傳統RAG的缺點
????????當我們將一段文本信息以句子分割后,存入到向量數據庫中。用戶提問“老王喜歡吃什么”,這個問題會與向量數據庫中的許多句子關聯性比較強,能返回準確且具體的信息。
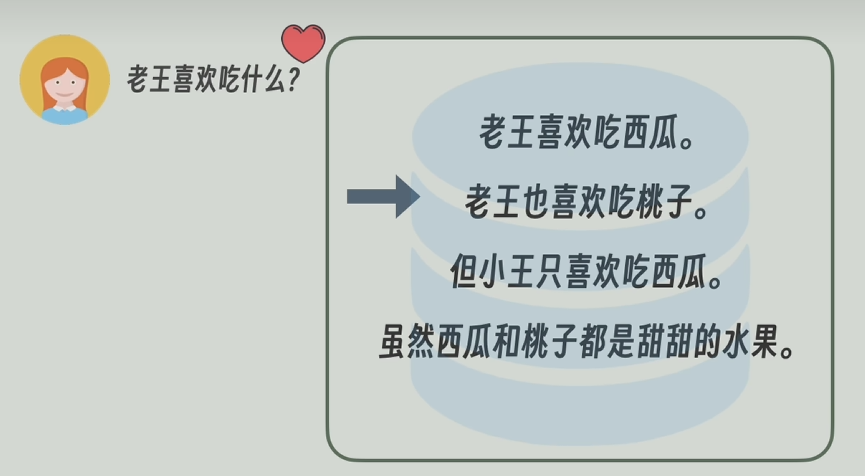
????????但是,若是問題換成“出現了幾次西瓜”,西瓜是一個比較具體的名詞/物品,它容易出現在很多句子中,但是在出現的句子中占比又不是很大。

????????用戶的問題中的“西瓜”,在“老王喜歡吃西瓜”這句話中出現,但是這句話的只有一小部分信息是“西瓜”,所以,在提問這種比較細節性的問題時,在做問題與句子之間的相似度計算,相似度可能并不是很大,這就導致最后的查詢結果會漏掉一些句子,甚至匹配錯誤。

????????那么如果劃分的顆粒度再細一點,將“老王喜歡吃瓜”,切成“老王”,“喜歡吃”,‘西瓜’,又分成了三段,那么問題“西瓜出現幾次”這個問題可能會比較好解決了(因為“西瓜”單獨出現了),但是回到原問題“老王喜歡吃什么”又難以解決了,因為“老王喜歡吃什么”,只會匹配到“老王”和“喜歡吃”,匹配不到‘西瓜’,所以原問題又難以得到解決。

????????所以當劃分段落的顆粒度比較粗,容易丟失細節,若劃分顆粒度太細,語義之間的聯系(老王--->喜歡吃---->西瓜)又被消除。這就是傳統RAG的缺點之一。

1. 檢索層面的缺點
-
語義召回不穩定:依賴向量召回(如基于 embedding),可能出現召回不相關或遺漏關鍵信息的情況。
-
知識碎片化:檢索出的文檔片段往往是局部的,缺乏整體結構,模型容易“拼湊”出不連貫的回答。
-
依賴索引質量:如果文本清洗、切分、embedding 表達不佳,檢索效果會大幅下降。
2. 生成層面的缺點
-
上下文窗口限制:檢索到的內容需要塞進模型上下文,受限于窗口大小,導致長文檔場景容易丟失重要信息。
-
幻覺問題仍存在:雖然 RAG 能緩解模型“胡編亂造”,但如果檢索不準,模型仍可能基于錯誤內容生成回答。
-
信息融合困難:模型可能無法很好地整合多個檢索片段的信息,尤其是在需要推理、對比或跨段整合時。
3. 系統架構層面的缺點
-
延遲較高:RAG 需要兩步(檢索 + 生成),相比純生成模型響應更慢。
-
維護復雜:需要單獨維護知識庫、向量索引和更新流程,工程成本高。
-
難以動態更新:傳統 RAG 對知識更新通常需要重新向量化和索引,實時性不足。
4. 應用層面的缺點
-
魯棒性不足:對用戶提問方式敏感,表達不同可能導致檢索結果差異顯著。
-
領域依賴強:在知識高度專業、語義微妙的領域(如法律、醫療),檢索誤差對結果影響極大。
-
可解釋性有限:雖然能返回檢索片段,但生成結果和檢索片段之間的邏輯聯系往往不透明。
知識圖譜
????????為了解決傳統RAG的缺點,人們就應用知識圖譜。下面這張就是一個典型的圖譜,有實體節點“老王”和“習慣”,也有關系節點“愛吃”。

