文章目錄
- Linux 背景知識
- Linux 基本使用
- Linux 常用的特殊符號和操作符
- Linux 常用命令
- 文本處理與分析
- 系統管理與操作
- 用戶與權限管理
- 文件/目錄操作與內容處理工具
- Linux系統防火墻
- Shell 腳本與實踐
- 搭建 Java 部署環境
- apt(Debian/Ubuntu 系的包管理利器)介紹
- 安裝 JDK
- 安裝 MySQL
- 部署 Web 項目到 Linux
Linux 背景知識
Linux 是一個操作系統,和 Windows 是"并列"的關系,安卓系統就是基于Linux進行的開發
嚴格來說 Linux 是一個完全開源免費的操作系統內核,而一個完整的操作系統 = 操作系統內核 + 配套的應用程序。因此有些公司/開源組織又基于 Linux 內核, 提供了不同的配套程序,這就構成了不同的 “發行版”
企業中主要使用的發行版是 RedHat (紅帽),CentOS(RedHat的社區免費版本) 和 Ubuntu 。但 RedHat 是收費的,CentOS 已經停止維護了,所以本文以 Ubuntu 為主
Linux的優勢
- 開源(意味著免費,便宜)
- 穩定(Linux 可以運行很多年,都不會發生重大問題)
- 安全(對讀、寫進行權限控制、審計跟蹤、核心授權等技術)
- 自由(不會被強加商業產品和服務)
- 社區支持(Linux 在全球社區都非常活躍和使用廣泛,有很多志愿者在線幫大家解決問題)
Linux 基本使用
環境我用的是云服務器,并使用遠程終端工具(能與遠程主機建立網絡連接并實現遠程操作) XShell 連接

@用來分隔用戶名和主機名,左邊是用戶名,右邊是主機名:右邊表示所在目錄,~表示當前路徑是在家目錄#是超級用戶終端提示符 ,表明這是在以 root 權限操作服務器
關于XShell 下的復制粘貼(可以重新設置快捷鍵)
復制:ctrl + insert
粘貼:shift + insert
PS:如果不行試試鼠標右鍵是不是有復制粘貼選項或者右鍵直接可以復制粘貼(我的 Docker 容器內右鍵是直接復制粘貼的)
Linux 終端常見操作
Ctrl+C:Linux 終端中最常用的 “萬能退出” 命令,其核心作用是強制終止當前正在運行的前臺程序(如腳本執行、命令運行等等)。若一次按下后未成功終止程序,可連續多按幾次,通常能有效中斷進程并返回終端命令行界面,操作簡單且適用性廣泛
clear:清空當前可見的屏幕內容,使光標回到終端頂部,讓界面恢復整潔狀態,方便后續操作。不過需要注意的是,clear 命令的 “清屏” 是視覺上的暫時清空,并非徹底刪除歷史輸出記錄。執行后,你仍可以通過鼠標滾輪向上滾動,或使用快捷鍵(如 Shift+PageUp)回溯查看之前的命令和輸出內容。部分終端支持 Ctrl+L 快捷鍵實現類似 clear 的效果。clear 命令因其輕量便捷,仍是日常清屏的首選
Tab 鍵:可自動補全目錄、文件名、命令等。輸入部分字符后按一次 Tab,若存在唯一匹配項,會直接補全剩余內容;若有多個匹配項(如輸入 “doc” 后對應 “document”“docs” 等),第一次按 Tab 會無反應(以此提示存在多選項),再次按下 Tab 則會列出所有符合條件的選項,便于用戶根據需求進一步輸入或選擇,有效減少手動輸入量并避免拼寫錯誤
按 上下方向鍵:可快速回溯或切換已執行過的歷史命令,按↑鍵向上翻閱更早的命令,按↓鍵向前查看較新的命令,選中后直接按 Enter 即可重復執行,適合快速調用最近操作過的命令
history:用于列出所有歷史命令記錄(通常包含序號、時間、用戶及具體命令,例如 71 2025-07-29 14:01:18 root cat note.txt),方便回溯過往操作。若需重復執行歷史命令,可通過高效方式調用:
- !序號(如 !71 直接執行第 71 條命令)
- !命令前綴(如 !git 執行最近一次以 git 開頭的命令)
- !! 作為 “萬能重試鍵”,可快速重復上一條命令,效果等同于按 ↑ 方向鍵調出上一條命令后回車,適合需要立即復用剛執行的命令場景
根目錄下的常見文件夾:
/稱為根目錄,整個文件系統的起點,所有目錄和文件都掛載在根目錄下,是系統目錄結構的 “根”/etc存放系統和應用程序的配置文件(如網絡配置、服務啟動腳本等),修改需謹慎/home是普通用戶個人主目錄(又稱家目錄)的集中存放地,每個用戶在此擁有一個以自己用戶名命名的專屬子目錄(如 /home/user1),用于存儲私人文件、用戶配置、個人程序等數據
這一設計的核心特點在于權限隔離:/home 下每個用戶子目錄(如 /home/user1)默認僅允許該用戶本人和超級用戶(root)進行讀寫操作,其他普通用戶無權隨意訪問,這是 Linux 權限安全機制的直接體現
需要注意的是,超級用戶(root)的家目錄并非位于 /home 下,而是獨立的 /root 目錄。這種設計既避免了普通用戶對 root 數據的誤操作,也進一步強化了系統最高權限與普通用戶權限的隔離,是 Linux 安全架構的重要組成部分
/bin存放所有用戶(包括普通用戶和 root)均可直接執行的基礎命令二進制文件,例如 ls、cp、mkdir等。這些命令是系統啟動、修復及日常操作的核心工具/lib存放/bin和/sbin目錄中程序依賴的共享庫文件(.so 文件),是程序運行的 “底層支撐代碼”,不可隨意刪除/user是 Linux 中用戶級軟件和資源的核心存放區,包含 /usr/bin(用戶日常命令)、/usr/lib(對應共享庫)、/usr/share(文檔等共享數據)及 /usr/local(用戶自行安裝軟件)等子目錄,集中存放非系統啟動必需但日常使用的工具、庫和數據,是用戶軟件的主要安裝位置/tmp存放臨時文件,系統會定期自動清理(或重啟后清空),適合程序運行時臨時存儲數據,所有用戶可讀寫
Linux 常用的特殊符號和操作符
管道符 |
管道是一種古老的 “進程間通信” 方式,在 Linux 指令中可以使用 | 作為管道標記。作用是將前一個命令的標準輸出(stdout) 直接作為后一個命令的標準輸入(stdin),這使得多個簡單命令可以組合成強大的功能鏈,舉例:
# 查看系統中所有包含"java"關鍵字的進程
# ps -ef 顯示系統中所有進程的詳細信息(e表示所有進程,f表示完整格式)
# grep "java" 過濾出包含"java"字符串的進程行
ps -ef|grep "java"# 查看系統中前10個進程的詳細信息
# head -10 取前10行輸出結果
ps -ef|head -10# 實時監控日志文件中包含"Exception"的日志信息
# tail -f log.txt 實時跟蹤log.txt文件的新增內容(f表示follow,持續輸出新內容)
# grep "Exception" 過濾出包含"Exception"的日志行
tail -f log.txt|grep "Exception"
變量 / 命令替換符 $
在 Shell 腳本和命令行中,$ 是一個非常關鍵的符號,用途廣泛,主要與變量、命令替換、參數傳遞等相關。以下是其核心用法的詳細說明:
- 引用變量($變量名)
示例:
name="Alice"
echo $name # 輸出:Alice(解析變量 name 的值)
echo "Hello, $name" # 輸出:Hello, Alice(在字符串中嵌入變量)
注意:若變量名后緊跟其他字符,可用 ${} 明確變量邊界,例如 echo ${name}123 會輸出 Alice123,而 echo $name123 會因變量 name123 未定義而輸出空
- 命令替換
$ 結合括號 $(…) 或就用反引號 `…` 包裹時,表示命令替換,即先執行括號/反引號內的命令,再將輸出結果作為參數或值使用
示例:
# ls 列出當前目錄下的所有文件和目錄(默認不包含隱藏文件)
# | 管道符:將 ls 的輸出作為 wc -l 的輸入
# wc -l 統計輸入內容的行數(即文件和目錄的總數量)
# 命令替換會將上述命令的輸出結果(一個數字)賦值給變量 count
count=$(ls | wc -l)
# 打印變量 count 的值,展示當前目錄下的文件和目錄總數
echo "文件數:$count"# 等價于上面的寫法(但推薦用 $(...),嵌套更清晰)
count=`ls | wc -l`
- 位置參數:$n(n 為數字)
在腳本或函數中,$1、$2…$n 用于獲取傳入的位置參數(即命令或腳本后的參數)
假設有腳本 test.sh ,內容如下:
#!/bin/bash
echo "第一個參數:$1"
echo "第二個參數:$2"
執行 ./test.sh apple banana 時,輸出:
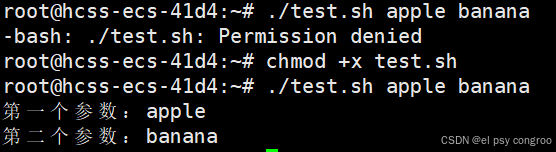
至于為什么有chmod +x test.sh下面的文件權限會介紹
特殊位置參數:
| 特殊參數 | 作用 |
|---|---|
| $0 | 當前腳本 / 命令的名稱(包含調用時的路徑) |
| $# | 統計 ??傳入腳本或函數的參數總數量 |
| $* | 所有參數的集合,默認以空格分隔,視為單個字符串(加引號時整體作為一個變量) |
| $@ | 所有參數的集合,每個參數獨立存在(加引號時保持參數間的獨立性) |
| $? | 上一條命令的退出狀態碼(0 表示成功,非 0 表示失敗) |
| $$ | 當前腳本 / 進程的 PID |
| $! | 上一個后臺進程的 PID(后臺運行命令時,獲取其進程 ID) |
| $- | 顯示當前 Shell 啟用的選項標志 |
| $PPID | 當前進程的父進程 PID(即啟動當前腳本的進程 ID) |
常見的環境變量及其作用:
| 環境變量 | 作用說明 |
|---|---|
| HOME | 當前用戶的主目錄路徑 |
| USER / LOGNAME | 當前登錄的用戶名 |
| UID | 當前用戶的用戶 ID(數字) |
| GID | 當前用戶的主組 ID(數字) |
| PWD | 當前工作目錄的絕對路徑 |
| OLDPWD | 上一次工作目錄的絕對路徑(cd - 命令依賴此變量) |
| HOSTNAME | 當前主機的名稱 |
環境變量是系統或程序預定義的變量,可通過 echo $變量名(如 echo $HOME)查看其值
用戶可通過 export 變量名=值(如 export PATH=$PATH:/new/dir)臨時設置環境變量,若需永久生效,需寫入 Shell 配置文件
輸入輸出重定向符(用于控制命令的輸入來源或輸出方向)
> 覆蓋輸出到文件(若文件存在則清空原有內容)
echo "Hello" > test.txt # 將 "Hello" 寫入 test.txt,覆蓋原有內容
>> 追加輸出到文件(在文件末尾添加內容)
echo "World" >> test.txt # 在 test.txt 末尾添加 "World"
< 從文件讀取輸入(代替標準輸入)
grep "error" < log.txt # 等價于 grep "error" log.txt,從 log.txt 中查找 "error"
