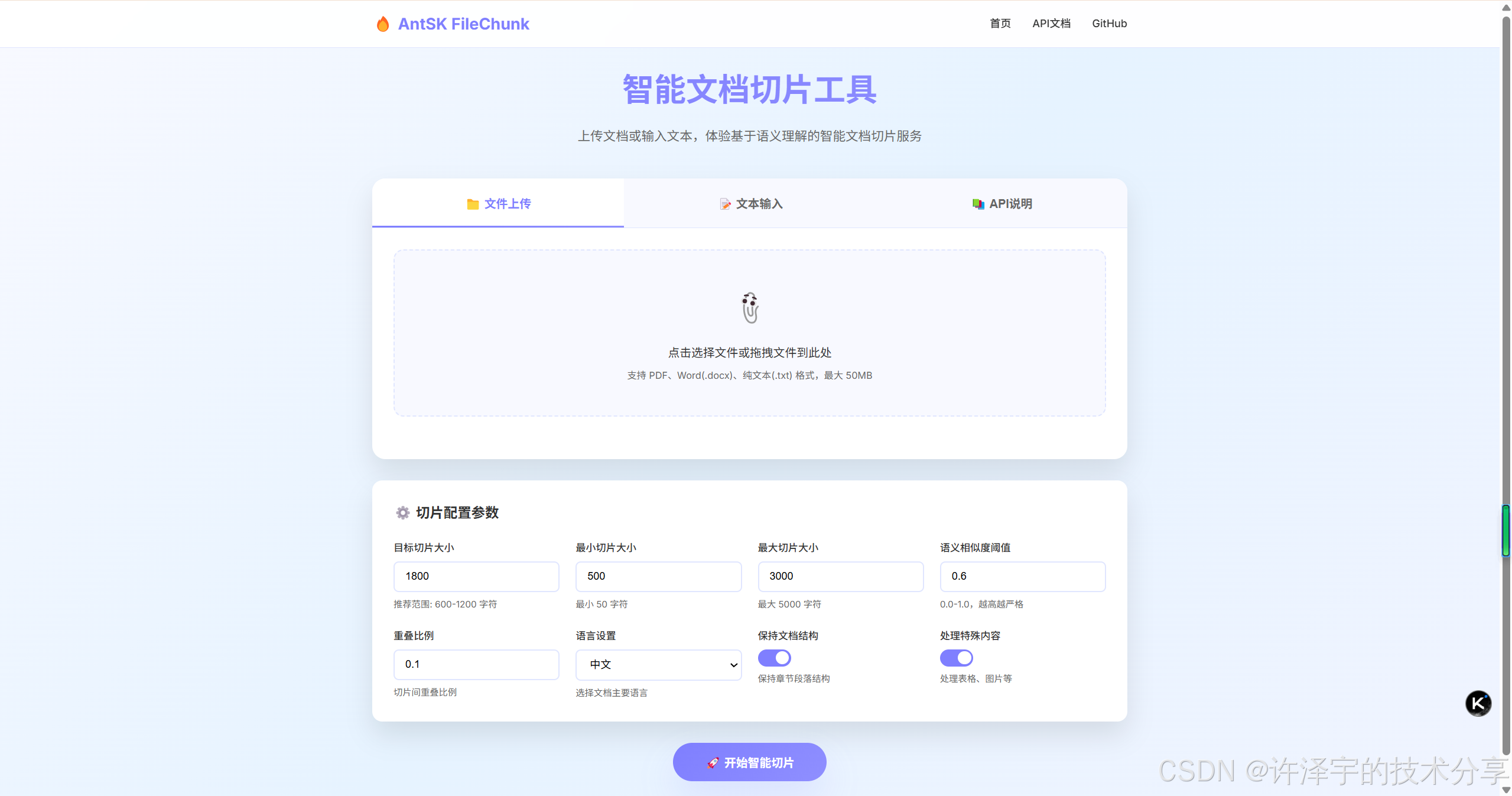
在當今大語言模型(LLM)應用蓬勃發展的時代,我們面臨著一個看似簡單卻至關重要的問題:如何有效地處理長文本?無論是構建知識庫、實現RAG(檢索增強生成)系統,還是進行文檔智能分析,都離不開一個核心環節——文本切片。
傳統的文本切片方法大多采用固定長度或基于Token數量的簡單切分策略。這些方法雖然實現簡單,但卻帶來了一系列問題:語義割裂、上下文丟失、格式混亂等。想象一下,如果一個重要的概念解釋被生硬地切成兩半,或者一個表格的數據與其標題被分到不同切片中,這對后續的檢索和理解將造成多大的障礙?
