一 交叉驗證
1 保留交叉驗證HoldOut
holdOut Cross-validation(Train-Test Split)
在這種交叉驗證技術中,整個技術集被隨機劃分為訓練集和驗證集。
根據經驗法則,整個數據集的近70%被用作訓練集,其余30%被用作驗證集,也就是最常使用的直接劃分數據集的方法。
1.1 缺點
1、不適用不平衡的數據集
假設有不平衡的數據集,有0類和1類。其中80%屬于0類,20%屬于1類。也就是說,訓練集的大小為80%,測試數據的大小為數據集的20%。可能發生的情況是,所有80%的0類數據都在訓練集中,所有1類數據都在測試集中。那么模型不能很好地概括測試數據,原因也很簡單,就是在訓練的時候就沒見過1類數據,自然也識別不出來。
2、一大塊數據被剝奪了訓練模型的機會
在小數據集的情況下,有一部分數據被保留下來用于測試模型,這些數據可能具有重要的特征,模型可能因為沒有在被保留測試的數據上進行訓練而錯過。
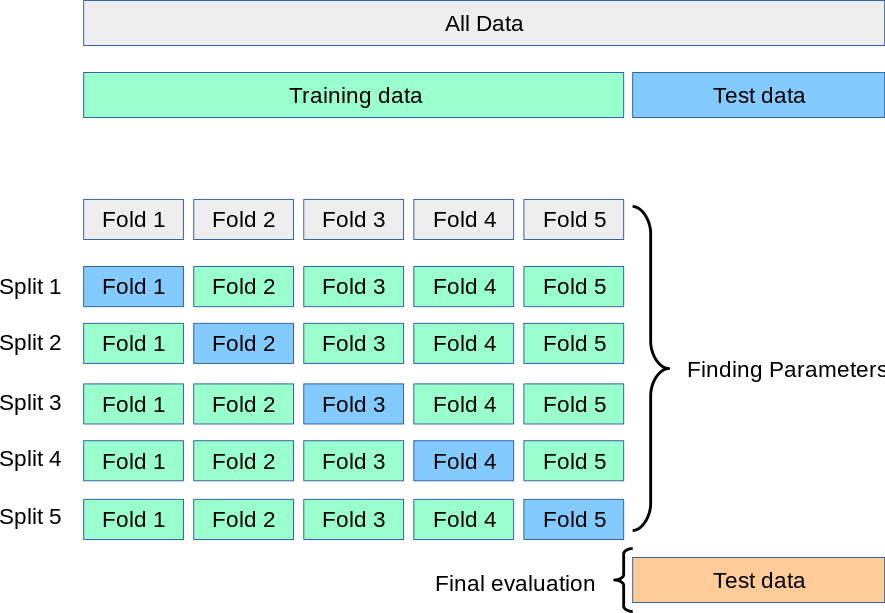
2 K-折交叉驗證(K-fold)
K-fold Cross Validation,記為K-CV或K-fold
K-Fold交叉驗證技術中,整個數據集被劃分為K個大小相同的部分。每個分區被稱為 一個”Fold”。所以我們有K個部分,我們稱之為K-Fold。一個Fold被用作驗證集,其余的K-1個Fold被用作訓練集。
該技術重復K次,直到每個Fold都被用作驗證集,其余的作為訓練集。
模型的最終準確度是通過取k個模型驗證數據的平均準確度來計算的。
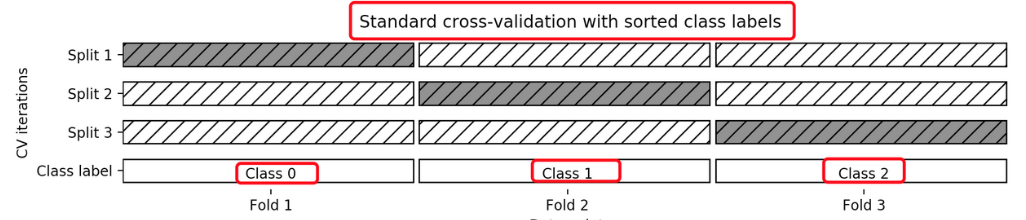
3?分層k-折交叉驗證Stratified k-fold
Stratified k-fold cross validation,
K-折交叉驗證的變種
分層是說在每一折中都保持著原始數據中各個類別的比例關系。
比如說:原始數據有3類,比例為1:2:1,采用3折分層交叉驗證,那么劃分的3折中,每一折中的數據類別保持著1:2:1的比例,這樣的驗證結果更加可信。
補充:去除p交叉驗證、留一交叉驗證、蒙特卡羅交叉驗證、時間序列交叉驗證
4 API
from sklearn.model_selection import StratifiedKFold普通K折交叉驗證和分層K折交叉驗證的使用是一樣的,只是引入的類不同
from sklearn.model_selection import KFold使用時只是KFold這個類名不一樣其他代碼完全一樣
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)n_splits劃分為幾個折疊 ? shuffle是否在拆分之前被打亂(隨機化),False則按照順序拆分 ?
random_state隨機因子indexs=strat_k_fold.split(X,y)返回一個可迭代對象,一共有5個折疊,每個折疊對應的是訓練集和測試集的下標
for train_index, test_index in indexs:X[train_index] y[train_index] X[test_index ] y[test_index ]用for循環取出每一個折疊對應的X和y下標來訪問到對應的測試數據集和訓練數據集 以及測試目標集和訓練目標集
5 代碼實例
'''使用StratifiedKFold來創建5個折疊,每個折疊中鳶尾花數據集的類別分布與整體數據集的分布一致。然后我們對每個折疊進行了訓練和測試,計算了分類器的準確性。'''
from sklearn.datasets import load_iris#加載鳶尾花數據集
from sklearn.model_selection import StratifiedKFold#分層K折交叉驗證,確保每折中各類別比例相同
from sklearn.neighbors import KNeighborsClassifier#K近鄰分類器
from sklearn.preprocessing import StandardScaler#書標準化處理器'''加載鳶尾花數據集
提取特征和標簽:
x:特征數據,150*4矩陣,包含4個特征
y:目標標簽,150*1向量,包含012三個類別'''
iris = load_iris()
X = iris.data
y = iris.target'''初始化分層k-折交叉驗證器
#n_splits劃分為幾個折疊 ,5個,80%訓練,20測試
shuffle是否在拆分之前被打亂(隨機化),True打亂順序,避免順序偏差,False則按照順序拆分
random_state隨機因子,確保結果可重現'''
