????????
目錄
1.排序的原理
1.1 保證子數組有序
1.2 時間復雜度
2. 遞歸實現
2.1 思路
2.2 代碼
3. 非遞歸實現
3.1 思路
3.2 代碼
4.面試題
4.1 題目
4.2 思路
? ? ? ?
1.排序的原理
歸并排序是外排序,所謂外排序就是說能夠對文件中的數據進行排序。
①首先,將待排序數組分成兩部分,這兩部分數組一定是有序的,使用兩個指針分別初始化于這兩部分的首元素;
②需要一個臨時空間,兩個指針指向的較小的元素先放入空數組中。
③如果選擇其中一個指針的元素,那么該指針需要后移一位,如果沒選到該元素,指針不動。
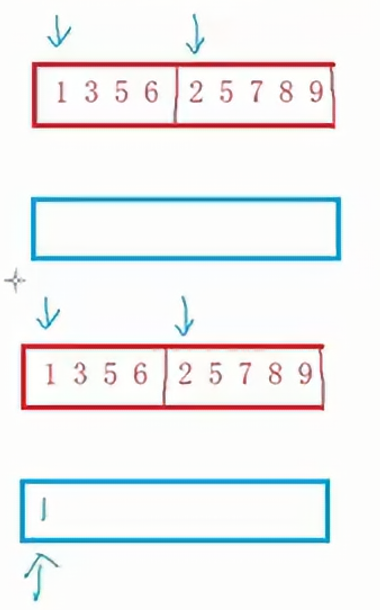
④如果其中一個數組元素被取完了,那么另外一個數組的內容直接填入空數組。
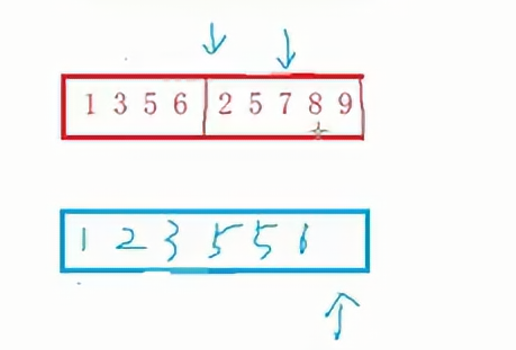
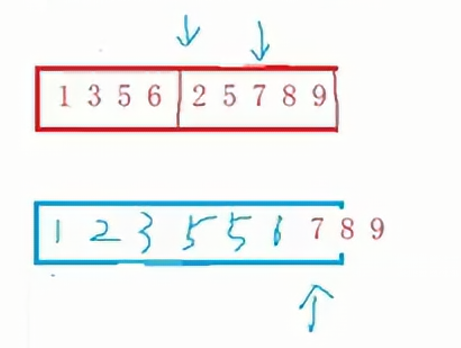
????????上面的操作是建立在兩部分數組是分別有序的情況下,但是我們如何保證兩部分的數組是有序的呢?
1.1 保證子數組有序
? ? ? ? ? ? ? ? 保證當前區間是有序的,如果該區間不是有序的,那么需要將該區間分成子區間,從而保證子區間有序,如果該區間只剩一個數,那么說明這個區間是有序的。
