目錄
初識Elasticsearch
什么是elasticsearch
正向索引和倒排索引
與mysql進行對比
安裝elasticsearch、kibana
安裝分詞器IK
IK分詞器的拓展和停用詞典
ik分詞器-拓展詞庫
ik分詞器-停用詞庫
索引庫操作
mapping映射屬性
索引庫的CRUD
查看、刪除索引庫
文檔操作
新增文檔
查詢文檔
刪除文檔
?修改文檔
RestClient操作索引庫
創建索引庫
1.導入數據
2.編寫mapping映射
3.初始化JavaRestClient
4.創建索引庫
刪除索引庫
判斷索引庫是否存在
RestClient操作文檔
新增文檔
查詢文檔
更新文檔
方式一:
方式二:
刪除文檔
批量導入文檔
DSL查詢文檔
DSL查詢分類
全文檢索查詢
精準查詢
地理坐標查詢
組合查詢(復合查詢)
搜索結果處理
排序
分頁
高亮
RestClient查詢文檔
快速入門
match查詢
精確查詢
復合查詢
排序、分頁、高亮
實例常用
初識Elasticsearch
什么是elasticsearch
elasticsearch是一款非常強大的開源搜索引擎,可以幫助我們從海量數據中快速找到需要的內容。
elasticsearch結合kibana、Logstash、Beats,也就是ELK。被廣泛應用在日志數據分析、實時監控等領域。
elasticsearch的發展
Lucene是一個Java語言的搜索引擎類庫,是Apache公司的頂級項目,由DougCutting于1999年研發。
Lucene的優勢:
易擴展
高性能(基于倒排索引)
Lucene的缺點:
只限于Java語言開發
學習曲線陡峭
不支持水平擴展
elasticsearch就是基于Lucene的開發,優勢:
支持分布式,可水平擴展
提供Restful接口,可被任何語言調用
正向索引和倒排索引
elasticsearch采用倒排索引:
文檔:每條數據就是一個文檔
詞條:文檔按照語義分成的詞語
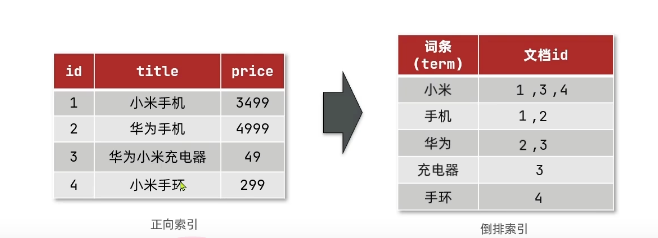
正向索引:基于文檔id創建索引。查詢詞條時必須先找到文檔,而后判斷是否包含詞條
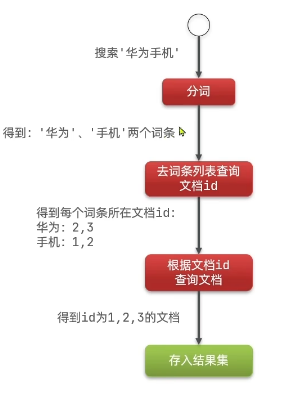
倒排索引:對文檔內容分詞,對詞條創建索引,并記錄詞條所在文檔的信息。查詢時先根據詞條查詢到文檔id,而后獲取到文檔
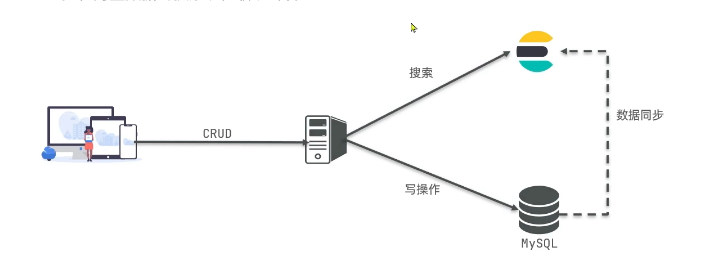
與mysql進行對比
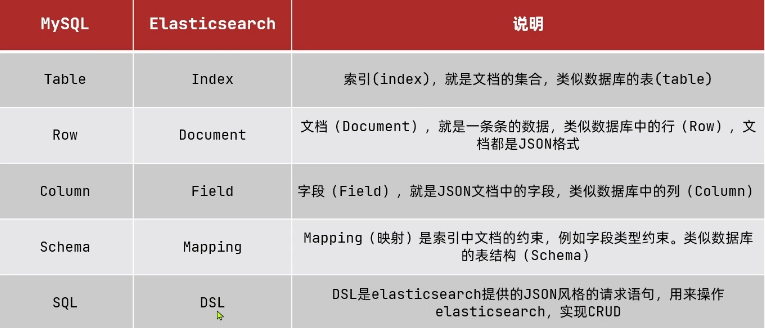
文檔
elasticsearch是面向文檔存儲的,可以是數據庫中的一條商品數據,一個訂單信息。
文檔數據會被序列化為json格式后存儲在elasticsearch中。
索引
索引:相同類型的文檔的集合
映射:索引中文檔的字段約束信息,類似表的結構約束
架構??
MySQL:擅長事務類型操作,可以確保數據的安全和一致性
Elasticsearch:擅長海量數據的搜索、分析、計算
安裝elasticsearch、kibana
建議以下連接
Elasticsearch集群和Kibana部署流程_kibana部署教程-CSDN博客
安裝分詞器IK
分詞器的作用是什么?
創建倒排索引時對文檔分詞
用戶搜索時,對輸入的內容分詞 ?
IK分詞器有幾種模式? ?
ik_smart:智能切分,粗粒度 ?
ik_max_word:最細切分,細粒度
es在創建倒排索引時需要對文檔分詞;在搜索時,需要對用戶輸入內容分詞。但默認的分詞規則對中文處理并不友好。
處理中文分詞,一般回使用IK分詞器。infinilabs/analysis-ik: 🚌 The IK Analysis plugin integrates Lucene IK analyzer into Elasticsearch and OpenSearch, support customized dictionary.
下載完將壓縮包解壓到es的plugins目錄即可
IK分詞器的拓展和停用詞典
ik分詞器-拓展詞庫
要拓展ik分詞器的詞庫,只需要修改一個ik分詞器目錄中的config目錄中的 IkAnalyzer.cfg.xml文件:

