論文題目:LightThinker: Thinking Step-by-Step Compression
論文來源:EMNLP 2025,CCF B
論文作者:

論文鏈接:https://arxiv.org/abs/2502.15589
論文源碼:https://github.com/zjunlp/LightThinker
一、摘要
大語言模型(LLMs)在復雜推理任務中展現出卓越性能,但其效率受到生成冗長token所帶來的巨大內存和計算開銷的嚴重制約。本文提出了一種新穎的方法——LightThinker,使LLMs能夠在推理過程中動態壓縮中間思維步驟。受人類認知過程啟發,LightThinker將冗長的推理鏈壓縮為緊湊的表示,并丟棄原始推理鏈,從而顯著減少上下文窗口中存儲的token數量。該方法通過以下方式實現:構建訓練數據以指導模型學習何時以及如何壓縮;將隱藏狀態映射為少量“gist token”;并設計專門的注意力掩碼。此外,我們引入了依賴度(Dependency, Dep)指標,用于通過衡量生成過程中對歷史token的依賴程度來量化壓縮效果。我們在兩個模型和四個數據集上進行了大量實驗,結果表明,LightThinker在保持競爭力的準確率的同時,顯著降低了峰值內存使用和推理時間。本研究為在不犧牲性能的前提下提升 LMs在復雜推理任務中的效率提供了新的方向。
二、Introduction(簡潔版)
問題:“慢思考”雖提升推理準確率,卻生成大量中間token,導致KV緩存爆炸、推理延遲飆升。
動機:受人類“只寫關鍵步驟、腦中壓縮其余”啟發,讓模型邊推理邊壓縮,兼顧性能與效率。
方法(提出LightThinker):
- 數據層面:插入特殊token教會模型何時壓縮;
- 模型層面:用gist token隱藏狀態壓縮思維鏈;
