今天,我們來具體介紹Transformer的架構設計。
一個完整的Transformer模型就像一個高效的語言處理工廠,主要由兩大車間組成:編碼車間和解碼車間。
首先來看這幅“世界名畫”,你可以在介紹Transformer的場景中常常看到這幅圖,這就是《Attention Is All You Need》論文中所畫的Transformer架構,左邊就是我們說的編碼車間,右邊是解碼車間。
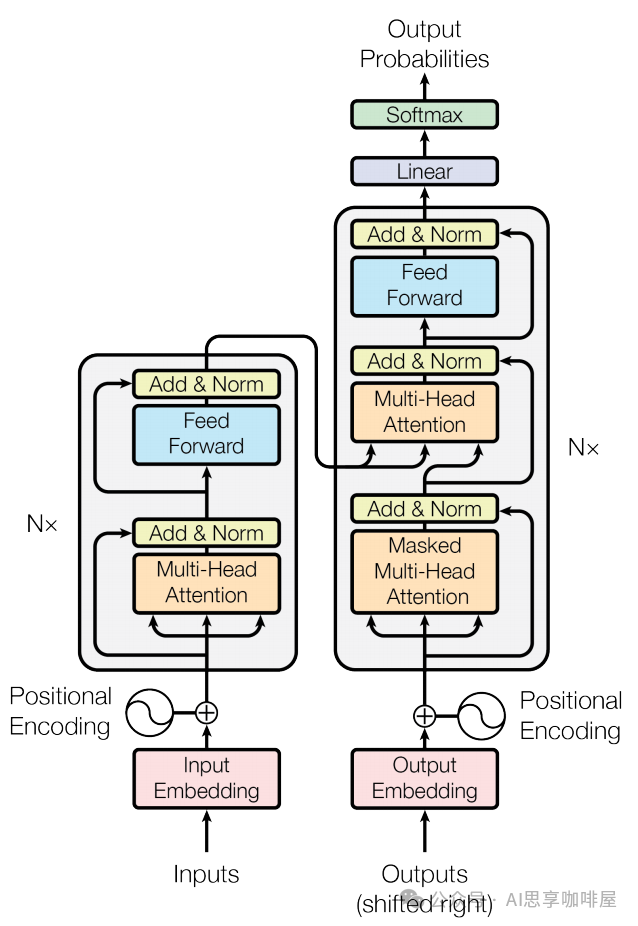
編碼器(Encoder)車間:
任務是深度閱讀理解輸入信息(比如一句中文)。
1.將輸入轉成數字信息(即粉色框中的嵌入):將輸入序列的每個token映射為高維向量。
2.再進行位置編碼(即圖中左側的Positional Encoding),前文中提到過,通過正弦余弦函數來增加詞向量的位置信息,彌補Transformer不考慮詞序先后的缺陷。
3.編碼團隊(即灰色框):由N個(即圖中左側的N*)結構一致的“編碼工人團隊”(Encoder Layer)串聯組成。

團隊的工作流程:
3-1自注意力小組(即橙色框中的多頭注意力):運用自注意力機制(前一篇中提到過,Transformer的最大創新),讓當前句子里的所有詞瘋狂交流、互相理解,形成富含上下文關系的詞表達。
3-2前饋神經網絡小組(即藍色框中的FFN):對每個詞進行更深層次、更復雜的特征提取和變換(可以想象成給每個詞的“升級版自我表達”再做一次深度加工和升華)。
3-3殘差連接與層歸一化(即黃色框中的Add & Norm):前面兩個小組每次工作完,還要通過“傳送帶”(殘差連接)快速傳遞,避免信息丟失;同時有“質檢員”(層歸一化)確保信息穩定、易處理,傳給下一個人。
N個團隊層層加工,讓輸入句子的理解越來越深刻、精準。
解碼器(Decoder)車間:
任務是根據編碼車間的深刻理解,生成輸出(比如對應的英文翻譯)。
1.輸出嵌入(粉色框)和2.位置編碼(右側的PE)同編碼車間。
3.解碼團隊(灰色框):同樣由N個結構相似的“解碼工人團隊”(Decoder Layer)串聯組成。
團隊的特殊技能:
3-1掩碼自注意力小組(下方橙色框中的掩碼多頭注意力):處理已生成的部分輸出(比如已經翻譯出來的前幾個英文詞)。這里的“掩碼”(Mask)很關鍵,它讓每個詞在交流時只能看到它前面的詞(已經生成的),看不到后面的(還沒生成的),確保生成過程是順序的、合理的(不能提前知道答案),即這是個自回歸過程。
這里初學者不太容易理解,我們前面介紹過自注意力的特點,就是可以全局同時并行處理,不用按序逐個循環處理,為什么這里的掩碼注意力是自回歸的,只能看到前面的詞,不能看到后面的內容呢?
這里的誤解是源于,這個世界名畫是介紹模型訓練,就是模型自己來找到這么多的參數的過程。注意!這里并不是你已訓練好了模型,輸入prompt,讓模型給出回答。
在訓練模型的過程中,我們是知道輸入的這句中文對應的英文翻譯的答案的,我們就是用這些信息去訓練模型。在生成任務的過程中,模型是需要逐步預測序列的下一個token的,如果不進行掩碼,由于自注意力機制是全局的,模型就能提前看到未來生成的信息,直接知道生成的答案,其實就是訓練時在作弊,會破壞自回歸生成邏輯,預測結果將偏離正式概率分布,所以這就是為什么需要掩碼。
在數學處理上,其實很簡單,就是只保留注意力中的下三角區域,即當前位置及其之前的注意力權重,還是用上一篇中的“我愛吃蘋果”舉例,掩碼注意力如下圖。

