0.1 數字識別
from sklearn.svm import SVC
from sklearn.metrics import silhouette_score
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.feature_extraction import DictVectorizer
from sklearn.cluster import KMeans
from sklearn.metrics import classification_report,roc_curve,roc_auc_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 封裝一個函數用于可視化結果
def visualization(data,c=None,title=None,centers=None):if data.ndim == 1 or data.shape[1] == 1:print("數據維度過低,跳過可視化")returndata = pd.DataFrame(data)pca = PCA(n_components=2)data = pca.fit_transform(data)plt.scatter(data[:, 0], data[:,1],c=c)if centers is not None:plt.scatter(centers[:,0],centers[:,1],c="red",s=100)plt.title(title)plt.show()data = pd.read_csv("../data/shuzi.csv")
X=data.drop(columns="label")
y=data["label"]
X=X.apply(lambda x:x/255,axis=0)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
AUC = []
for i in [0.75,0.8,0.85,0.9,0.95]:pca = PCA(n_components=i, svd_solver='full')print(i,":","拷貝")X_train_copy = X_train.copy()X_test_copy = X_test.copy()# 降維print(i,":","開始降維")X_train_copy =pca.fit_transform(X_train_copy)X_test_copy =pca.transform(X_test_copy)# 訓練print(i,":","開始訓練")svc = SVC(C=1,probability=True)svc.fit(X_train_copy,y_train)print(i,":","開始預測")y_pred = svc.predict(X_test_copy)y_proba = svc.predict_proba(X_test_copy)print(i,":","開始評估")# fpr, tpr, thresholds = roc_curve(y_test,y_proba[:,1])auc = roc_auc_score(y_test,y_proba,multi_class="ovr")print(i,"評估結果:\n",classification_report(y_test,y_pred))print(i,":auc:",auc)AUC.append(auc)print(i,":","可視化:")visualization(y_test,c=y_pred)
# 可視化
fig , axes = plt.subplots(2,1)axes[0].imshow(np.array(X.iloc[0,:]).reshape(28,28))
axes[1].imshow(np.array(X.iloc[1,:]).reshape(28,28))plt.show()
0.2 乳腺癌分類預測
from sklearn.svm import SVC
from sklearn.metrics import silhouette_score
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.feature_extraction import DictVectorizer
from sklearn.cluster import KMeans
from sklearn.metrics import classification_report,roc_curve,roc_auc_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 使用黑體
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題
# 繪制決策邊界
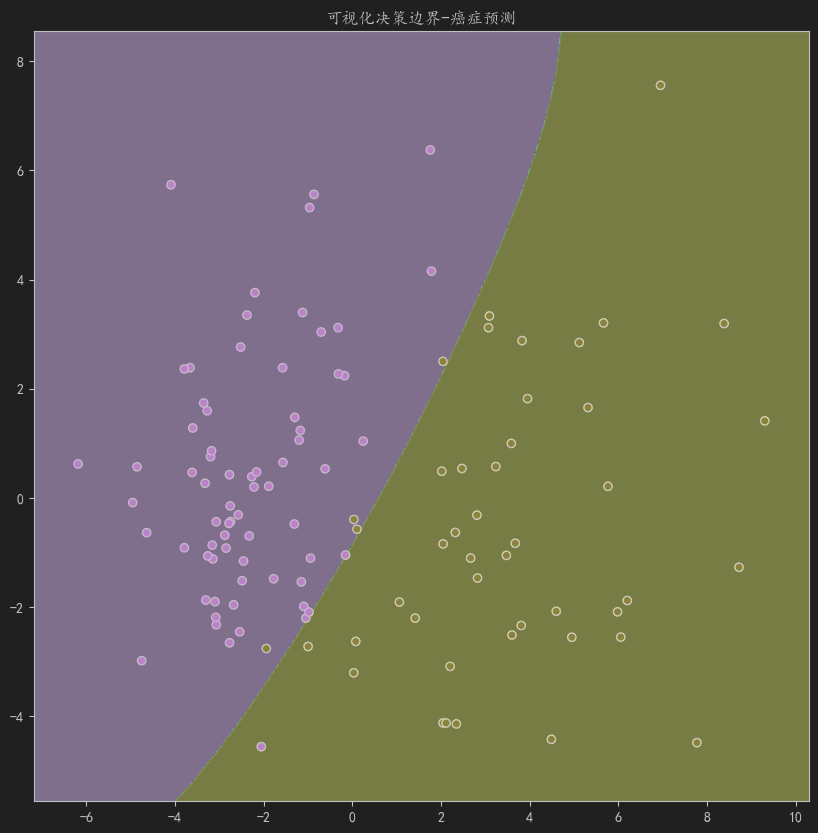
