DML?等術語概念
DML(Data?Manipulation Language,數據操縱語言):?DML主要用于插入、更新、刪除和查詢數據庫中的數據。常見的DML語句包括:
- INSERT:用于向表中插入新的數據行。
- UPDATE:用于修改表中的數據。
- DELETE:用于刪除表中的數據行。
- SELECT:用于從表中查詢數據。
DDL(Data?Definition Language,數據定義語言):?DDL主要用于創建、修改和刪除數據庫中的表結構。常見的DDL語句包括:
- CREATE:用于創建數據庫、表、視圖等。
- ALTER:用于修改數據庫、表、視圖等結構。
- DROP:用于刪除數據庫、表、視圖等。
DCL(Data Control Language,數據控制語言):?DCL主要用于控制不同數據的訪問權限。常見的DCL語句包括:
- GRANT:用于授予用戶操作權限。
- REVOKE:用于撤銷用戶操作權限。
TCL(Transaction Control Language,事務控制語言):?TCL主要用于管理數據庫中的事務。常見的事務控制語句包括:
- COMMIT:用于提交事務,即將事務中的所有操作永久保存到數據庫中。
- ROLLBACK:用于回滾事務,即撤銷事務中的所有操作。
- SAVEPOINT:用于在事務中設置一個保存點,可以回滾到該保存點。
事務
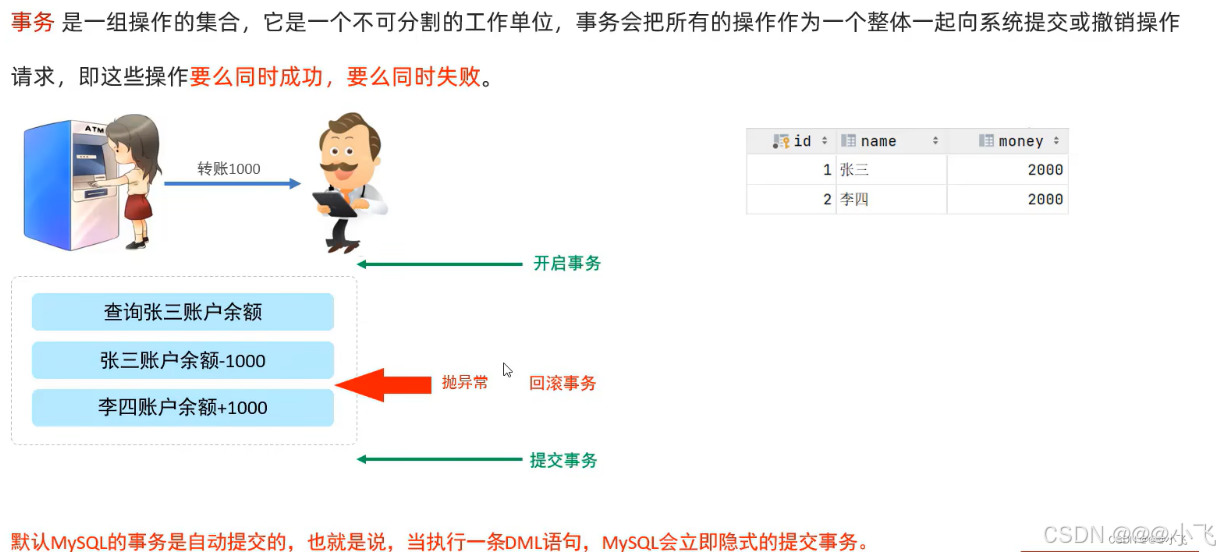
事務四大特性:
原子性(Atomicity):事務是不可分割的最小操作單元,要么全部成功,要么全部失敗。
一致性(Consistency):開始之前和事務結束之后,數據庫的完整性約束(如主鍵約束、外鍵約束、唯一約束等)都必須得到滿足。
隔離性(lsolation):數據庫系統提供的隔離機制,保證事務在不受外部并發操作影響的獨立環境下運行
持久性(Durability):事務一旦提交或回滾,它對數據庫中的數據的改變就是永久的。


分別對應中文:讀未提交、讀已提交、可重復讀、可串行化
臟讀、幻讀和不可重復讀是數據庫事務處理中可能出現的三種并發控制問題,它們都與事務的隔離級別和并發執行有關。
**臟讀(Dirty Read)**發生在當一個事務讀取了另一個尚未提交的事務的修改數據。具體來說,當事務A正在修改數據但還沒有提交時,事務B讀取了事務A尚未提交的修改數據。如果事務A最終回滾了它的修改,那么事務B所讀取的數據就是無效的或“臟”的。臟讀可能導致數據的不一致性和錯誤的結果。
**不可重復讀(Non-repeatable Read)**是指在一個事務內,多次讀取同一數據,但由于其他事務的修改導致每次讀取的數據可能不同。例如,事務A首先讀取了某個數據項的值,然后事務B修改了該數據項并提交,當事務A再次讀取該數據項時,發現其值已經改變。不可重復讀破壞了事務的一致性,因為同一個事務中的多次讀取可能得到不同的結果。
**幻讀(Phantom Read)**是指在一個事務內,同樣的查詢條件下,多次執行查詢得到的結果集不一致。這通常發生在其他事務向表中插入或刪除了符合查詢條件的記錄。例如,事務A執行了一個查詢,返回了某些記錄,然后事務B插入了一條新的記錄,這條新記錄符合事務A的查詢條件。當事務A再次執行相同的查詢時,會發現多了一條新的記錄,就好像出現了“幻影”一樣。
存儲引擎



默認innodb存儲引擎






索引


索引結構


B+Tree


(左小右大) 中間元素向上分且在葉子節點依舊保留并形成單向鏈表





引索分類





答:第一條sql效率高,因為第一條sql直接走聚集索引,第二條sql走二級索引之后再回表查詢
引索語法
#查看當前表的索引
show index from student;#創建常規引索(索引命名規范:idx_{{引索字段名}})
create index idx_student_name on student(name);#創建唯一引索(該列的值不能重復)
create unique index idx_student_phone on student(phone);#創建聯合索引
create index idx_id_name_phone on student(id, name, phone);#刪除索引
drop index idx_student_phone on student;
性能分析


一般在開發環境下開啟慢查詢,線上環境關閉慢查詢,因為開啟慢查詢會損耗一部分musql的性能
Windows慢查詢日志:LAPTOP-DHDL2KHM-slow.log

profile很少用
#查詢是否開啟profiling(檢查慢查詢的工具,0表示未開啟,1表示已開啟)
select @@profiling;#開啟profiling
set global profiling=1;#查詢執行的sql語句時間
show profiles;#查詢id為584的執行具體時間(for爆紅是idea問題)
show profile for query 584; ?
?

索引使用

如果最左邊的列不存在,引索失效,與sql語句的where條件順序無關

可以在業務允許時使>=符號








答:建立username和password的聯合索引




? 索引設計原則



SQL優化
數據插入優化


主鍵優化









order by 優化



group by 優化

limit 優化

覆蓋索引:指一個索引不僅能夠滿足查詢條件,還能夠覆蓋查詢結果中所有需要的數據,從而避免對表進行訪問的一種索引。(查詢的所有字段都在創建的索引字段中)
count 優化


updata 優化

注意:更新操作要根據索引更新,不然行鎖變表鎖,期間其他的用戶就不能更新,削弱并發能力
SQL優化總結

視圖
 虛擬存在的表,不保存查詢結果,只保存查詢的SOL邏輯、簡單、安全、數據獨立
虛擬存在的表,不保存查詢結果,只保存查詢的SOL邏輯、簡單、安全、數據獨立




/**視圖的基本簡單使用創建、修改、刪除、查詢、數據的增刪該*/-- 一會使用my_student作為基表
select * from my_student;-- 創建修改換視圖,將my_student表中性別為男的邏輯體提取出來,封裝成視圖
-- or replace 可選關鍵字,當視圖存在時,先刪除,再創建
create or replace view my_student_view as select * from my_student where gender = '男';-- 查詢視圖
select * from my_student_view;-- 修改視圖
-- 方式一:使用or replace關鍵字
create or replace view my_student_view as select * from my_student where gender = '女';
-- 方式二:
alter view my_student_view as select * from my_student where gender = '女';-- 刪除視圖,if exists:如果視圖不存在,不報錯
drop view if exists my_student_view;-- 向視圖插入數據:該數據其實是寫到基表my_student表中
insert into my_student_view values(7, '張無忌', 20, '男', '1');-- 刪除數據
delete from my_student_view where id = 7;-- ---------------------------------------------------
/**檢查選項 cascade: 級聯檢查,如果視圖1沒有加檢查選項,視圖2基于視圖1創建的視圖并加了檢查選項,那么操作視圖1也會檢查(相當于視圖1也加了檢查)檢查選項 local: 局部檢查,如果視圖1沒有加檢查選項,視圖2基于視圖1創建的視圖并加了檢查選項,那么操作視圖1時先檢查視圖1,再檢查視圖2(如果視圖1沒有檢查選項,那么不檢查,有則檢查)如果視圖2是cascaded,那么又會繼續檢查視圖2的基表...*/-- 創建一個基表為視圖的視圖并加上檢查選項cascaded,數據操作時檢查
create or replace view my_student_view2 as select * from my_student_view where id < 30 with cascaded check option;-- 向視圖插入數據:如果檢查發現不符合視圖創建的條件,就會報錯,不讓插入
-- my_student_view2的id < 30 檢查條件、my_student_view 的gender = '女' 檢查條件 同時檢查滿足才能插入
insert into my_student_view2 values(29, '張無忌', 20, '女', '1');-- 創建一個基表為視圖的視圖并加上檢查選項local,數據操作時檢查
create or replace view my_student_view3 as select * from my_student_view2 where id > 20 with local check option;-- 只檢查 my_student_view3 條件
insert into my_student_view3 values(21, '張三豐', 20, '女', '1');存儲過程
介紹

 事先定義并存儲在數據庫中的一段SQL語句的集合,減少網絡交互,提高性能、封裝重用
事先定義并存儲在數據庫中的一段SQL語句的集合,減少網絡交互,提高性能、封裝重用
基本語法



 如果在命令行中去執行創建語句要注意 ";" 號,命令行中會把 ";" 識別為結束符?
如果在命令行中去執行創建語句要注意 ";" 號,命令行中會把 ";" 識別為結束符?
-- 創建一個統計行數的存儲過程
create procedure p1()
beginselect count(*) from my_student;
end;-- 調用
call p1();-- 查看存儲過程
-- 方式一:根據存儲過程名查看
select * from information_schema.routines where routine_name = 'p1';
-- 方式二:根據數據庫名查看
select * from information_schema.routines where routine_schema ='study';
-- 方式三:
show create procedure p1;-- 刪除存儲過程
drop procedure if exists p1
變量
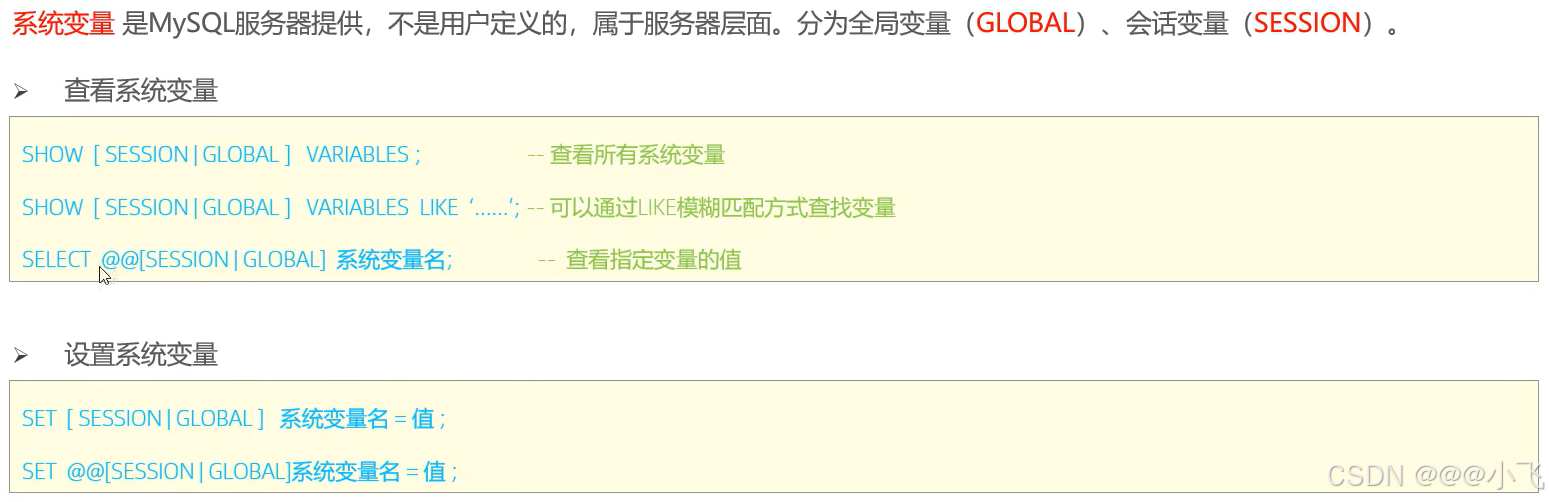
系統變量:

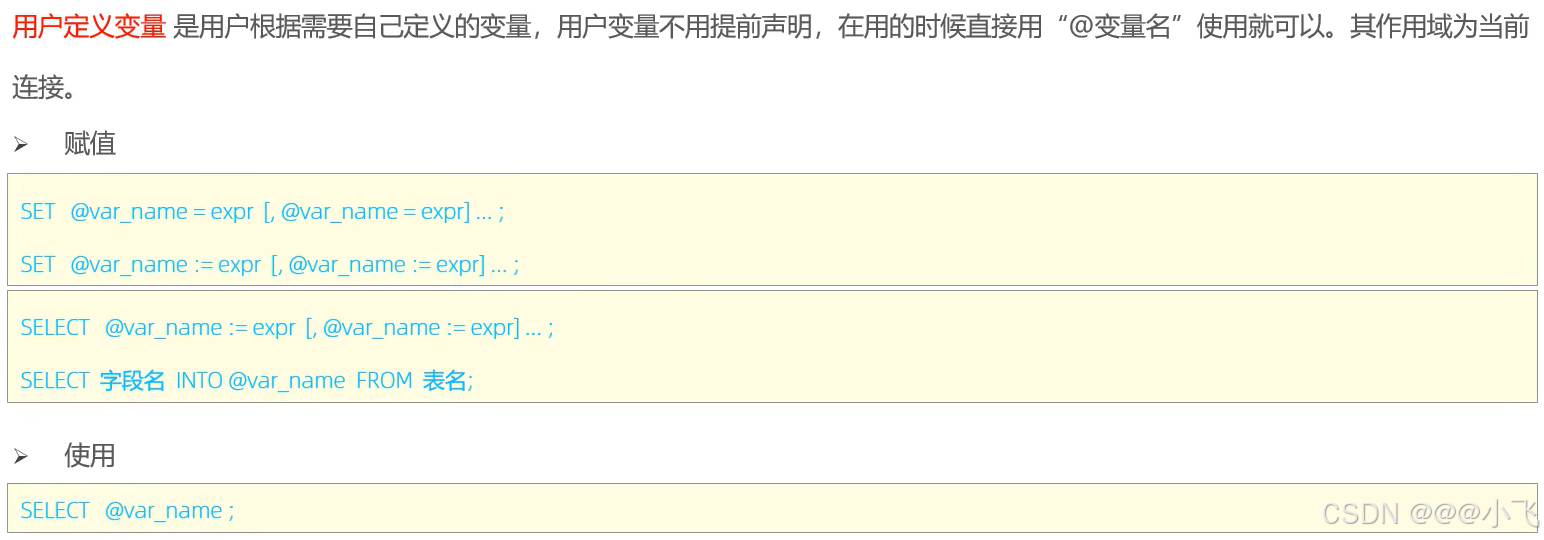
?用戶變量:

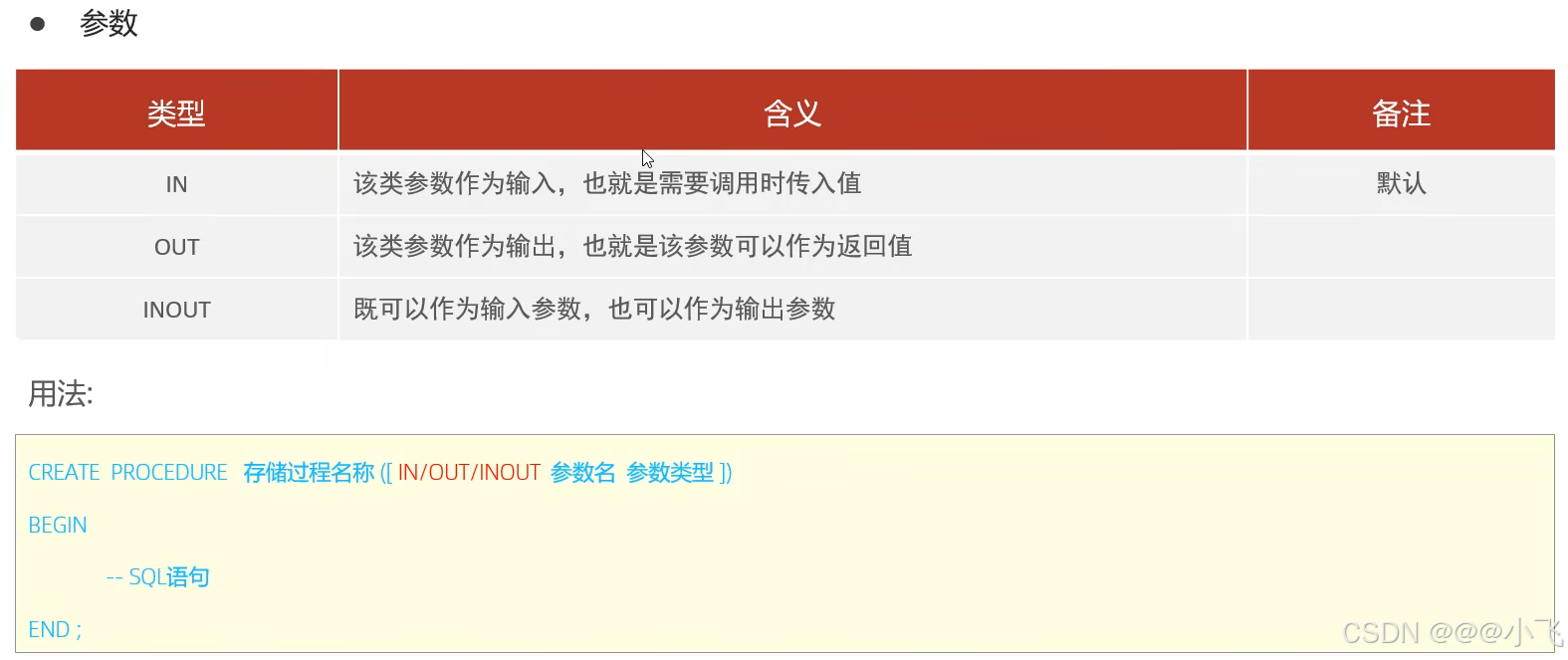
局部變量:

關鍵字if cursor while...
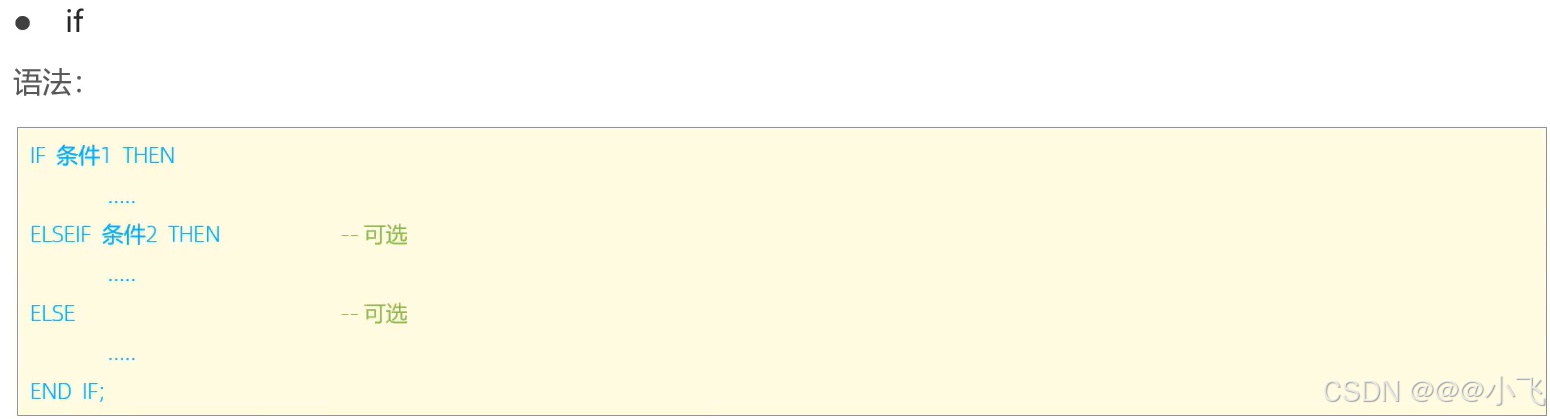
-- if語句,入參是score,int類型;出參是result,varchar類型
create procedure p3(in score int, out result varchar(10))
beginif score >= 85 thenset result := '優秀';elseif score >= 60 thenset result := '及格';elseset result := '不及格';end if;
end;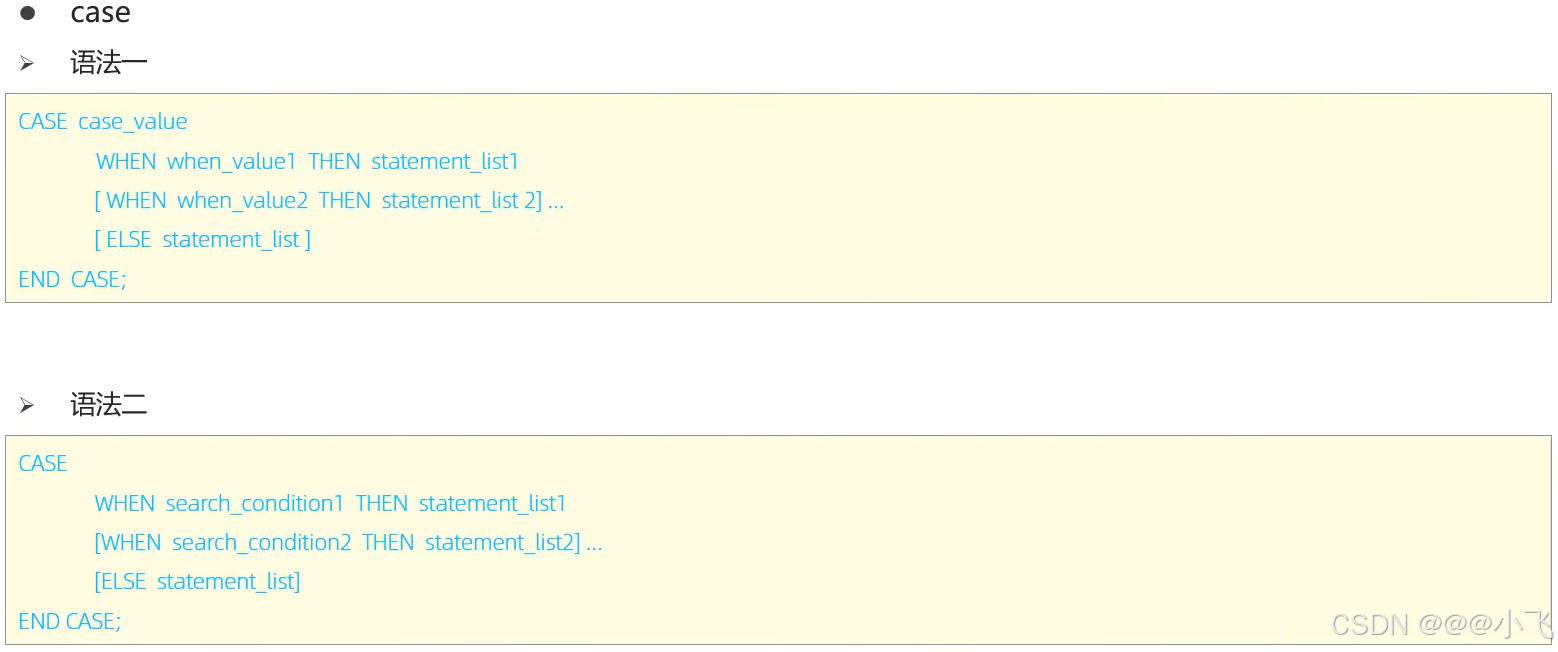
-- case語句
create procedure p5(in score int)
begindeclare result varchar(10);casewhen score >= 85 and score <=100 thenset result := '優秀';when score >= 60 thenset result := '及格';when score < 60 and score >=0 thenset result := '不及格';elseset result := '非法分數';end case;select concat('您的分數為:', score, ',等級為:', result);
end;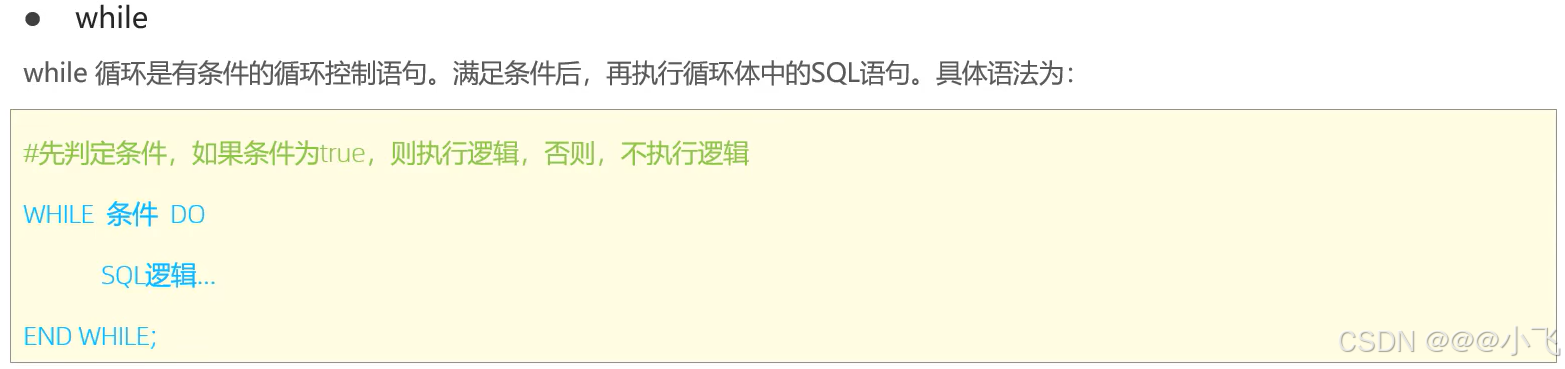
-- while循環語句,計算從1累加到n的和,n為入參
create procedure p6(in n int)
begindeclare total int default 0;while n > 0 doset total := total + n;set n := n - 1;end while;select concat('累加和為:', total);
end;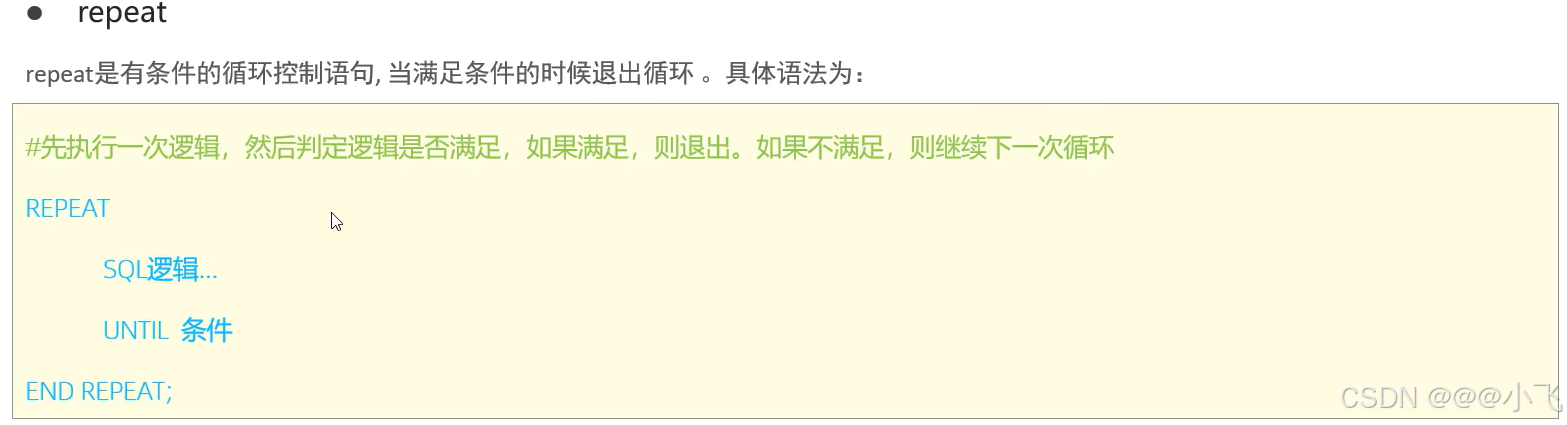
-- repeat循環語句,計算從1累加到n的和,n為入參
create procedure p7(in n int)
begindeclare total int default 0;repeatset total := total + n;set n := n - 1;until n <= 0 -- 退出條件end repeat;select concat('累加和為:', total);
end;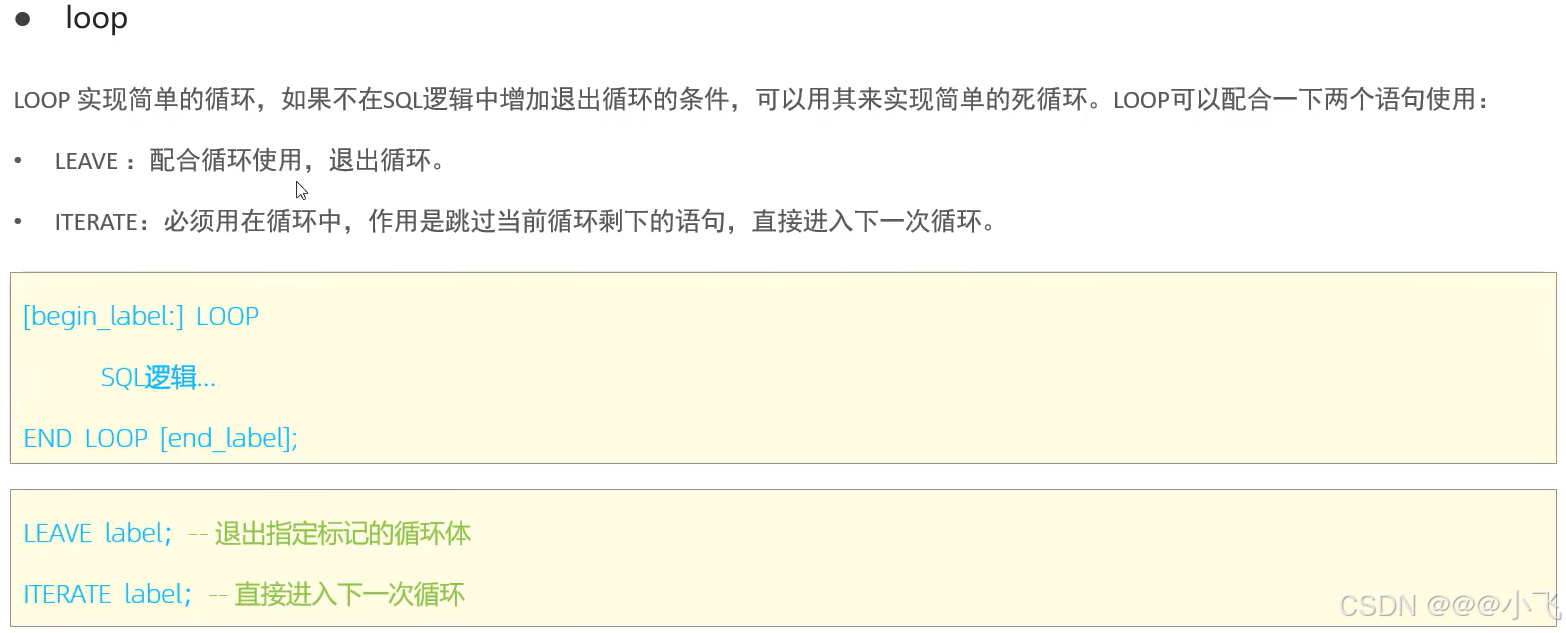
-- loop循環語句搭配leave和iterate,計算從1累加到n的奇數和,n為入參
create procedure p8(in n int)
begindeclare total int default 0;sum: loop -- 給循環起一個名字sumif n <= 0 thenleave sum; -- 退出循環end if;if n%2 = 1 thenset n := n - 1;iterate sum; -- 跳過本次循環,進入下一次循環end if;set total := total + n;set n := n - 1;end loop sum;select concat('累加和為:', total);
end;

