1.Innodb數據存儲
innodb如今能夠做到mysql的默認數據存儲引擎,肯定有著其好處的,那么innodb有什么好處呢?
1. 當意外斷電或者重啟, InnoDB 能夠做到奔潰恢復,撤銷沒有提交的數據2.InnoDB 存儲引擎維護自己的緩沖池,在訪問數據時將表和索引數據緩存到主存中。經常使用的數據直接從內存中處理。這種緩存適用于許多類型的信息,并加快了處理速度。在專用數據庫服務器上,高達80% 的物理內存通常分配給緩沖池3.where 、 groupby 、 orderBy 的自動優化、基于索引。4. 插入、更新和刪除是通過一種稱為更改緩沖的自動機制進行優化的
?innodb存儲引擎是作為數據存儲的,那么肯定是要落盤的,那么落盤落到哪里?innodb又是如何管理這些數據的呢?
在Innodb中會有一個表空間的概念,又可以分為很多的類型,比如系統表空間、通用表空間、獨立表空間等,我們的數據可以有選擇的決定存入到哪個表空間中,關于表空間的具體介紹可以參考官網,這里不再介紹,MySQL :: MySQL 8.0 Reference Manual :: 17.6.3 Tablespaces
那么表空間又是如何管理的呢? 每個表空間都是由大小相同的page頁來組成的,默認page頁是16kb,也可以根據innodb_page_size來設定頁的大小
在表空間中從上到下會依次劃分為segment(段)、extent(區)、page(頁)、rows(行)
segment:?段是表空間的分區,一個表空間中,會有多個段組成,常見的短有數據段、索引段、8.0之前有回滾段
extent:?區來管理頁,當頁的大小在16K以下,一個區的大小是1M,如果32K是2M,64K則為4M。后面磁盤釋放分配都是以區為單位. 所以,一個extent下最少可以存儲64個page頁
page:對于4KB、8KB、16KB和32KB的innodb_page_size設置,最大行長度略小于數據庫頁面大小的一半。例如,對于默認的16KB InnoDB頁面大小,最大行長度略小于8KB。對于64KB的innodb_page_size設置,最大行長度略小于16KB
rows:表的行格式決定了其行的物理存儲方式,這反過來又會影響查詢和 DML 操作的性能,為什么影響 我們在講索引的時候會講到
?行存儲如果超過,那么該頁就只存儲指針,其它內容交由外部溢出頁來存儲
行存儲分為四種存儲格式,不同的行格式,存儲方式、空間性能都不一樣
REDUNDANT:? 冗余行格式,主要是舊版本 mysql 的兼容,數據和行索引信息分開存儲,某些查詢操作會快,但是需要額外的空間,所以是之前老版本的格式設計COMPACT:? 減少了存儲行間,官網說大約 20% ,但是增加了cpu 的負荷。導致一些查詢的性能問題DYNAMIC: ?動態行格式 該行格式允許長度可變,所以會根據情況來決定是否需要更多空間,5.7 后的默認行格式COMPRESSED:? 壓縮行格式 對 COMPACT 進行了壓縮,減少了存儲空間使用,比如 text 長文本 會進行壓縮,但是檢索的時候,必須進行解壓,犧牲了 cpu
mysql默認的行格式是dynamic
也可以在創建表的時候定義表的行格式
CREATE TABLE t1 (c1 INT) ROW_FORMAT=DYNAMIC;?2.Innodb內存加載及管理
我們已經知道,我們的數據最終是會落盤到磁盤中的,那么假如我們每次檢索都去磁盤獲取,明顯性能會比較慢。所以Innodb為了性能的優化,采用了內存緩存機制,在內存中緩存相應的數據。這個內存區間叫做BufferPool.
緩沖池是主內存中的一個區域,在innodb訪問時緩存表和索引數據。緩沖池允許直接從內存訪問頻繁使用的數據,從而加快處理速度
SELECT @@innodb_buffer_pool_size; -- 默認134217728字節/1024/1024 128M也可以設置bufferpool的大小
mysql> SET GLOBAL innodb_buffer_pool_size=402653184;既然有了這個內存緩沖區,那么這個內存與磁盤數據是怎么交互的呢?
2.1內存與磁盤數據交互機制
該交互機制采用的是頁加載機制,這是為什么呢?
1. 如果用行交互,那么假如我查詢 200 條數據,那么 200 條數據都不在我們內存的話,需要跟磁盤交互200 次,但是 page 可能只有 1.2 個 page 頁2. 也不會用 extent 區來交互,因為一個 extent 包含 64 個頁。可能我只需要查一條數據,但是會加載64 個頁到內存,導致內存浪費。
處于內存的利用率與性能考慮,Innodb選擇了page頁
那么整體流程是什么樣子的呢?