今天,我要向大家介紹一個開源項目——AntSK-FileChunk,它通過語義理解的方式,徹底改變了我們處理文本切片的方式。這不僅是一個工具,更是一種思維方式的轉變:從機械切分到智能理解。
一、傳統文本切片的痛點與挑戰
在深入了解AntSK-FileChunk之前,讓我們先剖析一下傳統文本切片方法存在的主要問題:
1.1 語義割裂:切斷了知識的脈絡
傳統的固定長度切分方法就像一把無情的大刀,不管內容如何,到了指定長度就切一刀。這種方式經常會在句子中間、段落中間,甚至一個完整概念的中間進行切分,導致語義的嚴重割裂。
舉個例子,假設有這樣一段文本:
神經網絡是一種模擬人腦結構和功能的計算模型。它由大量相互連接的神經元組成,每個神經元接收輸入信號,經過處理后產生輸出信號。神經網絡通過調整神經元之間的連接權重來學習數據中的模式。
如果使用固定長度切分(假設限制為30個字符),可能會變成:
切片1:?神經網絡是一種模擬人腦結構和功能
切片2:?的計算模型。它由大量相互連接的
切片3:?神經元組成,每個神經元接收輸入
...
顯然,這種切分方式破壞了原文的語義完整性,第一個切片甚至沒有完成一個完整的定義。
1.2 上下文丟失:孤立的信息碎片
傳統切片方法無法保持相關內容的關聯性。當我們將文檔切分成多個小塊后,每個塊都成了孤立的信息孤島,失去了與其他部分的聯系。
例如,在一篇論文中,"方法"部分可能引用了"背景"部分的概念,或者"結論"部分需要結合"實驗結果"來理解。如果這些相關內容被分到不同的切片中,且沒有任何重疊或關聯機制,那么每個切片的信息價值都會大打折扣。
1.3 格式處理:結構化內容的噩夢
現實世界的文檔往往包含各種復雜的格式元素:表格、圖片、公式、代碼塊等。傳統切片方法對這些特殊內容的處理往往力不從心。
想象一下,一個包含10行的表格被切成了兩半,或者一個代碼示例被分割成多個片段,這不僅會導致信息的不完整,還可能引入錯誤的理解。
1.4 質量評估:缺乏有效的衡量標準
傳統切片方法通常缺乏對切片質量的評估機制。我們很難客觀地判斷一個切片是否"好"——它是否保持了語義的完整性?是否包含了足夠的上下文?是否有效地處理了特殊格式?