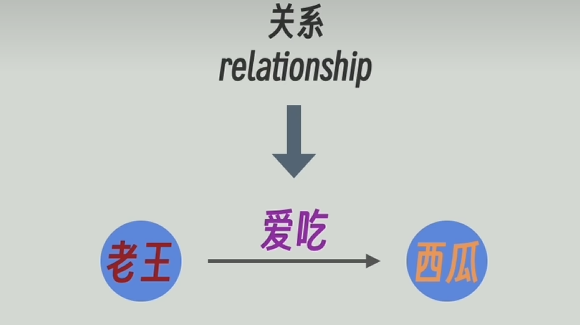
????????我們還可以賦予實體節點和關系節點屬性和描述,比如實體節點“老王”,他的標簽/屬性可以是“人”,可以附帶描述“愛吃西瓜”,關系節點“愛吃”,可以有描述“老王愛吃的東西”等等。比如,在neo4j圖知識庫中可以輕松做到這些。

????????在傳統知識圖譜構建中,我們需要從這一段文字中找出實體,抽取出實體之間的關系,算法十分復雜而且性能也一般。但是,再出現大模型之后,這些步驟就相對容易許多,而且性能也很好。做法就是,寫好一段示例,并加上數據傳給大模型,讓大模型來抽取出實體和關系。需要注意的是里面的實體類型,需要我們自己定義,你可以認為“人”是實體,可以認為“水果”是實體,還可以認為“味道”是實體。
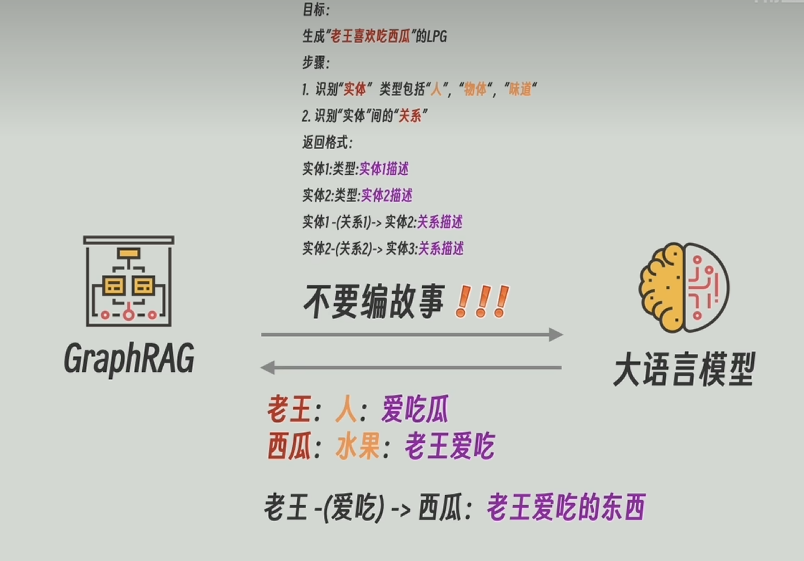
????????并且當大模型返回解析后的知識圖譜之后,通常來說我們會將知識圖譜和原文再發送給大模型,再讓他解析,循環往復直到大模型任務這個原文的實體和關系都已經以最細的粒度抽取完畢了。