- 訓練層面:設計注意力掩碼實現壓縮與繼續推理的解耦;
- 評估層面:引入Dep指標量化壓縮程度。
貢獻:
- 首次提出“動態壓縮推理鏈”的端到端方法;
- 在4個數據集、2個模型上驗證:峰值token↓70%,推理時間↓26%,準確率僅↓1%;
- 提供新的LLM推理加速思路,兼顧效率與性能。
三、相關工作
當前加速LLM推理的研究主要集中在三類方法:模型量化、減少生成token數量,以及縮減KV緩存。模型量化包括參數量化(Lin et al., 2024)和KV緩存量化(Liu et al., 2024b)。值得注意的是,生成長文本與理解長文本是兩種不同場景,因此專門針對“預填充階段”的加速技術(如 AutoCompressor、ICAE、LLMLingua、Activation Beacon、SnapKV、PyramidKV 等)本文不作討論。受篇幅限制,以下重點介紹后兩類方法。
3.1 減少生成token數量
- 離散token縮減:通過提示工程(Han et al., 2024)、指令微調(Liu et al., 2024a)或強化學習(Arora & Zanette, 2025)引導模型在推理時使用更少的離散token。
- 連續token替代:用連續空間的向量代替離散詞表token(如 CoConut)。
- 零token推理:把推理過程內化到模型層間,直接生成最終答案(Deng et al., 2023, 2024)。
這三種策略無需推理時額外干預,但加速效果越好,模型泛化性能下降越明顯,且第一種對顯存節省有限。
3.2 縮減KV緩存
- 基于剪枝的策略:為每個token設計顯式淘汰規則,保留重要token(StreamingLLM、H2O、SepLLM)。
