背景
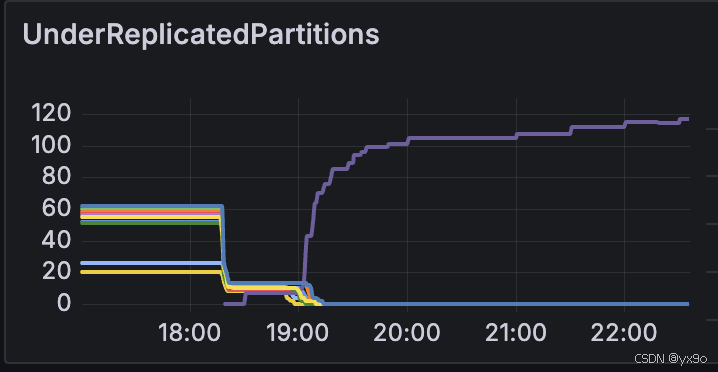
某高流量 Kafka 集群(原 10G 網卡)在切中心時頻繁觸發帶寬報警,擴容至 25G 網卡后出現副本同步異常:
- 操作流程:停機→升級網卡→重啟→觸發分區同步→切換首選 Leader
- 現象:
- 寫入流量上升后,ISR(同步副本集合)頻繁收縮
- 部分分區退化為單副本
- 根因:新舊節點
message.max.bytes配置不一致導致同步失敗
關鍵問題分析
- ISR 收縮本質:Broker 節點被踢出 ISR,意味著副本同步落后,無法跟上 Leader 的數據進度。
- 排查路徑:重點關注同步線程(如 ReplicaFetcherThread)相關日志,尋找報錯原因。
- 典型報錯:RecordTooLargeException —— Follower 拉取 Leader 消息時,批次大小超過自身配置上限。
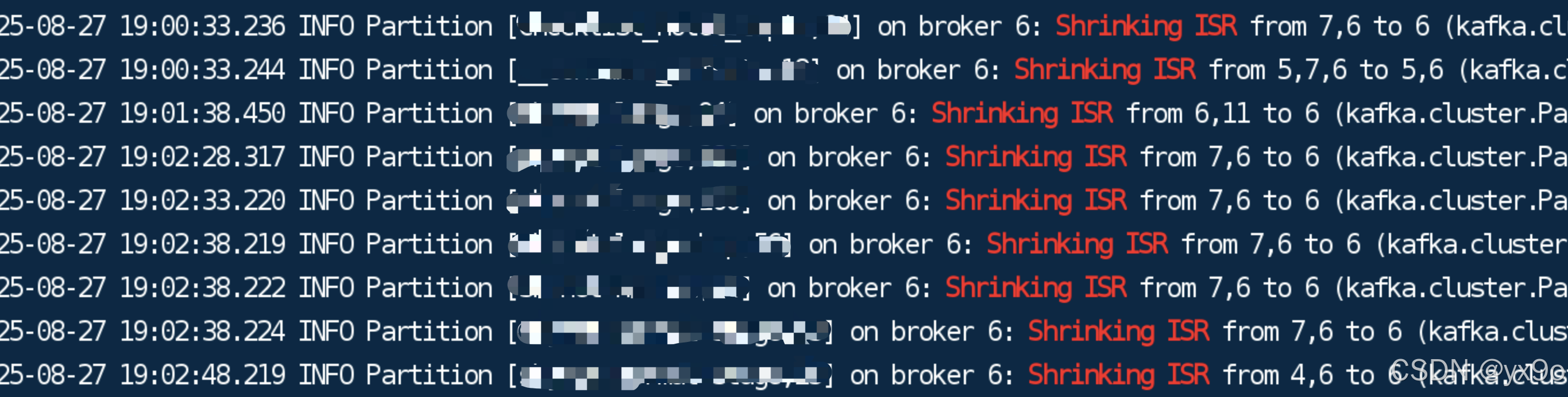

- 典型報錯:RecordTooLargeException —— Follower 拉取 Leader 消息時,批次大小超過自身配置上限。
根因復盤
- 配置不一致導致同步失敗
- 新節點升級后采用新配置(如 message.max.bytes=10485760,即10MB)
- 舊節點遺留舊配置(如 message.max.bytes=3145728,即3MB)
- 同步失敗鏈路
- 新 Leader 節點可接收大消息
- 舊 Follower 節點拉取大消息時超限,消費線程異常斷開
- Follower 被 Leader 剔除出 ISR
- 多數 Follower 失聯,分區退化為單副本
最佳實踐建議
- 運維變更前后,務必全量核查關鍵 Kafka 配置參數一致性
- 建議用自動化腳本統一檢查和修復配置,降低人工疏漏
- 變更后持續監控ISR、分區健康、Lag等指標
- 建議建立配置審計機制,每次升級或擴容都要 review 配置一致性
總結
Kafka 副本同步高度依賴于核心參數的一致性,message.max.bytes 等配置如不統一,極易引發副本同步失敗、ISR 收縮和分區退化等高危故障。
務必在運維升級、擴容、遷移等操作前后,統一配置并做好監控。
vs 片段(FS):OpenGL紋理滾動著色器的性能博弈與設計哲學)






![[特殊字符]論一個 bug 如何經過千難萬險占領線上](http://pic.xiahunao.cn/[特殊字符]論一個 bug 如何經過千難萬險占領線上)
)



)



威脅分析師)
)

)