2.1 數據介紹
有某公司的銷售數據表 sales.csv 如下:
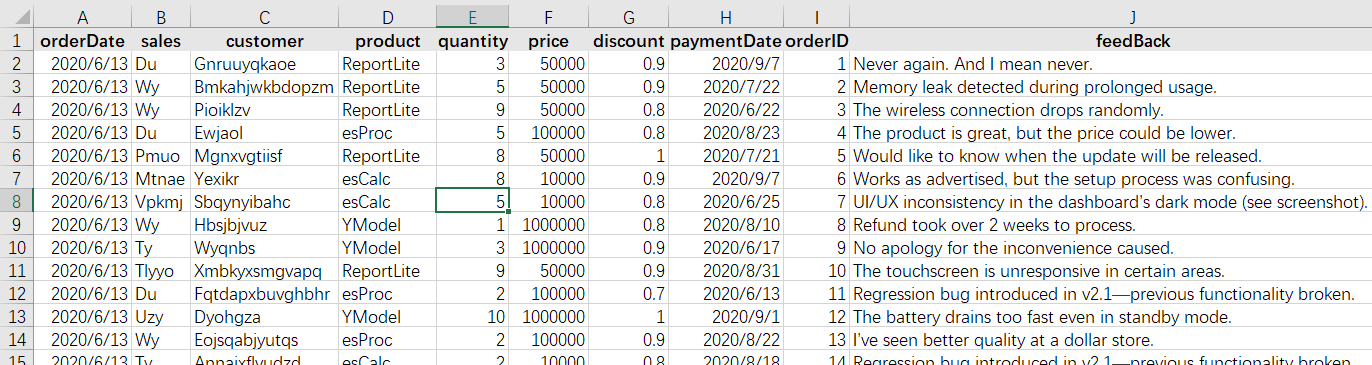
第一行是標題,解釋每一列存了什么東西。第二行開始每一行是一條數據,對應一個訂單。
這種數據有個專業的術語,叫結構化數據。這是現代數據處理中最常見的數據類型。
整個表格的數據統稱為一個數據表,其中的每一行(除了標題)稱為一條記錄,列稱為字段,標題中的字符串稱為字段名。上面這個表中能看見的部分有 12 條記錄,對應著這個 Excel 的第 2 到第 13 行;有 8 個字段,字段名分別是 orderDate, sales, customer, product, quantity, price, discount, paymentDate。字段名互不相同,可以唯一地標識某個列。這些字段(包括名稱和次序),稱為數據表的數據結構,簡稱結構。
結構化數據也就是有數據結構的數據。
表格中 A2:H13 部分就是數據表里的數據了。我們會說某條記錄的某個字段的取值是什么。比如這里第 2 條記錄的 sales 字段取值為 Hef,第 8 條記錄的 quantity 字段取值為 8。數據表中每條記錄的每個字段都會有一個取值。
注意,數據表中只有字段有名稱,記錄沒有名稱。我們后面會講用什么辦法來標識和區分記錄。
可以有各種各樣的數據表,不同數據表的數據結構當然可以不同。一個數據表一定要有一套數據結構,而且也只能有一套。有時我們也會說到記錄的結構,意思就是指記錄所在的數據表的結構。
因為結構化數據經常會以這種行列式表格的形式呈現,我們也會直觀地把記錄和字段稱為行和列,這是數據庫界的通行術語,并不是我們發明的通俗說法。甚至,有時候數據表呈現出來時已經沒有明顯的行和列了(馬上要講到這樣的例子),但人們仍然會用行和列這些術語來表示記錄和字段。
本文檔用到的 sales.csv 文件中列名的含義如下:
| 列名 | 含義 |
|---|---|
| orderID | 訂單 ID,取值為自然數列,和記錄序號一致 |
| orderDate | 下單日期 |
| sales | 銷售 |
| customer | 客戶 |
| product | 產品 |
| quantity | 訂單數量 |
| price | 訂單價格 |
| discount | 訂單折扣 |
| paymentDate | 付款日期 |
| feedBack | 客戶反饋 |
2.2 選出去年的所有銷售記錄
第一步:讀取 sales.csv 文件中的數據
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
A1 函數file("sales.csv")表示從主目錄中找到 sales.csv 這個文件,并產生文件對象,這里參數是個字符串,要加雙引號。import@tc()表示讀入文件對象 file(“sales.csv”) 中的數據,這里@t是函數 import 的選項,表示文件的第一行是標題行,如果沒有這個選項,會把第一行當成數據讀入。@c表示文件中數據的列間分隔符是英文逗號,如果沒有這個選項,會默認當成 tab 分隔符。當兩個選項 @t 和 @c 同時寫時,可以省略一個 @, 寫成@tc。
在界面中可以看到 A1 的值:
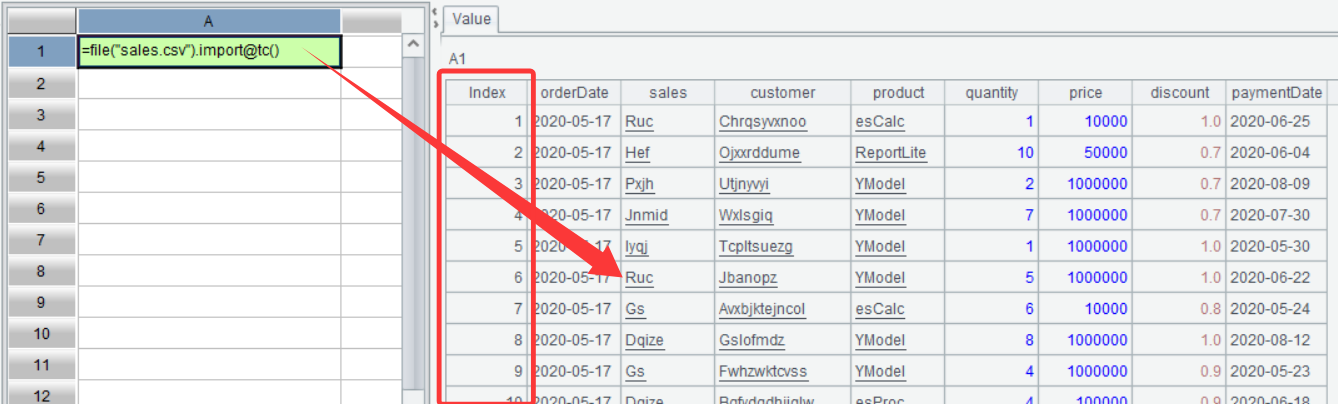
