文章目錄
- IPO編程方式、print、input函數
- print() -- 輸出信息到屏幕
- input() -- 讀取用戶的輸入
- 基本數據類型
- int、float、bool、str
- 常用 str 操作方法
- 格式化字符串的三種方式
- 數據驗證方法
- 字符串拼接
- 字符串去重
- 數據類型轉換函數
- 容器類型
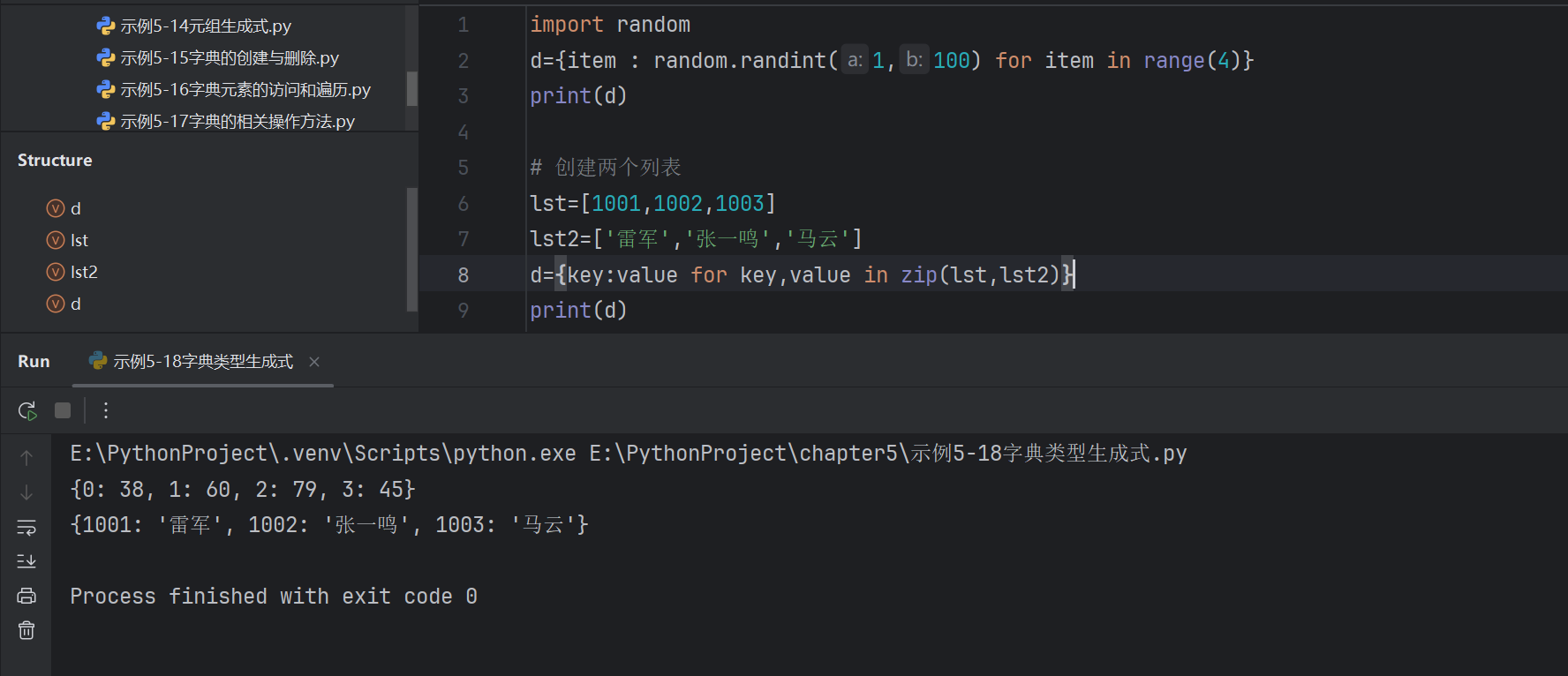
- 列表(list):可變、可重復、有序
- 元組(tuple): 不可變、可重復、有序
- 元組元素的訪問與遍歷
- 集合(set):可變、不重復、無序
- 集合的創建
- 集合元素的操作方法
- 字典(dict):鍵值對,類似 Java 中的 Map
- 字典類型創建方式
- 字典元素的訪問和遍歷
- 字典相關操作方法
- 字典類型生成式
- 列表、元組、字典、集合的區別
- 正則表達式
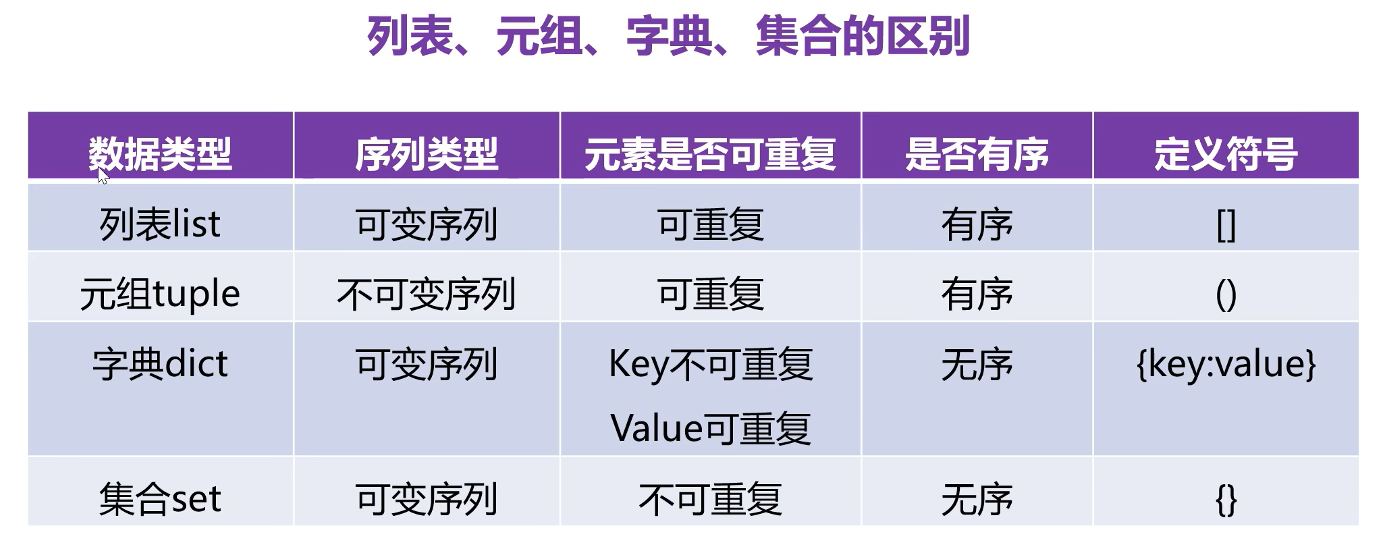
- 元字符
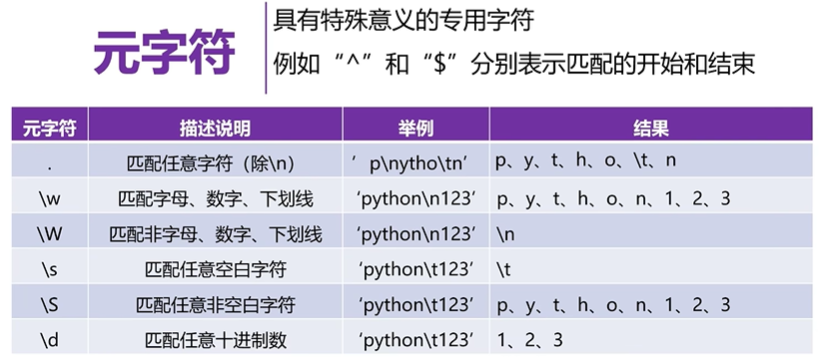
- 限定符
- 其他字符
- re模塊
- match函數的使用
- 函數的定義和調用
- 變量的作用域
- 匿名函數lambda
- 類與對象
- 類的組成
- 創建多個類的實例對象
- 動態綁定屬性和方法
- 封裝、繼承、多態
- 封裝
- 訪問私有屬性和方法
- dir() 函數。
- 繼承
- 多態
- Object 類
- 對象的特殊方法
- 特殊屬性
- 模塊
- 常用內置模塊
- random 模塊
- time 模塊
- datetime 模塊
- os 模塊
- 常用第三方模塊
- 第三方模塊的安裝與卸載
- requests
- 爬取景區的天氣預報
- 爬取百度LOGO圖片
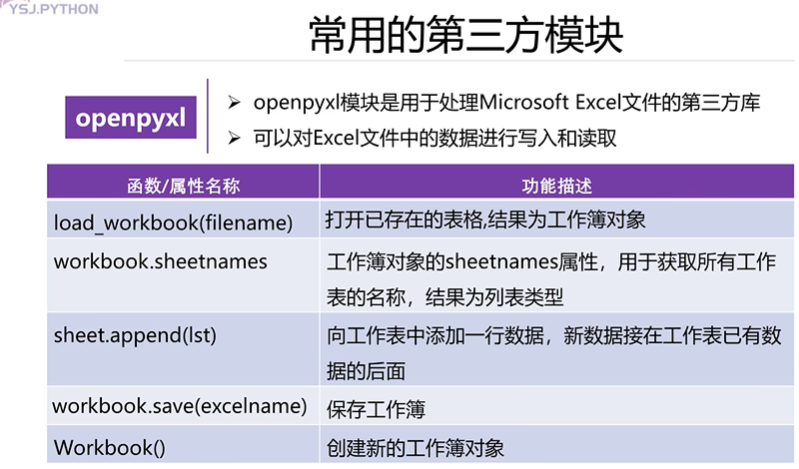
- openpyxl
- 將爬取到景區的天氣預報數據保存在Excel中
IPO編程方式、print、input函數
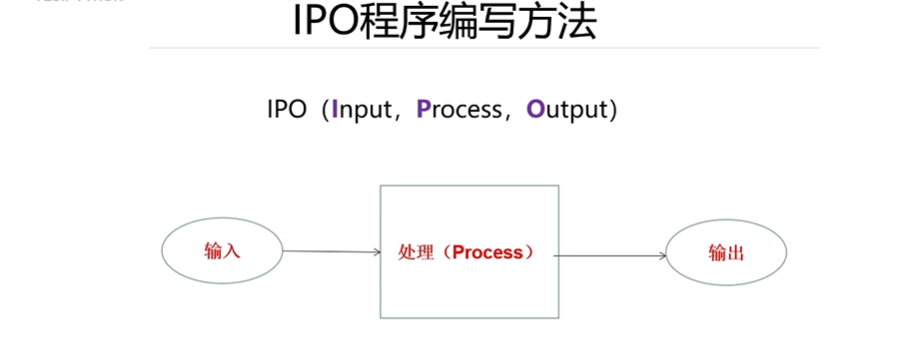
print() – 輸出信息到屏幕
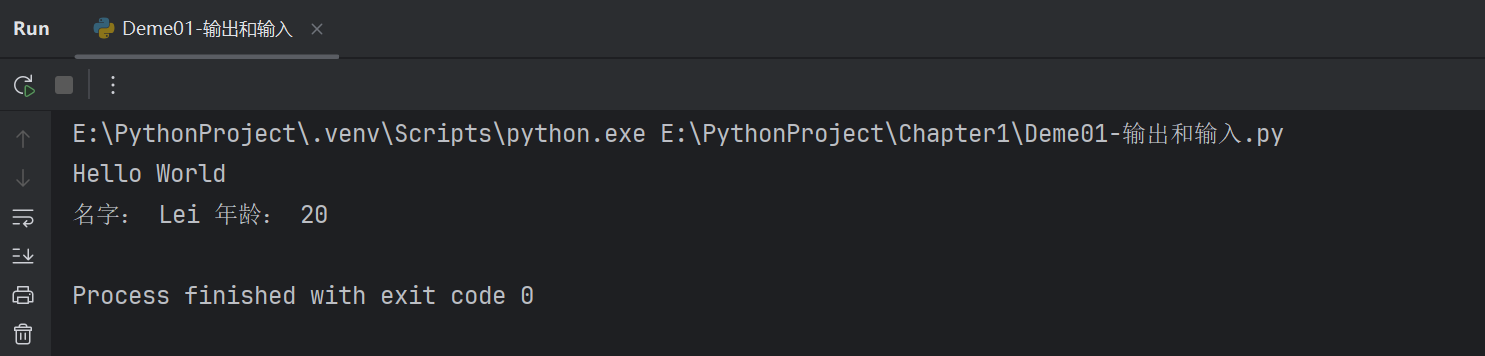
print('Hello World')name = "Lei"
age = 20
print("名字:", name, "年齡:", age)
常用參數
| 參數名 | 說明 |
|---|---|
sep | 指定多個參數之間的分隔符,默認是空格 " " |
end | 輸出結束后的字符,默認是換行符 "\n" |
file | 輸出目標,默認是終端,可以寫入文件 |
flush | 是否立刻輸出緩存,默認是 False |
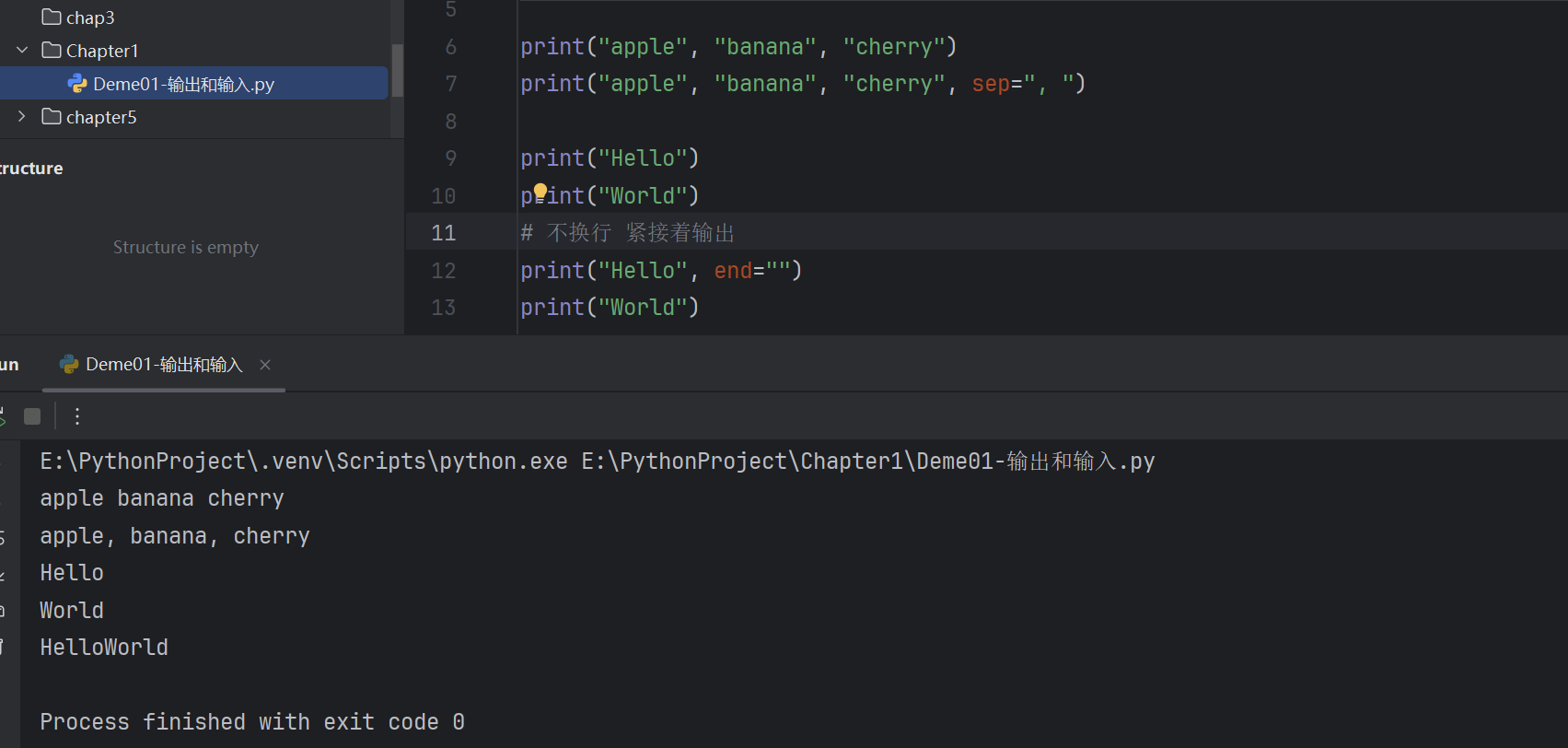
print("apple", "banana", "cherry", sep=", ") # 輸出用逗號分隔
# 輸出:apple, banana, cherryprint("Hello", end="") # 不換行
print("World") # 緊接著輸出
# 輸出:HelloWorld
輸出格式化字符串(推薦)
name = "Bob"
age = 25# 方法1:f-string(推薦)
print(f"我的名字是{name},我今年{age}歲。")
print("我的名字是{name},我今年{age}歲。")# 方法2:.format()
print("我的名字是{},我今年{}歲。".format(name, age))

input() – 讀取用戶的輸入
name = input("請輸入你的名字:")
print("你好," + name)
input() 會暫停程序,等用戶輸入內容并按回車
輸入內容是字符串(類型為 str)
如果你需要用戶輸入一個數字,比如整數或浮點數,需要手動轉換:
age = int(input("請輸入你的年齡:")) # 轉換為整數
height = float(input("請輸入你的身高(米):")) # 轉換為浮點數
name = input("請輸入你的名字:")
age = int(input("請輸入你的年齡:"))
print(f"{name},你明年就 {age + 1} 歲了!")

基本數據類型
int、float、bool、str
# 整數(int)
a = 10# 浮點數(float)
pi = 3.14# 布爾值(bool)
is_ok = True # 或 False# 字符串(str) 字符串可以用單引號或雙引號包圍。
name = "Alice"
sentence = 'Hello, world!'