2> 重定向錯誤輸出(2 代表標準錯誤流)
ls non_exist_file 2> error.log # 將錯誤信息寫入 error.log,而非屏幕
&> 直接合并標準輸出和錯誤輸出并重定向到指定位置,寫法簡潔且不依賴順序,但兼容性較差
command &> output.log # 命令的所有輸出(正常+錯誤)都寫入 output.log
2>&1 需先指定標準輸出的重定向,再讓錯誤輸出跟隨其方向(嚴格依賴此順序),兼容性強,是腳本常用寫法
# 把命令的正常輸出和錯誤輸出都寫入 output.log
command > output.log 2>&1 # 錯誤的,這是先讓 stderr 指向 stdout(屏幕),再將 stdout 重定向到文件,導致 stderr 仍輸出到屏幕
command 2>&1 > output.log
邏輯運算符(用于組合多個命令,根據前一個命令的執行結果決定是否執行后一個)
&& 邏輯與(前一個命令成功執行,才執行后一個)
make && make install # 只有 make 成功,才執行 make install
|| 邏輯或(前一個命令執行失敗,才執行后一個)
command || echo "命令執行失敗" # 若 command 失敗,輸出提示
; 命令分隔符(無論前一個命令是否成功,都執行后一個)
cd /tmp; ls # 先切換到 /tmp,再執行 ls(無論 cd 是否成功)
通配符(用于匹配文件名 / 路徑)
* 匹配任意數量的任意字符(包括 0 個)
ls *.txt # 列出所有 .txt 結尾的文件
? 匹配單個任意字符
ls file?.log # 匹配 file1.log、fileA.log 等(中間一個字符任意)
[] 匹配括號內的任意一個字符
ls [abc].txt # 匹配 a.txt、b.txt 或 c.txt
ls [0-9].log # 匹配 0.log 到 9.log
[^] 匹配不在括號內的任意字符(取反)
ls [^a].txt # 匹配除 a.txt 外的 x.txt(x 為任意字符)
引號
反引號 `` 等同于 $(…),用于命令替換,但推薦優先用 $(…)
echo "當前目錄:`pwd`" # 等價于 echo "當前目錄:$(pwd)"
雙引號""保留字符串整體結構(如空格),同時解析 $ 引導的變量 / 特殊參數、` 或 $(…) 形式的命令替換,并僅對 $、`、"、\ 啟用 \ 轉義
在雙引號中,\ 僅對 $、`、"、\ 這四個字符有轉義作用,對其他字符(如*、?、\n等),\會被當作普通字符輸出,不具備轉義功能
name="Alice"; echo "Hello $name" # 輸出:Hello Alice(變量被解析)
echo "價格:\$99" # 輸出:價格:$99(\$ 轉義為 $,不解析為變量)
echo "他說:\"你好\"" # 輸出 他說:"你好"(\ 轉義 ",避免提前結束雙引號)
echo "Line1\nLine2" # 輸出:Line1\nLine2(\n 不被轉義,原樣輸出),若要換行需用-e選項
echo "file*.txt" # 輸出:file*.txt(* 不解析為通配符,加不加\都一樣)
echo "file\*.txt" # 輸出:file\*.txt
echo "a\\b" # 輸出:a\b(\ 轉義自身,最終保留一個 \)
單引號 '' 完全禁用所有特殊字符的解析,包括變量($)、通配符(*)、命令替換(` 或 $())、轉義符(\)等,所有字符都會被當作字面量處理
name="Alice"; echo 'Hello $name' # 輸出:Hello $name($name 不解析)
echo '價格:\$99' # 輸出:價格:\$99($ 按字面輸出)
echo '他說:"你好"' # 輸出:他說:"你好"(雙引號無需轉義)
其他實用符號
~ 代表當前用戶的主目錄(等價于 $HOME)
cd ~ # 切換到主目錄
.. 和 . . . 代表上一級目錄,. 代表當前目錄
cd .. # 進入上一級目錄
cp ./file.txt ../ # 將當前目錄的 file.txt 復制到上一級目錄
# 注釋符號(# 后的內容不執行)
echo "Hello" # 這是一條注釋,不會被執行
& 將命令放入后臺執行(不阻塞當前終端)
python server.py & # 讓 server.py 在后臺運行,終端可繼續輸入其他命令
\(轉義符)的轉義作用具有場景依賴性,既能在特定條件下讓 *、?、$、" 等特殊字符失去特殊含義按字面處理,也能在特定條件下與 n、t 等普通字符組成轉義序列(如 \n 表示換行)賦予其特殊功能
echo * # 輸出:*(\ 轉義 *,使其失去通配符功能,僅作字面字符)
echo $HOME # 輸出:$HOME(\ 轉義 $,使其不解析為變量引用,僅作字面字符)
echo -e "換行:\n" # 輸出換行(-e 選項啟用轉義解析,\n 被識別為換行符)
這些符號是 Shell 命令行和腳本編程的基礎,靈活組合使用可以實現復雜的功能(如批量處理文件、條件執行命令、自動化任務等)。掌握它們能顯著提升 Linux 命令行的使用效率
Linux 常用命令
在 Linux 命令中,短選項(單橫線 + 單個字母)以簡潔可合并(如ls -la合并-l和-a)為優勢,長選項(雙橫線+ 完整單詞)以可讀性見長但無法合并,兩者功能等效;多數無參數選項順序可靈活調整(如rm -rf與rm -fr效果相同)
在命令語法說明中,
[](方括號)和<>(尖括號)是元字符,僅用于描述參數的性質(可選 / 必填),實際輸入命令時不用包含這些符號
例如 kill [選項] <PID>... 表示:
- [選項] 可寫可不寫
- <PID> 必須替換為具體的進程 ID
- … 表示可以跟多個 PID
這些符號的作用是清晰區分參數的必要性,簡化命令格式的說明,實際執行時只需替換為具體值即可,比如實際輸入可以為 kill -9 1234 而不是 kill [-9] <1234>
文本處理與分析
grep [選項] 模式 [文件]... 在文件或輸入流中搜索匹配指定模式(字符串或正則表達式),它會逐行掃描目標內容,輸出所有包含匹配模式的行,是文本搜索、日志分析的常用工具
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -n | --line-number | 顯示匹配行的行號 |
| -i | --ignore-case | 忽略大小寫匹配 |
| -r | --recursive | 遞歸搜索目錄下所有文件(包括子目錄) |
| -w | --word-regexp | 全字匹配,僅匹配完整單詞,避免部分包含的情況 |
| -c | --count | 只顯示匹配到的行數(不顯示具體內容) |
| -l | --files-with-matches | 只顯示包含匹配內容的文件名(適合多文件搜索) |
| 無 | --color | 高亮顯示匹配結果,方便快速定位目標內容 |
| 無 | --include | 指定搜索符合特定模式的文件 |
| 無 | --exclude | 指定排除某些文件 |
示例:
- 在文件中搜索字符串:
# 在 test.txt 中搜索包含 "error" 的行
grep "error" test.txt
- 忽略大小寫搜索
# 匹配 "Error"、"ERROR"、"error" 等
grep -i "error" log.txt
- 多文件搜索并顯示文件名:
# 在所有 .conf 文件中搜索 "port",并顯示包含該內容的文件名
grep -l "port" *.conf
- 與管道配合使用,過濾輸出結果:
# 查看進程列表中包含 "nginx" 的進程
ps aux | grep "nginx"
- 指定高亮顯示的方式
--color 后面可以跟一些參數來指定高亮顯示的具體方式
比如加上 always 表示始終對匹配的內容進行高亮顯示,即便輸出結果不是輸出到終端(例如重定向到文件時也會添加高亮的控制字符),例如:
grep --color=always "success" access.log > result.txt
雖然 result.txt 是文本文件,但其中匹配到 success 的部分添加了相應的顏色控制字符 ,如果用支持顯示顏色的文本查看工具打開(如在終端中用 less -r result.txt,-r 選項用于支持顯示顏色控制字符),能看到高亮效果
加上 never 表示從不進行高亮顯示,即便輸出到終端。這在希望輸出簡潔、不帶有顏色控制字符的文本時比較有用,例如:
grep --color=never "warning" system.log
加上 auto(默認情況)表示只有當輸出結果是輸出到終端時,才對匹配內容進行高亮顯示;如果輸出重定向到文件,則不進行高亮,例如:
grep --color=auto "info" app.log
# 輸出到終端,有高亮
grep --color=auto "info" app.log > backup.log
# 輸出到文件,無高亮
awk [選項] '模式 {動作}' [文件]... 對結構化文本(如日志、CSV、配置文件)進行模式匹配、字段提取、數據統計等操作。其核心思想是 “逐行處理輸入,按規則執行動作”,廣泛用于日志分析、數據清洗、報表生成等場景
- [選項]常用的有:
| 選項 | 功能描述 |
|---|---|
| -F 分隔符 | 指定字段分隔符(默認以連續空格 / 制表符為分隔符,多個空格視為一個) |
| -v 變量=值 | 在 awk 程序開始前定義變量并賦值,可在腳本中直接使用 |
| -f 腳本文件 | 從指定文件中讀取 awk 腳本(適合復雜邏輯,避免命令行過長) |
- ‘模式 {動作}’:awk 的核心邏輯(需用單引號包裹),其工作流程是:逐行讀取輸入,對每行判斷是否匹配 “模式”,若匹配則執行 “動作”,直至處理完所有內容,一個動作塊({} 內)中如果有多個語句,需要用 ; 分隔
- 模式(Pattern):用于指定條件篩選行,支持正則表達式(如 /error/ 匹配含 “error” 的行)、行號(如 NR == 5 匹配第 5 行)、比較表達式(如 $1 > 100 匹配第一列大于 100 的行)等,不指定則默認匹配所有行,多個模式(條件)之間用邏輯運算符 &&(與)、||(或)連接
- 動作(Action),用 {} 包裹:對匹配的行執行的操作,如打印第 n 個字段 {print $n}、變量運算(如 {sum += $1},累加第一列的值)、條件判斷(如 {if ($2 > 0) print $0},每行的第 2 個字段的值大于 0 時,打印整行內容)等。不指定動作時,默認打印整行,等價于 {print $0}
核心特性
- 非交互式處理:可直接處理文件(如 awk ‘…’ file.txt),也可通過管道接收其他命令輸出(如 cat file.txt | awk ‘…’)