strat_k_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)'''創建一個K近鄰分類器實例,使用7個最近鄰'''
knn = KNeighborsClassifier(n_neighbors=7)'''初始化準確率列表,用于存儲每次交叉驗證的準確率得分'''
accuracies = []'''開始交叉驗證循環
strat_k_fold.split(X,y)生成5對訓練集和測試機索引
每次循環得到一對索引train_index(訓練樣本索引)和test_index(測試樣本索引)'''
for train_index, test_index in strat_k_fold.split(X, y):print(train_index, test_index)#顯示每次折疊的訓練集和測試集樣本索引'''劃分訓練集和測試集,根據索引從完整數據中提取對應的特征和標簽'''X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]'''數據預處理(標準化)StandardScaler(): 創建標準化處理器(均值為0,標準差為1)fit_transform(X_train): 計算訓練集的均值和標準差,并轉換訓練集transform(X_test): 使用訓練集的參數來轉換測試集(避免數據泄露)'''scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)'''使用標準化的訓練數據來訓練K近鄰分類器'''knn.fit(X_train_scaled, y_train)'''計算在測試機的準確率,因為測試數據也需要標準化'''score = knn.score(X_test_scaled,y_test)print(score)'''把每次折疊的準確率并添加到列表中'''accuracies.append(score)'''輸出5次交叉驗證的平均準確率'''
print(sum(accuracies)/len(accuracies))結果:
[ ?0 ? 1 ? 2 ? 3 ? 4 ? 5 ? 6 ? 7 ? 8 ? 9 ?10 ?12 ?16 ?17 ?18 ?19 ?21 ?22
23 ?24 ?26 ?27 ?28 ?30 ?31 ?32 ?34 ?36 ?37 ?38 ?39 ?40 ?41 ?42 ?43 ?44
46 ?47 ?48 ?49 ?50 ?51 ?53 ?54 ?55 ?56 ?57 ?58 ?60 ?61 ?62 ?63 ?64 ?66
67 ?68 ?69 ?70 ?71 ?72 ?73 ?74 ?75 ?76 ?77 ?79 ?80 ?81 ?82 ?83 ?84 ?86
88 ?89 ?90 ?91 ?93 ?95 ?96 ?98 101 103 104 105 106 108 109 110 111 113
114 115 116 117 118 119 120 121 122 123 125 126 127 128 129 131 132 133
134 135 136 137 140 141 142 143 145 146 147 149] [ 11 ?13 ?14 ?15 ?20 ?25 ?29 ?33 ?35 ?45 ?52 ?59 ?65 ?78 ?85 ?87 ?92 ?94
97 ?99 100 102 107 112 124 130 138 139 144 148]
0.9666666666666667
[ ?1 ? 2 ? 3 ? 5 ? 6 ? 7 ? 8 ?11 ?12 ?13 ?14 ?15 ?16 ?17 ?18 ?20 ?22 ?23
24 ?25 ?26 ?27 ?28 ?29 ?30 ?32 ?33 ?34 ?35 ?36 ?37 ?38 ?39 ?41 ?43 ?44
45 ?46 ?48 ?49 ?50 ?51 ?52 ?53 ?54 ?55 ?56 ?57 ?59 ?61 ?62 ?63 ?64 ?65
66 ?67 ?69 ?70 ?71 ?72 ?73 ?76 ?77 ?78 ?79 ?81 ?83 ?84 ?85 ?86 ?87 ?88
91 ?92 ?93 ?94 ?95 ?97 ?98 ?99 100 101 102 103 104 105 107 112 113 115
116 117 118 119 122 123 124 125 126 127 128 129 130 131 132 133 134 135
137 138 139 140 141 142 143 144 145 146 147 148] [ ?0 ? 4 ? 9 ?10 ?19 ?21 ?31 ?40 ?42 ?47 ?58 ?60 ?68 ?74 ?75 ?80 ?82 ?89
