自建文章向量化技術:AI 浪潮下初學者的進階指南
在人工智能(AI)蓬勃發展的浪潮中,向量化作為將文本數據轉化為數值向量表示的關鍵技術,成為理解和處理文本的基石。本文將結合給定的代碼示例,深入探討自建文章向量化的技術原理、應用場景、實際作用,以及初學者在 AI 浪潮中學習向量化的有效路徑。
一、自建文章向量化的技術原理剖析
給定代碼基于詞袋模型(Bag of Words)實現文章向量化。詞袋模型假設文本中單詞的順序無關緊要,只關注單詞的出現頻率。
- 詞匯表管理:代碼中定義了?
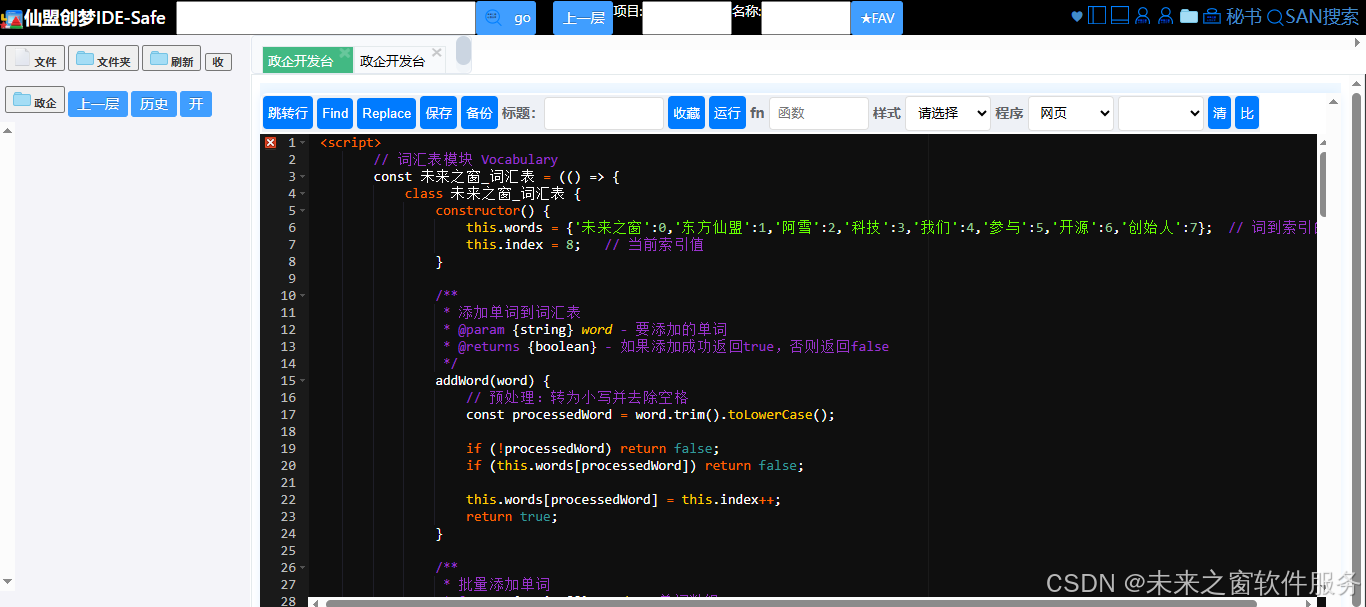
未來之窗_詞匯表?類,用于管理詞匯及其索引。它維護一個從單詞到索引的映射,以及當前的索引值。通過?addWord?方法添加單詞,getWordIndex?方法獲取單詞索引,getSize?方法獲取詞匯表大小等。這為向量化提供了基礎的詞匯索引體系。 - 文本預處理:
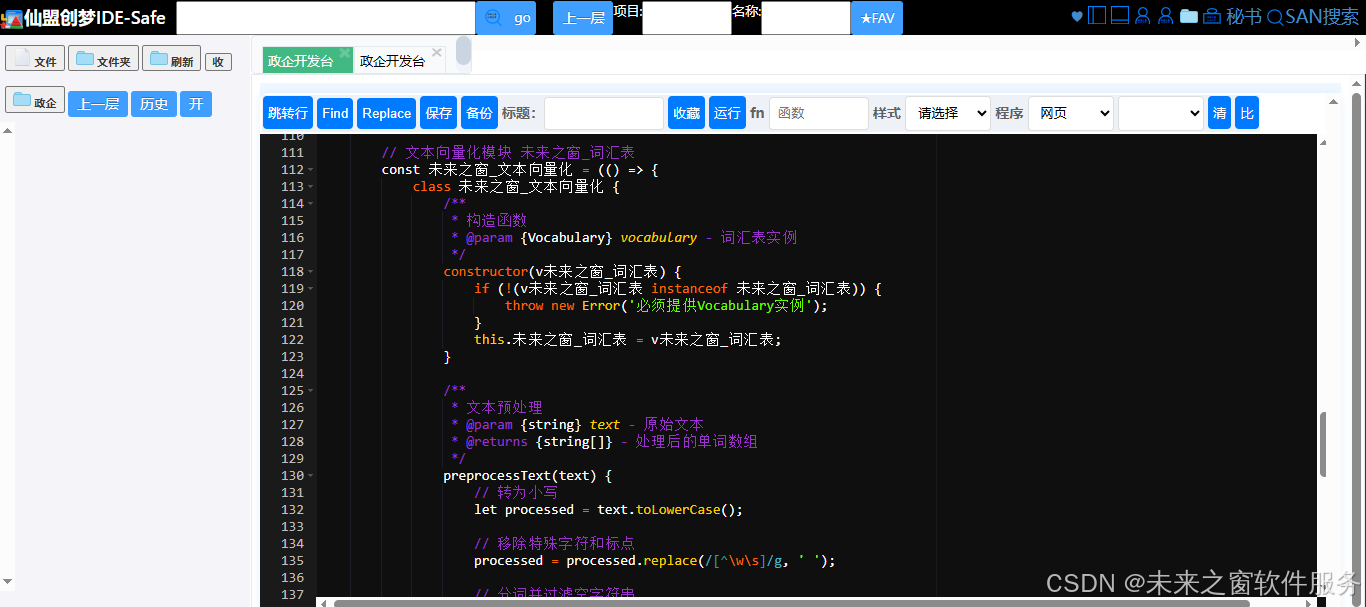
未來之窗_文本向量化?類中的?preprocessText?方法對輸入文本進行處理,先將文本轉換為小寫,然后移除特殊字符和標點,最后通過空格分詞并過濾掉空字符串,得到處理后的單詞數組。這一步確保文本數據的格式統一,便于后續的向量化操作。 - 向量生成:
vectorize?方法基于處理后的單詞數組和詞匯表生成向量。它先根據詞匯表的大小初始化一個全零向量,然后遍歷單詞數組,對于每個單詞,獲取其在詞匯表中的索引,并將對應索引位置的向量值加 1,以此表示該單詞在文本中的出現頻率。
二、自建向量化的應用場景
- 文本分類:在文本分類任務中,如新聞分類、情感分析等,通過將文本向量化,可將文本數據轉化為適合機器學習算法處理的數值形式。例如,判斷一段關于產品的評論是正面還是負面,可將評論向量化后輸入分類模型進行預測。代碼中的向量化工具能為這類任務提供基礎的數據轉換支持。
- 信息檢索:在搜索引擎或文檔檢索系統中,向量化可將文檔和用戶查詢轉化為向量形式,通過計算向量之間的相似度,找到與查詢最相關的文檔。比如在一個技術文檔庫中,用戶輸入關鍵詞查詢相關文檔,自建向量化工具可幫助快速定位匹配的文檔。
- 推薦系統:對于文本形式的推薦內容,如文章推薦、書籍推薦等,向量化能夠將用戶的歷史閱讀記錄和待推薦的內容都轉化為向量,基于向量相似度為用戶推薦感興趣的文本內容。
三、自建向量化的重要作用
- 數據標準化:將非結構化的文本數據轉化為結構化的向量數據,使不同文本之間具有統一的表示形式,便于機器學習算法進行處理和比較。這有助于提高算法的準確性和效率。
- 挖掘文本潛在特征:通過向量化,能夠將文本中隱藏的語義信息以數值形式展現出來,即使是看似無關的文本,也能通過向量計算發現其潛在的相似性或關聯性。這為深入理解文本內容提供了有力工具。
- 支持個性化應用:在信息檢索和推薦系統中,向量化使得系統能夠根據用戶的特定需求和偏好,提供個性化的服務。例如,根據用戶的瀏覽歷史向量化結果,為其推薦符合興趣的文章或產品。
四、初學者在 AI 浪潮中學習向量化的路徑