-- cursor游標 and handler
create procedure p9()
begindeclare c_name varchar(50);declare c_age int;-- 將查詢結果集賦值給游標c1declare c1 cursor for select name, age from my_student where id > 5; -- 游標的定義需要放在其他變量的后面declare exit handler for sqlstate '02000' close c1; -- 定義handler:當遇到02000錯誤時,關閉游標c1drop table if exists my_student_cursor;create table if not exists my_student_cursor(id int auto_increment primary key,name varchar(50),age int);open c1; -- 打開游標while true dofetch c1 into c_name, c_age; -- 將游標指向的行的數據賦值給變量name和ageinsert into my_student_cursor values (null, c_name, c_age);end while;select * from my_student_cursor;
end;存儲函數
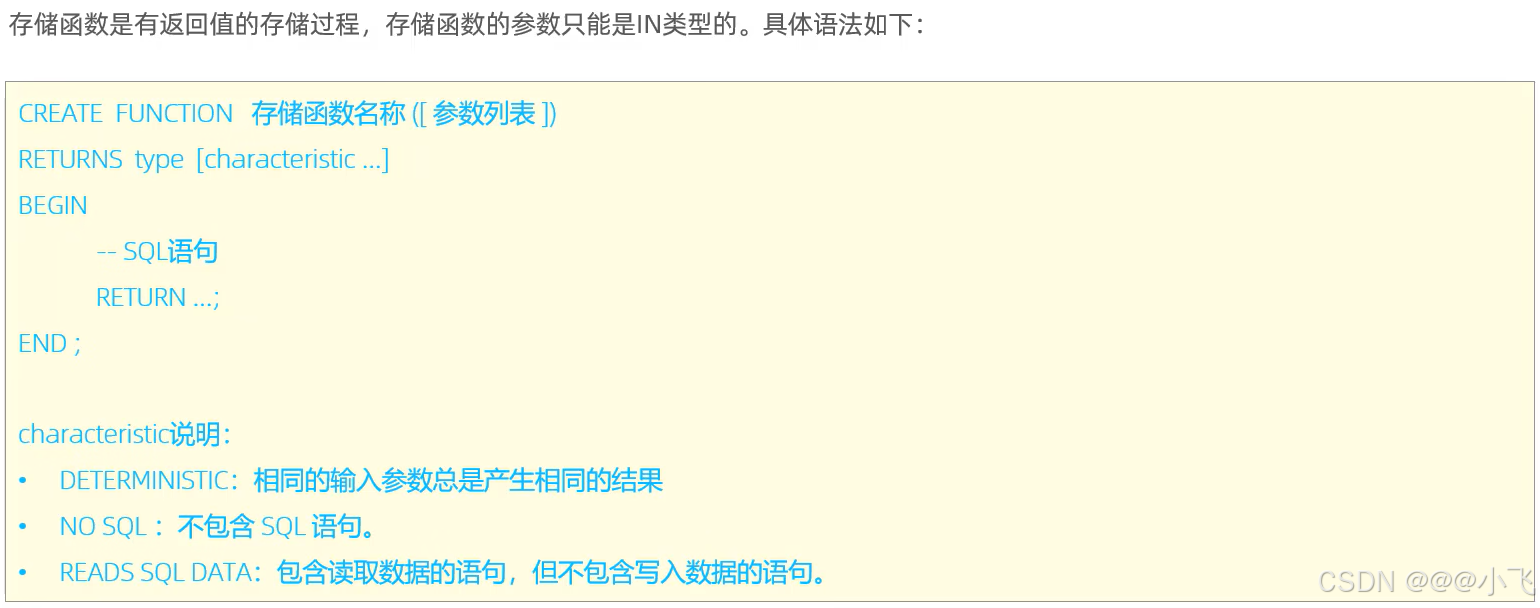 存儲函數是有返回值的存儲過程,參數類型只能為IN類型,存儲函數可以被存儲過程替代
存儲函數是有返回值的存儲過程,參數類型只能為IN類型,存儲函數可以被存儲過程替代
-- 定義存儲函數,必須是in,不能是out,默認是in,不寫也可以
create function f1(n int)
returns int deterministic -- 返回值類型,deterministic表示確定的,每次調用都會返回相同的結果
begindeclare total int default 0;while n > 0 doset total := total + n;set n := n - 1;end while;return total;
end;-- 查詢調用
select f1(100);
存儲函數用得少一點,因為存儲函數必須要求又入參,而且存儲函數能做到,存儲過程都可以做。
觸發器
介紹:
 可以在表數據進行INSERT、UPDATE、DELETE之前或之后觸發、保證數據完整性、日志記錄、數據校驗
可以在表數據進行INSERT、UPDATE、DELETE之前或之后觸發、保證數據完整性、日志記錄、數據校驗
語法:?
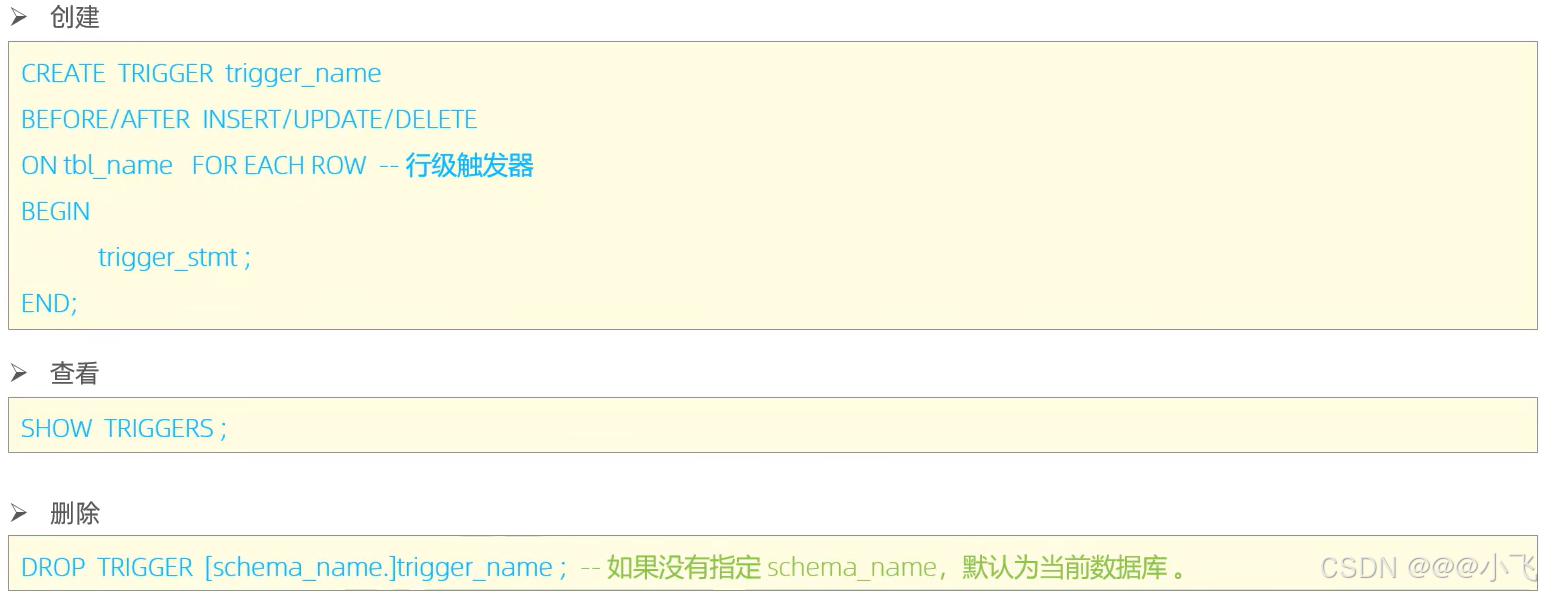
-- 觸發器-insert,
create trigger insert_student after insert on my_student for each row
begin-- 當my_student表插入數據時,執行該sql語句insert into trigger_logs(id, operation, operate_time, operate_id, operate_params)values (null, 'insert', now(), new.id,concat('插入的數據內容為:id=',new.id , ',name:', new.name, ',age:', new.age, ',gender:', new.gender, ',class_id:', new.class_id));
end;-- 查看
show triggers;-- 觸發器-update
create trigger update_student after update on my_student for each row
begininsert into trigger_logs(id, operation, operate_time, operate_id, operate_params)values (null, 'update', now(), new.id,concat('更新之前的數據:id=',old.id , ',name:', old.name, ',age:', old.age, ',gender:', old.gender, ',class_id:', old.class_id,'更新之后的數據:id=',new.id , ',name:', new.name, ',age:', new.age, ',gender:', new.gender, ',class_id:', new.class_id));
end;-- 觸發器-delete
create trigger delete_student after delete on my_student for each row
begininsert into trigger_logs(id, operation, operate_time, operate_id, operate_params)values (null, 'delete', now(), old.id,concat('刪除之前的數據:id=',old.id , ',name:', old.name, ',age:', old.age, ',gender:', old.gender, ',class_id:', old.class_id));
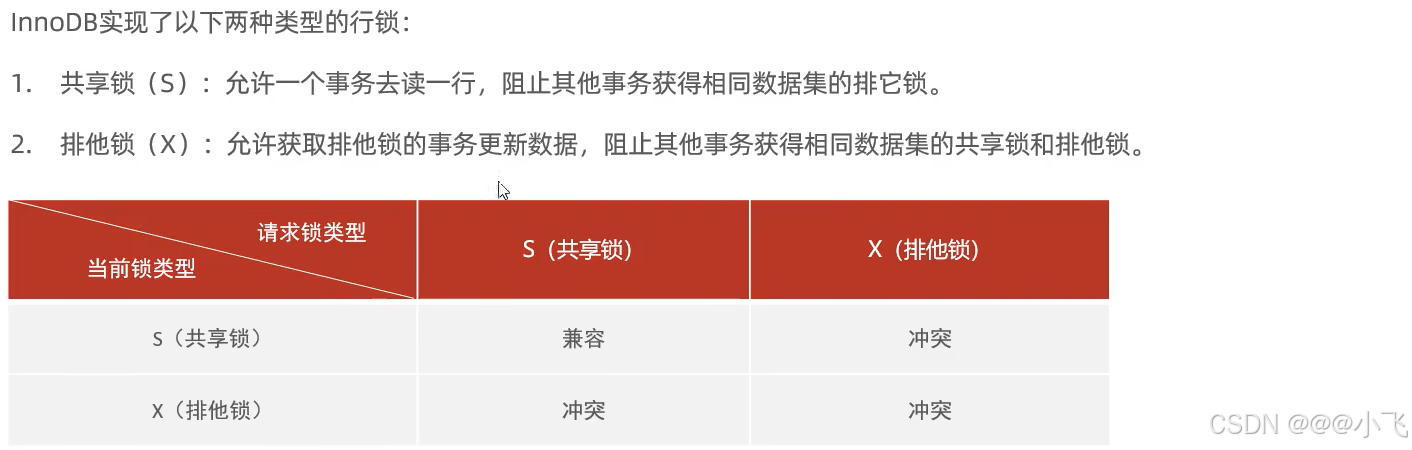
end;鎖
介紹:


全局鎖

flush tables with read lock; -- 加全局鎖
-- 導出數據,這個命令不是SQL語句,是MySQL提供的工具,需要在命令行執行
# mysqldump -h localhost -uroot -pmysql123456 study > E:\java\study\mysql\src\main\resources\sql\study.sql;
unlock tables; -- 釋放全局鎖

表級鎖

 表鎖
表鎖


讀鎖是自己和別人都不可以寫,但是都可以讀
寫鎖是自己既可以讀也可以寫,別人既不可以讀也不可以寫
元數據鎖
![]()

元數據鎖就相當于表結構鎖,讀寫時的鎖都是兼容的(共享),可以同方進行(因為沒有修改表結構);當修改表結構時加的鎖是和讀寫時加的鎖是互斥的,此時無法進行讀寫,當有讀寫操作的事務沒有提交時,進行表結構的修改也是會被阻塞的
-- 查看元數據鎖信息
select Object_type,object_schema,object_name,lock_type, lock_duration from performance_schema.metadata_locks;意向鎖
當需要加表鎖的時候,需要逐行檢查是否有行鎖,這樣性能極低,于是引入了意向鎖


行級鎖
介紹:


行鎖

 如果更新條件沒有使用索引,那么就會進行全表掃描,mysql 會將行鎖升級為表鎖(其實就是被掃描到的行都加行鎖),update 語句的where條件使用了唯一索引,就只會對這一行加行鎖(排他鎖)
如果更新條件沒有使用索引,那么就會進行全表掃描,mysql 會將行鎖升級為表鎖(其實就是被掃描到的行都加行鎖),update 語句的where條件使用了唯一索引,就只會對這一行加行鎖(排他鎖)
間隙鎖

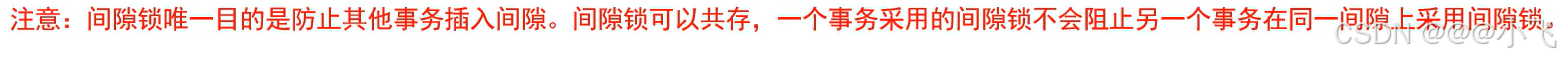
如果表中按唯一索引 id 順序存在id為5,8的數據,那么執行?update tb?set name = 'test' where id = 6; 這條數據不存在,那么就會加間隙鎖,開區間鎖住索引為5和8之間的數據,那么執行?insert into tb(id, name) values (7, 'test'); 將會被阻塞。
間隙鎖作用:防止幻讀,事務T1讀取了一組數據,事務T2在這組數據中插入了新的數據,如果T1再次讀取這組數據,就會看到T2插入的新數據,這就是幻讀。通過間隙鎖,可以鎖定這個范圍,防止其他事務在這個范圍內插入新的數據,從而避免幻讀。
?臨鍵鎖
?臨鍵鎖就是間隙鎖 + 行鎖,上述間隙鎖的第三點會加臨鍵鎖
行鎖優化:
1 盡可能讓所有數據檢索都通過索引來完成,避免無索引行或索引失效導致行鎖升級為表鎖。
2 盡可能避免間隙鎖帶來的性能下降,減少或使用合理的檢索范圍。
3 盡可能減少事務的粒度,比如控制事務大小,而從減少鎖定資源量和時間長度,從而減少鎖的競爭等,提供性能。
4 盡可能低級別事務隔離,隔離級別越高,并發的處理能力越低。
總結
mysql的鎖可以分為全局鎖和表鎖和行鎖。
全局鎖:全局鎖是鎖住整個庫,所有的寫操作語句都無法執行,在做數據庫備份的時候會自動觸發全局鎖,手動獲取全局鎖:flush tables with read lock;? 手動釋放:unlock tables;
表鎖:表鎖可以分為讀鎖和寫鎖
-
讀鎖(共享鎖,Shared Lock)
- 也稱為共享鎖。
- 允許多個事務同時獲得同一個表上的讀鎖。
- 但是,如果一個事務持有讀鎖,則不允許其他事務獲取寫鎖(排他鎖)。
- 在讀鎖下,可以進行查詢操作,但不能進行修改操作
-
寫鎖(排他鎖,Exclusive Lock)
- 排他鎖阻止其他事務獲取任何類型的鎖(包括讀鎖和寫鎖)。
- 當一個事務持有寫鎖時,只有這個事務可以對表進行讀取或寫入操作。
- 這種鎖通常用于確保數據的一致性,尤其是在執行更新、刪除或插入操作時。
在執行某些表結構的DDL語句時,MySQL 可能會自動為涉及的表添加寫鎖,例如 alter table;drop table;?truncate table; create index;? 讀鎖通常不會自動觸發;
行鎖:行鎖分為共享鎖和排他鎖,原理和表鎖差不多
- 共享鎖(Shared Locks, S Locks):允許多個事務同時讀取同一行數據,但阻止任何事務獲取該行的排他鎖。
- 排他鎖(Exclusive Locks, X Locks):阻止其他所有事務獲取該行的任何類型的鎖(包括共享鎖和排他鎖),確保只有當前事務可以修改或刪除該行。
鎖升級:
InnoDB 不支持自動鎖升級,只是出現了類似鎖升級的現象
updete索引未命中導致全表掃描:如果查詢條件列上沒有建立索引,MySQL 將掃描整個表以找到匹配的記錄。在這種情況下,逐行遍歷到的都會加行鎖(排他鎖),加的多了就類似表鎖了。
InnoDB 引擎
邏輯存儲結構
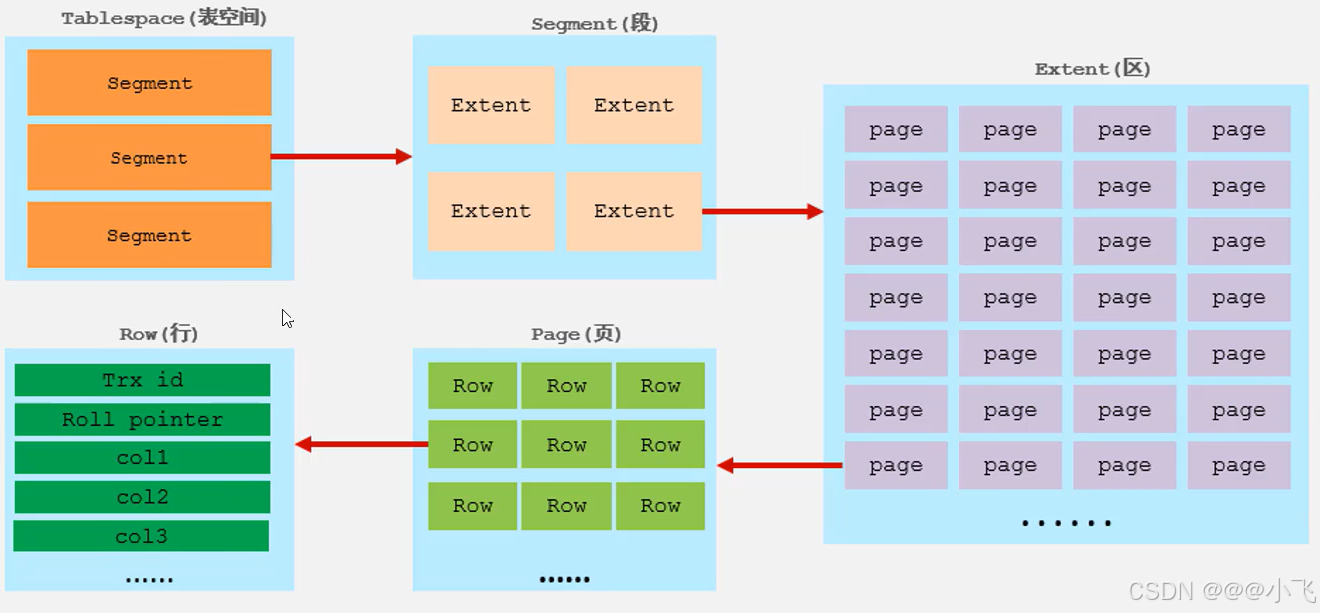
在InnoDB引擎邏輯結構中,數據和索引都是存放在表空間中,一個表空間有存在多個段,一個段中存在多個區,一個區中存在多個頁,一個頁中存在多個行,行中存放行數據的字段、回滾指針等