ik分詞器-停用詞庫
要禁用某些敏感詞條,只需要修改一個il分詞器目錄中的config目錄中的IkAnalyzer.cfg.xml文件:

拓展和禁用詞文件都必須在當前配置文件所在的目錄
索引庫操作
mapping映射屬性
mapping是對索引庫中文檔的約束,常見的mapping屬性包括:
type:字段數據類型,常見的簡單類型有
? ? ?字符串:text(可分詞的文本)、keyword(精確值,例如:品牌、國家、IP地址)
? ? ?數值:long、integer、short、byte、double、float
? ? ?布爾:boolean
? ? ?日期:date
? ? ?對象:object
index:是否創建索引,默認為true
ananlyzer:使用哪種分詞器
properties:該字段的子字段
索引庫的CRUD
ES中通過Restful請求操作索引庫、文檔。請求內容用DSL語句來表示。
創建索引庫和mapping的DSL語法如下:
 ? ??
? ??
PUT /haha
{"mappings":{"properties":{"info":{"type":"text","analyzer":"ik_smart"},"email":{"type":"keyword","index":false},"name":{"type":"object","properties":{"firstName":{"type":"keyword"},"lastName":{"type":"keyword"}}}}}
}查看、刪除索引庫
查看索引庫語法:
GET /索引庫名
刪除索引庫的語法:
DELETE /索引庫名
修改索引庫
索引庫和mapping一旦創建無法修改,但是可以添加新的字段,語法如下:

文檔操作
新增文檔

查詢文檔
GET /索引庫名/_doc/文檔id
刪除文檔
DELETE??/索引庫名/_doc/文檔id
?修改文檔
方式一:全量刪除,會刪除舊文檔,添加新文檔