def plot_boundary(data, estimator, y, pca=None,title=None):"""繪制決策邊界和數據點:param data: 預測的數據:param estimator: 訓練好的分類器:param y: 數據標簽:param pca: PCA對象,用于降維(在函數外已經使用了pca的情況,防止兩個pca不一樣,輸入pca保持降維結果一致):return: None"""data = np.array(data)if data.ndim == 1 or data.shape[1] == 1:print("維度過低")return # PCA 降維(如果傳入pca則直接使用傳入的pca)if data.shape[1] > 2:if pca is None:pca = PCA(n_components=2)data_reduced = pca.fit_transform(data) # 使用不同的變量名else:data_reduced = pca.transform(data)need_inv = True # 用于標記是否經歷過降維(如果降維過在后面需要重新升維,防止與estimator的訓練維度不統一)else:data_reduced = data need_inv = False # 用于標記是否經歷過降維(如果降維過在后面需要重新升維,防止與estimator的訓練維度不統一)# 基于降維后的數據創建網格min_x, max_x = data_reduced[:,0].min()-1, data_reduced[:,0].max()+1min_y, max_y = data_reduced[:,1].min()-1, data_reduced[:,1].max()+1xx, yy = np.meshgrid(np.arange(min_x, max_x, 0.02),np.arange(min_y, max_y, 0.02))# 轉為一維且合并的網格點,每行代表一個網格點,用于后續預測grid_points = np.c_[xx.ravel(), yy.ravel()]# 如果降過維,把網格點升回原始空間再預測if need_inv:grid_original = pca.inverse_transform(grid_points)else:grid_original = grid_points# 預測網格點的類別Z = estimator.predict(grid_original).reshape(xx.shape)# 繪圖plt.figure(figsize=(10, 10))plt.contourf(xx, yy, Z, alpha=0.8)plt.scatter(data_reduced[:,0], data_reduced[:,1], c=y, edgecolors='black')plt.title(f"可視化決策邊界-{title}")plt.show()
data = pd.read_csv("F:\py_MachineLearning\MachineLearning\MachineLearning\scikit_learn\data\乳腺癌分類.csv")# 可視化
sns.countplot(data,x="diagnosis",
)
plt.title("類別分布")
plt.show()
# 數據集劃分
X=data.drop(columns=['Unnamed: 32',"id","diagnosis"])
y = data["diagnosis"]
# 創建字典映射
dict={"B":0,"M":1
}
y = y.map(dict)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
from sklearn.preprocessing import StandardScaler
# 特征縮放
transfer = StandardScaler()
transfer.fit(X_train)
X_train = pd.DataFrame(transfer.transform(X_train),columns=X.columns)
X_test = pd.DataFrame(transfer.transform(X_test),columns=X.columns)
# 借助決策樹挑選特征
from sklearn.tree import DecisionTreeClassifier
DT = DecisionTreeClassifier()
DT.fit(X_train,y_train)
importances = {"feature":X.columns,"importance":DT.feature_importances_
}pd.DataFrame(importances).sort_values(by="importance",ascending=False)#選擇radius_worst和concave points_worst