常用 str 操作方法
| 方法 | 作用 | 示例 |
|---|---|---|
lower() | 轉換為小寫 | 'Hello'.lower() → 'hello' |
upper() | 轉換為大寫 | 'Hello'.upper() → 'HELLO' |
strip() | 去除前后空白字符 | ' hi '.strip() → 'hi' |
replace(old, new) | 替換字符串內容 | 'a-b-c'.replace('-', '+') → 'a+b+c' |
split(sep) | 拆分為列表 | 'a,b,c'.split(',') → ['a', 'b', 'c'] |
join(iterable) | 用當前字符串連接序列 | ','.join(['a', 'b']) → 'a,b' |
find(sub) | 查找子串,返回索引 | 'abc'.find('b') → 1 |
count(sub) | 子串出現次數 | 'banana'.count('a') → 3 |
startswith(prefix) | 是否以 prefix 開頭 | 'hello'.startswith('he') → True |
endswith(suffix) | 是否以 suffix 結尾 | 'hello'.endswith('lo') → True |
isdigit() | 是否是數字字符 | '123'.isdigit() → True |
isalpha() | 是否是字母 | 'abc'.isalpha() → True |
isalnum() | 是否是字母或數字 | 'abc123'.isalnum() → True |
format() | 格式化字符串 | 'Name: {}'.format('Tom') → 'Name: Tom' |
zfill(width) | 左側補零 | '42'.zfill(5) → '00042' |
s = " Hello, World! "print(s.strip()) # 去空格 → "Hello, World!"
print(s.lower()) # 小寫 → " hello, world! "
print(s.upper()) # 大寫 → " HELLO, WORLD! "
print(s.replace(",", ".")) # 替換 → " Hello. World! "
print(s.split(",")) # 拆分 → [' Hello', ' World! ']
print(".".join(["a", "b"])) # 拼接 → "a.b"
print(s.find("World")) # 查找 → 9
print(s.count("l")) # 統計 → 3
print("12345".isdigit()) # True
print("abc123".isalnum()) # True
print("Hello".startswith("He")) # True
str1='leilei@163.com'
list1=str1.split('@')
print('郵箱名是:',list1[0],'郵箱服務器:',list1[1]) # 郵箱名是: leilei 郵箱服務器: 163.com
🧠 提示:面試中優先記住這些!
strip() / lower() / replace() → 清洗字符串常用
split() / join() → 拆分與合并
find() / count() → 查找統計
startswith() / endswith() → 過濾文本
isdigit() / isalpha() / isalnum() → 驗證輸入格式
format() / f-string → 字符串格式化輸出
格式化字符串的三種方式

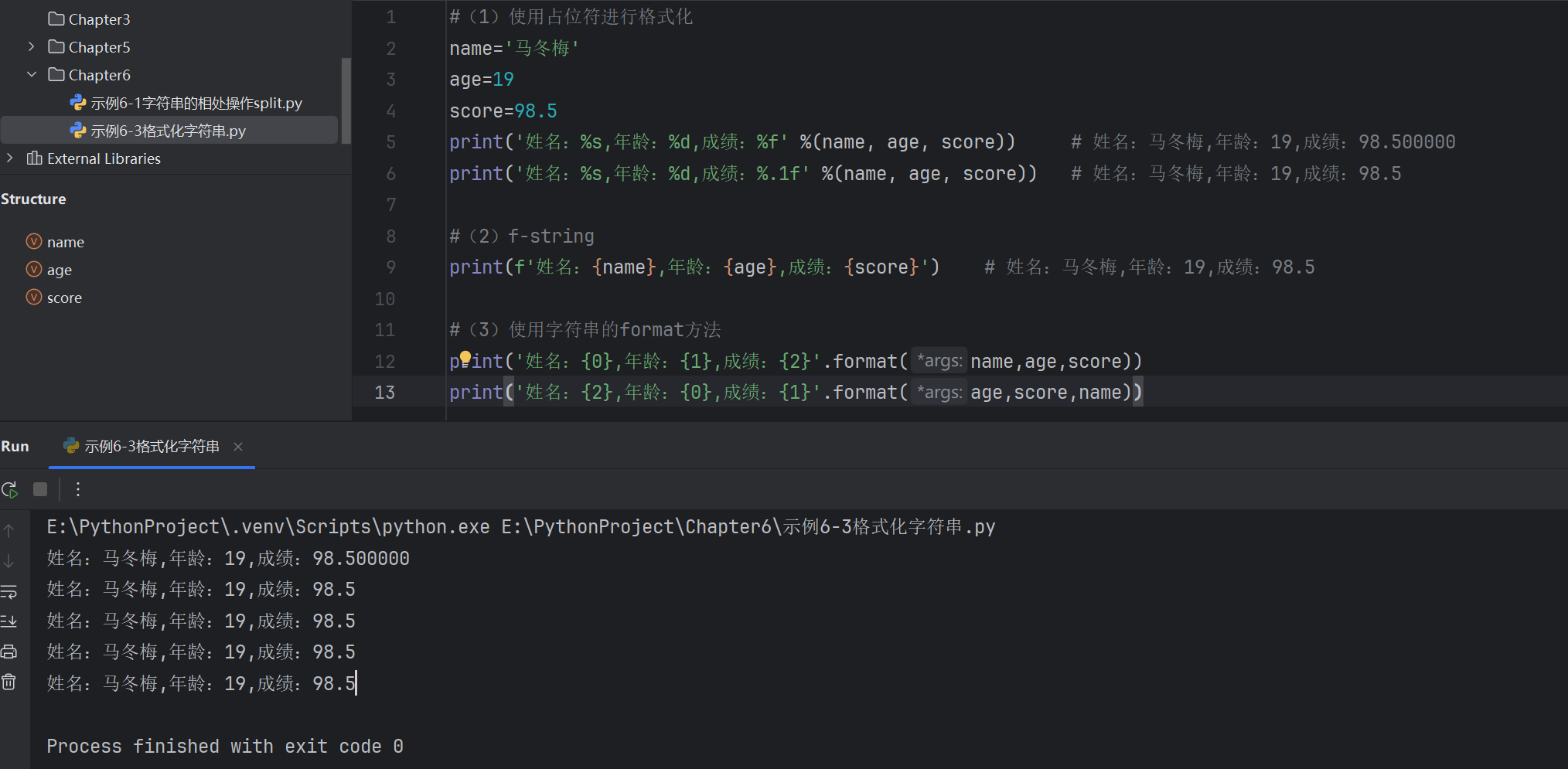
#(1)使用占位符進行格式化
name='馬冬梅'
age=19
score=98.5
print('姓名:%s,年齡:%d,成績:%f' %(name, age, score)) # 姓名:馬冬梅,年齡:19,成績:98.500000
print('姓名:%s,年齡:%d,成績:%.1f' %(name, age, score)) # 姓名:馬冬梅,年齡:19,成績:98.5#(2)f-string
print(f'姓名:{name},年齡:{age},成績:{score}') # 姓名:馬冬梅,年齡:19,成績:98.5#(3)使用字符串的format方法
print('姓名:{0},年齡:{1},成績:{2}'.format(name,age,score))
print('姓名:{2},年齡:{0},成績:{1}'.format(age,score,name))
數據驗證方法
# isdigit() 十進制的阿拉伯數字
print('123'.isdigit()) # True
print('一二三'.isdigit()) # False
print('0b101'.isdigit()) # False
print('-'*50)# 所有字符都是數字
print('123'.isnumeric()) # True
print('一二三'.isnumeric()) # True
print('0b10'.isnumeric()) # False
print('Ⅱ'.isnumeric()) # 羅馬數字 True
print('壹貳叁'.isnumeric()) # True
print('-'*50)# 所有字符都是字母(包含中文字符)
print('hello你好'.isalpha()) # True
print('hello你好123'.isalpha()) # False
字符串拼接
s1='hello'
s2='world'#第一種方式:使用加號'+'拼接
print(s1+s2) # helloworld#第二種方式:使用字符串的join()方法
print(''.join([s1,s2])) # helloworld 使用空字符串進行拼接
print('*'.join(['pyhon','java','linux','php'])) # pyhon*java*linux*php
print('你好'.join(['pyhon','java','linux','php'])) # pyhon你好java你好linux你好php#第三種方式:直接拼接
print('hello''world''你好') # helloworld你好#第四種方式:使用格式化字符串
print('%s%s' %(s1,s2)) # helloworld
print(f'{s1}{s2}') # helloworld
print('{0}{1}'.format(s1,s2)) # helloworld
字符串去重
s='helloworldhelloworldhelloworldhelloworldhelloworld'# 第一種方式:通過遍歷字符及not in
new_s=''
for it in s:if it not in new_s:new_s+=it
print(new_s) # helowrd# 第二種方式:使用索引+ not in
new_s2=''
for i in range(len(s)):if s[i] not in new_s2:new_s2+=s[i]
print(new_s2) # helowrd# 第三種方式:通過集合去重+列表排序
new_s3=set(s)
lst=list(new_s3)
lst.sort(key=s.index)
print(''.join(lst)) # helowrd
lst.sort(key=s.index) 排序
這一行是關鍵!
s.index(x) 會返回字符 x 在原字符串中第一次出現的索引位置。
key=s.index 讓 sort 以字符在原字符串的首次出現位置為排序依據。key 不是你定義的變量,而是 sort() 方法的一個參數名字,它用來指定排序時的比較依據(規則)。
key 參數的作用
- list.sort() 和 sorted() 都有一個可選的參數 key。
- 它要求你傳入一個函數(或可調用對象),這個函數接收一個元素,返回一個用來比較大小的值。
- 排序時,Python 會對列表里的每個元素調用這個函數,把返回值當作排序的依據。
數據類型轉換函數
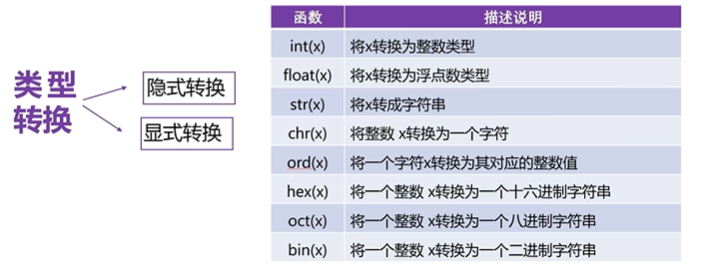
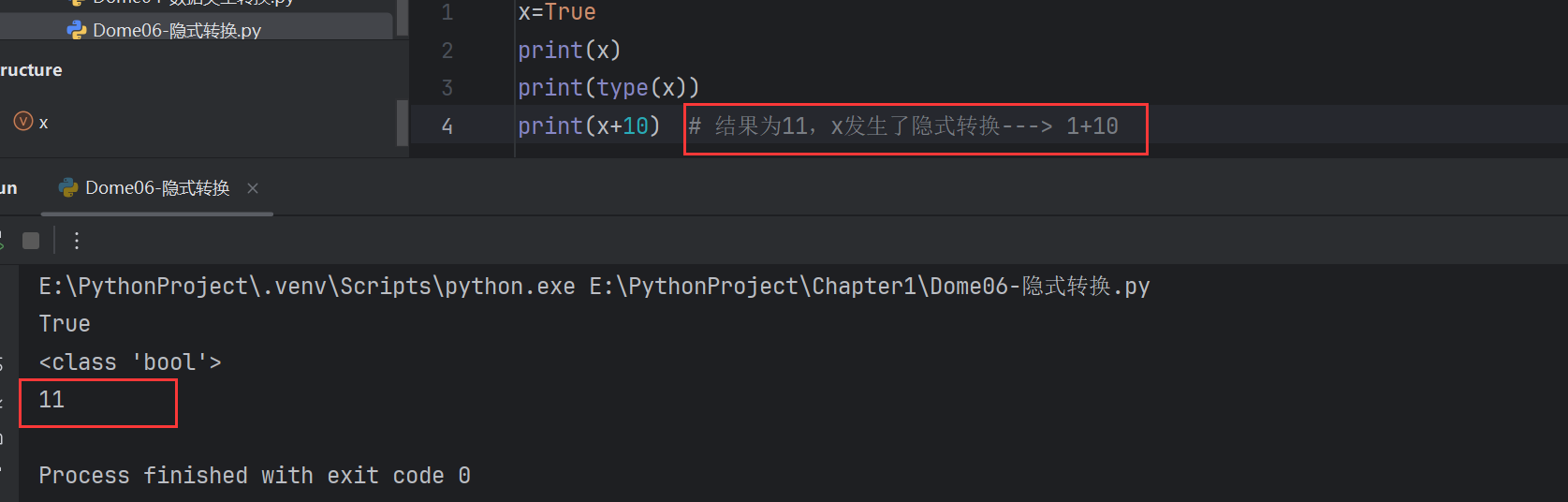
隱式轉換:Python主動完成
顯示裝換:使用下列函數:int()、float()、str()…等完成
| 目標類型 | 函數 | 示例 |
|---|---|---|
| 整數 | int(x) | int("123") → 123 |
| 浮點數 | float(x) | float("3.14") → 3.14 |
| 字符串 | str(x) | str(123) → "123" |
| 布爾值 | bool(x) | bool(0) → False |
| 列表 | list(x) | list("abc") → ['a', 'b', 'c'] |
| 元組 | tuple(x) | tuple([1,2]) → (1, 2) |
| 集合 | set(x) | set([1,1,2]) → {1, 2} |
| 字典 | dict(x) | dict([("a", 1), ("b", 2)]) |
str ? int / float(字符串 和 數字 之間轉換)
# 字符串轉整數
a = int("42") # 42# 字符串轉浮點數
b = float("3.14") # 3.14# 數字轉字符串
s = str(100) # "100"容器類型
列表(list):可變、可重復、有序
fruits = ["apple", "banana", "orange"]
fruits[0] # 訪問第一個元素 -> "apple"
fruits.append("grape") # 添加元素
元組(tuple): 不可變、可重復、有序
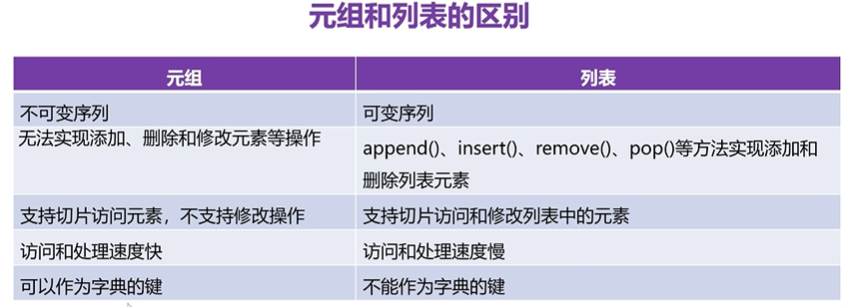
元組是Python中不可變數據類型,它沒有相關的增刪改的一系列操作,它只能使用索引去獲取元素和使用for循環去遍歷元素。
所謂的"不可變“”意思是:
一旦創建,變量的“整體結構”就不能被修改。
也就是說:
- 元組本身的長度不能變(不能添加/刪除元素)
- 元組中某個位置的元素不能被替換
?但很多人疑問:如果元組里放的是“可變對象”,還能改嗎?
? 答案是:可以修改可變對象的內容,但不能修改元組的結構!
來看看例子:
t = ([1, 2], 3)t[0].append(100) # ? 這是合法的!
