閑來沒事,找點近一年的論文看看
1. DiC: Rethinking Conv3x3 Designs in Diffusion Models
? 一句話總結:DiC用沙漏架構+稀疏跳躍+條件門控重構純Conv3x3擴散模型,在速度碾壓Transformer的同時性能反超,為實時生成任務開辟新路徑。
背景
擴散模型現狀:
- 主流架構從CNN-注意力混合(如U-Net)轉向純Transformer(如DiT、U-ViT),生成質量優異但推理速度慢(自注意力計算開銷大)。
- 加速嘗試(如高效注意力、SSM架構)效果有限,難以滿足實時需求。
卷積的潛力:
- Conv3x3是硬件友好的極速操作(支持Winograd加速),但傳統設計在擴散模型中性能不足(感受野有限,擴展性差)。
可以看出,這篇論文就是要重新設計CNN的合適結構去解決Diffusion推理慢的問題。
核心問題
如何設計純Conv3x3架構,使其在擴散模型中同時實現:
? 高生成質量(對標Transformer)
? 極快推理速度
? 強可擴展性(模型增大時性能持續提升)
Motivation
- 卷積的硬件效率遠超自注意力,但現有純Conv3x3擴散模型性能落后。
- 需系統性改進架構與條件機制,釋放Conv3x3在生成任務中的潛力。
架構設計
(1)作者死磕conv3x3
選擇3x3卷積作為基礎操作單元,是因為它速度極快,硬件(GPU)和算法(如Winograd)對其進行了極好的優化,計算量遠低于其他卷積類型(如深度可分離卷積),并行度高且內存訪問開銷小,簡單說就是“性價比”最高的基礎模塊;我們的目標正是僅用這個最簡單的積木塊來搭建高性能模型。在設計中,我們借鑒了老牌擴散模型(如DDPM的U-Net)中的卷積塊結構,但進行了關鍵簡化:直接移除自注意力模塊,只保留純卷積操作。具體而言,每個基本塊由GroupNorm、SiLU激活、3x3卷積、GroupNorm、SiLU激活和3x3卷積順序組成,并采用殘差連接(輸入直接加到輸出上)且通道數保持不變,這構成了純卷積擴散模型的起點,既保持了結構的簡潔高效,又確保了高吞吐量和硬件友好性。
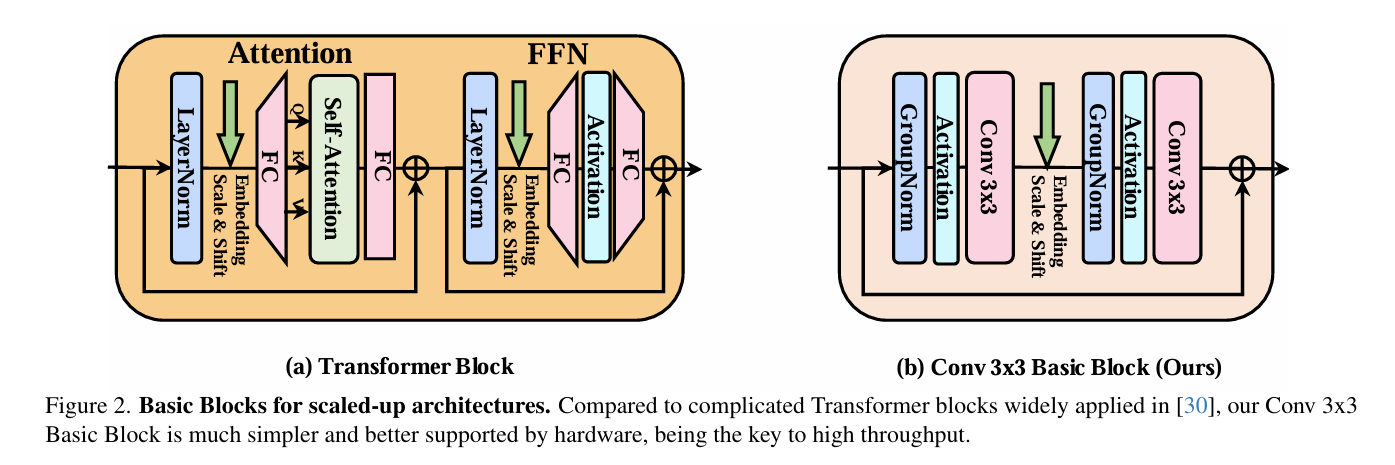
(2)模型結構
現在基礎Block設計好了,那么整體的網絡應該怎么處理呢?
