VideoMage:文本生成視頻擴散模型的多主體與動作定制化
paper title:VideoMage: Multi-Subject and Motion Customization
of Text-to-Video Diffusion Models
paper是National Taiwan University發表在CVPR 2025的工作
Code:鏈接

圖1. 多主體與動作定制化示意圖。給定多個主體的圖像、一個參考動作視頻以及相關的文本提示,我們的 VideoMage 能夠生成與這些輸入相匹配的視頻輸出。
Abstract
定制化文本生成視頻的目標是生成高質量的視頻,其中融入用戶指定的主體身份或動作模式。然而,現有方法主要集中于個性化單一概念,即主體身份或動作模式,這限制了它們在處理多個主體及其期望動作模式時的效果。為了解決這一挑戰,我們提出了一個統一的框架 VideoMage,用于同時在多個主體及其交互動作上進行視頻定制。VideoMage 使用主體 LoRA 和動作 LoRA,從用戶提供的圖像和視頻中捕捉個性化內容,并通過一種與外觀無關的動作學習方法,將動作模式從視覺外觀中解耦。此外,我們設計了一種時空組合方案,用于在期望動作模式下引導主體之間的交互。大量實驗表明,VideoMage 優于現有方法,能夠生成連貫的、用戶可控的視頻,并保持主體身份與交互的一致性。
1. Introduction
近年來,擴散模型 [17, 37, 38] 取得了前所未有的成功,大大提升了從文本描述生成照片級真實感視頻 [3, 16, 18, 19, 35] 的能力,使視頻內容創作有了新的可能性。然而,盡管現在可以合成高質量和多樣化的視頻,僅依靠文本描述無法對所需內容進行精確控制,難以與用戶意圖準確對齊 [24]。因此,從用戶提供的參考資料中定制用戶特定的視頻概念,受到了學術界和工業界的廣泛關注。
為了解決這一挑戰,一些工作 [14, 24, 43, 44] 探索了將所需主體身份定制到合成視頻中的方法。例如,AnimateDiff [14] 通過在預訓練圖像擴散模型中插入時間模塊并對其進行調優,使用戶提供的主體實現動畫化。VideoBooth [24] 進一步采用跨幀注意力機制來保留定制主體的細粒度視覺外觀。此外,CustomVideo [43] 在所有涉及的主體上同時微調跨注意力層,以在一個場景中定制多個主體。然而,這些方法僅關注靜態主體的定制。它們無法為用戶或視頻創作者提供將所需動態動作(如特定舞蹈風格)個性化到輸出視頻中的能力,嚴重限制了視頻內容定制的靈活性。
另一方面,為了賦予用戶對動態動作的可控性,近期一些方法 [23, 28, 32, 48, 51] 設計了模塊來捕捉來自參考視頻的動作模式。例如,Customize-A-Video [32] 在時間注意力層中插入低秩適配(LoRA)[21] 并對其進行微調,以學習所需的動作模式。類似地,MotionDirector [51] 通過使用一個捕捉錨幀與其他幀差異的目標,利用 LoRA 來學習動作。然而,僅僅調優時間模塊而沒有正確地從參考視頻中解耦動作信息,會導致嚴重的外觀泄漏問題,進而產生的動作模式無法應用于任意主體身份。此外,在缺乏對主體和動作組合的引導下,模型難以精確控制這些定制視頻概念之間的交互。因此,上述方法只能處理單一(即主體或動作)的概念定制。通過自由形式的提示同時定制多個主體和所需動作模式,仍然是一個具有挑戰性且尚未解決的問題。
在本文中,我們提出了 VideoMage,一個統一的視頻內容定制框架,它能夠對主體身份和動作模式實現可控性。VideoMage 引入了主體和動作 LoRA,從用戶提供的圖像和視頻中捕捉各自的信息。為確保動作 LoRA 不會被視覺外觀污染,我們提出了一種與外觀無關的動作學習方法,從參考視頻中分離動作模式。更具體地說,我們采用了基于視覺外觀的負向無分類器引導 [12, 22],有效地將動作與外觀細節解耦。通過學習到的主體和動作 LoRA,我們提出了一種時空協同組合機制,以引導多個主體在所需動作模式下的交互。我們進一步引入基于梯度的融合和空間注意力正則化,以吸收多主體信息,同時鼓勵主體的空間排列保持區分性。通過迭代地使用主體和動作 LoRA 引導生成過程,VideoMage 合成的視頻具有更強的用戶可控性和時空一致性。
我們在此總結本文的貢獻如下:
- 我們提出了 VideoMage,一個統一的框架,首次實現了多主體身份及其交互動作的視頻概念定制。
- 我們引入了一種新穎的與外觀無關的動作學習方法,通過改進的負向無分類器引導,將潛在動作模式與外觀解耦。
- 我們提出了一種時空協同組合機制,用于組合獲得的多主體和動作 LoRA,以在所需動作模式下生成一致的多主體交互。
2. Related Works
2.1. Text-to-Video Generation