90 ?96 106 108 109 110 111 114 120 121 136 149]
0.9666666666666667
[ ?0 ? 1 ? 2 ? 3 ? 4 ? 5 ? 8 ? 9 ?10 ?11 ?12 ?13 ?14 ?15 ?16 ?17 ?18 ?19
20 ?21 ?23 ?24 ?25 ?26 ?28 ?29 ?31 ?32 ?33 ?35 ?36 ?37 ?39 ?40 ?42 ?43
45 ?46 ?47 ?49 ?51 ?52 ?53 ?54 ?55 ?57 ?58 ?59 ?60 ?61 ?62 ?63 ?65 ?67
68 ?69 ?73 ?74 ?75 ?76 ?77 ?78 ?79 ?80 ?81 ?82 ?84 ?85 ?86 ?87 ?88 ?89
90 ?91 ?92 ?93 ?94 ?96 ?97 ?99 100 101 102 103 106 107 108 109 110 111
112 113 114 115 117 119 120 121 122 124 125 128 129 130 131 134 135 136
137 138 139 141 142 143 144 145 146 147 148 149] [ ?6 ? 7 ?22 ?27 ?30 ?34 ?38 ?41 ?44 ?48 ?50 ?56 ?64 ?66 ?70 ?71 ?72 ?83
95 ?98 104 105 116 118 123 126 127 132 133 140]
0.9
[ ?0 ? 3 ? 4 ? 5 ? 6 ? 7 ? 9 ?10 ?11 ?13 ?14 ?15 ?16 ?17 ?18 ?19 ?20 ?21
22 ?25 ?26 ?27 ?29 ?30 ?31 ?33 ?34 ?35 ?36 ?38 ?39 ?40 ?41 ?42 ?43 ?44
45 ?46 ?47 ?48 ?50 ?52 ?53 ?54 ?56 ?57 ?58 ?59 ?60 ?62 ?64 ?65 ?66 ?68
70 ?71 ?72 ?73 ?74 ?75 ?76 ?77 ?78 ?80 ?81 ?82 ?83 ?85 ?86 ?87 ?89 ?90
92 ?93 ?94 ?95 ?96 ?97 ?98 ?99 100 101 102 103 104 105 106 107 108 109
110 111 112 113 114 116 118 119 120 121 123 124 126 127 130 131 132 133
134 136 137 138 139 140 141 143 144 146 148 149] [ ?1 ? 2 ? 8 ?12 ?23 ?24 ?28 ?32 ?37 ?49 ?51 ?55 ?61 ?63 ?67 ?69 ?79 ?84
88 ?91 115 117 122 125 128 129 135 142 145 147]
1.0
[ ?0 ? 1 ? 2 ? 4 ? 6 ? 7 ? 8 ? 9 ?10 ?11 ?12 ?13 ?14 ?15 ?19 ?20 ?21 ?22
23 ?24 ?25 ?27 ?28 ?29 ?30 ?31 ?32 ?33 ?34 ?35 ?37 ?38 ?40 ?41 ?42 ?44
45 ?47 ?48 ?49 ?50 ?51 ?52 ?55 ?56 ?58 ?59 ?60 ?61 ?63 ?64 ?65 ?66 ?67
68 ?69 ?70 ?71 ?72 ?74 ?75 ?78 ?79 ?80 ?82 ?83 ?84 ?85 ?87 ?88 ?89 ?90
91 ?92 ?94 ?95 ?96 ?97 ?98 ?99 100 102 104 105 106 107 108 109 110 111
112 114 115 116 117 118 120 121 122 123 124 125 126 127 128 129 130 132
133 135 136 138 139 140 142 144 145 147 148 149] [ ?3 ? 5 ?16 ?17 ?18 ?26 ?36 ?39 ?43 ?46 ?53 ?54 ?57 ?62 ?73 ?76 ?77 ?81
86 ?93 101 103 113 119 131 134 137 141 143 146]
0.9666666666666667
0.96
二 超參數搜索
超參數搜索也叫網格搜索(Grid Search)
例如,在KNN算法中,K是一個可以人為設置的參數,所以就是一個超參數。網格搜索能夠自動幫助我們找到最好的超參數值。

