云原生消息引擎,它天生支持存算分離架構,具備快速的彈性擴展特性,同樣是一個選擇。不過其底下的存儲底座 Bookkeeper 仍然基于磁盤存儲,單節點受限于磁盤容量,在存儲成本上沒有明顯收益(但 Pulsar 近期也引入了分層存儲能力)。此外,考慮到歷史大量的存量作業,轉向 Pulsar 可能面臨較高的推廣難度和替換周期,眼下難以快速拿到收益。
在當前階段,“成本”是我們最關心的問題。如何獲得大量成本節省?如何縮短收益獲取周期?都是需要核心考慮的因素。在經過大量對比和取舍后,「分層存儲」架構依靠其低成本、中等彈性、短落地周期的特點,成為了我們當下的最佳選擇。
與社區版本相比,小紅書分層架構經過了完全的重新設計,解決了原有方案的多項問題,并顯著提升了數據遷移速度和冷數據讀取性能。在新架構上線六個月內,我們已完成線上 80% 的集群升級覆蓋,充分地獲得了新架構帶來的各項收益。
1.3.2 如何解決“虛機部署”帶來的問題?
為了解決虛機部署帶來的問題,關鍵在于提升混部與調度能力、優化算力資源的使用、以及增強自動化運維的水平。以下是幾種方案的對比分析:

綜合考慮,采用小紅書容器底座結合 PaaS 平臺托管的新型容器化架構,不僅能夠平滑地將 Kafka 遷移至云端,還能顯著提升算力資源的利用率,加強運維自動化。

2.1 整體架構
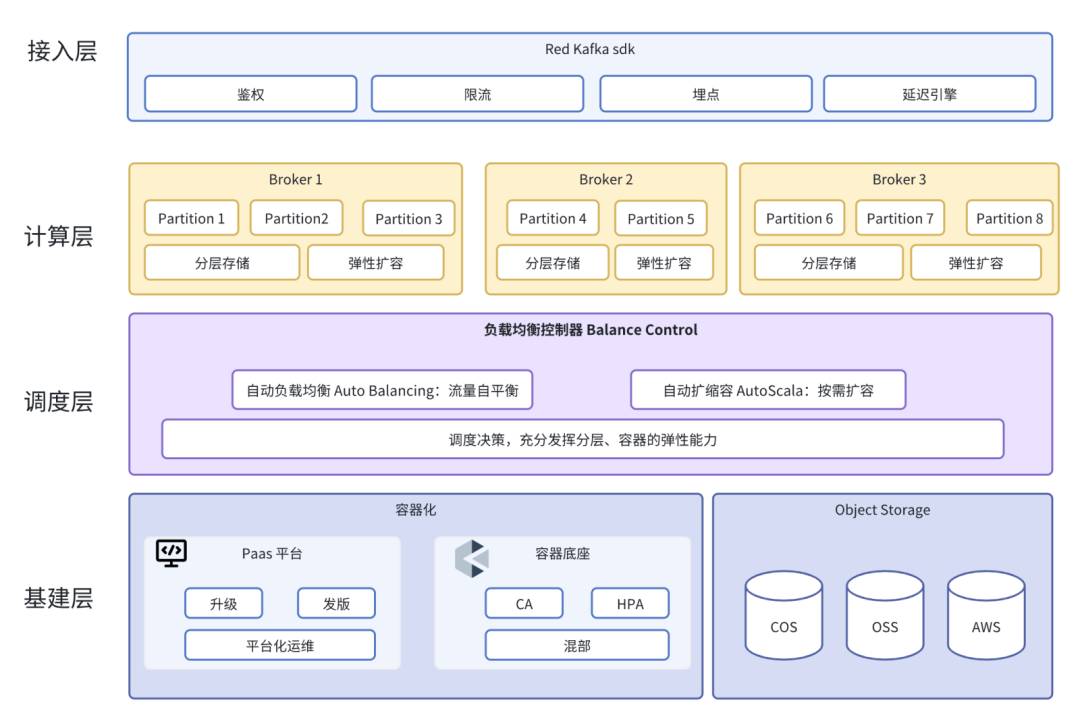
小紅書 Kafka 云原生架構共分為四層:
-
接入層:小紅書 Kafka 特色 SDK,提供鑒權、限流、服務發現等豐富功能,實現更加靈活和安全的數據流管理
-
計算層:Kafka Broker 基于「分層存儲」技術,實現本地數據“弱狀態化”,有效地解決了系統的彈性問題,保障系統的穩定性和可擴展性
-
調度層:負載均衡調度器向北可均衡 Broker 間流量負載,向南結合容器實現自動化彈性擴縮容,保障系統能夠根據實際需求動態調整資源,實現 “彈性伸縮、按量付費”
-
基建層:容器和對象存儲底座,為整個系統提供了強大的 PaaS 平臺化運維管理調度能力和低成本無限存儲能力
2.2 分層存儲
分層存儲作為 Kafka 云原生化的核心能力,提供成本優化、消費隔離、彈性擴展等多重優勢。其整體架構如下圖所示。基本原理是基于冷熱分層,即將近實時的熱數據保留在高性能云盤中,而將冷數據下沉至低成本、可靠性極高的對象存儲中。
對象存儲具有無限擴展、低成本、可靠性極高的特點。通過利用對象存儲來存儲數據,我們能夠從根本上解決不斷增長的數據存儲需求,擺脫了傳統數據存儲所帶來的諸多煩惱。對象存儲的架構設計理念,使其在處理大規模數據時表現出色,同時確保了數據的高可用性和安全性,為 Kafka 架構的云原生化提供了強大的支撐。