方式二:增量修改,修改指定字段

RestClient操作索引庫
RestClient是ES官方提供了各種不同語言的客戶端,用來操作ES。這些客戶端的本質就是組裝DSL語句,通過http請求發送給ES。官方文檔地址:Elasticsearch clients | Elastic Docs
創建索引庫
mapping要考慮的問題:
字段名、數據類型、是否參與搜索、是否分詞、如果分詞、分詞器是什么
1.導入數據
2.編寫mapping映射
id一般在ES中用keyword來表示


3.初始化JavaRestClient
(1).引入es的RestHighLevelClient依賴:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version></dependency>
(2).配置版本
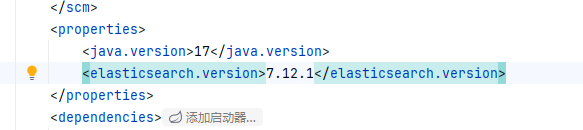
(3).初始化JavaRestClient
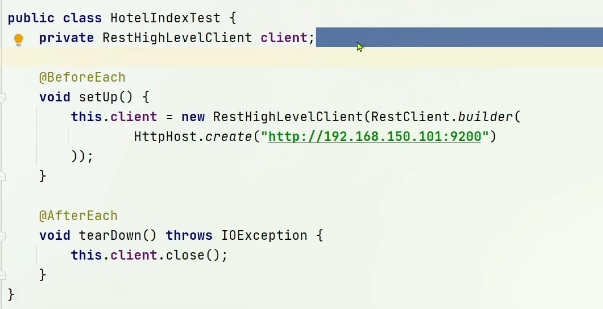
public class HotelIndex {private RestHighLevelClient client;@Testvoid testInit(){System.out.println(client);}@BeforeEachpublic void setUp() throws Exception {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://localhost:9200")));}@AfterEachpublic void tearDown() throws Exception {this.client.close();}}4.創建索引庫

@Testvoid createHotelIndex() throws IOException {CreateIndexRequest request = new CreateIndexRequest("hotel");request.source("""{"mappings": {"properties": {"name": {"type": "text"},"price": {"type": "long"},"location": {"type": "text"},"amenities": {"type": "keyword"}}}}""", XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);}刪除索引庫

@Testvoid deleteHotelIndex() throws IOException {client.indices().delete(new DeleteIndexRequest("hotel"), RequestOptions.DEFAULT);}
判斷索引庫是否存在

@Testvoid existsHotelIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("hotel");boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(exists);}RestClient操作文檔
文檔操作也同樣需要初始化RestHighLevelClient
新增文檔
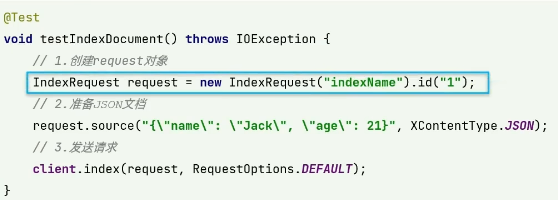
從數據庫中加載數據,并且轉換為JSON格式
查詢文檔
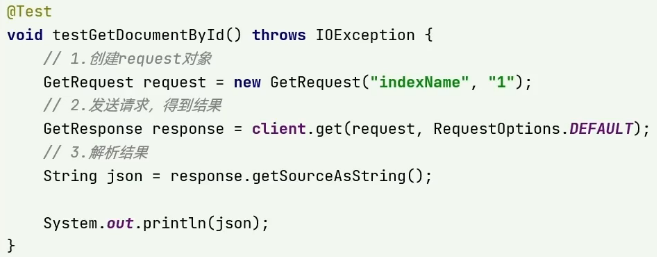
直接解析的結果為json格式,記得將json格式反序列化
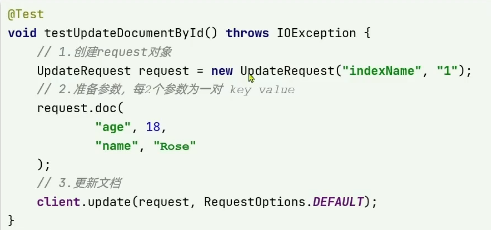
更新文檔
方式一:
全量更新。再次學日語id一樣的文檔,就會刪除舊文檔,添加新文檔
方式二:
局部更新。只更新部分字段
刪除文檔

批量導入文檔

DSL查詢文檔
DSL查詢分類
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)來定義查詢。常見的查詢類型包括:
1. 查詢所有:查詢出所有數據,一般測試用。例如:`match_all` ?

