【GPT入門】第46課 vllm安裝、部署與使用
- 1.準備服務器
- 2. 安裝 conda環境,隔離base環境
- 3. vllm使用
-
- 3.1 在線推理, openai兼容服務器
- 3.2 模型離線調用
- 4. 沒有使用GPU問題分析
1.準備服務器
cuda 版本選12.1
vllm官網介紹: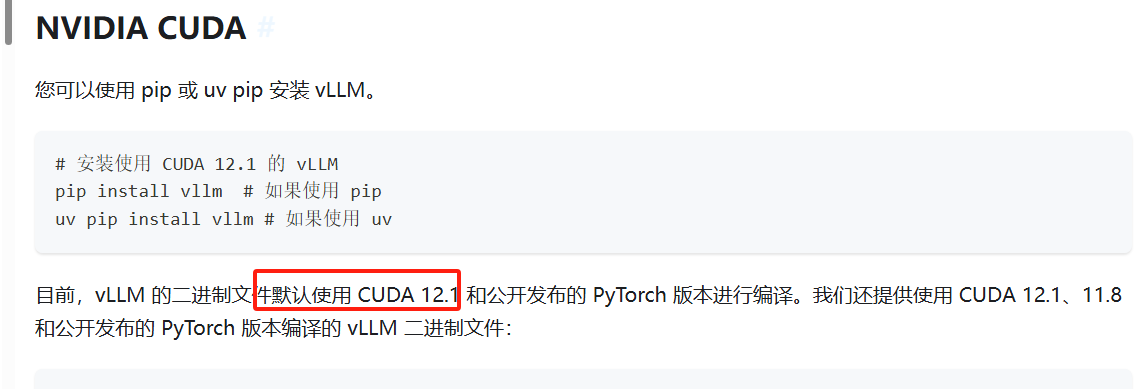
https://vllm.hyper.ai/docs/getting-started/installation/gpu
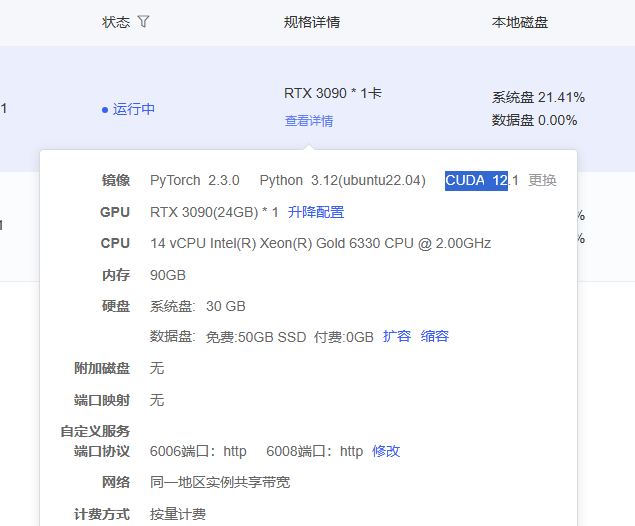
2. 安裝 conda環境,隔離base環境
為了實現高性能,vLLM 需要編譯多個 cuda 內核。然而,這一編譯過程會導致與其他 CUDA 版本和 PyTorch 版本的二進制不兼容問題。即便是在相同版本的 PyTorch 中,不同的構建配置也可能引發此類不兼容性。
因此,建議使用全新的 conda 環境安裝 vLLM。如果您有不同的 CUDA 版本,或者想要使用現有的 PyTorch 安裝,則需要從源代碼構建 vLLM。更多說明請參閱下文。
conda create -n vllm python=3.10 -y
conda activate vllmpip install vllm
3. vllm使用