2.2.1 存儲成本優化
在大數據場景下,業務方經常需要回溯過去多天的數據,以進行各種分析、回溯和審計等操作。然而,傳統的基于云盤的 Kafka 存儲解決方案不僅成本高昂,而且在存儲能力上也存在限制,只能滿足短期數據的存儲需求,這對于需要長期數據保留的業務場景構成了重大挑戰。
為了突破這一瓶頸,我們采用基于對象存儲的分層存儲架構。這一創新舉措顯著降低了存儲成本并提升了數據存儲的靈活性。對象存儲的低成本特性,結合其出色的擴展能力,使得小紅書 Kafka 能夠經濟高效地存儲大量數據,同時保證了數據的高可靠性和安全性。
在實施分層存儲架構的過程中,我們采取了以下策略:
-
冷數據存儲:將不常訪問的冷數據遷移到成本更低的對象存儲中,從而大幅度減少存儲開支。
-
熱數據存儲:對于頻繁訪問的熱數據,繼續使用性能較高的云盤存儲(EBS),但通過優化存儲策略,將存儲容量減少了75%。
通過這種新型的存儲架構,小紅書 Kafka 實現了存儲成本的大幅度降低——最高可達 60%。此外,這種架構還允許 Topic 的存儲時間從原來的 1 天延長至 7 天或更久,極大地增強了業務數據的回溯能力,為業務數據驅動決策提供更加堅實的基礎。
2.2.2 分鐘級彈性遷移
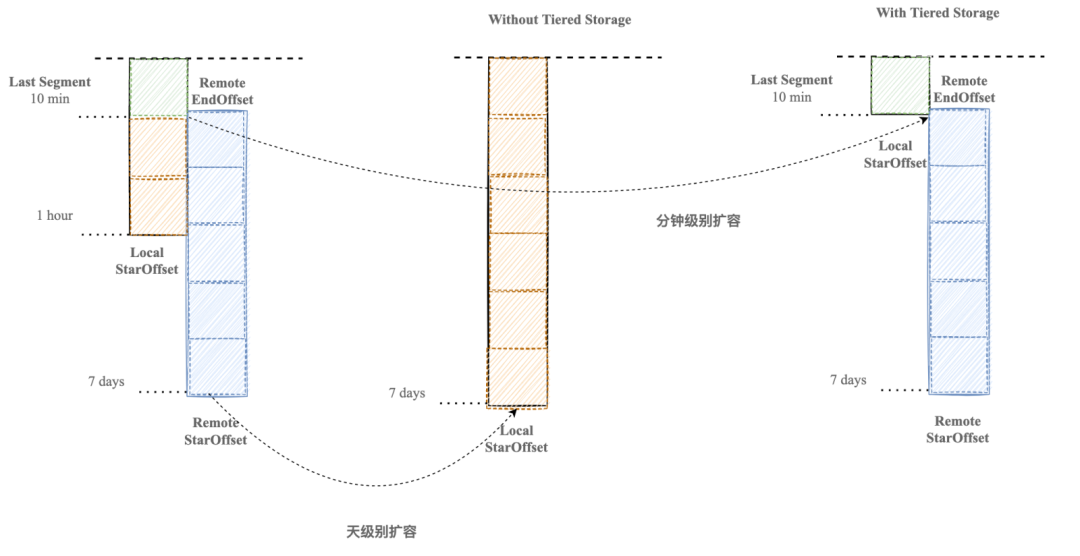
在 Kafka 原生架構中,集群擴容是一個復雜且耗時的過程。由于冷數據存儲在磁盤上,擴容時需要搬遷海量數據,這不僅會導致磁盤和網絡 IO 的負載達到極限,也會對集群的穩定性造成影響。
我們引入了分層存儲機制后,Topic 的所有副本可以共享同一份冷數據。這意味著對于 Topic 的新副本,在集群擴容時不再需要復制 Leader 本地的所有熱數據,而只需拷貝遠端尚未擁有的部分,通常是 Leader 本地存儲的最后一個 segment。
這種優化顯著減少了遷移數據的量,從而將 Topic 遷移的時間從天級別縮短到分鐘級別。在實際應用場景中,即使是對于具有 10GB/s 吞吐量的 Topic,在流量高峰期的遷移過程也僅需 5 分鐘即可完成。
2.2.3 高性能緩存策略
引入對象存儲后,雖然解決了存儲成本和彈性等問題,但也面臨了一些挑戰,主要包括訪問速度和延遲等方面,具體表現為:
-
訪問速度:?對象存儲的總吞吐上限理論只受帶寬限制,但單線程訪問速度較低,遠遠低于傳統磁盤存儲。
-
延遲:?目前對象存儲主要通過 HTTP 協議進行訪問,因此存在較高的延遲,包括建立連接等操作的延遲可達到 20 毫秒級別,對于部分小文件訪問極不友好。
針對這些問題,我們采取了以下優化策略:
-
批量讀取:?以 8MB 對齊的方式讀取 Segment 數據,減少訪問次數,從而提升數據讀取的效率。
-
緩存預加載:?結合數據訪問的局部性原理和消息隊列的順序讀特性,實現了并發的預讀機制,以提高數據的訪問速度和響應性。同時,通過內存隔離技術,避免了 pagecache 被污染的問題。
這些策略的實施帶來了顯著的性能提升:
-
高緩存命中率:?緩存命中率達到了 99%,有效地提高了數據訪問的效率和速度。
-
性能提升:冷數據讀取性能相比開源架構提升了 30%,這在大規模數據處理場景中尤為重要。