- 強大的模式匹配:支持正則表達式匹配,例如 $0 ~ /warning/ 可匹配含 “warning” 的行(~ 表示匹配)
- 可編程性:支持變量定義、循環(for/while)、條件判斷(if-else)等,可實現復雜邏輯(如統計、過濾、轉換)
核心內置變量(必知)
內置變量是 awk 操作行和字段的關鍵,常用變量如下:
| 變量 | 含義 |
|---|---|
| $0 | 表示當前行的整行內容 |
| $n | 表示當前行的第 n 個字段(n 為正整數) |
| NF | 當前行的字段總數 |
| NR | 當前處理的行號(從 1 開始累計) |
| FS | 字段分隔符(默認是空格 / 制表符,可自定義) |
| OFS | 輸出字段分隔符(默認是空格,自定義后可規范輸出格式) |
示例:
- 既有模式,又有動作(最常用)
場景:提取特定字段,從 /etc/passwd 中篩選出 bash 登錄用戶,并顯示其用戶名和 UID
# -F ':' 指定字段分隔符為冒號(適配/etc/passwd的格式)
# 模式:$7 ~ /bash$/(第7字段以bash結尾);動作:打印第1和第3字段
awk -F ':' '$7 ~ /bash$/ {print "用戶:", $1, "UID:", $3}' /etc/passwd
- 只有模式,無動作(默認動作:打印整行)
場景:篩選出access.log中第1字段為192.168.1.1且行中包含ERROR的行
awk '$0 ~ /ERROR/ && $1 == "192.168.1.1"' access.log
# 等價寫法(使用/ERROR/簡化形式)
awk '/ERROR/ && $1 == "192.168.1.1"' access.log
- 只有動作,無模式(默認匹配所有行)
場景:統計與計算scores.txt(格式:姓名 語文 數學)的數學成績平均值
# {sum += $3; count++} 對每一行:累加第3個字段(數學成績)到sum,并增加人數
# END { ... } 所有行處理完后執行:計算并打印平均值
awk '{sum += $3; count++} END {print "平均數學成績:", sum/count}' scores.txt
對文件中每一行都執行動作,適合批量處理所有內容
-
模式和動作都省略,實際用途較少,更多用于演示 awk 的默認行為
-
外部交互與三段式結構
假設有一個grades.txt文件,內容為學生 ID、語文成績、數學成績(空格分隔),需求:
- 從外部傳遞兩個閾值:語文及格線(chinese_pass)和數學及格線(math_pass)
- 循環處理每一行,篩選出 “至少有一門及格” 的學生
- 統計這些學生中兩門都及格的人數
chinese_pass=60
math_pass=60awk -v c_pass=$chinese_pass -v m_pass=$math_pass '# BEGIN塊:處理文件前執行(只執行一次)BEGIN {print "===== 學生成績篩選統計 ====="print "語文及格線:" c_pass "分"print "數學及格線:" m_pass "分"print "-------------------------"# 初始化變量(可選,顯式初始化更清晰,不初始化用的時候會隱式初始化為 0)total=0both_pass=0}# 逐行處理(隱含循環){# 判斷是否至少一門及格if ($2 >= c_pass || $3 >= m_pass) {total++ # 累計符合條件的學生print "學生" $1 ":語文" $2 ", 數學" $3 "(符合條件)"# 統計雙及格人數if ($2 >= c_pass && $3 >= m_pass) {both_pass++}}}# END塊:處理完所有行后執行END {print "-------------------------"print "統計結果:"print "符合條件的學生總數:" totalprint "兩門都及格的學生數:" both_passprint "雙及格率:" (both_pass/total)*100 "%"}
' grades.txt
- BEGIN 塊:
- 只在處理第一行內容之前執行一次
- 通常用于初始化變量、打印表頭、設置分隔符等預處理操作
- END 塊:
- 只在處理完所有行之后執行一次
- 通常用于計算最終結果、打印統計信息、匯總數據等收尾操作
這兩個塊體現了 awk 的可編程性,使它不僅能做簡單的文本過濾,還能實現復雜的數據分析邏輯
- 自定義輸入分隔符與輸出格式(CSV 轉 | 分隔格式并加表頭)
# -F ',' 指定輸入分隔符為逗號(適配CSV格式)
# BEGIN {OFS="|"; print "姓名|年齡|城市"} 處理前執行:設置輸出分隔符為|,并打印表頭
# {print $1, $2, $3} 按新格式輸出每行的3個字段
awk -F ',' 'BEGIN {OFS="|"; print "姓名|年齡|城市"} {print $1, $2, $3}' data.csv
- 結合管道
# 提取日志中所有IP(第1字段)→ 排序去重計數 → 按次數倒序 → 取前3
awk '{print $1}' access.log | # 從日志中提取所有IP地址sort | # 對IP排序(為uniq去重做準備)uniq -c | # 統計每個IP出現的次數(-c顯示計數)sort -k1,1nr | # 按第1列(計數)數字倒序排序head -n 3 # 取訪問量最高的前3個IP# 生成1-100序列 → 篩選偶數并計算平方和
seq 100 | # 生成1到100的連續數字awk '$1 % 2 == 0 { # 篩選偶數(對2取余為0)sum += $1 * $1 # 累加平方值(用$1*$1替代^,兼容性更好)}END {print "1-100偶數的平方和:", sum # 輸出最終結果}'
wc [選項] [文件]... 用于統計文件內容的實用命令,能快速計算行數、單詞數、字節數等
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -l | --lines | 僅統計行數(以換行符 \n 為標志) |
| -w | --words | 僅統計單詞數(以空白字符分隔的字符串,連續空白視為一個分隔符) |
| -c | --bytes | 僅統計字節數(包含所有字符,包括換行符、空格等) |
| -m | --chars | 統計字符數(多字節字符如中文按單個字符計數) |
| -L | --max-line-length | 顯示文件中最長行的長度(以字符為單位,不包含換行符本身) |
示例
- 統計單個文件的信息,默認情況下,wc 會按「行數 單詞數 字節數 文件名」的順序輸出
wc access.log
- 計算代碼行數(排除空行更精準)
# grep -v:反向匹配(輸出不匹配模式的行)
# '^$':正則表達式,表示空行(^ 匹配行開頭,$ 匹配行結尾,中間無任何字符)
# *.py:匹配當前目錄下所有以 .py 結尾的文件
grep -v '^$' *.py | wc -l
- 統計當前目錄文件數
ls | wc -l # 輸出當前目錄下的文件/文件夾總數
- 對比文件大小(字節級差異)
wc -c config.ini config.bak # 輸出兩個文件的字節數,便于對比
- 實時監控日志增長
# 使用 watch 命令定期執行統計操作
# -n 10:指定間隔時間為10秒(每10秒刷新一次結果)
# "wc -l access.log":被定期執行的命令
watch -n 10 "wc -l access.log"
sed [選項] '指令' [文件名]... 用于查找、替換、刪除、插入等操作,特別適合在管道中處理數據流或批量修改文件內容
常用選項:
| 選項 | 功能說明 |
|---|---|
| -i[SUFFIX] | 直接修改文件內容。若指定后綴,則會對原文件備份(帶該后綴), 再修改原文件;若不指定后綴,則直接修改原文件,不保留備份 |
| -e | 指定編輯指令(腳本),用于執行多個編輯操作時使用 |
| -n | 取消默認輸出(只顯示被 p 指令明確指定打印的行) |
核心指令
| 格式 | 說明 |
|---|---|
| s/原內容/新內容/[選項] | 替換文本內容。[選項] 包括:g(全局替換,不然默認只替換每行 第一個匹配)、數字(替換第 N 次匹配)、i(忽略大小寫)等 |
| d(配合模式匹配) | 刪除匹配模式的行(如 3d 刪除第 3 行,/pattern/d 刪除包含 pattern 的行) |
| p(通常配合-n使用) | 打印匹配模式的行 |
| i | 在指定行(或匹配行)前插入內容 |
| a | 在指定行(或匹配行)后追加內容 |
- 不使用 -i 選項時,上述命令僅對輸入內容進行處理并輸出到屏幕,不會修改原文件
- 使用 -i 選項時,所有命令的操作結果會直接作用于原文件(可通過指定后綴創建備份)
示例
sed 's/hello/HELLO/' file.txt # 替換每行第一個hello為HELLO
sed 's/hello/HELLO/g' file.txt # 替換每行所有hello為HELLO(g表示全局)
sed 's/^#//' file.txt # 去除行首的#(注釋符號)sed '/^$/d' file.txt # 刪除所有空行(^$表示空行)
sed '3d' file.txt # 刪除第3行sed -n '1,10p' file.txt # 只打印第1到10行
sed -n '/pattern/p' file.txt # 只打印包含pattern的行(等效于 grep "pattern" file.txt)sed '1i # 這是注釋' file.txt # 在第1行前插入注釋
sed '/^exit/a echo "完成"' script.sh # 在所有以exit開頭的行(^ 表示行首,確保精確匹配行首的 exit)后追加一行
系統管理與操作
hostname:查看和設置主機名
date:查看和設置系統日期、時間
reboot:重啟主機
ifconfig:配置和查看網絡接口信息,可以查看IP地址
netstat [參數]:用于查看網絡狀態的命令,可顯示系統的網絡連接、路由表、接口統計等
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -a | --all | 顯示所有網絡連接(包括監聽和非監聽狀態的套接字) |
| -u | --udp | 僅顯示 UDP 協議的連接 |
| -t | --tcp | 僅顯示 TCP 協議的連接 |
| -l | --listening | 僅顯示處于監聽(listening)狀態的連接 |
| -n | --numeric | 以數字形式顯示 IP 地址和端口號(不進行域名解析,速度更快) |