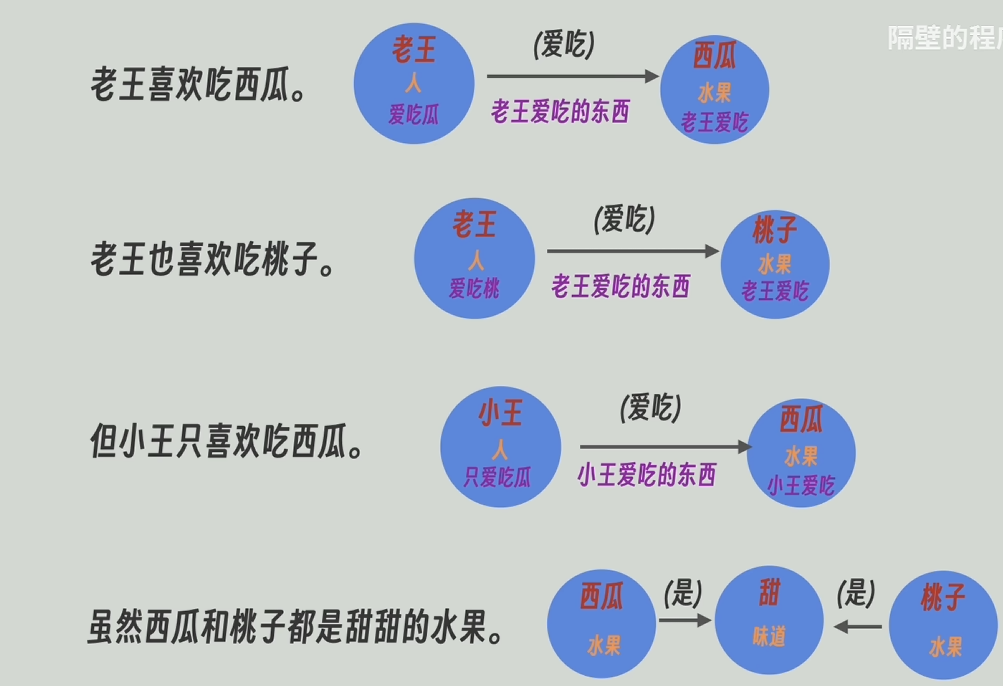
這樣我們就借助大模型生成了某一文本段落的知識圖譜。
GraphRAG
合并圖譜
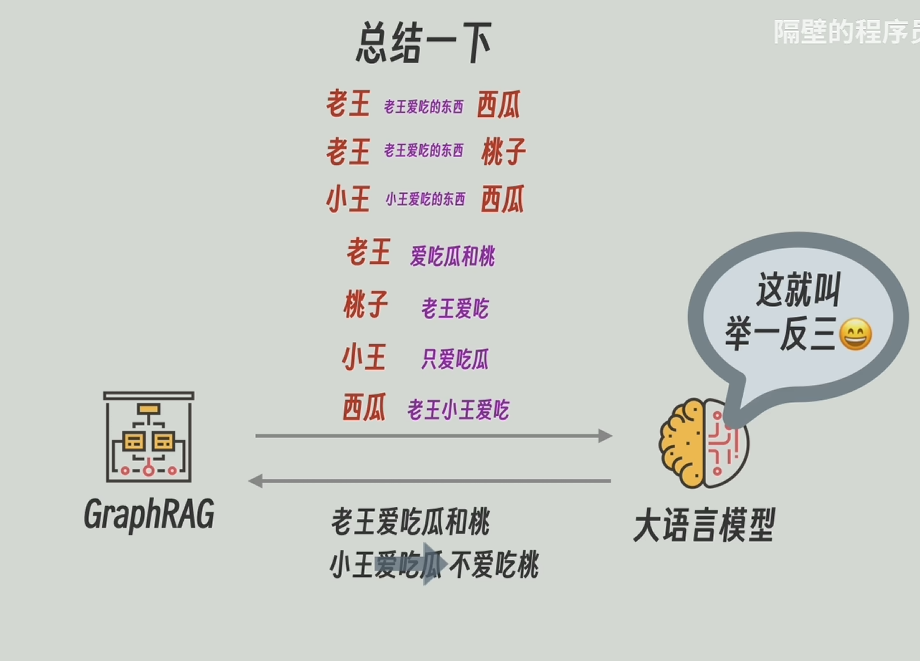
將拆分后的每個段落生成的知識圖譜合并,節點和關系合并的時候,其所帶的描述信息也會一同合并。
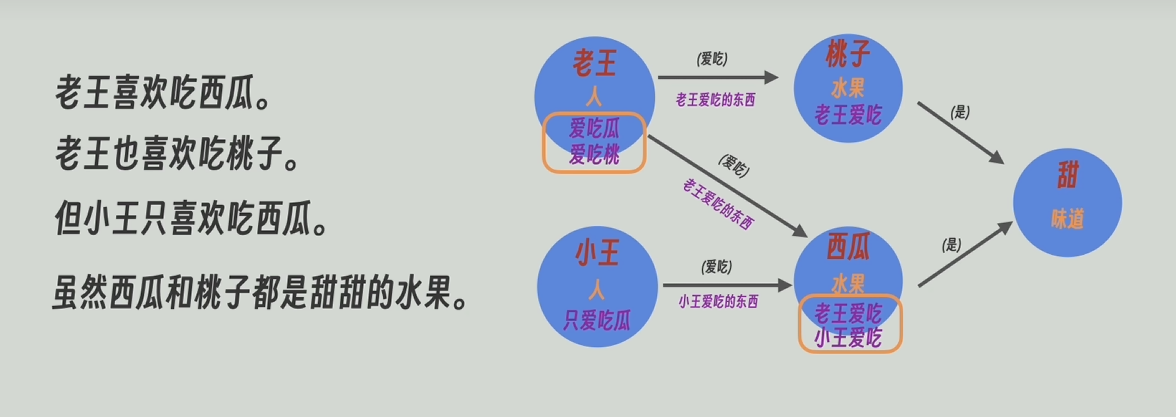