? ? ? ? 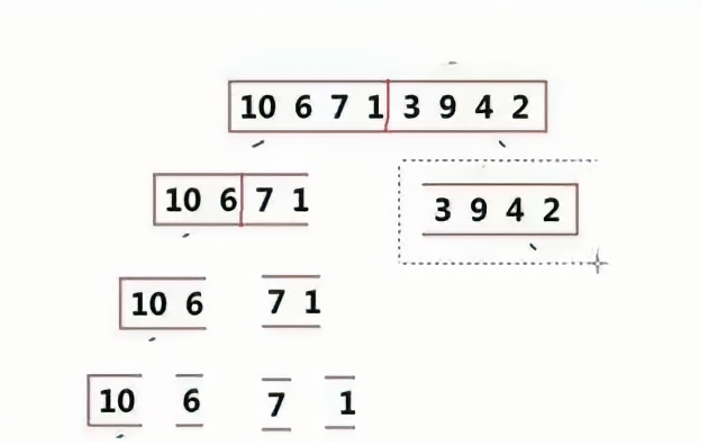 將區間細分到只有一個數的時候,這就是遞歸的“歸”,此時返回上一層的函數棧幀,使父區間變得有序。
將區間細分到只有一個數的時候,這就是遞歸的“歸”,此時返回上一層的函數棧幀,使父區間變得有序。
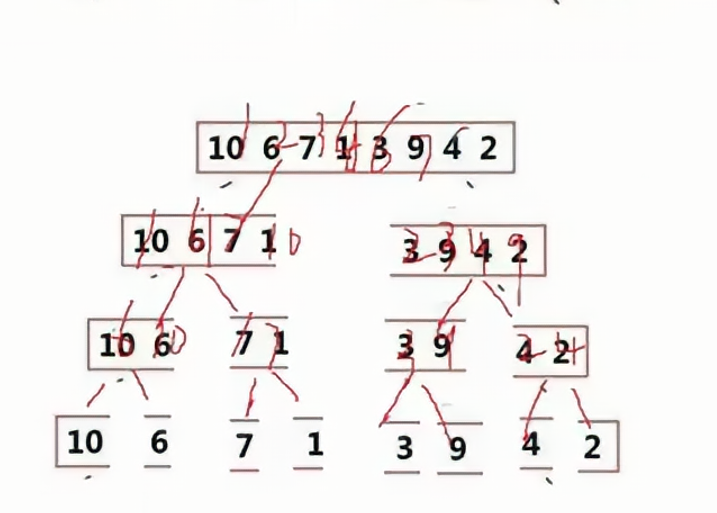
1.2 時間復雜度
????????這里可以將遞歸的過程當做二叉樹的生成,每一層的節點是N,二叉樹的高度是LogN,那么時間復雜度就可以計算出來是N*logN。
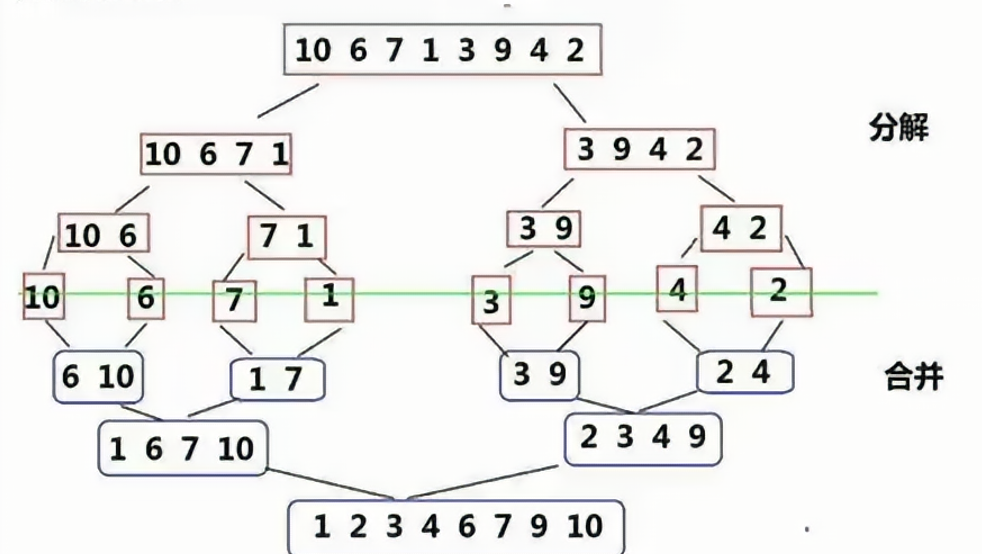
2. 遞歸實現
2.1 思路
①首先寫一個歸并排序的主函數,主函數需要創建一個臨時變量tmp,用于存放排序的數據;
②調用歸并排序的子函數,子函數需要傳入原數組、區間、臨時數組,子函數的目的是為了讓區間內的數組有序。
③子函數:首先這是一個遞歸,需要寫遞歸退出條件,即left >= right下標不合法或者就剩一個元素,說明是有序的,就退出遞歸。
④使用遞歸分別讓左右區間分別有序。
⑤開始合并有序數組,begin指針指向的元素更小的存入tmp中。
⑥把tmp數組的元素拷貝回原數組。
2.2 代碼
? ? ? ??