print(t) # 輸出:([1, 2, 100], 3)t[0] = [9, 9] # ? 報錯!不能替換整個元素解釋:
- 元組t包含兩個元素:一個列表[1, 2]和一個整數3
- 你不能改變 t[0] 這個位置放的對象是誰(這屬于元組結構),
- 但你可以修改 t[0] 這個列表內部的內容(因為列表是可變的)
point = (10, 20)
point[0] # -> 10
# point[0] = 30 # ? 報錯:tuple是不可變的,報錯:'tuple' object does not support item assignment
元組的創建方式
- 使用()去定義元組,元素之間使用英文逗號分隔
元組名=(element1,element2,element3,…elementN)- 使用()內置函數 tuple() 創建元組
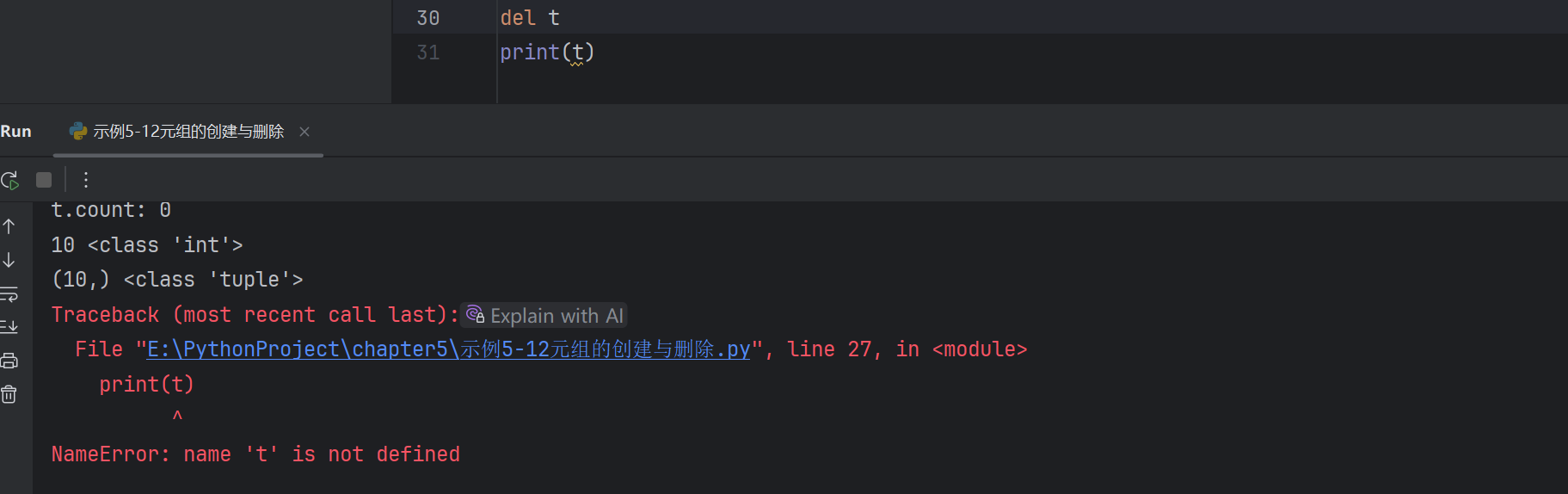
元組名= tuple(序列)刪除元祖:del()
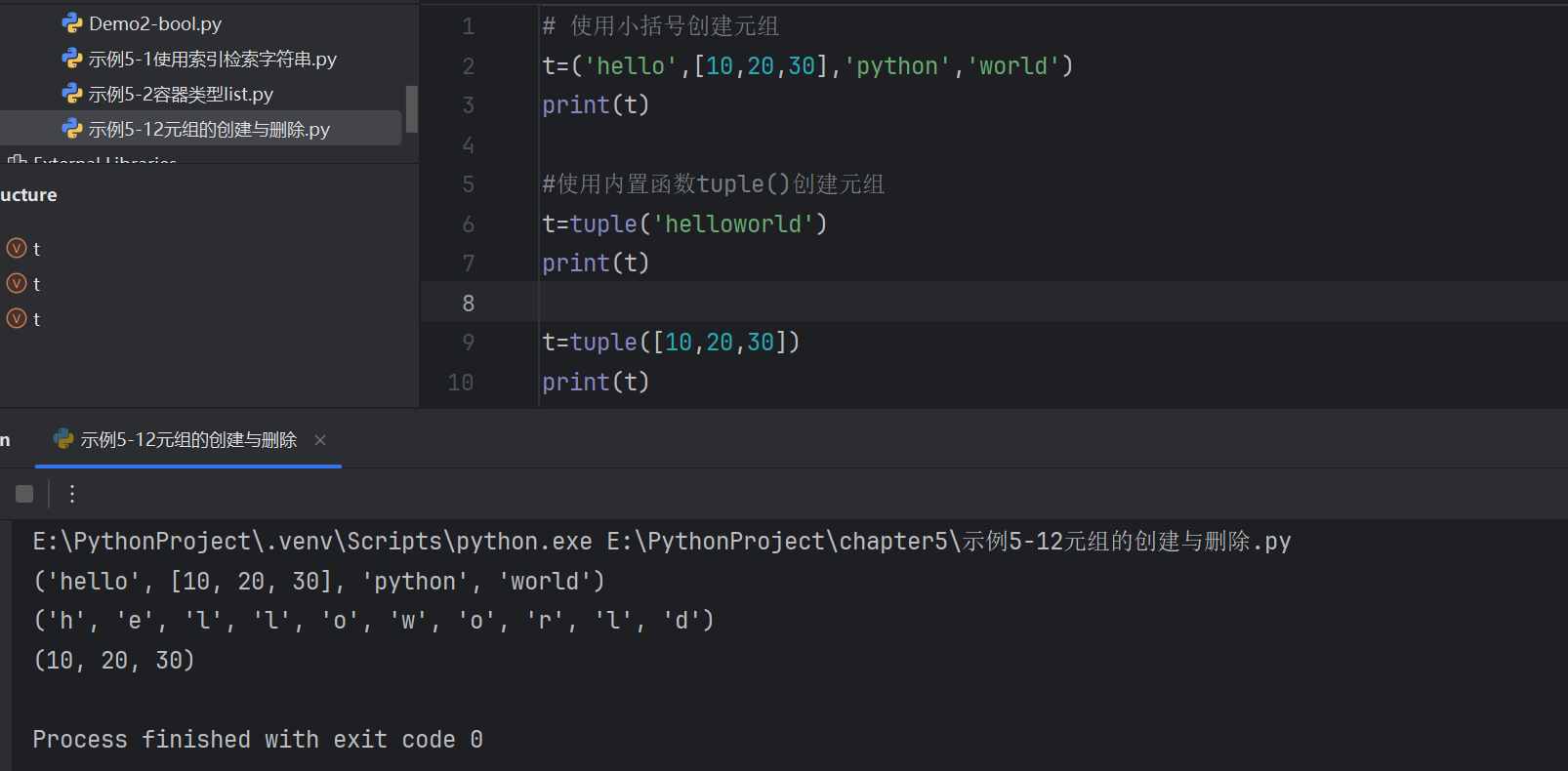
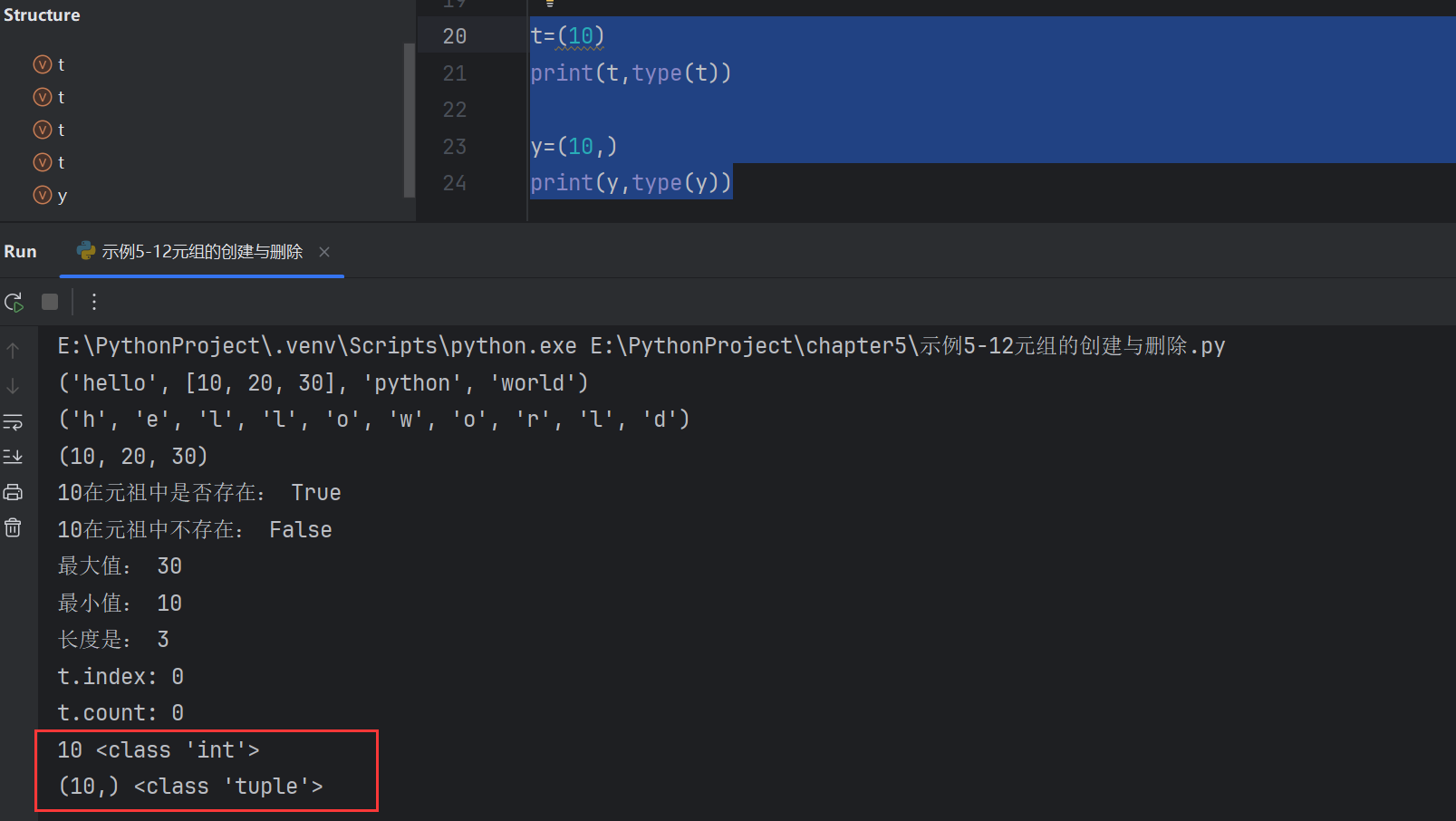
元組中只有一個元素時,逗號也不能省略
t=(10)
print(t,type(t)) #t輸出的是一個int類型y=(10,)
print(y,type(y)) #y輸出的才是元組類型
刪除元組
del 元組名
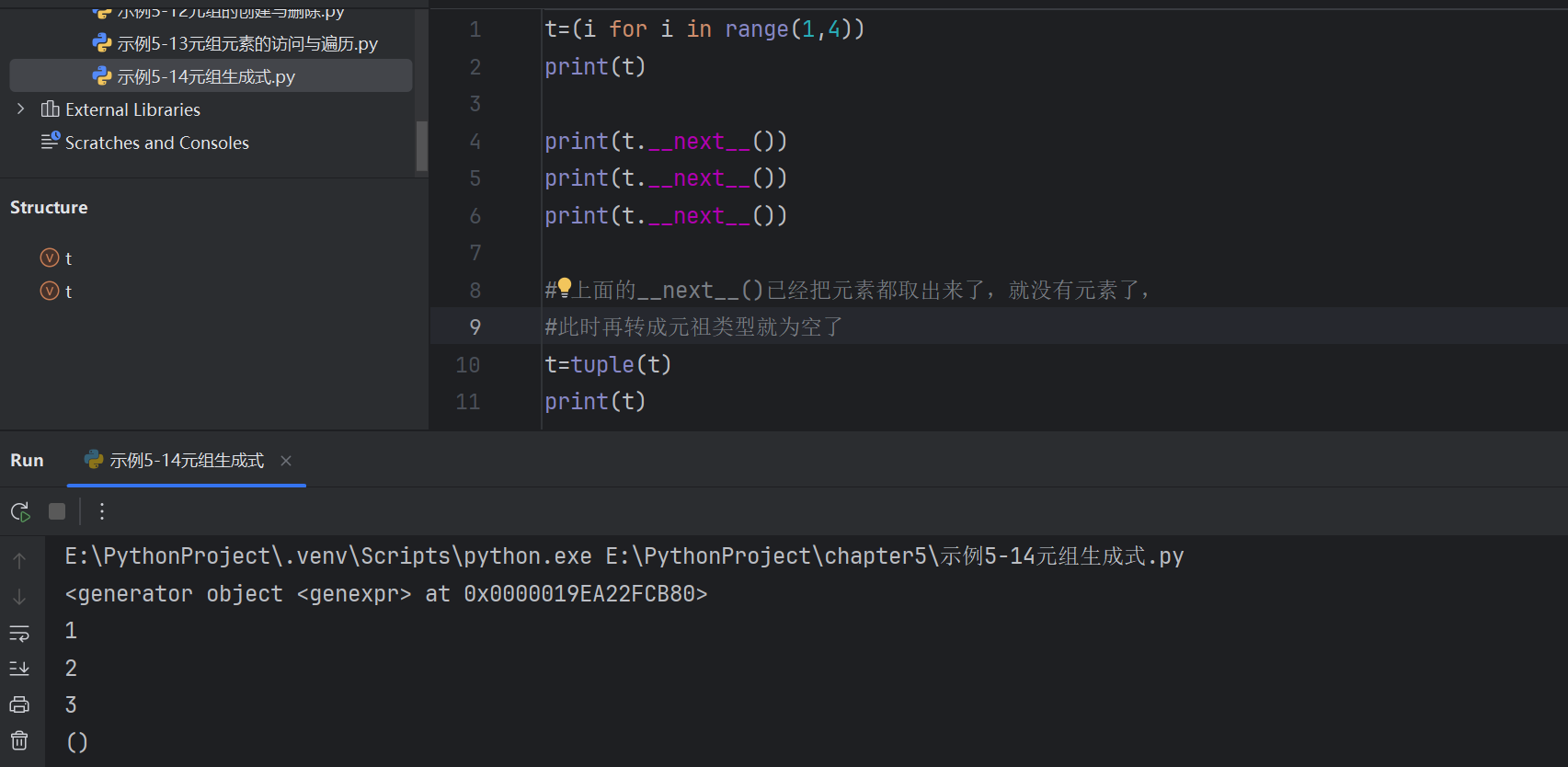
元組元素的訪問與遍歷
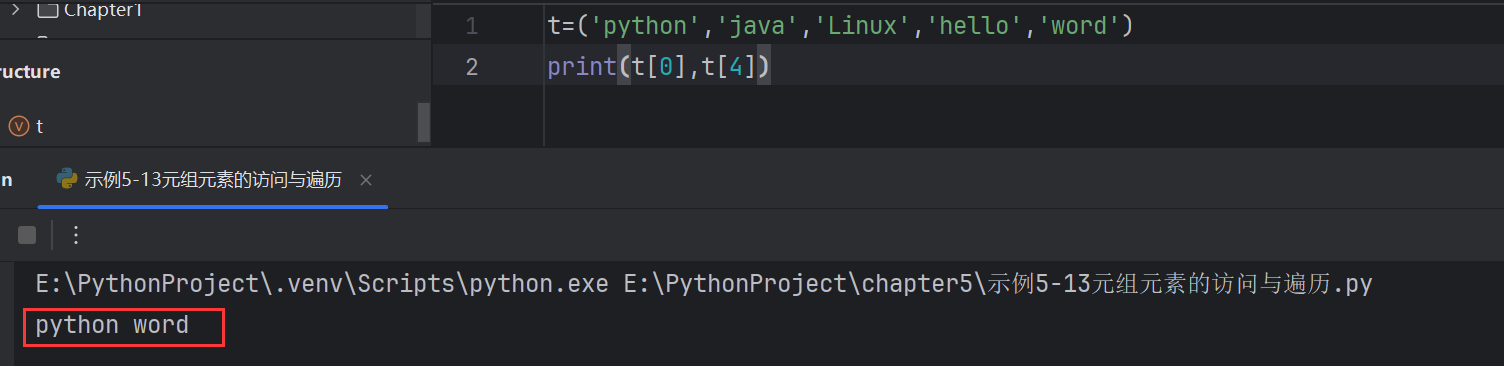
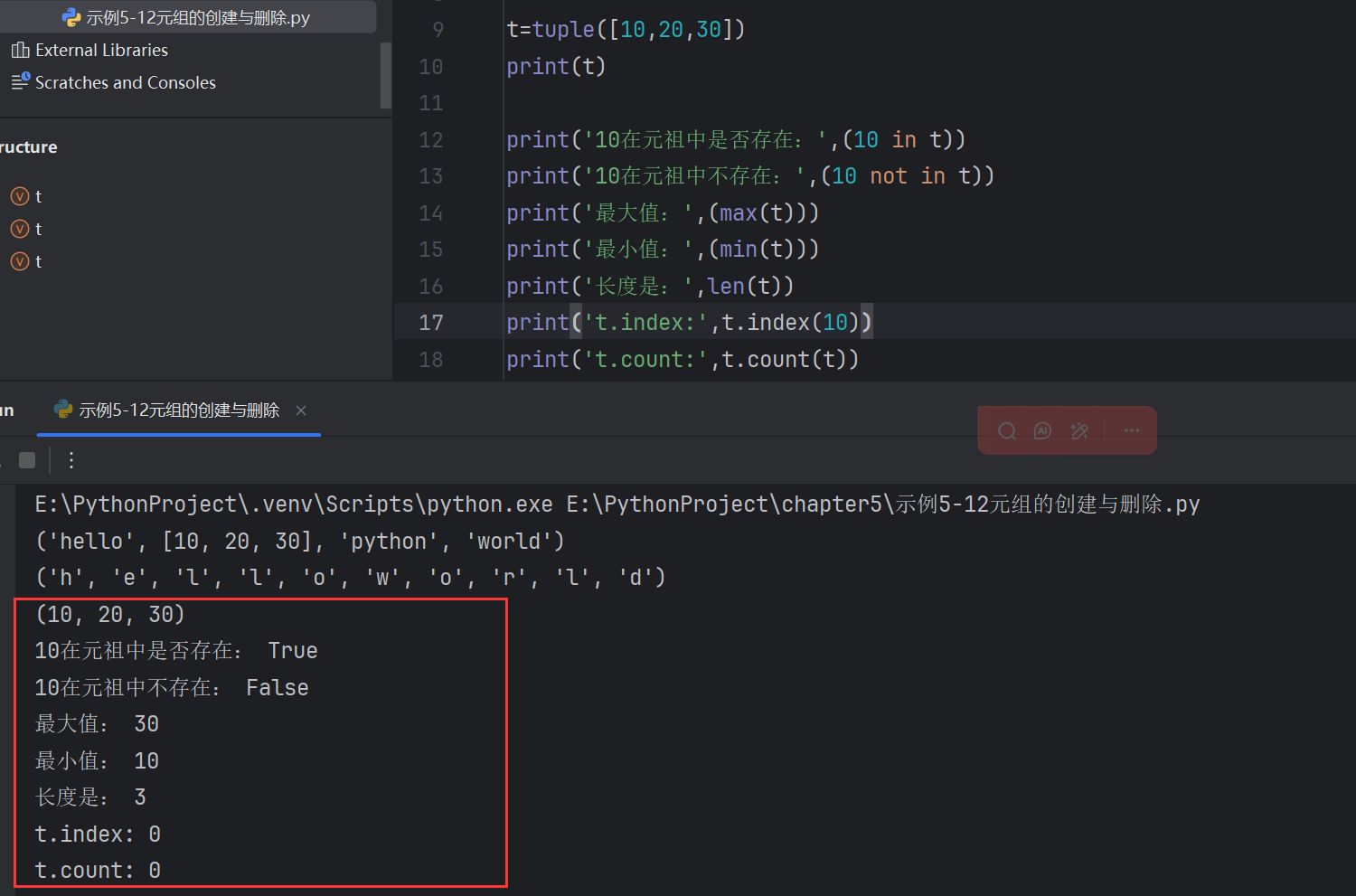
#切片操作
t2=t[0:3:2]
print(t2) # ('python', 'Linux')
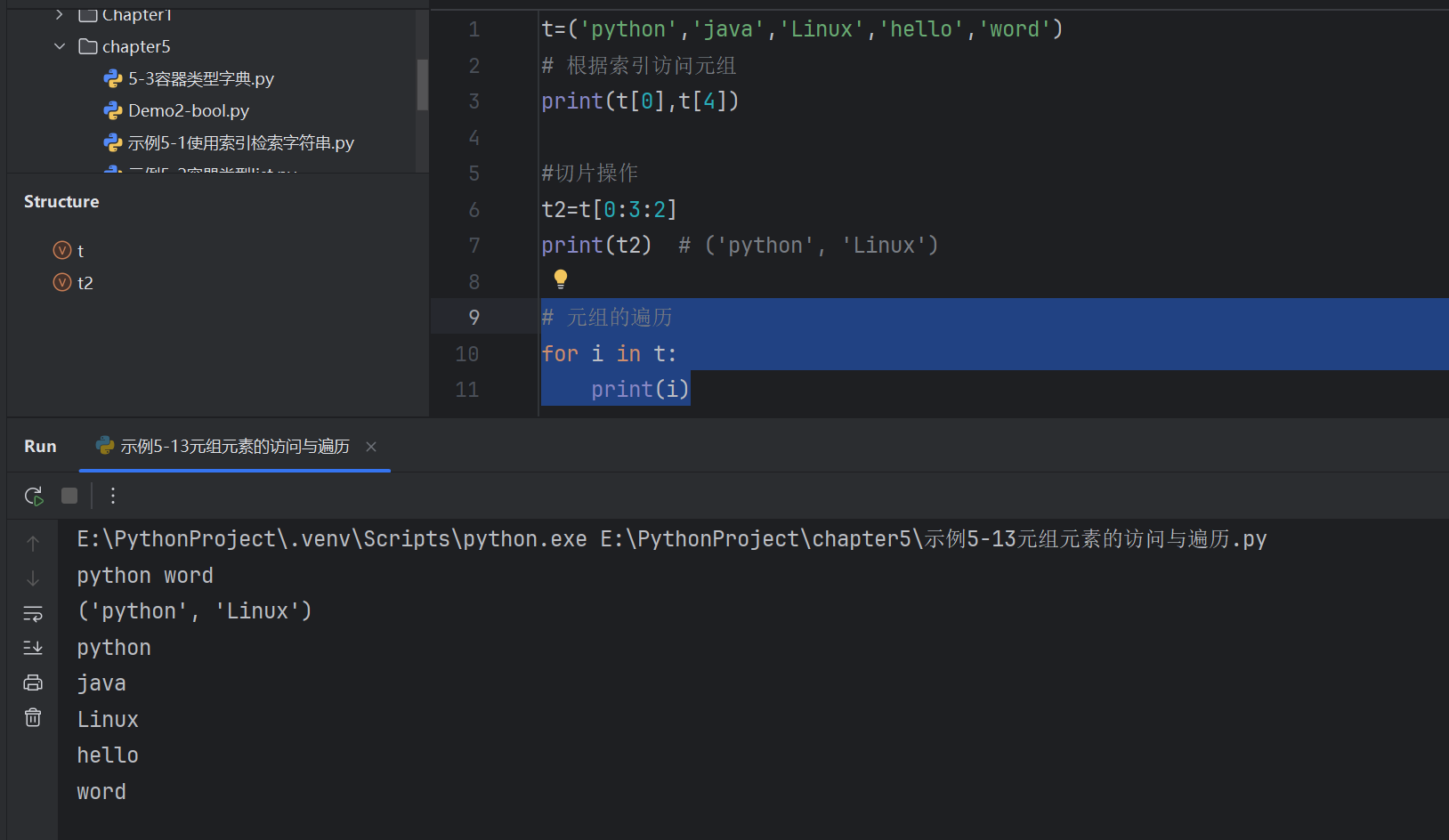
# 元組的遍歷
for i in t:print(i)
# for+range()+len()
for i in range(len(t)):print(i,t[i])打印結果
0 python
1 java
2 Linux
3 hello
4 word
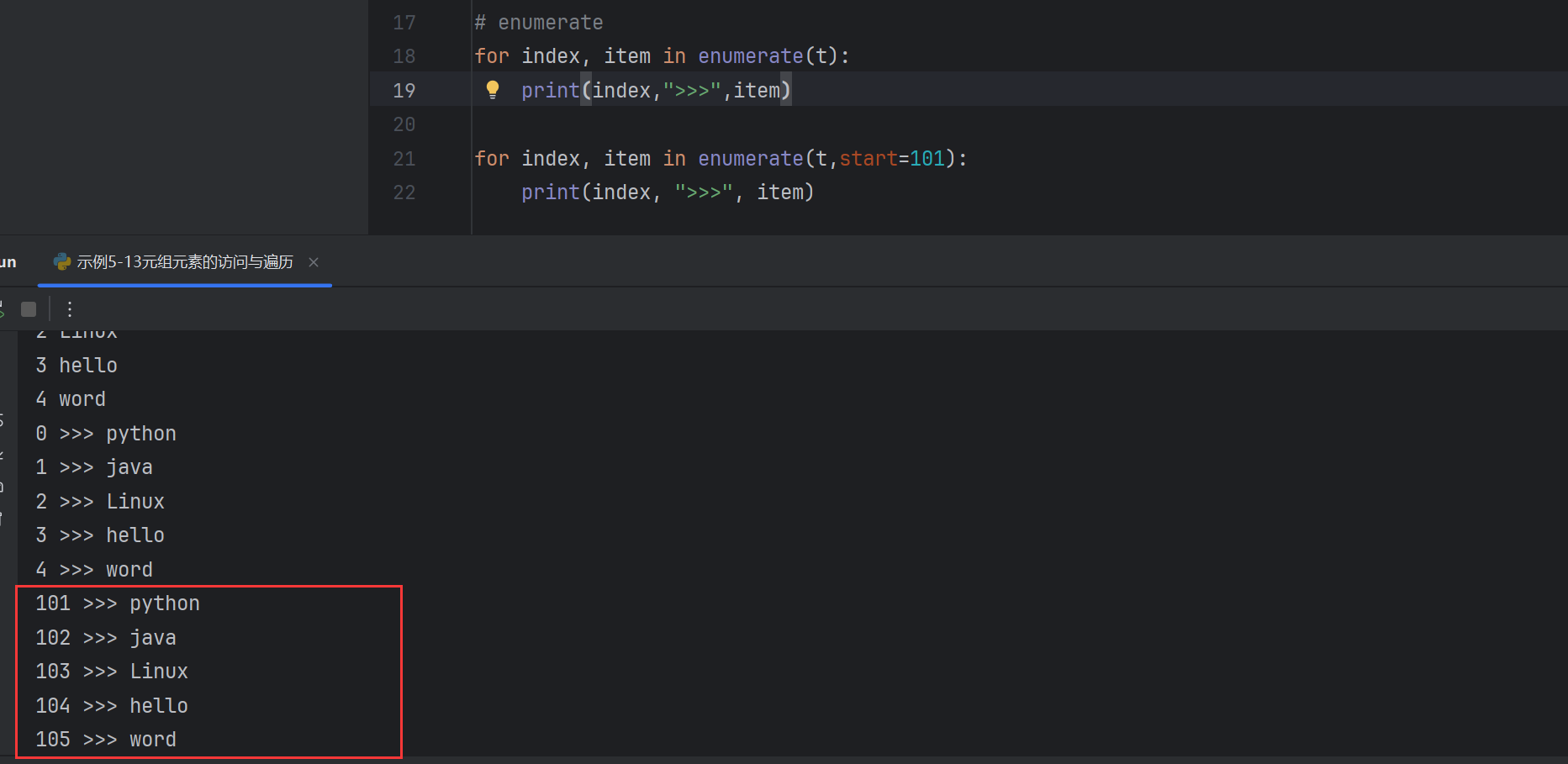
# enumerate
for index, item in enumerate(t):print(index,">>>",item)打印結果
0 >>> python
1 >>> java
2 >>> Linux
3 >>> hello
4 >>> word
修改序號
集合(set):可變、不重復、無序
colors = {"red", "green", "blue"}
colors.add("yellow")
自動去重。
不能通過下標訪問元素(因為無序)。
集合的創建
# {}直接創建集合
s={10,20,30,40}
print(s)# 集合只能存儲不可變數據類型
#s={[10,20],[30,40]}
#print(s) # TypeError: unhashable type: 'list'# 使用set()創建集合
s=set() # 創建了一個空集合,空集合的布爾值是False
print(s)
s={}
print(s,type(s)) # {} <class 'dict'>s=set('helloworld')
print(s) # {'l', 'd', 'r', 'e', 'h', 'o', 'w'} 無序不重復s2=set([10,20,30])
print(s2) # {10, 20, 30}s3=set(range(1,10))
print(s3) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
集合元素的操作方法
s3=set(range(1,10))
print(s3) # {1, 2, 3, 4, 5, 6, 7, 8, 9}# 集合屬于序列中的一種
print('max:',max(s3)) # max: 9
print('min:',min(s3)) # min: 1
print('len:',len(s3)) # len: 9print('9在集合中存在嗎?',(9 in s3)) # 9在集合中存在嗎? True
print('9在集合中不存在嗎?',(9 not in s3)) # 9在集合中不存在嗎? Falsedel s3
print(s3) # NameError: name 's3' is not defined. Did you mean: 's'?
A={10,20,30,40,50}
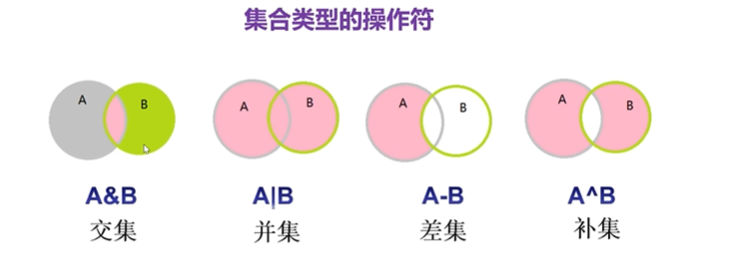
B={30,50,88,76,20}# 交集操作
print(A&B) # {50, 20, 30}
# 并集操作
print(A|B) # {40, 10, 76, 50, 20, 88, 30}
# 差集操作
print(A-B) # {40, 10}
print(B-A) # {88, 76}
# 補集操作
print(A^B) # {10, 88, 40, 76}
print(B^A) # {40, 10, 88, 76}
集合的相關操作方法

A={100,10,20,30}
# 向集合中添加元素
A.add(40)
print(A) # {100, 40, 10, 20, 30}# 刪除集合中的元素