沒有這些評估標準,我們就無法系統地優化切片策略,只能憑經驗進行調整,這顯然不是一個可靠的方法。
二、AntSK-FileChunk:語義切片的創新之道
面對傳統文本切片的種種挑戰,AntSK-FileChunk提出了一套全新的解決方案——基于語義理解的智能文本切片。這不僅是技術上的創新,更是思維方式的轉變。
2.1 核心理念:以語義為中心
與傳統方法不同,AntSK-FileChunk的核心理念是以語義為中心,而非簡單地以字符數或Token數為標準。這意味著:
-
尊重語義邊界:切片的邊界應該盡可能地與語義邊界一致,如段落、句子或完整的概念單元。
-
保持上下文連貫:相關的內容應該盡可能地保持在同一個切片中,或通過重疊機制保持連貫。
-
適應內容特點:切片大小應該根據內容的復雜性和密度動態調整,而非固定不變。
2.2 技術架構:模塊化設計
查看AntSK-FileChunk的源碼,我們可以看到它采用了清晰的模塊化設計,主要包括以下幾個核心組件:
SemanticChunker?(主控制器)
├──?DocumentParser?(文檔解析器)
├──?SemanticAnalyzer?(語義分析器)
├──?ChunkOptimizer?(切片優化器)
└──?QualityEvaluator?(質量評估器)
這種設計不僅使代碼結構清晰,也使得每個組件可以獨立優化和擴展。讓我們深入了解每個組件的功能:
2.2.1 DocumentParser:智能文檔解析
DocumentParser負責將各種格式的文檔(PDF、Word、純文本等)解析為統一的結構化表示。它不僅提取文本內容,還識別文檔的結構信息,如標題、段落、表格等。
從源碼中可以看到,它針對不同的文檔格式采用了不同的處理策略:
def?parse_file(self,?file_path:?Union[str,?Path])?->?DocumentContent:file_extension?=?file_path.suffix.lower()if?file_extension?==?'.pdf':return?self._parse_pdf(file_path)elif?file_extension?in?['.docx',?'.doc']:return?self._parse_docx(file_path)elif?file_extension?==?'.txt':return?self._parse_txt(file_path)
對于PDF文件,它使用PyMuPDF庫提取文本、識別表格和圖片;對于Word文檔,則使用python-docx庫進行解析;對于純文本文件,則進行智能段落分割。
2.2.2 SemanticAnalyzer:深度語義分析
SemanticAnalyzer是整個系統的核心,它負責計算文本的語義向量,并基于這些向量分析文本的語義關系。
它使用預訓練的Transformer模型(如SentenceTransformer)將文本轉換為高維向量表示:
def?compute_embeddings(self,?texts:?List[str])?->?np.ndarray:processed_texts?=?[self._preprocess_text(text)?for?text?in?texts]embeddings?=?self.model.encode(processed_texts,show_progress_bar=True,batch_size=32,normalize_embeddings=True??#?歸一化向量)return?embeddings
這些向量捕捉了文本的語義信息,使得系統能夠判斷不同文本片段之間的語義相似度,從而為切片決策提供依據。
2.2.3 SemanticChunker:智能切片決策
SemanticChunker是整個系統的主控制器,它協調各個組件的工作,并實現核心的切片算法。
從源碼中可以看到,它的切片決策不僅考慮了文本長度,更重要的是考慮了語義連貫性:
def?_should_start_new_chunk(self,?current_indices,?current_length,?new_para_length,?embeddings,?new_para_index)?->?bool:#?硬性長度限制potential_length?=?current_length?+?new_para_lengthif?potential_length?>?self.config.max_chunk_size:??#?默認1500字符return?True#?語義連貫性檢查semantic_coherence?=?self._calculate_semantic_coherence(current_indices,?new_para_index,?embeddings)if?semantic_coherence?<?self.config.semantic_threshold:??#?默認0.7if?current_length?>=?self.config.target_chunk_size:??#?默認800字符return?True
這段代碼展示了切片決策的兩個關鍵條件:
-
硬性長度限制:確保切片不會過長,超過模型的處理能力。
-
語義連貫性檢查:通過計算語義相似度,判斷新段落是否與當前切片在語義上連貫。