從圖中可以看出 A1 的值是一個二維表。前面介紹過,sales.csv 文件中存儲的是結構化數據,SPL 中用于裝載結構化數據的對象稱為序表,從名稱上可以理解為有次序的二維表。上圖中 A1 的值就是一個序表,從圖上看,序表比原始的結構化數據多了一個 Index,這就是序表的記錄次序,也稱為記錄序號,可以通過序號來訪問序表中的某一條記錄,比如 =A1(3),將返回 A1 中的第三條記錄:

第二步:從 A1 中選出 2024 年下單的數據:
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc() |
| 2 | =A1.select(year(orderDate)==2024) |
A2 select 函數表示過濾,這里的過濾條件year(orderDate)==2024表示選出 orderDate 的年份等于 2024 的數據。在 SPL 中相等比較用==,而=表示賦值。year函數表示獲得日期參數的年份。
界面上可以再看一下 A2 的值:
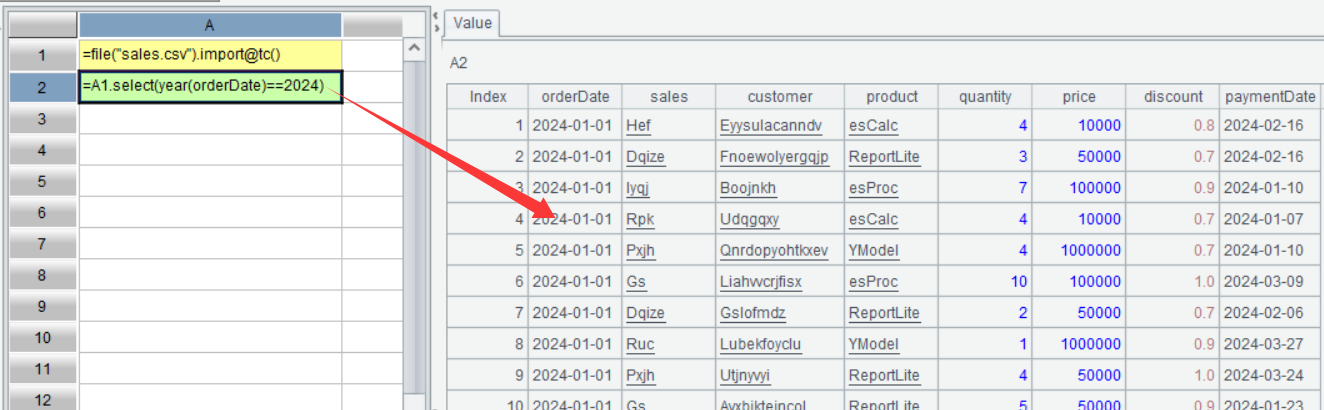
從界面上看,A2 是 2024 年的銷售記錄,表面上看和 A1 的序表似乎長得差不多,但它不是序表,它只是從 A1 序表中取出的部分記錄組成的一個有序集合,在 SPL 中有個專門的名稱叫排列。
2.3 計算去年的總銷售額、單筆最大訂單額、訂單個數
第一步:讀取 sales.csv 文件中的數據
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(orderDate,quantity,price,discount) |
A1 由于本例中只用到了orderDate,quantity,price,discount這幾個字段,所以可以在 import 函數參數中指定這幾個字段,這樣讀數時只讀這幾個字段,可以提高讀數效率,減少內存占用。
第二步:過濾出 2024 年的數據,并算出訂單金額,以計算列的形式添加到原排列中
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024).derive(quantity*price*discount:amount) |
A2 derive 函數表示添加計算列,其中quantity*price*discount是計算表達式,amount是新產生的計算列的列名,表達式和列名之間用冒號分隔。特別強調的是表達式在前面,列名在后面。
第三步:聚合運算
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.sum(amount) |
| 4 | =A2.max(amount) |
| 5 | =A2.count() |
A3 對 A2 中的 amount 字段求和。
A4 對 A2 中的 amount 字段求最大值。
A5 對 A2 計數,算出 A2 的記錄數。
2.4 選出金額最大的三個訂單
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc() |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.sort(-amount) |
| 4 | =A3.to(3) |