A.remove(20)
print(A) # {100, 40, 10, 30}
A.pop()
print(A) # {40, 10, 30}# 清空集合中所有元素
# A.clear()
# print(A) # set()# 集合中的遍歷
for item in A:print(item) # 40 10 30# 使用enumerate()函數
for index,value in enumerate(A):print(index,'-->',value)
#輸出結果:
# 0 --> 40
# 1 --> 10
# 2 --> 30# 集合的生成式
s={i for i in range(1,10)}
print(s) # {1, 2, 3, 4, 5, 6, 7, 8, 9}s={i for i in range(1,10) if i%2==1}
print(s) # {1, 3, 5, 7, 9}
字典(dict):鍵值對,類似 Java 中的 Map
key --> value
字典中的鍵要求是不可變的序列(字符串、整數、浮點、元組都可以),列表是不允許作為字典的鍵(它的可變的)
person = {"name": "Alice", "age": 25}
person["name"] # -> "Alice"
person["age"] = 26 # 修改
注意事項:
字典中的key是無序的,
Python3.5及其之前的版本字典的key在輸出時無序,
但是從Python3.6版本之后Python解釋器進行了處理,所以才會看到輸出的順序與添加的順序“一致”
字典類型創建方式
第一種使用{}直接創建字典
d={key1:value1,key2:value2,key3:value3}
第二種使用內置函數dict()創建字典
dict(key1=value1,key2=value2…)
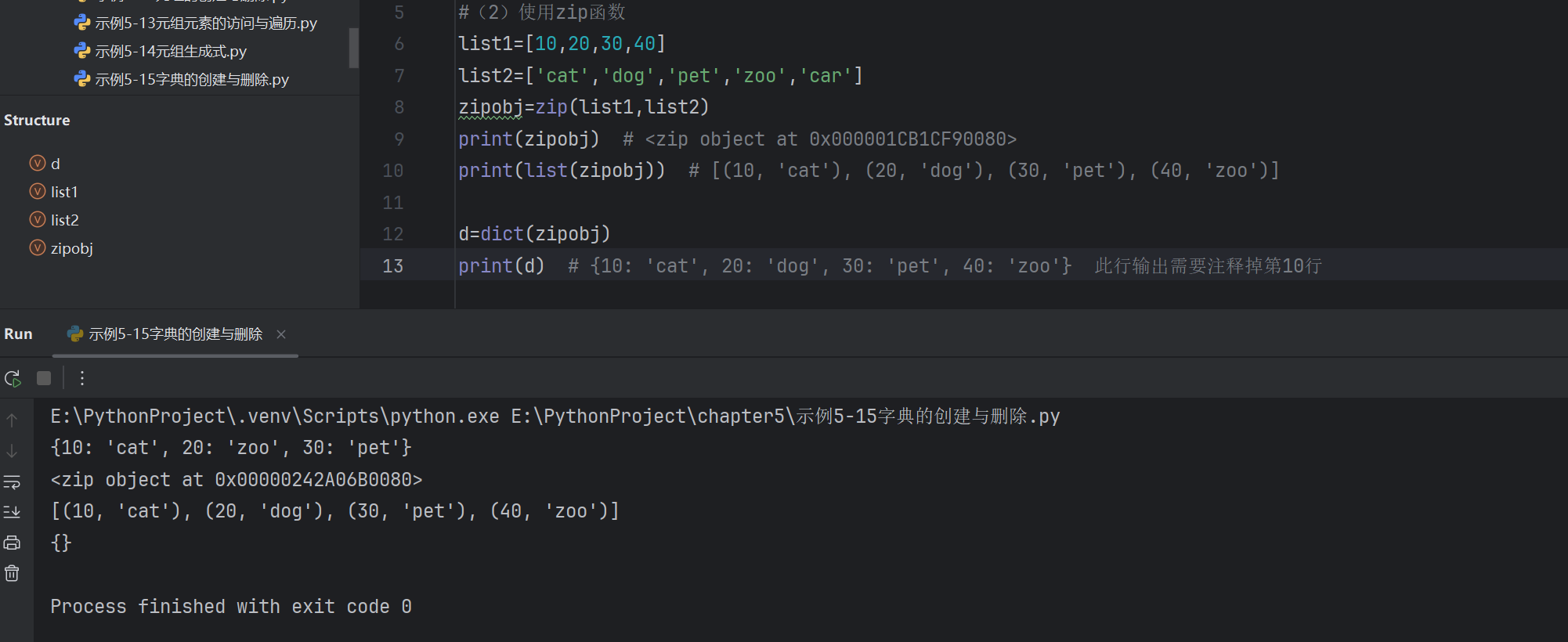
# 使用參數創建字典
d=dict(cat=10,dog=20)
print(d) # {'cat': 10, 'dog': 20}
t=(10,20,30)
print({t:10}) # {(10, 20, 30): 10} t是key,10是value,元組是可以作為字典中的key的
列表不能作為字典的鍵
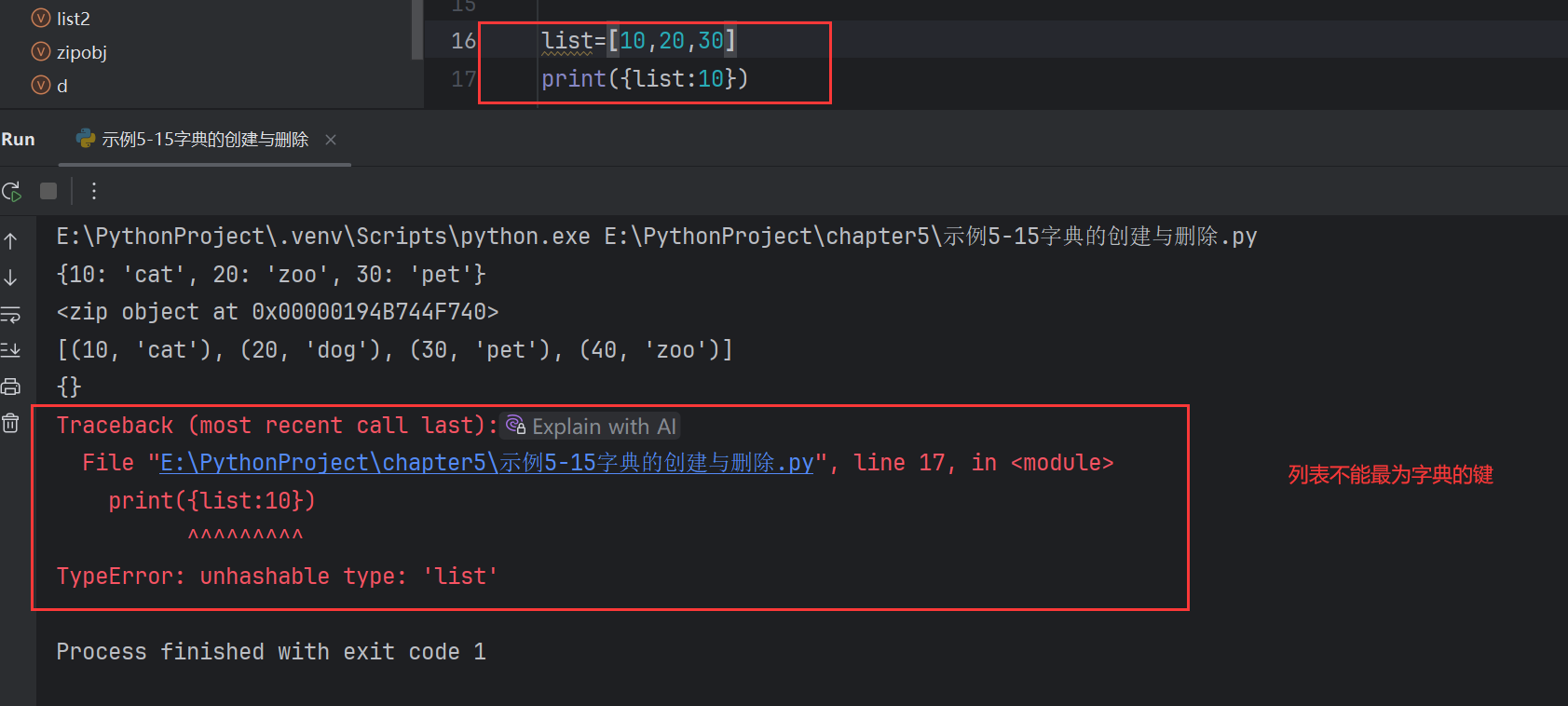
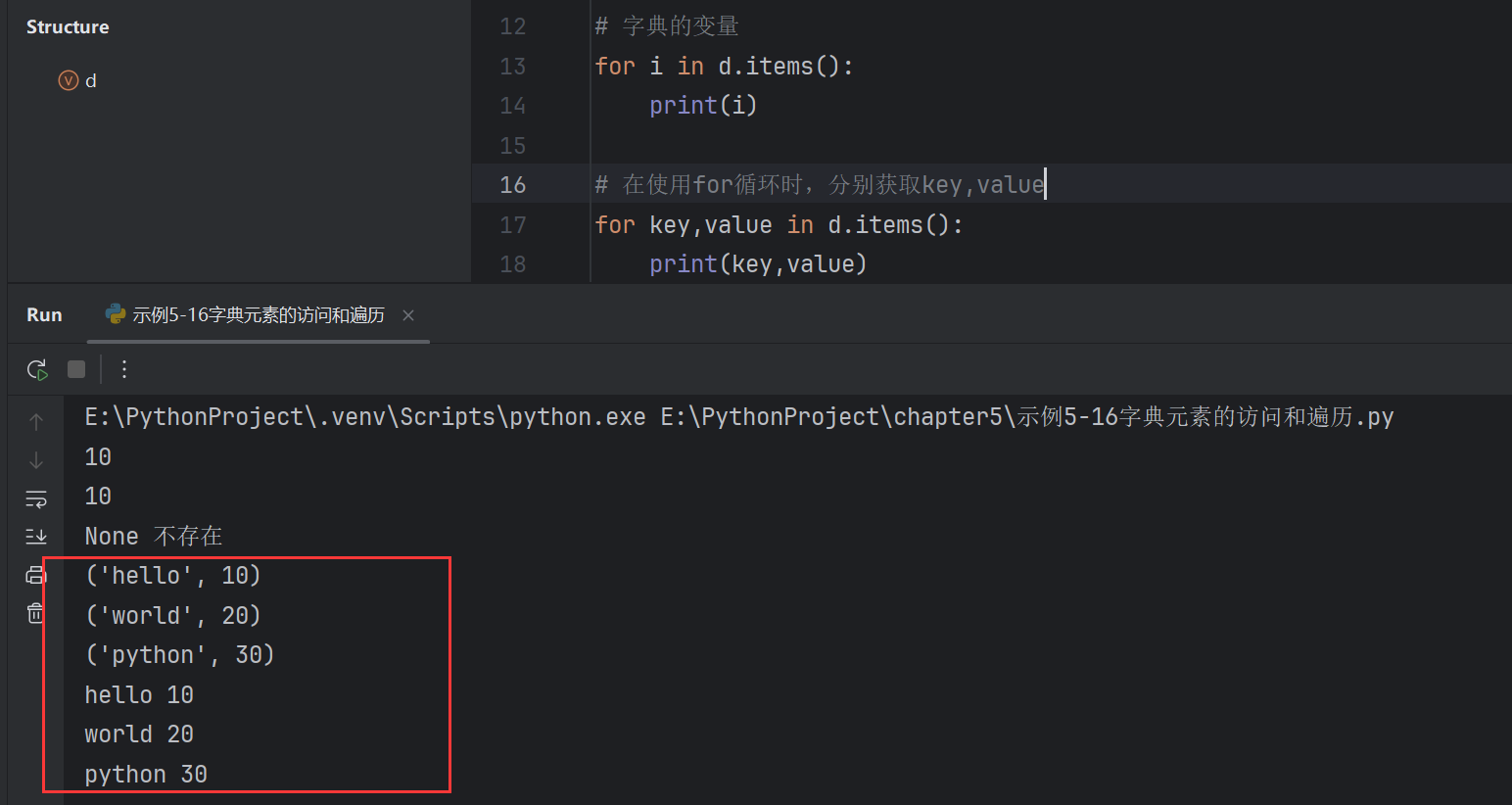
字典元素的max()、min()、len() 和刪除
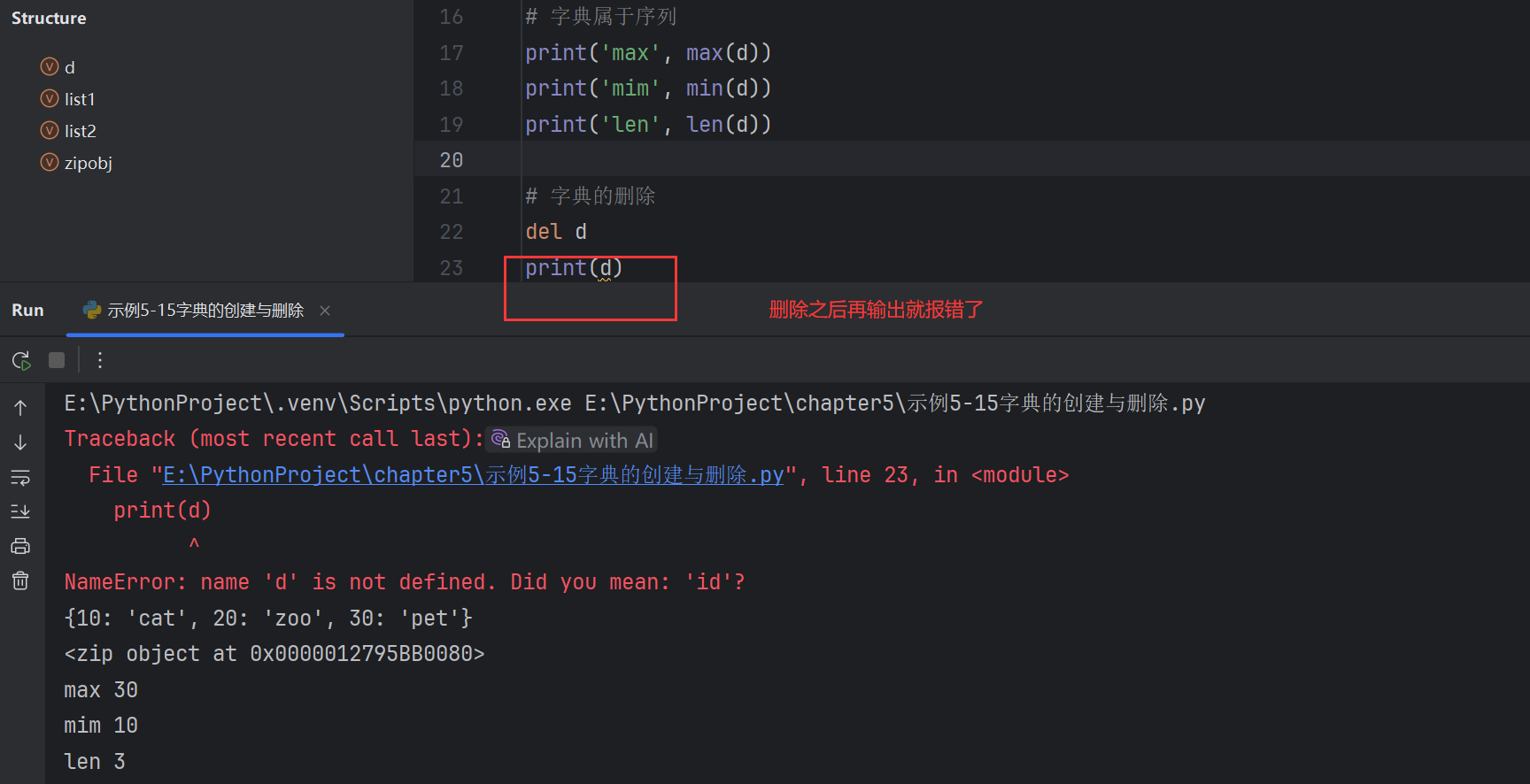
字典元素的訪問和遍歷
d={'hello':10,'world':20,'python':30}
# 訪問字典中的元素
# (1)使用d[key]
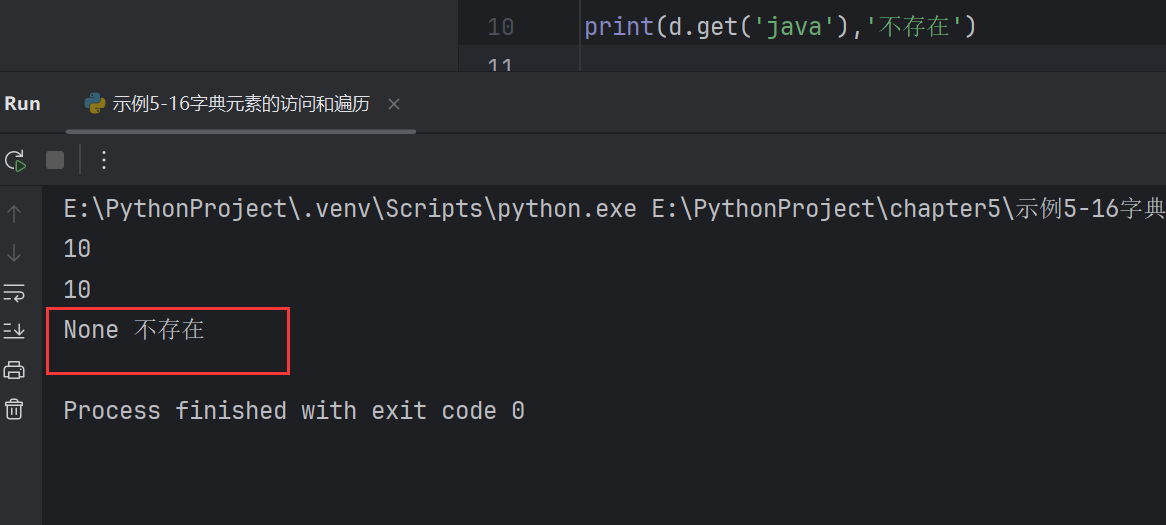
print(d['hello']) # 10# (2)d.get(key)
print(d.get('hello')) # 10
取值時,(1)d[key] 和 (2)d.get(key) 是有區別的
如果key不存在
- d[key]會報錯
- d.get[key]可以指定默認值
d[key]會報錯
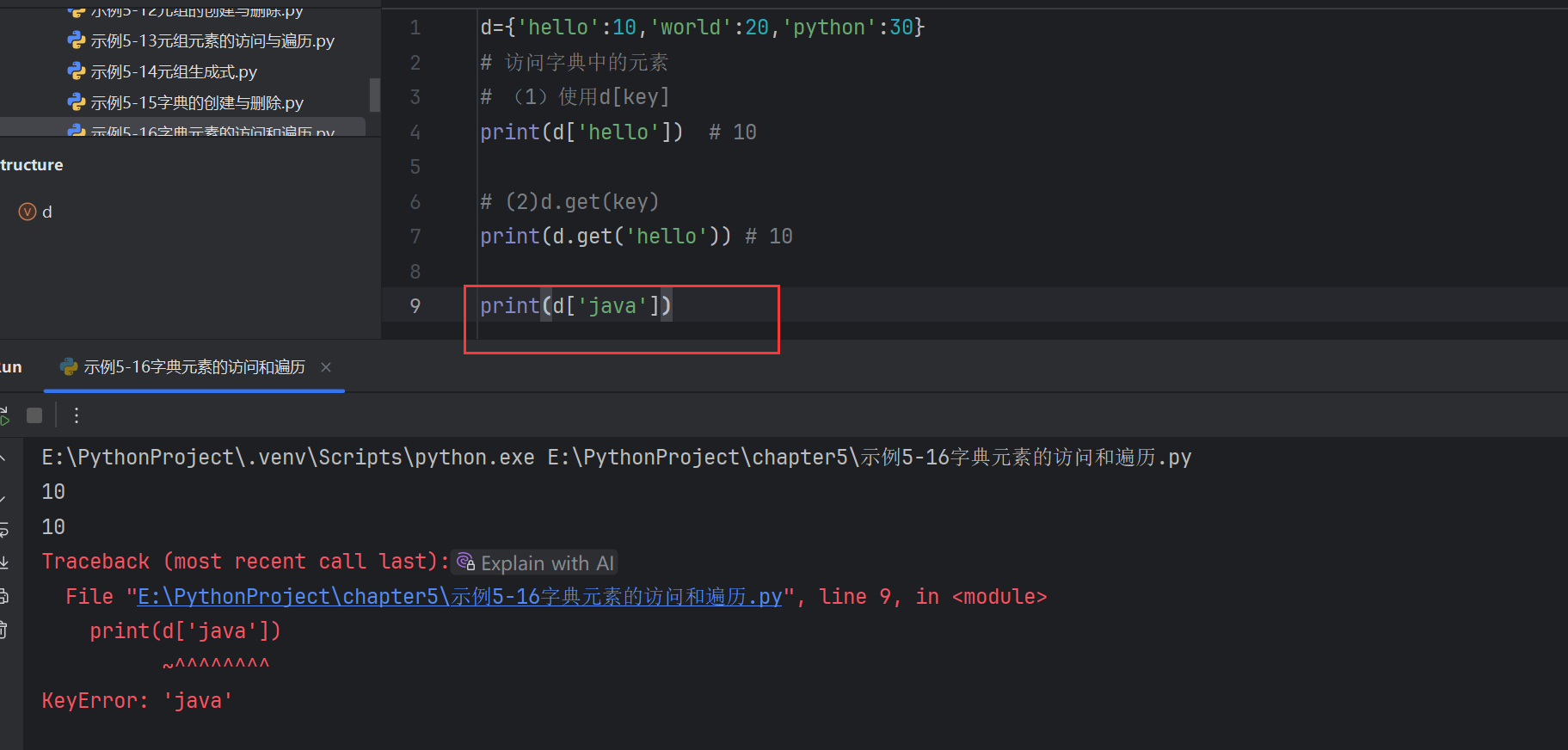
d.get[key]可以指定默認值
遍歷字典元素
字典相關操作方法
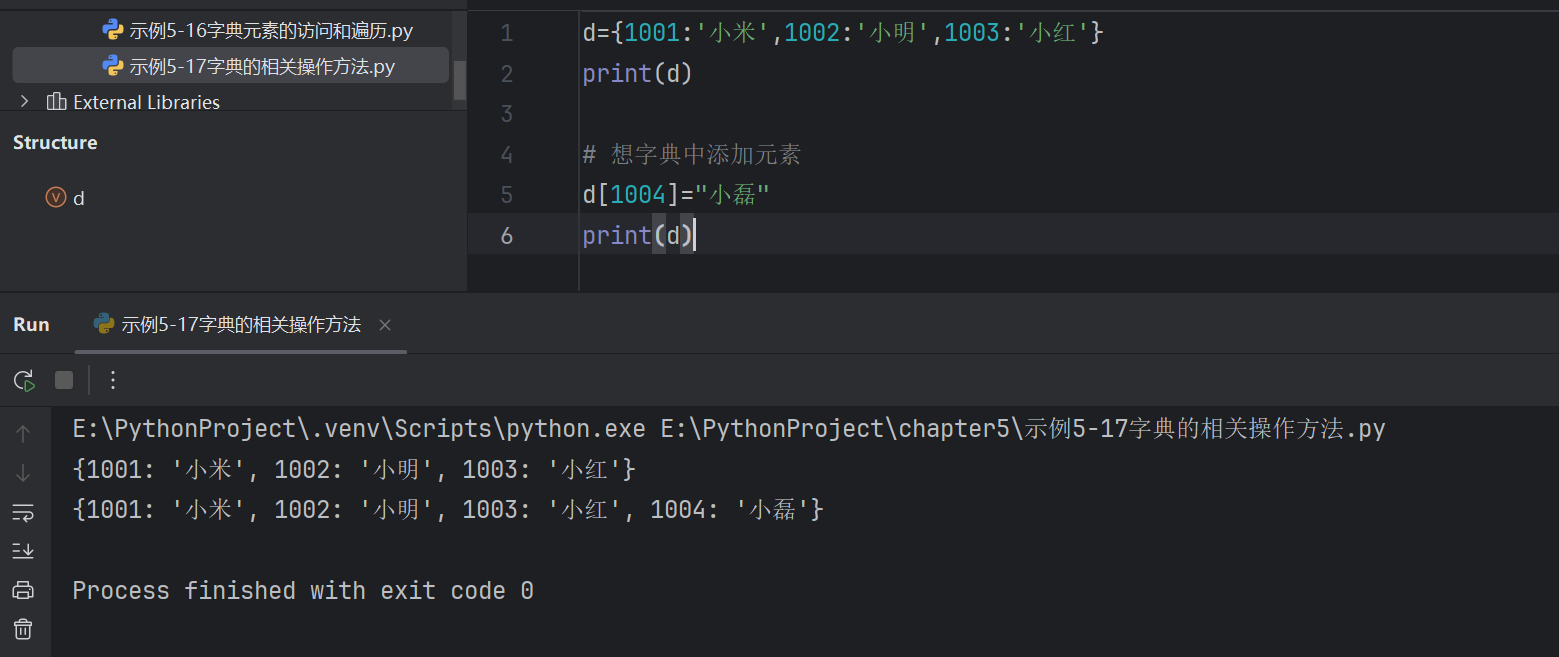
d={1001:'小米',1002:'小明',1003:'小紅'}
print(d)# 想字典中添加元素
d[1004]="小磊"
print(d)# 獲取字典中所有的key
keys=d.keys()
print(keys) # dict_keys([1001, 1002, 1003, 1004])
print(list(keys)) # [1001, 1002, 1003, 1004]
print(tuple(keys)) # (1001, 1002, 1003, 1004)# 獲取字典中所有的value
values=d.values()
print(values) # dict_values(['小米', '小明', '小紅', '小磊'])
print(list(values)) # ['小米', '小明', '小紅', '小磊']
print(tuple(values)) # ('小米', '小明', '小紅', '小磊')# 如何將字典中的數據轉換成key-value的形式,以元組的方式進行展現
lst=list(d.items())
print(lst) # [(1001, '小米'), (1002, '小明'), (1003, '小紅'), (1004, '小磊')]d=dict(lst)
print(d) # {1001: '小米', 1002: '小明', 1003: '小紅', 1004: '小磊'}# 使用pop函數
print(d.pop(1004)) # 小磊
print(d) # {1001: '小米', 1002: '小明', 1003: '小紅'}print(d.pop(1008,'不存在'))# 隨機刪除
print(d.popitem()) # (1003, '小紅')
print(d) # {1001: '小米', 1002: '小明'}# 清空字典中所有的元素