內存架構
內存架構中有:BufferPool、ChangeBuffer、AdaptiveHashIndex、LogBuffer

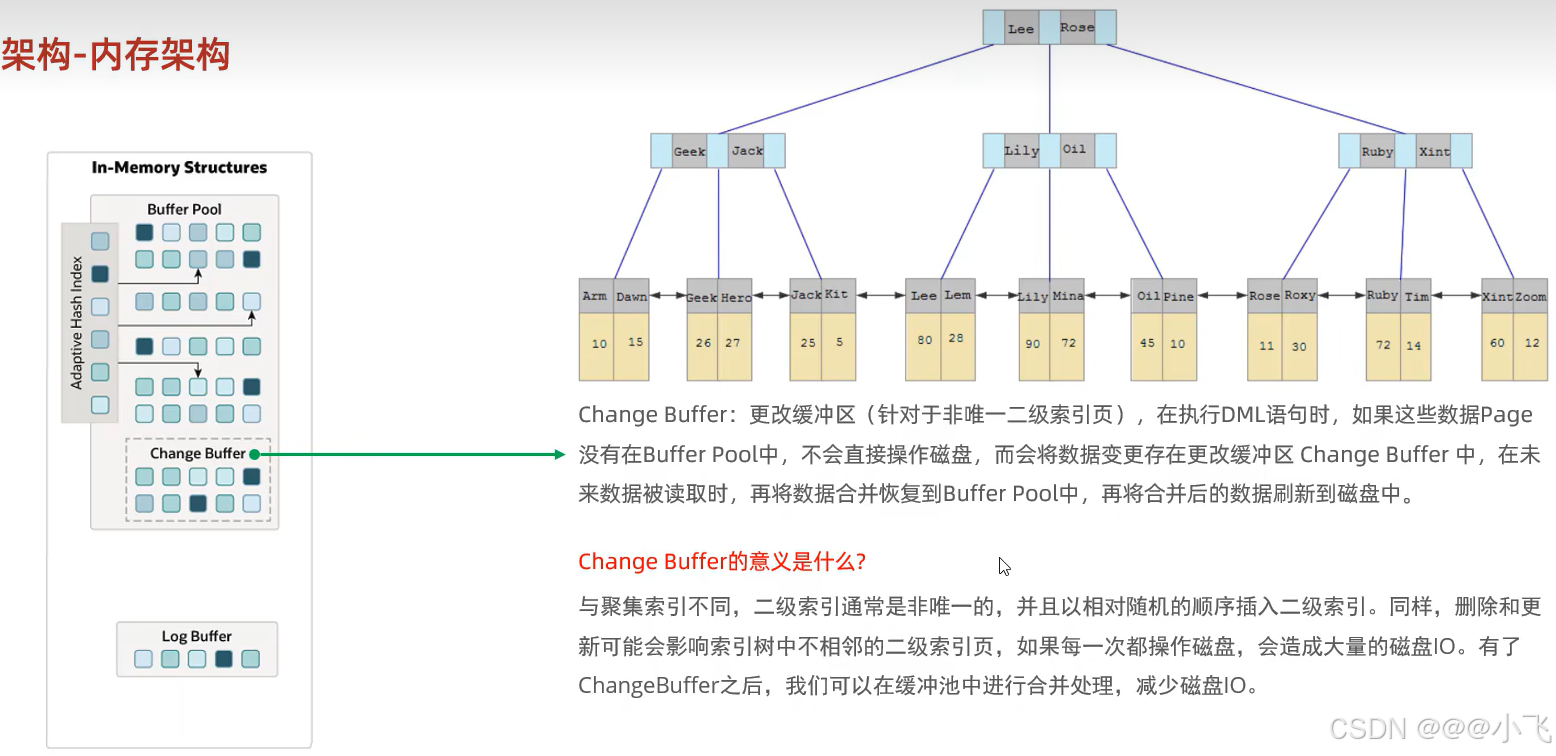


如果一臺服務器專門部署MySQL,那么通常 80% 的內存都分配給MySQL
磁盤架構
磁盤架構中有:系統表空間、獨立表空間、通用表空間、臨時表空間、雙寫緩沖區、重做日志
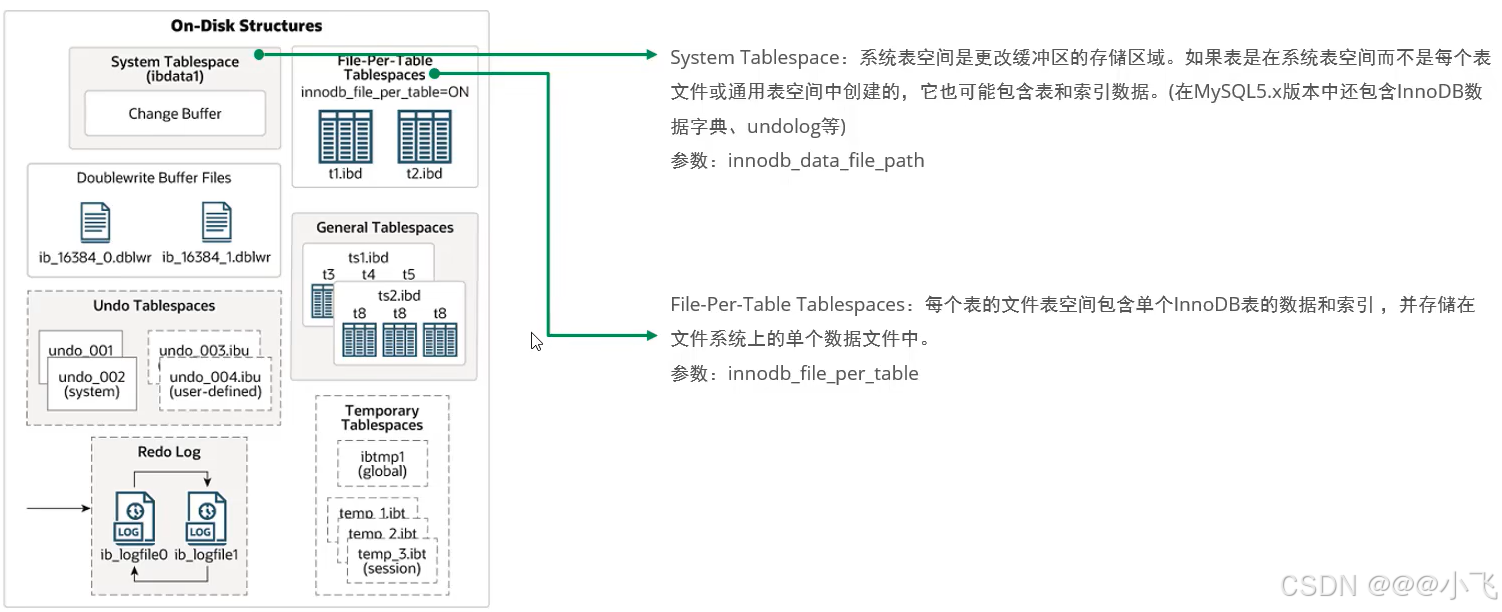
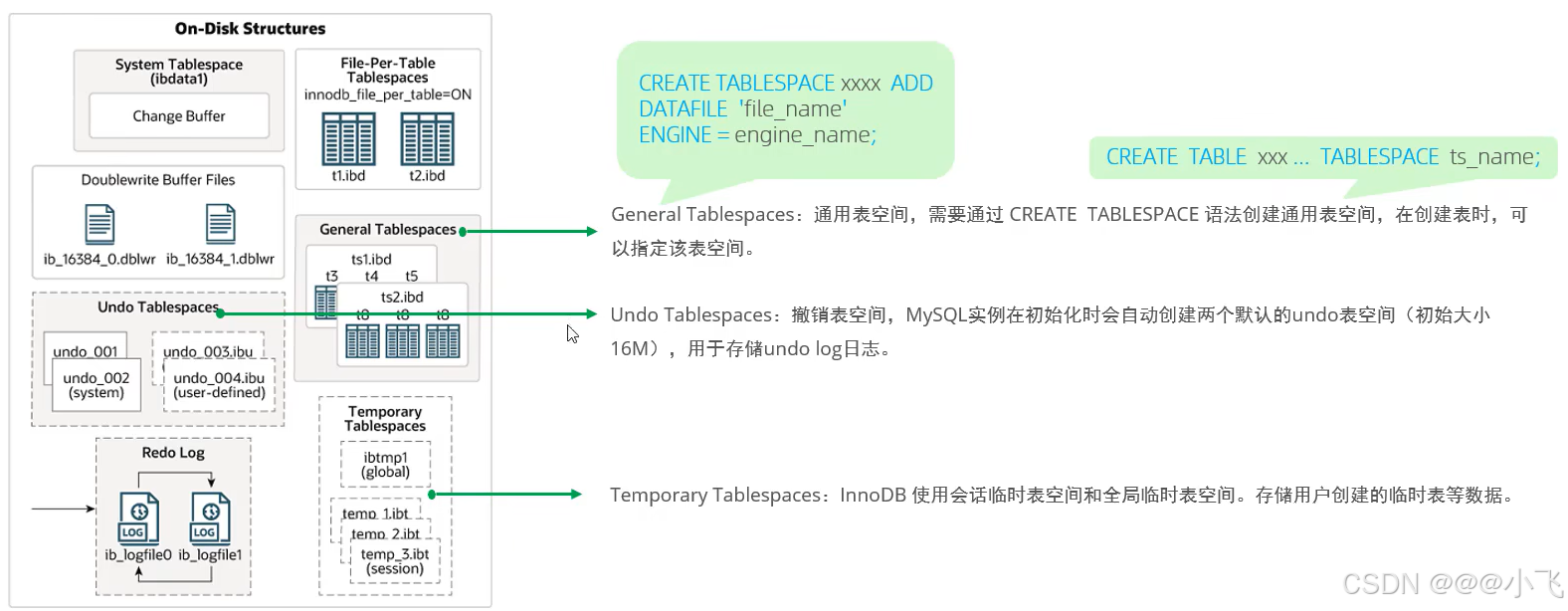
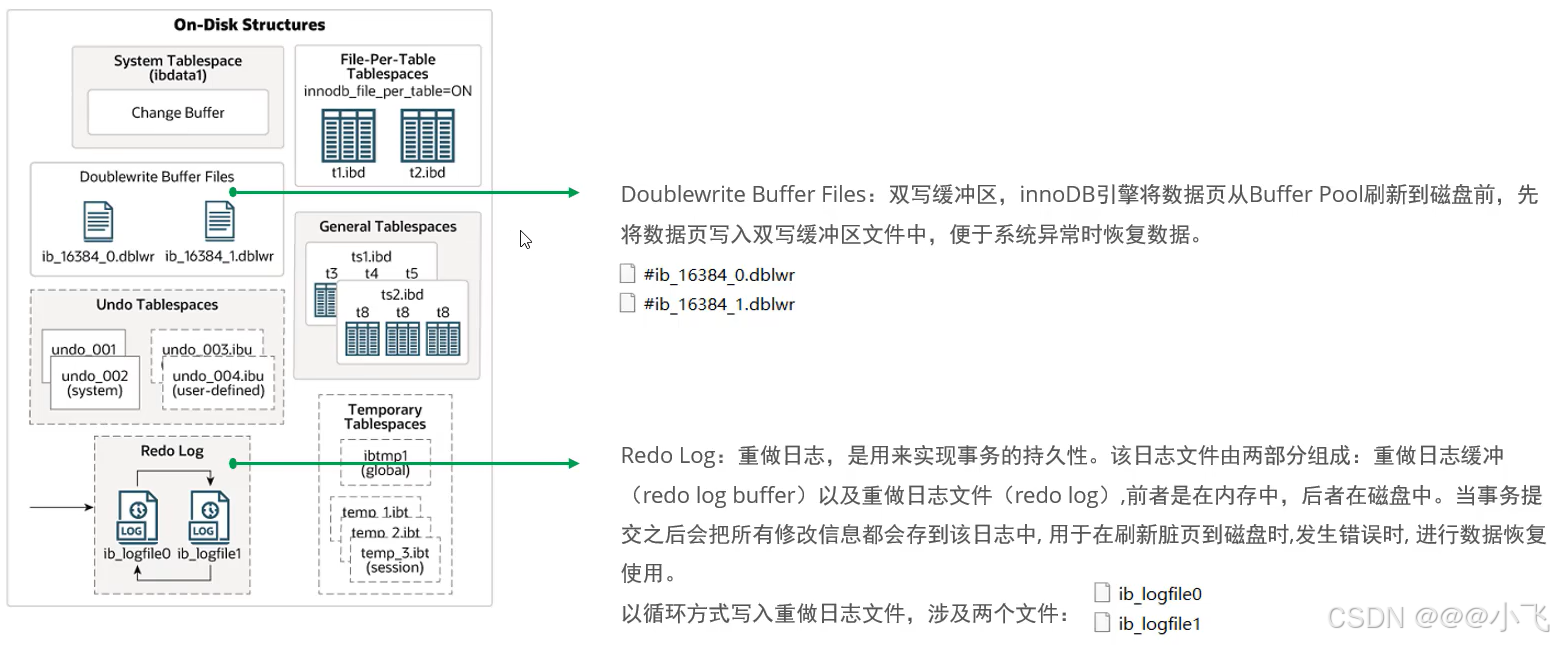
?后臺線程

事務原理
概述


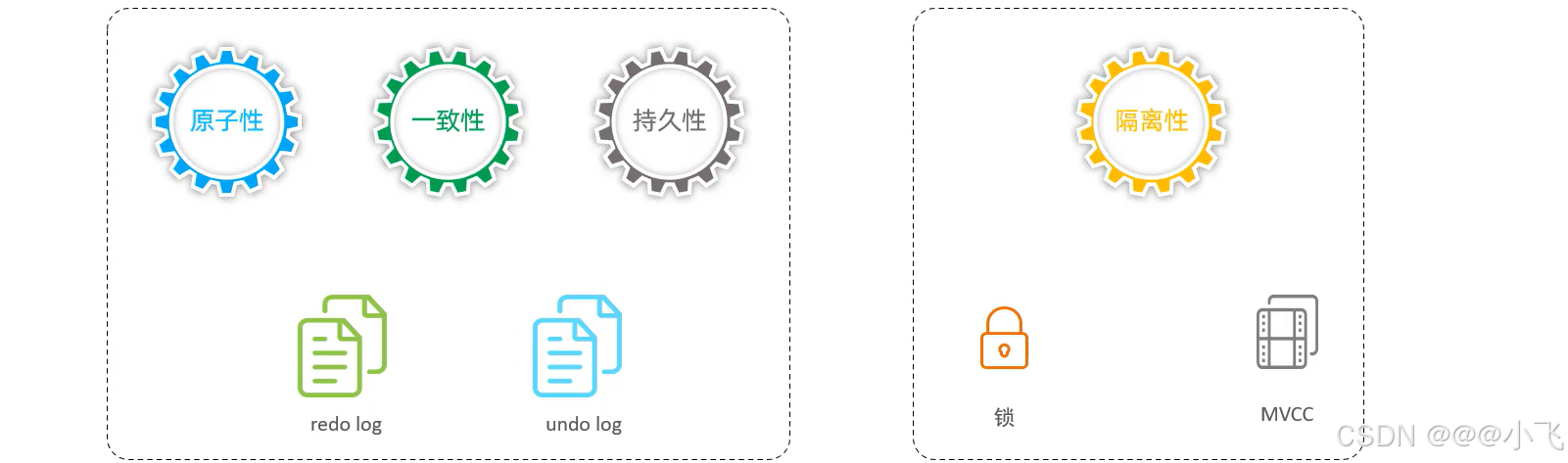
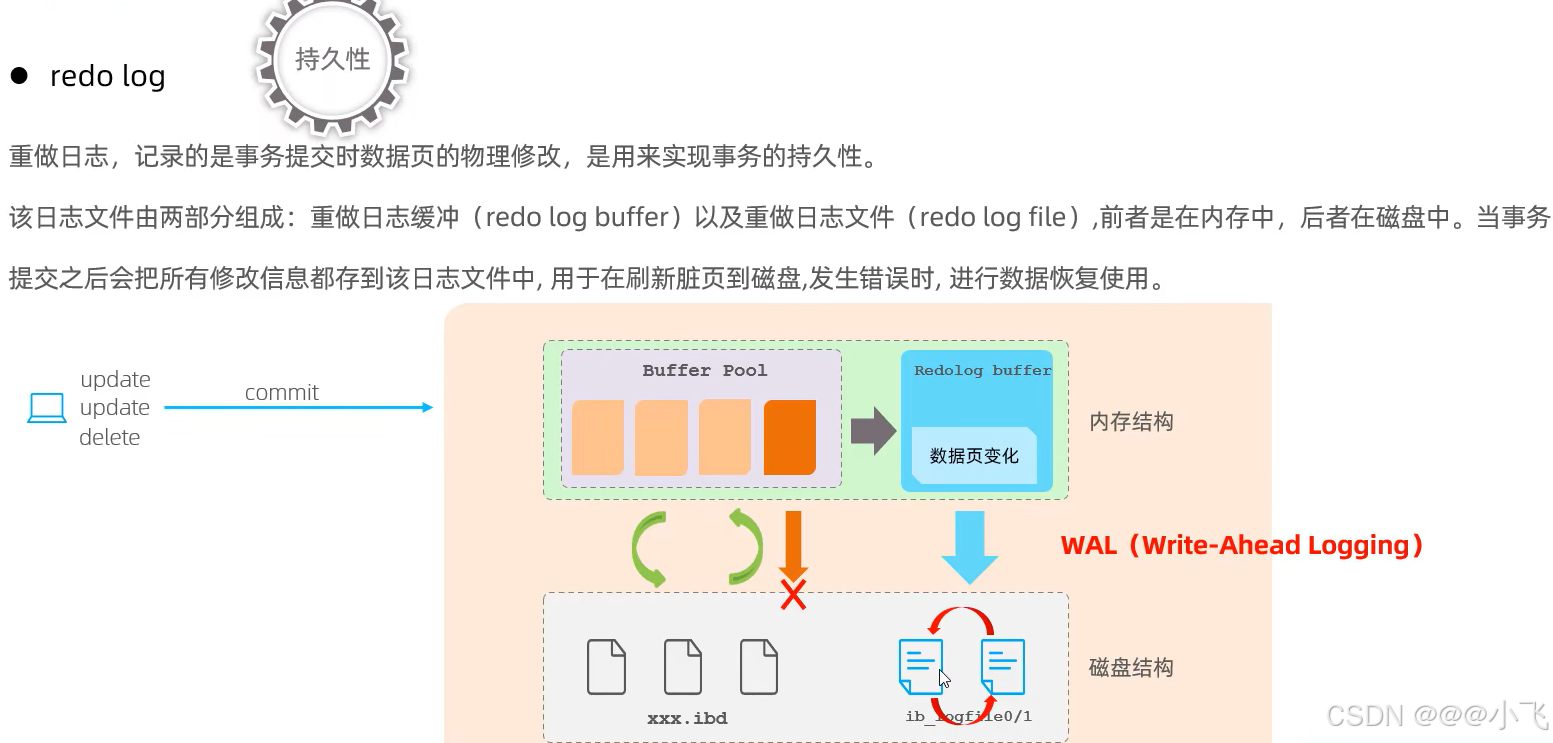
redo log
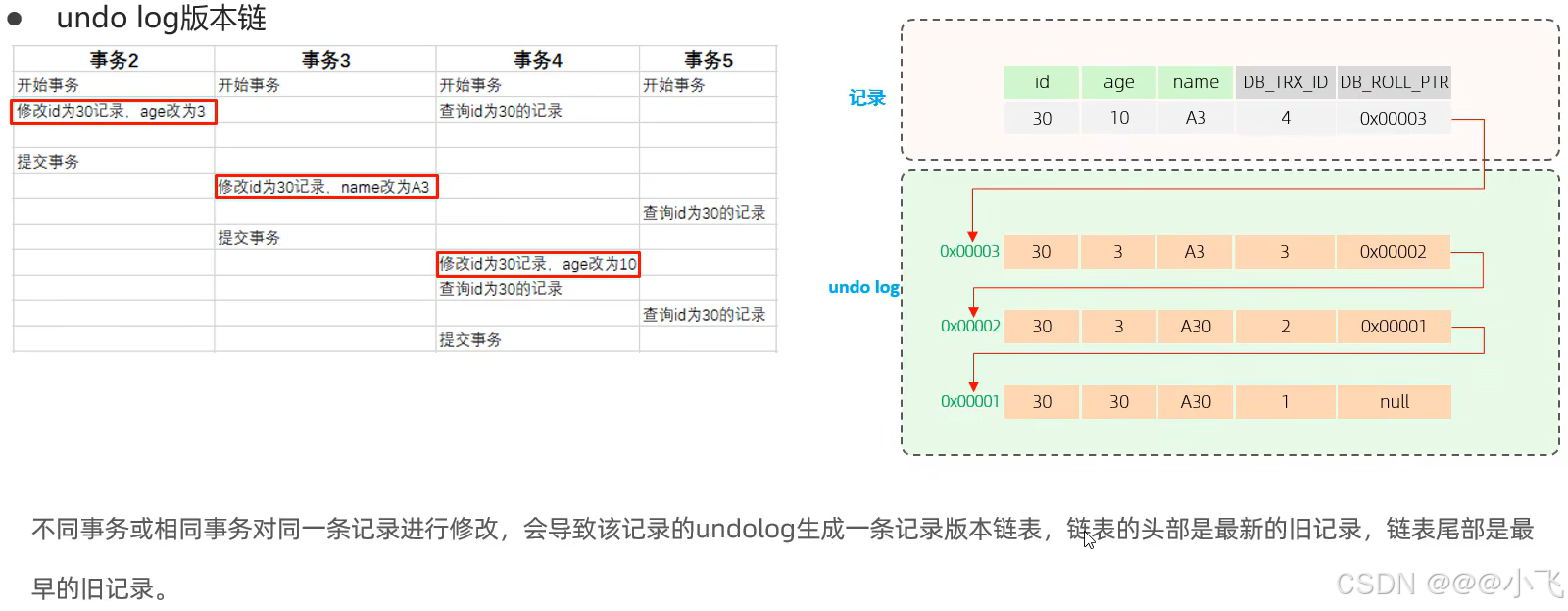
undo log