- 理論學習:首先要掌握向量化的基本概念和常用模型,如詞袋模型、TF - IDF(詞頻 - 逆文檔頻率)、Word2Vec 等。了解這些模型的原理、優缺點及適用場景,為實際應用打下堅實的理論基礎。可以通過在線課程、教材、學術論文等多種資源進行學習。
- 實踐操作:像給定代碼示例一樣,動手實現簡單的向量化工具。從基礎的詞袋模型開始,逐步嘗試不同的文本預處理方法和向量生成策略。可以利用 Python 等編程語言,結合相關的庫如 NLTK(自然語言工具包)、Scikit - learn 等進行實踐。在實踐過程中,深入理解每個步驟的作用和效果,不斷優化代碼。
- 項目應用:嘗試將向量化技術應用到實際項目中,如小型的文本分類項目、簡單的信息檢索系統等。通過實際項目,進一步鞏固所學知識,同時也能了解向量化在不同場景下的應用技巧和面臨的挑戰。可以參與開源項目,借鑒他人的經驗,與其他開發者交流學習。
- 持續關注與學習:AI 領域發展迅速,新的向量化技術和方法不斷涌現。初學者要保持對前沿技術的關注,及時學習和掌握新的知識和工具。關注學術會議、技術博客、專業論壇等,與行業保持同步發展。
自建文章向量化技術在 AI 浪潮中具有重要的地位和廣泛的應用前景。對于初學者而言,通過系統的理論學習、大量的實踐操作以及持續的關注與學習,能夠逐步掌握這一關鍵技術,在 AI 領域邁出堅實的步伐。
系統設計
-
模塊化設計:
Vocabulary?模塊:負責詞匯表的管理,包括添加詞匯、獲取索引、導入導出等TextVectorizer?模塊:負責文本預處理和向量化轉換
-
向量化原理:
-
使用詞袋模型 (Bag of Words) 將文本轉換為向量,向量的每個維度對應詞匯表中的一個詞,值為該詞在文本中出現的次數。
-
主要功能:
- 文本輸入與向量化轉換
- 手動添加自定義詞匯
- 詞匯表管理(清空、查看)
- 詞匯表的 JSON 導入導出
- 實時顯示向量結果和詞匯索引
-
使用方法:
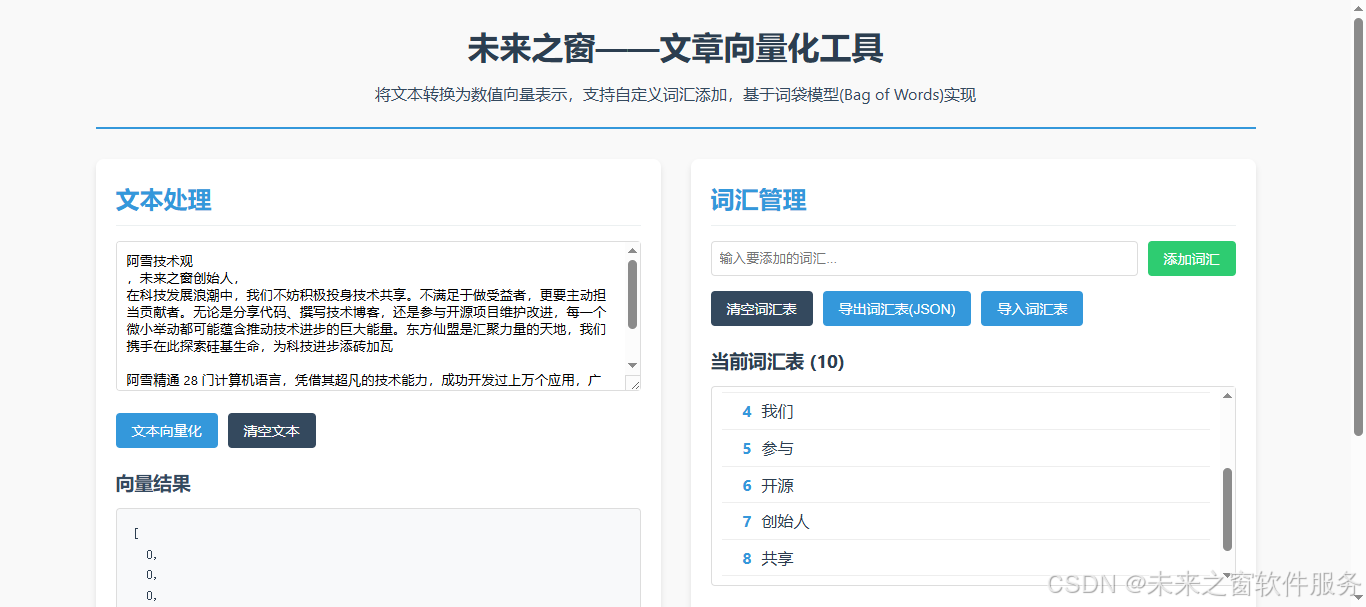
- 在左側文本框輸入要向量化的文本,點擊 "文本向量化"
- 在右側可以添加自定義詞匯,這些詞匯會被納入向量計算
- 向量結果會顯示在左側下方,每個數字代表對應詞匯在文本中出現的次數
- 可以導出詞匯表以便下次使用,也可以導入之前保存的詞匯表
?完整開源地址
https://gitee.com/cybersnow/wlzcImmortal-Alliance-commonly-used-source-code
代碼
<script>// 詞匯表模塊 Vocabularyconst 未來之窗_詞匯表 = (() => {class 未來之窗_詞匯表 {constructor() {this.words = {'未來之窗':0,'東方仙盟':1,'阿雪':2,'科技':3,'我們':4,'參與':5,'開源':6,'創始人':7}; // 詞到索引的映射this.index = 8; // 當前索引值}/*** 添加單詞到詞匯表* @param {string} word - 要添加的單詞* @returns {boolean} - 如果添加成功返回true,否則返回false*/addWord(word) {// 