d.clear()
print(d) # {}# python中一切皆對象,每個對象都有一個布爾值
print(bool(d)) # False 空字典的布爾值為False
字典類型生成式
列表、元組、字典、集合的區別
正則表達式
元字符
限定符
其他字符
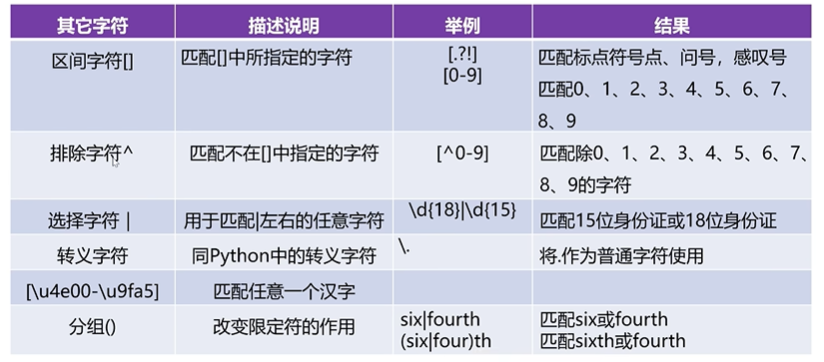
re模塊
re是python中的內置模塊,用于實現python中的正則表達式操作。
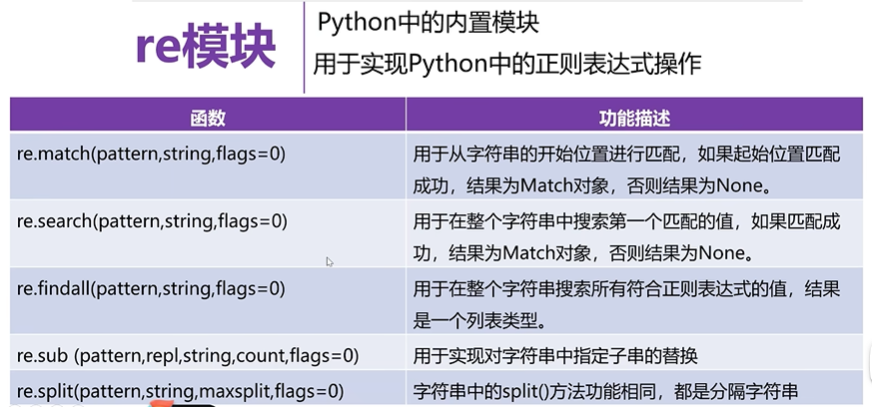
match函數的使用
import re # 導入re模塊
pattern='\d\.\d+' # +限定符,\d 0-9數字出現1次或多次
s='I study Python 3.11 every day' # 代匹配字符串
match=re.match(pattern,s,re.I) # 從頭開始查找
print(match) # None, 因為開頭沒有數字所以為nones2='3.11I study Python every day'
match2=re.match(pattern,s2,re.IGNORECASE)
print(match2) # <re.Match object; span=(0, 4), match='3.11'> /找到了,還告訴了范圍span=(0, 4)print('匹配值的起始位置:', match2.start()) # 匹配值的起始位置: 0
print('匹配值的結束位置:', match2.end()) # 匹配值的結束位置: 4
print('匹配區間的位置元素:', match2.span()) # 匹配區間的位置元素: (0, 4)
print('待配區間的字符串:', match2.string) # 待配區間的字符串: 3.11I study Python every day
print('匹配的數據:', match2.group()) # 匹配的數據: 3.11
函數的定義和調用
自定義函數
def 函數名詞 (參數列表):函數體[return 返回值列表]
def get_num(num): # num是形式參數s = 0for i in range (1,num+1):s+=iprint(f'1到{num}之間的累加和是:{s}')# 函數的調用
get_num(10) # 1到10之間的累加和是:55 # 10是實際參數
get_num(100) # 1到100之間的累加和是:5050
get_num(1000) # 1到1000之間的累加和是:500500print(get_num(1)) # None
其中 get_num(num) 中num是形式參數,get_num(10)中 10,100…是實際參數
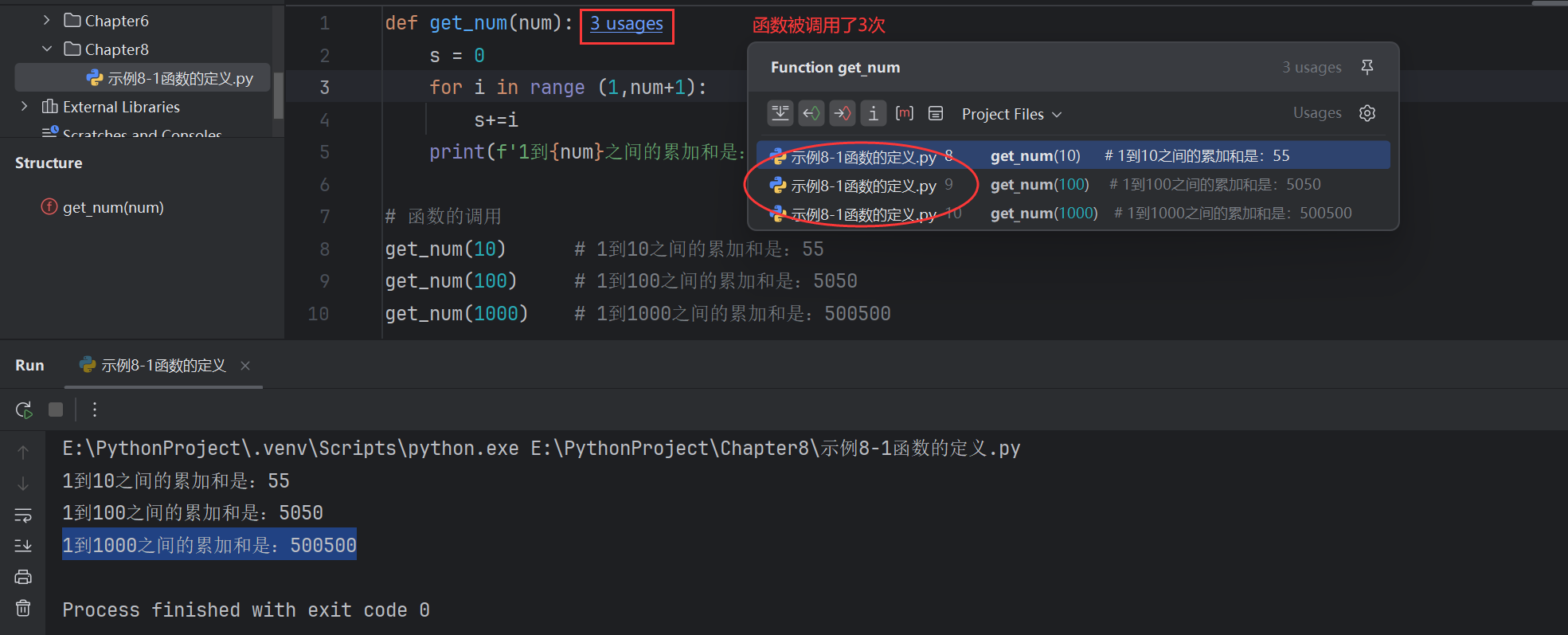
如果一個函數沒有通過return顯示的返回一個內容,python也會默認的給此函數返回一個“None”,可以通過print() 函數答應這個默認的返回值
變量的作用域

局部變量的使用
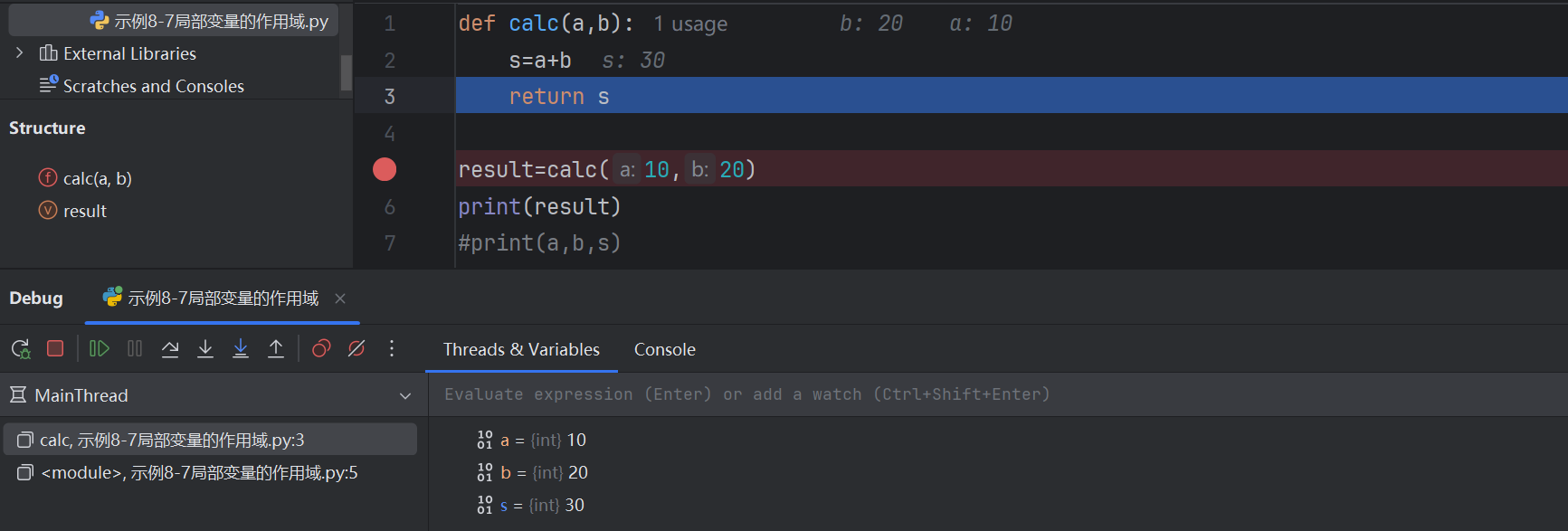
def calc(a,b):x=5s=x+a+breturn sprint(calc(10,20)) # 35
# print(x) # x是calc(a,b)內部定義的,所以打印會報錯NameError: name 'x' is not defined
全局變量的使用
a=100def calc(x,y):s=a+x+yreturn s
print(a) # 100
print(calc(10,20)) # 130
print("--"*30)def calc1(x,y):a=200 # 局部變量命名與全局變量重名s=a+x+y # a=200參與了此函數中的計算,也就是說當局部變量命名與全局變量重名時,局部變量的優先級更高。return s
print(a) # 100
print(calc1(10,20)) # 230
print("--"*30)def calc2(x,y):global b # b是在函數中定義的變量,但是使用了global關鍵字聲明,此時b就變成了全局變量b=300 # 聲明和賦值,必須是分開編寫的s=b+x+yreturn s
print(b) # NameError: name 'b' is not defined
print(calc2(10,20)) # 330
print(b) # 因為 b被global聲明為全局變量,所以b可以在calc2函數之外被打印出來,但在函數被調用之前會報錯匿名函數lambda
lambda
是指沒有名字的函數,這種函數只能使用一次,一般是在函數的函數體只有一句代碼且只有一個返回值時,可以使用匿名函數來簡化。
語法結構:result=lambda 參數列表:表達式
def calc(a,b):return a+b
print(calc(10,20)) # 30
print('+'*30)#將calc(a,b)改為匿名函數
s=lambda a,b:a+b # 此時s就是一個匿名函數
print(type(s)) # <class 'function'>#調用匿名函數
print(s(10,15))
print('@'*30)
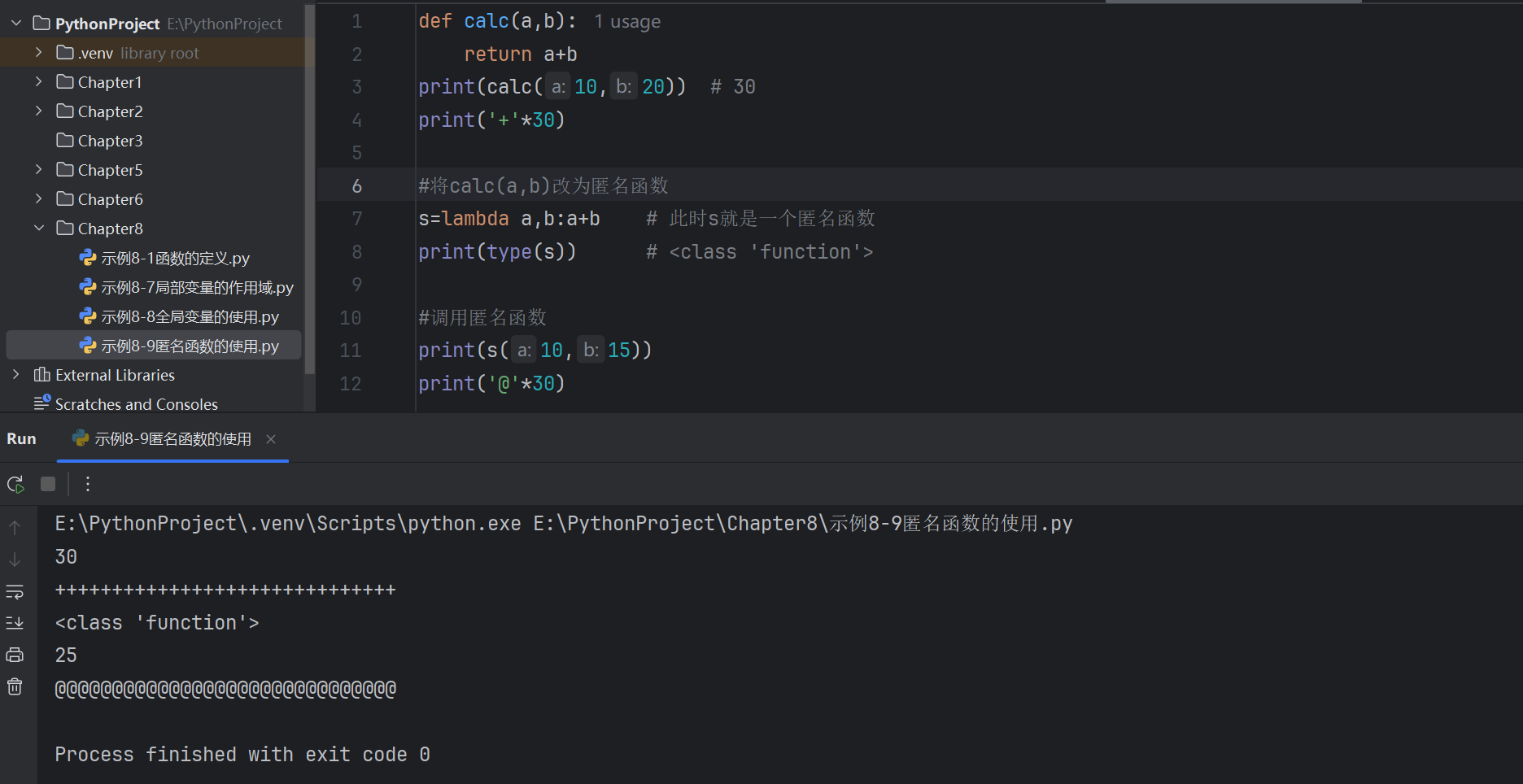
# 正常的列表循環取值
lst=[5,10,15,35,55]
