在生成式人工智能飛速發展的今天,“眼見為實”這句話的有效性正面臨前所未有的挑戰。以往,圖像篡改往往通過傳統的圖像處理工具(如 Photoshop)進行,需要較高的技術門檻和人工成本;而現在,僅需通過幾行 Prompt 指令,便能批量生成難以辨別真偽的圖像或高清視頻。這一趨勢不僅降低了內容生成的門檻,也為深度偽造(Deepfake)技術的規模化應用提供了溫床,尤其在金融、社交網絡等領域,深度偽造已成為一種嚴峻的安全威脅。據網絡安全公司 Surfshark 的統計,僅 2025 年上半年,與深度偽造相關的金融詐騙全球損失已高達約 9 億美元,凸顯出視覺內容鑒偽技術的重要性和緊迫性。
為應對這一技術難題,業界近年來涌現了多種新興的 AI 鑒偽方法,致力于從底層視覺信號到高層語義分析的全棧式檢測。
一、人臉視頻篡改檢測:從像素差異到時序異常的全鏈路分析
從技術實現層面看,深度偽造的人臉視頻檢測本質上是一個極具挑戰性的二分類問題:需要在實時數據流中準確地區分真實視頻和偽造視頻,且面臨實時性和泛化能力的雙重壓力。其中,合合信息自 2022 年開始在圖像篡改檢測領域積累了深厚的技術經驗,并陸續發布了人臉視頻篡改檢測、AIGC 圖像鑒別技術及通用篡改檢測平臺。以下將從技術實現的角度,具體解析人臉視頻篡改檢測的關鍵技術思路。這類檢測通常圍繞兩個關鍵技術維度展開:
低層像素級噪聲特征挖掘 深度偽造算法的本質之一是圖像融合或插值,這些操作會不可避免地產生特定的微小視覺異常(如高頻噪聲、圖像邊緣的不連續性、色彩漸變的不自然過渡等)。從技術角度講,這些異常特征雖然不易被人眼識別,但在頻域或空間域上仍可通過深度學習模型有效地捕獲。 當前較為主流的像素級鑒偽方法是利用深度卷積神經網絡(如改進的 U-Net 或 Transformer 結構)對篡改區域進行分割和像素級概率標注。這種方法類似于醫學圖像分析中的病變區域分割,通過訓練大量標注了篡改痕跡的圖像數據集,模型可以學習到高度泛化的特征表達,從而增強對未知攻擊手法的抵御能力。
高層時序異常特征的捕捉與分析 視頻與靜態圖像的本質區別在于時序信息。真實的人臉視頻中,面部動作與表情演變存在內在的連續性與一致性。而深度偽造的視頻往往通過逐幀生成或修正,從而在連續幀之間出現潛在的動態不一致,如眼球運動、面部微表情或嘴唇動作的不自然性。 技術層面上,檢測模型通常通過 3D CNN 或 Transformer 等結構,對視頻序列中的時序特征進行編碼和建模,進而捕獲連續幀之間的異常變化。這種方法能夠補充單幀視覺分析的不足,顯著提升對高質量偽造視頻的識別能力。同時,為滿足實際業務中毫秒級實時檢測的需求,還會采用模型蒸餾、量化壓縮或輕量級網絡設計等策略,以減少檢測延遲并提高性能表現。

從技術生態和模型演進的角度來看,為了應對不斷出現的新型偽造方法,現有檢測系統通常會部署持續的增量學習機制(Incremental Learning),不斷吸納新樣本進行在線訓練與模型更新。這種動態調整的機制使得模型能更快速地適應攻擊方法的變種,避免因技術滯后造成的安全漏洞。
上述這些技術方法的組合形成了一套完整的視頻鑒偽管道,具備較高的泛化能力和實時檢測能力,能夠有效應對實際業務場景中大規模深度偽造視頻的威脅。
二、AIGC 圖像鑒別:假畫無處遁形
? 生成式人工智能(AIGC)技術日益成熟,生成的圖像質量也越來越高,傳統的單一維度圖像檢測手段(例如單純的頻譜分析或紋理檢測)難以應對新型生成圖像的挑戰。因此,當前行業內圖像鑒別技術開始向多維特征融合的方向發展,合合信息的AIGC圖像鑒別技術便是這種趨勢下的典型實踐之一。