## X_train,X_test=X_train.loc[:,["radius_worst","concave points_worst"]],X_test.loc[:,["radius_worst","concave points_worst"]]svc = SVC()
svc.fit(X_train,y_train)
y_pred = svc.predict(X_test)
print("classification_report:\n",classification_report(y_test,y_pred))
# 繪制決策邊界
plot_boundary(X_test,svc,y=y_test,title="癌癥預測")
結果
1 相關知識
拉格朗日乘子法:
1 帶約束的優化問題
min?xf0(x)\min_x f_0(x)xmin?f0?(x)
subject?to?fi(x)≤0,i=1,...m\text{subject to } f_i(x) \leq 0, i = 1,...msubject?to?fi?(x)≤0,i=1,...m
hi(x)=0,i=1,...qh_i(x) = 0, i = 1,...qhi?(x)=0,i=1,...q
2 原始轉換
min?L(x,λ,v)=f0(x)+∑i=1mλifi(x)+∑i=1qvihi(x)\min L(x, \lambda, v) = f_0(x) + \sum_{i=1}^{m} \lambda_i f_i(x) + \sum_{i=1}^{q} v_i h_i(x)minL(x,λ,v)=f0?(x)+i=1∑m?λi?fi?(x)+i=1∑q?vi?hi?(x)
2 SVC推導過程
2.1 損失函數的推導
2.1.1 距離的方向
已知決策超平面:wTX+b=0w^TX+b=0wTX+b=0
w1x1+w2x2=0w_1x_1+w_2x_2=0w1?x1?+w2?x2?=0 可以轉化為兩個向量相乘 (w1,w2)?(x1,x2)=0(w_1,w_2)·(x_1,x_2)=0(w1?,w2?)?(x1?,x2?)=0
此時會發現(w_1,w_2)正好垂直于(x_1,x_2),這就是法向量,這樣就獲得了垂直于決策超平面距離的方向wT∣∣w∣∣\frac{w^T}{||w|| }∣∣w∣∣wT?(除以w的范數是為了保證這個向量的長度=1.只是單純的方向沒有距離信息)
2.1.2 距離的計算
現在只需要在決策超平面上取一個點x′x'x′ ,再得到支持向量xxx,計算(x?x′)?wT∣∣w∣∣(x-x')*\frac{w^T}{||w|| }(x?x′)?∣∣w∣∣wT?就是x,x′x,x'x,x′在法向量上的距離,也就是支持向量到平面的距離
2.1.3損失函數
現在得到了(x?x′)?wT∣∣w∣∣(x-x')*\frac{w^T}{||w|| }(x?x′)?∣∣w∣∣wT?
因為x′x'x′取自決策超平面:wTX+b=0w^TX+b=0wTX+b=0 ,所以wTx′=?bw^Tx'=-bwTx′=?b
所以:(x?x′)w=wTx?wTx′=wTx+b(x-x')w=w^Tx-w^Tx'=w^Tx+b(x?x′)w=wTx?wTx′=wTx+b
這樣就得到了初步的損失函數:wTx+b∣∣w∣∣\frac{w^Tx+b}{||w||}∣∣w∣∣wTx+b?
簡化,由于yiy_iyi?和wT?Φ(xi)+bw^T \cdot \Phi(x_i) + bwT?Φ(xi?)+b處于同一側,符號同號(隱含假設,否則則是分類錯誤)。所以結果不變,得到:yi(wT?Φ(xi)+b)∣∣w∣∣\frac{y_i \bigl(w^T \cdot \Phi(x_i) + b\bigr)}{||w||}∣∣w∣∣yi?(wT?Φ(xi?)+b)?
(Φ(xi)\Phi(x_i)Φ(xi?)表示核函數,表示升維,暫時可繼續理解為X)
最后得到:
arg?max?w,b{1∣∣w∣∣min?i[yi?(wT?Φ(xi)+b)]}\arg \max_{w,b} \left\{ \frac{1}{||w||} \min_i \left[ y_i \cdot (w^T \cdot \Phi(x_i) + b) \right] \right\}argmaxw,b?{∣∣w∣∣1?mini?[yi??(wT?Φ(xi?)+b)]}
2.2 空間縮放
為了進一步簡化損失函數
對w和x同乘γ\gammaγ對整個空間進行縮放,使得yi?(wT?Φ(xi)+b)≥1y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1yi??(wT?Φ(xi?)+b)≥1
此時min?[yi?(wT?Φ(xi)+b)≥1]\min[y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1]min[yi??(wT?Φ(xi?)+b)≥1]就等于1
最后損失函數就成了arg?max?w,b1∣∣w∣∣\arg \max_{w,b}\frac{1}{||w||}argmaxw,b?∣∣w∣∣1?