for i in range(len(lst)):print(lst[i])
print('++'*30)# 使用lambda匿名函數取值
for i in range(len(lst)):result=lambda x:x[i] # 根據索引取值,result的類型是function, x是形式參數print(result(lst)) # lst是實際參數
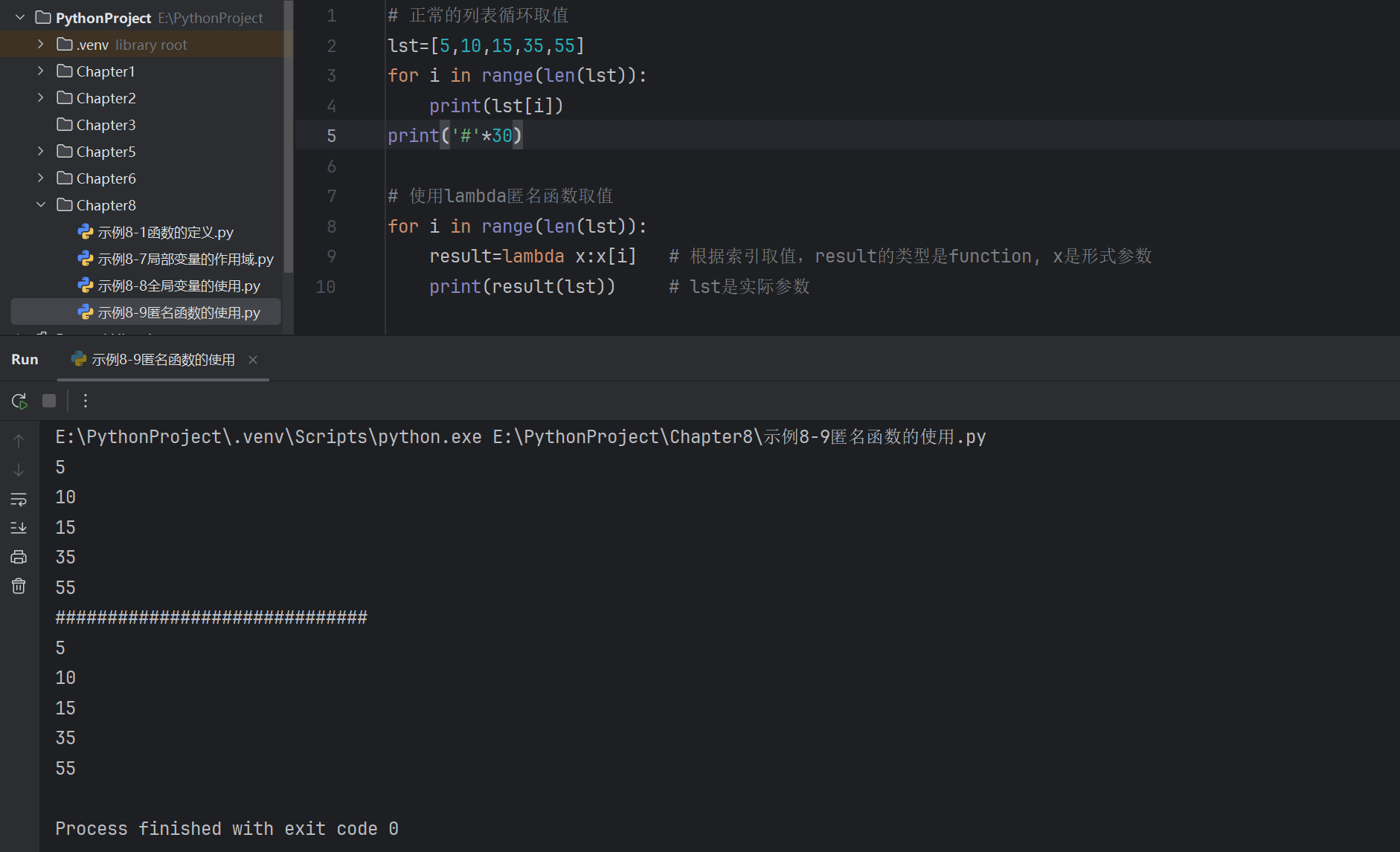
# 對列表按照score分數排序
student_score=[{'name':'小明','score':92},{'name':'紅紅','score':73},{'name':'濛濛','score':100},{'name':'蕾蕾','score':69},
]
student_score.sort(key=lambda x:x.get('score'),reverse=True)
print(student_score) # [{'name': '濛濛', 'score': 100}, {'name': '小明', 'score': 92}, {'name': '紅紅', 'score': 73}, {'name': '蕾蕾', 'score': 69}]
類與對象
類的組成

class Student:# 類的屬性:定義在類中,方法外的變量school='長江大學'# 初始化方法def __init__(self,name,age): # name,age是初始化方法的形式參數,是局部變量,name,age的作用域是整個__init__方法self.name=name # =左側self.name是實例屬性,右邊name是局部變量,將局部變量的值xm賦值給實例屬性self.nameself.age=age # 實例的名稱和局部變量的名稱可以相同# 定義在類中的函數,稱為方法,自帶一個參數selfdef show(self):print(f'我叫:{self.name},今年:{self.age}歲了')# 靜態方法@staticmethoddef sm():print('這是一個靜態方法,不能調用實例屬性,也不能調用實例方法')@classmethoddef cm(cls): # cls --> class的簡寫print('這是一個類方法,不能調用實例屬性,也不能調用實例方法')#創建類的對象
stu=Student('lei',13) #為什莫這里傳入了兩個參數,因為__init__方法中有兩個形參,self是自帶的參數,無需手動傳入
print(stu) # <__main__.Student object at 0x000002A493379B50>
#實例屬性,使用對象名進行打點調用
print(stu.name,stu.age) # lei 13
#類屬性,直接使用類名打點調用
print(Student.school) # 長江大學
#實例方法,使用對象名打點調用
stu.show() # 我叫:lei,今年:13歲了#類方法,@classmethod進行修飾的方法,直接使用類名打點調用
Student.cm() # 這是一個類方法,不能調用實例屬性,也不能調用實例方法#靜態方法,@staticmethod進行修飾的方法,直接使用類名打點調用
Student.sm() # 這是一個靜態方法,不能調用實例屬性,也不能調用實例方法
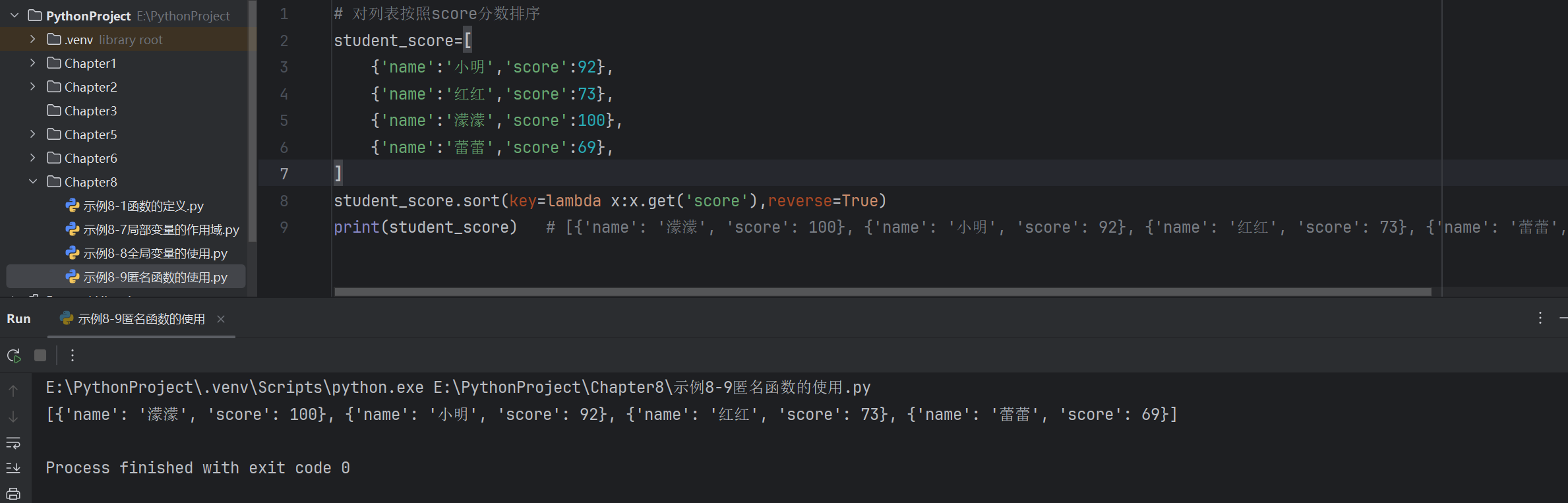
創建多個類的實例對象
class Student:# 類的屬性:定義在類中,方法外的變量school='長江大學'# 初始化方法def __init__(self,name,age): # name,age是初始化方法的形式參數,是局部變量,name,age的作用域是整個__init__方法self.name=name # =左側self.name是實例屬性,右邊name是局部變量,將局部變量的值xm賦值給實例屬性self.nameself.age=age # 實例的名稱和局部變量的名稱可以相同# 定義在類中的函數,稱為方法,自帶一個參數selfdef show(self):print(f'我叫:{self.name},今年:{self.age}歲了')stu=Student('萌萌',4)
stu1=Student('淚淚',8)
stu2=Student('微微',12)
stu3=Student('小小',9)lst=[stu,stu1,stu2,stu3]
for item in lst:item.show()
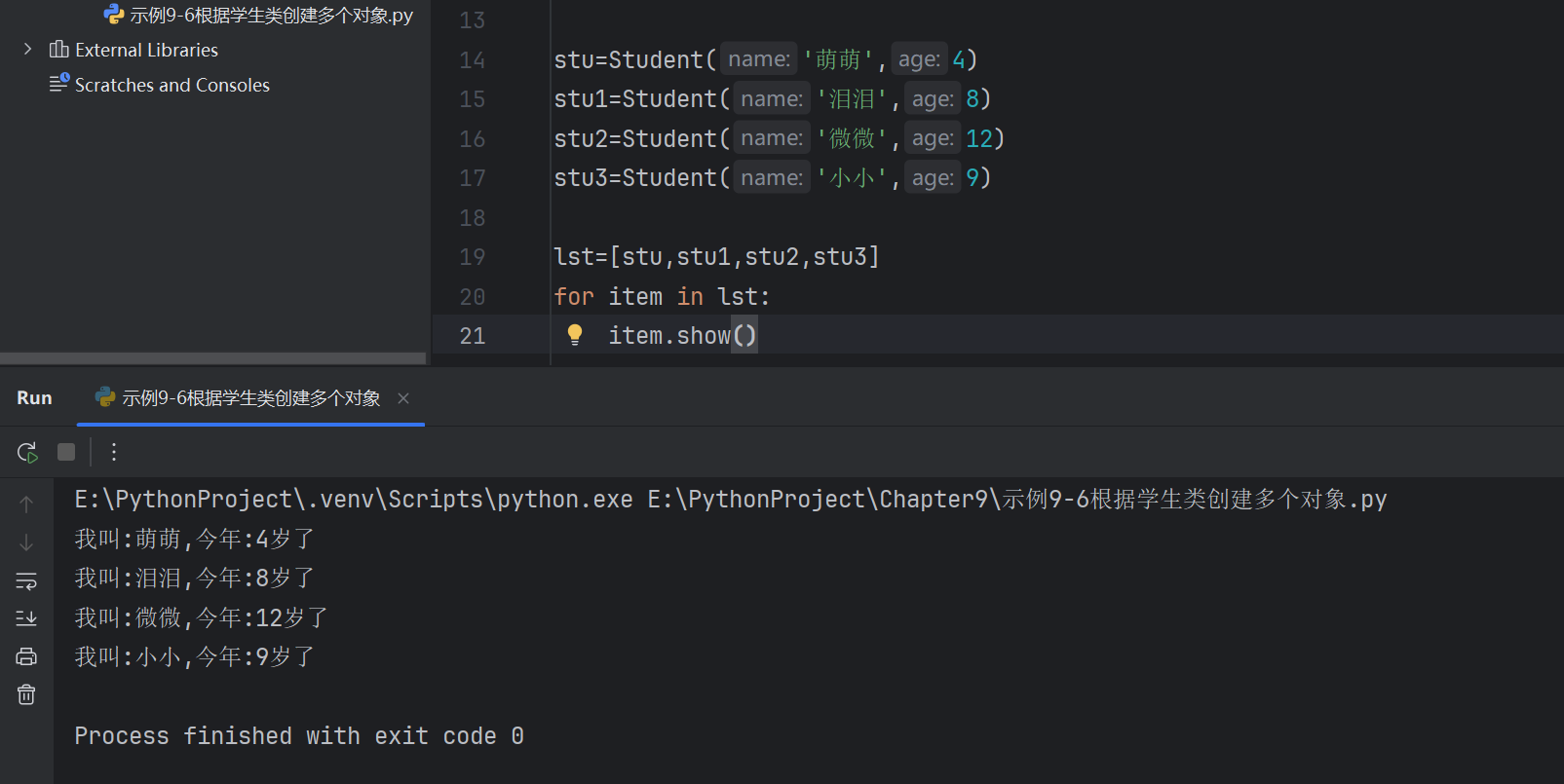
動態綁定屬性和方法
class Student:# 類的屬性:定義在類中,方法外的變量school='長江大學'# 初始化方法def __init__(self,name,age): # name,age是初始化方法的形式參數,是局部變量,name,age的作用域是整個__init__方法self.name=name # =左側self.name是實例屬性,右邊name是局部變量,將局部變量的值xm賦值給實例屬性self.nameself.age=age # 實例的名稱和局部變量的名稱可以相同# 定義在類中的函數,稱為方法,自帶一個參數selfdef show(self):print(f'我叫:{self.name},今年:{self.age}歲了')stu=Student('萌萌',4)
