23. Imagic: Text-Based Real Image Editing with Diffusion Models
??該文提出一種基于文本的真實圖像編輯方法,能夠根據純文本提示,實現復雜的圖像編輯任務,如改變一個或多個物體的位姿和組成,并且保持其他特征不變。相比于其他文本-圖像編輯工作,Imagic具備更豐富的編輯方式,并且能夠更好的保留編輯對象原有的特征。下面先展示一波結果,秀一下肌肉。可以看到編輯的效果非常逼真,而且是對圖像中目標物體直接進行編輯,而不是重新生成一個新的對象。

??基于擴散模型的文本-圖像編輯和生成的基礎理論我這里就不再贅述了,不清楚的可以參考本博客該專欄下的其他文章。籠統點來講,我們要把輸入的文本描述轉化為一個嵌入式向量,并將其作為一種條件信息引入到圖像生成過程中,從而實現圖像的編輯。本文提出的方法包含三個步驟:文本嵌入特征的優化,擴散模型的微調,以及特征插值與圖像生成,如下圖所示。
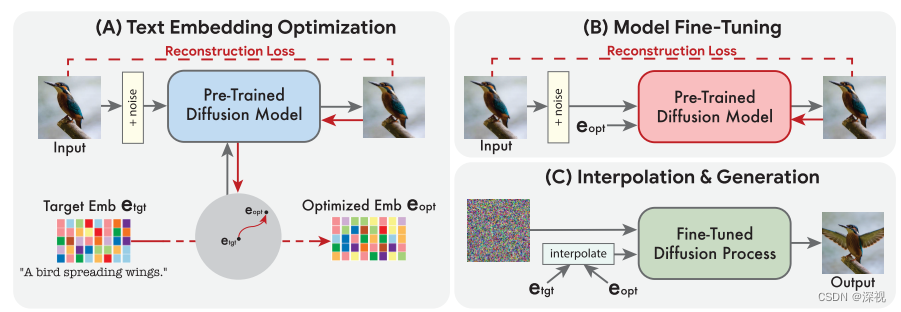
??首先,輸入的文本描述經過一個文本編碼器得到一個目標文本特征 e t g t e_{tgt} etgt?,并使用一個預訓練好的文本-圖像生成模型 f θ f_{\theta} fθ?對文本特征 e t g t e_{tgt} etgt?進行優化,損失函數如下 L ( x , e , θ ) = E t , ? [ ∥ ? ? f θ ( x t , t , e ) ∥ 2 2 ] \mathcal{L}(\mathbf{x},\mathbf{e},\theta)=\mathbb{E}_{t,\epsilon}\left[\left\|\boldsymbol{\epsilon}-f_{\theta}(\mathbf{x}_{t},t,\mathbf{e})\right\|_{2}^{2}\right] L(x,e,θ)=Et,??[∥??fθ?(xt?,t,e)∥22?]其中初始的 e \mathbf{e} e就是我們上文得到的 e t g t e_{tgt} etgt?,在這個過程中生成模型 f θ f_{\theta} fθ?的參數是固定不變的。隨著訓練的過程, e t g t e_{tgt} etgt?被不斷地更新,使其與輸入圖像 x x x的特征更加對齊,最終得到優化后的文本特征 e o p t e_{opt} eopt?。
??然后,我們再固定輸入的文本特征 e o p t e_{opt} eopt?不變,還是用上面的損失函數,對生成模型 f θ f_{\theta} fθ?進行微調訓練;同時如果還有其他的輔助模型,如提升分辨率的模型,也在這個過程中進行微調,只不過文本條件仍使用目標文本特征 e t g t e_{tgt} etgt?,而不是優化過的 e o p t e_{opt} eopt?。不要問為什么,問就是實驗顯示 e t g t e_{tgt} etgt?效果更好。
??最后,我們使用一個線性插值函數來計算 e t g t e_{tgt} etgt?和 e o p t e_{opt} eopt?之間的插值,如下式 e ˉ = η ? e t g t + ( 1 ? η ) ? e o p t \bar{\mathbf{e}}=\eta\cdot\mathbf{e}_{tgt}+(1-\eta)\cdot\mathbf{e}_{opt} eˉ=η?etgt?+(1?η)?eopt? η \eta η是可調的超參數,將插值得到的條件 e ˉ \bar{\mathbf{e}} eˉ輸入到微調后的文本-圖像生成模型中,即可得到對應的編輯結果。如下圖所示,通過調整 η \eta η的大小,我們可以得到有原始圖像到目標圖像的漸進變化過程,作者表示 η \eta η取值為0.6-0.8時編輯的效果是最好的。

??作者與許多現有的圖像編輯方法進行了比較,結果如下圖所示








 二叉搜索樹(BST)底層和模擬實現)
)

)

(Java))
)



)