#include<stdio.h>// 使區間變得有序的方法
void _merge_sort(int* arr, int left, int right, int* tmp)
{// 遞歸退出條件if (left >= right){return;}// 求mid,將[left,right]分為[left,mid][mid+1,right]兩部分int mid = (left + right) / 2;// 保證兩區域是有序的才能進行合并有序數組_merge_sort(arr, left, mid, tmp);_merge_sort(arr, mid + 1, right, tmp);// 開始合并有序數組int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;// 記錄tmp的下標int tmp_index = begin1;while (begin1 <= end1 && begin2 <= end2){// 兩個有序數組,哪個小放哪個if (arr[begin1] < arr[begin2]){tmp[tmp_index++] = arr[begin1++];}else{tmp[tmp_index++] = arr[begin2++];}}// 退出的時候是某一數組已經取值完畢了while (begin1 <= end1){tmp[tmp_index++] = arr[begin1++];}while (begin2 <= end2){tmp[tmp_index++] = arr[begin2++];}// 將tmp數組的值全部放回arr去,進行覆蓋for (int i = left; i <= right; ++i){arr[ i] = tmp[i];}
}void merge_sort(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_merge_sort(arr, 0, n - 1, tmp);free(tmp);
}
3. 非遞歸實現
3.1 思路
? ? ? ? 使用循環,首先每一個元素作為一個單位進行排序,接下來兩個一組為單位進行排序如下圖所示:
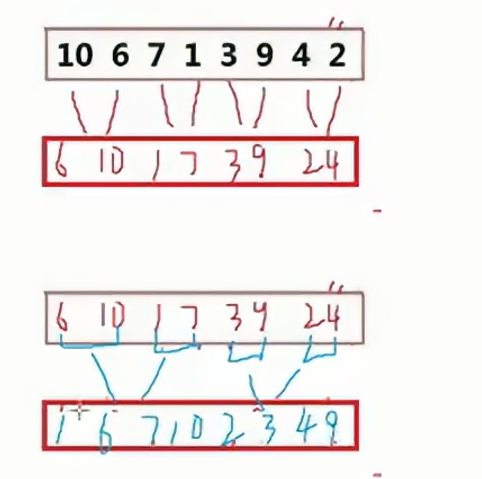
最后按照四個元素一組進行排序,我們只需要控制間距即可。
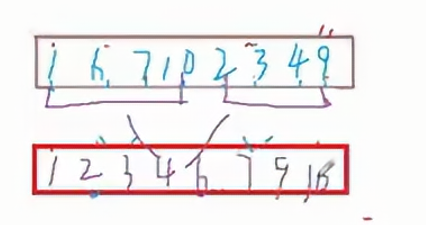
3.2 代碼
? ? ? ? 首先寫gap為1的時候,該如何操作,當gap為1的的時候,我們只需要將相鄰兩個元素進行合并操作,例如將10和6合并成6和10,下一次合并需要將7和1合并成1和7;以此類推。
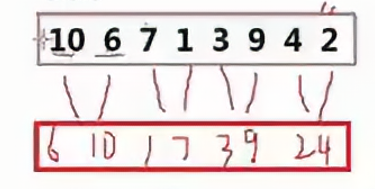
????????我們可以將合并有序數組這個方法單獨抽象出來,然后后面直接調用此方法即可,下面的代碼就是當gap=1的時候,書寫的代碼。
// 抽象合并有序數組的函數
void merge_array(int* arr, int begin1, int end1, int begin2, int end2, int* tmp)