近年來,文本生成視頻取得了顯著進展。其方法從早期基于生成對抗網絡(GANs)[34, 36, 40, 41] 和自回歸 Transformer [20, 45, 46, 49],發展到近期的擴散模型 [3, 7, 18, 19, 35, 42],大大提升了生成視頻的質量與多樣性。開創性工作如 VDM [19] 和 Imagen-Video [18] 在像素空間中建模視頻擴散過程,而 LVDM [16] 和 VideoLDM [3] 則在潛在空間中建模,以優化計算效率。為了解決缺乏配對視頻-文本數據的挑戰,Make-A-Video [35] 利用圖生文先驗實現了文本生成視頻。另一方面,開源模型如 VideoCrafter [7]、ModelScopeT2V [42] 和 Zero-Scope [39] 融入了時空模塊以增強文本生成視頻的能力,展現出生成高保真視頻的顯著性能。這些強大的文本到視頻擴散模型推動了定制化內容生成的發展。
2.2. Video Content Customization
主體定制。近年來,定制化生成受到了廣泛關注,尤其是在圖像合成領域 [11, 26, 33]。基于這些進展,近期的研究逐漸聚焦于視頻主體定制 [6, 8, 14, 24, 43, 44],這更具挑戰性,因為需要在動態場景中生成主體。例如,AnimateDiff [14] 在預訓練的圖像擴散模型中插入了額外的動作模塊,使得自定義主體能夠實現動畫化。此外,VideoBooth [24] 采用跨幀注意力機制來保留定制主體的細粒度視覺外觀。最近,CustomVideo [43] 在所有相關主體上微調跨注意力層,以實現多主體定制。然而,這些方法往往只能產生輕微的主體動作 [44, 47],缺乏用戶可控性,無法實現對動作的精確控制。
動作定制。給定少量描述目標動作模式的參考視頻,動作定制 [23, 28, 32, 44, 48, 51] 旨在生成能夠復現目標動作的視頻。例如,Customize-A-Video [32] 在時間注意力層中集成低秩適配(LoRA)[21] 并對其進行微調,以從參考視頻中捕捉特定的動作模式。類似地,MotionDirector [51] 通過微調 LoRA 來學習動作,其方法是捕捉錨幀與其他幀之間的差異,從而有效地將動態行為遷移到生成的視頻內容中。最新的研究 DreamVideo [44] 探索了單一主體執行特定動作的定制化,其方法是分別在空間層和時間層中加入身份適配器(ID adapter)和動作適配器(motion adapter)。然而,外觀泄漏問題以及缺乏對主體與動作組合的合理引導,阻礙了這些方法生成多主體交互的視頻。因此,利用任意主體和動作模式定制視頻內容的靈活性受到嚴格限制。為賦予用戶對主體與動作視頻概念更強的可控性,我們采用了獨特的 VideoMage 框架,以實現多個定制主體身份之間的所需交互。
3. Method
問題表述。我們首先定義設置和符號。給定NNN個主體,每個主體由3-5張圖像表示,記作xs,ix_{s,i}xs,i?表示第iii個主體(為簡化省略單個圖像索引),一個參考交互動作視頻xmx_mxm?,以及用戶提供的文本提示ctgtc_{tgt}ctgt?,我們的目標是基于ctgtc_{tgt}ctgt?生成一個視頻,其中這NNN個主體按照動作模式進行交互。為了解決上述問題,我們提出了VideoMage,這是一個統一框架,用于定制多個主體和交互動作的文本生成視頻。通過對視頻擴散模型的快速回顧(第3.1節),我們詳細說明了如何利用LoRA模塊分別從輸入圖像和參考視頻中學習視覺和動作信息(第3.2節)。不同于簡單的組合方式,我們提出了一種獨特的時空協同組合機制,用于整合學習到的主體/動作LoRA以進行視頻生成(第3.3節)。
3.1. Preliminary: Video Diffusion Models
視頻擴散模型(VDMs)[3, 16, 18, 19, 35] 旨在通過逐步去噪從高斯分布采樣的一系列噪聲來生成視頻 [17]。具體而言,擴散模型?θ\epsilon_\theta?θ?學習在每個時間步ttt預測噪聲?\epsilon?,其條件是輸入ccc,而ccc是在文本生成視頻中的文本提示。訓練目標簡化為一個重建損失:
L=Ex,?,t[∥?θ(xt,c,t)??∥22],(1)\mathcal{L} = \mathbb{E}_{x,\epsilon,t} \left[ \left\| \epsilon_\theta(x_t, c, t) - \epsilon \right\|_2^2 \right], \tag{1} L=Ex,?,t?[∥?θ?(xt?,c,t)??∥22?],(1)
其中噪聲?∈RF×H×W×3\epsilon \in \mathbb{R}^{F \times H \times W \times 3}?∈RF×H×W×3從N(0,I)\mathcal{N}(0,I)N(0,I)中采樣,時間步t∈U(0,1)t \in \mathcal{U}(0,1)t∈U(0,1),并且xt=αˉtx+1?αˉt?x_t = \sqrt{\bar{\alpha}_t}x + \sqrt{1-\bar{\alpha}_t}\epsilonxt?=αˉt??x+1?αˉt???
