目錄
一、需求分析
1. 搞清楚業務目標:這數據是要解決啥問題?
2. 明確數據邊界:哪些數據該要,哪些不該要?
3. 弄明白使用場景:誰用這數據,怎么用?
二、模型設計
1. 第一步:確定業務過程
2. 第二步:識別維度
3. 第三步:確定度量
4. 第四步:選擇模型類型(星型vs雪花)
三、實施落地
1. 數據分層:讓模型好維護
2. ETL設計:讓模型能跑起來
3. 存儲選型:讓模型跑得快
四、迭代優化
1. 什么時候該迭代了?
2. 迭代有啥策略?
結語
在數據團隊待久了,總會遇到兩種讓人頭疼的情況:
- 業務同事說“你們做的模型太繞,我要個銷售額數據都費勁”;
- 技術同事也嘆氣,“業務需求變得比翻書還快,模型剛弄好就得大改”。
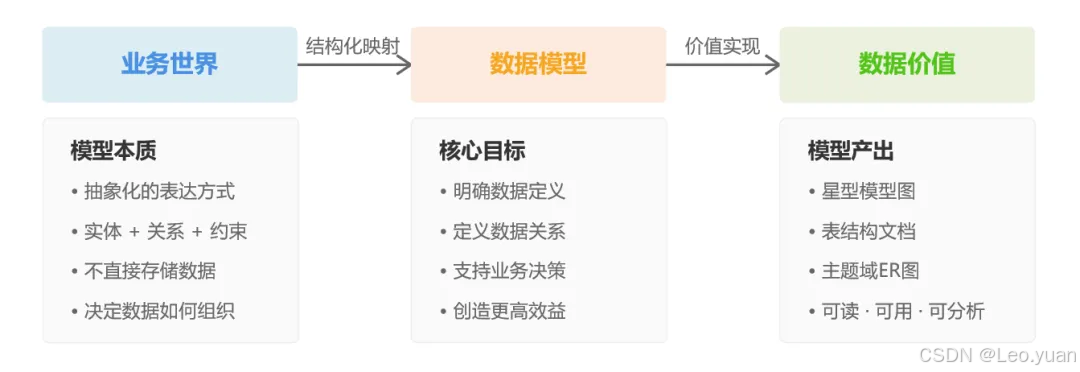
其實數據建模這事兒,就是把業務需求和技術實現連起來的那根線,看著基礎,卻藏著不少坑。它真不是畫幾張圖、寫幾行代碼那么簡單,得真懂業務邏輯,還得算著技術成本,甚至得提前想到以后可能會變的地方,是個實打實的系統活兒。
今天我就不跟你扯教科書上的理論了,就從實際應用的角度,把數據建模的全流程拆解開,重點說說這四個核心問題:
- 需求該怎么接
- 模型該怎么設計
- 落地時要避開哪些坑
- 后續怎么跟著迭代
開篇福利:先給大家分享一份《數據倉庫建設方案》資料包,可以幫助大家更全面、深入地理解數據建模,并將其巧妙運用到數據倉庫建設 “大工程” 之中。需要自取:數據倉庫建設解決方案 - 帆軟數字化資料中心(復制到瀏覽器打開)
一、需求分析
數據建模第一步,80%人都會踩坑——把需求分析做成了簡單記錄。
業務方說:“我要用戶復購率的周環比數據。”技術同學記下來,轉頭就從訂單表里取“下單時間”“用戶ID”“金額”,按周分組一算。
結果交上去的時候,業務方就問了:
“預售訂單怎么沒算進去?為啥用支付時間不是下單時間?怎么只算了APP端的數據?”
問題出在哪?
需求分析根本不是原樣轉述,而是得翻譯。業務方提需求的時候,往往帶著他們自己的業務語境,模糊不清是常有的事。
這時候,數據建模就得把需求拆成三個關鍵部分:

1. 搞清楚業務目標:這數據是要解決啥問題?
就拿復購率來說:
- 它到底是用來驗證“用戶生命周期價值(LTV)的短期情況”,
- 還是評估“促銷活動的效果”?
目標不一樣,模型里的字段設計、關聯的維度,那差別可就大了:
- 要是前者,就得把用戶的首單時間、以前的消費層級都關聯上;
- 要是后者,就得關聯活動標簽、優惠券使用情況。
2. 明確數據邊界:哪些數據該要,哪些不該要?