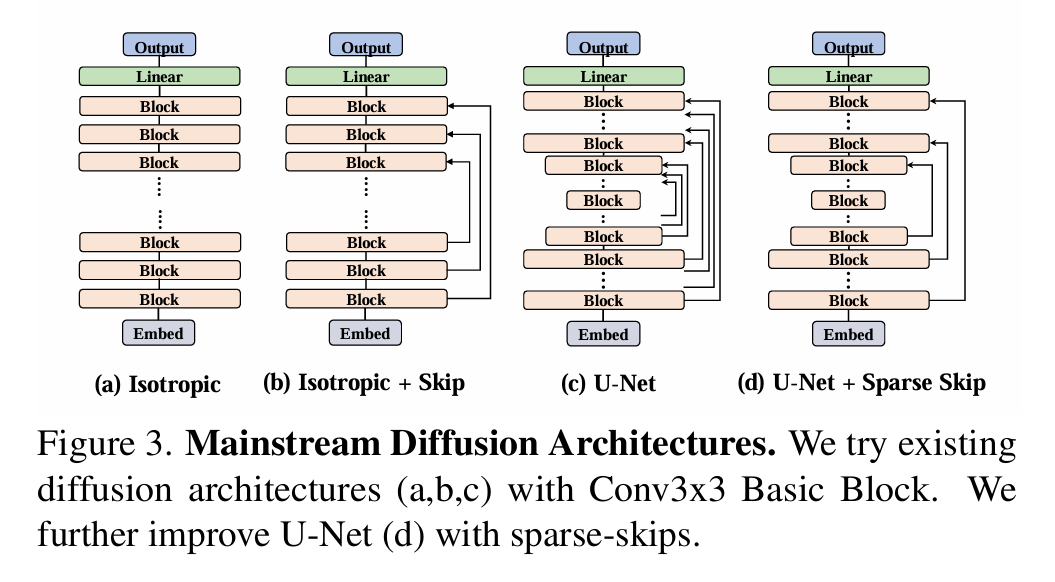
作者探討了幾種網絡結構。
(a) 直筒型 (Isotropic): 像 DiT/Transformer 那樣,從頭到尾特征圖大小不變(不上下采樣),就是一層層堆疊基本塊。結果:最差。 因為 Conv3x3 感受野太小,堆很深才能看到全局,效率低效果差。
(b) 帶跳躍的直筒型 (Isotropic + Skip): 還是特征圖大小不變,但在堆疊的塊之間加長距離跳躍連接(像 U-ViT)。結果:比純直筒好點,但還不夠。
(c)沙漏型/U-Net (U-Net Hourglass): 經典編碼器-解碼器結構。編碼器一路下采樣(縮小圖,增大感受野),解碼器一路上采樣(放大圖),中間還有密集的跳躍連接(把編碼器信息直接傳給解碼器對應層)。結果:明顯最好!