也產生了一個約束條件:min?[yi?(wT?Φ(xi)+b)≥1]\min[y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1]min[yi??(wT?Φ(xi?)+b)≥1]
(接下來的推導均處于這個縮放后的空間)
2.3 目標求解
2.3.1 拉格朗日乘子法
現在的目標函數是arg?max?w,b1∣∣w∣∣\arg \max_{w,b}\frac{1}{||w||}argmaxw,b?∣∣w∣∣1?,約束條件是min?[yi?(wT?Φ(xi)+b)≥1]\min[y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1]min[yi??(wT?Φ(xi?)+b)≥1]
正常來說需要將求解極大值問題轉化為求解極小值問題,然后求最優值但此時由于有一個約束條件,可以采用拉格朗日乘子法將約束條件融合進f(x)f(x)f(x),使其表面上轉化為一個無約束問題
通過拉格朗日乘子法得到:L(w,b,α)=12∣∣w∣∣2?∑i=1nαi(yi(wT?Φ(xi)+b)?1)L(w, b, \alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{n} \alpha_i \left( y_i \left( w^T \cdot \Phi(x_i) + b \right) - 1 \right)L(w,b,α)=21?∣∣w∣∣2?i=1∑n?αi?(yi?(wT?Φ(xi?)+b)?1),約束:αi>=0\alpha_i>=0αi?>=0(這個約束源于拉格朗日乘子法的KKT性質)
(αi\alpha_iαi?:拉格朗日乘數,負號是因為約束條件被重寫為 ?[yi(wT?Φ(xi)+b)?1]≤0?[yi(wT?Φ(xi)+b)?1]≤0?[yi(wT?Φ(xi)+b)?1]≤0?[yi(wT?Φ(xi)+b)?1]≤0-[y_i(w^T \cdot \Phi(x_i) + b) - 1] \leq 0?[yi(wT?Φ(xi)+b)?1]≤0?[yi(wT?Φ(xi)+b)?1]≤0?[yi?(wT?Φ(xi?)+b)?1]≤0?[yi(wT?Φ(xi)+b)?1]≤0 的形式)
2.3.2 對偶性
由于對偶性質(這個當定理記即可,推導極為復雜)
min?w,bmax?αL(w,b,α)→max?αmin?w,bL(w,b,α)\min_{w,b} \max_{\alpha} L(w,b,\alpha) \to \max_{\alpha} \min_{w,b} L(w,b,\alpha)minw,b?maxα?L(w,b,α)→maxα?minw,b?L(w,b,α)
2.3.3 求導*
對w求偏導:?L?w=0?w=∑i=1nαiyiΦ(xi)\frac{\partial L}{\partial w} = 0 \Rightarrow w = \sum_{i=1}^{n} \alpha_i y_i \Phi(x_i)?w?L?=0?w=∑i=1n?αi?yi?Φ(xi?)
對b求偏導:?L?b=0?0=∑i=1nαiyi\frac{\partial L}{\partial b} = 0 \Rightarrow 0 = \sum_{i=1}^{n} \alpha_i y_i?b?L?=0?0=∑i=1n?αi?yi?
代入:L(w,b,α)=12∣∣w∣∣2?∑i=1nαi(yi(wTΦ(xi)+b)?1)L(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{n} \alpha_i (y_i(w^T \Phi(x_i) + b) - 1)L(w,b,α)=21?∣∣w∣∣2?∑i=1n?αi?(yi?(wTΦ(xi?)+b)?1)
其中 w=∑i=1nαiyiΦ(xi)0=∑i=1nαiyiw = \sum_{i=1}^{n} \alpha_i y_i \Phi(x_i) \quad 0 = \sum_{i=1}^{n} \alpha_i y_iw=∑i=1n?αi?yi?Φ(xi?)0=∑i=1n?αi?yi?
=12wTw?wT∑i=1nαiyiΦ(xi)?b∑i=1nαiyi+∑i=1nαi= \frac{1}{2}w^T w - w^T \sum_{i=1}^{n} \alpha_i y_i \Phi(x_i) - b\sum_{i=1}^{n} \alpha_i y_i + \sum_{i=1}^{n} \alpha_i=21?wTw?wT∑i=1n?αi?yi?Φ(xi?)?b∑i=1n?αi?yi?+∑i=1n?αi?
=∑i=1nαi?12(∑i=1nαiyiΦ(xi))T∑i=1nαiyiΦ(xi)= \sum_{i=1}^{n} \alpha_i - \frac{1}{2}(\sum_{i=1}^{n} \alpha_i y_i \Phi(x_i))^T \sum_{i=1}^{n} \alpha_i y_i \Phi(x_i) \quad=∑i=1n?αi??21?(∑i=1n?αi?yi?Φ(xi?))T∑i=1n?αi?yi?Φ(xi?)
=∑i=1nαi?12∑i=1,j=1nαiαjyiyjΦT(xi)Φ(xj)= \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i=1,j=1}^{n} \alpha_i \alpha_j y_i y_j \Phi^T(x_i)\Phi(x_j)=∑i=1n?αi??21?∑i=1,j=1n?αi?αj?yi?yj?ΦT(xi?)Φ(xj?)