| -p | --program | 顯示每個連接對應的 PID 和進程名稱(需要 root 權限) |
lsof:列出系統中所有被進程打開的文件。在 Unix/Linux 系統中,“文件” 的概念非常寬泛,不僅包括普通文件,還包括網絡套接字、管道、設備、目錄等,因此 lsof 常被用于排查系統資源占用、進程依賴、網絡連接等問題
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -i <:端口號> | --internet <:端口號> | 顯示占用指定網絡端口的進程信息 |
| -u <用戶名> | --user <用戶名> | 查看用戶打開的文件 |
| -c <進程名> | --command <進程名> | 按進程名稱過濾 |
| -p <PID> | --pid <PID> | 查看進程打開的文件 |
| -t | --terse | 表示僅輸出 PID ,便于批量操作 |
# 列出所有占用 8080 端口的進程
lsof -i :8080
# 可指定協議(TCP/UDP)
lsof -i tcp:80
# 可查看與指定 IP 的連接
lsof -i @192.168.1.100
# 列出 root 用戶所有進程打開的文件,便于審計特定用戶的操作
lsof -u root
# 查看所有 nginx 進程打開的文件
lsof -c nginx
# 列出 PID 為 1234 的進程打開的所有文件,可用于排查進程依賴的資源
lsof -p 1234
# 直接殺死占用 8080 端口的進程
kill $(lsof -t -i :8080)
ps [參數]:用于顯示當前系統中運行的進程信息(如進程 ID、運行狀態、占用資源等)
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -a | 無 | 顯示所有用戶的進程(除了后臺進程),與 -x 結合可顯示所有進程 |
| -u [用戶名] | --user [用戶名] | 若指定用戶名顯示該用戶的進程;若不指定則顯示當前用戶進程 |
| -x | 無 | 顯示沒有控制終端的進程(通常是后臺進程) |
| -e | --everyone 或 --all-processes | 顯示系統中所有進程(等價于 -A) |
| -f | --full | 顯示完整格式的進程信息 |
| -l | --long | 以長格式顯示進程信息(包含更詳細的狀態字段) |
| -p <PID> | --pid <PID> | 只顯示指定 PID 的進程信息 |
| -t <終端> | --tty <終端> | 顯示指定終端上運行的進程 |
| 無 | --sort <字段> | 按指定字段排序 |
常用組合示例:
# 以 System V 風格顯示系統所有進程的完整信息
# -e: 顯示所有進程;-f: 輸出完整格式
ps -ef# 以 BSD 風格顯示所有進程的詳細用戶信息
# -a: 顯示所有有終端的進程;-u: 以用戶為中心展示信息;-x: 包含無終端的后臺進程
ps -aux# 查看指定 PID(如 1234)的進程詳情
# -p: 按進程 ID 過濾,僅顯示目標進程信息
ps -p 1234# 顯示所有進程并按 CPU 占用率降序排序(頂部為占用最高的進程)
# --sort=-%cpu: 按 CPU 使用率降序排列(- 表示降序,+ 表示升序可省略,默認即為升序)
ps -aux --sort=-%cpu
常見進程狀態字段(STAT 含義):
- R:運行中(正在執行或等待 CPU 時間)
- S:睡眠中(等待事件完成,可被喚醒)
- D:不可中斷睡眠(通常與 I/O 相關,無法被信號喚醒)
- Z:僵尸進程(已終止但未被父進程回收的進程)
- T:暫停狀態(被信號暫停,如 Ctrl+Z 暫停的進程),或被跟蹤
- <:高優先級進程
- N:低優先級進程
ps 命令常與 grep 結合過濾特定進程(如 ps -ef | grep “nginx” 查找 nginx 相關進程),是系統監控和進程管理的基礎工具
kill [進程信號] <PID>...:用于向進程發送信號(默認是終止信號),實現進程的終止、暫停、重啟等操作
進程信號用數字或名稱表示,以下是最常用的幾個:
| 信號數字 | 信號名稱 | 含義 | 典型場景 |
|---|---|---|---|
| 1 | SIGHUP | 掛起信號(讓進程重讀配置文件,不終止) | 重啟服務 |
| 9 | SIGKILL | 強制終止信號(無法被進程忽略,強制殺死) | 常規方法無法終止的頑固進程 |
| 15 | SIGTERM | 終止信號(默認,允許進程優雅退出,清理資源) | 正常終止進程 |
| 2 | SIGINT | 中斷信號(等同于 Ctrl+C) | 手動中斷前臺運行的進程 |
echo [選項] [輸出內容]:用于在終端輸出字符串、變量值或命令結果,是 Shell 腳本中打印信息的常用工具
常用選項:
| 短選項 | 功能說明 |
|---|---|
| -n | 輸出內容后不自動換行(默認情況下,echo 會在輸出末尾添加換行符) |
| -e | 啟用對輸出字符串中轉義字符的解析(如 \n 表示換行、\t 表示制表符) |
用戶與權限管理
一、用戶賬戶管理
- 核心定義:用戶賬戶是個體或進程使用系統的 “身份憑證”,核心屬性包括用戶名、唯一數字標識UID、所屬用戶組、家目錄、默認 Shell 等
- 核心標識:UID(User ID)是用戶的唯一數字標識,用于區分不同用戶。而用戶名是為了方便用戶記憶而設置的
- 關鍵文件(依托下述兩個文件實現用戶信息的存儲與管理,為權限控制提供基礎身份依據):
- 用戶信息文件(/etc/passwd):存儲所有用戶的基礎公開信息,每行對應一個用戶,清晰記錄用戶名、UID、默認組 GID、家目錄路徑、默認 Shell 等非敏感數據
- 用戶密碼文件(/etc/shadow):專門存儲用戶密碼及敏感信息(而非 /etc/passwd ),包括加密后的密碼、密碼最后修改時間、有效期、失效策略等,文件權限嚴格限制,保障密碼安全
二、用戶組(Group)管理
- 核心定義:用戶組是用于集中組織用戶的機制,可將多個用戶納入同一組,實現權限的批量統一管控,一個用戶可同時屬于多個組
- 核心標識:GID(Group ID)是用戶組的唯一數字標識,用于區分不同用戶組
- 關鍵文件:組信息文件(/etc/group) 存儲系統所有用戶組信息,每行對應一個組,記錄組名、GID、組內成員列表等內容,便于快速查詢組與用戶的關聯關系
三、用戶與用戶組的關聯
/etc/passwd 中記錄用戶的主組 GID(每個用戶必須屬于且默認生效的組),而 /etc/group 中除了記錄組的基本信息,還通過成員列表記錄了屬于該組的所有用戶(包括以該組為主組的用戶,以及將該組作為附加組的用戶)。這種設計使得一個用戶既擁有唯一的主組,又可以加入多個附加組,同時一個組也能包含多個用戶,從而形成 “用戶 - 組” 的多對多關系
這種機制既通過用戶賬戶實現了個體身份的精準管理,又通過主組與附加組的靈活組合,實現了權限的批量分配與精細化管控 —— 用戶既繼承主組的基礎權限,又能通過附加組獲得額外權限,共同構成了 Linux 系統權限體系的基礎
whoami:查看當前有效用戶身份
sudo <具體命令>:臨時提權,以系統管理者的身份執行指令,執行完成后權限自動回收
passwd [用戶名]:修改指定用戶的密碼(不指定用戶名則修改當前用戶密碼)
su [用戶名]:切換到指定用戶,但保留當前環境變量(如當前目錄、PATH 等),不加用戶名默認切換 root 。若加 - 或 --login 則加載目標用戶的完整環境(如家目錄、Shell 配置等,接近重新登錄),切換用戶后執行 exit 或按 Ctrl+D 退回原用戶
用戶
useradd <用戶名>:創建新用戶
執行時,系統會默認完成:
- 在 /etc/passwd 中添加用戶記錄,包含自動分配的 UID、默認 GID(通常與 UID 相同)等信息
- 在 /etc/shadow 中創建密碼占位記錄(初始無密碼,需用 passwd 用戶名 手動設置后才能登錄)
- 在 /etc/group 中創建與用戶名同名的主組(GID 通常與 UID 一致)
- 若未指定,默認家目錄為 /home/用戶名(但需手動創建或用 -m 參數自動創建)
- 默認 Shell 為 /bin/sh 或 /bin/bash(依系統而定)
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -m | --create-home | 自動創建用戶家目錄(推薦使用) |
| -s <shell路徑> | --shell <shell路徑> | 指定默認 Shell |
| -g <組名/組GID> | --gid <組名/組GID> | 指定用戶主組(需預先存在) |
| -G <組1,組2…> | --groups <組1,組2...> | 指定附加組(多個組用逗號分隔) |
| -u <UID> | --uid <UID> | 手動指定 UID(需確保唯一) |
userdel <用戶名>:刪除用戶
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -r | --remove | 刪除用戶的同時,自動移除其家目錄(/home/用戶名) 及郵件緩存(通常在 /var/spool/mail/用戶名),避免殘留文件占用空間 |
| -f | --force | 強制刪除用戶,即使該用戶當前正處于登錄狀態(需謹慎使用, 可能導致文件權限混亂) |
id [用戶名/UID]:查看用戶信息(包含 uid、gid、groups)。不指定用戶時,默認展示當前登錄用戶的信息;指定用戶時,展示對應用戶的信息(需驗證操作權限)
在類 Unix 系統中,用戶信息通過以下字段體現權限與歸屬關系:
- uid=0(root)
- uid(用戶 ID):系統唯一的用戶數字標識,0 是超級用戶(root)的專屬 ID,括號中 root 為用戶名
- 特性:uid=0 的用戶擁有最高系統權限,可無限制操作所有文件、進程及系統資源
- gid=0(root)
- gid(組 ID):用戶所屬主組的唯一標識,此處表示 root 用戶的主組 ID 為 0,組名為 root
- 作用:每個用戶都有一個主組,用戶創建文件 / 目錄時,默認歸屬其主組,主組權限直接影響這些資源的訪問控制
- groups=0(root)
- groups:列出用戶所屬的所有組(含主組和附加組),這里表明 root 僅屬于 root 組,沒有附加組
- 擴展:實際場景中用戶可加入多個附加組(如 sudo、docker 組),從而獲得對應權限(如執行管理員命令、管理容器)
uid 唯一區分用戶身份,gid 定義主組歸屬,groups 擴展附加權限,三者共同構成類 Unix 系統的基礎權限管理體系
usermod [選項] <用戶名>:修改用戶信息
cat /etc/passwd :用于查看系統中所有用戶的基礎信息