之后,把每個節點和關系(邊)的合并后的描述信息再發送給大模型,讓他對這些信息再總結一下,高度概括一下。
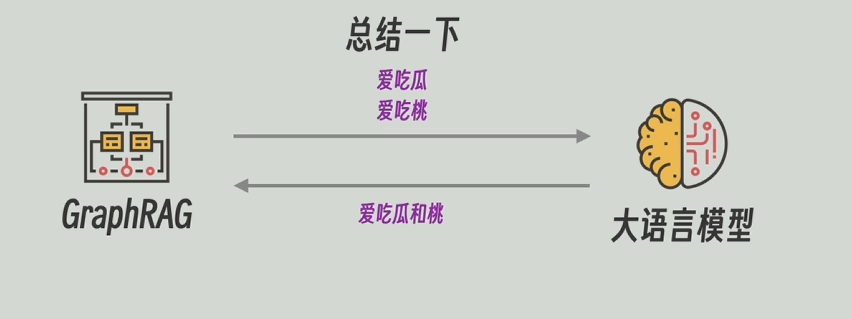
用大模型高度總結后的描述信息代替原本合并后的描述信息。此外GraphRAG還會一直維護著圖譜和原文的關聯信息。比如實體節點“老王”是由哪幾段生成。
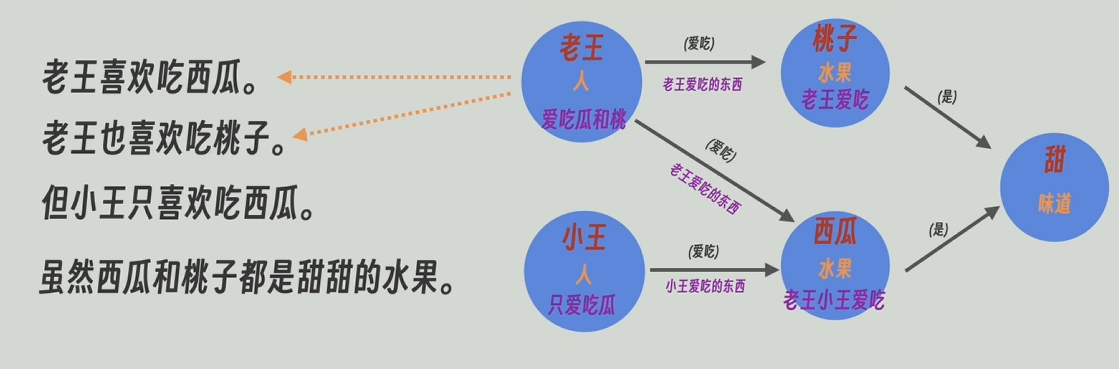
同理,一段原文也會對應著知識圖譜中的哪些實體節點和關系節點