繼續對α求極大值:max?α∑i=1nαi?12∑i=1n∑j=1nαiαjyiyj(Φ(xi)?Φ(xj))\max_{\alpha} \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j (\Phi(x_i) \cdot \Phi(x_j))maxα?∑i=1n?αi??21?∑i=1n?∑j=1n?αi?αj?yi?yj?(Φ(xi?)?Φ(xj?))
條件:∑i=1nαiyi=0\sum_{i=1}^{n} \alpha_i y_i = 0∑i=1n?αi?yi?=0、αi≥0\alpha_i \geq 0αi?≥0
極大值轉換成求極小值:min?α12∑i=1n∑j=1nαiαjyiyj(Φ(xi)?Φ(xj))?∑i=1nαi\min_{\alpha} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j (\Phi(x_i) \cdot \Phi(x_j)) - \sum_{i=1}^{n} \alpha_iminα?21?∑i=1n?∑j=1n?αi?αj?yi?yj?(Φ(xi?)?Φ(xj?))?∑i=1n?αi?
條件:∑i=1nαiyi=0\sum_{i=1}^{n} \alpha_i y_i = 0∑i=1n?αi?yi?=0、αi≥0\alpha_i \geq 0αi?≥0
2.4松弛因子
加入松弛因子成為軟間隔
min?12∣∣w∣∣2+C∑i=1nξi\min \frac{1}{2} ||w||^2 + C \sum_{i=1}^{n} \xi_imin21?∣∣w∣∣2+C∑i=1n?ξi?
約束變成了C?αi?μi=0C - \alpha_i - \mu_i = 0C?αi??μi?=0和μi≥0\mu_i \geq 0μi?≥0
通過與硬間隔一樣的求解方式最后得到解
min?α12∑i=1n∑j=1nαiαjyiyj(xi?xj)?∑i=1nαi\min_{\alpha} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_{i=1}^{n} \alpha_iαmin?21?i=1∑n?j=1∑n?αi?αj?yi?yj?(xi??xj?)?i=1∑n?αi?
約束:
∑i=1nαiyi=0\sum_{i=1}^{n} \alpha_i y_i = 0∑i=1n?αi?yi?=0、0≤αi≤C0 \leq \alpha_i \leq C0≤αi?≤C
3 SVC api
(基于SVM的分類)
SVC(C=1.0,
gamma=‘scale’,
random_state=None,
)
C : # 正則化參數,控制分類邊界的平滑程度。C值越大對誤分類懲罰越強,可能導致過擬合;C值較小則允許更多誤分類,泛化能力更強但可能欠擬合
gamma:# 核函數系數,可選’scale’(1/(n_features*X.var()))、‘auto’(1/n_features)或具體數值。影響數據映射到高維空間的分布
代碼示例
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_reportiris = load_iris()
data= pd.DataFrame(iris.data, columns=iris.feature_names)
data["target"] = iris.target
X = data.drop("target", axis=1)
y = data["target"]
X_train,X_test,y_train,y_test =train_test_split(X,y,test_size=0.2)transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)svc = SVC(kernel='rbf')
svc.fit(X_train,y_train)
y_pred = svc.predict(X_test)print(classification_report(y_test, y_pred))
4 SVR
4.1 原理
目的:
SVR也是擬合一個函數y=wx+by=wx+by=wx+b這一點有些類似于線性回歸
2. 核心概念
1 ε-不敏感區間
如果 |f(x_i) - y_i| ≤ ε,則認為預測是“足夠好”,不計入損失
2 支持向量
只有落在 ε 區間之外的數據點才會對模型產生影響,這些點稱為支持向量
3. 損失函數
SVR 的損失函數(ε-insensitive loss):
L?(y,f(x))={0,if?∣y?f(x)∣≤?∣y?f(x)∣??,if?∣y?f(x)∣>? L_\epsilon(y, f(x)) = \begin{cases} 0, & \text{if } |y - f(x)| \le \epsilon \\ |y - f(x)| - \epsilon, & \text{if } |y - f(x)| > \epsilon \end{cases} L??(y,f(x))={0,∣y?f(x)∣??,?if?∣y?f(x)∣≤?if?∣y?f(x)∣>??
