

前引:在STL的關聯式容器中,
set以其嚴格的元素唯一性和自動排序特性成為處理有序數據的核心工具。其底層基于紅黑樹(Red-Black Tree)實現,保證了O(log n)的查找、插入與刪除復雜度!本文將從底層原理切入,結合關鍵操作源碼剖析,探討set在去重排序、高效檢索等場景的工程實踐。通過對比unordered_set與自定義排序規則,揭示其在內存效率與訪問性能的平衡藝術?!
目錄
【一】set 與 multiset 的介紹
【二】特點詳解
(1)自動排序
(2)唯一元素
(3)高效操作
(4)不支持隨機訪問
(5)迭代器支持
【三】接口學習
(1)構造
(2)插入
(3)迭代器訪問
(4)范圍for訪問
(5)find 搜索+erase 刪除
(6)find 搜索 與 count搜索
(7)lower 與 upper
(8)元素個數
(9)equal_range
【一】set 與 multiset 的介紹
完整解釋:
在C++標準模板庫(STL)中,
set是一種關聯容器,用于存儲唯一元素(本身是 key),并自動按升序排序。它基于紅黑樹(一種自平衡二叉搜索樹)實現,提供了高效的查找、插入和刪除操作。set常用于需要快速訪問和唯一性保證的場景,如去重、排序或作為字典鍵
set 通俗理解:
基于紅黑樹實現的一種容器,具有自動排序(升序)+不重復的特點
?multiset 通俗理解:
基于紅黑樹實現的一種容器,具有自動排序(升序)特點,但?
multiset?的節點允許鍵值重復
【二】特點詳解
(1)自動排序
自動排序簡而言之就是當你存入數據到 set 容器時,它會自動把它插入到合適的位置,從而實現自動排序,感覺就像《搜索二叉樹+中序遍歷》例如:
