
本文整理自 Discord 機器學習工程師 David Christle 在 Pulsar Summit NA 上的演講內容,一起來看 Discord 是如何基于 Pulsar 實現兼顧安全和個性化功能的實時流式機器學習平臺的~
1. 背景
Discord 是一個實時?視頻通信平臺,?持?本/語?/視頻頻道交流,廣泛應用于1對1、中小團隊或?型社區的在線交流場景,能支持用戶從私密聊天到百萬級社區通信的不同需求。平臺于2015年創立,最初在游戲社區中流行起來,目前已擴展到多個領域,月活用戶達1.5億。
2. 挑戰
Discord 面臨的核心挑戰是升級其實時流式機器學習平臺,以應對安全和個性化需求,例如限制垃圾信息訪問或保護用戶賬戶免遭入侵。其原先架構是為啟發式規則設計的,而非機器學習。為了尋求一個穩健、可擴展且實時的解決方案,他們探索了集成 Apache Pulsar、Flink和 Iceberg 的方案。

2.1 需求

“該系統的運行速度和可擴展性是關鍵所在。”
“該框架非常強大,支持過濾、轉換、連接、聚合等操作;你在數據處理方式上擁有極大的自由度,即使在實時場景下效率也非常高。這些管道可以非常簡單,比如事件采集和去重;也可以用來完成 ETL 任務。我們能在流數據上以極低延遲進行機器學習。”

安全
反垃圾郵件:通過跨職能團隊協作,最大程度避免?戶對垃圾內容和垃圾郵件發送者的接觸
賬戶安全:主動保護?戶賬戶免遭?侵,并在?侵發?時實現快速檢測
處理速度和可擴展性:解決?案的速度和可擴展性?關重要,直接影響?戶體驗和安全防護效果
個性化
發現服務器(Discord Server,類似興趣組):幫助?戶快速發現感興趣的新服務器
通知優化:實時確定最佳通知內容和發送時機,確保信息時效性
響應速度:需要在?分鐘內完成相關計算,避免內容過時失效
2.2 痛點
規則引擎不適合ML: 專為人工規則設計,無法處理歷史數據,基礎計算困難,導致新特征上線延遲長達一個月。
批處理延遲高、整合難: 數據獲取的延遲依賴批處理的效率,手動拼接批處理與實時特征易錯難調,模型問題診斷困難。
微服務臃腫低效: 每個模型獨立部署微服務帶來高復雜度與部署負擔,響應速度跟不上威脅變化,靈活性犧牲了實時性。
3. 解決方案
Discord 采用了基于 Pulsar、Flink 和 Iceberg 的實時流處理方案。其中,從 Google Cloud Pub/Sub(GCP) 遷移到 Pulsar 是一個關鍵決策,顯著提升了效率和可擴展性。Flink 和 Iceberg 則在分析實時數據、管理歷史事件以及回填(backfill)方面發揮了至關重要的作用。

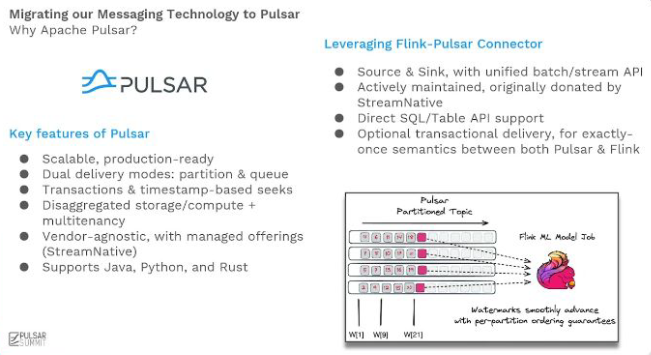
“對我們而言,Pulsar 的關鍵優勢在于它不僅擁有隊列傳輸模式(這在 Discord 非常常用),還提供了分區式傳輸模式。”
“Pulsar 分區傳輸在保障順序性的同時,還能實現極低的延遲 ;我們利用這一點實現了近乎即時的水位線(watermark)體驗,并在低延遲的情況下獲得了準確的結果。”

