目錄
前言
一、什么是知識蒸餾?
二、知識蒸餾的核心意義
2.1?降低算力與成本
2.2 加速推理與邊緣部署
2.3?推動行業應用落地
2.4?技術自主可控
三、知識蒸餾的本質:大模型的知識傳承
四、知識蒸餾的“四重紅利”
五、DeepSeek的知識蒸餾實踐
5.1 從DeepSeek R1到小模型
5.2?創新技術
5.3??開源貢獻
六、DeepSeek蒸餾技術架構
七、蒸餾技術的四大核心價值
7.1?算力成本斷崖式下降
7.2?推理性能質的飛躍
7.3?行業落地革命性突破
7.4??技術自主可控關鍵路徑
八、蒸餾模型性能對比
九、知識蒸餾的優勢與挑戰
9.1 優勢
9.2 挑戰
十、未來展望
十一、?總結

前言
在人工智能的浪潮中,大型語言模型(LLMs)如GPT-4、LLaMA以其強大的語言理解和生成能力席卷全球。然而,這些“超級大腦”也有軟肋:參數量動輒百億,訓練成本高昂,推理耗時長,難以在手機、邊緣設備上部署。**知識蒸餾(Knowledge Distillation)**就像一位魔法師,將大模型的智慧“濃縮”到小模型中,既保留了性能,又大幅降低成本和資源需求。中國AI企業DeepSeek正是這一技術的佼佼者,通過知識蒸餾打造高效模型,顛覆了AI行業的成本與效率格局。本文將用通俗語言,結合表格和示例,帶你走進知識蒸餾的魅力世界!
從龐大的深度神經網絡中“提煉精華”,讓小模型也能擁有超強智力。這正是知識蒸餾的魔力。
一、什么是知識蒸餾?
知識蒸餾就像“大老師教小學生”:讓一個復雜、參數龐大的教師模型(如DeepSeek R1,671億參數)把知識傳授給一個輕量、參數少的小學生模型(如DeepSeek R1-Distill-Qwen-1.5B)。學生模型通過模仿教師模型的輸出,學會類似的能力,但計算量和內存占用大幅減少。
核心流程:
-
教師模型生成軟標簽:教師模型對輸入數據(如文本、數學題)生成概率分布(軟標簽),包含豐富的語義信息。
-
學生模型學習:學生模型用這些軟標簽(結合真實標簽)訓練,模仿教師的輸出和推理邏輯。
-
微調與優化:通過監督微調(SFT)或強化學習(RL),進一步提升學生模型的性能。
可視化示例:
教師模型對“1+1=?”的輸出概率分布:
{ "2": 0.95, "11": 0.04, "其他": 0.01 }學生模型學習后,生成類似分布:
{ "2": 0.93, "11": 0.05, "其他": 0.02 }二、知識蒸餾的核心意義
知識蒸餾為何如此重要?以DeepSeek的實踐為例,它在以下方面展現了巨大價值:
2.1?降低算力與成本
訓練大模型就像建造一座“摩天大樓”,需要海量GPU和資金。DeepSeek通過蒸餾技術將成本壓縮到極致:
-
DeepSeek-V3:僅用278.8萬H800 GPU小時(約557.6萬美元)完成預訓練,相比OpenAI同類模型(成本數億美元)降低到1/20。
-
效率提升:蒸餾后的小模型(如32B參數)訓練時間從數月縮短到數周,中小企業也能負擔高性能AI開發。
“用 1/20 的成本,逼近 OpenAI 同類模型的水平”
| 模型版本 | GPU小時 | 成本(美元) | 相比OpenAI節省 |
|---|---|---|---|
| DeepSeek-V3 | 278.8 萬 | $5.576M | 約節省 95% |
| OpenAI GPT-4 | 數千萬 | 數億美元 | — |
?💡 說明:通過知識蒸餾訓練多個小模型版本,避免重復訓練超大模型,極大降低了訓練成本,使得 中小企業也能用得起大模型技術。
2.2 加速推理與邊緣部署