1. 假如一條查詢語句 查詢出的數據有 2.3.4.5.6.7 6 條數據2. 去 bufferpool 中查看 2.3.4.5.6.7 所在的 page 頁是否存在3. 如果存在,直接返回4. 如果不存在,根據 2.3.4.5.6.7 的數據所在的 page 頁,去磁盤加載,加載完后保存到內存5. 下次查詢 id=5, 由于在內存中已經存在,直接返回
?另外,mysql還提供了一種預讀機制,我們每次讀取數據的時候,會將對應的page頁加載到內存,預讀機制就是,我就算沒讀到,也能提前把一些可能讀到的數據加載到內存。
預讀機制:?MySQL :: MySQL 8.0 Reference Manual :: 17.8.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)
?預讀請求是一種i/o請求,用于在緩沖池中異步預取多個頁面,在請求某些頁面時,預計即將需要extent的其它頁面。那么這個預計的頁面是怎么知道的呢?主要通過兩種預讀算法
線性預讀:按照訪問順序的頁來執行預加載 某個區里面的頁面有多少個頁按順序訪問了,那么就會預加載這個區里面所有的頁。具體多少個頁被順序訪問,具體配置為innodb_read_ahead_threshold
隨機預讀:根據緩存池中已有的頁來預加載,如果在緩沖池中找到了來自同一個區連續的13個頁面,InnoDB會異步發出一個請求來預取該區剩余的頁面。開關控制:innodb_random_read_ahead
?2.2BufferPool內存管理
假如我們查詢到的頁或者與加載的頁都加載到我們的bufferpool,那么肯定要進行管理,因為我們的bufferpool內存也是有限的,不能無休無止的往里面添加。此時,就可以采用淘汰策略。(還記得redis中的淘汰策略嗎)
歷史總是驚人的相似,Mysql也是采用LRU算法去進行page頁淘汰的,只不過實現方式稍有變化。
? ? ? ?? InnoDB 有預讀機制,只是猜測會用,但是不一定真的會用到,那么假如如 果用傳統的 LRU 實現,那么我們會發現,會預加載很多頁到 bufferpool ,但 是可能用戶根本不適用,但是又淘汰不了,既占用了內存,也沒有得到很 大的性能提升!
?針對Innodb的特殊情況,采用LRU的變種
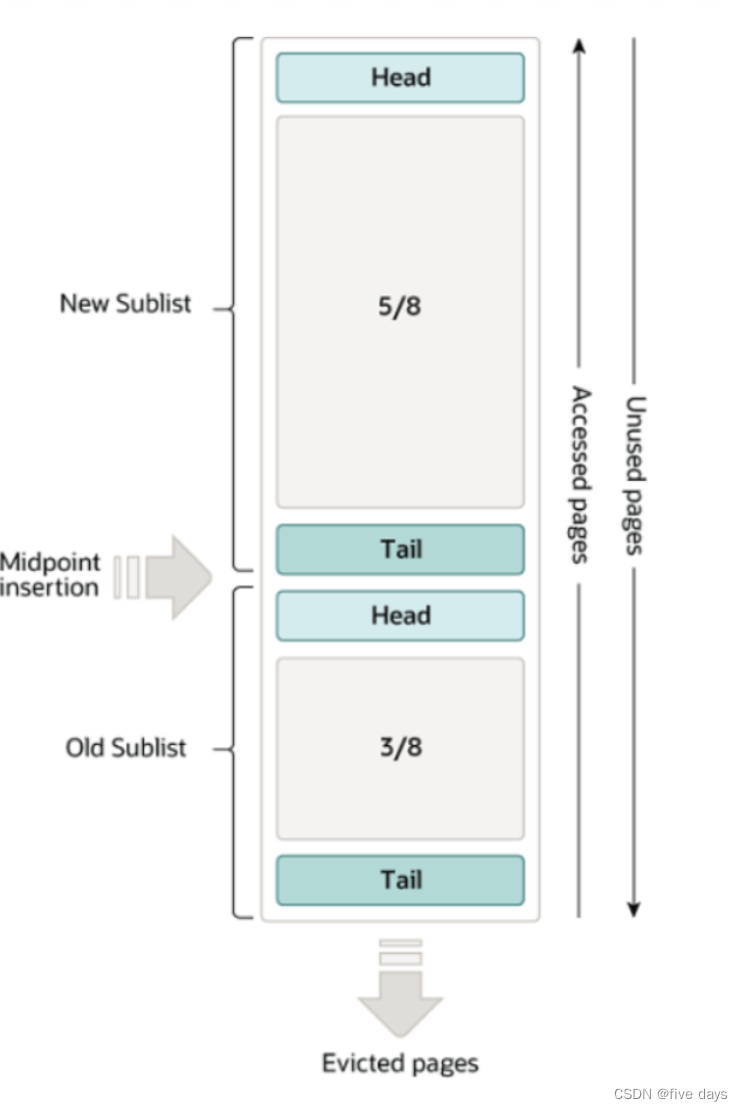
將LRU列表分為2段,鏈表的前面8分之5是新頁列表,后面的8分之3是老頁,然后淘汰頁面從后面尾部進行淘汰。具體流程如下:
1. 當新的頁面緩存到 BufferPool ,先加入到 oldSublist 的頭部,包括預讀的頁。2. 當 old 的頁面被訪問時 , 會添加到 new 的頭部成為一個最近訪問的頁3.new sublist 的鏈表會隨著新數據的加入向后移動 同樣的 old 的鏈表會隨著新數據的加入向后移動;淘汰old sublist 的鏈尾。
分析: 既然不確定用到,那么就先放到一個中間位置,當用到了后再放到頭部避免淘汰。如果加載了但沒用到,隨著推移,慢慢的進行淘汰掉,從而來提升內存的利用率。?
