續接上回《PostgreSQL 系國產數據庫%SYS CPU newfstatat() high 調優一例(一)》,這個問題還在持續,并且原因并不只是一個,從調了文件系統級atime,到調整wal size減少日志被動清理,還有在驗證temp文件,這里后來又發現了sysdate函數的timezone調用,簡單記錄。
前面有提到是newfsatat()函數產生的system CPU,用于文件驗證,這可能是因為是BClinux 22的原因,也有可能早期版本調用的是stat()函數。
分析思路
確認是系統級還是進程級
如果是PG進程,跟蹤當時執行的命令
多并發會話,壓力測試還原問題
使用strace跟蹤定位函數占用
使用strace跟蹤函數調用的內容,如newfsatat()驗證的是什么文件
根據操作的文件類型,判斷相關功能。
相關命令
--確認進程idselect?pg_backend_pid();-- 跟蹤函數占比strace?-c?-p xxx--跟蹤進程strace?-p xxx ??-o ?str.log-- 查看文件調用grep newfsatat str.log使用捕捉的SQL幾個并發pgbench壓測,負載如下,可見sys cpu使用近80%
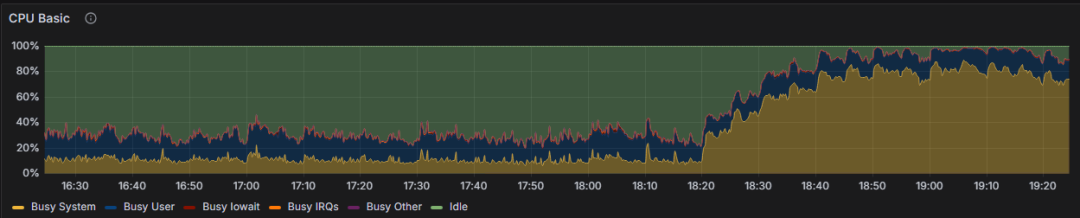
問題一
產生的是pg_temp

$grep?newfsatat xxx
newfstatat(AT_FDCWD,?"base/pgsql_tmp/pgsql_tmp....newfstatat(AT_FDCWD, "base/pgsql_tmp/pgsql_tmp....案例中一條3張表的left join操作,調用了3000多次newfstatat調用,并且幾乎全是pgsql_tmp的臨時文件。
PostgreSQL 哪些使用臨時文件
在數據庫中的一些操作,可能會用到臨時文件,比如排序、HASH JOIN、聚合、distinct、中間結果存儲等等。為了提高數據庫的執行效率,一些操作可能會使用內存代替臨時存儲,僅僅當內存不足時使用臨時文件。通過work_mem可以設置會話Query使用的臨時內存的閾值,這里的臨時都是Query執行過程中產生的臨時文件,而不是臨時表,通常臨時空間在事務結束、Query結束后會自動回收。
加大work_mem可以減少臨時文件,配置參數temp_file_limit=0可以把產生臨時文件和SQL信息寫到日志中。另外注意explain執行計劃中的Sort Method: external merge Disk: xxxkB,僅顯示了一部分的臨時文件使用情況,這里的實際情況是,explain顯示的是峰值使用量,而不是總使用量。
可以在視圖pg_stat_database中看到數據庫級別的統計信息,其中有temp_files和temp_bytes。這兩列非常重要,因為它們會告訴您數據庫是否必須向磁盤寫入臨時文件,這將不可避免地減慢操作速度。通常是因為work_mem設置太低,大量的低效SQL操作大數據,當時在創建索引等。
問題二
讀取/etc/timezone