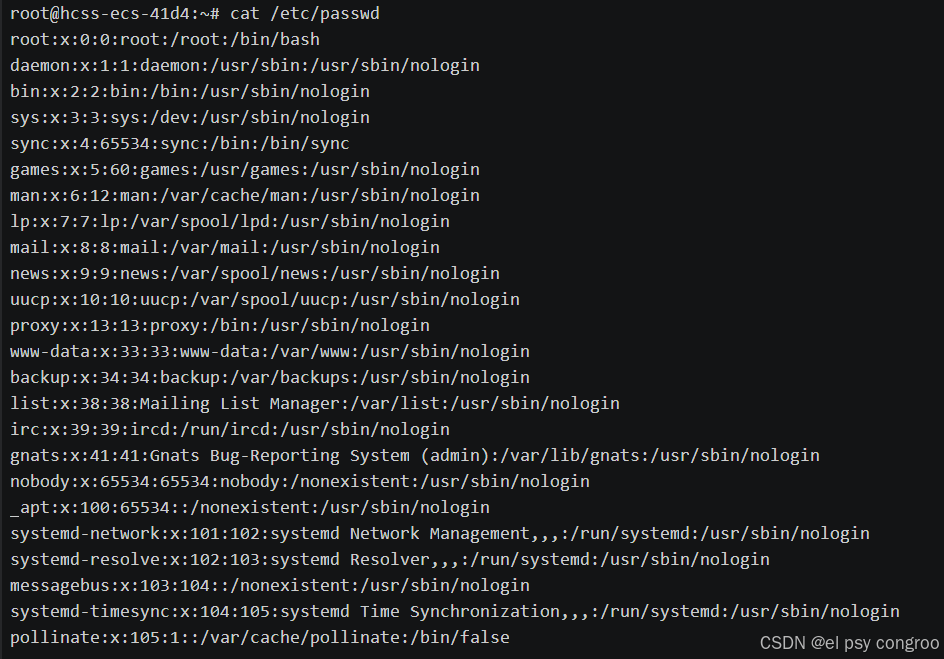
文件中每行對應一個用戶,以冒號 : 分隔為 7 個字段,格式為:
用戶名:密碼占位符:UID:GID:用戶描述:家目錄:默認Shell(命令解釋器)
- 密碼占位符:固定為 x,表示密碼存儲在 /etc/shadow 中
- 用戶描述:可選字段(如用戶全名),部分系統可能為空
- 默認 Shell:它是用戶與 Linux 操作系統進行交互的接口。用戶通過在終端中輸入命令,Shell 解釋并執行這些命令,并向用戶提供反饋
列出所有普通用戶(UID ≥ 1000):cat /etc/passwd | awk -F: '$3 >= 1000 {print $1}'
用戶組
groupadd [選項] <組名>:創建新用戶組,執行后會在 /etc/group 中添加一條新組記錄
groupdel [選項] <組名>:刪除用戶組
groups [用戶名]:若指定用戶則查看指定用戶所屬的用戶組(若不指定用戶名,則默認查看當前登錄用戶所屬的用戶組)
groupmod [選項] <組名>:修改用戶組信息
cat /etc/group:查看所有組
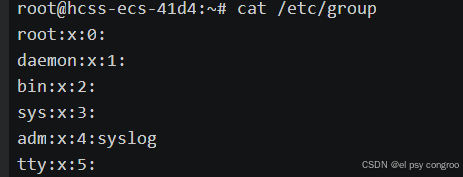
文件中每一行代表一個用戶組,以冒號 : 分隔為 4 個字段,格式為:
組名:密碼占位符:GID:附加用戶列表
- 組名:用戶組的名稱
- 密碼占位符:通常為x(表示密碼存儲在/etc/gshadow中),實際很少設置組密碼
- GID:組的唯一標識(如0對應root組,1000及以上多為普通用戶組)
- 附加用戶列表:以該組為附加組的用戶(用逗號分隔,主組用戶不會出現在這里)。可以為空,若字段為空則表示沒有用戶將此組作為附加組
文件/目錄操作與內容處理工具
vim/vi 工作模式
在 Linux 系統中,vi和vim都是文本編輯器,vim是vi的增強版本
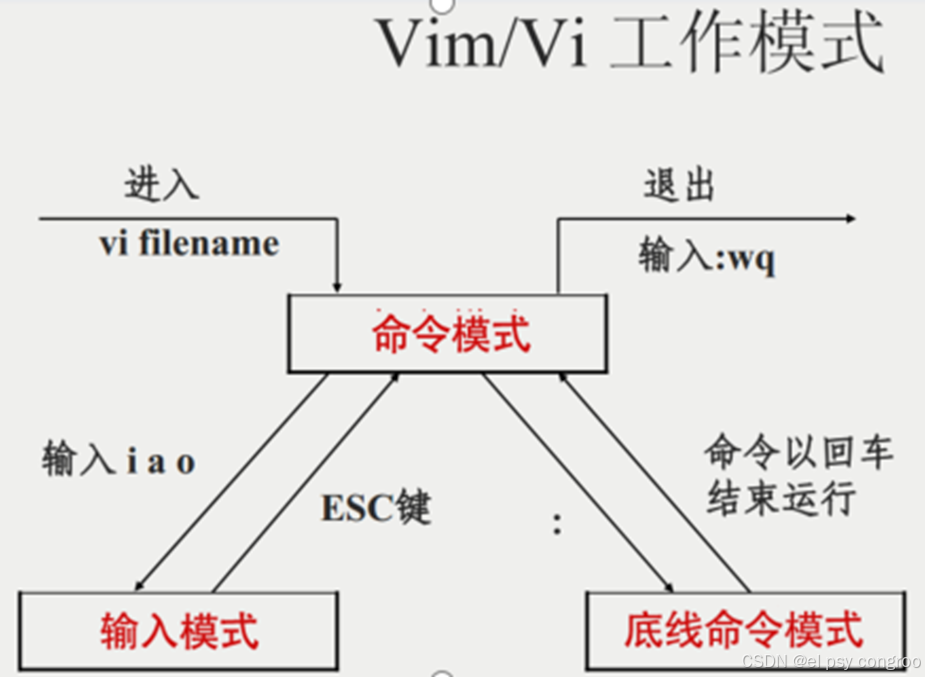
- 啟動與初始模式
vi/vim 路徑+文件名:
- 若文件存在 → 打開文件并進入命令模式(可瀏覽、移動光標、刪除內容、復制粘貼文本 )
- 若文件不存在 → 新建文件并進入命令模式(后續保存時會實際創建文件 )
在命令模式,可以通過特定的按鍵操作實現文本瀏覽與編輯,例如:
- 按 u 鍵撤銷上一次操作
- 移動光標:h 鍵向左、j 鍵向下、k 鍵向上、l(小寫的L) 鍵向右
- 刪除內容:x 鍵刪除光標所在字符,dd 刪除光標所在行
- 復制粘貼:yy 復制光標所在行,p 鍵將剪貼板內容粘貼到光標下方
該模式下,鍵盤輸入的字符會被識別為操作命令,而非直接插入文本的內容。若需輸入內容,需按下 i、a、o 等按鍵切換到輸入模式(左下角提示 --INSERT-- )
- 模式切換關系(命令模式是 “中轉站”)
- 命令模式按 i(在光標前插入)、a(在光標后插入)、o(在當前行的下方插入一個新行)其中一個→ 進入輸入模式
- 命令模式按
:→ 進入底線命令模式(可執行保存、退出、查找替換等復雜操作,命令顯示在底部狀態欄) - 輸入模式 / 底線命令模式 → 按 ESC 或者 執行完底線命令(按回車確認)→ 切回命令模式
(3)文件保存與退出(底線命令模式回車執行)
| 場景 | 命令 | 說明 |
|---|---|---|
| 保存文件(不退出) | :w | 寫入(write)修改到文件 |
| 文件未修改時退出 | :q | 直接退出(quit) |
| 文件修改后保存并退出 | :wq | 保存(write)+ 退出(quit) |
| 強制退出不保存 | :q! | 強制(!)退出,丟棄修改 |
| 強制保存并退出 | :wq! | 忽略文件的只讀屬性限制,強制保存修改并退出 (適用于文件本身設為只讀但用戶擁有寫入權限的場景) |
| 全文替換文本(示例) | :%s/old/new/g | 在整個文件(% 表示全文范圍)中,替換 old 為 new (g 表示全局替換,若無 g 則僅替換每行第一個匹配項) |
ls[選項][?錄/?件]
- 若指定目錄,則列出該目錄下的所有子目錄與文件(默認以平鋪方式顯示名稱,不含詳細信息)
- 若指定文件,則僅列出該文件名(默認不顯示額外信息,除非使用 -l 等選項)
- 若不指定目錄 / 文件,默認列出當前目錄下的內容
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -a | --all | 列出目錄下的所有文件和子目錄,包括以 . 開頭的隱藏文件 |
| -d | --directory | 將目錄本身當作文件顯示其信息,而非列出該目錄下的內容 |
| -k | --block-size=1K | 以 KB(千字節)為單位顯示文件大小(1K = 1024 字節) |
| -l | --format=long,通常簡化為 --long | 以長格式顯示詳細元信息,包括權限、所有者、所屬組、大小等 |
| -h | --human-readable | 以人類可讀格式顯示文件大小 |
| -r | --reverse | 對排序結果進行反向顯示 |
| -t | --sort=time | 加上按文件的修改時間排序(最新在前),默認按名稱排序 |
| -R | --recursive | 遞歸列出所有子目錄中的內容 |
| -S | --sort=size | 按文件大小從大到小排序(結合 -r 可改為從小到大) |
ls -l 與 ll
ls -l 是 ls 命令的標準選項組合,-l 表示以長格式顯示文件的詳細元信息,它是 Linux 和 macOS 系統的內置命令,所有用戶都可以直接使用

ll 并非系統原生命令,而是ls命令的別名(alias),其具體行為取決于系統默認配置或用戶自定義設置,不同環境下可能存在差異:
- 在 Ubuntu、Debian 等基于 Debian 的 Linux 發行版中,往往會將 ll 定義為 ls -alF , 這意味著執行 ll 時,會以列表形式展示包括隱藏文件(.開頭)在內的所有文件,并在文件名后添加類型標識(如 /表示目錄、*表示可執行文件)。不過部分精簡版系統或新用戶環境可能未預設該別名
- 而在 macOS 系統中,默認的 bash 或 zsh 配置里通常沒有 ll 別名,直接輸入會提示命令不存在,需要用戶手動在配置文件中添加定義(例如alias ll=‘ls -l’)才能使用
- 其他系統中也可能有不同設定,比如部分 RedHat、CentOS 版本默認將 ll 指向 ls -l(僅顯示非隱藏文件的詳細列表)
若想確認當前環境中 ll 的具體定義,可在終端執行alias ll查看
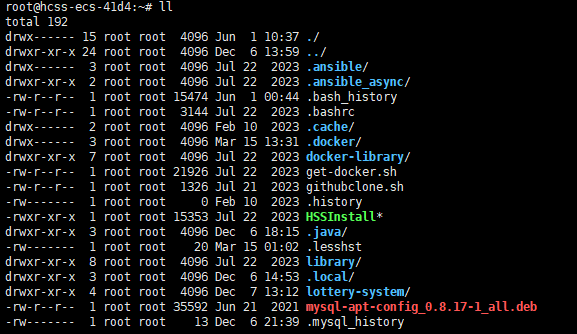
各列從左到右依次為:類型與權限、硬鏈接數、所有者、所屬組、大小、修改時間、名稱 ,下面逐個拆解
- 類型與權限(第 1 列):由 10 個字符組成
第 1 位字符表示文件類型,常見值及含義:
| 標識 | 含義 | 通俗類比 / 典型示例 |
|---|---|---|
| d | 目錄(Directory) | 類似 Windows 的 “文件夾” |
| - | 普通文件 | 文本文件(.txt)、二進制程序(.exe) |
| l | 軟鏈接(Symbolic Link) | Windows 的 “快捷方式”,指向其他文件 / 目錄 |
| b | 塊設備(Block Device) | 硬盤、U 盤 |
| c | 字符設備(Character Device) | 鍵盤、串口 |
| s | 套接字(Socket) | 網絡通信的 “端口”(如進程間通信端點) |
| p | 管道(Pipe) | 臨時 “數據通道”(如 mkfifo 創建的管道) |
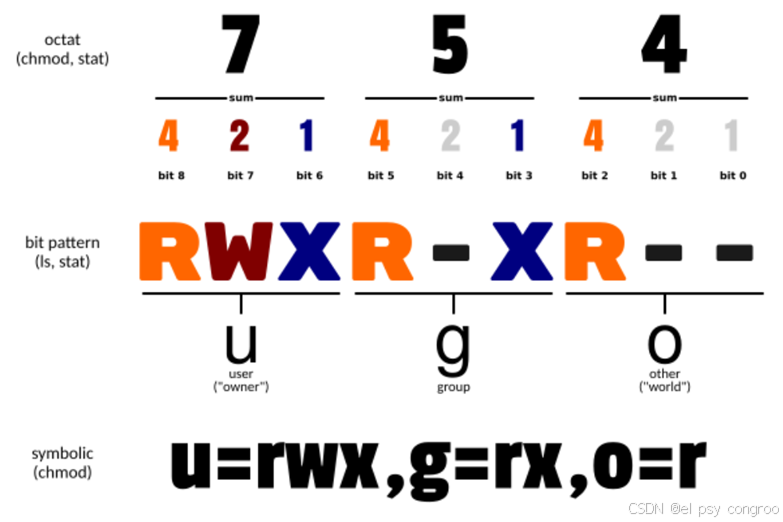
第 2 - 10 位:文件權限分為所有者(u)、所屬組(g)、其他用戶(o)三組,每組包含讀(r,權重 4,可查看文件內容或列出目錄文件)、寫(w,權重 2,可修改文件內容或在目錄中創建 / 刪除文件)、執行(x,權重 1,可運行程序或進入目錄)三個權限位,無對應權限則用 “-” 占位。比如 rwxr-xr-x 表示:
- 文件擁有者權限(u):rwx ,擁有讀、寫、執行權限
- 文件所屬組用戶權限(g):r-x ,擁有讀、執行權限,無寫權限
- 其他用戶權限(o):r-x ,同樣讀、執行權限,無寫權限
權限位的數字表示
| 權限組合 | 二進制 | 數字(4+2+1) | 含義解析 |
|---|---|---|---|
| --- | 000 | 0 | 無任何權限 |
| --x | 001 | 1 | 僅執行權限 |
| -w- | 010 | 2 | 僅寫權限 |
| -wx | 011 | 3 | 寫和執行權限 |
| r– | 100 | 4 | 僅讀權限 |
| r-x | 101 | 5 | 讀和執行權限 |
| rw- | 110 | 6 | 讀和寫權限 |
| rwx | 111 | 7 | 讀、寫、執行全權限 |
當需要表示所有者、所屬組、其他用戶的完整權限時,只需將每組對應的數字按順序拼接即可,例如:
- 所有者有 rwx(7)、所屬組有 r-x(5)、其他用戶有 r-x(5),組合起來就是 755
- 所有者有 rw-(6)、所屬組有 r--(4)、其他用戶有 ---(0),組合起來就是 640
權限修改命令:
- chmod (文件權限管理):
chmod <數字權限> <文件/目錄名>(數字形式,簡潔高效):用三位數字(0-7)分別表示 u、g、o 的權限,每位數字由 r(4)、w(2)、x(1) 相加得到chmod <用戶組><操作符><權限> <文件/目錄名>(符號形式,直觀靈活):通過符號精確調整權限
| 操作符 | 說明 |
|---|---|
| + | 添加權限 |
| - | 移除權限 |
| = | 設置權限(覆蓋原有權限) |
示例:
# 權限字符串:rwxr-xr-x
# 含義:所有者有全權限,其他用戶可讀可執行(不可寫)
# 適用:可執行腳本、程序、公共目錄(允許他人運行或進入)
chmod 755 script.sh含義:給所有者添加執行權限(不影響已有權限)
場景:剛下載的程序需要運行時
chmod u+x app含義:移除所屬組的寫權限,同時移除其他用戶的讀權限
場景:限制組內成員修改重要文件,同時禁止外部用戶查看
chmod g-w,o-r file.txt含義:給所有用戶(u/g/o)設置讀和寫權限(覆蓋原有權限)
場景:臨時共享文件,允許所有人編輯
chmod a=rw shared.doc含義:所有者全權限,所屬組可讀可進入,其他用戶無權限
對應數字形式:chmod 750 data/
場景:部門內部共享數據,拒絕外部訪問
chmod u=rwx,g=rx,o=- data/含義:遞歸給所屬組添加寫權限(包括目錄內所有文件)
場景:團隊協作時,允許組內成員修改項目所有文件
chmod -R g+w project/