簡化圖譜
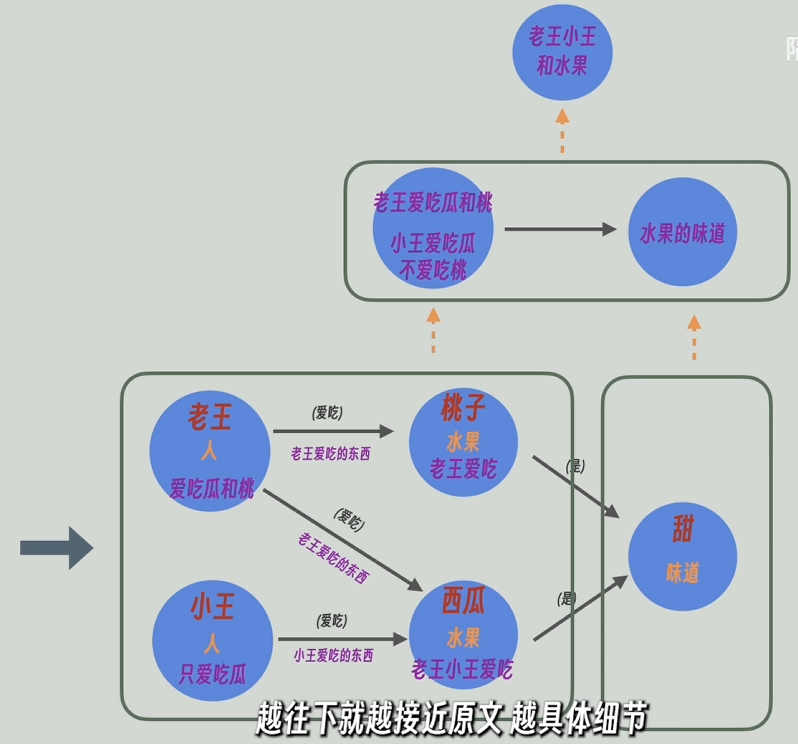
現在的知識圖譜太大了,GraphRAG會通過算法合并部分圖譜作為一個整體,比如將現在的知識圖譜合并成了兩個整體。
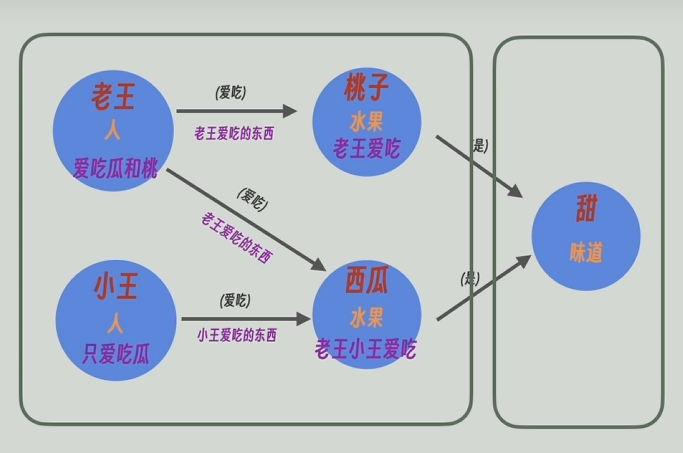
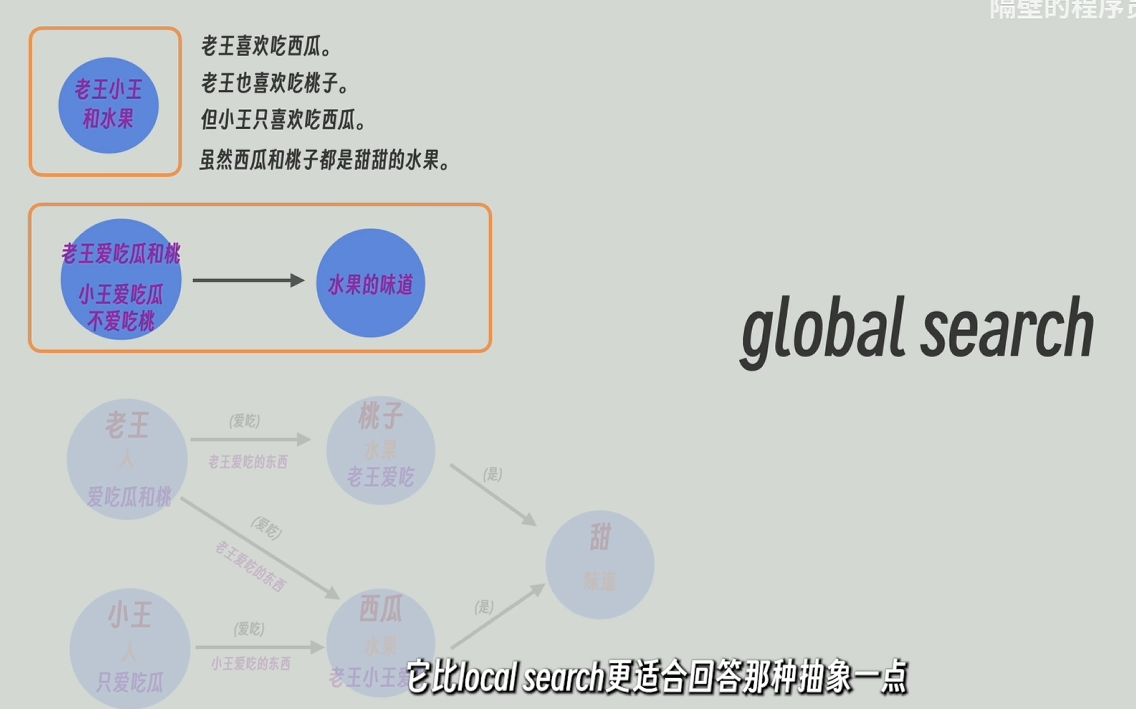
再把每個整體中的所有節點和關系的描述信息發送給大模型,再讓大模型進行高度總結,甚至還能推理。