2. 全文檢索(full text)查詢**:利用分詞器對用戶輸入內容分詞,然后去倒排索引庫中匹配。例如: ?
? ?- `match_query` ?
? ?- `multi_match_query` ?
3. 精確查詢:根據精確詞條值查找數據,一般是查找keyword、數值、日期、boolean等類型字段。例如: ?
? ?- `ids` ?
? ?- `range` ?
? ?- `term` ?
4. 地理(geo)查詢:根據經緯度查詢。例如: ?
? ?- `geo_distance` ?
? ?- `geo_bounding_box` ?
5. 復合(compound)查詢:復合查詢可以將上述各種查詢條件組合起來,合并查詢條件。例如: ?
? ?- `bool` ?
? ?- `function_score`

全文檢索查詢
match查詢:全文檢索查詢的一種,會對用戶輸入內容分詞,然后去倒排索引庫檢索,語法:

multi_match:與match查詢類似,只不過允許同時查詢多個字段,語法:

精準查詢
精確查詢一般是查找keyword、數值、日期、boolean等類型字段。所以不會對搜索條件分詞。常見的有: ?
term:根據詞條精確值查詢

range:根據值的范圍查詢

地理坐標查詢
根據經緯度查詢。常見的使用場景包括:
攜程:搜索我附近的酒店
滴滴:搜索我附近的出租車
微信:搜索我附近的人
geo_bounding_box:查詢geo_point值落在某個矩形范圍的所以文檔
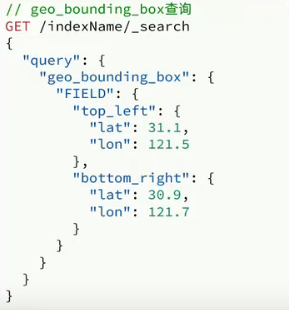
geo_distance:查詢到指定中心點小于某個距離值的所有文檔

組合查詢(復合查詢)
復合查詢:復合查詢可以將其它簡單查詢組合起來,實現更復雜的搜索邏輯,例如:
fuction score:算分函數查詢,可以控制文檔相關性算分,控制文檔排名。例如百度競價
相關性算分
當我們利用match查詢時,文檔結構會根據與搜索詞條的關聯度打分(_score),返回結構時按照分值降序排列。
![]()


-
TF-IDF:
-
在Elasticsearch 5.0之前使用。
-
隨著詞頻(Term Frequency)的增加,相關性分數會不斷增大。
-
-
BM25:
-
從Elasticsearch 5.0開始采用。
-
隨著詞頻的增加,相關性分數也會增大,但增長曲線會逐漸趨于平緩,避免過度偏向高頻詞
-
使用 fuction score query,可以修改文檔的相關性算分,根據新得到的算分排序。
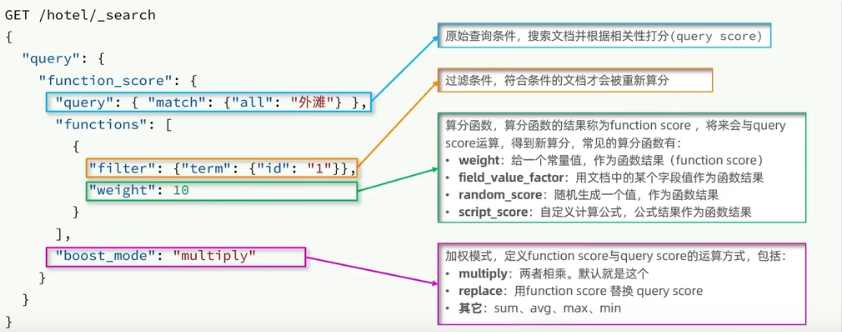
復合查詢 Boolean Query
布爾查詢是一個或多個查詢子句的組合。子查詢的組合方式有:
must:必須匹配每個子查詢,類似“與”
should:選擇性匹配子查詢,類似“或”
must_not:必須不匹配,不參與算分,類似“非”
filter:必須匹配,不參與算分