2.2.4 ChunkOptimizer:切片優化
切片生成后,ChunkOptimizer會對初步切片進行優化,包括合并過小的切片、分割過大的切片、優化切片邊界等。
這一步確保了最終的切片不僅在語義上連貫,也在長度上適合后續處理。
2.2.5 QualityEvaluator:質量評估
QualityEvaluator提供了一套多維度的切片質量評估體系,包括:
-
連貫性:切片內部的語義連貫程度
-
完整性:切片是否包含完整的語義單元
-
長度平衡性:切片長度的分布是否均衡
-
語義密度:切片中包含的信息密度
-
邊界質量:切片邊界是否符合語義邊界
這些評估指標不僅可以用來判斷切片質量,還可以指導切片策略的優化。
2.3 工作流程:從文檔到切片
了解了各個組件的功能后,讓我們看看整個系統的工作流程:
-
文檔解析:將輸入文檔解析為結構化的段落列表。
-
預處理:對段落進行清理、過濾和規范化。
-
語義向量計算:為每個段落計算語義向量。
-
智能切片:基于語義相似度和長度限制,將段落組織成切片。
-
切片優化:合并過小切片,分割過大切片,優化切片邊界。
-
質量評估:對切片質量進行多維度評估,提供優化建議。
這個流程確保了最終的切片既滿足技術要求(如長度限制),又保持了語義的完整性和連貫性。
三、深入理解語義切片算法
語義切片的核心在于如何基于語義相似度進行切片決策。讓我們深入了解AntSK-FileChunk的語義切片算法。
3.1 語義向量計算
語義切片的第一步是計算文本的語義向量。AntSK-FileChunk使用預訓練的Transformer模型將文本轉換為高維向量:
def?compute_embeddings(self,?texts:?List[str])?->?np.ndarray:#?預處理文本processed_texts?=?[self._preprocess_text(text)?for?text?in?texts]#?計算嵌入向量embeddings?=?self.model.encode(processed_texts,show_progress_bar=True,batch_size=32,normalize_embeddings=True??#?歸一化向量)return?embeddings
這些向量捕捉了文本的語義信息,使得我們可以通過計算向量之間的相似度來判斷文本之間的語義關系。
3.2 語義相似度計算
有了語義向量后,我們可以通過余弦相似度計算文本之間的語義相似度:
def?_calculate_semantic_coherence(self,?current_indices,?new_index,?embeddings)?->?float:#?提取新段落的語義向量new_embedding?=?embeddings[new_index:new_index+1]#?提取當前切片中所有段落的語義向量current_embeddings?=?embeddings[current_indices]#?計算新段落與當前切片中所有段落的相似度similarities?=?cosine_similarity(new_embedding,?current_embeddings)[0]#?返回平均相似度作為連貫性得分return?np.mean(similarities)
這個函數計算了新段落與當前切片中所有段落的平均相似度,作為語義連貫性的度量。
3.3 切片邊界決策
基于語義相似度和長度限制,AntSK-FileChunk實現了智能的切片邊界決策:
def?_should_start_new_chunk(self,?current_indices,?current_length,?new_para_length,?embeddings,?new_para_index)?->?bool:#?硬性長度限制potential_length?=?current_length?+?new_para_lengthif?potential_length?>?self.config.max_chunk_size:??#?默認1500字符return?True#?語義連貫性檢查semantic_coherence?=?self._calculate_semantic_coherence(current_indices,?new_para_index,?embeddings)if?semantic_coherence?<?self.config.semantic_threshold:??#?默認0.7if?current_length?>=?self.config.target_chunk_size:??#?默認800字符return?Truereturn?False
這個函數決定了是否應該開始一個新的切片,它考慮了兩個關鍵因素:
-
長度限制:如果添加新段落后切片長度超過最大限制,則開始新切片。
-
語義連貫性:如果新段落與當前切片的語義連貫性低于閾值,且當前切片已達到目標長度,則開始新切片。
這種決策機制確保了切片既不會過長,也保持了語義的連貫性。
3.4 重疊處理機制
為了進一步增強切片之間的連續性,AntSK-FileChunk實現了重疊處理機制:
def?_calculate_overlap(self,?indices:?List[int],?content:?List[str])?->?Tuple[List[int],?List[str]]:#?計算重疊段落數量overlap_count?=?max(1,?int(len(indices)?*?self.config.overlap_ratio))#?取當前切片的最后幾個段落作為重疊內容overlap_indices?=?indices[-overlap_count:]overlap_content?=?content[-overlap_count:]return?overlap_indices,?overlap_content
這個函數計算了當前切片與下一個切片之間應該重疊的段落,確保了切片之間的平滑過渡。
四、實際應用案例分析
理論講解之后,讓我們通過幾個實際案例來看看AntSK-FileChunk的語義切片效果。
4.1 學術論文處理
學術論文通常包含復雜的結構和專業術語,是傳統切片方法的難點。
假設我們有一篇AI領域的學術論文,其中包含了大量的專業術語、公式和引用。使用傳統的固定長度切分方法,可能會導致一個公式被切分成兩半,或者一個概念的定義與其解釋被分到不同的切片中。
而使用AntSK-FileChunk的語義切片,系統會:
-
識別論文的結構(標題、摘要、章節等)
-
理解專業術語之間的語義關聯
-
保持公式和引用的完整性
-
確保每個切片都包含足夠的上下文
最終,切片結果會更加符合人類的閱讀理解習慣,便于后續的檢索和分析。
4.2 法律文檔處理
法律文檔是另一類具有挑戰性的文本,它們通常包含復雜的條款、引用和專業術語。
使用AntSK-FileChunk處理法律文檔,系統會:
-
識別法律條款的邊界
-
保持相關條款之間的關聯
-
確保引用和定義的完整性
-
適當處理列表和表格等特殊格式
這樣處理后的切片不僅保持了法律文檔的嚴謹性,也便于后續的法律分析和檢索。
4.3 技術文檔處理
技術文檔通常包含代碼示例、API說明、表格等特殊內容,這些都是傳統切片方法的難點。
使用AntSK-FileChunk處理技術文檔,系統會:
-
識別代碼塊的邊界,確保代碼示例的完整性
-
保持API說明與其參數說明的關聯
-
完整處理表格和列表
-
識別技術術語之間的關聯
這樣處理后的切片更加適合技術文檔的特點,便于開發者查詢和理解。
五、性能與優化
語義切片雖然在質量上有明顯優勢,但也面臨著性能挑戰。AntSK-FileChunk通過多種優化策略解決了這些問題。
5.1 緩存機制
語義向量的計算是整個過程中最耗時的部分。為了避免重復計算,AntSK-FileChunk實現了緩存機制:
def?compute_embeddings(self,?texts:?List[str])?->?np.ndarray:#?使用緩存避免重復計算cached_embeddings?=?[]texts_to_compute?=?[]indices_map?=?[]for?i,?text?in?enumerate(texts):text_hash?=?hashlib.md5(text.encode()).hexdigest()if?text_hash?in?self.embedding_cache:cached_embeddings.append(self.embedding_cache[text_hash])indices_map.append((i,?len(cached_embeddings)?-?1,?True))else:texts_to_compute.append(text)indices_map.append((i,?len(texts_to_compute)?-?1,?False))#?只計算未緩存的文本if?texts_to_compute:new_embeddings?=?self.model.encode(texts_to_compute,?...)#?更新緩存for?i,?text?in?enumerate(texts_to_compute):text_hash?=?hashlib.md5(text.encode()).hexdigest()self.embedding_cache[text_hash]?=?new_embeddings[i]#?組合緩存和新計算的向量all_embeddings?=?np.zeros((len(texts),?self.embedding_dim))for?orig_idx,?cache_or_new_idx,?is_cached?in?indices_map:if?is_cached:all_embeddings[orig_idx]?=?cached_embeddings[cache_or_new_idx]else:all_embeddings[orig_idx]?=?new_embeddings[cache_or_new_idx]return?all_embeddings
這種緩存機制大大減少了重復計算,提高了系統的整體性能。
5.2 批處理優化
對于大型文檔,一次性處理所有段落可能會導致內存問題。AntSK-FileChunk采用了批處理策略:
def?compute_embeddings(self,?texts:?List[str])?->?np.ndarray:#?批量處理,避免內存溢出batch_size?=?32embeddings?=?[]for?i?in?range(0,?len(texts),?batch_size):batch_texts?=?texts[i:i+batch_size]batch_embeddings?=?self.model.encode(batch_texts,?...)embeddings.append(batch_embeddings)return?np.vstack(embeddings)
這種批處理策略不僅解決了內存問題,還提高了計算效率。
5.3 多線程處理
對于大型文檔,AntSK-FileChunk還支持多線程處理,進一步提高了處理速度:
def?process_large_document(self,?document_content):#?將文檔分割成多個部分parts?=?self._split_document(document_content)#?多線程處理各部分with?concurrent.futures.ThreadPoolExecutor()?as?executor:futures?=?[executor.submit(self._process_part,?part)?for?part?in?parts]results?=?[future.result()?for?future?in?futures]#?合并結果return?self._merge_results(results)
這種多線程處理策略使得系統能夠充分利用多核CPU,顯著提高了處理大型文檔的速度。
六、未來展望與發展方向
AntSK-FileChunk已經在語義切片領域取得了顯著成果,但仍有許多值得探索的方向。
6.1 多模態內容處理
目前的AntSK-FileChunk主要處理文本內容,未來可以擴展到多模態內容處理,包括:
-
圖像內容理解:識別圖片內容,將相關的圖片與文本關聯起來。
-
表格語義提取:深入理解表格的結構和內容,提取表格的語義信息。
-
代碼語義分析:針對代碼塊進行專門的語義分析,理解代碼的功能和結構。
6.2 領域適應性優化
不同領域的文檔有不同的特點和要求,未來可以針對特定領域進行優化:
-
醫療文檔:處理醫療術語、病歷格式等特殊內容。
-
金融報告:處理財務數據、圖表等特殊內容。
-
教育資料:優化對教材、習題等內容的處理。
6.3 交互式切片調整
目前的切片過程是全自動的,未來可以引入交互式調整機制:
-
可視化界面:直觀展示切片結果,便于用戶理解和調整。
-
反饋學習:根據用戶反饋調整切片策略,不斷優化切片效果。
-
自定義規則:允許用戶定義特定的切片規則,滿足特殊需求。
6.4 與大語言模型的深度集成
隨著大語言模型的發展,可以將AntSK-FileChunk與大語言模型進行更深度的集成:
-
語義理解增強:利用大語言模型的語義理解能力,提高切片的質量。
-
動態切片策略:根據文檔內容和查詢需求,動態調整切片策略。
-
多級切片:實現多級切片機制,滿足不同粒度的查詢需求。
七、總結與思考
AntSK-FileChunk通過語義理解的方式,徹底改變了我們處理文本切片的方式。它不僅解決了傳統切片方法的痛點,還為文本處理提供了新的可能性。
7.1 核心價值
-
語義完整性:確保每個切片在語義上的完整性和連貫性。
-
上下文保持:通過重疊機制和語義關聯,保持切片之間的上下文連續性。
-
格式智能處理:針對表格、圖片等特殊內容進行智能處理。
-
質量評估體系:提供多維度的切片質量評估,指導優化。
7.2 應用前景
語義切片技術在多個領域有廣闊的應用前景:
-
知識庫構建:為企業知識庫提供高質量的文檔切片。
-
RAG系統:為檢索增強生成系統提供更精準的檢索單元。
-
文檔智能分析:支持對長文檔的智能分析和理解。
-
內容推薦:基于語義相似度,實現更精準的內容推薦。
7.3 開發者建議
對于想要使用或貢獻AntSK-FileChunk的開發者,我有以下建議:
-
理解核心概念:深入理解語義切片的核心概念和算法。
-
定制化配置:根據具體需求調整切片配置,如語義閾值、切片大小等。
-
性能優化:針對大型文檔,考慮使用緩存和多線程處理。
-
擴展功能:根據特定領域需求,擴展特定的處理功能。
結語:從切片到理解
文本切片看似是一個簡單的技術問題,但實際上它反映了我們如何看待和處理信息的方式。從機械切分到語義理解,這不僅是技術的進步,更是思維方式的轉變。
AntSK-FileChunk讓我們看到了一種可能性:通過深入理解內容的語義,我們可以更好地組織和利用信息。這種方式不僅適用于文本切片,也適用于更廣泛的信息處理領域。
在信息爆炸的時代,我們需要的不僅是更多的信息,還有更好的信息組織方式。語義切片技術正是朝著這個方向邁出的重要一步。
互動環節
感謝您閱讀本文!我很想聽聽您的想法和經驗:
-
您在文本切片中遇到過哪些挑戰?傳統方法是如何解決的?
-
您認為語義切片技術還有哪些可以改進的地方?
-
您是否有使用AntSK-FileChunk的經驗?效果如何?
歡迎在評論區分享您的見解,也歡迎提出任何問題,我會盡力回答。如果您覺得這篇文章對您有幫助,別忘了點贊和收藏,讓更多人看到!
關注我,獲取更多AI技術深度解析!
更多AIGC文章








` 數據庫查詢函數)
![[系統架構設計師]通信系統架構設計理論與實踐(十七)](http://pic.xiahunao.cn/[系統架構設計師]通信系統架構設計理論與實踐(十七))

)


)
)