三 Sklearn API
同時進行交叉驗證(cv)、網絡搜索(GridSearch)
GridSearchCV實際上也是一個估計器(estimator),它有幾個重要屬性:
估計器(estimator),同時它有幾個重要屬性:
best_params_ ?最佳參數
best_score_ 在訓練集中的準確率
best_estimator_ 最佳估計器
cv_results_ 交叉驗證過程描述
best_index_最佳k在列表中的下標
class sklearn.model_selection.GridSearchCV(estimator, param_grid)參數:
estimator:scikit-learn估計器實例;
param_grid:以參數名稱(str)作為鍵,將參數設置列表嘗試作為值的字典;
示例:
{"n_neighbors": [1, 3, 5, 7, 9, 11]}
cv: 確定交叉驗證切分策略,值為:
(1)None ?默認5折
(2)integer ?設置多少折
如果估計器是分類器,使用"分層k-折交叉驗證(StratifiedKFold)"。在所有其他情況下,使用KFold。
四 代碼實例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVdef knn_iris_gscv():# 1)獲取數據iris = load_iris()# 2)劃分數據集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)# 3)特征工程:標準化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)KNN算法預估器, 這里就不傳參數n_neighbors了,交給GridSearchCV來傳遞estimator = KNeighborsClassifier()# 加入網格搜索與交叉驗證, GridSearchCV會讓k分別等于1,2,5,7,9,11進行網格搜索償試。cv=10表示進行10次交叉驗證estimator = GridSearchCV(estimator, param_grid={"n_neighbors": [1, 3, 5, 7, 9, 11]}, cv=10)estimator.fit(x_train, y_train)# 5)模型評估# 方法1:直接比對真實值和預測值y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率score = estimator.score(x_test, y_test)print("在測試集中的準確率為:\n", score) #0.9736842105263158# 最佳參數:best_params_print("最佳參數:\n", estimator.best_params_) #{'n_neighbors': 3}, 說明k=3時最好# 最佳結果:best_score_print("在訓練集中的準確率:\n", estimator.best_score_) #0.9553030303030303# 最佳估計器:best_estimator_print("最佳估計器:\n", estimator.best_estimator_) # KNeighborsClassifier(n_neighbors=3)# 交叉驗證結果:cv_results_print("交叉驗證過程描述:\n", estimator.cv_results_)#最佳參數組合的索引:最佳k在列表中的下標print("最佳參數組合的索引:\n",estimator.best_index_)#通常情況下,直接使用best_params_更為方便return Noneknn_iris_gscv()五 補充
20 新聞KNN,加GridSearchCV


)


)



添加管道,實現管道流動效果)

![[吾愛出品] 圖片轉換王 v1.01 - 多格式支持 / 支持pds、Ai格式](http://pic.xiahunao.cn/[吾愛出品] 圖片轉換王 v1.01 - 多格式支持 / 支持pds、Ai格式)



)
(3) RTL實現實戰)

)