chown [用戶名][:組名] <文件名>:修改文件 / 目錄的所有者(用戶)和所屬組(用戶組)
- 硬鏈接數(第 2 列):表示有多少個硬鏈接指向該文件或目錄 。對于目錄,硬鏈接數計算包含自身、父目錄對它的鏈接以及其他目錄通過硬鏈接關聯它的數量;對于普通文件,就是有多少個硬鏈接指向該文件實體
- 所有者(第 3 列):該文件或目錄的所有者用戶
- 所屬組(第 4 列):該文件或目錄所屬的用戶組
- 大小(第 5 列):文件或目錄占用的磁盤空間大小 ,單位默認是字節。對于目錄,顯示的是目錄本身元數據等占用的空間(目錄實際包含文件總大小得用 du 等命令看 ),4096 字節是 Linux 系統里目錄常見的基礎塊大小;對于普通文件,就是文件內容實際占用字節數
- 修改時間(第 6 - 8 列):文件或目錄的最后一次修改時間(修改文件內容權限、目錄內增刪文件 / 目錄等操作會更新此時間 ),包含月份、日期、具體時間點
- 名稱(第 9 列):文件或目錄的名稱 ,以 . 開頭的是隱藏文件 / 目錄
pwd:是 Print Working Directory 的縮寫,顯示當前所在目錄的絕對路徑
cd <目錄路徑>:切換工作目錄。將當前工作目錄改到指定的目錄下,cd 命令后面既可以跟絕對路徑,也可以跟相對路徑
cd ~/cd:快速回到用戶主目錄cd ..:回到上一級目錄cd -:切換回上一次工作目錄
mkdir [選項] <目錄路徑>:創建目錄(文件夾),mkdir 命令支持同時創建多個目錄
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -p | --parents | 遞歸創建目錄,當需要創建多級目錄且父目錄不存在時非常實用 |
| -m <權限模式> | --mode=<權限模式> | 創建目錄時指定權限(如 -m 755 表示設置權限為 rwxr-xr-x) |
touch [選項] <文件路徑>:創建新的空文件,也可以用于修改文件的訪問時間和修改時間,touch 命令支持同時操作多個文件
cat [選項] :查看文件,也可以用于創建簡單的文件或合并文件內容
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -n | --number | 對輸出的所有行編號(包括空行) |
| -b | --number-nonblank | 僅對非空行編號,優先級比 -n 高 |
tail [選項] <文件路徑>:查看文件的末尾內容,默認顯示文件最后 10 行,常用于實時監控日志文件等場景
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -f | --follow | 實時追蹤文件新增內容,按 Ctrl+C 退出 |
| -n <行數> 或 -<行數> | --lines=<行數> | 指定顯示文件末尾的行數 |
| -c <字節數> | --bytes=<字節數> | 以字節為單位顯示文件末尾內容 |
特殊用法
- 若要從文件的某一行開始顯示(而非末尾),可結合 + :
# 從第100行開始顯示到文件末尾
tail -n +100 document.txt
- 通過管道符可以截取其他命令輸出的末尾內容
# 查看目錄下最后5個文件/目錄的詳細信息
ls -l | tail -n 5
# 查找包含"error"的行,并只顯示最后3行
cat large_file.txt | grep "error" | tail -n 3
除此之外還有:
- head:查看文件的開頭部分內容,默認顯示文件前 10 行
- more :以分頁方式查看文件內容,適合查看較長的文件(支持逐頁滾動)
- less:高級分頁查看工具,功能比 more 更強大,支持自由滾動和搜索
rmdir [選項] <目錄路徑>:用于刪除空目錄(目錄內必須無任何文件或子目錄)
最常用的選項是 -p(或 --parents),用于遞歸刪除空目錄鏈(即當父目錄也為空時,一并刪除)
示例:
# 若 a/b/c 是一個空目錄,且 b 和 a 也為空,會依次刪除 c、b、a 三個空目錄
rmdir -p a/b/c
rm [選項] <目錄/文件>:刪除文件或目錄,使用 rm 刪除目錄時,必須使用 -r 或 --recursive,由于刪除操作不可逆,使用時需特別謹慎,尤其是針對重要文件或系統目錄
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -r | --recursive | 遞歸刪除目錄及其所有內容(包括子目錄、文件) |
| -f | --force | 強制刪除(即使文件屬性為只讀),忽略不存在的文件,不提示確認 |
| -i | --interactive | 刪除前逐一提示確認(加上此選項可強制所有刪除都提示,避免誤操作) |
cp [選項] <源文件/目錄> <目標文件/目錄>:復制文件或目錄到指定的目標位置
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -r | --recursive | 遞歸復制目錄(包括目錄內的所有文件和子目錄),復制目錄必須使用此選項 |
| -f | --force | 忽略文件的只讀屬性并強制覆蓋,而不是 “開啟覆蓋功能”,覆蓋功能本就存在 |
| -i | --interactive | 目標文件存在時提示確認(避免誤覆蓋,優先于 -f) |
cp 命令復制時,多源文件 / 目錄需以已存在目錄為目標才會全部復制過去,否則報錯;單源時,若目標是已存在文件則直接覆蓋(除非用 -i 選項),是目錄則復制到其下
mv [選項] <源文件/目錄> <目標文件/目錄>:移動或重命名文件 / 目錄,操作具有原子性(要么完全成功,要么完全失敗)
常用選項:
| 選項 | 對應長選項 | 功能說明 |
|---|---|---|
| -f | --force | 強制操作,若目標文件已存在則直接覆蓋,不提示 |
| -i | --interactive | 若目標文件已存在,移動 / 重命名前提示確認(避免誤覆蓋) |
| -n | --no-clobber | 若目標文件已存在,則不執行移動 / 重命名操作,也不提示(防止意外覆蓋文件) |
說明:mv命令可直接操作目錄(無需像cp那樣加-r),當目標是已存在的文件時,若源是文件則覆蓋(除非用-i或-n選項),若源是目錄則報錯;當目標是已存在的目錄時,單個源文件或源目錄會被移入該目錄,多個源文件或源目錄(可混合)也會被移入該目錄;當目標不存在時,源文件或源目錄會被重命名為目標路徑
find [查找路徑] [匹配條件] [處理動作]:是強大的文件查找工具,能按多種條件精準定位文件或目錄
# 列出 /etc 目錄下包含 "localhost" 的文件
find /etc -type f | xargs grep "localhost"# 查找 /var 下 7 天內修改、大小大于 100MB、屬主為 root 的 log 文件
find /var -type f -name "*.log" -mtime -7 -size +100M -user root
Linux系統防火墻
一、介紹
防火墻通過管理員設定的規則控制數據包進出,核心作用是保護內網安全,默認狀態為關閉。目前 Linux 系統主流防火墻為 iptables(靜態)和 firewalld(動態)
| iptables(靜態防火墻) | firewalld(動態防火墻) | |
|---|---|---|
| 適用場景 | 早期 Linux 系統默認使用,部分老舊系統仍在使用 | 取代 iptables 成為主流,現代 Linux 系統常用 |
| 工作層級 | 主要工作在網絡層 | 主要工作在網絡層 |
| 配置方式 | 僅支持命令行配置,配置文件為 /etc/sysconfig/iptables | 支持命令行和圖形化界面配置,配置文件位于 /usr/lib/firewalld 和 /etc/firewalld |
| 默認規則 | 默認允許所有數據包,需通過 “拒絕” 策略限制 | 默認拒絕所有數據包,需通過 “允許” 策略放行 |
| 規則生效 | 修改規則后需全部刷新才能生效,會導致現有連接丟失(無守護進程) | 支持動態修改單條規則,更新時不破壞現有會話和連接(支持守護進程) |
| 過濾范圍 | 只能過濾互聯網的數據包,無法過濾內網到內網的數據包 | 新增區域概念,不僅可以過濾互聯網的數據包,也可以過濾內網的數據包 |
常用管理命令
| 操作 | firewalld 命令 | iptables 命令 |
|---|---|---|
| 查看狀態 | sudo systemctl status firewalld | sudo systemctl status iptables |
| 安裝(RPM 系統) | sudo yum install firewalld | sudo yum install iptables |
| 安裝(Debian 系統) | sudo apt install firewalld | sudo apt install iptables |
| 啟動服務 | sudo systemctl start firewalld | sudo systemctl start iptables |
| 關閉服務 | sudo systemctl stop firewalld | sudo systemctl stop iptables |
| 開機自啟 | sudo systemctl enable firewalld | sudo systemctl enable iptables |
| 禁止開機自啟 | sudo systemctl disable firewalld | sudo systemctl disable iptables |
總結
iptables 是靜態防火墻,依賴全量刷新規則,適合簡單場景;firewalld 作為動態防火墻,支持規則實時更新和多配置方式,更適應現代系統的靈活需求。兩者均工作在網絡層,核心差異在于規則管理的動態性和配置便捷性
Shell 腳本與實踐
Shell 是一個用 C 語言編寫的應用程序,它為用戶提供了操作 Linux 內核服務的界面,是用戶與 Linux 系統交互的橋梁
Shell 腳本(shell script)則是為 Shell 編寫的腳本程序,類似 Windows 的批處理文件,主要用于便捷地批量處理多種操作。作為內置腳本,它語法簡單、易學易用,開發效率高,能依賴強大的命令快速完成批處理任務
Linux 系統中有多種 Shell 類型,常見的包括:
- Bourne Shell(路徑通常為 /usr/bin/sh 或 /bin/sh)
- Bourne Again Shell(即 bash,路徑為 /bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
其中,bash 因易用性和免費特性被廣泛使用,是大多數 Linux 系統的默認 Shell
示例
創建文件,注意后綴是sh