2.3 容器化
下圖為小紅書 Kafka 容器化的整體架構:
-
PaaS 能力托管:通過小紅書容器化調度 PaaS 平臺來托管 Kafka 集群,這不僅簡化了部署和運維流程,降低了運維成本,而且通過圖形化界面實現了集群版本和配置的直觀管理,即所謂的「白屏化操作」。
-
服務狀態管理:為了保證有狀態應用服務的連續性和狀態的一致性,我們采用 DupicateSet(StatefulSet) 來管理 Kafka 服務。
-
異常保護機制:
-
基于 Supervisord 的進程監控:在容器內部,Supervisord 作為主要的進程管理工具,監控 Kafka 進程。一旦 Kafka 進程異常退出,Supervisord 能夠迅速重啟進程,避免了容器級別的重建,從而減少了服務中斷時間。
-
快速修復(HotFix):當基礎環境如數據存儲出現問題時,業務團隊可以直接進入容器進行快速修復,這種即時的干預能力大大提高了系統的穩定性和恢復速度。
-
集群狀態的刪除保護:我們實現了基于 Kafka 集群狀態的刪除防護機制。當集群中掉隊實例的數量超過預設閾值時,通過 Webhook 技術自動拒絕所有可能惡化集群狀態的操作請求,從而保護集群不受進一步損害。
-

2.3.1 狀態管理
在 Kubernetes 環境中部署有狀態服務如 Kafka 時,確保其狀態的持久性和可靠性是至關重要的。
Kafka 的狀態主要包括拓撲狀態和存儲狀態,以下是對這兩部分狀態的管理策略:
-
拓撲狀態:拓撲狀態涉及 Pod 的網絡和身份標識,確保每個 Pod 具有固定的標識和訪問方式。我們通過容器底座提供的能力保障了 Pod IP 不變。