是ttt時刻的帶噪輸入,αˉt\bar{\alpha}_tαˉt?是控制擴散過程的一個超參數 [17]。為了降低計算成本,大多數VDMs [7, 16, 42] 將輸入視頻數據x∈RF×H×W×3x \in \mathbb{R}^{F \times H \times W \times 3}x∈RF×H×W×3 編碼為潛在表示(例如,通過VAE [25] 獲得)。為簡化起見,本文始終使用視頻數據xxx作為模型的輸入。
3.2. Subject and Motion Customization
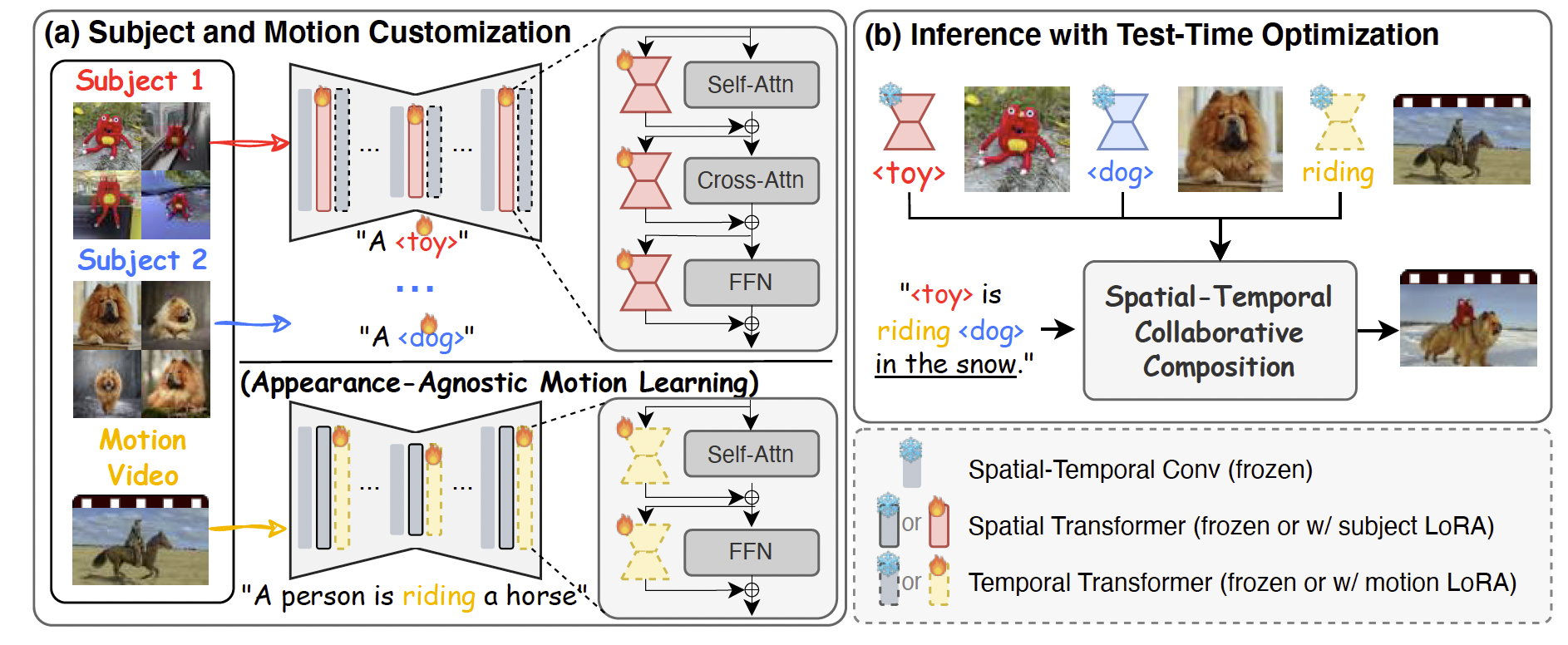
圖2. VideoMage 概覽。(a) 給定多個主體的圖像和一個包含期望動作的參考視頻,VideoMage 分別利用 LoRA 來捕捉視覺外觀知識和與外觀無關的動作信息。(b) 在包含上述視覺與動作概念的文本提示下,我們的時空協同組合機制對輸入的帶噪潛變量xtx_txt?進行優化,從而生成匹配期望視覺與動作信息的視頻。
視覺主體的學習。如圖2(a)頂部所示,為了在視頻生成中捕捉主體外觀,我們學習一個特殊的token(例如,“<toy>”),并使用主體LoRA(Δθs\Delta \theta_sΔθs?)對預訓練視頻擴散模型進行微調。為了避免干擾時間動態,主體LoRA僅應用于UNet的空間層。其目標函數定義為:
Lsub=Exs,?,t[∥?θs(xs,t,cs,t)??∥22],(2)\mathcal{L}_{sub} = \mathbb{E}_{x_s,\epsilon,t} \left[ \left\| \epsilon_{\theta_s}(x_s,t,c_s,t) - \epsilon \right\|_2^2 \right], \tag{2} Lsub?=Exs?,?,t?[∥?θs??(xs?,t,cs?,t)??∥22?],(2)
其中xs∈R1×H×W×3x_s \in \mathbb{R}^{1 \times H \times W \times 3}xs?∈R1×H×W×3是主體圖像,θs=θ+Δθs\theta_s = \theta + \Delta \theta_sθs?=θ+Δθs?表示施加了主體LoRA的預訓練模型參數,csc_scs?是包含特殊token的提示(例如,“A ”)。
然而,僅使用圖像數據進行微調可能導致視頻擴散模型喪失生成運動信息的能力。參考[47],我們利用一個輔助視頻數據集DauxD_{aux}Daux?(例如,Panda70M [9])來正則化微調過程,同時保留預訓練的動作先驗。更具體地,給定從DauxD_{aux}Daux?中采樣的視頻-字幕對(xaux,caux)(x_{aux}, c_{aux})(xaux?,caux?),其正則化損失定義為:
Lreg=Exaux,?,t[∥?θs(xaux,t,caux,t)??∥22].(3)\mathcal{L}_{reg} = \mathbb{E}_{x_{aux},\epsilon,t} \left[ \left\| \epsilon_{\theta_s}(x_{aux}, t, c_{aux}, t) - \epsilon \right\|_2^2 \right]. \tag{3} Lreg?=Exaux?,?,t?[∥?θs??(xaux?,t,caux?,t)??∥22?].(3)
因此,總體目標函數定義為:
L=Lsub+λ1Lreg,(4)\mathcal{L} = \mathcal{L}_{sub} + \lambda_1 \mathcal{L}_{reg}, \tag{4} L=Lsub?+λ1?Lreg?,(4)
其中λ1\lambda_1λ1?是控制正則化損失權重的超參數。優化該目標能夠捕捉主體外觀,同時保留動作先驗。通過我們的訓練目標,我們能夠在不損害VDM能力的情況下,支持用戶提供的主體身份的定制。然而,微調后的VDM在從參考視頻中精確控制動作模式方面仍具有挑戰性,從而限制了用戶的靈活性與可控性。
與外觀無關的動作學習。為了從參考視頻xmx_mxm?中學習期望的動作模式,一個樸素的策略是微調動作LoRA,并將其注入UNet的時間層(即圖2(a)底部的Δθm\Delta \theta_mΔθm?)。然而,直接應用公式(1)中的標準擴散損失會導致外觀泄漏問題,即動作LoRA無意中捕捉到了參考視頻中主體的外觀。這種主體外觀與動作的糾纏阻礙了將學習到的動作模式應用到新主體的能力。
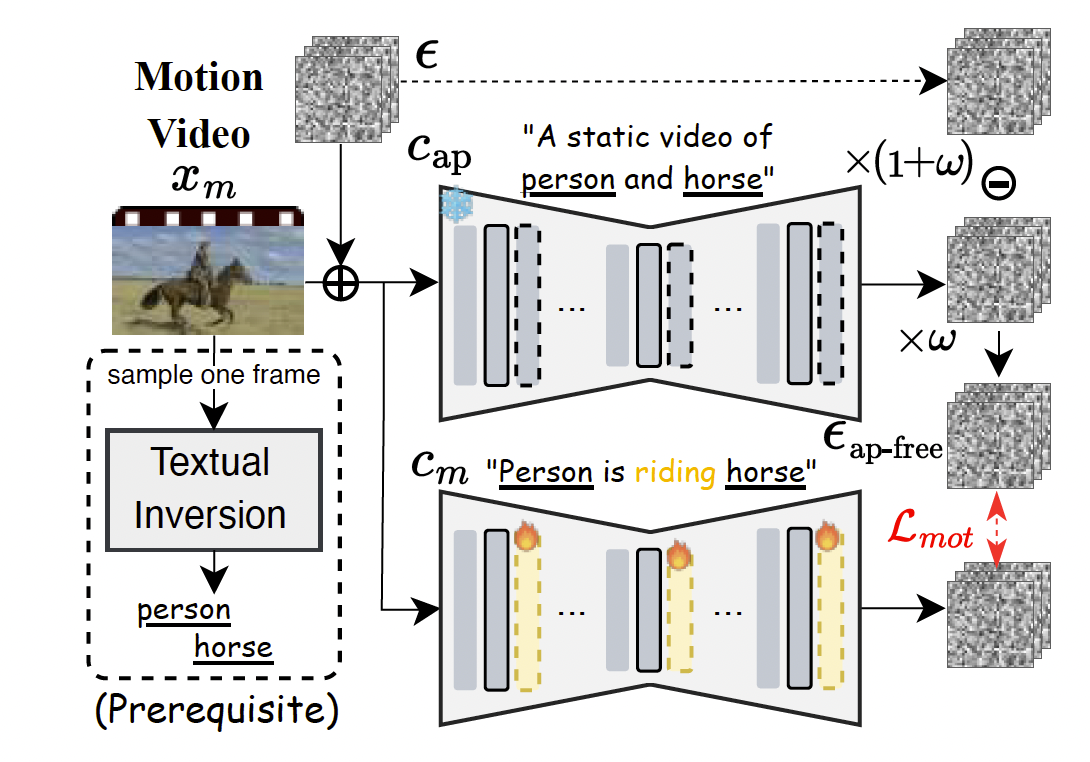
圖3. 與外觀無關的動作學習。通過利用強調外觀信息的文本提示(即capc_{ap}cap?),我們旨在通過所提出的負向無分類器引導提取與外觀無關的動作信息。
為了解決這一問題,我們提出了一種新穎的與外觀無關的目標(appearance-agnostic objective),如圖3所示,它能夠有效地將參考視頻中的動作模式與外觀隔離。受到概念擦除方法[12, 22]的啟發,我們提出了基于視覺主體外觀的負向無分類器引導(negative classifier-free guidance),專注于在動作學習過程中消除外觀信息。這確保了動作LoRA僅專注于動作動態。
為實現這一點,我們首先為參考視頻中的主體學習特殊token(例如圖3中的“person”和“horse”),方法是在參考視頻的一幀上應用文本反演[11]。這能夠捕捉主體外觀,同時最小化動作的影響,有效地實現外觀與動作的解耦。在獲得上述特殊token后,我們訓練動作LoRA,使用一個與外觀無關的目標函數,該目標通過負向引導抑制外觀信息,使動作LoRA能夠獨立于主體外觀學習動作模式。更具體地,訓練目標定義為:
Lmot=Exm,?,t[∥?θm(xm,t,cm,t)??ap-free∥22],\mathcal{L}_{mot} = \mathbb{E}_{x_m,\epsilon,t} \left[ \left\| \epsilon_{\theta_m}(x_m,t,c_m,t) - \epsilon_{\text{ap-free}} \right\|_2^2 \right], Lmot?=Exm?,?,t?[∥?θm??(xm?,t,cm?,t)??ap-free?∥22?],
其中
?ap-free=(1+ω)??ω?θ(xm,t,cap,t).(5)\epsilon_{\text{ap-free}} = (1+\omega)\epsilon - \omega \epsilon_\theta(x_m,t,c_{ap},t). \tag{5} ?ap-free?=(1+ω)??ω?θ?(xm?,t,cap?,t).(5)
注意,?ap-free\epsilon_{\text{ap-free}}?ap-free?是經過負向引導的無外觀噪聲,ω\omegaω是控制引導強度的超參數,cmc_mcm?和capc_{ap}cap?分別描述動作和靜態主體外觀(例如,“Person riding a horse”和“A static video of person and horse”)。
通過優化公式(5),動作LoRA能夠獨立于主體外觀學習動作模式。這種解耦對于在多個主體之間組合定制動作至關重要,我們將在后文進一步討論。
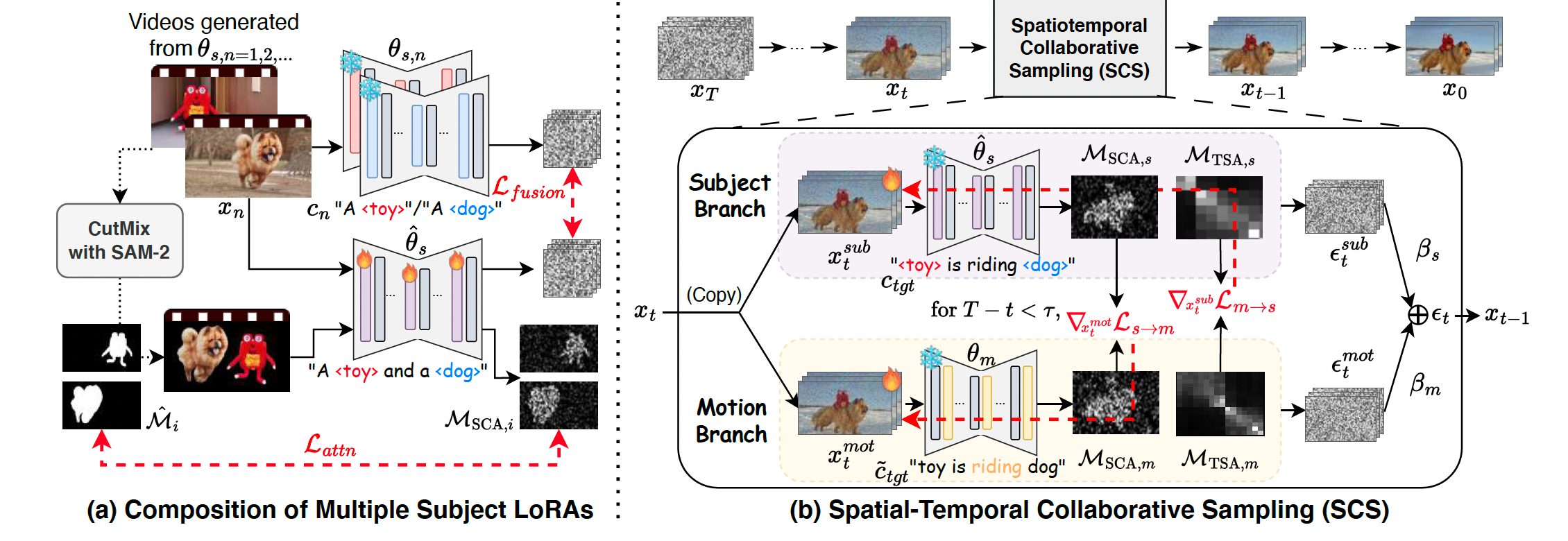
圖4. 用于T2V測試時優化的時空協同組合。(a) 測試時融合主體LoRA θ^s\hat{\theta}_sθ^s?,其采用注意力正則化Lattn\mathcal{L}_{attn}Lattn?以確保每個視覺主體的外觀得以保留。(b) 時空協同采樣(SCS)通過跨模態對齊,將融合的主體LoRA θ^s\hat{\theta}_sθ^s?與動作LoRA θm\theta_mθm?進行整合,從而確保視覺與時間上的一致性。
3.3. Spatial-Temporal Collaborative Composition
在獲得多個主體LoRA和一個交互式動作LoRA之后,我們的目標是生成這些主體按照期望動作模式進行交互的視頻。然而,結合具有不同屬性(即視覺外觀與時空動作)的LoRA并非一項簡單的任務。在本工作中,我們提出了一種測試時優化方案——時空協同組合(spatial-temporal collaborative composition),該方案能夠使上述LoRA之間進行協作,從而生成同時具備期望外觀和動作特性的視頻。下面我們將詳細討論所提出的方案。
多主體LoRA的組合。我們首先討論如何融合描述不同視覺主體信息的LoRA。我們采用基于梯度的融合方法 [13],將每個主體LoRA中的獨特身份特征提煉為一個單一的融合LoRA。即,給定多個LoRA,記作Δθs,1,Δθs,2,…,Δθs,N\Delta \theta_{s,1}, \Delta \theta_{s,2}, \ldots, \Delta \theta_{s,N}Δθs,1?,Δθs,2?,…,Δθs,N?,其中NNN是主體數量,每個LoRA對應一個特定主體,我們的目標是學習一個融合LoRA Δθ^s\Delta \hat{\theta}_sΔθ^s?,能夠生成包含多個主體的視頻。