GCP 提供了一種無狀態且無序的內部事件流量托管方案,適用于不關?時間順序的寬泛分發隊列、大規模并?處理的?狀態任務,但存在以下問題:
Connector:Flink-PubSub 連接器維護不?且過時;需要依賴開源 PR 才能實現統?批流 API
高延遲:高達20-40s的延遲
高成本:隨著規模擴大成本明顯拉高
在這種場景下,Pulsar 憑借豐富的 Connector 支持、分區和隊列雙模式、存算分離、原生多租戶支持及優秀的低延遲表現從眾多方案中脫穎而出。
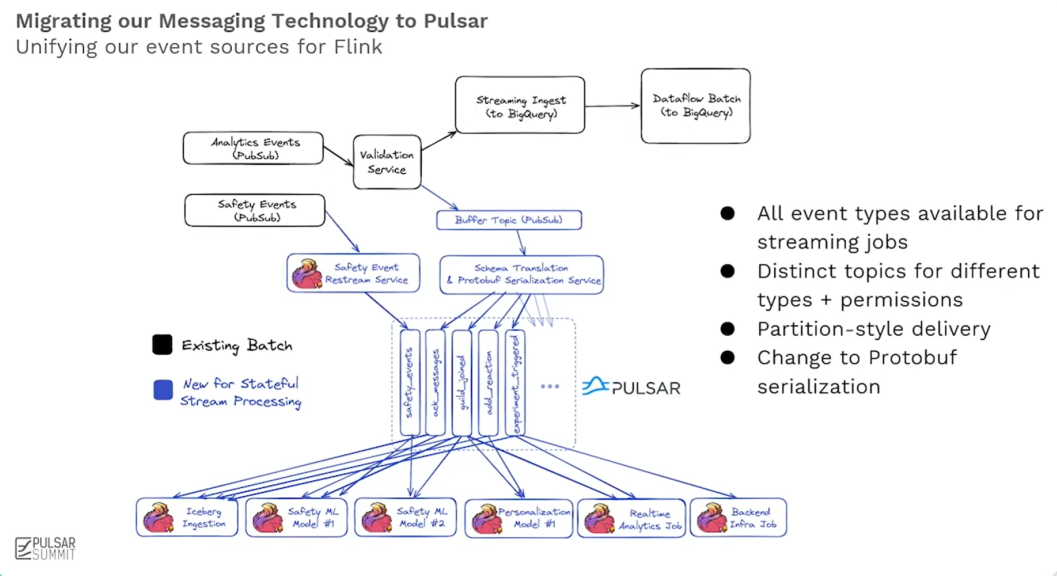
基于業務需求,Discord 的工程師團隊構建了一個成熟精簡、高效靈活且突破傳統限制的生產級架構,Pulsar 在其中扮演了實時數據主干網與流批融合關鍵樞紐的角色。
精簡架構與生產就緒的 ML 生態系統:該方案顯著簡化了架構,減少了部署組件。工程師無需關注底層數據來源的復雜性,系統自動處理數據分區和可靠交付。利用 Flink 作業進行實時的特征計算(過濾、聚合、連接等),并將長期運行(數月)的計算結果直接輸出到 Iceberg 表中,作為高質量的訓練數據集。模型部署采用ONNX格式,兼容XGBoost、PyTorch、TensorFlow等主流框架,其二進制文件可直接嵌入Flink作業運行,完全摒棄了傳統獨立的模型服務,這不僅大幅降低了系統復雜度和潛在錯誤,也使得開發調試更簡單快速,顯著提升了開發效率。
靈活流處理與混合源能力: 系統的關鍵創新在于利用 Flink 的HybridSource技術,無縫融合了批處理源(Iceberg)和流處理源(Pulsar)。Pulsar 作為核心的實時數據流來源,與 Iceberg 的歷史數據結合得天衣無縫。系統能夠在預定時間戳自動在批處理和流處理源之間透明切換,這對工程師完全隱藏了底層復雜性。這種設計確保了開發環境與生產環境數據源的高度一致性,工程師可以直接使用 Pulsar 流和 Iceberg 表進行開發測試,并支持從歷史任意時間點(數月甚至一年前)啟動作業,進行回填或調試。即使在處理海量數據時,基于 Pulsar 提供的穩定實時流和 Iceberg 的可靠存儲,系統也表現出極強的穩定性和增量處理能力。
突破實時狀態與回填限制:該架構徹底解決了實時 ML 系統常見的狀態管理和歷史數據回填難題。得益于流批一體的設計(核心是 Pulsar 流與 Iceberg 表的融合)和模型內嵌于 Flink 作業的簡化架構(模型僅是作業中的一個“小方塊”),系統發生變更后,歷史數據的回填速度極快,僅需 3-4 小時即可完成。這使得快速訓練新模型并部署上線觀察效果成為現實,極大加速了模型迭代周期。運維層面,通過自定義 Bazel 規則簡化了 ML 工程師的工作流,并利用 Flink Kubernetes Operator自動化管理作業的完整生命周期(包括部署、保存點、高可用性),確保了系統的穩健運行。Pulsar 提供的持久化、可重放實時流,是支撐快速、穩定回填的關鍵基礎設施之一。
關鍵安全指標提升與廣泛適用性:此系統在 Discord 最核心的安全場景(如垃圾郵件過濾和賬戶保護)中實現了兩位數的關鍵指標提升,并成功將平臺超過 60% 的安全評分決策從傳統啟發式規則遷移至實時 ML 模型驅動。這得益于 Pulsar 提供的高吞吐、低延遲實時數據流,使得系統能夠在虛假賬戶和僵尸網絡發起攻擊、造成實際損害前就進行主動檢測與攔截,顯著增強了平臺的實時防御能力。更重要的是,該架構設計具備高度通用性,其基于成熟開源技術棧(Pulsar、Flink、Iceberg)的精簡模型和流批一體能力,使其可輕松擴展應用于 A/B 測試、用戶實驗、個性化推薦等多個場景。
4. 結語
Discord 的成功實踐充分驗證了由 Pulsar、Flink 和 Iceberg 構建的實時機器學習平臺的高效性與強大潛力。利用 Pulsar 作為高吞吐、低延遲的實時數據主干網,無縫連接流處理與批處理,為 Flink 的實時特征計算和模型嵌入提供了堅實基礎。
David Christle 的分享不僅展示了這一技術棧(尤其是 Pulsar 在流批融合中的關鍵作用)的強大實力,更凸顯了小型團隊基于成熟開源技術打造精簡、高效生產系統的卓越能力。該案例也為業界探索實時機器學習融合、構建以可靠消息流(如 Pulsar)為核心的實時數據管道提供了極具參考價值的范本。
公眾號后臺發送“Discord”獲取完整演講視頻