但作者發現,當模型變大變深時,傳統 U-Net 這種每層都跳的密集跳躍太“奢侈”了,解碼器要處理太多跳過來的信息,又費算力又占內存,很多跳躍其實沒多大用,反而拖累模型變大。于是作者想了個新招:稀疏跳躍連接。意思就是別每層都跳,改成隔幾層跳一次(比如只跳第一層到第一層、第四層到第四層,中間的二三層不跳)。這樣好處很大:跳的連接少了,計算和內存開銷大減;去掉沒用的跳躍,信息傳遞更高效;
(3) 剩下的一些小改進
- 個性化條件嵌入 (針對沙漏式網絡有效)
老模型(如DDPM)采用單一條件嵌入表(即“一個詞表通吃”)為整個U-Net結構提供提示語,但這忽略了U-Net的層級特性:編碼器早期層處理高分辨率細節特征(如邊緣和紋理),而解碼器后期層處理低分辨率整體特征(如物體形狀和場景),二者任務迥異,如同讓小學生和大學生共用同一本教材,必然導致效果打折;為此,DiC引入分階段專屬詞表(Stage-Specific Embeddings)的改進方案,即為U-Net中每個分辨率相同階段(一組基本塊)配置獨立的條件嵌入表,使編碼器底層能獲取適配細節理解的提示、解碼器高層能獲取適配整體把握的提示,從而顯著提升性能(FID指標從11.49降至10.07),而代價僅增加少量參數(14M,占模型總量2%)和計算量(12M FLOPs),相對于整體收益幾乎可忽略不計,性價比極高。
- 在哪里設置條件輸入?(借助DiT的成功經驗)
有兩種選擇:(1)在模型第一個conv3x3的前面輸入(2)在模型第二個conv3x3的前面輸入
作者發現在第二個前面會好一點點 (就是圖哪里scale and shift的地方)
那么選好了輸入的地方,該怎么輸入呢?
- 為增強條件響應的靈活性,DiC直接借鑒了Diffusion Transformer (DiT) 中的AdaLN機制,引入條件門控(Conditional Gating),其核心不僅對特征圖進行常規的縮放(scale)和平移(shift),還額外學習一個通道維度的門控向量,如同為每個特征通道配置可動態調節的“小開關”,實現更精細的特征調控,使模型能自適應不同條件(如圖像類別),進一步將FID降至6.54;盡管該設計非原創,但因其高效易集成且收益顯著,成為提升模型性能的關鍵補充。
- 采用GELU而不是SiLU (借助ConvNeXt的成功經驗)
作為一項次要但有效的優化,DiC 模型將原先廣泛用于 CNN 的 SiLU(Swish)激活函數統一替換為 Transformer 領域標配的 GELU;這一改動直接借鑒了 ConvNeXt 的成功經驗(該工作通過引入 Transformer 風格組件顯著提升了 CNN 性能),在 DiC 的純卷積結構中驗證有效——盡管提升幅度有限,卻能穩定優化生成質量(FID 指標從 6.54 降至 6.26);作者雖知存在更新的激活函數候選,但為兼顧實現簡單性與訓練穩定性,最終選擇了經過大規模實踐驗證的 GELU,以最小代價換取可靠收益。
2. DropKey
最近在小紅書刷到一個特別有意思的帖子,為什么自己寫的多頭自注意力機制不夠torch自帶的MultiheadAttention好呢?