-
存儲狀態:存儲狀態包括云盤數據、日志數據和配置文件等,這些數據需要在 Pod 遷移、重啟或升級時保持不變。
-
持久卷(PV)和持久卷聲明(PVC):使用 DupicateSet 使用,為每個 Pod 分配專用的存儲資源,確保存儲狀態的持久性和一致性。
-
配置管理:使用 ConfigMap 和環境變量來管理 Kafka 的配置,確保 Pod 即使重啟,配置也能保持不變。
-
日志管理:將日志目錄放置在持久化數據卷中,保障日志數據在 Pod 重啟或遷移時不會丟失。
-
2.3.2 離線混部
在上云之前,Kafka 作為存儲產品,面臨著單機 CPU 能效低下的問題,大約只有 10% 的效率,這主要是由于夜間流量低谷以及 IO-bound 特性所致。在這種情況下,往往存在大量的閑置 CPU 資源,導致資源利用率不高。
上云后通過容器提供的混部能力,我們可以將離線業務調度至 Kafka Kubernetes 機器池中,填平 CPU 低谷,從而保證全天利用率達到一個較高的水平。這種整合策略顯著提升了資源的全天利用率,上云后的能效利用率提高到了 40% 以上,遠高于之前的水平。
利用容器技術的混部能力,使得我們能夠更加靈活地管理和調度資源,根據實際情況對資源進行動態分配和利用,從而最大限度地提高了系統的整體性能和資源利用率。
2.3.3 CA 資源調度
除了上述提及能力外,容器技術還為我們帶來了資源層面的彈性調度能力,其中 Cluster Autoscaler(CA)是一項關鍵技術。
在未采用 Cluster Autoscaler 的傳統模式下,系統工程師(SRE)需要手動執行服務器的啟動和關閉操作,這不僅效率低下,而且在面對緊急的擴容需求時,現有的流程顯得繁瑣且響應遲緩,無法及時適應業務需求的波動。
引入 Cluster Autoscaler 之后,這一狀況得到了根本性的改善。CA 能夠自動管理業務集群的擴縮容流程,以緩沖區(Buffer)的形式智能地調整資源分配。它通過實時監控集群的負載情況,動態地增加或減少節點數量,實現了快速且精準的資源彈性調度。這種自動化的調度機制不僅提升了系統的適應性和穩定性,而且顯著降低了運維團隊的工作負擔,確保了業務的持續穩定運行。
2.4 彈性調度
在線上部署的 Apache Kafka 集群中,流量波動、Topic 的增減以及 Broker 的啟動與關閉是常態。這些動態變化可能導致集群中節點的流量分布不均衡,進而引起資源浪費和影響業務的穩定性。為了解決這一問題,需要對 Topic 的分區進行主動調整,以實現流量和數據的均衡分配。
原生 Apache Kafka 由于磁盤上存儲大量歷史數據,因此在進行均衡調度時會打滿磁盤 IO 和網絡帶寬,從而影響實時業務的正常運行,導致集群負載均衡較為困難。
相比之下,分層的彈性架構則為負載均衡提供了可能。這種架構設計使得在進行負載均衡調度時可以避免過多的 IO 壓力,從而減少對實時業務的影響,使得負載均衡的調整更加靈活和高效。
因此,除了分層和容器兩大關鍵 『彈性』 技術,我們還自研了負載均衡服務 「Balance Control」,其能夠充分利用分層和容器的軟硬件彈性能力,實現持續數據平衡和自動彈性擴縮容,使得集群能夠更加靈活地應對流量波動和業務變化,從而保障了系統的穩定性和可靠性。
2.4.1 持續數據自平衡(Auto-Balancing)
Balance Control 采用多目標優化算法來實現資源分配的最優化。其能夠綜合考慮 Topic 副本、網絡帶寬、磁盤存儲、計算資源等多種因素,自動調整 Partition 分配,以達到最佳的資源負載平衡。整體自平衡流程如下:
-
數據采集:Kafka 側 Metrics Reporter 監聽 Kafka 內置的所有指標信息,并定期對感興趣的指標(如網絡進出口流量、CPU 利用率等)進行采樣,并上報指標
-
指標聚合:收集的指標用于生成集群狀態快照 ClusterModel,包括 Broker 狀態、Broker 資源容量、各 Broker 管理的 Topic-Partition 流量信息等
-
調度決策自平衡:調度決策器定期獲取集群狀態模型的快照,并根據各個 Broker 的容量和負載信息,識別出流量過高或過低的 Broker。隨后,它會嘗試移動或交換分區,以完成流量的重新平衡。