Apache Pulsar 作為一個高性能、分布式的發布-訂閱消息系統,正在全球范圍內獲得越來越多的關注和應用。如果你對分布式系統、消息隊列或流處理感興趣,歡迎加入我們!
Github:?
https://github.com/apache/pulsar

掃碼添加pulsarbot,加入Pulsar社區交流群
最佳實踐
互聯網
騰訊BiFang?|?騰訊云?|?微信?|?騰訊?|?BIGO?|?360?|?滴滴? |?騰訊互娛?|?騰訊游戲?|?vivo?|?科大訊飛?|?新浪微博?|?金山云?|?STICORP?|?雅虎日本?|?Nutanix Beam?|?智聯招聘?
金融/計費
騰訊計費?|?平安證券?|?拉卡拉?|?Qraft?|?甜橙金融?
電商
Flipkart?|?誼品生鮮?|?Narvar?|?Iterable?
機器學習
騰訊Angel PowerFL
物聯網
云興科技智慧城市?|?科拓停車?|?華為云?|?清華大學能源互聯網創新研究院?|?涂鴉智能
通信
江蘇移動?|?移動云?
教育
網易有道?|?傳智教育
推薦閱讀
免費可視化集群管控?|?資料合集?|?實現原理?|?BookKeeper儲存架構解析?|?Pulsar運維?|?MQ設計精要?|?Pulsar vs Kafka?|?從RabbitMQ 到 Pulsar?|?內存使用原理?|?從Kafka到Pulsar?|?跨地域復制?|?Spring + Pulsar?|?Doris + Pulsar?|?SpringBoot + Pulsar?

)




自動化工具鏈介紹)




的架構思考)






)