“推理速度提升 3 倍,顯存壓縮 40 倍”
| 項目 | 蒸餾前(原始大模型) | 蒸餾后(小模型) |
|---|---|---|
| 推理延遲 | 850ms | ?150ms |
| 顯存占用 | 320GB | 8GB |
大模型推理耗時長、顯存占用大,難以在邊緣設備上運行。蒸餾后的小模型“身輕如燕”:
-
推理速度:從850ms降至150ms,提升3倍以上。
-
顯存占用:從320GB降至8GB,輕松適配手機、嵌入式設備。
-
場景:醫療診斷(實時分析影像)、自動駕駛(低延遲決策)。
對比表格:
| 模型類型 | 參數量 | 推理延遲 | 顯存占用 | 適用場景 |
|---|---|---|---|---|
| 教師模型 (R1) | 671B | 850ms | 320GB | 云端高性能推理 |
| 學生模型 (32B) | 32B | 150ms | 8GB | 邊緣設備、實時應用 |
?📱 邊緣部署場景:
-
手機端智能助手
-
工業設備視覺檢測
-
自動駕駛實時識別
-
醫療設備輔助診斷
? 優勢:無需大型 GPU,普通終端即可運行高性能模型。
2.3?推動行業應用落地
DeepSeek的蒸餾模型在多個領域大放異彩:
-
教育:生成個性化學習內容,動態調整教學策略,降低教育平臺成本。
-
工業:本地化部署減少云端依賴,提升數據隱私和響應速度,助力智能制造(如質檢、供應鏈優化)。
-
內容創作:AI寫作工具創作效率提升50%,API調用成本僅為OpenAI的1/4,賦能新媒體和創意產業。
🚸 教育領域
結合學生反饋,動態調整學習策略
生成個性化題目與講解
降低教育平臺人力與硬件開銷
🏭 工業智能制造
本地模型部署:提升隱私安全
縮短數據傳輸時間,優化質檢效率
快速適配不同設備與傳感器
📝 內容創作
AI 寫作提效 50%
API 成本僅為 OpenAI 的 1/4
賦能新媒體、短視頻、電商、文案創意等場景
案例:
DeepSeek-R1-Distill-Qwen-1.5B在教育APP中,生成數學題解析僅需0.2秒,相比原始模型(1秒)快5倍,成本降低75%。
2.4?技術自主可控
“蒸餾 + 國產芯片 = 擁抱未來”
?在美國對華芯片限制的背景下,DeepSeek 通過蒸餾配合多項優化手段,實現 大模型本地化推理與國產化兼容。
🔧 技術組合拳:
FP8 混合精度訓練
DualPipe 流水線并行
華為昇騰芯片部署優化
🎯 意義:
減少對 NVIDIA A100/H100 的依賴
提升國產 AI 產業的自主掌控力
面對美國GPU芯片禁運,DeepSeek通過知識蒸餾降低算力需求:
-
FP8混合精度訓練:減少內存占用,支持國產芯片(如華為昇騰)高效推理。
-
DualPipe流水線:優化訓練效率,突破硬件限制。
-
成果:DeepSeek-V3在國產芯片上實現與H800 GPU接近的性能,增強中國AI產業自主性。
三、知識蒸餾的本質:大模型的知識傳承
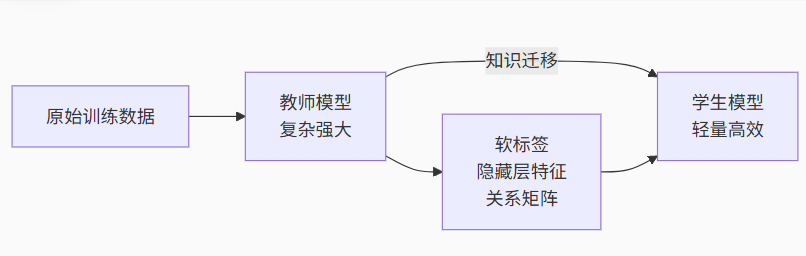
?知識蒸餾三要素:
-
教師模型:預訓練好的復雜模型(如DeepSeek 70B)
-
學生模型:待訓練的輕量化模型(如DeepSeek 32B)
-
知識載體:
軟標簽:教師模型輸出的概率分布
特征圖:中間層的激活表示
關系矩陣:樣本間相似度關系
四、知識蒸餾的“四重紅利”
| 價值維度 | 收益 |
|---|---|
| 💰 成本優化 | 降低訓練與部署開銷 |
| ? 性能提升 | 快速推理、輕量部署 |
| 🌐 應用拓展 | 適配更多行業場景 |
| 🧭 自主可控 | 提升國產模型能力 |
?