3.數據同步機制
從第2節中我們可以知道我們的數據都會以page頁的方式同步到我們的內存,那么在我們的系統中,就有2份數據,一份在內存,一份在磁盤,那么這2個數據是怎么去做數據同步的呢?怎么保證數據的一致性?
為什么不直接同步到磁盤呢?一致性問題不久解決了。假如說每次操作都需要先跟磁盤同步,那么就會出現以下問題:
1. 由于內存跟磁盤交互的最小單位是 page 頁,那么你改動一行數據,整個頁都需要跟磁盤進行交互同步。2. 這個更改的數據你是不知道在哪個磁盤位置的,屬于一個隨機 IO 。
上面的這兩個問題 都會導致每次操作數據會非常慢。
所以innodb采用的是異步刷盤機制,?何為異步刷盤,就是我優先去更改內存的數據,然后通過異步線程去進行跟磁盤的同步。這個時候,肯定會出現內存跟磁盤不一樣的頁,這種頁就叫做臟頁。
出現臟頁怎么辦?innodb是如何才能夠保證數據的一致性呢?
Mysql提供了一個doubleWrite機制,簡單點,就是備份。
什么是雙寫呢?就是當page頁刷新到磁盤的時候,把這個page數據寫到不同的地方去,當出現問題時,由備份來達到持久性跟數據的一致性。
雙寫過程:
1. 當臟頁被寫入到緩存池(也稱為內存池)時,它們將被寫入到Doublewrite緩沖區中,而不是直接寫入到磁盤上的表空間中2.? Doublewrite 緩沖區是一個位于內存中的緩沖區,用于存儲即將寫入磁 盤的臟頁的數據。在寫入到 Doublewrite 緩沖區后,數據將被寫入到兩 個不同的磁盤區域,這樣即使其中一個磁盤出現問題,數據也可以從另 一個磁盤恢復。在寫入到磁盤之前,數據會被緩存到磁盤的 WriteCache 中,確保數據能夠快速寫入磁盤。3. 在數據被寫入磁盤之前, Doublewrite 緩沖區中的每個臟頁的 LSN (日志序列號)都會被更新,以確保數據的一致性。這是因為LSN 是一種用于恢復數據的唯一標識符,它可以確保在數據庫出現故障時,數據可以恢復到一個一致的狀態。4. 一旦數據被成功寫入到磁盤上的兩個不同區域并且 LSN 已經被更新,數據就被標記為干凈頁并從緩存池中移除。此時,這個臟頁的數據已經被持久化到磁盤中,并且數據庫可以確保數據的一致性和可靠性。
分析:DoubleWrite機制會占用一部分內存和磁盤的空間,同時也會導致一定的性能損失,但這是為了保證數據的安全性和可靠性而進行的權衡。
3.1 change-buffer?
現在我們知道了,我們更改的數據都是異步同步到磁盤的,但是在更改之前呢,我們內存中不存在的數據,是不是還得從磁盤拿取,那可不可以再優化一下,我先改了放到內存,然后下次讀取到相關數據再進行合并呢。
innodb中也有這樣的優化,叫做change-buffer(更改緩沖區)
更改緩沖區是一種特殊的數據結構, 當這些頁面不在緩沖池中時,它會緩 存對二級索引 頁面的更改, 稍后會在其他讀取操作將頁面加載到緩沖池中時合并。為啥是二級索引,因為二級索引的插入跟修改一般是無序的,所以 IO 開銷更大,更需要提升性能。還有主鍵索引。唯一的,所以我們要去磁盤進行唯一校驗,本來就需要去磁盤進行 IO ,如果內存沒有數據的話。
4.RedoLog
我們已經知道了innodb中的數據是異步刷新到磁盤的,那么假如,在刷新到磁盤之前就宕機了。那么數據是不是就丟失了,innodb怎么數據的一致性與持久性呢?