貼主給出了需要注意的點:
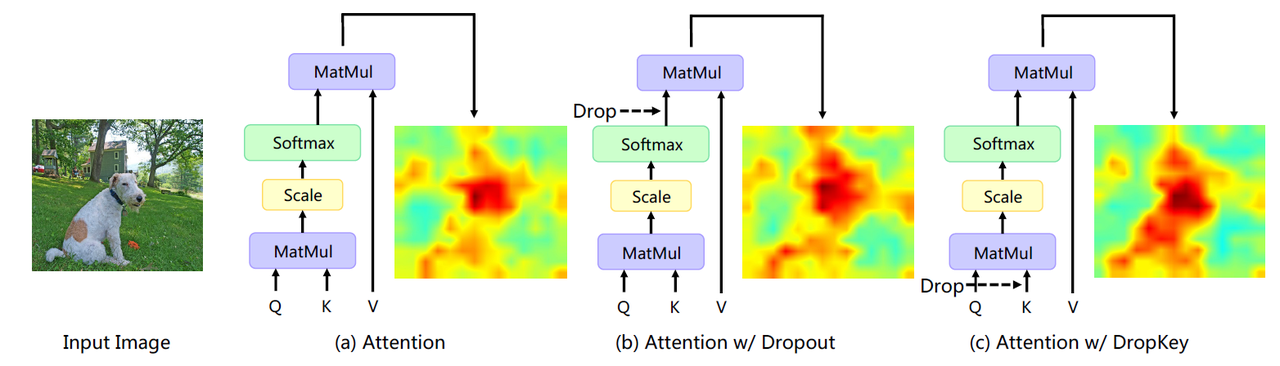
- 多頭注意力的Dropout并不是drop掉輸出,而是drop掉attn_weight
這個Trick是cvpr2023 DropKey這篇論文提出的,講了ViT通過Drop掉權重(也就是drop掉Key,為什么不叫DropWeight,我不懂)而不是softmax之后的值。
具體的實現是很簡單的幾行代碼:

我看了一下torch實現的代碼,現在的drop確實是drop掉weight,而不是softmax之后的值。
這篇論文還講了蒙特卡洛算法來bridge因為drop導致的train和test之間的代溝,我看一下這部分的內容,額外學習一下。
同時作者還論證了隨著層數的增加,dropout的概率應該降低,這讓模型學習得更好:
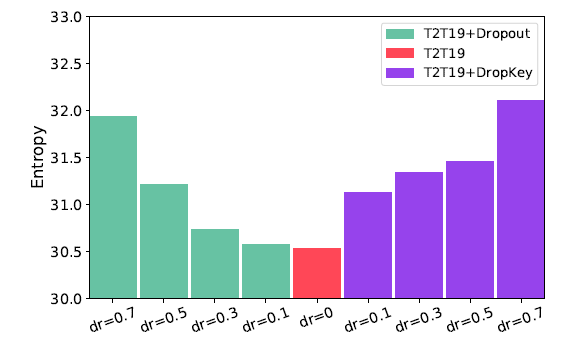
小的熵值表示模型更聚焦于sparse patches,由于class token對于聚合整張圖的信息有幫助,這里計算它的熵作為模型提取全局信息能力的度量。從這個圖可以看出,當Dropout變小的時候,模型提取全局信息能力更強,因此后續的層dropout應該小一些。
- 這里實驗的具體實現應該就是:計算 cls-token 和其他image patch token的attention weight,因為weight是0-1的一個概率,我們可以把它輸入進去這個熵的公式,然后得到這個token的熵,最后所有token的熵求一個平均。如果是多頭注意力,那么就每個頭再求一次平均。
- 低熵值:意味著向量中只有少數幾個權重值很大,其他都很小。這表示該注意力頭高度聚焦在少數幾個關鍵的圖像塊上(sparse patches)。
- 高熵值:意味著向量中所有權重值都比較平均。這表示該注意力頭將注意力平滑地分散在更多的圖像塊上,關注的是更全局的特征。
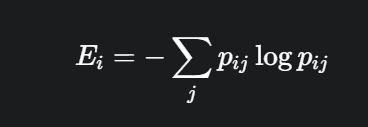
但是作者頁論證了dropkey的一些不足:
- 未對齊的期望 [推理階段沒有 Dropout] 會對模型產生一定的負面影響,因此作者使用兩種方法來對齊期望。
- 第一種,用蒙特卡羅法估算,通過執行多次隨機下降,并在每次下降操作后計算注意力權重矩陣。 最后,將計算出的多重權重矩陣的平均值用作下一步的輸入。
- 第二個,在沒有 DropKey 的情況下微調模型,作為 DropKey 訓練后的額外階段。作者通過實驗驗證第二種策略的性能更好。







)
)










)