為實現這一點,我們希望強制融合后的LoRA Δθ^s\Delta \hat{\theta}_sΔθ^s? 能夠生成與每個特定主體LoRA一致的視頻。更具體地,我們通過匹配融合LoRA與特定LoRA的預測噪聲來優化Δθ^s\Delta \hat{\theta}_sΔθ^s?。多主體融合的目標函數Lfusion\mathcal{L}_{fusion}Lfusion?定義為:
Lfusion=1N∑n=1NExn,?,t[∥?θ^s(xn,t,cn,t)??n∥22],(6)\mathcal{L}_{fusion} = \frac{1}{N} \sum_{n=1}^{N} \mathbb{E}_{x_n,\epsilon,t} \left[ \left\| \epsilon_{\hat{\theta}_s}(x_n,t,c_n,t) - \epsilon_n \right\|_2^2 \right], \tag{6} Lfusion?=N1?n=1∑N?Exn?,?,t?[??θ^s??(xn?,t,cn?,t)??n??22?],(6)
其中?n=?θs,n(xn,t,cn,t)\epsilon_n = \epsilon_{\theta_{s,n}}(x_n,t,c_n,t)?n?=?θs,n??(xn?,t,cn?,t),xnx_nxn?是由θs,n\theta_{s,n}θs,n?生成的視頻,cnc_ncn?是對應第nnn個主體的提示。
此外,為了鼓勵不同主體身份合理排列,我們進一步引入空間注意力正則化(spatial attention regularization)Lattn\mathcal{L}_{attn}Lattn?,以明確引導模型關注正確的主體區域。具體來說,如圖4(a)所示,我們隨機采樣并使用Grounded-SAM2 [30, 31]分割兩個主體,然后將分割結果組合為CutMix風格 [15, 50]的視頻。我們正式定義Lattn\mathcal{L}_{attn}Lattn?如下:
Lattn=12∑i=12∥MSCA,i?M^i∥22,(7)\mathcal{L}_{attn} = \frac{1}{2} \sum_{i=1}^{2} \left\| \mathcal{M}_{SCA,i} - \hat{M}_i \right\|_2^2, \tag{7} Lattn?=21?i=1∑2??MSCA,i??M^i??22?,(7)
其中MSCA,i\mathcal{M}_{SCA,i}MSCA,i?是第iii個采樣主體的空間交叉注意力圖,M^i\hat{M}_iM^i?是對應的真實分割掩碼。因此,多主體LoRA的最終目標函數定義為:
L=Lfusion+λ2Lattn,(8)\mathcal{L} = \mathcal{L}_{fusion} + \lambda_2 \mathcal{L}_{attn}, \tag{8} L=Lfusion?+λ2?Lattn?,(8)
其中λ2\lambda_2λ2?控制注意力損失的權重。需要注意的是,我們僅在一次訓練中融合多個主體。一旦獲得融合LoRA θ^s\hat{\theta}_sθ^s?,我們即可生成具有任意動作模式的視頻。
時空協同采樣(SCS)。為了進一步將基于動作的LoRA Δθm\Delta \theta_mΔθm? 與前述融合后的視覺主體LoRA Δθ^s\Delta \hat{\theta}_sΔθ^s? 結合,我們提出了一種新穎的時空協同采樣(spatial-temporal collaborative sampling, SCS)方法,以有效控制和引導多個定制主體的交互。在SCS中,我們分別從主體分支和動作分支中獨立采樣并整合噪聲。為鼓勵早期時間步的對齊,我們引入了一種協作引導機制,使兩個分支的空間與時間注意力圖相互細化輸入潛變量。這種互相對齊使定制主體及其交互更為一致。
如圖4(b)所示,給定帶噪輸入視頻xtx_txt?,我們將其復制為xtsubx_t^{sub}xtsub?和xtmotx_t^{mot}xtmot?,分別送入主體分支和動作分支。在融合主體LoRA模型θ^s\hat{\theta}_sθ^s?和動作LoRA模型θm\theta_mθm?的條件下,我們生成主體噪聲?tsub\epsilon_t^{sub}?tsub?和動作噪聲?tmot\epsilon_t^{mot}?tmot?:
?tsub=?θ^s(xtsub,ctgt,t),?tmot=?θm(xtmot,c~tgt,t),(9)\epsilon_t^{sub} = \epsilon_{\hat{\theta}_s}(x_t^{sub}, c_{tgt}, t), \\ \epsilon_t^{mot} = \epsilon_{\theta_m}(x_t^{mot}, \tilde{c}_{tgt}, t), \tag{9} ?tsub?=?θ^s??(xtsub?,ctgt?,t),?tmot?=?θm??(xtmot?,c~tgt?,t),(9)
其中ctgtc_{tgt}ctgt?是包含主體特殊token的輸入提示(例如“A is riding a ”),而c~tgt\tilde{c}_{tgt}c~tgt?則通過將特殊token替換為對應類別構造(例如“A toy is riding a dog”)。