業務方說“用戶行為數據”,可能在他們看來,默認就包括APP、小程序、H5三端的點擊記錄,但技術這邊就得問清楚:
- PC端的算不算?
- 機器人的流量要不要過濾掉?
- 設備信息(比如是iOS還是Android)用不用關聯?
邊界要是沒劃清:
模型上線后,肯定就得陷入“補數據-改模型”的循環里,沒完沒了。
3. 弄明白使用場景:誰用這數據,怎么用?
同樣是“銷售額報表”:
- 給老板看的周報,得匯總到品牌、大區這個級別;
- 給運營看的日報,就得細到SKU、門店;
- 要是給算法做預測用,可能還得保留用戶分群標簽、時間序列特征。
說白了,使用場景決定了模型的細致程度和冗余情況——老板要的是整體情況,算法要的是細節特征,模型得跟這些場景匹配上才行。
所以跟業務方溝通需求的時候,拿著“5W1H”清單去問細節:
- Who(誰用)
- What(具體要啥指標)
- When(時間范圍是啥)
- Where(數據從哪兒來)
- Why(業務上要解決啥問題)
- How(輸出成啥樣)
二、模型設計
需求分析清楚了,就到模型設計這一步了。這一步的核心,就是用結構化的模型語言,把業務邏輯固定成能計算的資產。
數據建模的方法不少,像維度建模、實體關系建模、數據湖建模等等。但實際干活的時候,最常用的還是維度建模,特別是星型模型和雪花模型。
為啥呢?
因為它夠簡單——
- 業務的人能看明白,
- 技術團隊也好實現,
- 計算效率也有保障。
1. 第一步:確定業務過程
業務過程就是模型里的“核心事件”,比如:
- “用戶下單”
- “商品入庫”
- “優惠券核銷”
它必須是能量化、能追蹤的具體動作,不能是抽象的概念。比如說“用戶活躍”是一種狀態,它對應的業務過程應該是“用戶登錄”“用戶點擊”這些具體動作。

2. 第二步:識別維度
維度就是看業務過程的角度,用來回答“誰、何時、何地、什么條件”這些問題。比如分析“用戶下單”,可能涉及的維度有:
- 時間維度(下單時間、支付時間)
- 用戶維度(用戶ID、性別、注冊渠道、會員等級)
- 商品維度(商品ID、類目、品牌、價格帶)
- 場景維度(渠道:APP/小程序;活動:大促/日常;地域:省/市)
要注意的是:
維度得“全面準確”,但別“過度設計”。也就是說維度設計得基于當前的業務需求,同時留點兒擴展的空間。
3. 第三步:確定度量
度量是業務過程的“量化結果”,必須是數值型的、能聚合的字段,像訂單金額、商品銷量、支付轉化率這些都是。
這里有個容易被忽略的點:度量得明確“計算規則”。比如說:
- “銷售額”,是指“下單金額”還是“支付金額”?
- “復購率”是“30天內購買2次及以上”還是“最近一次購買距離首單不超過30天”?
規則不統一,模型輸出的指標就容易讓人產生誤解。
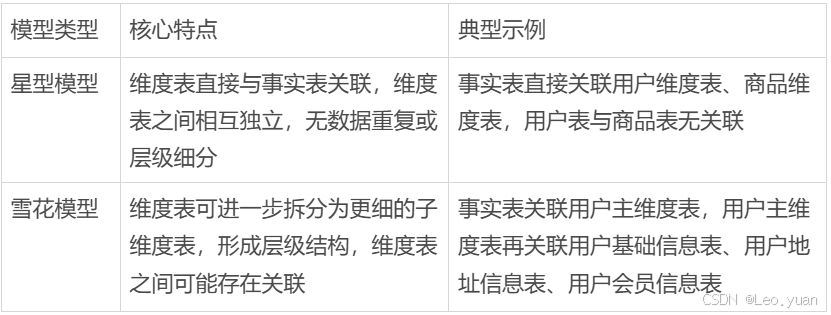
4. 第四步:選擇模型類型(星型vs雪花)
怎么選呢?