搜索結果處理
排序
Elasticsearch支持對搜索結果進行排序,默認情況下是根據相關度算分(_score)進行排序。支持的排序字段類型包括:keyword類型、數值類型、地理坐標類型、日期類型


獲取經緯度的方式:高德開放平臺 | 高德地圖API
分頁
elasticsearch默認情況下只返回top10的數據。而如果要查詢更多數據就需要修改分頁參數了。
elasticsearch中通過修改from、size參數來控制要返回的分頁結果:

該方法限制了查詢上限為10000條
深度分頁問題
ES是分布式的,所以會面臨深度分頁問題。例如按price排序后,獲取from=990,size=10的數據:

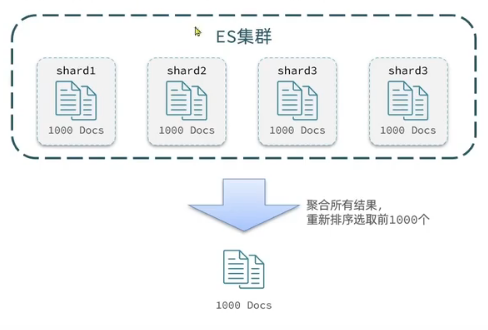
深度分頁解決方案:
-
Search After
-
原理:基于上一頁的排序值繼續查詢下一頁數據,要求分頁時必須指定排序規則。
-
特點:官方推薦的方式,適用于實時滾動查詢,避免性能問題。
-
-
Scroll
-
原理:將排序數據生成快照并保存在內存中,適合大批量數據遍歷。
-
特點:官方已不再推薦使用,因為會占用較多資源且數據可能不是最新的。
-
高亮
高亮:就是在搜索結果中把搜索關鍵字突出顯示。
原理:
將搜索結果中的關鍵字用標簽標記出來
在頁面中給標簽添加css樣式

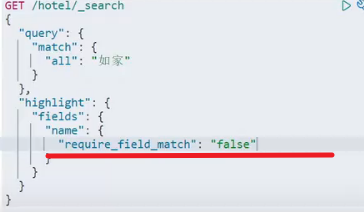
默認情況下,ES搜索字段必須與高亮字段一致
增加字段匹配即可
RestClient查詢文檔
快速入門
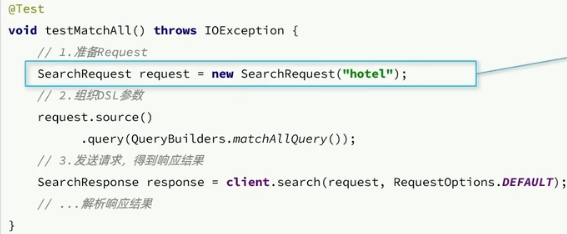
1.創建SearchRequest對象
2.準備Request.source(),也就是DSL
3.發送請求,得到結果
4.解析結果

match查詢

精確查詢

復合查詢

排序、分頁、高亮
排序和分頁

高亮
高亮API包括請求DSL構建和結果解析兩部分。
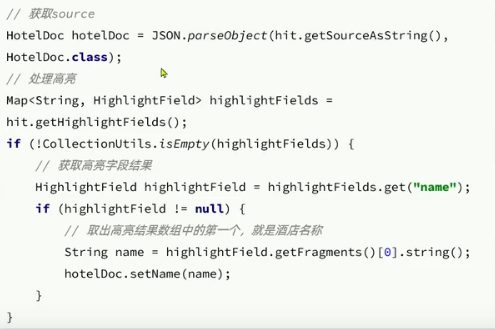
DSL構建

高亮的結果處理
實例常用
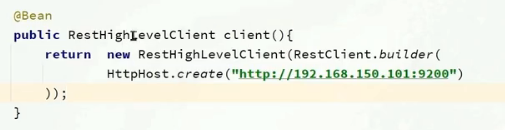
將Client注入到Bean對象中
距離排序

讓指定內容在搜索結果中排名置頂
我們給需要置頂的文檔添加一個標記。然后利用function score給帶有標記的文檔增加權重




)












:使用開發者工具創建天氣預報項目)