比如通過“老王愛吃瓜和桃”和“小王只愛吃瓜”能總結/推理出“小王不愛吃桃”,再將高度總結后的更寬泛更高維的信息返回。
循環此操作,就可以得到一個層級結構的知識圖譜,越往上,信息越凝練高度概括,越往下信息越詳細
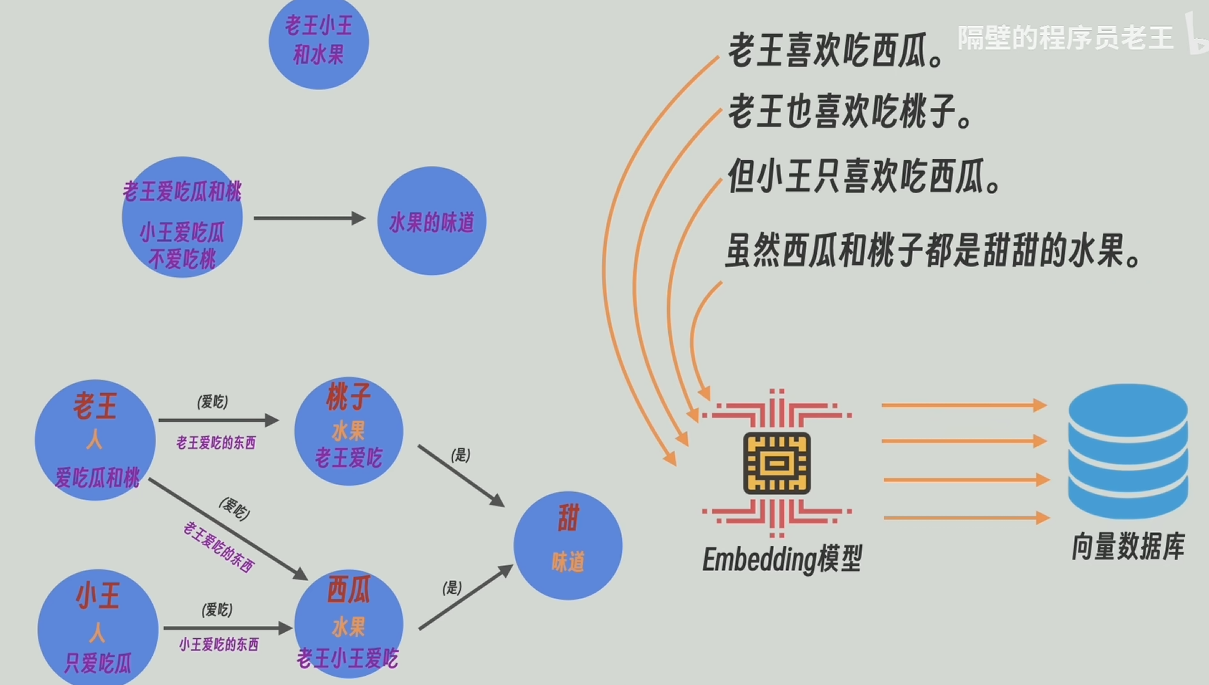
查詢
把這個層級結構的知識圖譜中的每條邊每個節點的實體信息和描述都當做文本片段embedding后存入向量數據庫中