主要看查詢效率:
- 星型模型減少了JOIN操作,適合經常查詢的場景,比如BI報表;
- 雪花模型更規范,適合不常查詢但分析復雜的場景,比如數據科學家做深度的關聯分析。
用過來人的經驗告訴你,優先選星型模型。在大數據的場景下,JOIN操作特別費計算資源,星型模型能明顯提高查詢速度。
要是維度需要細分:
可以把常用的維度字段合并到事實表里,做成“寬表”來優化,別動不動就拆成雪花結構。
三、實施落地
模型設計好了,就該落地實施了。這一步難的不是寫代碼,而是在“模型夠不夠好”和“工程上能不能實現”之間找到平衡。
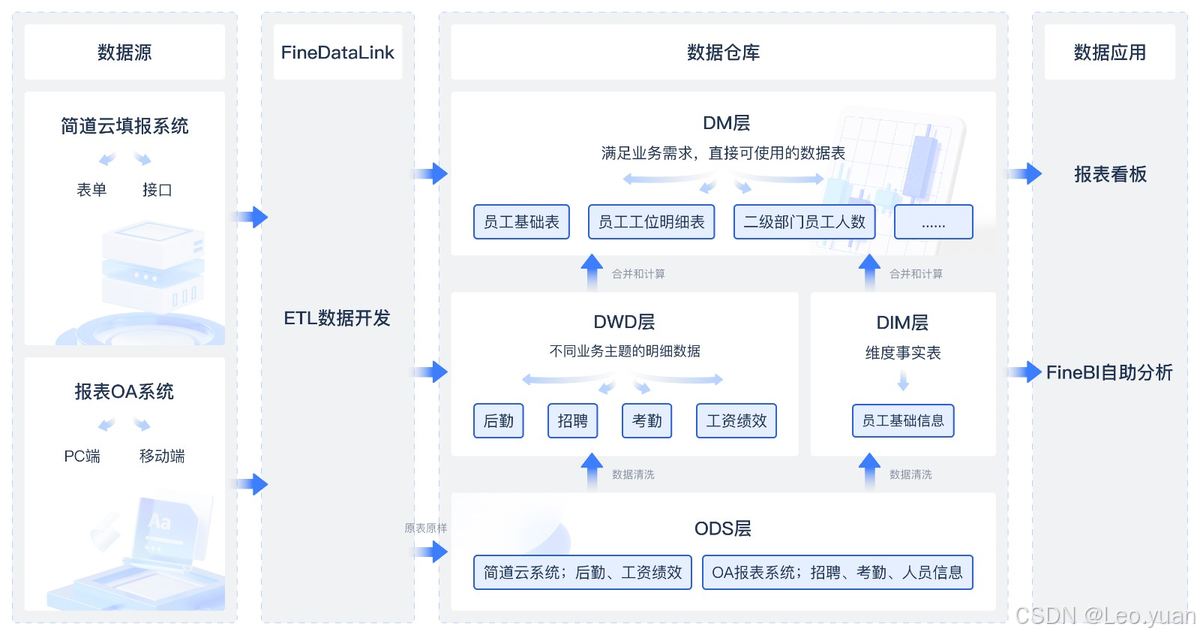
1. 數據分層:讓模型好維護
數據倉庫的分層設計(ODS→DWD→DWS→ADS)是實施階段的基礎。每一層的職責得明確:
- ODS(原始數據層):存著原始的日志和業務庫數據,一點都不修改,用來回溯和校驗;
- DWD(明細數據層):做清洗、去重、標準化的工作,比如統一時間格式、填補缺失的值;
- DWS(匯總數據層):按主題來聚合數據,比如用戶主題、商品主題的日活、周銷數據;
- ADS(應用數據層):直接對接業務需求,像BI報表、算法模型的輸入數據都從這兒來。
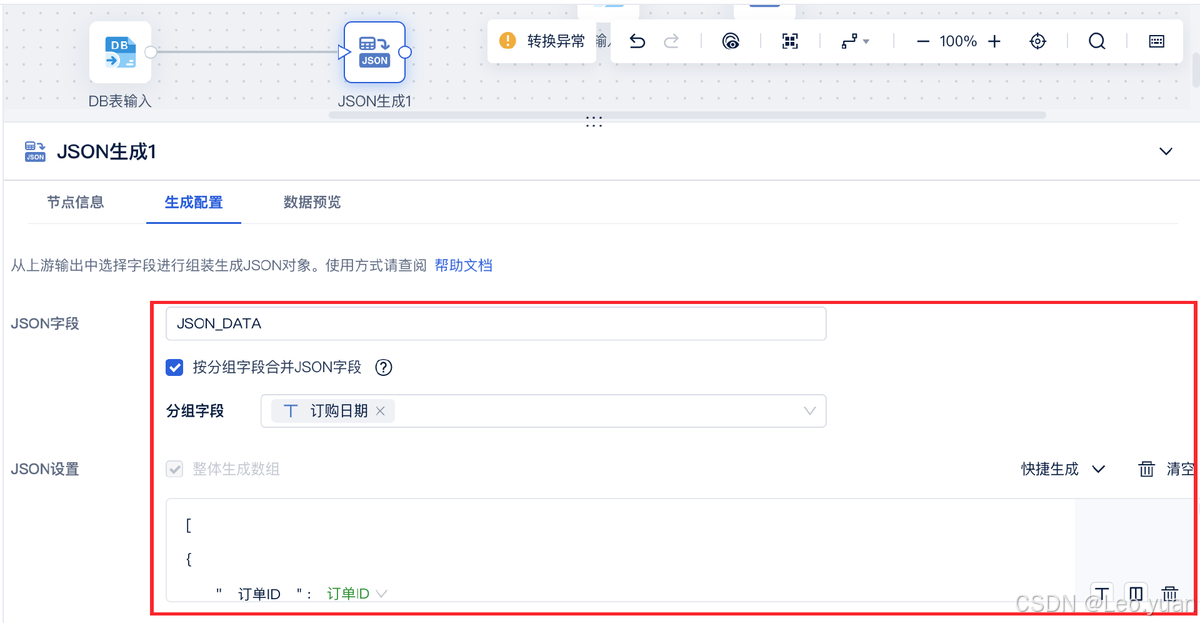
具體怎么做數據轉換?
使用 API 輸出,實現將 API 數據寫入指定接口,將數據庫或者其他形式的數據生成為 JSON 格式,以便進行數據交互。