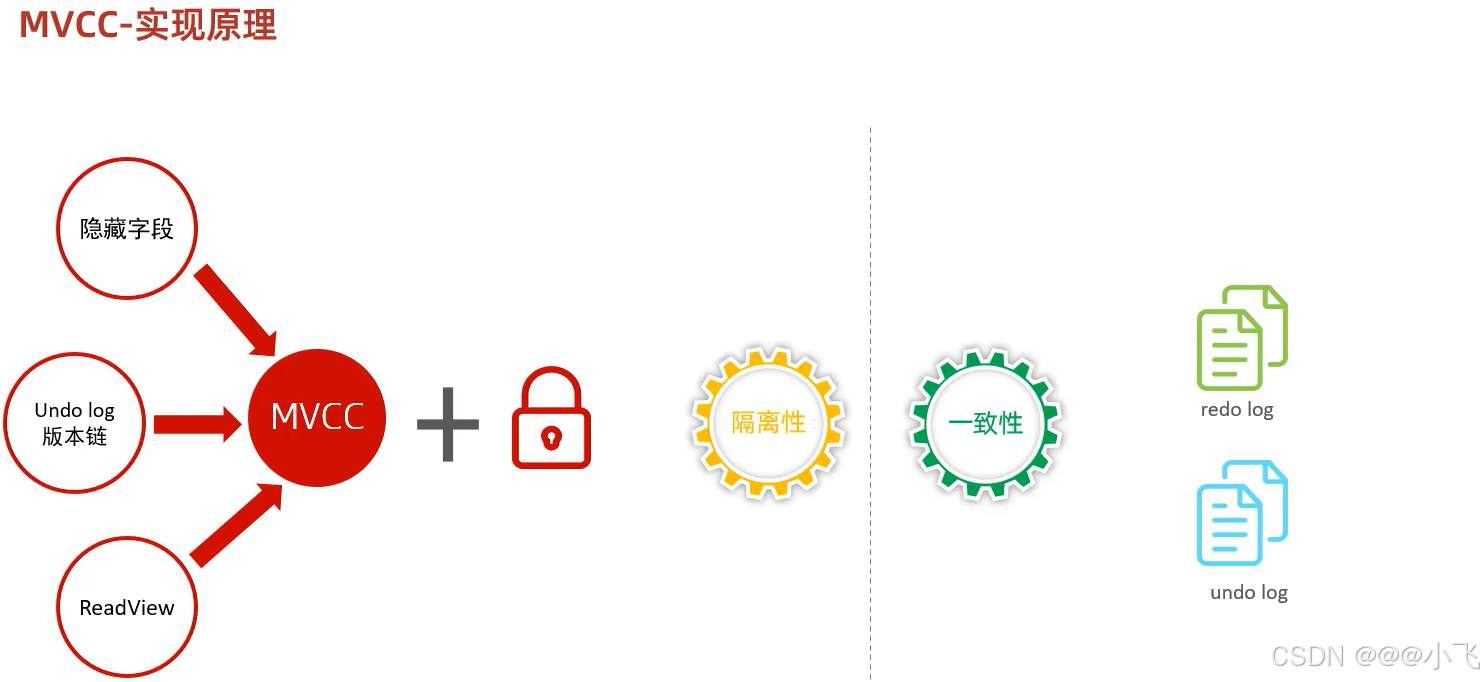
MVCC
基本概念

實現原理


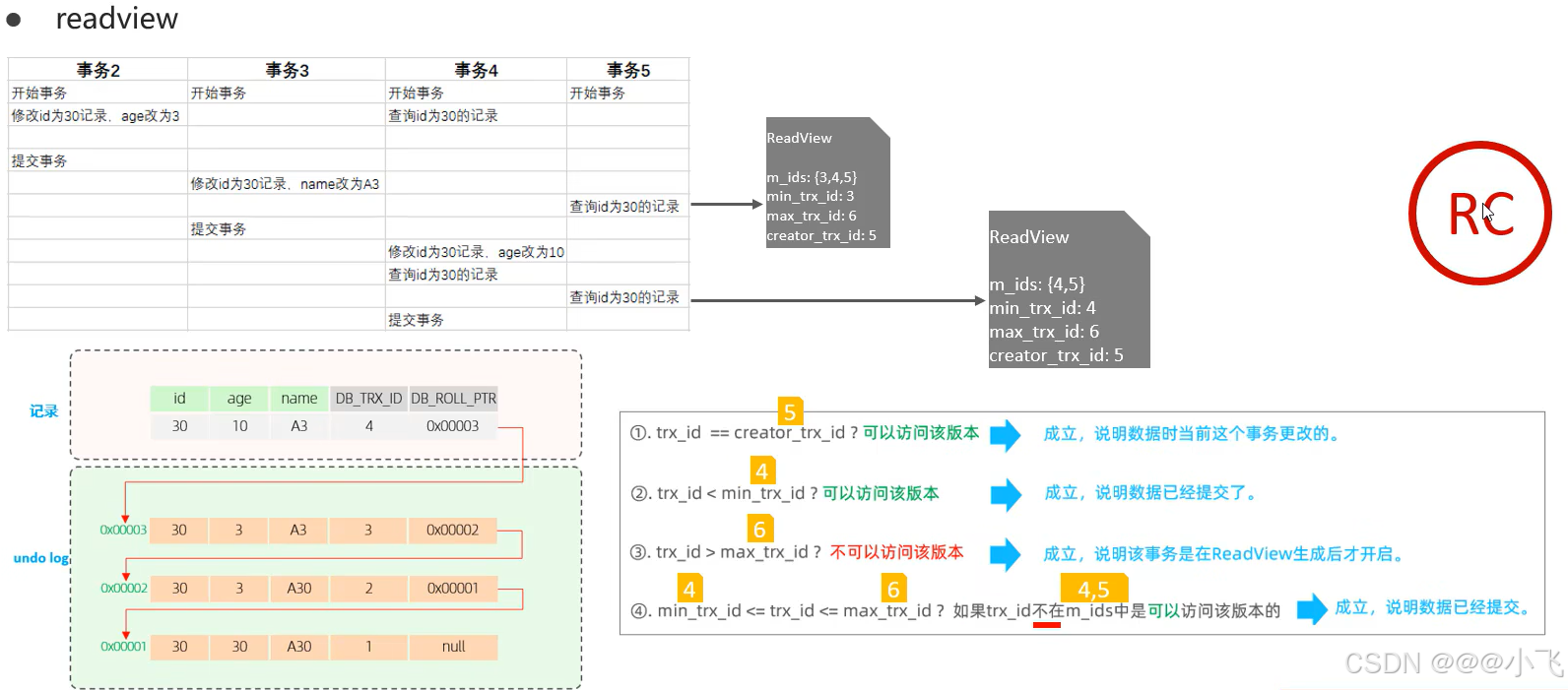
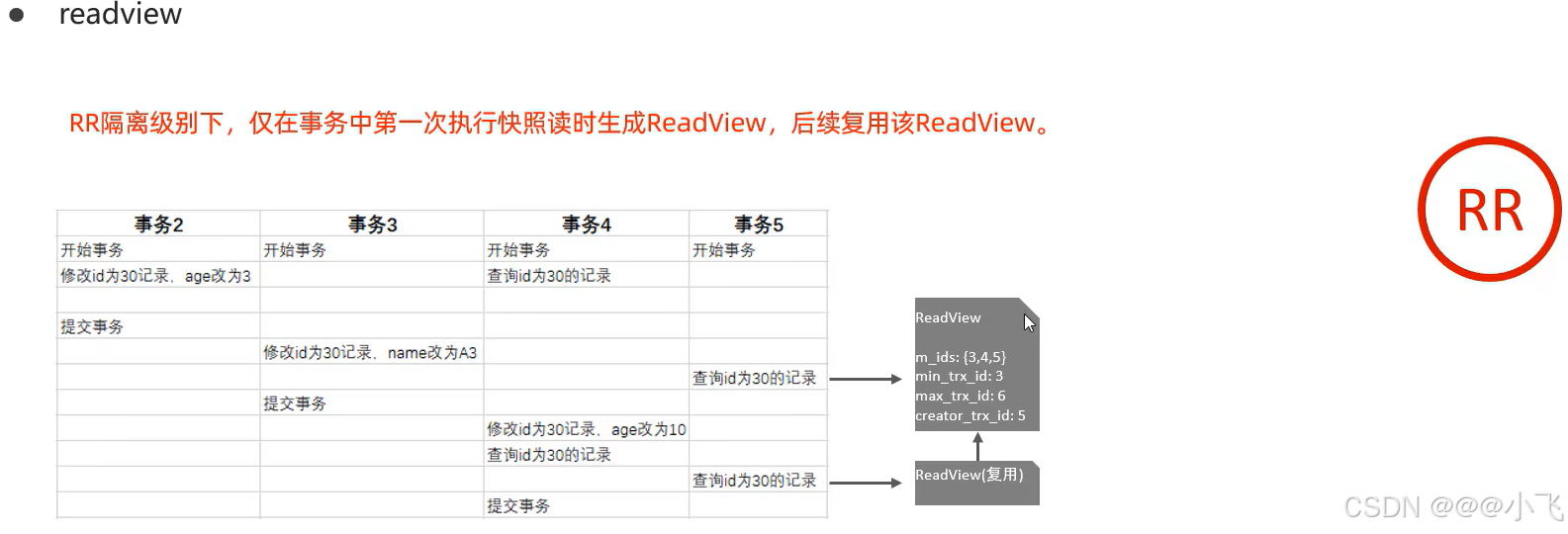
當 undo log 有多個版本的時候,查詢應該返回那個版本的數據呢?這個是有 readview 控制的



MySQL管理
介紹

常用工具
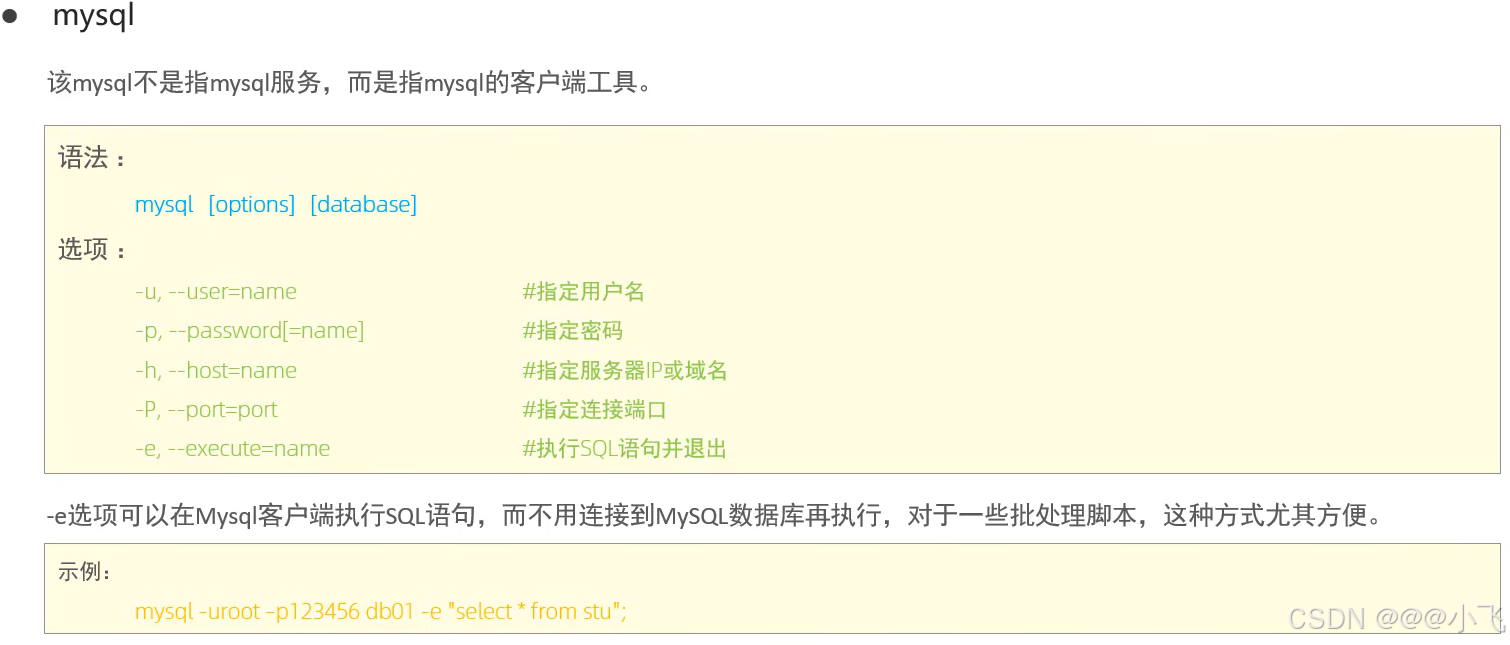
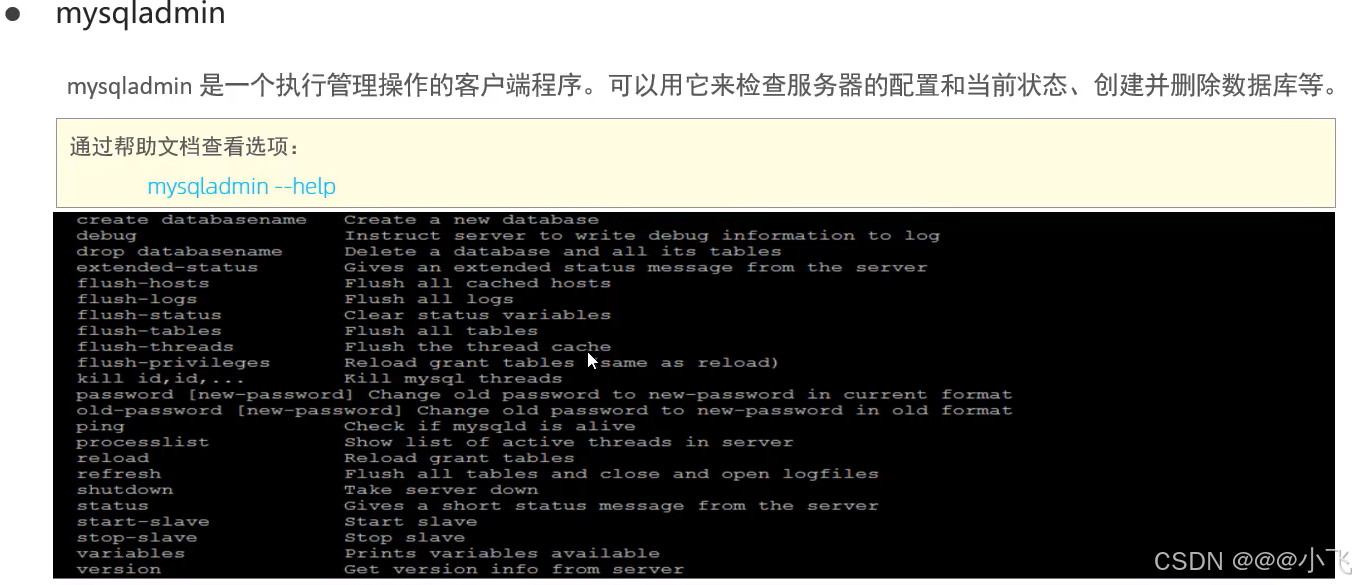
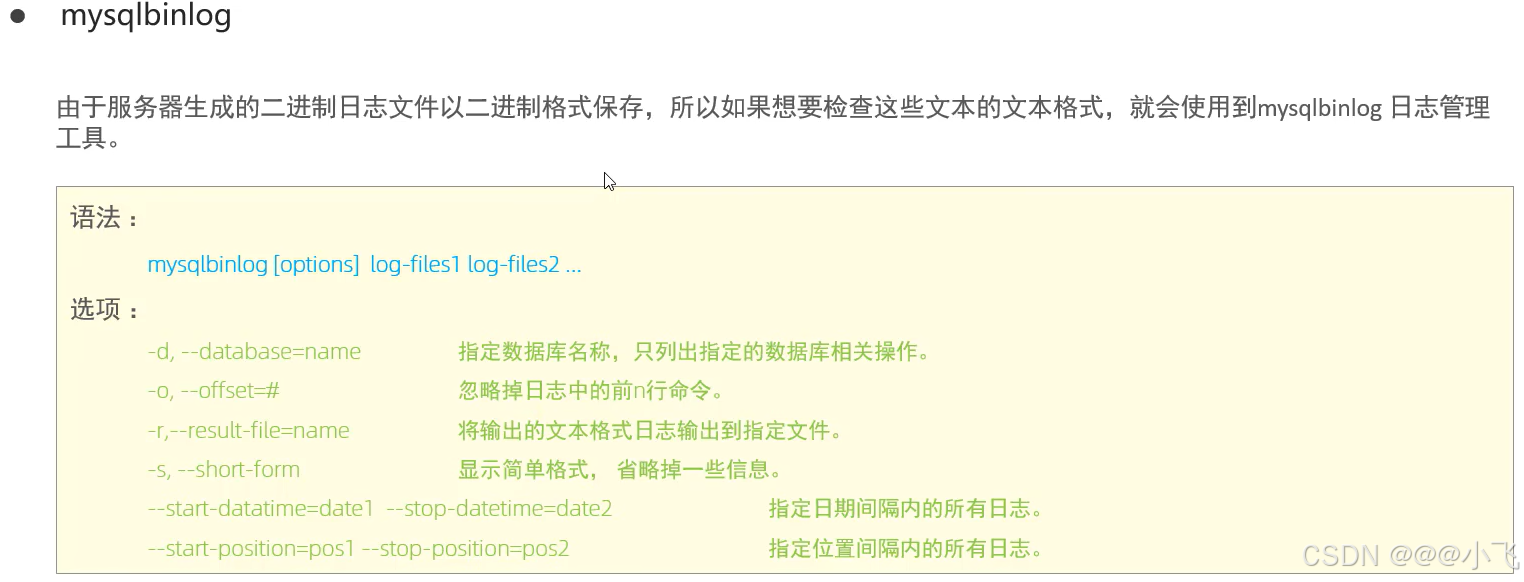


