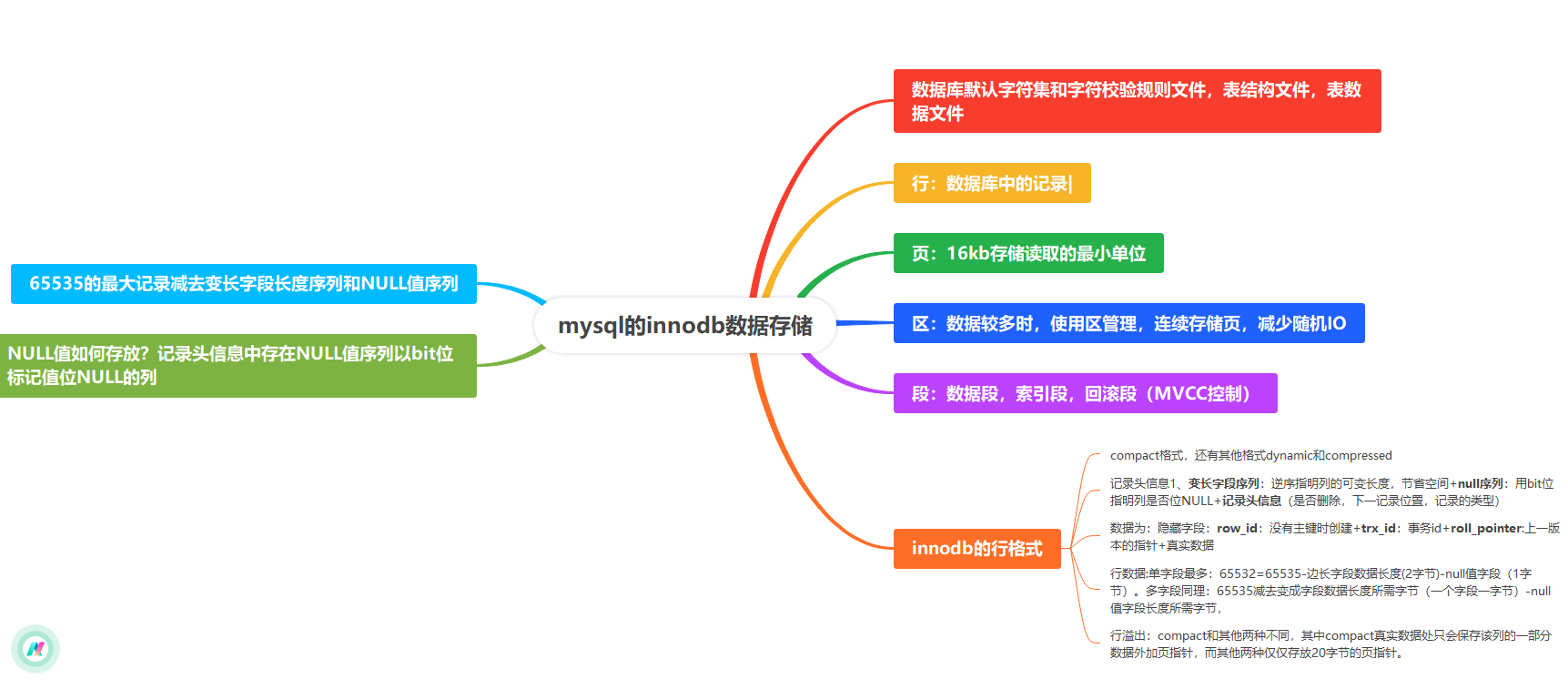
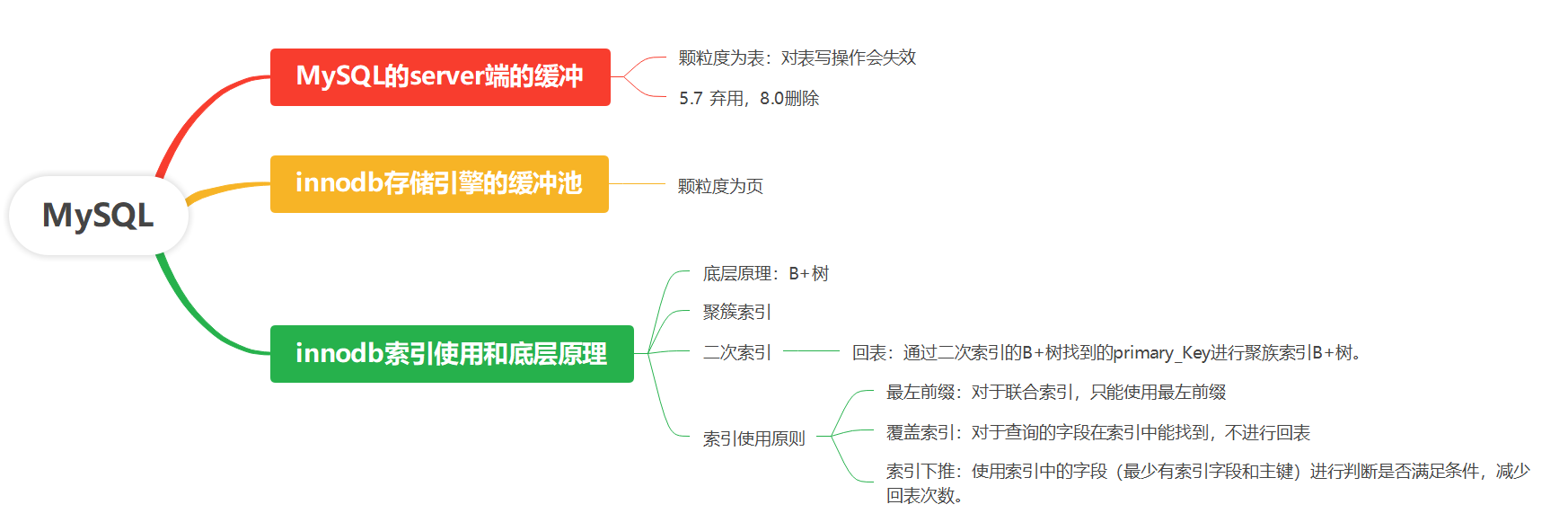
MySQL Server端的緩存(查詢緩存)是MySQL Server層的特性,而InnoDB的緩存(緩沖池)是InnoDB存儲引擎層的特性。兩者是完全獨立的。
下面我們來深入探討這兩者以及InnoDB索引的原理。
1. MySQL Server層的緩存 - 查詢緩存 (Query Cache)
歸屬:MySQL Server特性。它是一個全局性的組件,理論上對所有存儲引擎(如InnoDB, MyISAM)的查詢都可能生效。
工作原理:
當執行一個SELECT語句時,MySQL會先計算這個語句的哈希值,然后去查詢緩存中查找是否有完全匹配(字節對字節完全相同)的查詢結果。
如果找到(緩存命中),則直接返回結果,完全跳過解析、優化和執行階段,效率極高。
如果未找到(緩存未命中),則繼續執行查詢,獲取結果后,會將結果存儲到查詢緩存中,以備下次使用。
失效機制:非常粗粒度。只要對某張表進行了任何寫操作(INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE等),那么所有與這張表相關的查詢緩存都會全部失效并被清除。這對于寫操作頻繁的數據庫來說,緩存命中率會非常低,維護緩存反而帶來了巨大的性能開銷。