- 基于融合的策略:引入anchor token,訓練模型把歷史關鍵信息壓縮進這些token,實現KV緩存融合(AnLLM)。
二者均需推理時干預;區別在于前者無需訓練卻需逐token判斷,后者需訓練但由模型自主決定何時壓縮。
四、方法(簡潔版)
LightThinker的核心思想是:在推理過程中,讓模型自動判斷何時壓縮當前的冗長思維鏈,將其壓縮成少量“gist tokens”(壓縮標記),并丟棄原始長文本,只保留壓縮后的信息繼續推理。下圖為LightThinker的方法框架圖
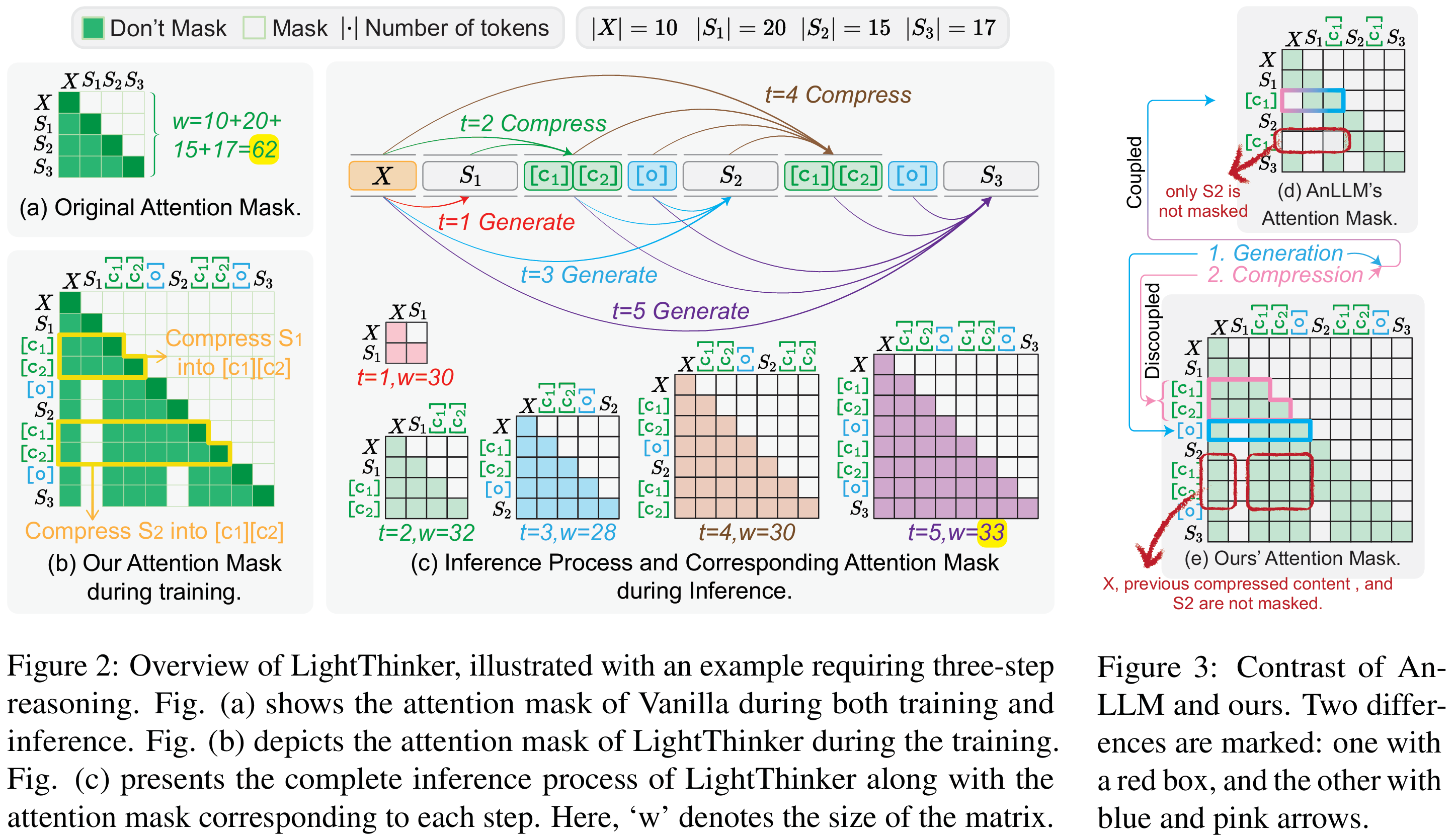
LightThinker涉及到的兩個關鍵問題是何時壓縮,以及如何壓縮?整個過程可以概括為以下三個關鍵步驟:
第一步:數據重構——在思考流程中植入壓縮指令
LightThinker的第一步是改造訓練數據,讓LLM明白“壓縮”的存在和時機。具體操作是:
- 步驟劃分:首先,將模型原本冗長的完整回答Y,按照語義或段落(即一個完整的「想法」)切分成若干個思維步驟S1, S2, S3, ...。
- 插入特殊指令符:在這些思維步驟之間,插入一組特殊的指令令牌。這組指令符主要包含兩個部分:
- 緩存令牌(Cache Tokens, [c]):這是一組特殊的、用于存儲壓縮后信息的摘要令牌。它的作用就像是為即將產生的思想摘要預留的空白便簽。
- 輸出令牌(Output Token, [o]):這是一個強制性的輸出信號,它的作用是告訴模型:“好了,摘要寫完了,現在請基于這份摘要繼續你下一步的思考”。
經過這樣的改造,原本一條完整的思考鏈,就變成了一個「思考步驟S1 →?進行壓縮?→ 繼續思考步驟S2 →?再次壓縮?→ ...」的全新格式。這等于是在模型的學習材料中明確地標注出了何時需要進行壓縮。注意,研究者在具體實現中,采用換行符作為思維步驟的劃分,此處不存在任何數據精心構造的過程。