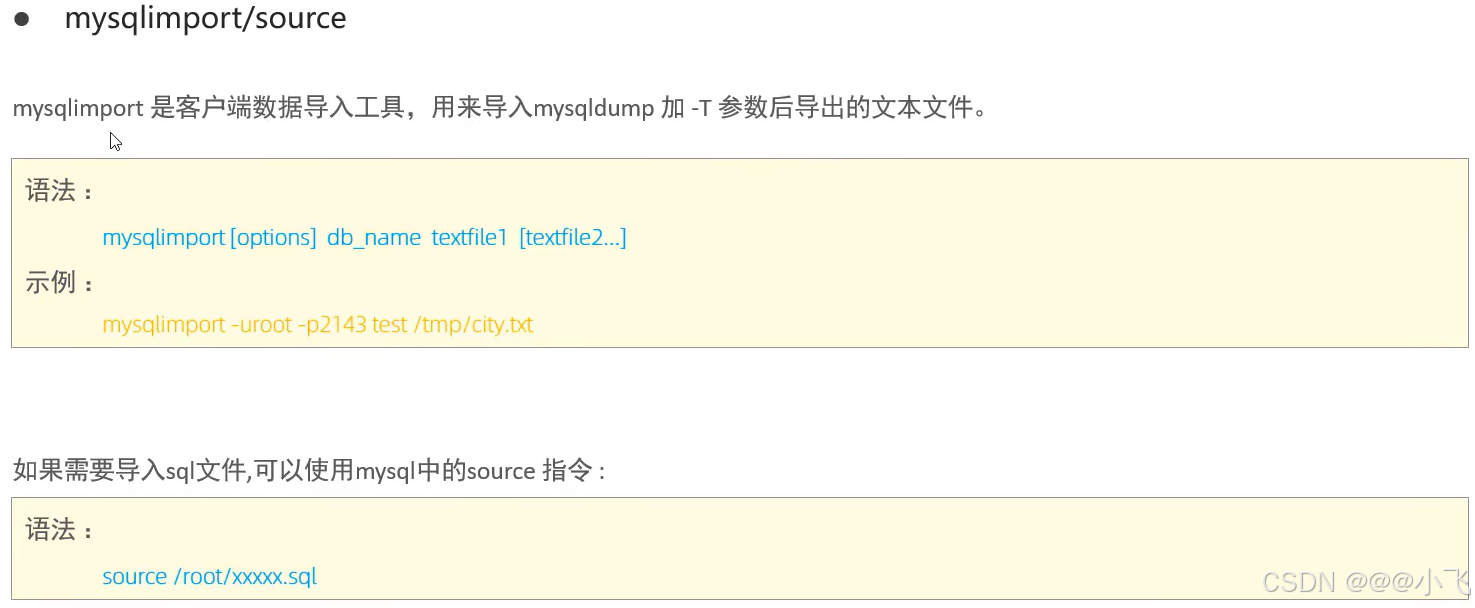
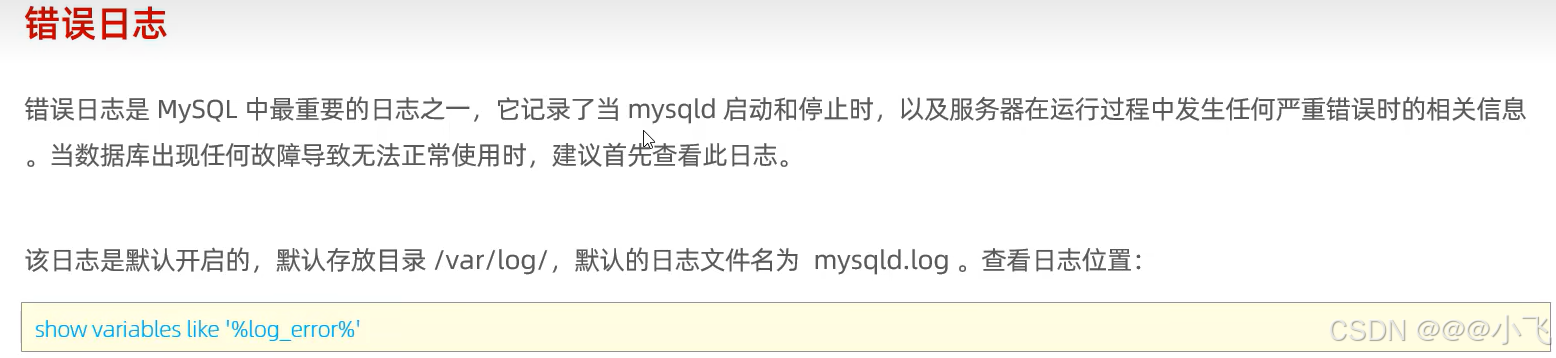
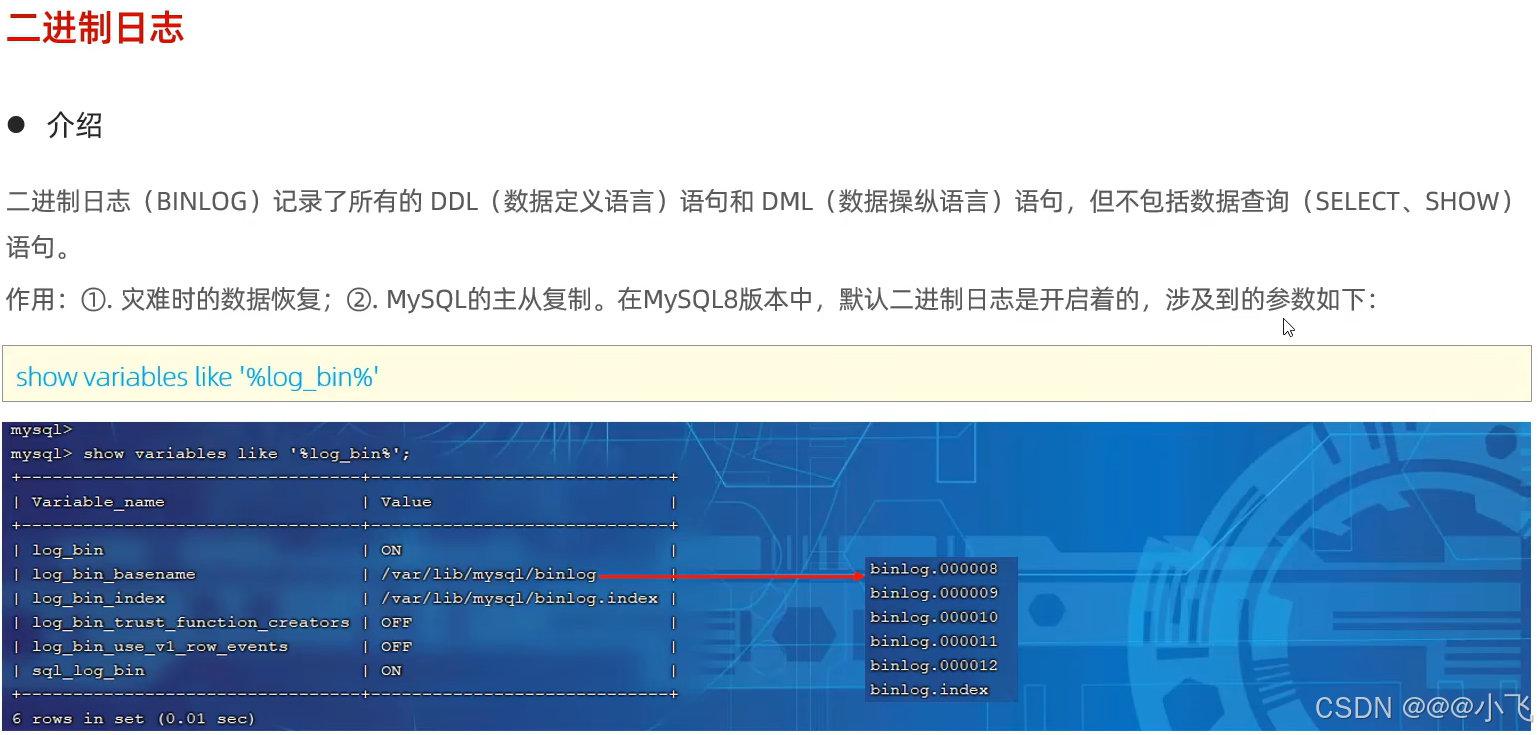
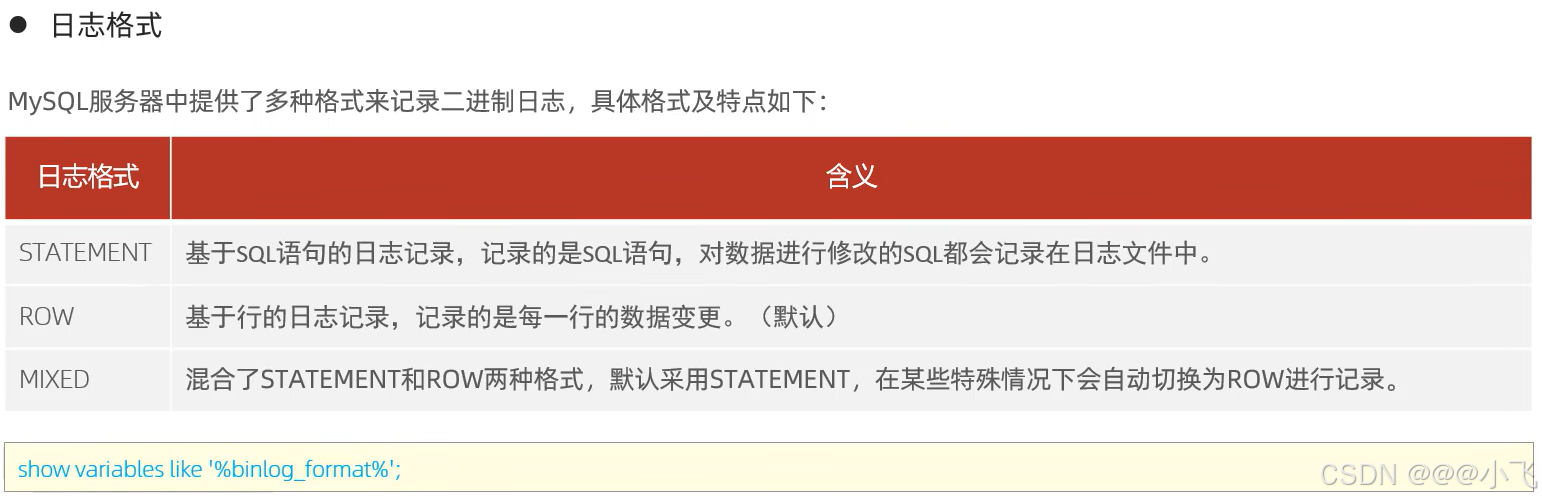
日志


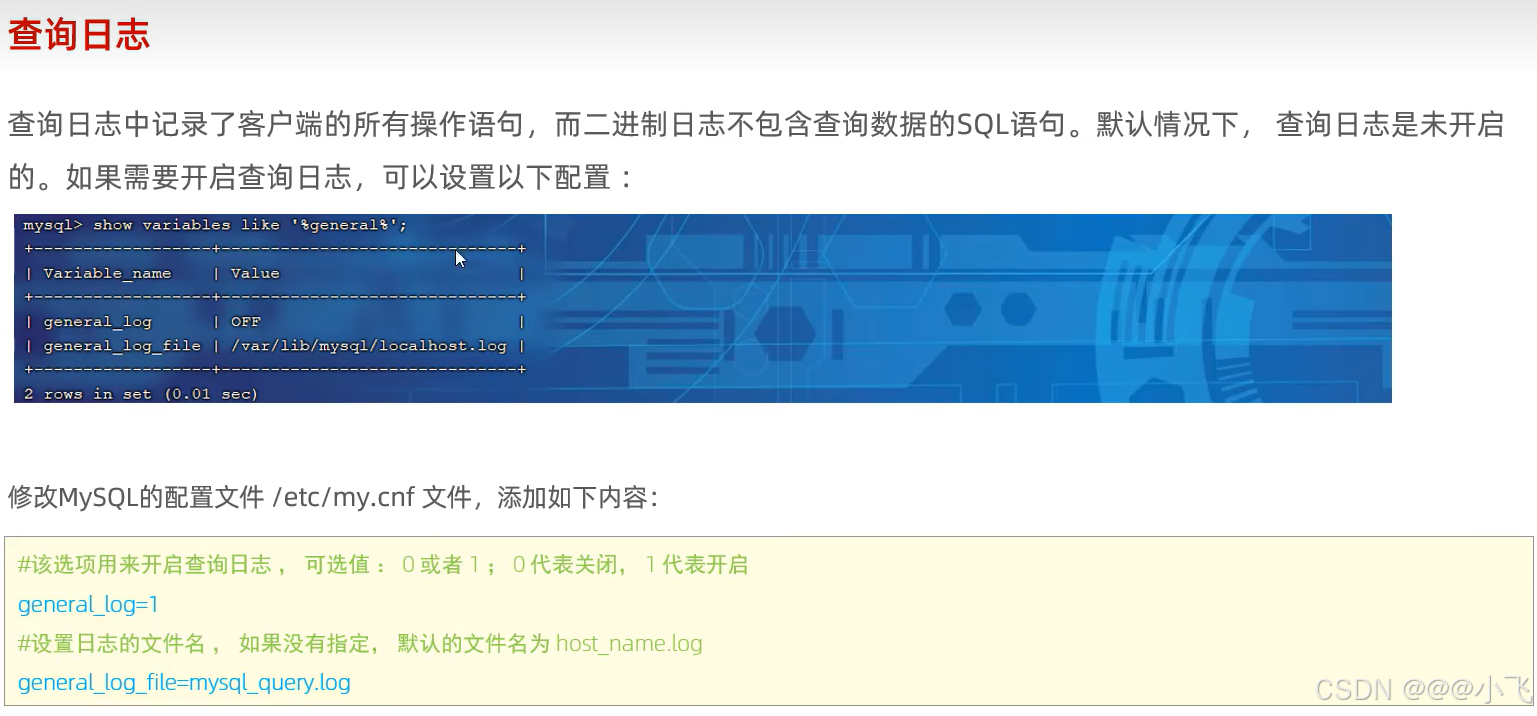

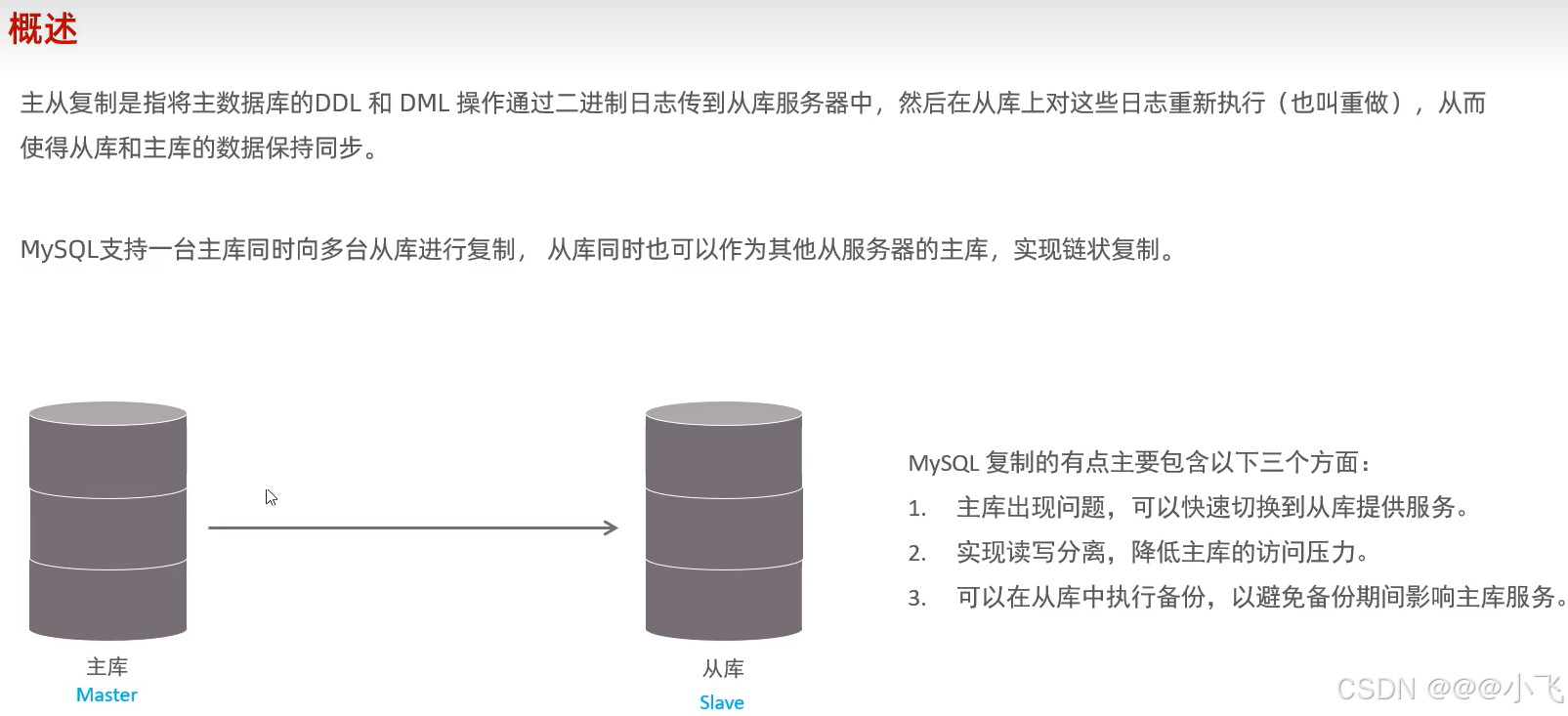
主從復制
前置知識
?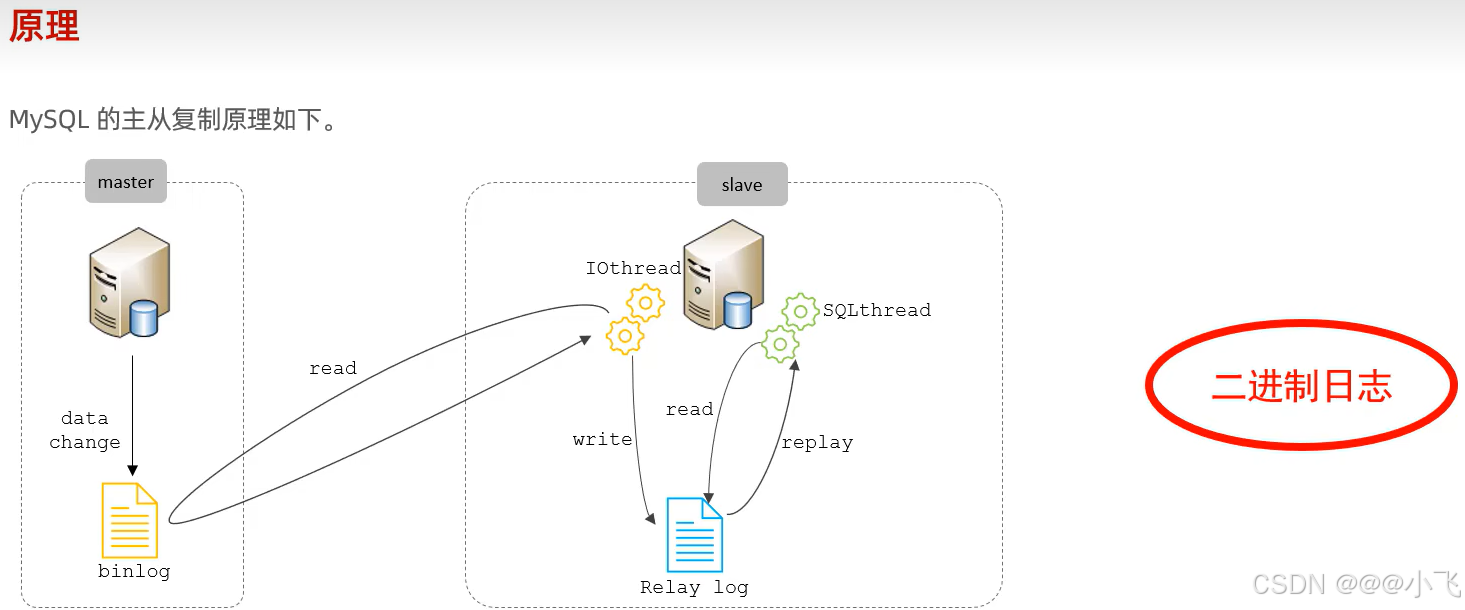