同時,將原文的每個切片也都存入向量數據庫中
接下來就是把用戶的提問轉為embedding之后,可以和知識圖譜某基層也可以和原文片段進行匹配,也可以全部查一遍
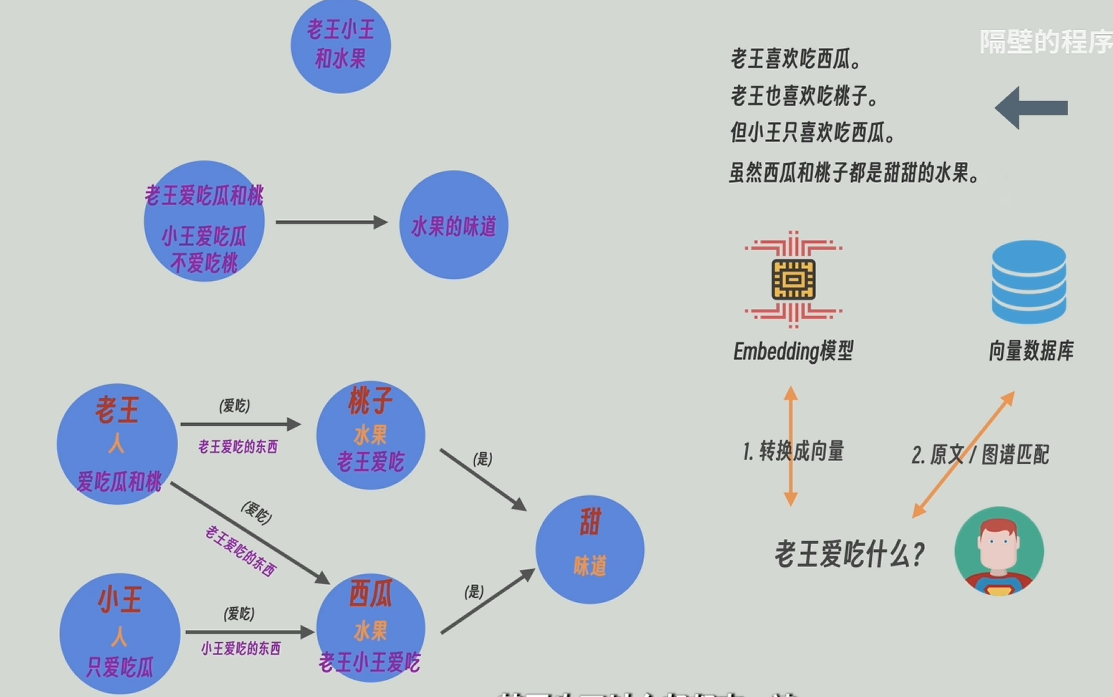
local_search策略:先從最底層(詳細接近原文)的知識圖譜中找出和問題最近的實體,再反向查詢這個底層的知識圖譜是由原文中哪些片段組成的,這個底層的知識圖普相關的上層(有高層次的抽象問題)或相鄰的節點(低層次的細節問題)和關系也會被找到,最后將這些節點和邊的信息和原文片段和問題一起發給大模型。local_search從最底層,所以適應細節問題