可以借助數據集成與治理一體化平臺FineDataLink,使用 JSON 生成算子,生成 JSON 格式數據,滿足復雜業務場景下的數據清洗、轉換和同步等需求。FineDataLink體驗地址→免費激活FDL(復制到瀏覽器打開)
2. ETL設計:讓模型能跑起來
ETL(抽取-轉換-加載)是模型落地的關鍵。很多團隊在這一步容易出問題:
- 要么是ETL的任務鏈太長,依賴關系復雜,導致經常失敗;
- 要么是轉換邏輯寫死在代碼里,需求一變更,就得重新開發。
正確的打開方式是:
- 用元數據管理ETL流程:借助FineDataLink把任務依賴可視化,設置重試機制和告警;
- 把轉換邏輯“參數化”:像時間窗口(按天/周/月聚合)、維度過濾條件這些,用配置表來管理,別硬寫到代碼里;
- 保留“中間結果”:在ETL過程中輸出臨時表,比如清洗后的用戶明細表,方便排查問題和回溯。
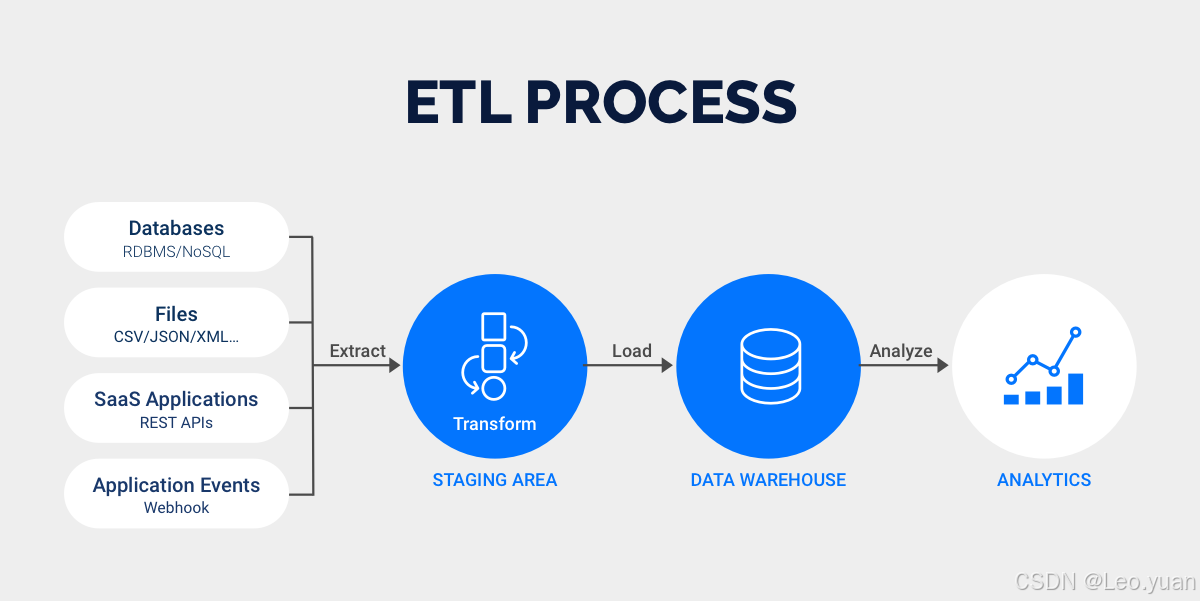
3. 存儲選型:讓模型跑得快
不同的模型場景,得用不同的存儲介質:
- 經常查詢的小數據集:用關系型數據庫(MySQL、PostgreSQL)或者OLAP引擎(ClickHouse);
- 大規模的明細數據:用分布式存儲(Hive、HBase)或者數據湖(Delta Lake、Iceberg);
- 有實時數據需求的:用流批一體存儲(Flink + Kafka)。