插入(1,、9、7、6),set 容器里面存儲(1、6、7、9)
(2)唯一元素
唯一性體現在數據的獨一無二,例如:
插入(1、2、3、3、3、7、7、6),set 容器里面存儲(1、2、3、6、7)
(3)高效操作
查找 ?插入 ?刪除:我們可以根據《搜索二叉樹》理解,每次折半,那么時間復雜度可以保證在O(logn),這些高效性源于紅黑樹的平衡特性!
(4)不支持隨機訪問
它的結構不是像數組那樣的下標訪問,元素的位置由樹結構決定
(5)迭代器支持
支持正向和反向兩種迭代器(下文有例舉!)
【三】接口學習
(1)構造
set 比較常使用的是默認構造:set + 數據類型 + 變量
set<int> V;(2)插入
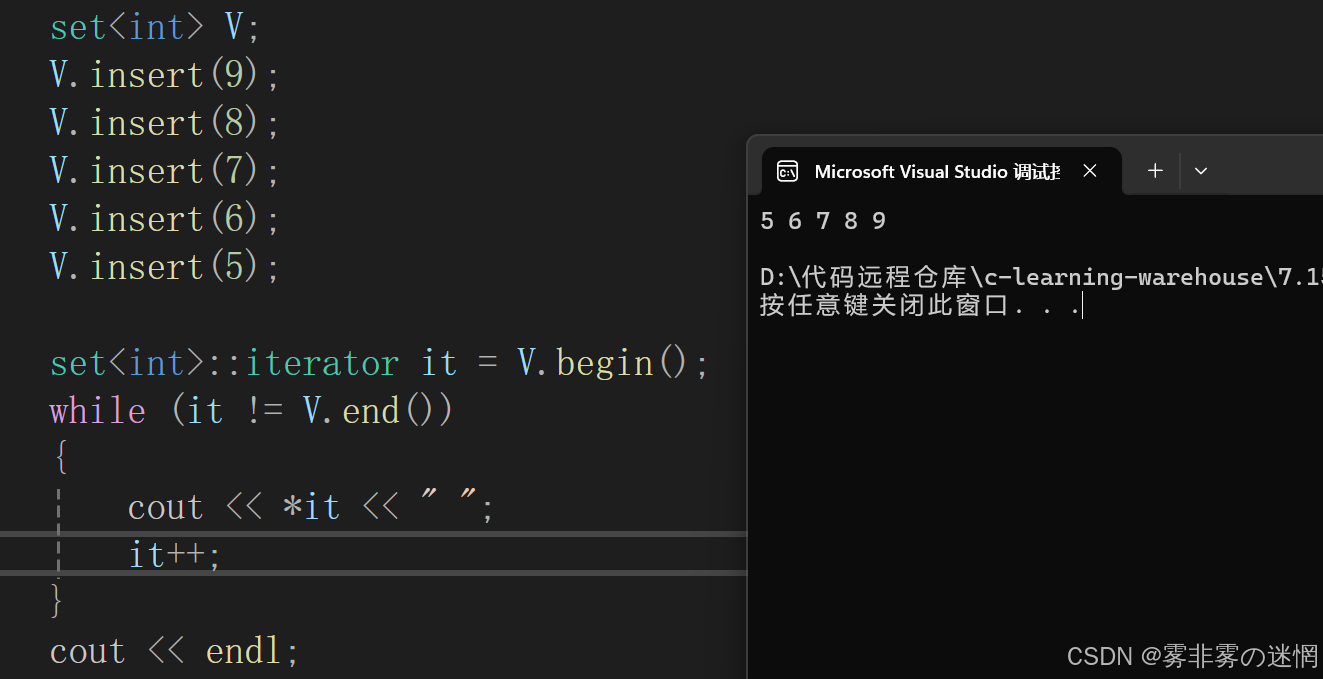
V.insert(9);(3)迭代器訪問
set<int>::iterator it = V.begin();