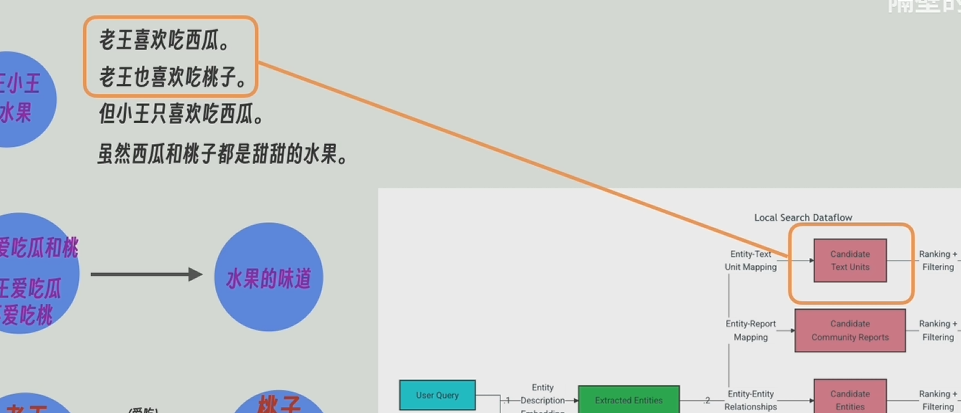

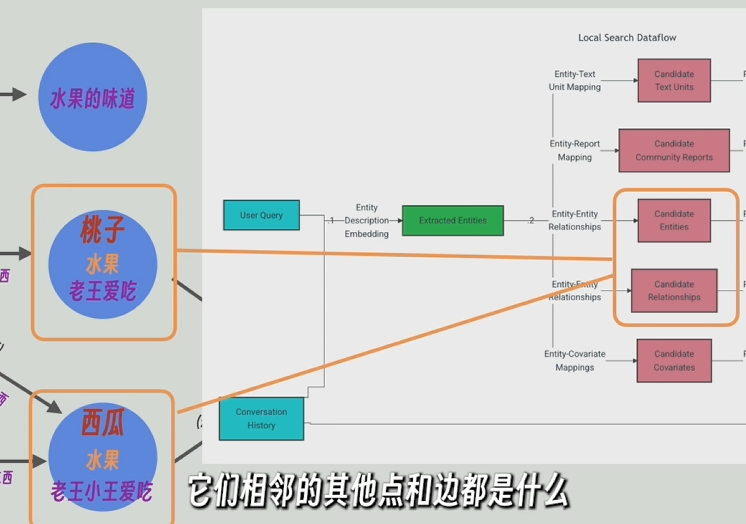

global_serch從知識圖譜的頂層開始查起,所以比較適用于高層次抽象問題,比如“這篇文章的主旨是什么”
補充
萊頓社區檢測算法








b站:AI知識圖譜 GraphRAG 是怎么回事?_嗶哩嗶哩_bilibili
)













))
、GitHub Desktop(版本控制工具)、VSCode(代碼編輯器))

 sync.Pool)

 選擇器詳解:為什么它是“父選擇器”?如何實現真正的容器查詢?)