現狀:在MySQL 5.7中開始棄用,在MySQL 8.0中已被徹底移除。主要原因就是其弊大于利,在高并發讀寫場景下,緩存失效帶來的爭用甚至會導致性能下降。現在通常建議使用應用層緩存(如Redis, Memcached)來替代它。
2. InnoDB存儲引擎的緩存 - 緩沖池 (Buffer Pool)
歸屬:InnoDB存儲引擎的特性。這是InnoDB自身實現的核心組件。
工作原理:
緩沖池是主內存中的一片區域,用于緩存表和索引數據。當需要讀取數據時,InnoDB會先檢查數據頁是否在緩沖池中。如果在(緩存命中),則直接讀取內存,速度極快。
如果不在(緩存未命中),則從磁盤讀取相應的數據頁,并將其放入緩沖池中,然后再進行讀取。
對于寫操作,修改的也是緩沖池中的數據頁。這些被修改但尚未刷新到磁盤的頁稱為臟頁 (Dirty Page)。InnoDB有后臺線程定期將臟頁刷新到磁盤,這個過程稱為刷臟 (Checkpointing)。
重要性:這是InnoDB性能的核心。通過緩沖池,InnoDB將磁盤I/O操作最小化,將最多的操作在內存中完成。緩沖池的大小(通過?