第二步:注意力改造——學會壓縮與理解壓縮的內容
教會了模型何時壓縮,下一步就是最關鍵的如何壓縮。第二步這主要通過一種名為Thought-based Attention Mask的技術來實現,如Figure2 (b)所示。它能夠精確地控制著模型在思考時 “能看什么” 和 “不能看什么” 。這個過程分為兩個階段:
- 壓縮階段(生成思維摘要)。當模型需要將思維步驟Si壓縮進緩存令牌C時,注意力掩碼會強制這些C令牌只能看到三個東西:最初的問題X、先前已經壓縮好的歷史摘要、當前正在處理的思維步驟Si。其他所有原始的、未壓縮的思維步驟都會被遮蔽。這迫使模型必須將Si中的所有關鍵信息高度濃縮并存儲到C中 。
- 生成階段(基于摘要生成思維)。當思維步驟Si被成功壓縮進C之后,更關鍵的一步來了。在生成下一個思緒片段S(i+1)時,注意力掩碼會徹底遮蔽掉原始的思維步驟Si。此時,模型只能看到最初的問題X和包括剛剛生成的摘要在內的所有歷史摘要 。
通過這種方式,模型被迫學會僅依賴緊湊的思想摘要來進行連貫的、層層遞進的推理,而不是依賴越來越長的原始思考全文。
第三步:動態推理——即用即棄的高效循環
經過以上兩個步驟的訓練,LightThinker模型在實際推理時,就會形成一種高效的動態循環,如Figure 1?(b) 和Figure 2 (c) 所示,清晰地展示了“生成→壓縮→拋棄”的動態循環過程。下面以Figure 1 (b)為例進行分析:
- 模型接收問題,生成第一段思考(Thought 1)。
- 觸發壓縮,將Thought 1中的核心信息壓縮成緊湊的摘要(C T1)。
- 拋棄原文,將冗長的Thought 1從上下文中丟棄。