innodb引入了一個redolog。也叫做重做日志,當發生異常的時候,導致數據丟失的時候,從redolog日志中找到想要的數據。
因為 InnoDB 的數據操作是只會實時去操作我們的 bufferpool 的 page 頁的,然后通過其他的一些異步方式將bufferpool 中的數據同步到磁盤,所以,數據丟失是很容易產生的。那么就需要我們的RedoLog 來保證數據的不丟失。它屬于InnoDB 存儲引擎層面實現
4.1 RedoLog格式
當操作數據時,就會記錄一條redolog日志,這個日志只是一條記錄,記錄的是在什么表空間,什么頁對數據驚醒了什么樣的更改。
?
type: 操作類型 插入、修改還是刪除'spaceId: 表空間 IDpage num : 鎖在的頁data: 修改的前后數據
這種記錄在某個偏移量發生了什么變更的這種日志格式,也叫做物理日志。
4.2 redolog的存儲與寫入
innodb通過rdolog解決數據丟失的問題。所以redolog肯定是一個基于磁盤的數據結構,肯定會寫入磁盤,每次sql語句提交的時候,都會去寫入redolog
首先,要保證數據不丟失,那么肯定是要落到磁盤的。那么肯定會有redolog的磁盤文件。
思考: 既然都要寫入磁盤,為什么不直接將數據同步到表空間的磁盤呢?
1. 因為 bufferPool 跟磁盤交互的最小單位是 page ,所以,只要 page 里面改 動一條數據,整個page 都會進行跟磁盤同步,導致不必要的同步。 RedoLog只會同步某些記錄。2. 你改動的數據是隨機的,不是順序的,隨機 IO 的性能比較慢,但是RedoLog是一直往上加,是順序 IO ,速度比數據 page 同步要快。
另外,redolog為了保證數據的一致性跟持久性的同時,性能得到保證,減少磁盤IO,于是作者又開辟了一個logBuffer的內存區間,緩存redolog,redolog不馬上寫到磁盤,而是先寫到logbuffer,然后一次性的從logbuffer同步到磁盤。
4.3 logbuffer 跟磁盤的同步
只要觸發了刷新到磁盤,就能百分比保證數據不丟失嗎?如果不丟失,性能是不是又會有所損耗
所以作者提供了不同的方案供選擇:
SELECT @@innodb_flush_log_at_trx_commit; //RedoLog同步方案默認設置為11 : 每次事務提交時,將日志刷新到磁盤,安全性高,能夠保證持久性,默認配置0 : 每秒從內存寫到操作系統,并且刷新( fsync() )到硬盤,可能會導致數據丟失2 :每次寫入 logbuffer 并且寫到操作系統,但是每秒 fsync() 到磁盤,最終刷新交給操作系統操作,只要操作系統不掛,也能保證持久性,但是操作系統掛了,數據沒刷新就會數據丟失
?
當然,除了配置?innodb_flush_log_at_trx_commit的 同步機制外,還有以下情況也會導致redolog同步到磁盤
a.buffer空間不足時
b. 后臺異步線程定期刷新
c.正常關閉服務器
d.checkPoint檢查哪些數據沒有同步到磁盤的時候
4.4 redolog的開啟與禁用
SHOW GLOBAL STATUS LIKE 'Innodb_redo_log_enabled'; -- 查看RedoLog是否開啟
ALTER INSTANCE disable INNODB REDO_LOG -- 禁用RedoLog5.總結
????????innodb作為一個存儲數據的引擎;利用了表空間,分段分區分頁的思想對數據進行管控;并且采用了內存緩沖池的機制減少IO,提升數據交互的效率;但是就可能造成兩處數據的不一致,形成臟頁,innodb就又采用了雙寫機制,提前做好備份,能夠應該故障和災難時,數據的不一致性問題。但是這解決了更改的性能,更改之前還需要從磁盤中拿,于是innodb又提出了change-buffer(更改緩沖區),改了先放內存,下次用了再同步。當然,這些都是采用了異步刷盤的思想,如果,刷盤之前就宕機了呢?innodb又提出了一個很重要的概念,redolog,每一次變更,都會存儲到該磁盤中,相較于存儲到表空間的磁盤中,該磁盤是順序添加的,順序IO性能肯定比隨機IO要好。說白了,innodb就是采用了各種內存緩存機制,來減少與磁盤的IO次數,從而提高性能的。有了緩存,那么就肯定少不了內存管理機制,數據的一致性和持久性。
學習筆記)
數據操作語言)







文件夾)





)
總數算不出+隨機抽取10張)