3.1 在線推理, openai兼容服務器
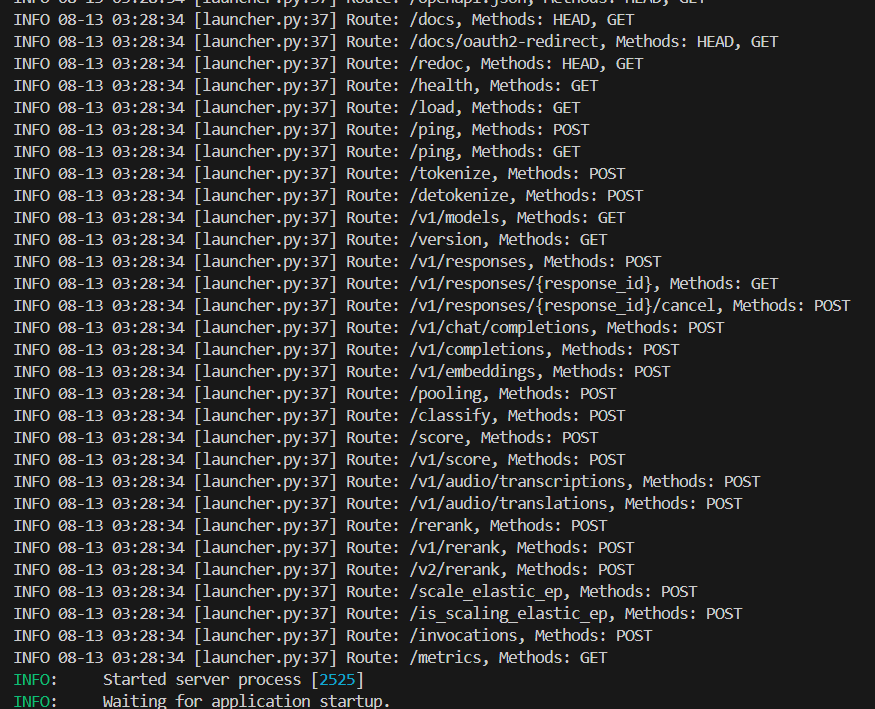
vLLM 可以部署為實現 OpenAI API 協議的服務器。這使得 vLLM 可以作為使用 OpenAI API 的應用程序的直接替代品。默認情況下,服務器在 http://localhost:8000 啟動。您可以使用 --host 和 --port 參數指定地址。服務器目前 1 次托管 1 個模型,并實現了諸如:列出模型、創建聊天補全和創建補全等端點。
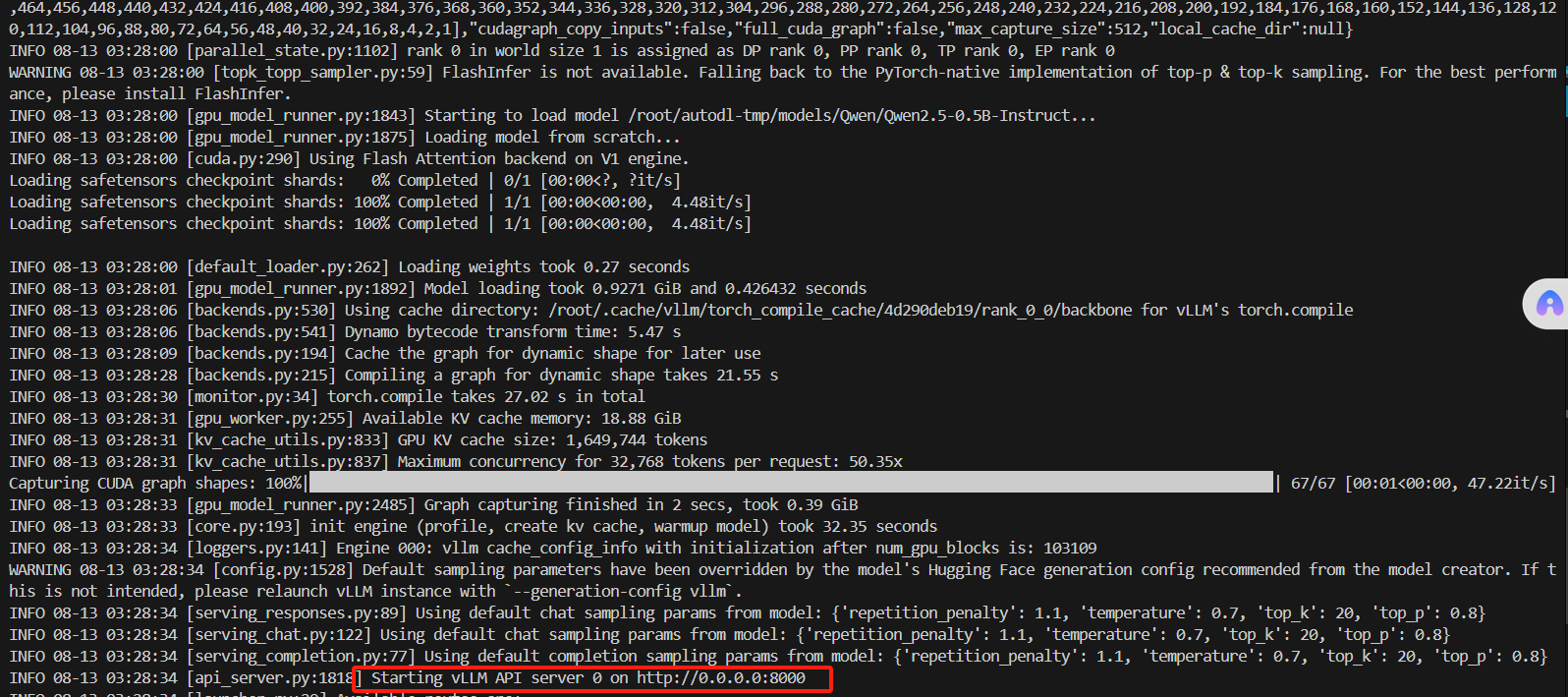
- 運行以下命令以啟動 vLLM 服務器并使用 Qwen2.5-0.5B-Instruct 模型:
使用Qwen2.5模型
pip install model_scope
from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir='/root/autodl-tmp/models')
print(model_dir)
- 啟動服務
vllm serve /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct
列出模型
curl http://localh)


)




(獲取方式看綁定的資源))









 時間插入、刪除和獲取隨機元素))