while (it != V.end())
{cout << *it << " ";it++;
}
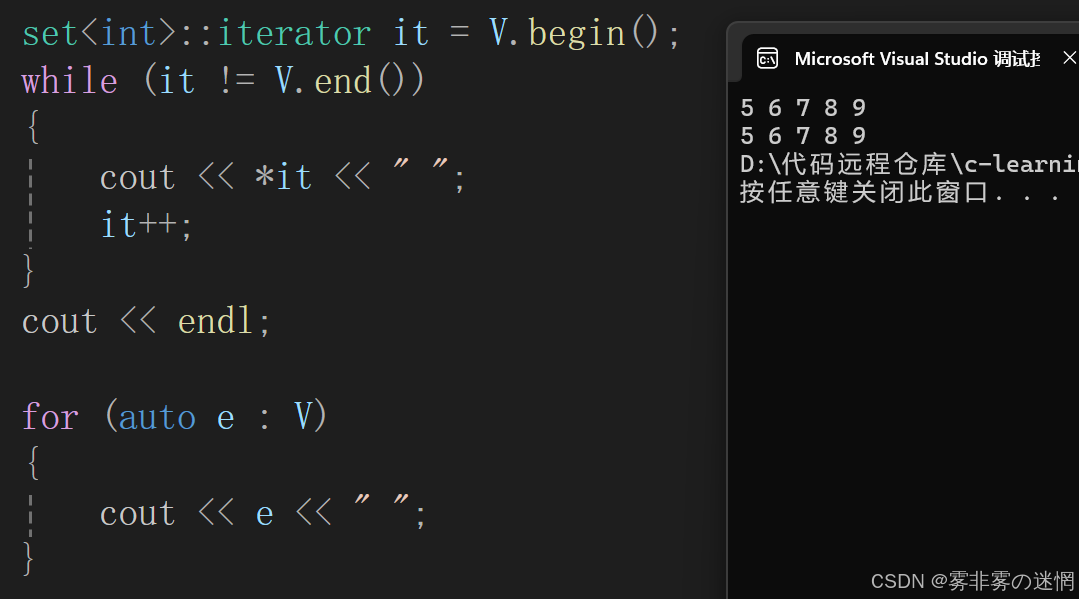
(4)范圍for訪問
for (auto e : V)
{cout << e << " ";
}
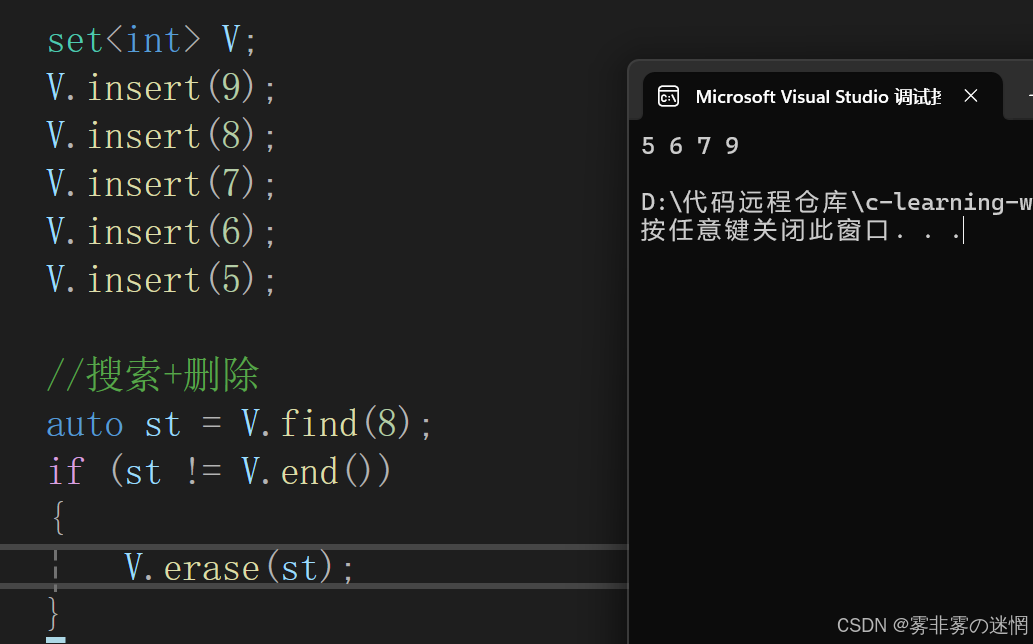
(5)find 搜索+erase 刪除
第一種查找:庫里面通用的查找函數,屬于暴力查找,時間復雜度為 O(N)
第二種查找:set 容器里面的,根據 set 的結構查找,時間復雜度為 O(logn)
//搜索+刪除auto st = find(V.begin(), V.end(), 5); //第一種
auto st = V.find(8); //第二種