?當主庫執行DDL(結構相關的語句)和增刪改時,會往 dataChange 寫下 binlog 日志,從庫的 IOthread 線程會發起網絡請求讀取 主庫的 binlog 并寫入中繼日志?Relaylog,SQLthread 線程就會讀取?Relaylog 執行記錄的 SQL 語句
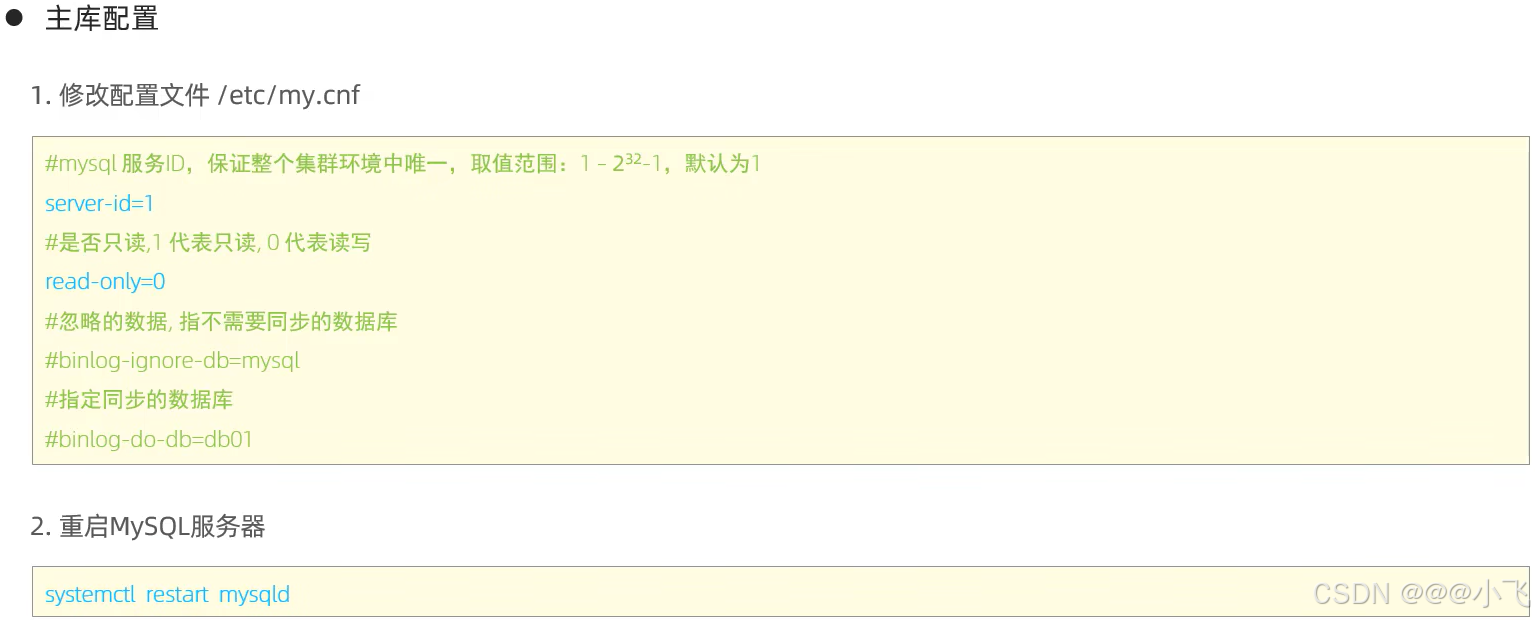
主從搭建-普通方式




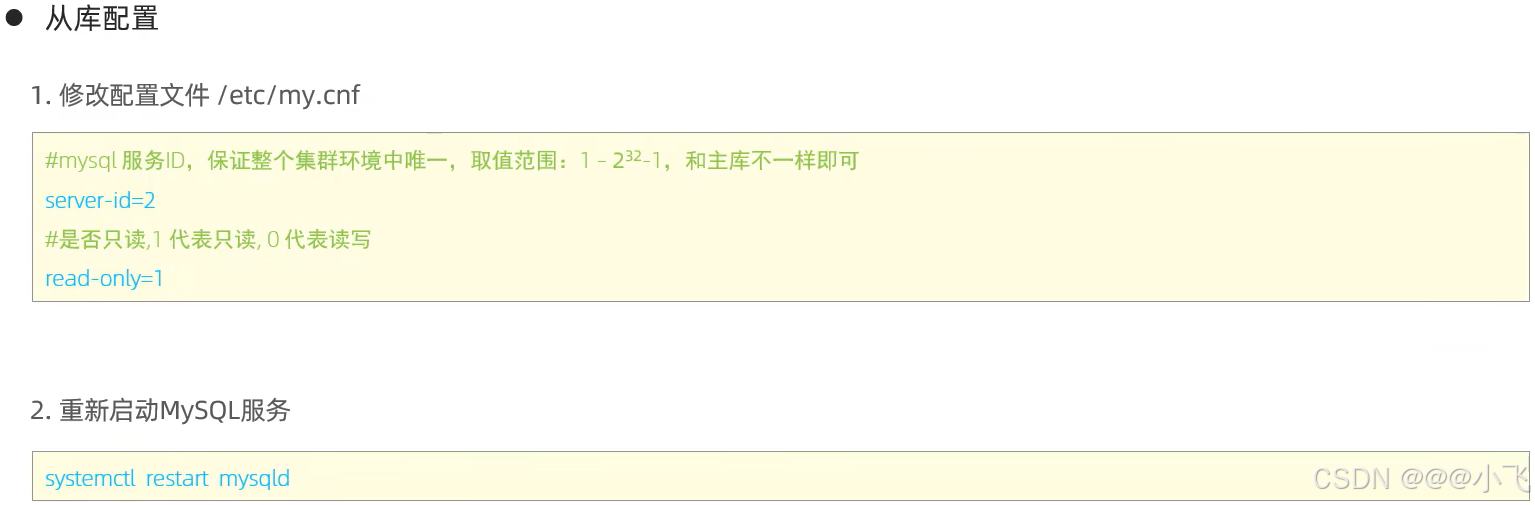
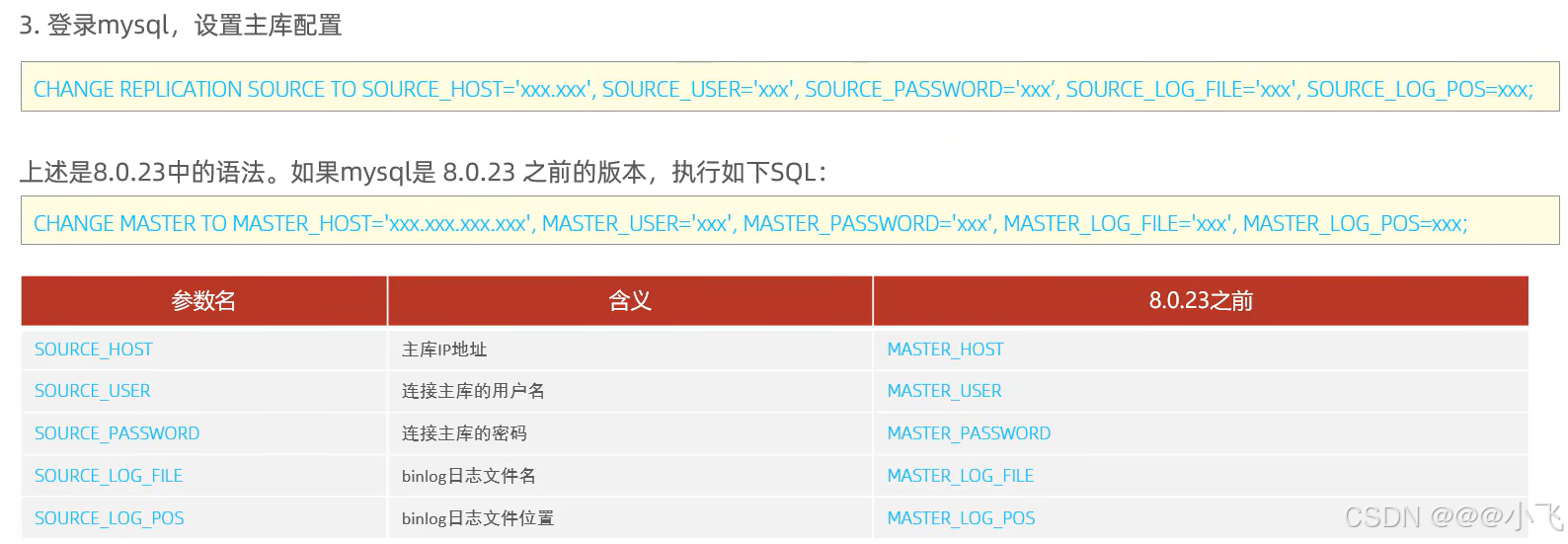
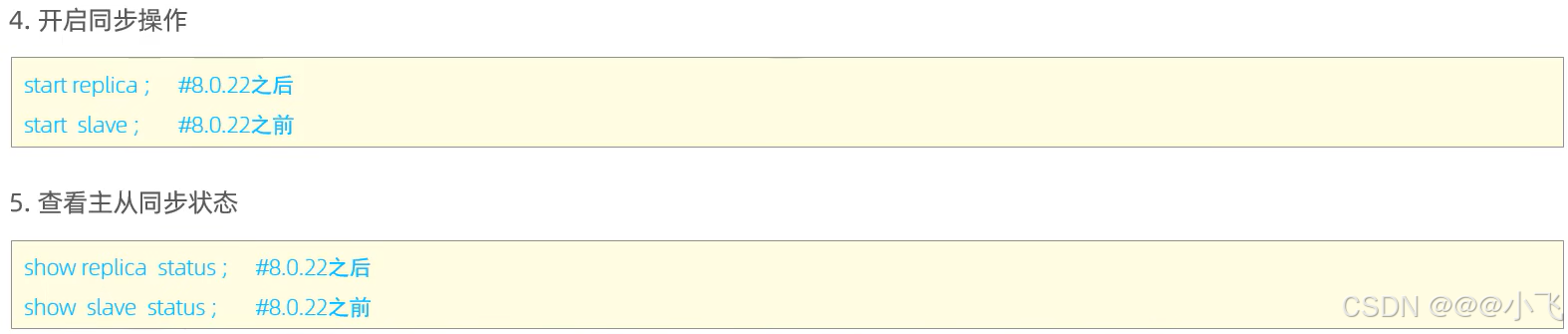

主從搭建-Docker
1、創建主從復制的目錄結構,創建配置文件,文件夾授權
mkdir -p /dockerAppData/study/mysql/one_master-slave/{master,slave}/{data,conf}
touch /dockerAppData/study/mysql/one_master-slave/master/conf/master.cnf
touch /dockerAppData/study/mysql/one_master-slave/slave/conf/slave.cnf
chmod -R 775 /dockerAppData/study/mysql/one_master-slave2、寫入配置
[mysqld]
# 主從復制-主機配置
# 主服務器唯一ID
server-id = 1
# 指定MySQL數據目錄的位置
datadir = /dockerAppData/study/mysql/one_master-slave/master/data
# 設置服務器默認字符集
character-set-server = utf8
# 1:只讀,0:讀寫,默認值0,表示默認讀寫都可
# read-only = 0# 啟用二進制日志
log-bin=mysql-bin
# 設置logbin格式
binlog_format = STATEMENT
# 1:表名不區分大小寫,統一小寫存入磁盤,這樣可以兼容Windows和Linux
lower-case-table-names = 1[mysqld]
# 主從復制-從機配置
# 主服務器唯一ID
server-id = 2
# 指定MySQL數據目錄的位置
datadir = /dockerAppData/study/mysql/one_master-slave/slave/data
# 設置服務器默認字符集
character-set-server = utf8
# 1:只讀,0:讀寫,默認值0,表示默認讀寫都可
# read-only = 1# 啟用中繼日志
relay-log = mysql-relay
# 1:表名不區分大小寫,統一小寫存入磁盤,這樣可以兼容Windows和Linux
lower-case-table-names= 13、創建 master 容器
docker run --name mysql-master \
-p 3310:3306 \
-v /dockerAppData/study/mysql/one_master-slave/master/data:/var/lib/mysql \
-v /dockerAppData/study/mysql/one_master-slave/master/conf/my.cnf:/etc/mysql/my.cnf \
-e MYSQL_ROOT_PASSWORD=mysql123456 \
-d mysql4、創建 slave容器
docker run --name mysql-slave \
-p 3311:3306 \
-v /dockerAppData/study/mysql/one_master-slave/slave/data:/var/lib/mysql \
-v /dockerAppData/study/mysql/one_master-slave/slave/conf/my.cnf:/etc/mysql/my.cnf \
-e MYSQL_ROOT_PASSWORD=mysql123456 \
-d mysql5、在master上操作
# 進入容器內部
docker exec -it mysql-master /bin/bash# 登錄
mysql -uroot -pmysql123456# 創建用戶,用于從庫連接主庫,'@'%表示允許從任意主機連接
create user 'slave'@'%' identified with mysql_native_password by 'mysql123456';# 授權,slave可以從master上復制所有表操作
grant replication slave on *.* to 'slave'@'%';# 刷新權限
flush privileges;# 查詢server_id值
show variables like 'server_id';# 查詢Master狀態,并記錄File和Position的值,這里的值是后面slave需要的
show master status;# 在還沒有主從同步的時候就先不要執行sql語句了
6、在slave上操作
# 進入從數據庫容器
docker exec -it mysql-slave /bin/bash
# 登錄
mysql -uroot -pmysql123456# 查詢server_id值,這里的值不能和主數據庫的server_id相同
show variables like 'server_id';# 若之前設置過同步,請先重置
stop slave;
reset slave;# 設置主數據庫
change master to master_host='192.168.222.129',master_port=3310,master_user='slave',master_password='mysql123456',master_log_file='mysql-bin.000003',master_log_pos=829;# 開始同步
start slave;# 查詢Slave狀態
show slave status\G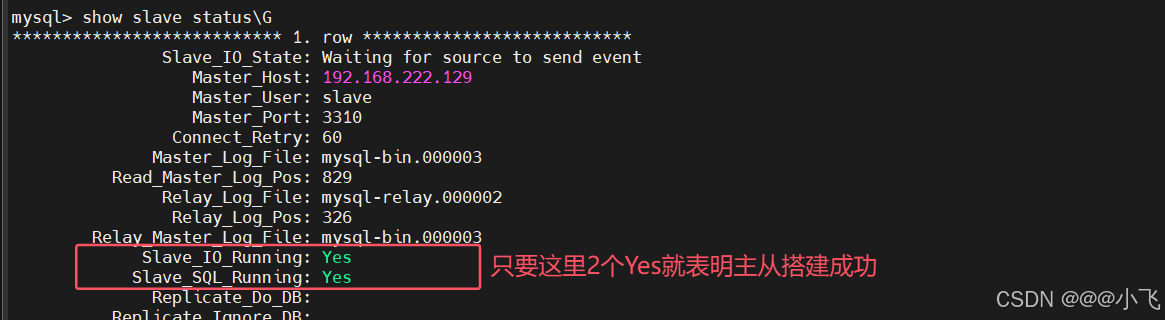
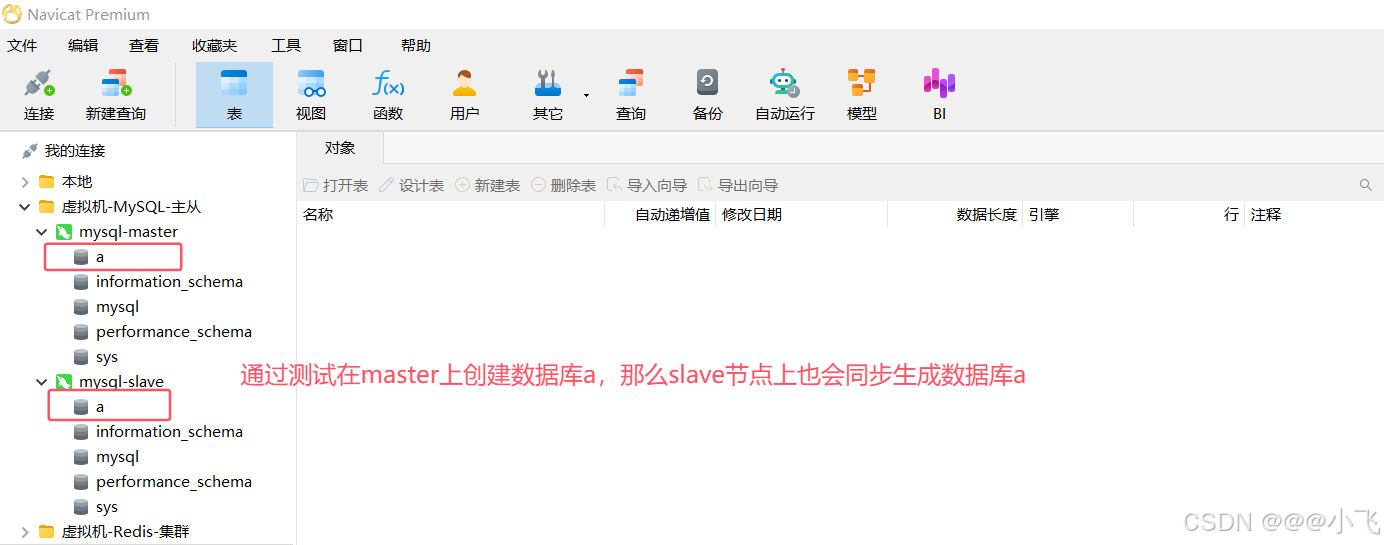
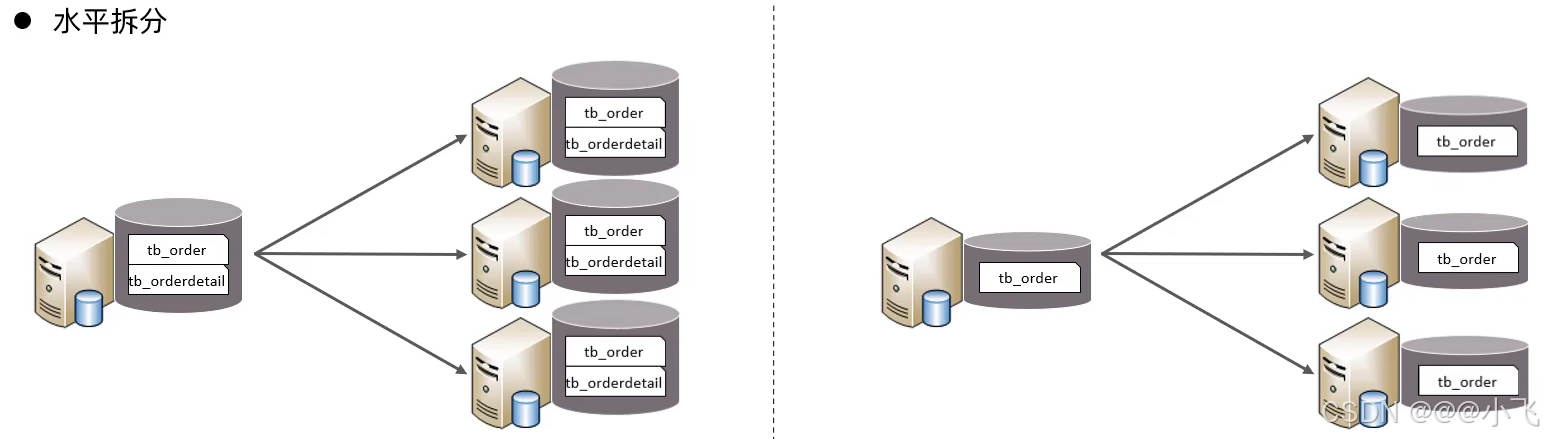
分庫分表
前置知識
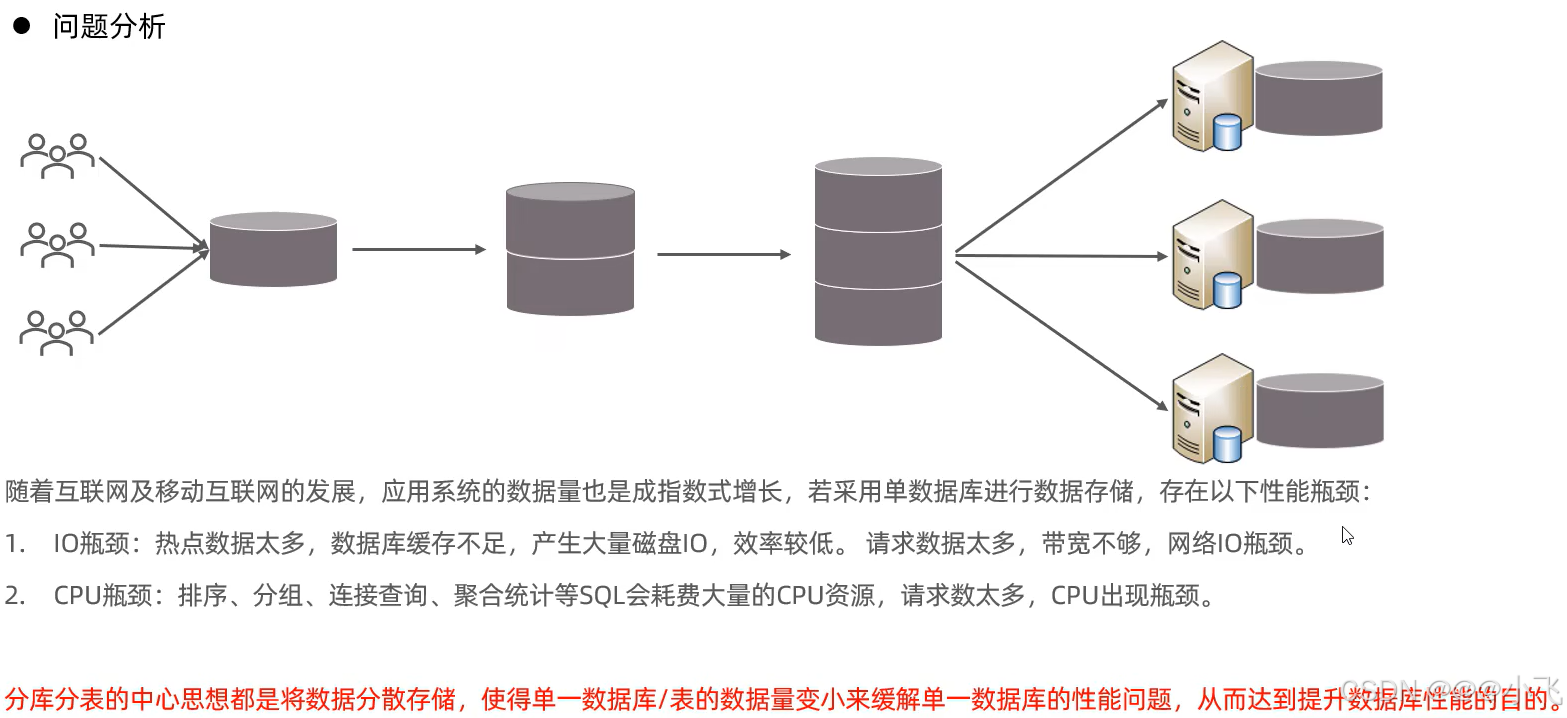
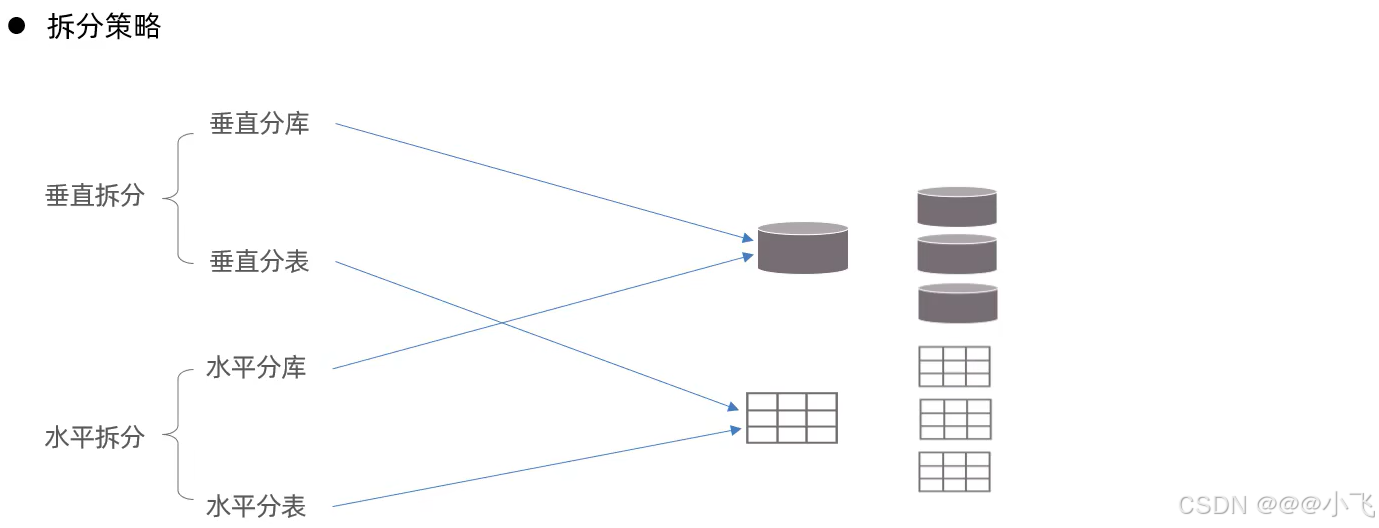
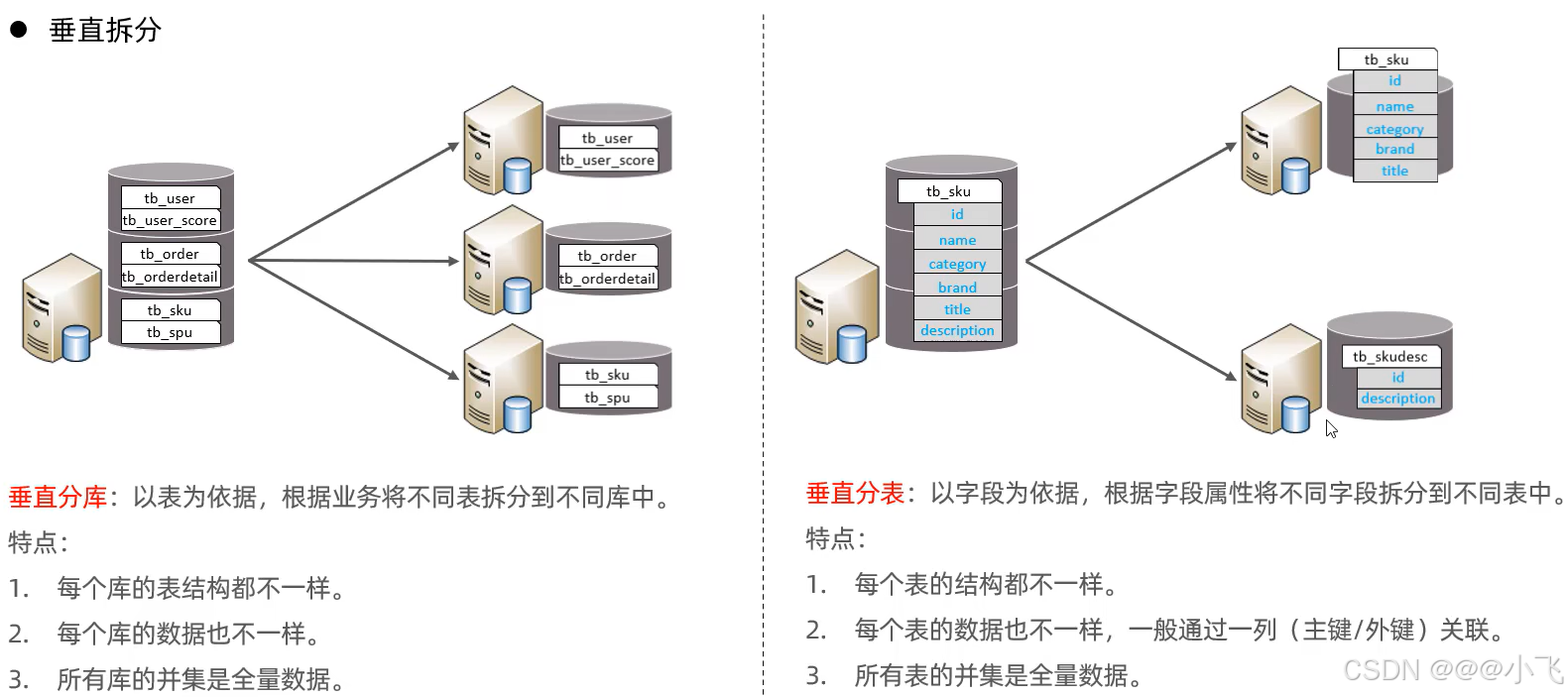