預處理:轉為小寫并去除空格const processedWord = word.trim().toLowerCase();if (!processedWord) return false;if (this.words[processedWord]) return false;this.words[processedWord] = this.index++;return true;}/*** 批量添加單詞* @param {string[]} words - 單詞數組*/addWords(words) {words.forEach(word => this.addWord(word));}/*** 獲取單詞的索引* @param {string} word - 單詞* @returns {number|null} - 索引值或null*/getWordIndex(word) {const processedWord = word.trim().toLowerCase();return this.words[processedWord] !== undefined ? this.words[processedWord] : null;}/*** 獲取詞匯表大小* @returns {number} - 詞匯表大小*/getSize() {return this.index;}/*** 清空詞匯表*/clear() {this.words = {};this.index = 0;}/*** 導出詞匯表為JSON* @returns {string} - JSON字符串*/exportToJSON() {return JSON.stringify({words: this.words,index: this.index}, null, 2);}/*** 從JSON導入詞匯表* @param {string} jsonStr - JSON字符串* @returns {boolean} - 導入成功返回true*/importFromJSON(jsonStr) {try {const data = JSON.parse(jsonStr);if (typeof data.words === 'object' && typeof data.index === 'number') {this.words = data.words;this.index = data.index;return true;}return false;} catch (e) {console.error('導入詞匯表失敗:', e);return false;}}/*** 獲取所有單詞* @returns {string[]} - 單詞數組*/getAllWords() {return Object.keys(this.words);}/*** 獲取單詞及其索引的映射* @returns {Object} - 單詞-索引映射對象*/getWordMap() {return { ...this.words };}}return 未來之窗_詞匯表;})();// 文本向量化模塊 未來之窗_詞匯表 const 未來之窗_文本向量化 = (() => {class 未來之窗_文本向量化 {/*** 構造函數* @param {Vocabulary} vocabulary - 詞匯表實例*/constructor(v未來之窗_詞匯表) {if (!