(只有預測值超過 ε 的誤差才會被懲罰)
4. 優化目標
最小化:
1/2∣∣w∣∣2+C∑i(ξi+ξi?)1/2 ||w||^2 + C ∑_i (ξ_i + ξ_i^*)1/2∣∣w∣∣2+Ci∑?(ξi?+ξi??)
ξ_i, ξ_i^*:松弛變量,度量超出 ε 的誤差
C:控制對超出誤差的懲罰程度
可通過對偶問題使用核函數處理非線性情況
核方法
與SVC一樣
理解
除了支持向量(線性回歸的誤差的樣本參與計算,SVR的誤差只有在 ε 區間之外的數據點才參與計算)、核方法和松弛變量(線性回歸并沒有這種內嵌的正則化方式)等區別。SVR就是使用的線性回歸那套損失函數,只是SVR根據自身的思想改了一點,且最終有一個∣∣w∣∣||w||∣∣w∣∣距離不是像線性回歸一樣的均方誤差而是通過SVM的計算∣∣w∣∣||w||∣∣w∣∣的方式來計算的。也就是說SVR就是基于支持向量思想對線性回歸的升級
4.2 api
(基于SVM的回歸)
from sklearn.svm import SVR
SVR(kernel=‘rbf’, C=100, gamma=0.1, epsilon=0.1)
常用參數?:
C:正則化參數。C的值越大,模型會盡可能減小訓練誤差,這可能導致過擬合。C的值越小,模型會盡可能平坦,這可能導致欠擬合。
epsilon:SVR中的ε-不敏感損失函數參數。它指定了SVR中函數f與真實值y之間允許的最大偏差。在這個間隔內的樣本點被忽略,只有間隔邊緣上的樣本點才被用于計算損失。
kernel:指定算法中使用的核函數類型。常見的核函數有線性核(‘linear’)、多項式核(‘poly’)、徑向基函數核(‘rbf’)等。
degree和gamma參數與SVC中的含義相同。
?常用方法?:**
fit(X, y):訓練模型。
predict(X):使用訓練好的模型進行預測。
score(X, y):返回給定測試數據和標簽的R^2分數,也稱為確定系數。它是回歸模型擬合優度的一種度量。最好的可能分數是1.0,它可能小于1.0(因為模型的誤差可能比隨機誤差大)。
代碼示例
from sklearn.svm import SVR
from sklearn.metrics import root_mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
X=np.sort(5*np.random.rand(100,1),axis=0)#100個0-5之間的隨機數,并按列排序
y = np.sin(X).ravel()+np.random.rand(100)*0.3svr = SVR(C=100,gamma=0.1) # 核函數參數 影響決策邊界的形狀)
svr.fit(X,y)X_test = np.linspace(0,5,100)
X_test = X_test.reshape(-1,1)
pred =svr.predict(X_test)plt.scatter(X,y)
plt.plot(X_test,pred,c ="red")
plt.show()
root_mean_squared_error(y,pred)# svr = SVR(kernel='rbf')4.3 SVR、SVC、線性回歸區別
- SVM:主要用于分類(有SVC),也可用于回歸(SVR)
- 線性回歸:專門用于回歸問題
1.?目標函數?
- SVM:
- 分類:最大化間隔(margin)
- 回歸(ε-SVR):最小化預測誤差,同時保持預測值在ε管道內
- 線性回歸:最小化均方誤差(MSE)
2.?損失函數?
- SVM:
- 分類:鉸鏈損失(Hinge Loss)
- 回歸:ε不敏感損失
- 線性回歸:平方損失
3.?輸出結果?
- SVM分類:離散的類別標簽
- SVM回歸:連續值,但受ε管道約束
- 線性回歸:無約束的連續值輸出
4.?處理異常值?
- SVM:通過調節C參數控制對異常值的敏感度
- 線性回歸:對異常值非常敏感(因使用平方損失)
5.?非線性擴展?
- SVM:可通過核技巧處理非線性問題
- 線性回歸:需要手動添加多項式特征
6.?幾何解釋?
- SVM:尋找最大間隔超平面
- 線性回歸:尋找最小化垂直距離的超平面
?
7 典型應用場景對比?: - SVM更適合:
- 小樣本高維數據(如文本分類)
- 需要明確決策邊界的情況
- 存在明顯間隔的數據集
- 線性回歸更適合:
- 預測連續數值
- 需要解釋特征權重的情況
- 大數據量的線性關系建模

)












)


`與`pg.key.get_pressed()` ,二者有什么區別與聯系?)