{int left = begin1, right = end2;// 記錄tmp的下標int tmp_index = begin1;while (begin1 <= end1 && begin2 <= end2){// 兩個有序數組,哪個小放哪個if (arr[begin1] < arr[begin2]){tmp[tmp_index++] = arr[begin1++];}else{tmp[tmp_index++] = arr[begin2++];}}// 退出的時候是某一數組已經取值完畢了while (begin1 <= end1){tmp[tmp_index++] = arr[begin1++];}while (begin2 <= end2){tmp[tmp_index++] = arr[begin2++];}// 將tmp數組的值全部放回arr去,進行覆蓋for (int i = left; i <= right; ++i){arr[ i] = tmp[i];}
}void merge_sort_non(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);int gap = 1;// 【i,i + gap - 1】和【i + gap,i + 2 * gap - 1】閉區間for (int i = 0; i < n; i+= 2*gap)// 1,2合并之后,i下一次要合并3,4,{merge_array(arr, i, i + gap - 1, i + gap, i + 2 * gap - 1, tmp);// gap=1的時候就是兩個數合并}free(tmp);
}
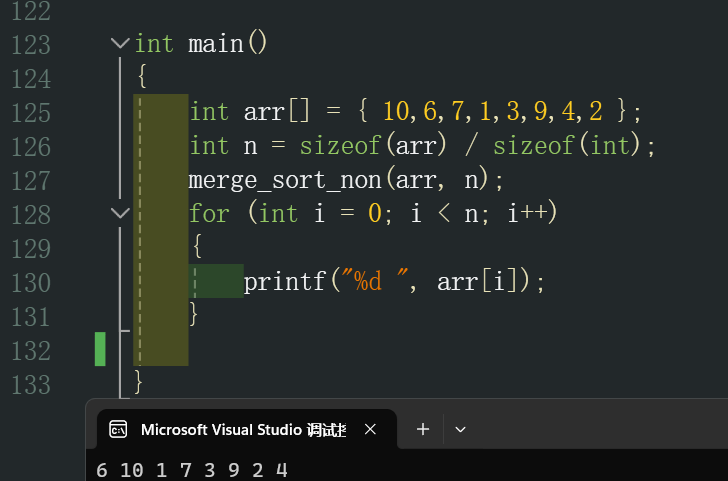
我們可以驗證一下,當gap=1的時候是否正確:
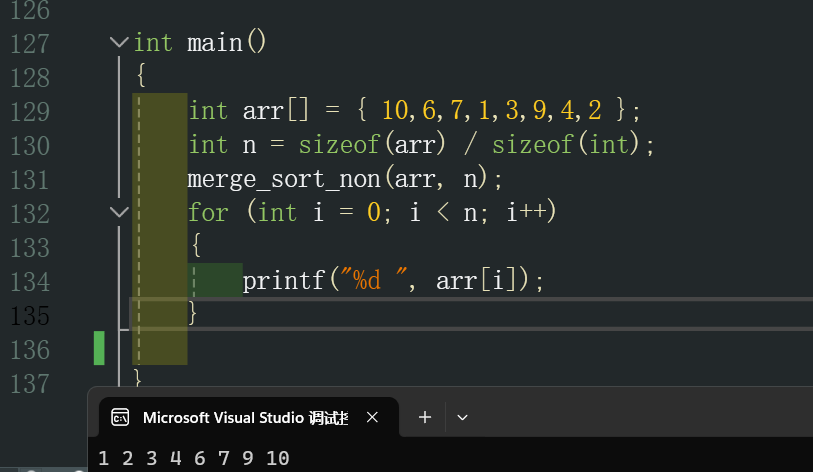
最后調整gap,外面增加一層循環,gap最多是n/2,每次循環gap需要變為原來的2倍,1,2,4.....
? ? ? ? 這里需要注意的是,當gap不斷變化,第二組有可能會出現越界的情況,下面需要標注第二組兩種越界情況。
void merge_sort_non(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);int gap = 1;while (gap <n){// 【i,i + gap - 1】和【i + gap,i + 2 * gap - 1】閉區間for (int i = 0; i < n; i += 2 * gap)// 1,2合并之后,i下一次要合并3,4,{// 確保不越界int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;// 確保不越界if (begin2 >= n) break; // 第二個數組不存在if (end2 >= n) end2 = n - 1; // 調整第二個數組的結束位置merge_array(arr, begin1, end1, begin2, end2, tmp);}gap *= 2;}free(tmp);
}
gap其實就是決定有多少個數進行合并,gap為1的時候,其實就是1個數和1個數進行合并。
4.面試題
4.1 題目
? ? ? ? ①文件有10億個數據,需要排序,怎么辦?假設內存中最多只能放1000w個數據。
首先將數據分成100份,一份就是1000w個數據,將每一份數據兩兩歸并排序成一個文件(磁盤)
假設文件中的數據是按照換行來分割的:

首先需要將數據分成n等份,每一份的大小剛好可以存入內存里,然后對每一份進行排序,生成n份文件。
// 外排序,返回一個文件名
void file_sort(char* file)
{FILE* fout = fopen(file, "r");if (fout == NULL){printf("文件打開失敗\n");exit(-1);}int num = 0;int n = 10;// 將文件內容分成10份int arr[10];// 臨時存10個數int i = 0;char subfile[20];// 子文件名稱int id = 0; // 子文件下標while (fscanf(fout, "%d\n", &num) != EOF){if (i < n){arr[i++] = num;}else{// 滿10個了就排序merge_sort(arr, n);sprintf(subfile, "sub\\subfile_%d.txt", id++);printf("%s", subfile);// 對每一個文件進行寫FILE* fin = fopen(subfile, "w");for (int i = 0; i < n; i++){fprintf(fin, "%d\n", arr[i]);}fclose(fin);i = 0;}}fclose(fout);}int main()
{file_sort("sort.txt");}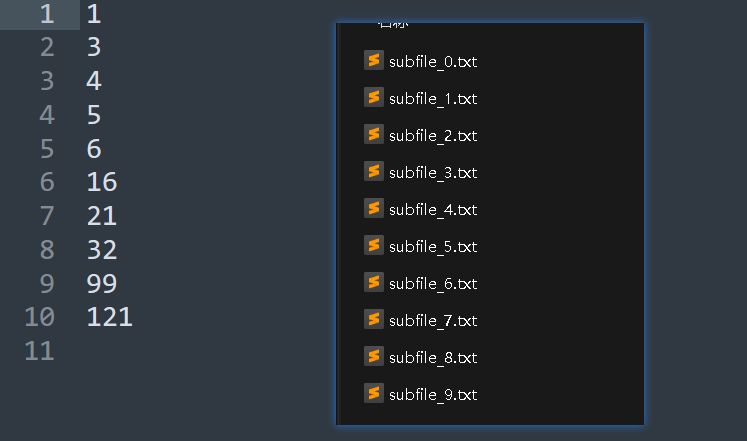
然后對這n份文件進行合并,實現整體有序,兩兩合并,可以如下圖也可以兩兩等分合并。
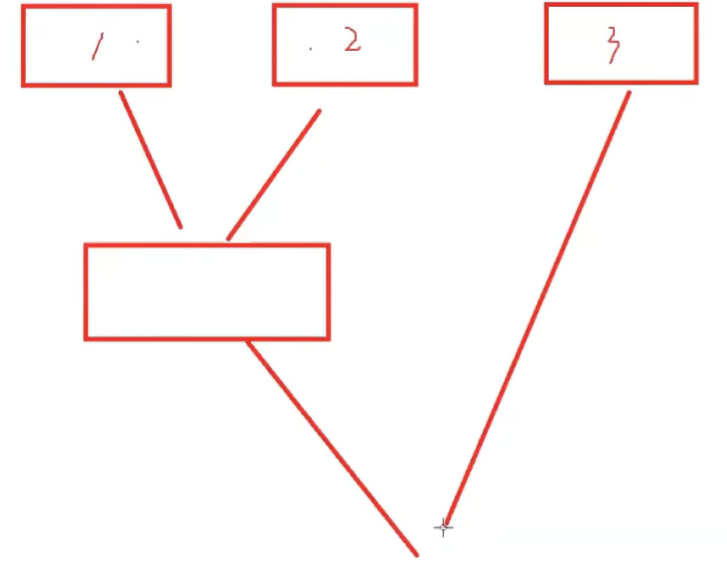
思路就是,有兩個小文件file1、file2作為臨時變量,首先合并形成m_file,然后將fiel2后移一位到下一個文件,file1變成m_file,繼續合并形成新的m_file。
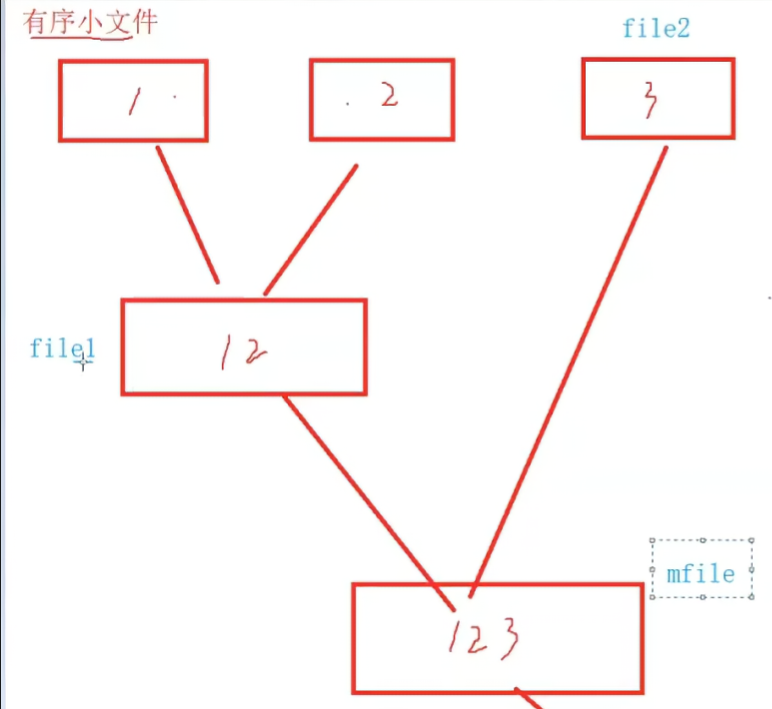
4.2 思路
①每n個數據為一組(這里n=10),讀到n個的時候進行排序創建一個文件,那么100個數據就會有10個文件1-10;每一個文件需要先排序再寫入。
②使用三個變量,file1、file2、m_file用于存儲文件名,file1和file2合并之后寫死文件名為12;后面將合并后的數據給file1,修改m_file的文件名為:之前的文件名+i(當前下標+1,i從2開始),使其命名能夠逐步增加。
③依次迭代1+2的數據稱為新的file1再和迭代后新的file2繼續合并,最后的結果就是10個文件的最終排序結果。
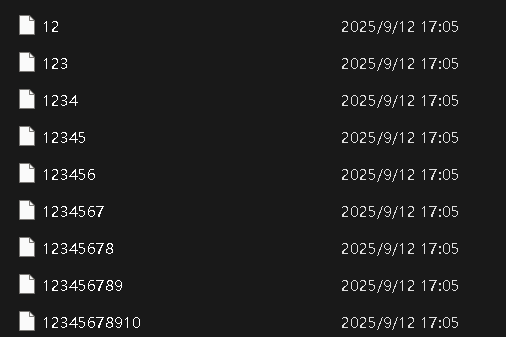
void _merge_file(const char* file1, const char* file2, const char* m_file)
{FILE* fout1 = fopen(file1, "r");if (fout1 == NULL){printf("文件打開失敗\n");exit(-1);}FILE* fout2 = fopen(file2, "r");if (fout2 == NULL){printf("文件打開失敗\n");exit(-1);}FILE* fin = fopen(m_file, "w");if (fin == NULL){printf("文件打開失敗\n");exit(-1);}int