多模態語義分析
大語言模型的快速發展使得視覺語義推理技術變得更加成熟。技術人員可以通過構建一系列提示指令(prompt),來指導模型對生成圖像的邏輯合理性進行分析。例如,模型通過分析圖像中的透視關系、光影的一致性,以及場景語義的邏輯性,評估畫面的真實性。這種方式彌補了傳統圖像檢測中語義分析缺乏的問題,使得模型能從語義層面檢測偽造痕跡。
頻域高低頻特征融合
除語義分析外,頻域分析也在圖像鑒別技術中發揮了重要作用。生成圖像往往在高頻域會留下不自然的偽造痕跡,如重復的細節、特定的偽影和噪聲。合合信息技術團隊通過傅里葉變換等頻域方法,將圖像轉換到頻譜空間,重點分析高低頻譜的幅值譜和相位譜,并結合空間域的視覺特征進行多維融合判斷。這種方法在圖像被壓縮、裁剪或上傳至網絡平臺后仍能有效檢測出偽造痕跡,增強了模型的魯棒性。
對抗訓練與泛化性能優化
為了提高檢測技術對未知生成圖像類型的泛化性能,技術團隊在訓練模型時采用了對抗樣本訓練(Adversarial Training)。通過引入具有代表性的多種生成模型(如MidJourney、Stable Diffusion、StyleGAN、GPT-4o等)的圖像,以及通過對抗網絡生成難例樣本,迫使檢測模型學習更廣泛的偽造特征。此外,通過模型融合與投票機制,降低單模型的識別偏差,提高整體模型的準確性和泛化能力。
憑借這種語義理解與頻譜分析結合的策略,該技術在樣本集上的鑒定準確率超過 90%,而毫秒級的推理效率意味著它可以嵌入社交平臺內容治理或商業風控系統,實時過濾海量圖片。
三、TextIn 通用篡改檢測平臺:技術架構與應用邏輯
日常文檔(如身份證、發票、合同)的篡改雖然技術門檻不高,但因涉及個人隱私、財務安全,技術難度反而較大。為解決這一問題,TextIn平臺基于深度神經網絡和模塊化的系統架構,實現了針對文檔篡改的高效準確檢測。

模塊化檢測架構
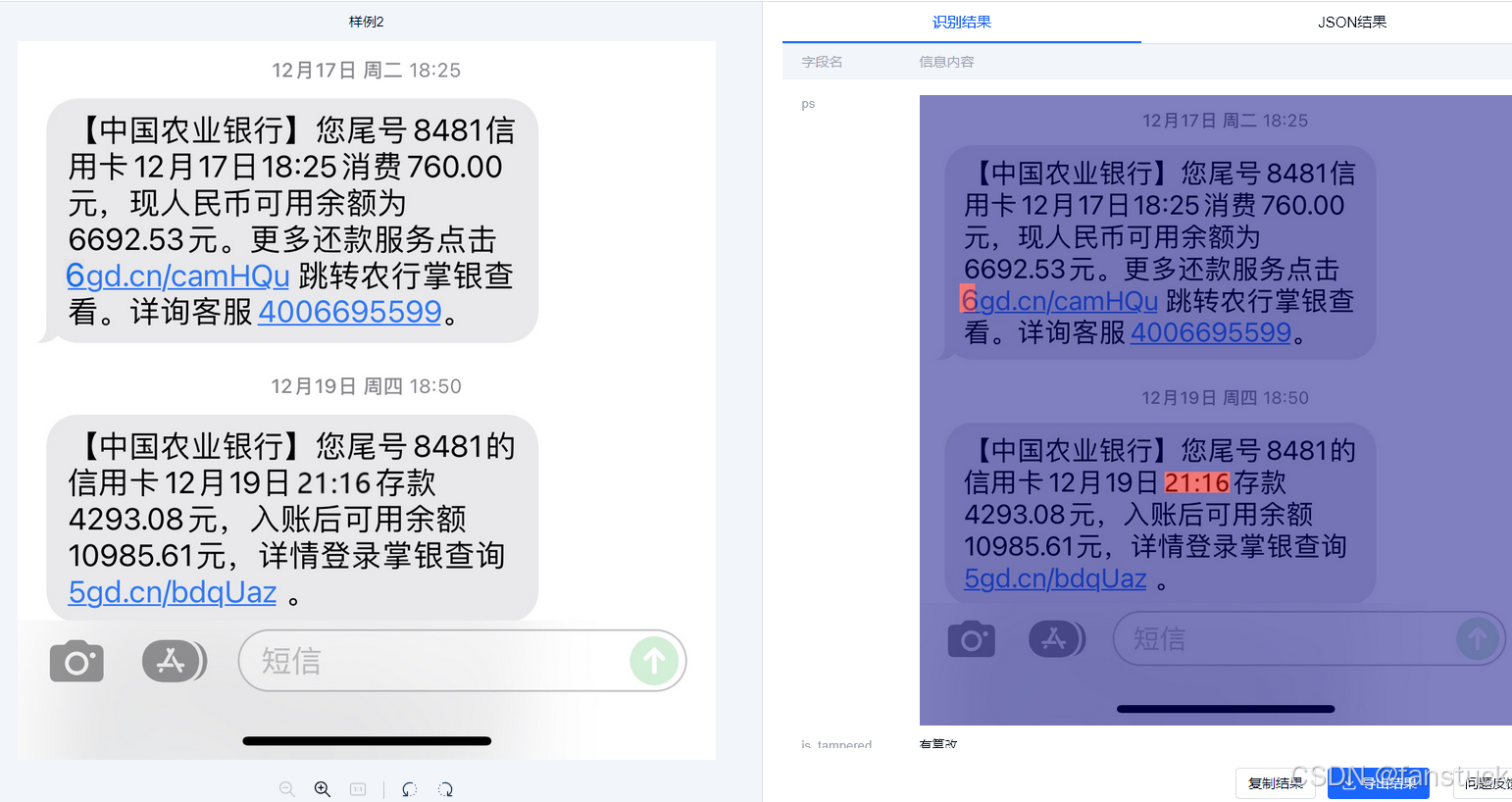
TextIn平臺采用模塊化技術架構,將整個檢測過程分為快速粗檢和精細像素級檢測兩個階段。粗檢階段使用輕量化網絡快速篩選出存在篡改嫌疑的文檔;精細檢測階段則對疑似文檔區域進行像素級分析,準確定位具體的篡改區域。
動態閾值調節技術
考慮到實際業務場景對誤檢率和召回率的不同需求,技術團隊引入了動態閾值調整機制。開發人員可以根據不同業務需求靈活調整檢測靈敏度,從而精確控制檢測結果在敏感度與準確性之間的平衡,顯著降低了誤檢率,滿足多種業務場景的實際需求。