(v未來之窗_詞匯表 instanceof 未來之窗_詞匯表)) {throw new Error('必須提供Vocabulary實例');}this.未來之窗_詞匯表 = v未來之窗_詞匯表;}/*** 文本預處理* @param {string} text - 原始文本* @returns {string[]} - 處理后的單詞數組*/preprocessText(text) {// 轉為小寫let processed = text.toLowerCase();// 移除特殊字符和標點processed = processed.replace(/[^\w\s]/g, ' ');// 分詞并過濾空字符串return processed.split(/\s+/).filter(word => word.length > 0);}/*** 將文本轉換為向量* @param {string} text - 輸入文本* @param {boolean} [updateVocab=true] - 是否更新詞匯表* @returns {number[]} - 文本向量*/vectorize(text, updateVocab = true) {const words = this.preprocessText(text);// 如果需要,更新詞匯表if (updateVocab) {this.未來之窗_詞匯表.addWords(words);}// 初始化向量const vector = new Array(this.未來之窗_詞匯表.getSize()).fill(0);// 計算詞頻words.forEach(word => {const index = this.未來之窗_詞匯表.getWordIndex(word);if (index !== null) {vector[index]++;}});return vector;}/*** 獲取詞匯表* @returns {Vocabulary} - 詞匯表實例*/getVocabulary() {return this.未來之窗_詞匯表;}}return 未來之窗_文本向量化;})();阿雪技術觀
在科技發展浪潮中,我們不妨積極投身技術共享。不滿足于做受益者,更要主動擔當貢獻者。無論是分享代碼、撰寫技術博客,還是參與開源項目維護改進,每一個微小舉動都可能蘊含推動技術進步的巨大能量。東方仙盟是匯聚力量的天地,我們攜手在此探索硅基生命,為科技進步添磚加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets, hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology. ?


)


——接口與事務代碼的編寫)







)

)!)