然而,主體分支(僅含主體LoRA)會生成錯誤的動作,動作分支(僅含動作LoRA)會產生不準確的空間排列,直接結合?tsub\epsilon_t^{sub}?tsub?和?tmot\epsilon_t^{mot}?tmot?可能導致信息不完整。為此,我們鼓勵θ^s\hat{\theta}_sθ^s?和θm\theta_mθm?之間的對齊,以生成一致的噪聲輸出。具體來說,如圖4(b)所示,我們考慮主體空間排列的空間交叉注意力圖MSCA\mathcal{M}_{SCA}MSCA?,以及捕捉動作動態的時間自注意力圖MTSA\mathcal{M}_{TSA}MTSA?。相應的協作引導損失為:
Ls→m=∥MSCA,s?MSCA,m∥22,Lm→s=∥MTSA,s?MTSA,m∥22,(10)\mathcal{L}_{s \to m} = \left\| \mathcal{M}_{SCA,s} - \mathcal{M}_{SCA,m} \right\|_2^2, \\ \mathcal{L}_{m \to s} = \left\| \mathcal{M}_{TSA,s} - \mathcal{M}_{TSA,m} \right\|_2^2, \tag{10} Ls→m?=∥MSCA,s??MSCA,m?∥22?,Lm→s?=∥MTSA,s??MTSA,m?∥22?,(10)
其中下標sss與mmm分別表示來自主體分支和動作分支。
隨后,我們更新xtsubx_t^{sub}xtsub?和xtmotx_t^{mot}xtmot?:
xtsub:=xtsub?αt?xtsubLm→s,xtmot:=xtmot?αt?xtmotLs→m,(11)x_t^{sub} := x_t^{sub} - \alpha_t \nabla_{x_t^{sub}} \mathcal{L}_{m \to s}, \\ x_t^{mot} := x_t^{mot} - \alpha_t \nabla_{x_t^{mot}} \mathcal{L}_{s \to m}, \tag{11} xtsub?:=xtsub??αt??xtsub??Lm→s?,xtmot?:=xtmot??αt??xtmot??Ls→m?,(11)
其中αt\alpha_tαt?是梯度更新的步長,該引導在前τ\tauτ個去噪步驟中應用,τ\tauτ是超參數。最后,預測噪聲由下式計算:
?t=βs?tsub+βm?tmot,(12)\epsilon_t = \beta_s \epsilon_t^{sub} + \beta_m \epsilon_t^{mot}, \tag{12} ?t?=βs??tsub?+βm??tmot?,(12)
其中我們設定βs=βm=0.5\beta_s = \beta_m = 0.5βs?=βm?=0.5以簡化計算。更多細節見附錄中的算法1。



軟件調試---vcpkg安裝crashpad(34))

vs 片段(FS):OpenGL紋理滾動著色器的性能博弈與設計哲學)






![[特殊字符]論一個 bug 如何經過千難萬險占領線上](http://pic.xiahunao.cn/[特殊字符]論一個 bug 如何經過千難萬險占領線上)
)



)