要注意的是:
別為了用新技術而選復雜的存儲方式。比如存用戶畫像,要是沒有強一致性的需求,用MySQL加Redis的組合,可能比用HBase更簡單高效。
四、迭代優化
數據模型上線了不算完,它的生命周期長著呢。隨著業務發展,模型得不斷迭代——這一點很多團隊都容易忽略,最后往往要付出額外的成本。
1. 什么時候該迭代了?
出現這些情況,就得考慮優化模型了:
- 性能下降:以前10秒能出結果的查詢,現在要1分鐘,可能是數據量太大了,也可能是索引失效了;
- 滿足不了新需求:業務方需要新的維度(比如“用戶社交關系”)或者新的度量(比如“分享率”);
- 存儲成本太高:模型冗余太多,比如雪花模型的多層維度表重復存儲數據,導致存儲費用飆升。
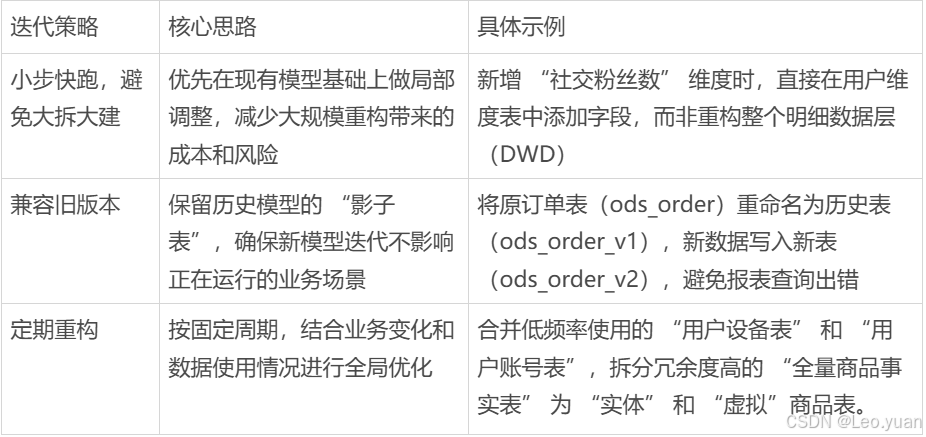
2. 迭代有啥策略?
迭代不能拍腦袋決定,得看數據反饋進行策略調整:
結語
數據建模是把業務價值和技術實現連起來的“結合點”,一個好的模型:
- 讓業務的人看得懂、用著順,
- 讓技術的人改起來方便、跑起來順暢。
還想跟你說句實在話:“先讓模型能用起來,再慢慢讓它變好。”別追求一開始就做出“完美模型”,在業務迭代中不斷優化,這才是數據建模最實在的經驗。

 核心概念、重要指令)
)
用戶畫像數據分析模型)

)





)
:實踐篇 - 從 `Dockerfile` 到 Pod 的權限深耕)