基于上面的問題我們壓測是在tmp文件,查看執行計劃使用的是hash join,該join是會產生tmp,我們在謂詞列和join列創建了索引,優化器使用了nest loop join而不是hash join,結果不再產生temp,再使用相同的負載壓測,負載sys cpu縮少了一倍,近30%,但顯然也不正常。
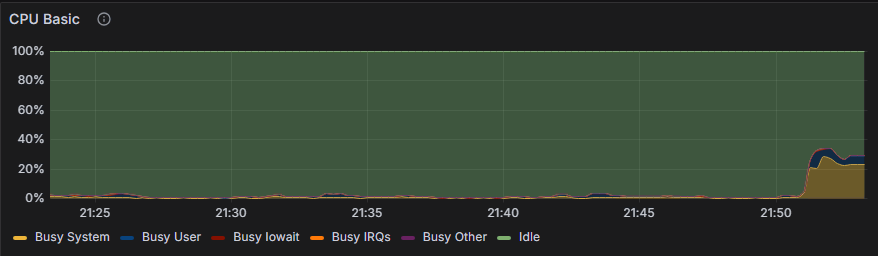
使用上面的方法繼續strace跟蹤,發現如下:
newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...},?0) =?0newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...},?0) =?0newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...},?0) =?0newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...},?0) =?0newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...},?0) =?0...近幾千次的/etc/localtime調用。判斷應該是在做timezone相關調用,查看SQL 謂詞條件有使用一個oracle兼容的函數sysdate,取的是一個join查詢后日期字段(已創建索引)最近8小時的記錄,cdate> sysdate-to_dsinterval(‘0 8:00:00).
測試是否sysdate()和now()調用localtime
數據庫名=# select pg_backend_pid();?pg_backend_pid----------------? ? ? ? ?785320(1?row)數據庫名=# select ?sysdate;? ? ? sysdate-------------------?20250612?18:07:59(1?row)[{events=EPOLLIN, data={u32=669907864, u64=669907864}}],?1,?-1,?NULL,?8)?=?1recvfrom(12,?"Q\0\0\0\25select ?sysdate;\0",?8192,?0,?NULL,?NULL)?=?22newfstatat(AT_FDCWD,?"/etc/localtime", {st_mode=S_IFREG|0644, st_size=561,?...},?0)?=?0sendto(11,?"\2\0\0\0\300\3\0\0\216?\0\0\10\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"...,?960,?0,?NULL,?0)?=?960sendto(12,?"T\0\0\0?\0\1sysdate\0\0\0\0\0\0\0\0\0#0\0\10\377\377\377\377\0"...,?81,?0,?NULL,?0)?=?81recvfrom(12,?0xc03d58,?8192,?0,?NULL,?NULL)?=?-1?EAGAIN?(Resource?temporarily unavailable)epoll_pwait(4,數據庫名=# ?SELECT?now();? ? ? ? ? ? ? now-------------------------------?2025-06-12?18:08:10.254791+08(1?row)[{events=EPOLLIN, data={u32=669907864, u64=669907864}}],?1,?-1,?NULL,?8)?=?1recvfrom(12,?"Q\0\0\0\22SELECT now();\0",?8192,?0,?NULL,?NULL)?=?19sendto(11,?"\2\0\0\0@\0\0\0\216?\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"...,?64,?0,?NULL,?0)?=?64sendto(12,?"T\0\0\0\34\0\1now\0\0\0\0\0\0\0\0\0\4\240\0\10\377\377\377\377\0\0D\0\0"...,?89,?0,?NULL,?0)?=?89recvfrom(12,?0xc03d58,?8192,?0,?NULL,?NULL)?=?-1?EAGAIN?(Resource?temporarily unavailable)epoll_pwait(4,驗證了我的判斷,在該國產數據庫中使用sysdate需要調用newfstatat(AT_FDCWD,“/etc/localtime”),而 PostgreSQL 原生的now函數并沒有,而當前使用nl join后可能是關連的filter時,多過的調用了sysdate,而導致了問題的發生,繼續優化改為使用now(),繼續壓測。
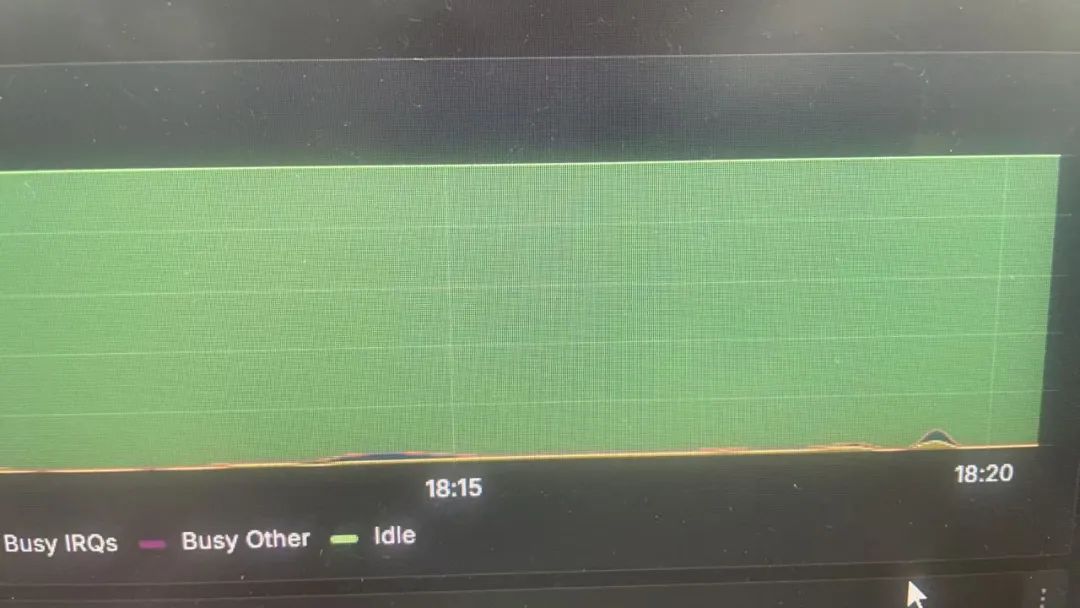
如果不放大看,幾乎沒有波動,sys CPU占用的問題得到解決,并且SQL整體的響應時間大大得到了優化提升。

數據驅動,成就未來,云和恩墨,不負所托!
云和恩墨創立于2011年,是業界領先的“智能的數據技術提供商”。公司以“數據驅動,成就未來”為使命,致力于將創新的數據技術產品和解決方案帶給全球的企業和組織,幫助客戶構建安全、高效、敏捷且經濟的數據環境,持續增強客戶在數據洞察和決策上的競爭優勢,實現數據驅動的業務創新和升級發展。
自成立以來,云和恩墨專注于數據技術領域,根據不斷變化的市場需求,創新研發了系列軟件產品,涵蓋數據庫、數據庫存儲、數據庫管理和數據智能等領域。這些產品已經在集團型、大中型、高成長型客戶以及行業云場景中得到廣泛應用,證明了我們的技術和商業競爭力,展現了公司在數據技術端到端解決方案方面的優勢。












)
)

安全管理(3)-行級訪問控制)
的核心區別,以及 Wi-Fi 技術未來的發展方向)

進階)》)
)