多模態交叉驗證
單純視覺信息往往難以獨立支撐高度可靠的篡改鑒定。因此,技術團隊通過結合OCR字符識別技術與業務規則校驗實現跨模態的交叉驗證。以發票檢測為例,通過OCR識別出關鍵信息如發票號碼,再與官方稅務平臺或第三方數據源進行交叉核驗,這種融合視覺與語義的多模態鑒別技術進一步提高了鑒偽結果的可靠性。
上述這些技術實現手段,共同構成了一個完整的、適用于多種應用場景的通用文檔篡改檢測平臺。
? 更值得一提的是,這個平臺并不只是一個“演示工具”,而是經受住了實際業務的考驗。比如某大型銀行在貸款審核系統中接入了該模型,成功識別出偽造票據并幫助客戶減少了 80% 的潛在風險。在銀行票據審核、保險理賠材料驗證、證券資質文件校驗等場景中,文檔量大、版式復雜,TextIn 依靠百萬級數據訓練可以在毫秒內完成一次鑒定,誤檢率低至千分之一。正因為實戰表現出色,它已經在金融、零售、互聯網等多行業落地,成為企業提升內容真實性的基礎設施。
四、技術實力與行業標準:從競賽冠軍到標準制定者
技術的發展離不開持續的實踐和行業共識。在過去幾年,圖像篡改檢測領域涌現了眾多技術挑戰賽,這些競賽為各個供了公平而嚴格的環境,以驗證和提升自身算法的有效性。合合信息在多次技術比賽中表現優異,通過參與這些賽事,不僅檢驗了團隊的技術能力,也積累了豐富的實踐經驗。技術團隊提
例如,在 2022 年的真實場景篡改圖像檢測挑戰賽中,合合信息團隊依靠穩健的模型設計和深度學習技術,成功處理了復雜的真實場景數據;2023 年,在 ICDAR DTT 競賽中,他們以較低的誤檢率和較高的召回率取得佳績;同年,在 AFAC 金融數據驗真賽上,通過嚴謹的模型結構設計和訓練策略有效地處理了金融場景中的文檔篡改問題;2024 年,團隊在全球 AI 攻防挑戰賽中展現了出色的泛化能力和抗攻擊性。
除賽事之外,合合信息也在推動技術規范化方面做出了貢獻。2024 年 10 月,他們聯合中國信通院以及多家高校、研究機構共同起草了《文本圖像篡改檢測系統技術要求》,明確了行業的技術標準和規范。標準中包含了檢測數據集的構建原則、模型訓練的技術細節、結果評估方法等具體內容。這一標準的建立為后續行業內技術交流、模型比對和成果驗證提供了清晰統一的依據。
五、前景與挑戰:AI安全賽道上的長跑者
此次WAIC所展示的視覺內容安全技術,體現了當前AI鑒偽技術從單一模態向多模態、多場景應用的趨勢。人臉視頻篡改檢測、AIGC圖像鑒別和文檔篡改檢測已成為視覺安全領域的重要研究方向。
然而,AI偽造技術本身也在不斷演進,未來的技術挑戰依舊嚴峻。深度偽造算法在質量和生成效率上持續提升,對鑒偽技術提出了更高的實時性和準確性要求。同時,新興的應用場景如實時流媒體、沉浸式虛擬現實(VR)、增強現實(AR)等領域,也亟需更高效、更精準的檢測方案。
此外,AI鑒偽技術在實際應用中還需兼顧倫理與隱私保護。如何在實現精準鑒偽的同時,不侵犯個人隱私,并合理使用數據,仍然是技術實施中的重要課題。未來,行業技術人員與監管部門需要共同探索解決方案,確保技術應用的合法合規性。
總體而言,AI視覺內容鑒偽技術將繼續向多模態融合、實時高效檢測、泛化性能增強等方向發展,并持續推動行業技術標準的完善與統一。這不僅能有效提升整體安全生態的可靠性,也為產業界帶來更加可信的技術環境。

?











創建第一個Shader項目)

的組成詳解)
)