2.4.2 自動彈性擴縮容(Auto-Scaling)
原生 Kafka 擴容需要搬遷海量數據,耗時通常為小時甚至天級,幾乎無法做到按需擴縮容。為了維持集群的穩定性,運維團隊不得不提前規劃資源,以應對可能的流量高峰,這種做法往往導致資源的浪費和效率的降低。
云原生時代,通過借助分層和容器的軟硬件彈性能力,Balance Control 可以在分鐘級自動完成集群的原地擴縮容和流量的重新調度,以適應業務負載的變化,做到 「彈性伸縮、按量付費」 的目標。這一關鍵能力我們稱之為 AutoScala。
AutoScala:實時監控 Kafka 集群的負載,并根據預設的策略自動調整集群規模。例如,當集群負載超過某個閾值(如 70%)并保持一段時間時,系統會自動增加集群規模;從而實現快速、高效的集群擴縮容,優化資源利用率。
整體流程如下:
-
負載監控:Kubernetes 的 Horizontal Pod Autoscaler(HPA)組件根據預設的策略(如定時、資源水位等)來判斷是否需要擴容,并相應地調整集群規模配置。
-
自動負載均衡:當 Balance Control 探測到新加入的 Broker,分鐘級完成流量調度平衡。


總體來看,云原生彈性架構為小紅書 Kafka 帶來了巨大的成本收益和運維效率提升。從落地效果上看,我們實現了 60% 的存儲成本節省和 10 倍的擴縮容運維效率提升,并成功實現了「彈性伸縮、按量付費」的商品化模式。
此外,我們正不斷探索和優化云原生消息引擎的能力,以期提供更穩定和高效的服務。未來,我們計劃持續研究存算分離技術和多活容災方案,以實現極致的系統可擴展性和穩定性,滿足業務日益增長的服務需求。
隨著技術的不斷演進,我們將不斷引入新的技術能力和創新方案,為業務提供更加卓越的消息引擎服務,期待您加入團隊!

-
六娃(張億皓)
小紅書大數據存儲架構團隊負責人,現負責小紅書流存儲引擎 Kafka、分布式文件加速系統等領域建設。
-
劍塵(黃章衡)
小紅書消息引擎內核研發專家,Apache RocketMQ Committer & SOFASTACK SOFAJRaft Committer,現負責小紅書 Kafka 分層存儲、負載均衡、存算分離等技術領域建設。
-
阿坎(焦南)
小紅書消息引擎內核研發專家,現負責小紅書 Kafka 流批一體、容器化等生態探索和建設。

小紅書-大數據存儲研發專家(上海/北京)
工作職責:
負責大數據存儲產品(流存儲、文件/緩存系統)的研發與優化工作,構建一流的數據基礎設施,滿足大數據和 AI 對于數據基礎設施不斷增長的需求。
新一代 Kafka 云原生架構的研發落地工作,結合對象存儲、容器化與流批一體等技術,通過存算分離架構大幅提升彈性伸縮能力,在成本與效率方面取得新的收益
自研分布式文件加速系統,提升大數據/AI 引擎的 IO 性能和彈性能力,在大模型時代進一步拉近計算與存儲距離,助力各數據引擎進一步云原生,提升用戶體驗,實現降本增效。
崗位要求:
本科及以上學歷,3 年以上大數據存儲研發經驗
熟悉主流的大數據存儲產品 (Kafka/HDFS/Alluxio/JuiceFS/HBase 等),有文件系統研發經驗或者開源社區 Committer 尤佳;
優秀的設計與編碼能力,針對業務需求與問題,可快速設計與實現解決方案;
具備良好的溝通和團隊協作能力,做事主動積極負責任,有技術熱情和激情面對挑戰。
歡迎感興趣的同學發送簡歷至 REDtech@xiaohongshu.com,并抄送至 yihaozhang@xiaohongshu.com
![[圖解]SysML和EA建模住宅安全系統-07 to be塊定義圖](http://pic.xiahunao.cn/[圖解]SysML和EA建模住宅安全系統-07 to be塊定義圖)











2023年05月真題C語言軟件編程等級考試三級(含詳細解析答案))






)