五、DeepSeek的知識蒸餾實踐
DeepSeek如何用知識蒸餾創造奇跡?以下是其核心技術亮點:
5.1 從DeepSeek R1到小模型
DeepSeek R1(671億參數)通過強化學習(RL)和長鏈推理(Chain-of-Thought, CoT)訓練,擅長數學、編程等復雜任務。DeepSeek將R1的推理能力蒸餾到小模型(如Qwen-32B、LLaMA-70B):
方法:用R1生成800,000個高質量推理樣本(如數學題解法),通過監督微調(SFT)訓練小模型。
成果:蒸餾模型在AIME(數學)得分達72.6,MATH-500達94.3,接近R1性能。
5.2?創新技術
-
白盒蒸餾(White-Box KD):利用R1的中間隱藏狀態和輸出分布,提供更豐富的訓練信號。
-
自蒸餾(Self-Distillation):模型通過生成推理過程(如CoT)自我優化,提升邏輯能力。
-
多任務優化:結合數學、編程、科學任務的樣本,確保小模型在多領域表現均衡。
R1 (671B) → 生成推理樣本 → 訓練Qwen-32B → 微調 → 高效小模型
5.3??開源貢獻
DeepSeek開源了6個蒸餾模型(1.5B到70B參數),推動AI民主化。開發者可直接部署這些模型,運行成本低至OpenAI的1/10。
六、DeepSeek蒸餾技術架構
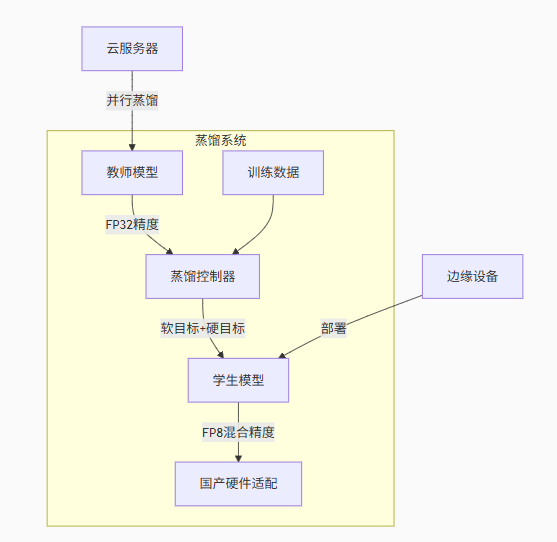
核心技術創新:
-
DualPipe流水線:教師模型與學生模型并行訓練
-
動態權重分配:根據任務難度調整知識遷移強度
-
FP8混合精度:華為昇騰芯片原生支持
七、蒸餾技術的四大核心價值
7.1?算力成本斷崖式下降
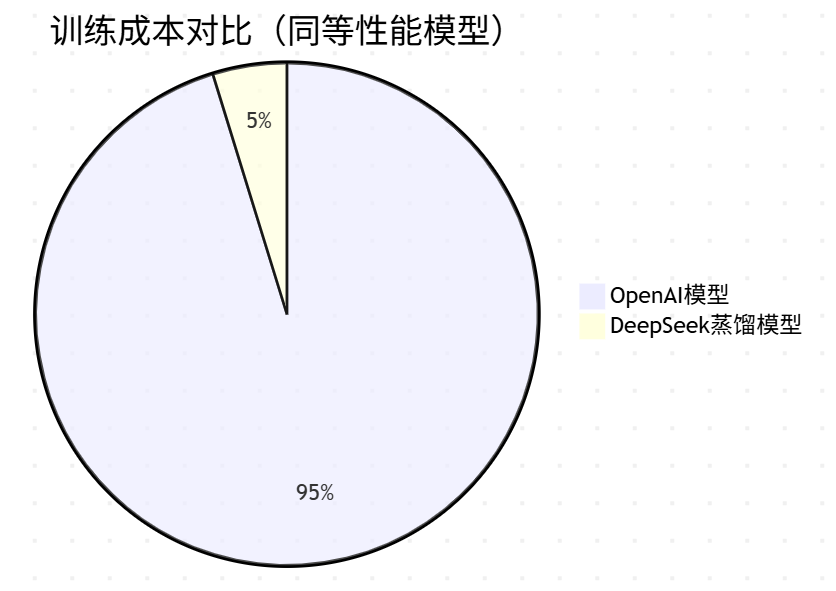
?