stu1=Student('淚淚',8)#給stu1動態綁定一個除了name和age的另外的屬性
stu1.gender='男'
print(stu1.name,stu1.age,stu1.gender) # 淚淚 8 男# 動態綁定方法
def introduce():print('我是一個普通的函數,我被動態綁定成了su1對象的方法')
stu1.meth=introduce #函數的賦值#調用
stu1.meth() # 我是一個普通的函數,我被動態綁定成了su1對象的方法
封裝、繼承、多態

封裝

class Student():# 首尾雙下劃線def __init__(self,name,age,gender):self._name=name # self._name受保護的,只能本類和子類訪問self.__age=age # self.__age 表示私有的,只能本身去訪問self.gender=gender # 普通的示例屬性,類的內部,外部,以及子類都可以訪問def _fun1(self): # 受保護的print('子類及本身可以訪問')def __fun2(self): # 私有的print('只有定義的類可以訪問')def show(self): # 普通的實例方法self._fun1() # 類本身訪問受保護的方法self.__fun2() # 類本身訪問私有方法print(self._name) # 受保護的實例屬性print(self.__age) # 私有的實例屬性# 創建一個學生類的對象
stu=Student('蕾蕾',18,'男')
# 類的外部
print(stu._name) # 蕾蕾
print(stu.__age) # AttributeError: 'Student' object has no attribute '__age'. Did you mean: '_name'? 超出類的定義范圍就不能用了# 調用受保護的實例方法
#stu._fun1() # 子類以及本身可以訪問
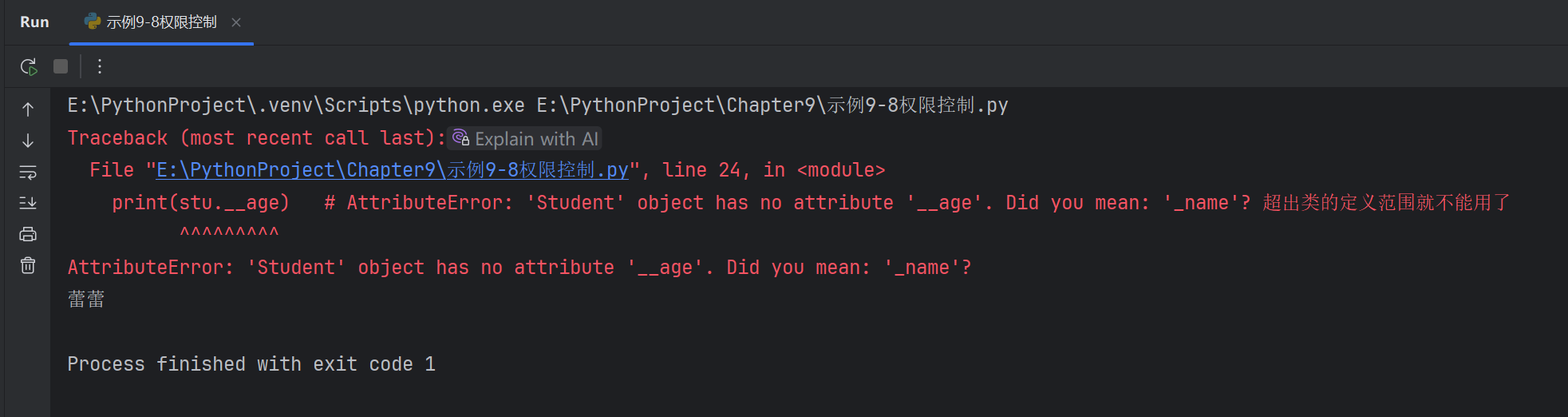
訪問私有屬性和方法
class Student():# 首尾雙下劃線def __init__(self,name,age,gender):self._name=name # self._name受保護的,只能本類和子類訪問self.__age=age # self.__age 表示私有的,只能本身去訪問self.gender=gender # 普通的示例屬性,類的內部,外部,以及子類都可以訪問def _fun1(self): # 受保護的print('子類及本身可以訪問')def __fun2(self): # 私有的print('只有定義的類可以訪問')def show(self): # 普通的實例方法self._fun1() # 類本身訪問受保護的方法self.__fun2() # 類本身訪問私有方法print(self._name) # 受保護的實例屬性print(self.__age) # 私有的實例屬性# 創建一個學生類的對象
stu=Student('蕾蕾',18,'男')#私有的實例屬性和方法是真的不能訪問嗎
print(stu._Student__age) # 18 訪問私有屬性需要通過對象名Student來訪問
stu._Student__fun2() # 只有定義的類可以訪問
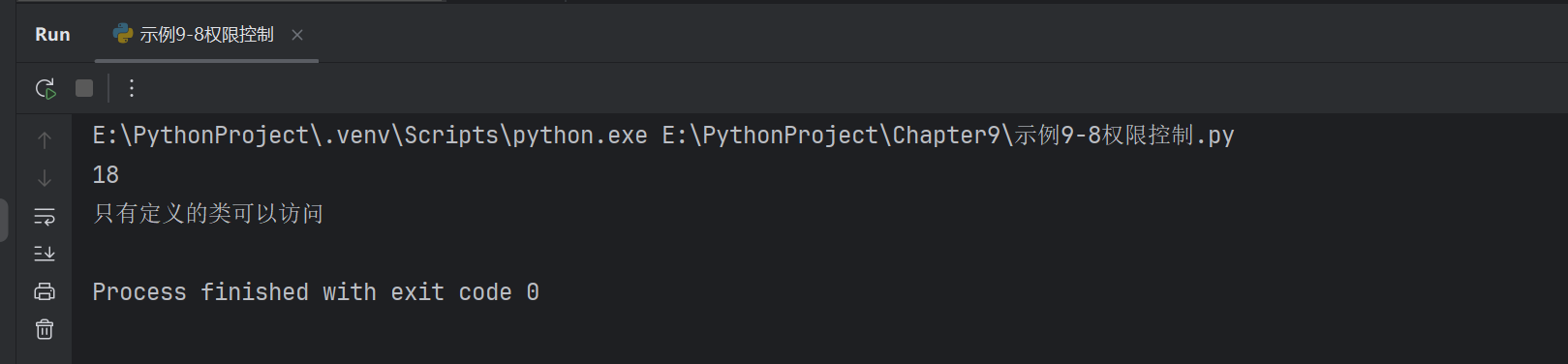
dir() 函數。
print(dir(stu))
我們可以通過dir() 內置函數,可以看出stu這個對象中的所有屬性和方法。也看一看出權限訪問控制在這里的是怎么第一書寫規范的。
['_Student__age', '_Student__fun2', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_fun1', '_name', 'gender', 'show']
繼承
多態
Object 類

對象的特殊方法

特殊屬性
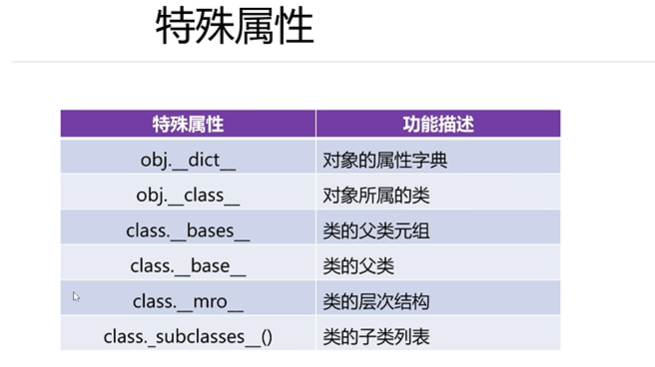
模塊
常用內置模塊
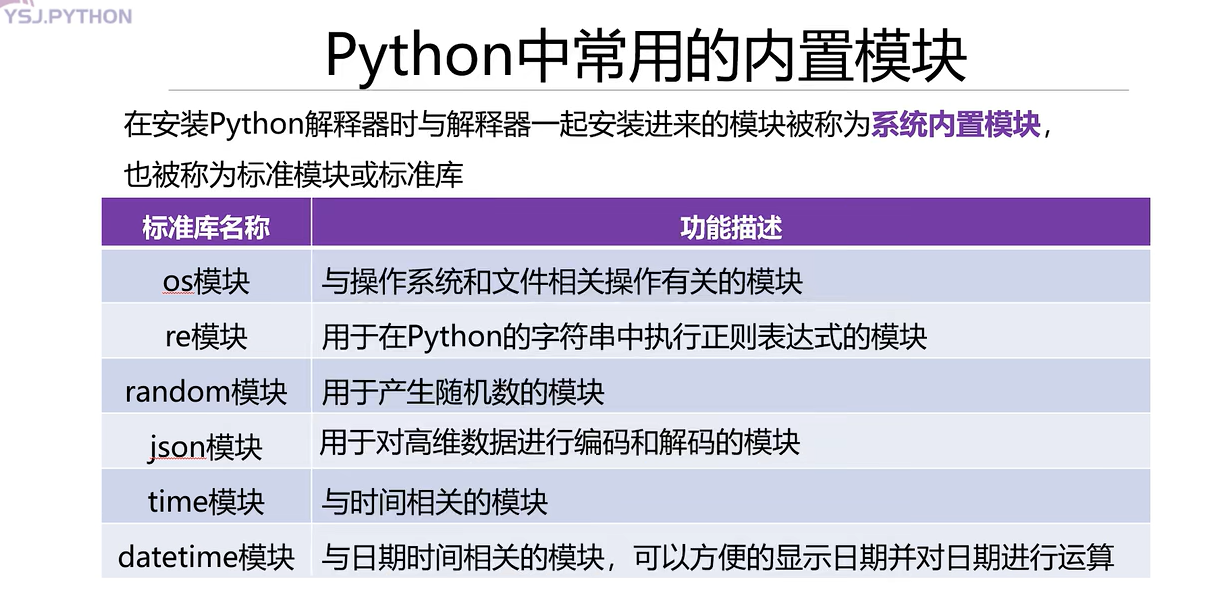
random 模塊

time 模塊
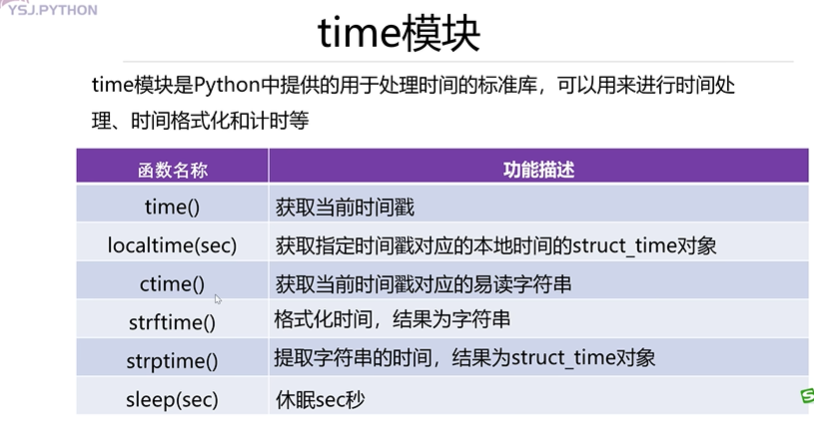
時間格式化字符串
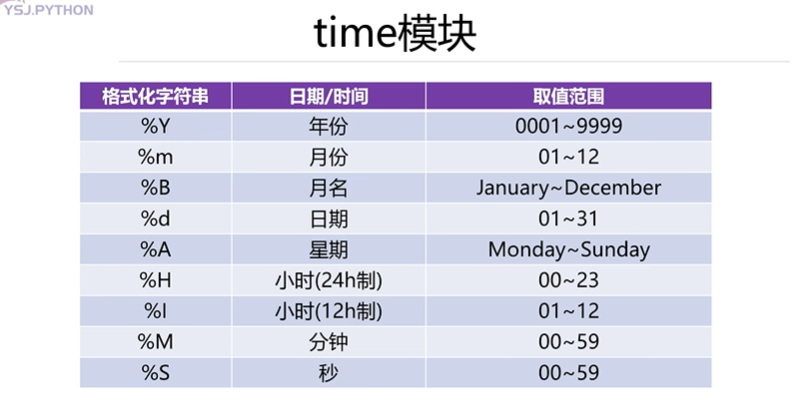
datetime 模塊
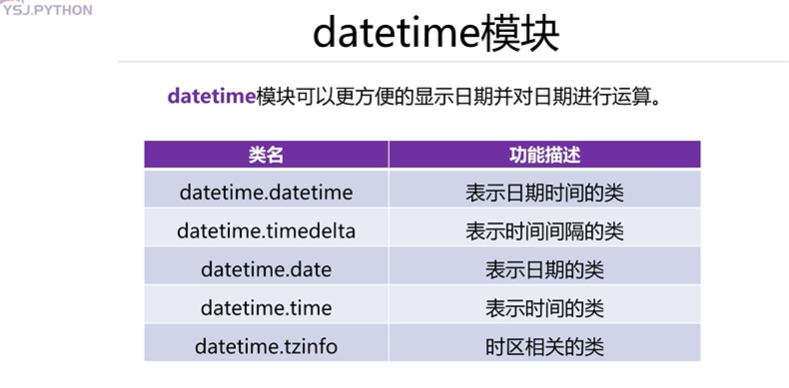
os 模塊
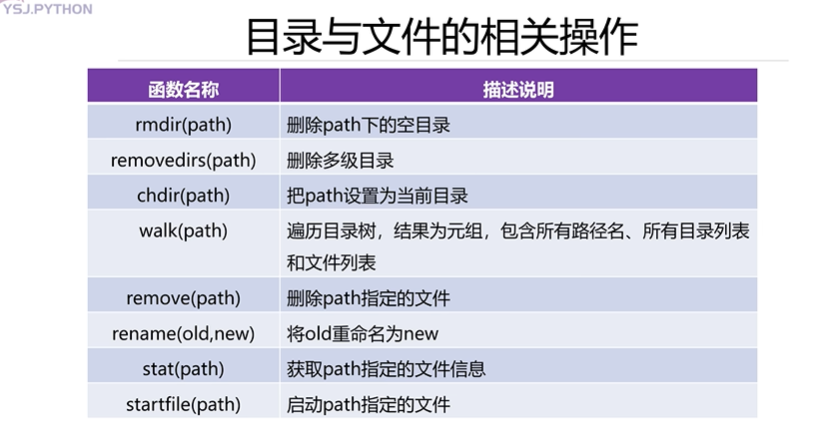
import osprint('當前的工作路徑:',os.listdir())
lst=os.listdir()
print('當前路徑下的所有目錄以及文件:',lst)
print('指定路徑下所有目錄以及文件:',os.listdir('E:/PythonProject'))# 創建目錄
os.mkdir('好好學習') # 若文件已存在,則報錯FileExistsError: [WinError 183] 當文件已存在時,無法創建該文件。: '好好學習'
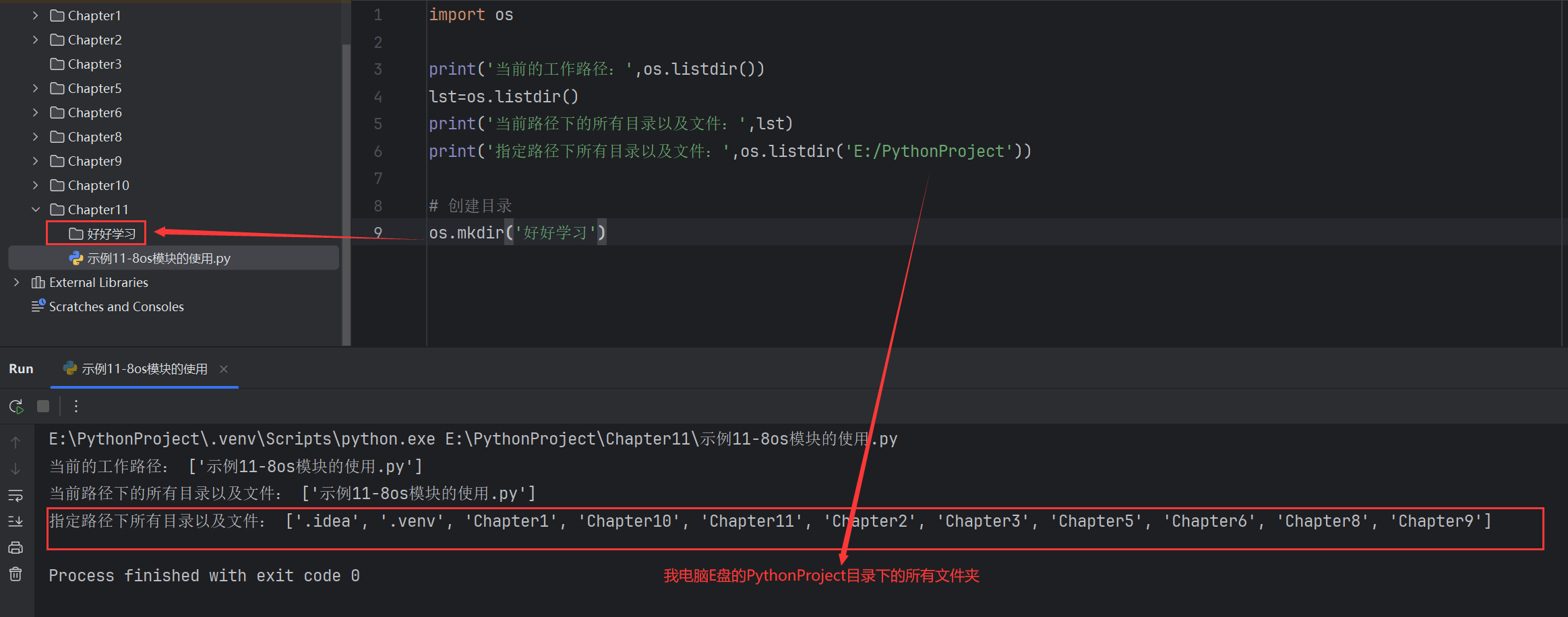
常用第三方模塊
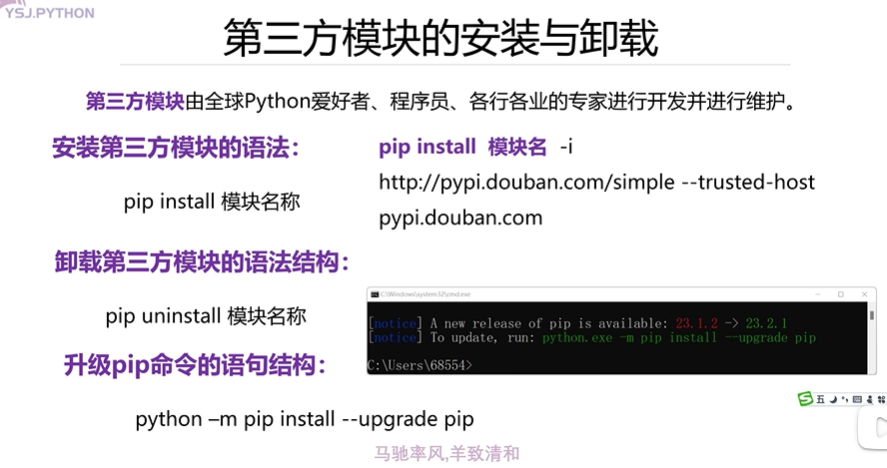