- 模型基于問題和摘要(C T1),生成第二段思考(Thought 2)。
- 再次壓縮,將Thought 2壓縮為摘要(C T2),并丟棄Thought 2原文。
- 如此循環,直到問題解決。
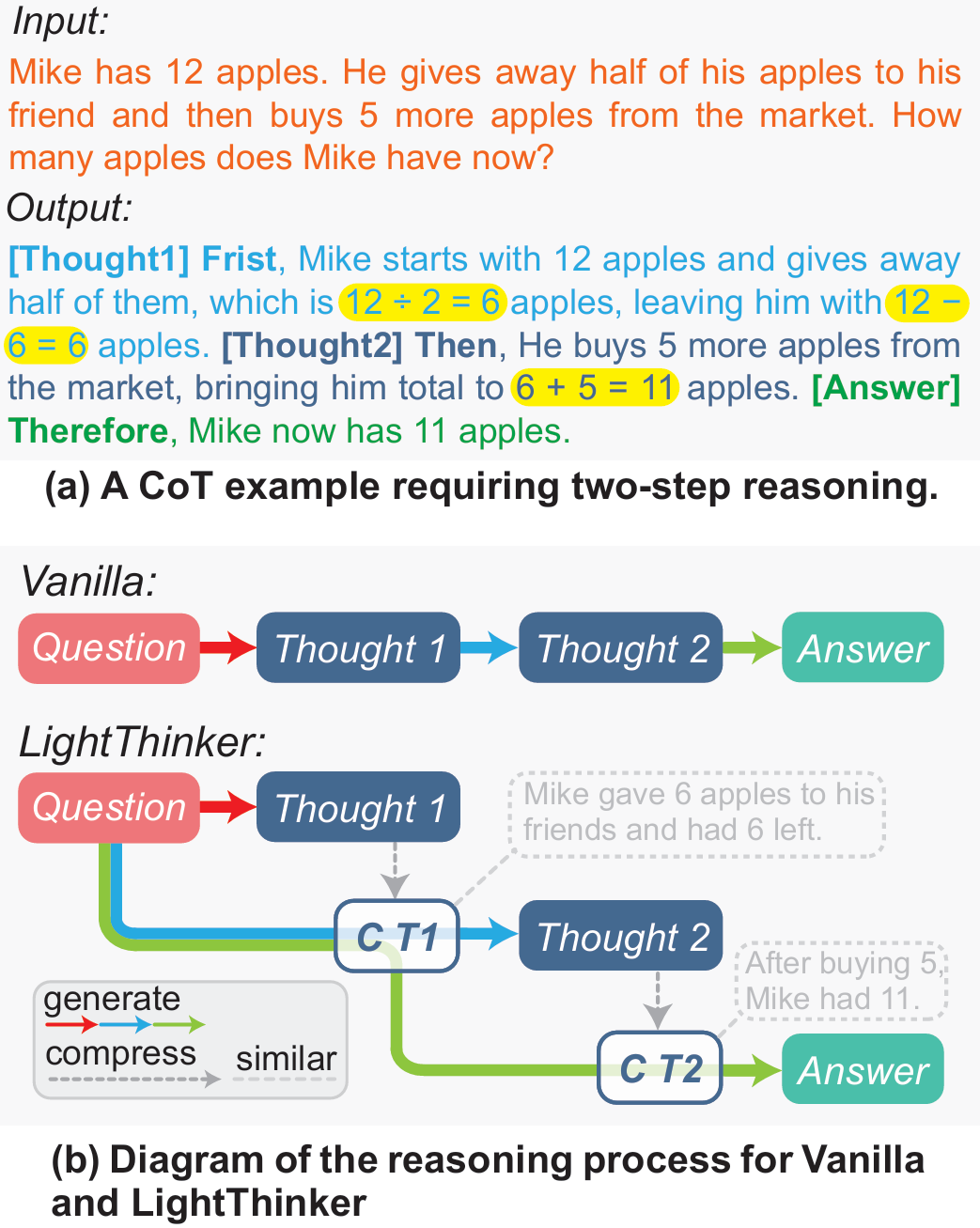
圖1?LightThinker與原始CoT的區別
(a) 例子展示冗余性。標準CoT會生成完整句子:“Mike starts with 12 apples … gives away half … buys 5 more …”。黃色高亮的才是“真正影響答案”的關鍵數字與運算;其余token僅維持語言流暢,可被壓縮。
(b) 流程對比:
- Vanilla:從頭到尾保留整條推理鏈(Thought 1 → Thought 2 → Answer),token 數隨步驟線性增長。
- LightThinker:每產生一段Thought i后,立即將其壓縮成極短的gist token C_Ti,并丟棄原長文本;后續推理只依賴這些壓縮表示。結果上下文里始終只有“問題 + 若干gist token”,顯著降低KV緩存。
通過這種“即用即棄”的機制,LightThinker確保了模型的上下文窗口始終保持在一個非常小的尺寸,從而解決了因上下文過長導致的內存爆炸和計算緩慢問題,實現了效率與性能的完美平衡。
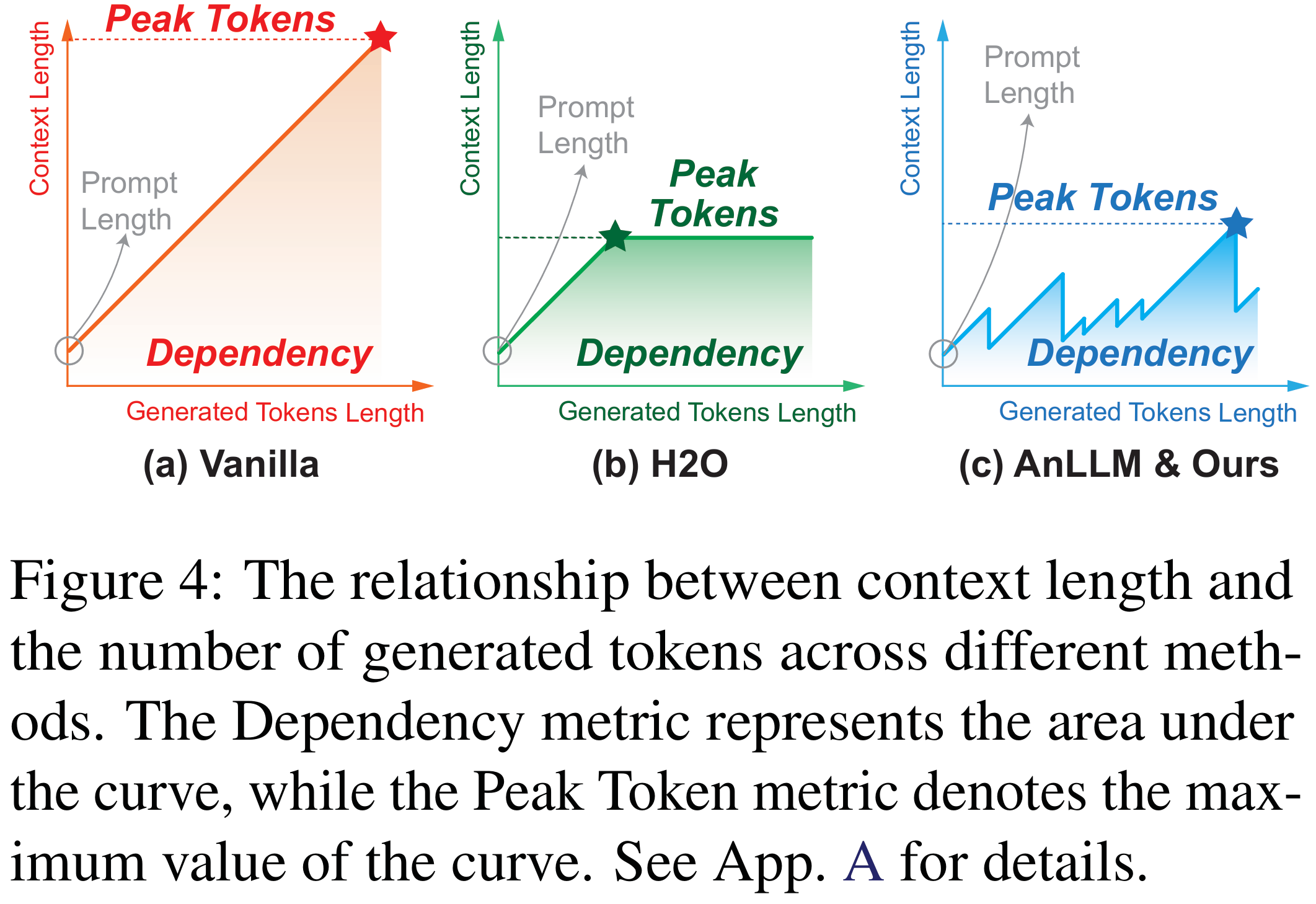
下圖展示了不同方法在推理過程中上下文長度的變化,其中曲線和坐標軸圍城的面積為我們定義的新指標Dependency,其意義生成token時需要關注token的數量總和。
五、實驗(簡潔版)
5.1 主要實驗
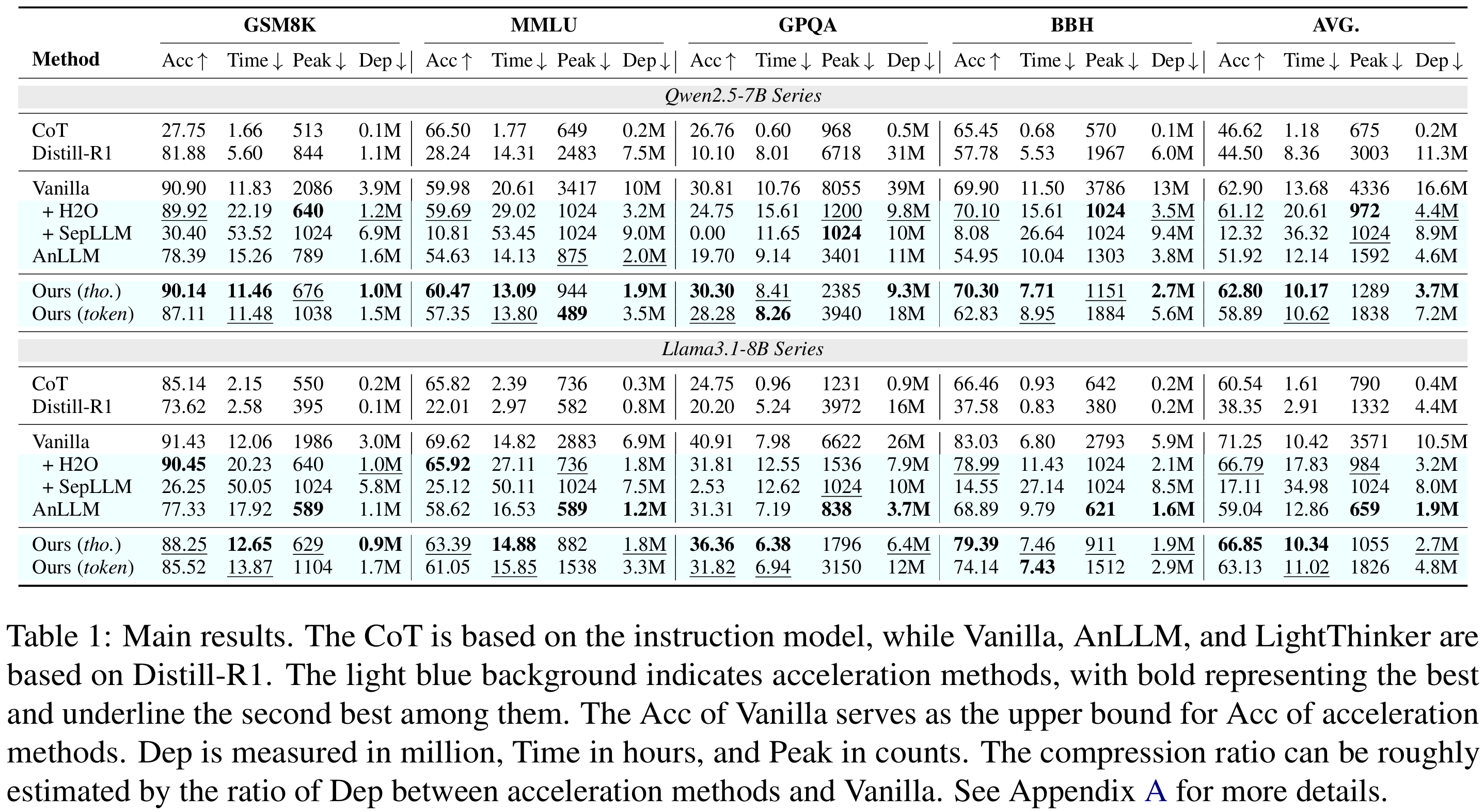
