本文重點
在邏輯回歸的時候,我們可以將神經網絡的權重參數初始化為0(或者同樣的值),但是如果我們將神經網絡的權重參數初始化為0就會出問題,上節課程我們已經進行了簡單的解釋,那么既然初始化為0不行,神經網絡該如何進行參數初始化呢?神經網絡的權重參數初始化是模型訓練的關鍵步驟,直接影響收斂速度和最終性能。
權重W過大和過小
為權重W賦值比較小的數值
W=np.random.randn(input,output)*0.01
np.random.randn會隨機生成標準正態分布,也就是說均值為0,方差為1,乘以0.01,那么此時的均值為0,方差為0.01。
這種情況下,訓練的時候,我們會發現,神經網絡層數比較多的時候,神經網絡后面的層的權重參數均值和方差會逐漸變為0,那么這種情況就和前面的權重初始化為一樣的值是一樣的效果,此時神經網絡是沒有辦法訓練的了。
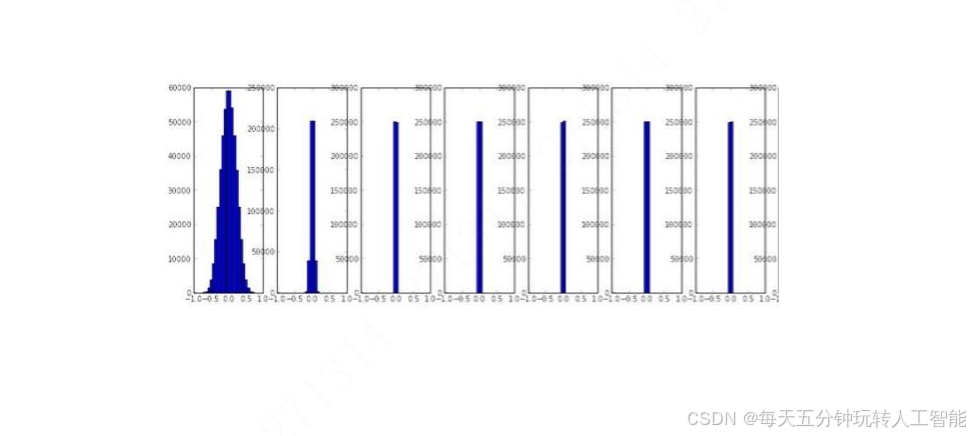
為權重W賦值比較大的數值
W=np.random.randn(input,output)*1.0因為當權重過大的時候,sigmoid就會出現飽和的情況,也就是說sigmoid(wx)=1或者-1,無論是1還是-1,此時的sigmoid的梯度都是0,那么此時反向傳播是沒有辦法訓
![[論文閱讀] 告別“數量為王”:雙軌道會議模型+LS,破解AI時代學術交流困局](http://pic.xiahunao.cn/[論文閱讀] 告別“數量為王”:雙軌道會議模型+LS,破解AI時代學術交流困局)
)
)



-Spark 應用核心組件剖析)



 本節目標 1. 掌握樹的基本概念 2. 掌握二叉樹概念及特性 3. 掌握二叉樹的基本操作 4. 完成二叉樹相關的面試題練習)





![【系列文章】Linux中的并發與競爭[05]-互斥量](http://pic.xiahunao.cn/【系列文章】Linux中的并發與競爭[05]-互斥量)