if (st != V.end())
{V.erase(10);
}
(6)find 搜索 與 count搜索
find:如果找到指定元素了,會返回它的位置,否則返回end
count:如果找到指定元素返回1,否則返回0
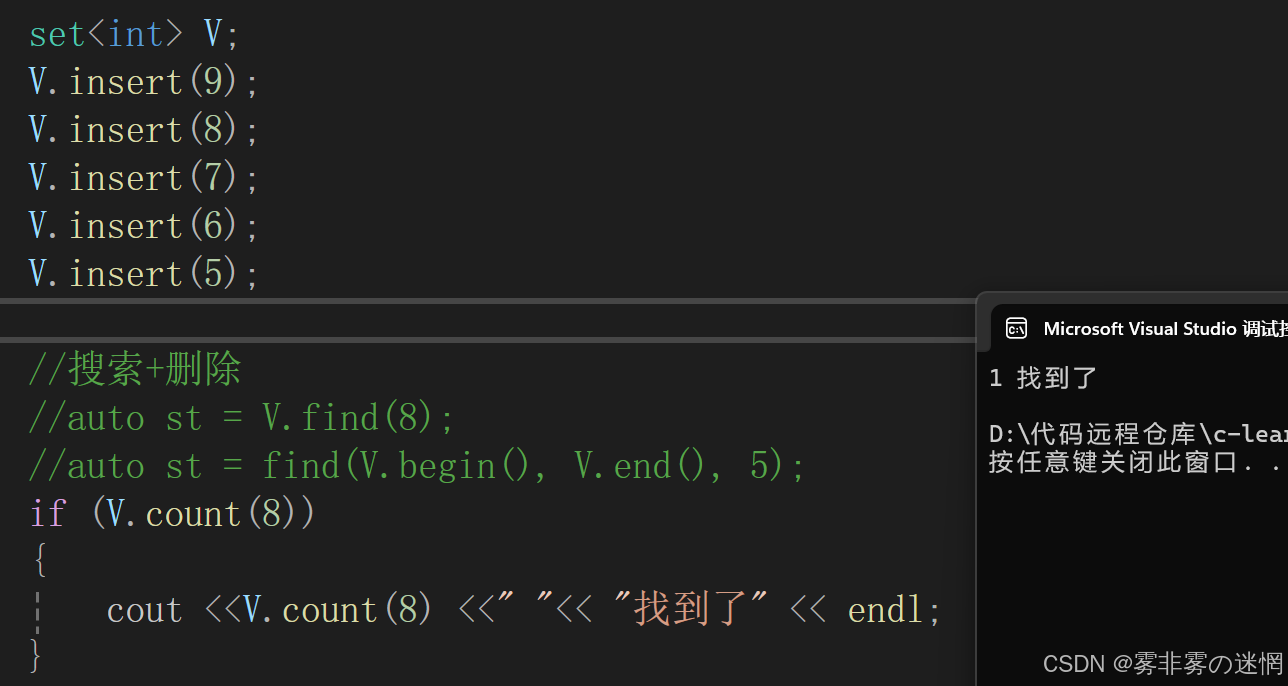
(7)lower 與 upper
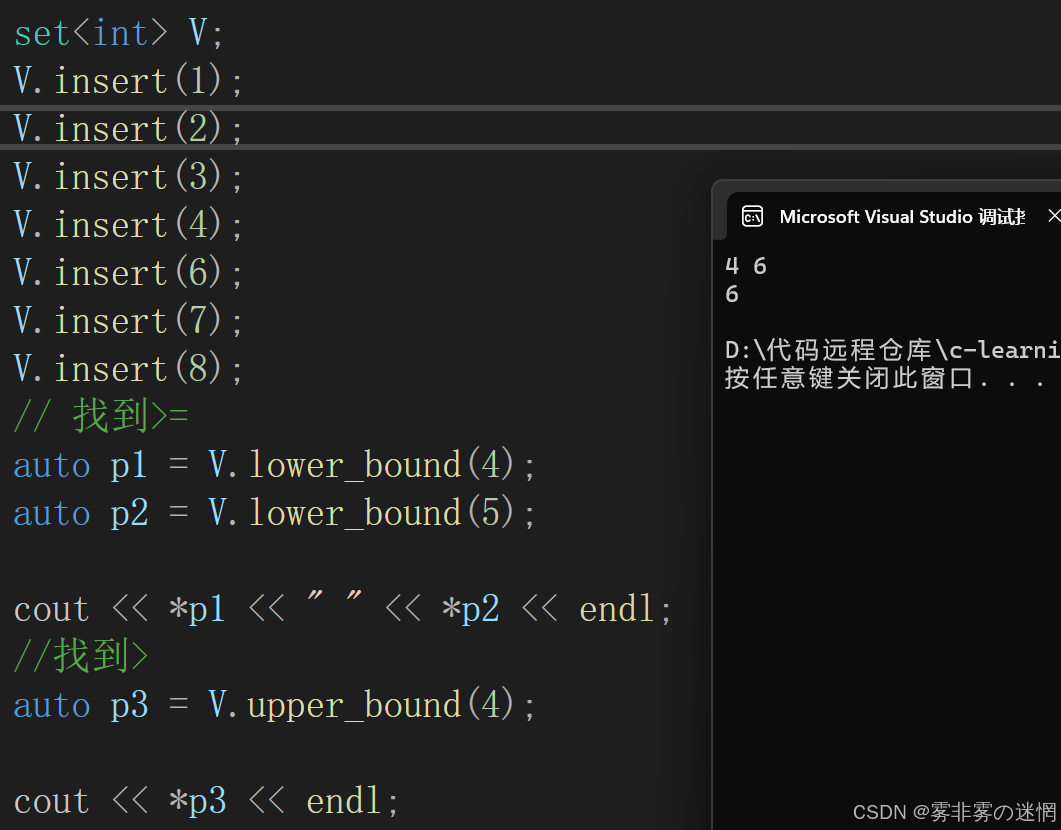
lower_bound:返回范圍內?>= 指定元素的位置,否則返回end
例如:(1,2,3,4,6,7,8)查找4,返回4的位置;查找5,返回6的位置
upper_bound:返回范圍內 >?指定元素的位置,否則返回end
例如:(1,2,3,4,6,7,8)查找4,返回6的位置
(8)元素個數