在Qwen-7B與Llama-8B上,LightThinker(thought級)以僅犧牲1-6個百分點的準確率為代價,將峰值token使用量降低約70%,推理時間縮短26%-41%,依賴度Dep(壓縮比)提升3.9-4.5倍,全面優于H2O、SepLLM、AnLLM等基線,在準確率與效率之間取得最佳平衡。
5.2 效率(Efficiency)
- 生成token數反而比Vanilla少13~15%。
- 32k token長文本推理時間省44%。
5.3 消融(Ablation)
- 解耦token + 專用注意力掩碼合計帶來9%準確率提升。
- 增大gist token數|C| → 準確率↑、壓縮頻率↓、生成token↓。
5.4??Case Study
- 壓縮漏掉關鍵數字會導致最終答案錯誤,提示需更好處理數值信息。
六、結論
本文提出LightThinker,一種通過在生成過程中動態壓縮中間思維鏈來提升大語言模型復雜推理效率的新方法。通過訓練模型學習何時、如何將冗長的思維步驟壓縮為緊湊表示,LightThinker在顯著降低內存占用與計算成本的同時,仍保持了具有競爭力的準確率。我們引入了Dependency(Dep)指標,用于統一量化不同加速方法的壓縮程度。大量實驗表明,LightThinker在效率與性能之間取得了良好平衡,為未來的LLM推理加速提供了新的思路。




(54))
![[嵌入式embed][Qt]Qt5.12+Opencv4.x+Cmake4.x_用Qt編譯linux-Opencv庫 測試](http://pic.xiahunao.cn/[嵌入式embed][Qt]Qt5.12+Opencv4.x+Cmake4.x_用Qt編譯linux-Opencv庫 測試)


)






)


)