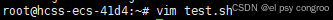
輸入:
#! /bin/bash
echo "hello world"
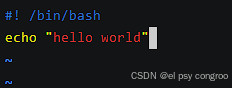
- #! /bin/bash:指定腳本使用的解釋器是Bash
- echo “hello world”:打印 hello world 到終端
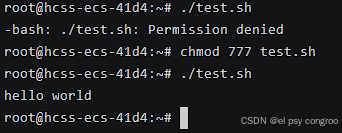
如果沒權限的話加上權限
搭建 Java 部署環境
apt(Debian/Ubuntu 系的包管理利器)介紹
apt(Advanced Packaging Tool)是 Ubuntu、Debian 及衍生發行版中管理 .deb 格式軟件包的工具,可實現安裝、更新、卸載等全生命周期管理,多數操作需 sudo 權限,其工作基于可用軟件包的數據庫,因此安裝 Linux 系統后應首先更新該數據庫,否則系統無法知曉是否有更新的軟件包可用
一、核心配置:鏡像源
鏡像源是指在不同地區或網絡環境中,通過復制并同步主服務器的軟件包與數據而搭建的服務器。其核心作用是為用戶提供本地化的資源訪問節點,從而大幅提升軟件下載與安裝速度,優化用戶體驗。而軟件包的具體下載來源,通常由系統或軟件管理工具中的鏡像源列表進行管控 —— 用戶可根據自身網絡狀況、地理位置等因素,在列表中配置合適的鏡像源,系統會據此優先從指定節點獲取資源
配置文件為:
vim /etc/apt/sources.list # 編輯鏡像源(需 root 權限)
鏡像源決定了軟件包的下載速度和可用性,國內常用阿里、清華等鏡像源
二、常用命令速查表
| 命令 | 說明 |
|---|---|
| sudo apt update | 更新軟件包數據庫,獲取最新可用版本信息(僅更新列表,不升級軟件) |
| sudo apt upgrade | 升級所有已安裝軟件包(保留配置文件) |
| sudo apt install <包名> | 安裝指定軟件,自動處理依賴關系;可同時安裝多個包(空格分隔) |
| sudo apt remove <包名> | 刪除軟件二進制文件,保留配置文件(便于后續重新安裝) |
| sudo apt purge <包名> | 徹底卸載軟件及所有配置文件(適合完全清理) |
| apt list --installed | 顯示系統中所有已安裝的軟件包 |
| apt list | grep <關鍵詞> | 搜索包含關鍵詞的軟件包(避免直接用 apt list 因數量過多導致卡頓) |
| apt list --all-versions <包名> | 查看指定軟件包的所有可用版本及當前安裝狀態 |
| apt search <關鍵詞> | 搜索包含關鍵詞的軟件包(比 apt list | grep 更高效) |
| apt show <包名> | 顯示軟件包的詳細信息(版本、依賴、描述等) |
三、關鍵細節與注意事項
- remove 與 purge 的選擇:
- 常規卸載用 remove(保留配置,如需重新安裝可復用配置)
- 需徹底清除痕跡(如配置錯亂后)用 purge
- apt 是 apt-get 的優化升級版本,核心功能一致(均管理 .deb 包),但 apt 更簡潔直觀適合日常使用,apt-get 輸出穩定適合腳本或特殊場景
安裝 JDK
- 更新軟件包
sudo apt update
- 安裝 openjdk
# 搜索包含"jdk"關鍵詞的軟件包列表(jdk是Java開發工具包的縮寫)
apt list | grep "jdk"# 安裝 openjdk-17-jdk 軟件包(OpenJDK 17版本的Java開發工具包)
sudo apt install openjdk-17-jdk
注意:此處安裝的 OpenJDK 是一個開源版本的 JDK,和 Oracle 官方的 JDK 略有差別。此處我們就使用 OpenJDK 即可,安裝 Oracle JDK 比較麻煩
使用 java -version 命令驗證是否安裝成功,如果提示 “java 命令找不到” 則說明安裝失敗
卸載 OpenJDK
# 檢查已安裝的 OpenJDK 包
dpkg --list | grep -i jdk# 卸載 OpenJDK 相關包
sudo apt-get purge icedtea-* openjdk-* # icedtea 是 OpenJDK 的相關組件(如瀏覽器插件),可一并卸載# 清理殘留依賴
sudo apt-get autoremove # 自動移除不再需要的依賴
sudo apt-get autoclean # 清理緩存的過時包文件# 驗證卸載結果
dpkg --list | grep -i jdk
安裝 MySQL
- 使用 apt 安裝 MySQL
# 查找安裝包
apt list |grep "mysql-server"# 安裝 mysql
sudo apt install mysql-server
- 查看 MySQL 狀態
sudo systemctl status mysql
- MySQL 安全設置
默認的 MySQL 設置是不安全的,MySQL 提供了一個安全腳本,運行以下命令:
sudo mysql_secure_installation
腳本會依次彈出以下問題(根據實際環境選擇,建議按安全最佳實踐配置):
Press y|Y for Yes, any other key for No: y# 這是 MySQL 安全配置中設置密碼驗證策略強度的交互提示,需要輸入數字選擇強度:
# 輸入 0 對應 LOW(低強度,僅檢查長度)
# 輸入 1 對應 MEDIUM(中等強度,默認推薦,檢查長度、數字、大小寫、特殊字符)
# 輸入 2 對應 STRONG(高強度,在中等基礎上增加字典檢查)
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 2# 移除匿名用戶? 選 y
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y# 禁止 root 遠程登錄? 生產環境選 y
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y# 移除 test 數據庫? 選 y
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y# 刷新權限讓配置生效? 選 y
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
- 設置密碼
連接mysql服務器,由于沒有設置密碼,不用輸密碼直接就能進入
使用 alter user 命令修改密碼
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密碼';
如果要退出 MySQL 的話可以 ctrl+d 或者輸入 exit/quit 回車
要連接 MySQL 可以輸入mysql -u用戶名 -p
- -u后面緊跟用戶名
- 執行后,系統會提示 Enter password: ,在這后面輸入密碼(輸入的值是不顯示的)
還有一種連接方式:mysql -u用戶名 -p密碼,密碼(如果有特殊符號建議用單引號包裹)緊跟在 -p 后面,無空格。這種寫法會將密碼明文暴露在命令歷史或日志中,存在安全風險
卸載 mysql
# 停止 MySQL 服務
# 說明:卸載前必須先停止服務,避免文件被占用導致卸載失敗或殘留
sudo systemctl stop mysql# 徹底卸載 MySQL 核心組件
# 包含服務器端(mysql-server)、客戶端(mysql-client)和通用組件(mysql-common)
sudo apt-get purge mysql-server mysql-client mysql-common# 刪除殘留的配置文件和數據目錄
# 說明:這些目錄不會被 apt 自動清理,包含數據庫文件、日志和自定義配置
# /etc/mysql:全局配置文件目錄;/var/lib/mysql:實際數據存儲目錄
sudo rm -rf /etc/mysql /var/lib/mysql# 清理不再需要的依賴和緩存文件
# autoremove:移除因安裝 MySQL 而自動安裝的、現在無用的依賴包
# autoclean:清理本地緩存中已過時的 .deb 安裝包,釋放磁盤空間
sudo apt-get autoremove
sudo apt-get autoclean# 驗證 MySQL 是否完全卸載
mysql --version
部署 Web 項目到 Linux
程序開發與發布涉及三類核心環境,各自承擔不同職能:
- 開發環境:專供開發人員編寫、調試代碼的機器環境,是程序誕生的 “初稿階段”
- 測試環境:供測試人員對開發完成的程序進行功能、性能等多維度測試的機器環境,用于排查問題、完善程序,相當于 “審核階段”
- 生產環境(線上環境):最終發布項目時所使用的機器環境,直接面向外網用戶,對穩定性要求極高,是程序的 “正式上線階段”
而將程序安裝到生產環境的過程,被稱為 “部署”(也叫 “上線”)。這一步至關重要:部署成功后,程序即可被萬千普通用戶訪問;若程序存在 BUG,用戶會直接接觸到;一旦部署過程出現問題,甚至可能引發服務器不可用等嚴重事故
為降低部署風險,企業通常會采用 Jenkins 等自動化部署工具,但本文先通過手工部署的方式實踐這一過程
環境配置
一、環境基礎準備:數據結構一致性
程序運行依賴的數據庫表結構需在各環境(開發、測試、生產等)保持一致。操作方式:
- 復用統一的數據庫建表腳本(如 SQL 文件),在目標服務器的數據庫中執行
- 執行前建議通過版本控制工具(如 Git)確認腳本為最新穩定版,避免因表結構差異導致程序報錯
- 執行后驗證表結構完整性(如字段類型、約束、索引等),確保與開發環境完全一致
二、多環境配置管理:區分差異,統一規范
不同環境(開發 dev、測試 test、生產 prod 等)的依賴配置(如數據庫賬號密碼、服務地址、端口等)存在差異,建議通過「環境隔離的不同配置文件」管理,避免手動修改導致的錯誤
配置文件命名規范
采用「主配置文件 + 環境特定配置文件」 分離,配合動態激活機制,實現配置的安全、高效管理,命名格式固定為:
| 配置文件類型 | 命名格式 | 作用 |
|---|---|---|
| 主配置文件 | application.yml 或者 application.properties | 存放通用的配置(如應用名稱、日志格式等),可指定默認激活的環境 |
| 環境特定配置文件 | application-XXX.yml 或者 application-XXX.properties (XXX 為環境標識,如 dev、test、prod) | 存放當前環境獨有的配置(如數據庫連接信息),僅在該環境激活時生效 |
下面以 application-XXX.yml 為例
- 主配置文件(application.yml):定義公共配置和默認激活環境,例如:
spring:application:name: mybatis-test # 應用名稱,自定義(建議小寫,用橫線分隔)profiles:active: dev # 默認激活開發環境(可被運行時參數覆蓋)
- 環境特定配置文件:僅存放當前環境的差異配置,例如數據庫信息:
開發環境(application-dev.yml)對應配置:
# 數據庫連接配置
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/dev_db?characterEncoding=utf8&useSSL=false # 開發環境數據庫地址username: dev_user # 開發環境賬號password: dev_pwd # 開發環境密碼driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:# 配置 mybatis xml的?件路徑,在resources/mapper創建表的 xml ?件mapper-locations: classpath:mapper/**Mapper.xmlconfiguration:# 開啟 MyBatis 的日志打印功能并輸出到控制臺log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
生產環境(application-prod.yml)對應配置,不用加上 MyBatis 日志打印:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/prod_db?characterEncoding=utf8&useSSL=false # 生產環境數據庫地址username: prod_user # 生產環境賬號password: prod_pwd # 生產環境密碼driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:mapper-locations: classpath:mapper/**Mapper.xml
環境激活方式
環境激活的核心是指定 Spring 加載對應環境的配置文件,其實現方式可歸納為四類,優先級從低到高依次為:主配置文件默認指定、命令行參數、環境變量、JVM 系統屬性。其中,后三類屬于運行時參數,是動態切換環境的關鍵
一、四類環境指定方式
-
主配置文件默認指定,在 application.yml 中通過 spring.profiles.active: XXX 設置默認環境
- 作用:本地開發時無需額外配置,直接啟動即可加載預設的環境配置
- 局限性:優先級最低,若通過其他方式指定環境,會被覆蓋
-
命令行參數:啟動時通過 --spring.profiles.active=XXX 傳入參數(如 java -jar app.jar --spring.profiles.active=prod)。優先級高于主配置文件,無需修改配置文件,直接通過啟動命令指定環境,適合臨時切換場景
-
環境變量:系統中設置 SPRING_PROFILES_ACTIVE=XXX 環境變量(如 Linux 中 export SPRING_PROFILES_ACTIVE=test)。優先級高于命令行參數,適用于固定環境的部署場景(如測試服務器默認激活測試環境),避免每次啟動手動輸入參數
-
JVM 系統屬性:啟動時通過 -Dspring.profiles.active=XXX 定義 JVM 參數(如 java -Dspring.profiles.active=dev -jar app.jar)。靈活性極強,可在不修改代碼或配置的情況下,快速適配開發、測試、生產等多場景
二、打包與運行階段的處理邏輯
- 打包階段:Maven/Gradle 會打包代碼、src/main/resources/ 下的所有配置文件(包括主配置文件以及各環境特定配置文件),同時打包依賴庫。注意:命令行參數、環境變量、JVM 系統屬性 這三類參數不參與打包,僅為運行時參數
- 運行階段:啟動時,JVM 或 Spring 框架按優先級(從低到高:主配置文件默認值 → 命令行參數 → 環境變量 → JVM 系統屬性)解析環境指定參數,選擇最高優先級的參數值(如 test),加載對應的環境特定配置文件( application-test.yml),并與主配置文件(application.yml)中的通用配置合并后生效
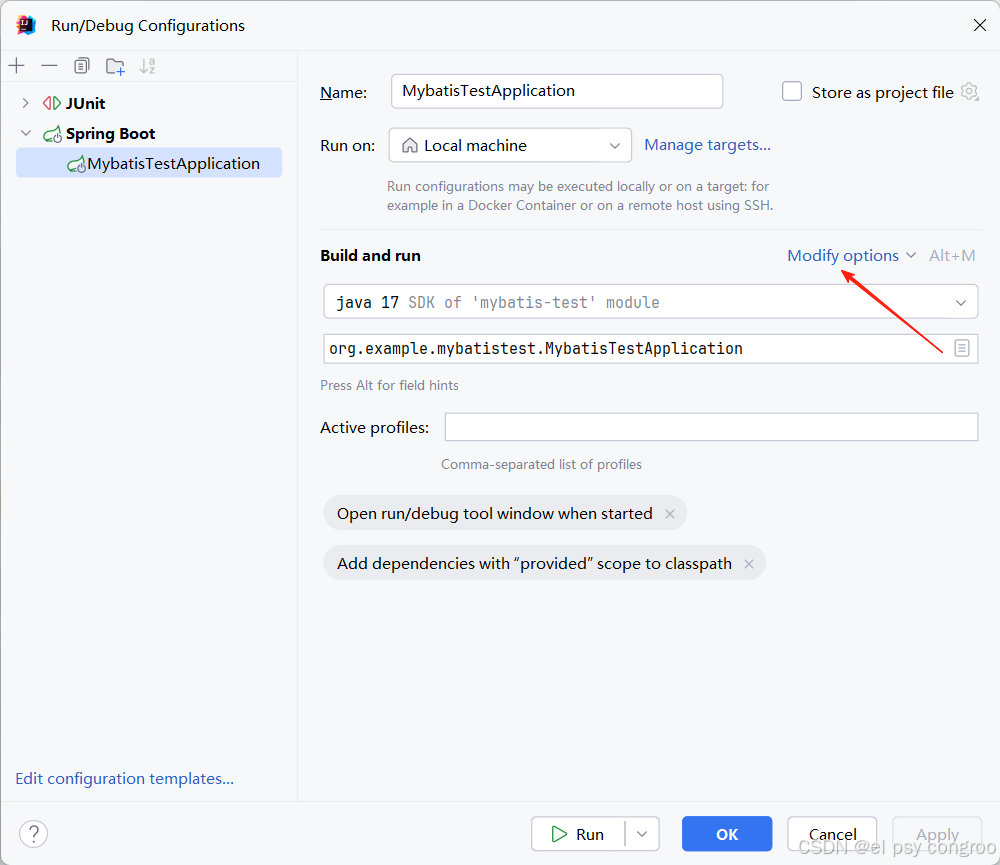
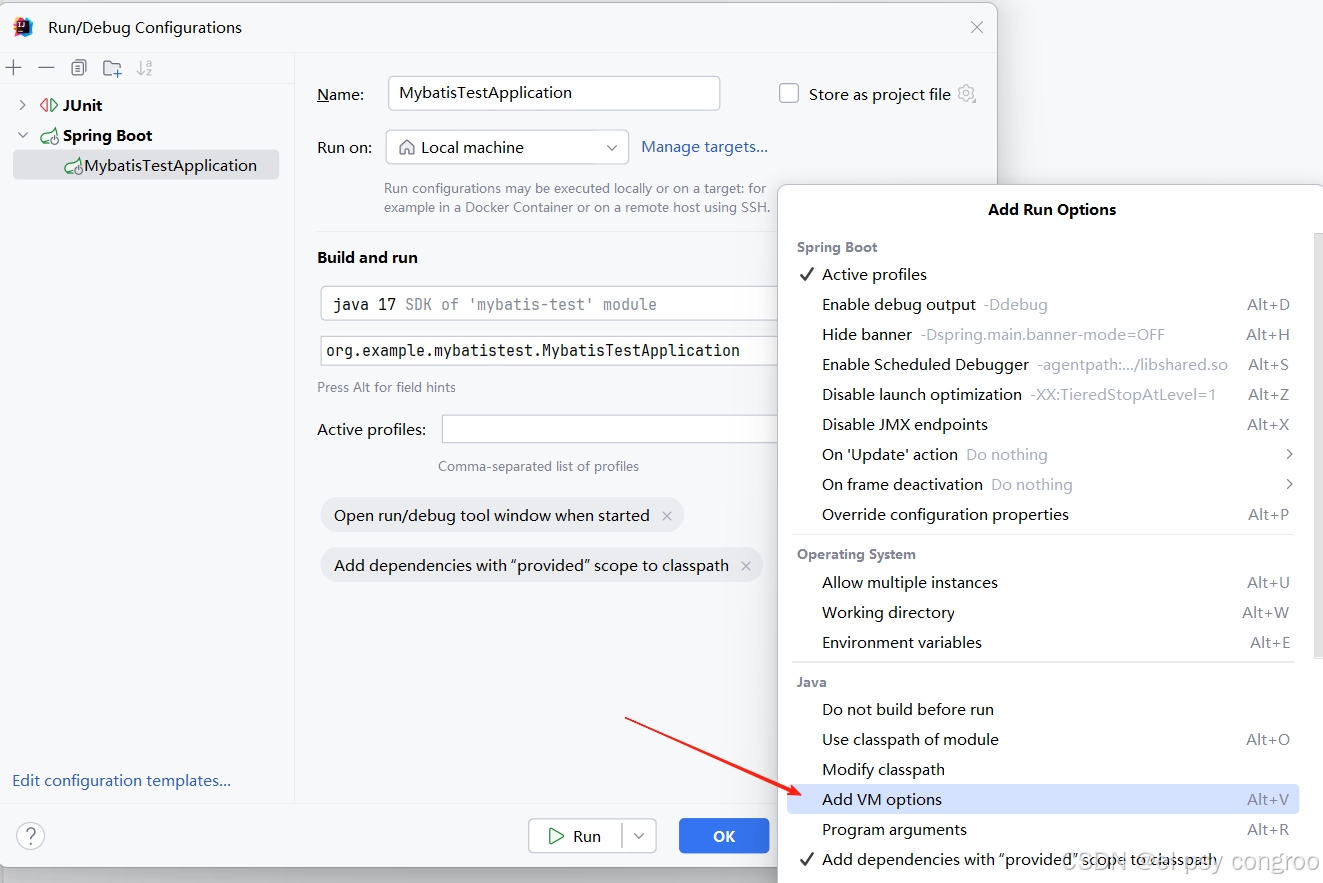
實操技巧: 本地開發(IDE 配置)
主配置文件就指定生產環境的配置文件方便打包部署,而在 IDEA/Eclipse 的 “運行配置” 中添加 JVM 參數 -Dspring.profiles.active=dev,這樣啟動即加載開發環境
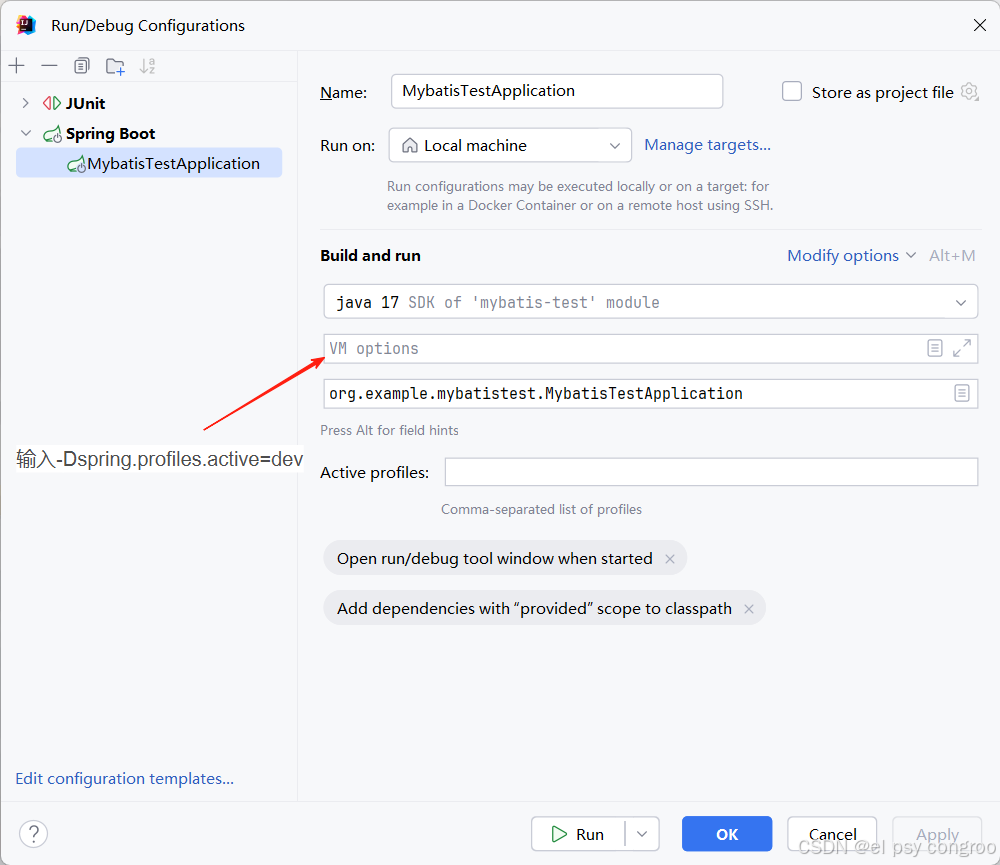
還可以使用 Maven 指定哪個配置文件:
<profiles><profile><id>dev</id><properties><profile.name>dev</profile.name></properties></profile><profile><id>test</id><properties><profile.name>test</profile.name></properties></profile><profile><id>prod</id><properties><profile.name>prod</profile.name></properties></profile></profiles>
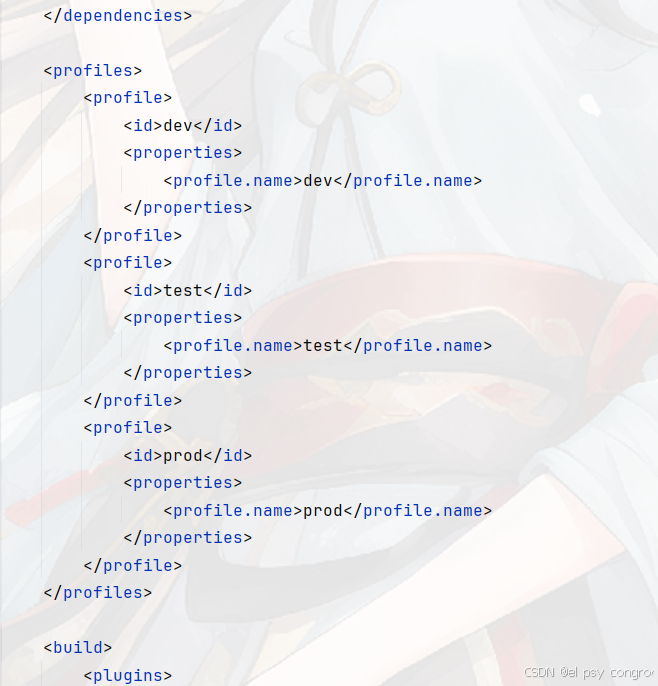
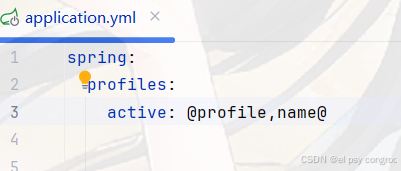
主配置文件改成這樣:
spring:profiles:active: @profile,name@
刷新 Maven ,Profiles 里面會多出這三個
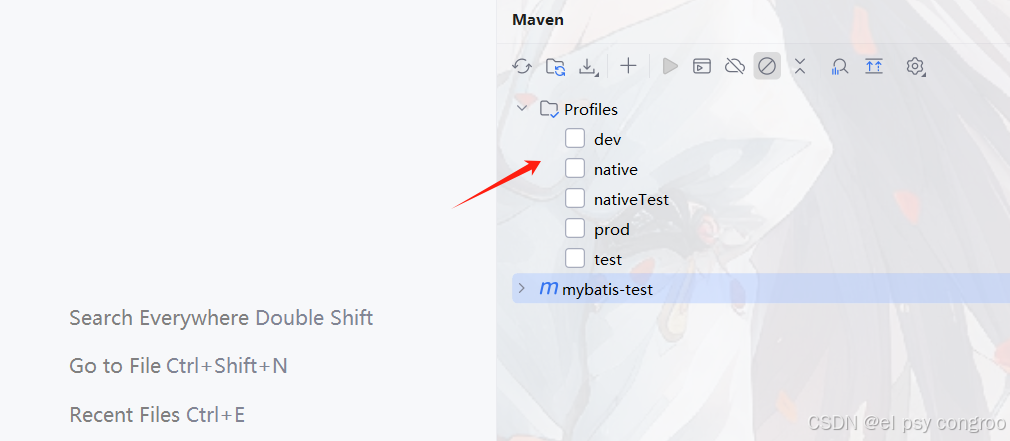
用哪個勾上哪個就行了,勾完記得刷新,還可以配置dev為默認的環境
<profile><id>dev</id><activation><activeByDefault>true</activeByDefault></activation><properties><profile.name>dev</profile.name></properties></profile>
構建項目并打包(使用 Maven )
在使用 Maven 構建 Spring Boot 項目時(如執行 package 命令打包),Maven 默認會先執行項目中的測試代碼(如 JUnit 測試用例),再進入打包階段。打包過程中,我們常常需要跳過測試階段,原因如下:
- 若測試代碼涉及數據庫連接、遠程服務調用等環境相關操作,例如測試用例要連接數據庫,但打包用的是生產環境的配置,就可能導致數據庫賬號密碼錯誤,從而導致測試失敗,中斷打包流程。此時跳過測試可避免因環境問題阻塞打包
- 節省構建時間。當項目規模較大、測試用例繁多時,運行全部測試可能耗時數分鐘甚至更久。跳過測試能顯著加快打包速度
在 IDEA 點擊下圖的圖標,即可跳過測試
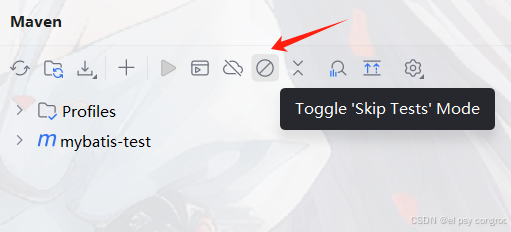
點擊該按鈕后,在執行 Maven 的 package 等構建命令時,就會跳過測試階段,直接進行后續的打包等操作;再次點擊則關閉 “跳過測試” 模式,恢復 Maven 正常的構建流程
Maven 打包時,多數情況下建議先執行 clean 以避免舊文件殘留導致異常,再點擊 package 進行打包
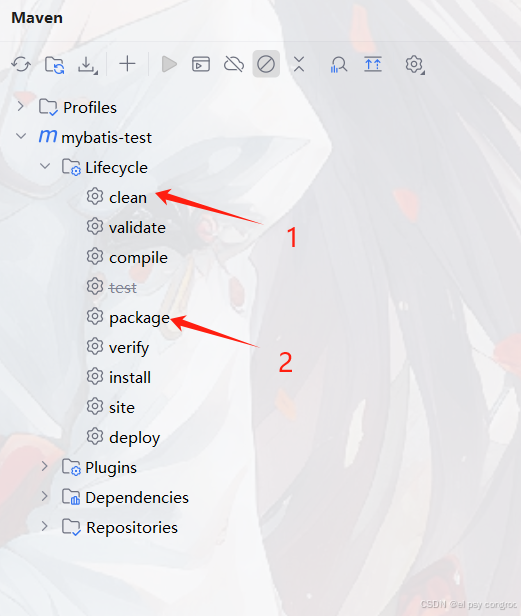
根據打包結果找到 jar 包
上傳 jar 包到服務器,并運行
直接拖動打包好的 jar 包到 Xshell 窗口即可完成文件的上傳,這個依賴 rz 命令,如果不行可以自己安裝或者使用第三方工具
rz(Receive Zmodem)和 sz(Send Zmodem)是基于 Zmodem 協議的文件傳輸命令,適用于通過 SSH 或 Telnet 連接的終端環境,無需額外圖形界面即可快速實現本地與遠程服務器的文件互傳
如果執行上述命令之后,提示 Command ‘XX’ not found ,表示當前云服務器未安裝 lrzsz ,可以通過包管理器安裝:
# Debian/Ubuntu/Kali 系統
sudo apt-get install lrzsz # RedHat/CentOS 系統
sudo yum install lrzsz
安裝后即可使用 rz(上傳)和 sz(下載)命令
運行程序
java -jar mybatis-test-0.0.1-SNAPSHOT.jar
運行沒問題之后可以設置后臺運行程序,因為是后臺運行程序所以看不到日志,推薦把日志輸出重定向到指定文件中:
nohup java -jar mybatis-test-0.0.1-SNAPSHOT.jar >> mybatis-test.log 2>&1 &
- nohup: 后臺運行程序,退出終端不會影響程序的運行
- 設置輸出日志到 mybatis-test.log
- &:將程序放入后臺執行,此時終端會立即釋放,你可以繼續輸入其他命令,不影響后臺程序的運行
記得云服務器一定要開放安全組/防火墻
常見問題
一個程序的正常運行,既依賴代碼本身的正確性,也離不開運行環境的適配性。即便代碼完全一致,在 Windows 系統能正常運行,在 Linux 系統中也可能出現問題 —— 不同操作系統對代碼的解析邏輯和支持程度存在差異,例如 Windows 系統的 MySQL 不區分大小寫,而 Linux 系統的 MySQL 則嚴格區分大小寫,這類細節就可能導致程序行為不一致
當服務無法正常訪問時,可從以下主要方向排查原因:
一、服務未啟動
- 先通過 ps -ef|grep java 命令檢查程序進程是否存在
- 若進程存在,可進一步通過 curl http://127.0.0.1:8080/login.html 測試本地訪問
- 若能返回正常 HTML 頁面,說明程序啟動成功,問題可能出在端口未對外網開放
- 若服務未啟動,則需查看日志定位具體原因,常見情況包括:
- 數據庫不存在或表不存在(尤其注意 Linux 環境下的大小寫問題)
- 數據庫賬號密碼錯誤
- JDK 未安裝、版本不兼容或環境變量配置有誤等
二、端口未開放
若服務已正常啟動但外部無法訪問,需檢查云服務器的防火墻規則或安全組配置,確認程序使用的端口(如 8080)是否已允許外部訪問
停掉服務
如果我們需要重啟服務,或者重新部署等,都需要先停止之前的服務
# 查看當前服務的進程
ps -ef|grep mybatis-test

上圖 425197 就是該服務的進程
# 殺掉進程
kill -9 425197









)
)
)

資源限制-詳細介紹)





)