innodb_buffer_pool_size?參數設置)是MySQL性能調優最重要的參數,通常建議設置為服務器物理內存的50%-80%。與索引的關系:B+樹索引的非葉子節點和頻繁訪問的葉子節點都會常駐在緩沖池中,這使得基于索引的查詢速度非常快。
3. InnoDB索引使用與底層原理
索引數據結構:B+樹
InnoDB使用B+樹作為其索引的數據結構。B+樹是為磁盤存儲而優化的,它具有以下特點:
矮胖樹:層級很少,通常只需2-4次I/O就能在億萬級數據中找到目標。
所有數據都存儲在葉子節點:非葉子節點只存儲鍵值(索引列的值)和指向子節點的指針,這使得非葉子節點可以存儲大量鍵值,讓樹更“矮胖”。
葉子節點形成有序鏈表:范圍查詢效率極高,只需找到范圍的起始點,然后沿著鏈表遍歷即可。
聚集索引 (Clustered Index)
InnoDB的表必須有一個聚集索引。
數據行本身就直接存儲在聚集索引的葉子節點上。因此,表數據本身就是按聚集索引的順序物理存儲的。
通常,聚集索引就是主鍵(PRIMARY KEY)。如果沒有定義主鍵,InnoDB會選擇一個唯一的非空索引代替。如果也沒有,則會隱式創建一個 rowid 作為聚集索引。
二級索引 (Secondary Index)
也叫非聚集索引或輔助索引。
二級索引的葉子節點存儲的不是完整的數據行,而是該行的主鍵值。
當通過二級索引查詢時,需要先找到對應的主鍵值,然后再回到聚集索引中根據主鍵查找完整的行數據。這個過程稱為回表 (Bookmark Lookup)。
索引使用原則
最左前綴原則:對于聯合索引?
(a, b, c),它可以用于查詢?a,?(a, b),?(a, b, c)?的條件,但不能用于跳過?a?直接查詢?b?或?c。覆蓋索引 (Covering Index):如果查詢的字段都包含在某個索引中(例如在索引?
(a, b)?上查詢?a, b),則引擎可以直接從索引中獲取數據,而無需回表,極大提升性能。索引下推 (Index Condition Pushdown, ICP):MySQL 5.6引入。在索引遍歷過程中,提前對索引中包含的字段進行WHERE條件過濾,減少回表的次數。
ps:如果沒有索引下推優化(或稱ICP優化),當進行索引查詢時,首先根據索引來查找記錄,然后再根據where條件來過濾記錄;在支持ICP優化后,MySQL會在取出索引的同時,判斷是否可以進行where條件過濾再進行索引查詢。
總結與對比
| 特性 | MySQL Server查詢緩存 | InnoDB緩沖池 (Buffer Pool) |
|---|---|---|
| 歸屬層面 | MySQL Server層 | InnoDB存儲引擎層 |
| 緩存內容 | 完整的查詢結果集 | 表和索引的數據頁 |
| 粒度 | 粗(表級) | 細(頁級,通常16KB) |
| 失效機制 | 對表的任何寫操作導致所有相關緩存失效 | 基于LRU算法和刷臟機制,精細管理 |
| 現狀 | MySQL 8.0中已移除 | InnoDB核心組件,至關重要 |
| 目的 | 避免重復執行相同的SQL查詢 | 減少磁盤I/O,加速數據訪問 |
因此,在現代MySQL(尤其是8.0+)的架構討論和性能優化中,我們關注的重點幾乎完全在?InnoDB緩沖池?上,而早已不再考慮已被廢棄的Server層查詢緩存。理解緩沖池的工作原理和大小設置,是優化數據庫性能的第一步,也是最關鍵的一步。



![[論文閱讀] 告別“數量為王”:雙軌道會議模型+LS,破解AI時代學術交流困局](http://pic.xiahunao.cn/[論文閱讀] 告別“數量為王”:雙軌道會議模型+LS,破解AI時代學術交流困局)
)
)



-Spark 應用核心組件剖析)



 本節目標 1. 掌握樹的基本概念 2. 掌握二叉樹概念及特性 3. 掌握二叉樹的基本操作 4. 完成二叉樹相關的面試題練習)





![【系列文章】Linux中的并發與競爭[05]-互斥量](http://pic.xiahunao.cn/【系列文章】Linux中的并發與競爭[05]-互斥量)