A3 sort 函數是排序,缺省是從小到大排,想從大到小排,相當于其相反數從小到大排,所以這里加了個負號,寫成-amount。
A4 A3.to(3)表示選出 A3 中的前三條記錄。熟練之后可以把 A3 和 A4 寫到一起:A2.sort(-amount).to(3)。
A4 的結果為:

可以看出,這種算法雖然簡單,但是沒有解決排名并列的問題,對于可能存在并列的數據,SPL 還有個 top 函數可以處理:
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc() |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.top@r(3;-amount) |
A3 A2.top@r(3;-amount)表示將A2排序后取前 3 條記錄。缺省排序規則和sort函數一致,但是top函數有個@r選項可以解決并列的情況。特別需要強調的是,3和-amount之間是分號分隔,這時候返回的是排名前三的記錄。如果寫成逗號分隔,則返回排名前三的amount字段值。和 Excel 及其它程序語言不同,SPL 的參數分隔符不只是逗號,還可能有分號和冒號(在前面 derive 函數中就出現過冒號,用來分隔計算式和字段名)。
A3 的結果為:
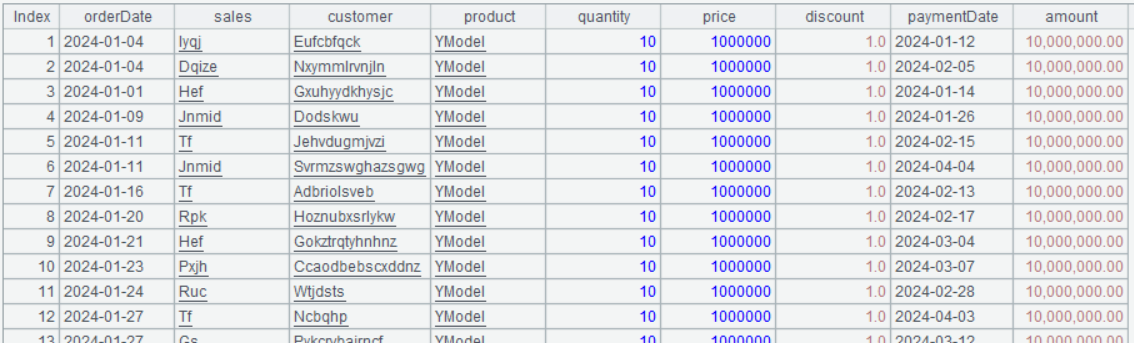
top 函數解決了排名并列的問題。
2.5 第一筆付款的訂單、最后一筆付款的訂單
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc() |
| 2 | =A1.select(year(orderDate)==2024) |
| 3 | =A2.minp(paymentDate) |
| 4 | =A2.maxp(paymentDate) |
A3 A2.minp(ParmentDate)表示從排列 A2 中選出paymentDate的值最小的記錄,這里用于選出第一筆付款的訂單,它有點相當于 top(1,…)。由于本例中日期數據只精確到日,同一天可能存在多單付款,如果要把同一天付款的所有訂單都選出,可以給 minp 函數加上@a選項,如:A2.minp@a(paymentDate)。
A4 選出最后一筆付款的訂單,maxp 函數規則和 minp 一致,這里不再贅述。
2.6 統計 2025 年 5 月 1 日以后下單的客戶數和付款的客戶數(去重)
| A | B | |
|---|---|---|
| 1 | =file(“sales.csv”).import@tc() | 2025-05-01 |
| 2 | =A1.select(orderDate>B1) | |
| 3 | =A2.icount(customer) | |
| 4 | =A2.select(paymentDate).icount(customer) | |
A3 A2.icount(customer)表示對A2逐行獲得customer的值,并對結果進行去重計數。
A4 A2.select(paymentDate)表示選出paymentDate不為空的記錄,即已付款記錄






SQL引擎-SQL執行流程)


——PCL庫點云特征之NARF特征描述 Normal Aligned Radial Feature(NARF))
事件驅動框架)