第三方模塊的安裝與卸載
爬蟲庫的安裝
pip install requests
requests

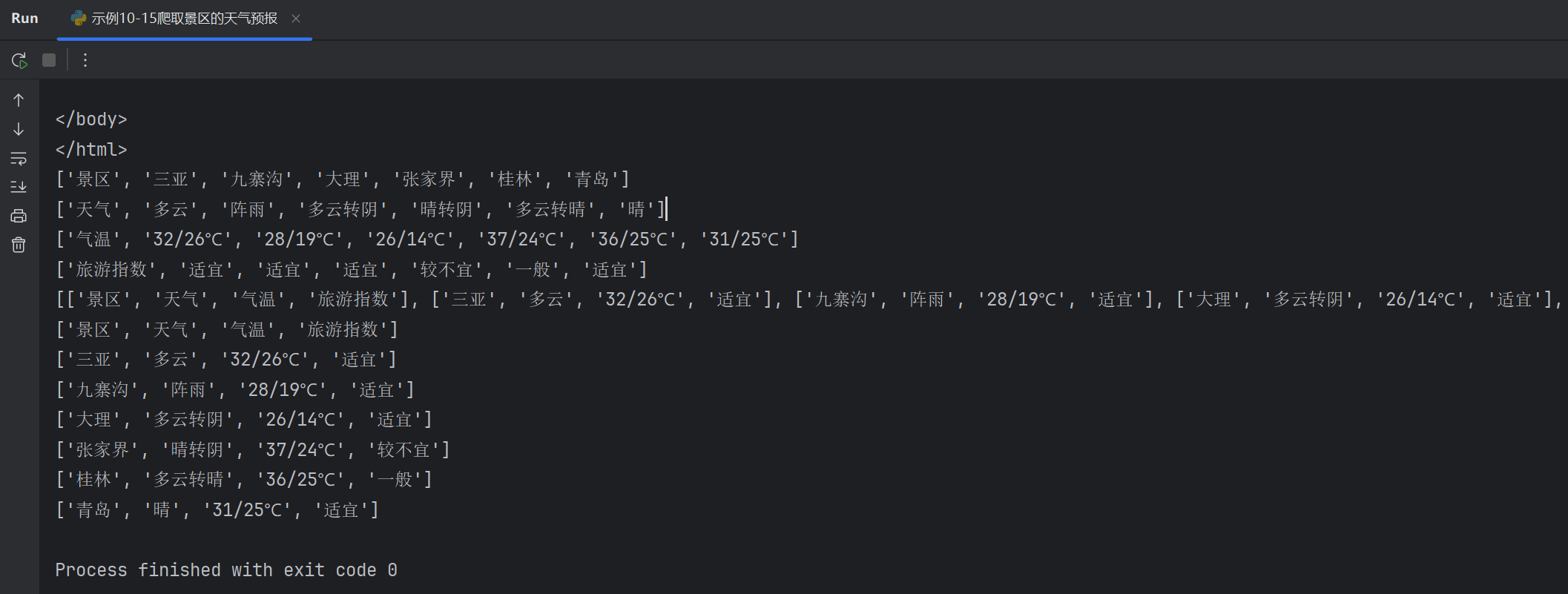
爬取景區的天氣預報
import re
import requests
url='https://www.weather.com.cn/weather40d/101280601.shtml' # 爬蟲打開的瀏覽器上的網頁
resp=requests.get(url) # 打開瀏覽器并打開網址
# 設置編碼格式
resp.encoding='utf-8'
print(resp.text) # resp相應對象,對象名.屬性名 resp.textcity=re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>',resp.text)
weather=re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>',resp.text)
wd=re.findall('<span class="wd">(.*)</span>',resp.text)
zs=re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>',resp.text)print(city)
print(weather)
print(wd)
print(zs)lst=[]
for a,b,c,d in zip(city,weather,wd,zs):lst.append([a,b,c,d])
print(lst)
for item in lst:print(item)
爬取百度LOGO圖片
import requests
url='https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
resp=requests.get(url)# 保存圖片到本地
with open('logo.png','wb')as file:file.write(resp.content)
openpyxl
將爬取到景區的天氣預報數據保存在Excel中
先封裝爬取到的天氣信息,以便在保存到Excel代碼中可以import
weather.py
import re
import requestsdef get_html():url='https://www.weather.com.cn/weather40d/101280601.shtml' # 爬蟲打開的瀏覽器上的網頁resp=requests.get(url) # 打開瀏覽器并打開網址# 設置編碼格式resp.encoding='utf-8'return resp.textdef parse_html(html_str):city=re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>',html_str)weather=re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>',html_str)wd=re.findall('<span class="wd">(.*)</span>',html_str)zs=re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>',html_str)lst=[]for a,b,c,d in zip(city,weather,wd,zs):lst.append([a,b,c,d])return lst
保存Excel代碼
import weather
import openpyxlhtml=weather.get_html() # 發請求,得響應結果
lst=weather.parse_html(html) # 解析數據# 創建一個新的Excel工作簿
workbook=openpyxl.Workbook() # 創建對象,注意這里要加括號()# 在Excel文件中創建工作表
sheet=workbook.create_sheet('景區天氣')# 向工作表中添加數據
for item in lst:sheet.append(item) # 一次添加一行workbook.save('景區天氣.xlsx')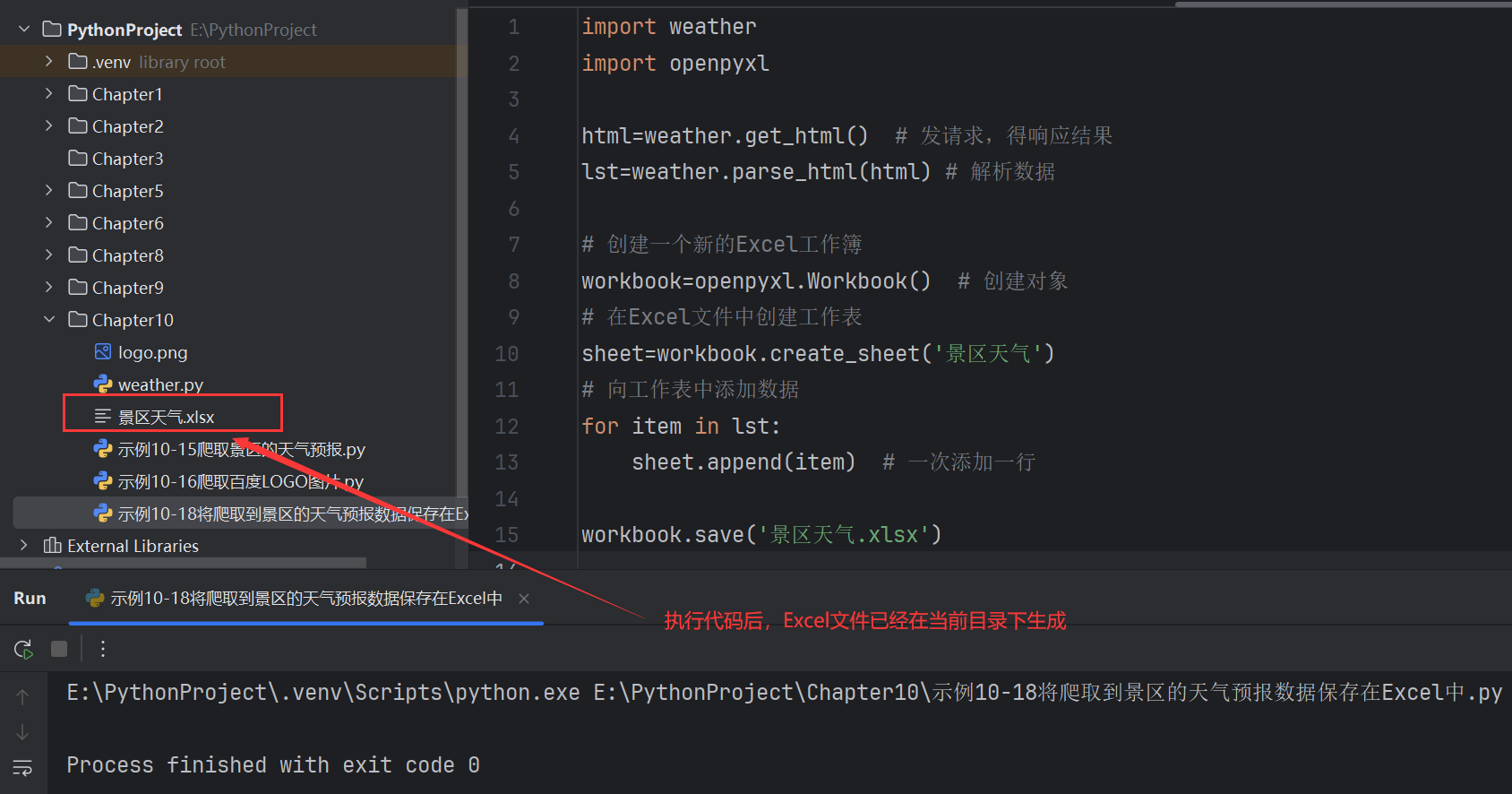
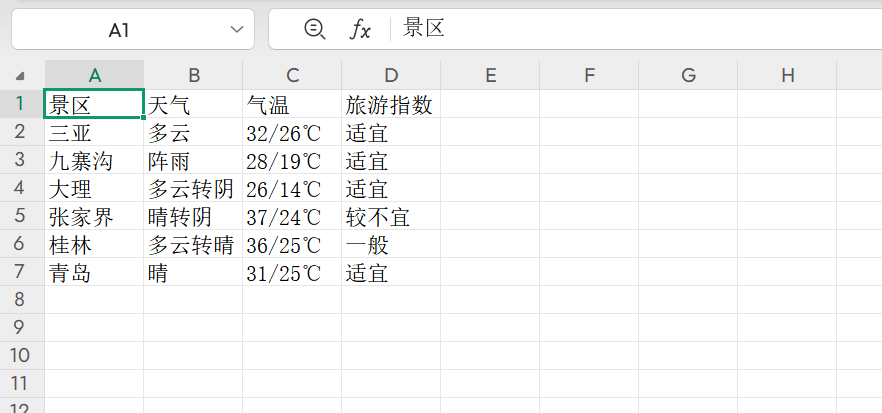
再從Excel中讀取數據
import openpyxl
# 打開工作簿
workbook=openpyxl.load_workbook('景區天氣.xlsx')# 選擇要操作的工作表
sheet=workbook['景區天氣']# 表格數據是二維列表,先遍歷的是行,后遍歷的是列
lst=[] # 存儲的是行數據
for row in sheet.rows:sublst=[] # 存儲單元格數據for cell in row: # cell單元格sublst.append(cell.value)lst.append(sublst)for item in lst:print(item)

















` 數據庫查詢函數)
![[系統架構設計師]通信系統架構設計理論與實踐(十七)](http://pic.xiahunao.cn/[系統架構設計師]通信系統架構設計理論與實踐(十七))