V.size();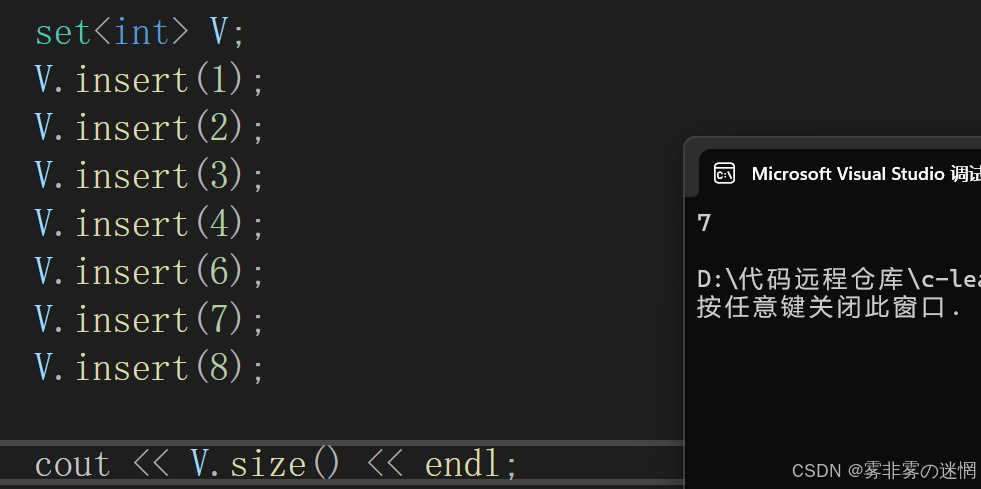
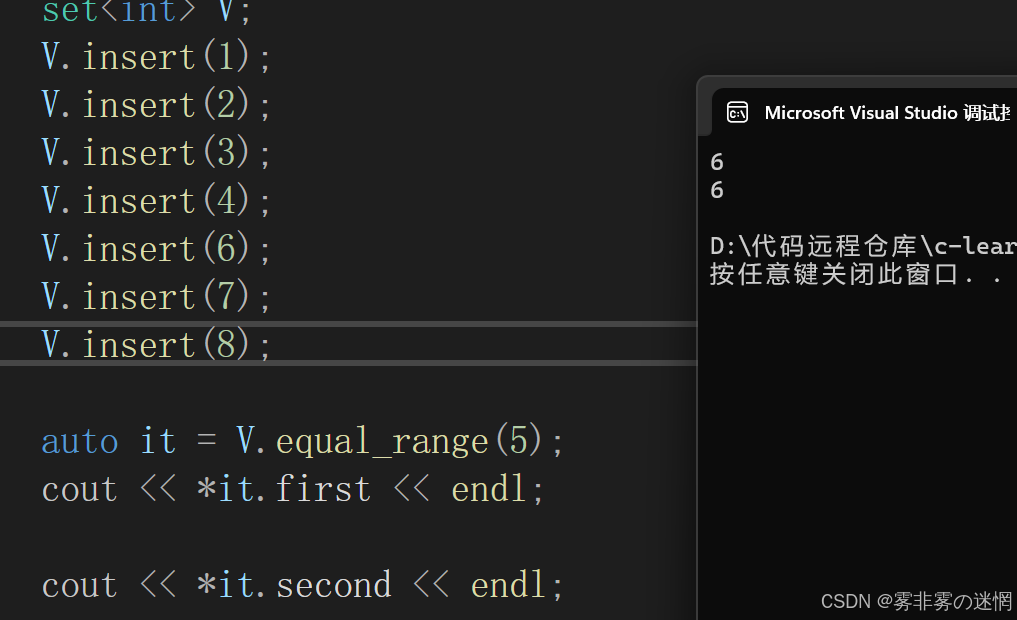
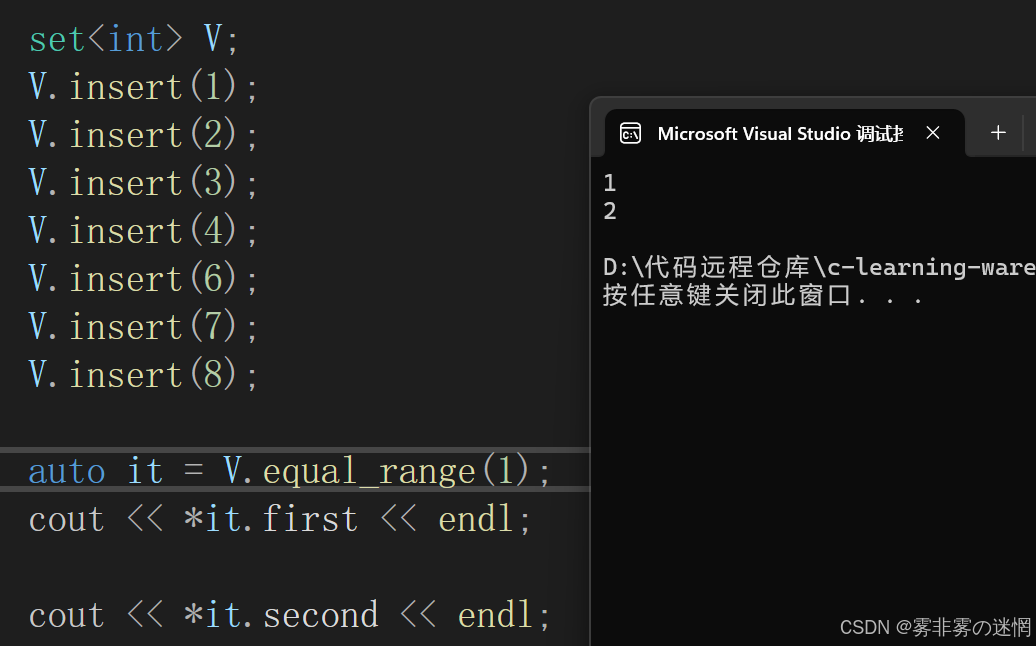
(9)equal_range
返回值:
該函數返回一個?pair
其成員?pair::first?是范圍的下限(與?lower_bound?相同)>=
pair::second?是上限(與?upper_bound?相同)>

)


)
)

)
![[論文閱讀] 人工智能 + 軟件工程 | 大型語言模型對決傳統方法:多語言漏洞修復能力大比拼](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 大型語言模型對決傳統方法:多語言漏洞修復能力大比拼)