num1, num2;// 如果兩個文件都沒有讀完就繼續int ret1 = fscanf(fout1, "%d\n", &num1);int ret2 = fscanf(fout2, "%d\n", &num2);while (ret1 != EOF&& ret2 != EOF){if (num1 < num2){// nums1寫到m_filefprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);// fiel1的指針后移}else{fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);// fiel1的指針后移}}// 其中一個結束,另外一個按序寫入while (ret1 != EOF){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);// fiel1的指針后移}while (ret2 != EOF){fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);// fiel1的指針后移}fclose(fin);fclose(fout1);fclose(fout2);
}// 外排序,返回一個文件名
void file_sort(char* file)
{FILE* fout = fopen(file, "r");if (fout == NULL){printf("文件打開失敗\n");exit(-1);}int num = 0;int n = 10;// 將文件內容分成10份int arr[10];// 臨時存10個數int i = 0;char subfile[20];// 子文件名稱int id = 1; // 子文件下標while (fscanf(fout, "%d\n", &num) != EOF){if (i < n - 1) // 前n-1個數據{arr[i++] = num;}else{// 第十個arr[i] = num;// 滿10個了就排序merge_sort(arr, n);sprintf(subfile, "%d", id++);printf("%s", subfile);// 對每一個文件進行寫FILE* fin = fopen(subfile, "w");for (int i = 0; i < n; i++){fprintf(fin, "%d\n", arr[i]);}fclose(fin);i = 0;}}fclose(fout);// 讀取兩個文件char file1[100] = "1";char file2[100];char m_file[100] = "12"; // 合并的文件for (int i = 2; i <= n; i++){sprintf(file2, "%d.txt", i);// 讀取file1和file2,將合并內容放到m_file_merge_file(file1, file2, m_file);// file1變成mfilestrcpy(file1,m_file);sprintf(m_file, "%s%d", m_file,i+1); // 拼接}}int main()
{file_sort("sort.txt");}
:項目探索)
)

)


重點與易錯點全面總結)