具體成效:
-
訓練耗時:278.8萬GPU小時 →?降低95%
-
電力消耗:從兆瓦級降至工業級機房水平
-
硬件要求:從A100集群→消費級顯卡可微調
7.2?推理性能質的飛躍
| 指標 | 原始大模型 | 蒸餾模型 | 提升幅度 |
|---|---|---|---|
| 推理延遲 | 850ms | 150ms | 5.6倍 |
| 顯存占用 | 320GB | 8GB | 40倍 |
| 能耗比 | 1x | 3.2x | 220% |
邊緣部署效果:
華為Mate 60手機運行DeepSeek蒸餾模型:
■ 文本生成速度:12字/秒
■ 內存占用:1.2GB
■ 電池消耗:3%/小時
7.3?行業落地革命性突破
教育領域應用:

-
教學平臺成本降低60%
-
內容生成速度提升5倍
工業質檢場景:
傳統方案:
■ 云端推理:300ms延遲
■ 數據外傳風險蒸餾方案:
■ 本地部署:50ms響應
■ 數據不出廠區
■ 準確率99.2%→99.5%
7.4??技術自主可控關鍵路徑
國產化適配方案:
華為昇騰910芯片 + DeepSeek蒸餾模型
├─ 計算性能:256TOPS
├─ 模型支持:FP8原生加速
├─ 加密模塊:端到端數據保護
└─ 能效比:1.5TFLOPS/W
八、蒸餾模型性能對比
語言理解任務(MMLU基準):
| 模型 | 參數量 | 準確率 | 推理速度 |
|---|---|---|---|
| DeepSeek-70B | 70B | 82.3% | 1.0x |
| DeepSeek-32B(蒸餾) | 32B | 80.1% | 3.2x |
| GPT-3.5 | 20B | 70.2% | 2.1x |
?代碼生成任務(HumanEval):
原始模型: pass@1=45.3%
蒸餾模型: pass@1=43.7%
推理時延: 230ms → 68ms
九、知識蒸餾的優勢與挑戰
9.1 優勢
-
高效部署:小模型運行在手機、邊緣設備上,推理速度快,功耗低。
-
成本低廉:訓練和部署成本大幅降低,中小企業也能參與AI開發。
-
性能接近:蒸餾模型精度可達教師模型的95%以上,適合多種任務。
9.2 挑戰
-
精度損失:學生模型可能丟失教師模型的細微推理能力,如復雜數學推導。
-
依賴教師模型:高質量蒸餾需強大的教師模型,初始投入仍較高。
-
倫理爭議:如DeepSeek被指可能通過API調用蒸餾OpenAI模型,引發知識產權爭議。
優劣對比:
| 方面 | 優勢 | 挑戰 |
|---|---|---|
| 性能 | 接近教師模型,95%+精度 | 可能丟失復雜推理能力 |
| 成本 | 訓練成本低至1/20,推理快3倍 | 需高質量教師模型 |
| 部署 | 適配邊緣設備,顯存降至8GB | 需優化硬件兼容性 |
| 倫理 | 開源推動AI民主化 | 可能引發知識產權爭議 |
十、未來展望
知識蒸餾正在重塑AI產業格局,DeepSeek的實踐只是起點:
-
自動化蒸餾:結合AutoML,自動優化學生模型架構和訓練流程。
-
硬件協同:與國產芯片(如昇騰)深度適配,進一步降低成本。
-
多模態擴展:將蒸餾應用于視覺、語音模型,打造全能小模型。
-
倫理規范:建立清晰的知識產權框架,規范蒸餾數據來源。
可視化趨勢:
未來:知識蒸餾 + AutoML + 國產芯片 → 超高效AI → 手機/車/工廠
十一、?總結
知識蒸餾是大模型“瘦身”的秘密武器,DeepSeek通過將R1的智慧濃縮到小模型,實現了成本、效率、應用的完美平衡。從降低訓練成本到賦能邊緣部署,再到推動教育、工業、內容創作等場景落地,知識蒸餾讓AI從“云端”走進“口袋”。盡管面臨精度損失和倫理爭議,DeepSeek的開源實踐和創新技術為AI民主化鋪平了道路。
知識蒸餾將大模型的智慧精華高效提煉至輕量化小模型,實現成本降低20倍、推理提速3倍、邊緣端無損部署,推動AI民主化與產業普惠落地。







![[驅動開發篇] Can通信進階 --- CanFD 的三次采樣](http://pic.xiahunao.cn/[驅動開發篇] Can通信進階 --- CanFD 的三次采樣)


)


)