3-2編碼-解碼注意力小組(中間橙色框中的多頭注意力,起到關鍵橋梁作用):這是Decoder的巧妙設計,這里的工人會專門去“凝視”編碼器車間最終輸出的那個深刻理解(代表整個輸入中文句子的精華信息)。他們讓正在生成的每個英文詞,都能有選擇地、動態地聚焦于輸入中文句子中最相關的部分。用我們翻譯的例子來說明,我在翻譯某個中文對應的英文時,我同時要關注這個中文的信息,這樣翻譯的結果會更加“信達雅”。
3-3前饋神經網絡小組(藍色框):同樣進行深度特征處理。
3-4傳送帶與質檢(黃色框):同樣保證信息流穩定高效。
4.最終,解碼器車間的輸出經過一個簡單的“包裝處理”(紫色框中的線性層)和“概率轉換”(綠色框中的Softmax層),就能預測出下一個最可能的詞是什么了。一個個詞生成,就得到了最終的翻譯結果。
前面為了方便理解,我們用了工廠流水線的例子來進行比喻,讀到這里,大家已經有個大致的了解,那我們再簡單總結一下編碼器和解碼器。
編碼器(Encoder)就是將輸入序列(例如一句中文)轉換成一個富含上下文信息的、固定大小的表示序列,每個輸入元素對應一個輸出向量,每個向量都包含了整個輸入序列的上下文信息。
解碼器(Decoder)就是利用編碼器提供的上下文信息,逐步生成輸出序列(例如目標語言的翻譯)。
助理deepseek進行了下述比較總結:
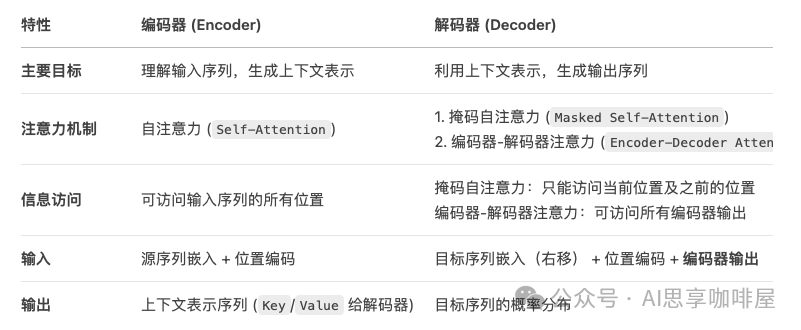
這里再額外說明一下,2017年發表的《Attention Is All You Need》論文中所述的Transformer是一個包含編碼器和解碼器的完整架構,但在后續訓練產生的生成式大模型中,并非都是采用這樣完整的編碼器解碼器模型,還有僅解碼器模型、僅編碼器模型、編碼器-解碼器模型。
僅解碼器模型,就像內容創作者,擅長寫出引人入勝且信息豐富的內容,但不擅長理解主題和學習目標。僅解碼器模型的例子有GPT系列模型,如GPT-3。
僅編碼器模型,就像審核者,擅長理解語言之間的關系和上下文,但不擅長生成內容。僅編碼器模型的例子有BERT。
如果既能創作又能審核測驗,這就是編碼器-解碼器模型。如BART和T5。
特意提出上述不同模型種類,是希望大家不要拘泥于對Transformer 架構的靜態理解(不要死記硬背地學),實際應用中,模型設計需根據任務動態調整,Transformer 的編碼器-解碼器結構是通用框架,但并非所有任務都需要完整使用。例如GPT 系列繼承了 Transformer 的自注意力機制,但通過架構簡化(僅解碼器)和訓練策略優化(如 RLHF),實現了生成能力的突破。
最后
選擇AI大模型就是選擇未來!最近兩年,大家都可以看到AI的發展有多快,我國超10億參數的大模型,在短短一年之內,已經超過了100個,現在還在不斷的發掘中,時代在瞬息萬變,我們又為何不給自己多一個選擇,多一個出路,多一個可能呢?
與其在傳統行業里停滯不前,不如嘗試一下新興行業,而AI大模型恰恰是這兩年的大風口,整體AI領域2025年預計缺口1000萬人,人才需求急為緊迫!
由于文章篇幅有限,在這里我就不一一向大家展示了,學習AI大模型是一項系統工程,需要時間和持續的努力。但隨著技術的發展和在線資源的豐富,零基礎的小白也有很好的機會逐步學習和掌握。
【2025最新】AI大模型全套學習籽料(可白嫖):LLM面試題+AI大模型學習路線+大模型PDF書籍+640套AI大模型報告等等,從入門到進階再到精通,超全面存下吧!
獲取方式:有需要的小伙伴,可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】
包括:AI大模型學習路線、LLM面試寶典、0基礎教學視頻、大模型PDF書籍/筆記、大模型實戰案例合集、AI產品經理合集等等
大模型學習之路,道阻且長,但只要你堅持下去,一定會有收獲。本學習路線圖為你提供了學習大模型的全面指南,從入門到進階,涵蓋理論到應用。
L1階段:啟航篇|大語言模型的基礎認知與核心原理
L2階段:攻堅篇|高頻場景:RAG認知與項目實踐
L3階段:躍迀篇|Agent智能體架構設計
L4階段:精進篇|模型微調與私有化部署
L5階段:專題篇|特訓集:A2A與MCP綜合應用 追蹤行業熱點(全新升級板塊)





AI大模型全套學習資料【獲取方式】





)




之 文本向量化——仙盟創夢IDE)


)


——接口與事務代碼的編寫)