![]()
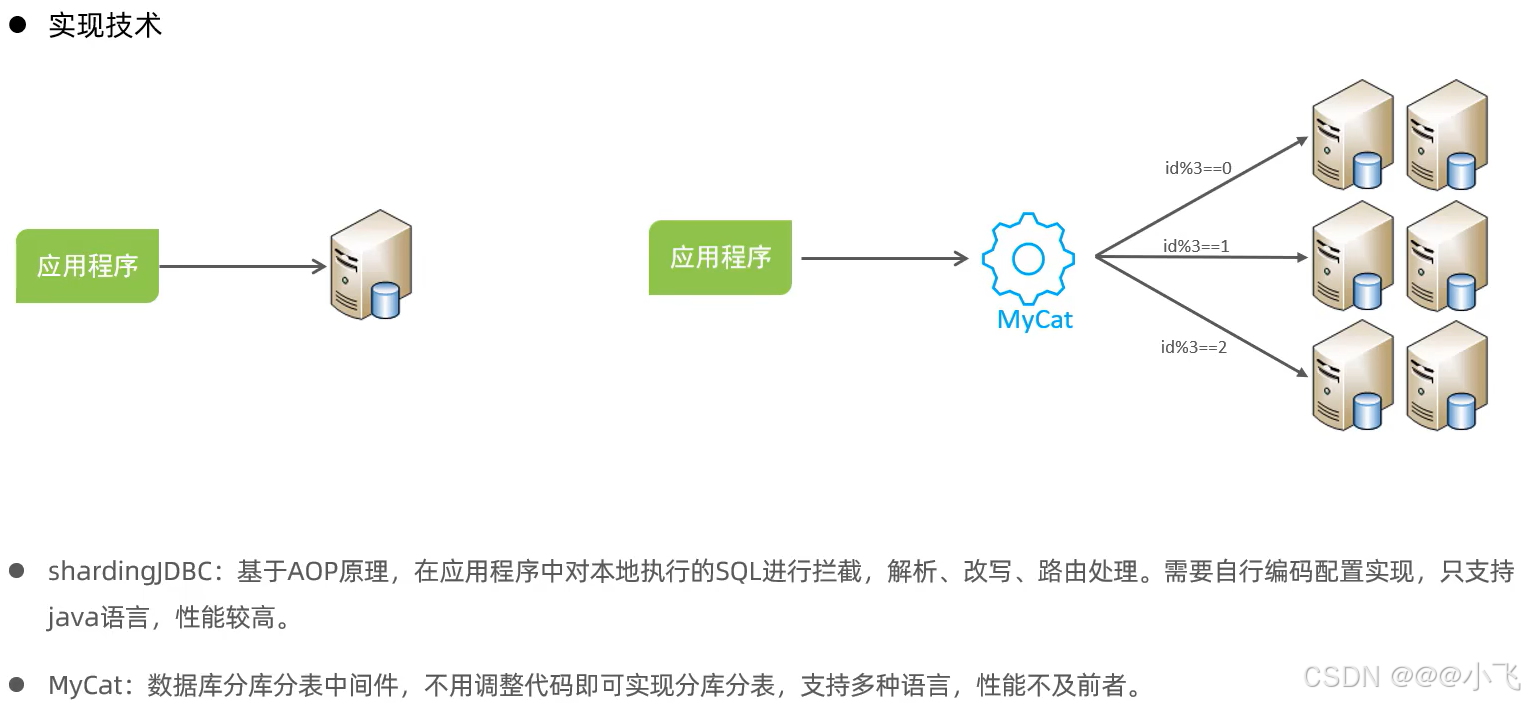
MyCat? ? ??
安裝與概述
MyCat下載鏈接
MyCat官方網站
由于 MyCat 目前沒有支持 MySQL8.0 之后的版本,所有需要修改一些東西:
在 Mycat 安裝目錄下的 lib 目錄有一個?mysql-connector-java-5.1.35.jar ,將其替換為?mysql-connector-j-8.0.33.jar 就可以連接 MySQL8.0 版本了
?mysql-connector-j-8.0.33.jar 下載可以到 Maven 倉庫中搜索
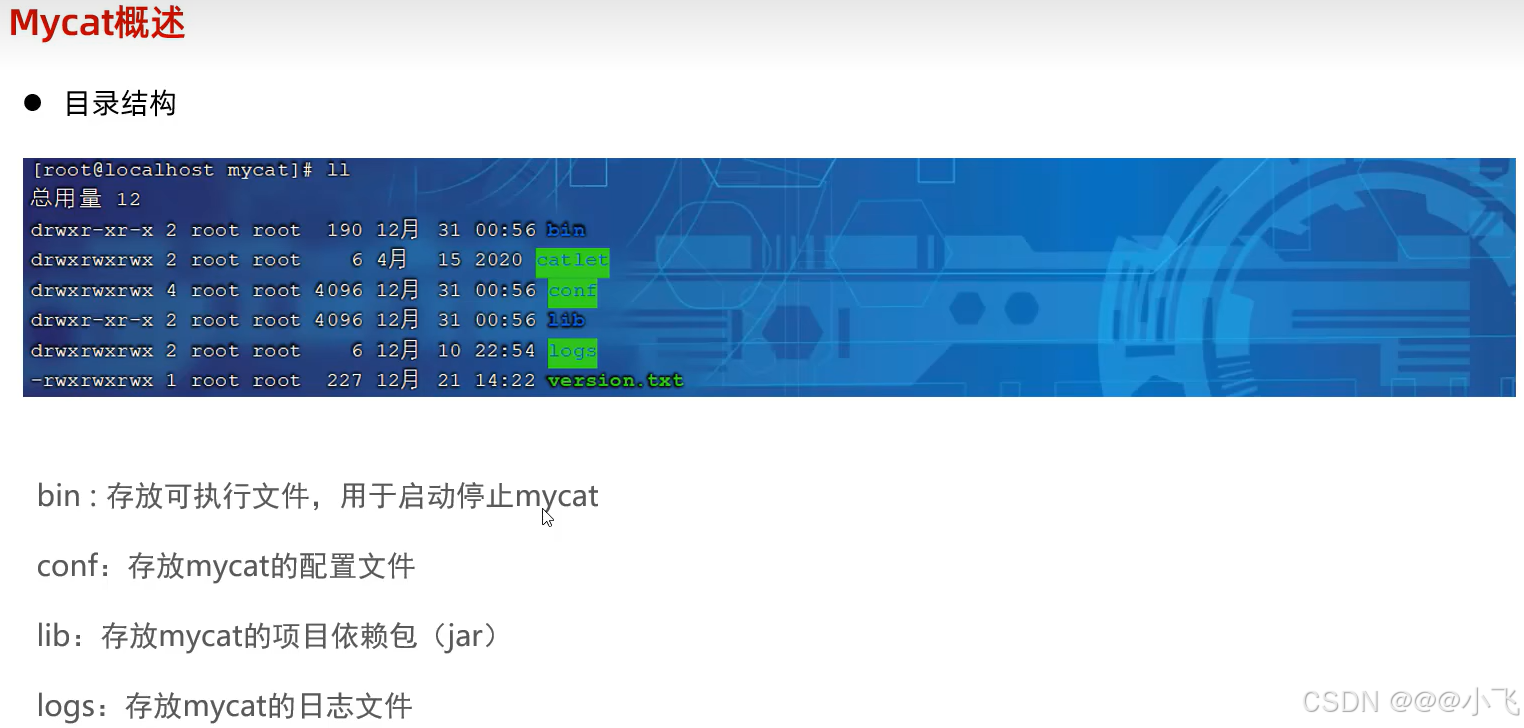
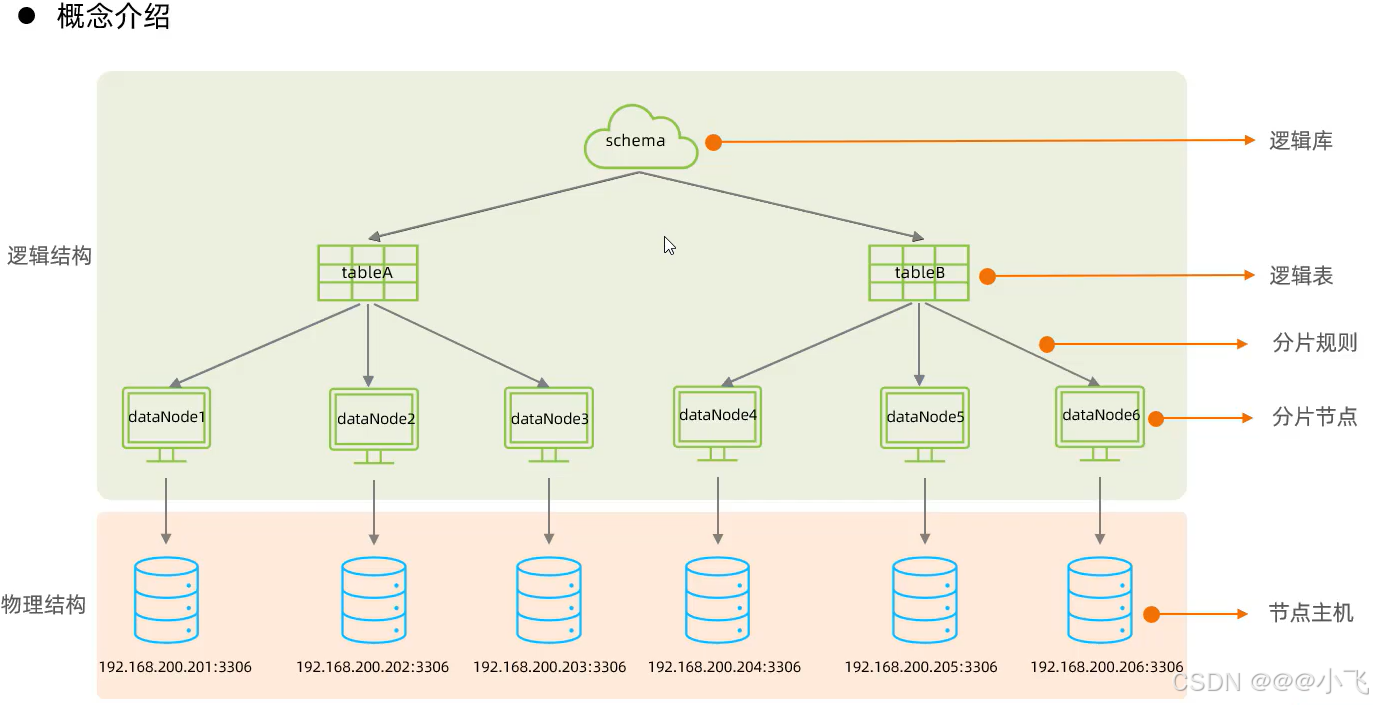
由于 MyCat 比較老,且多年未更新,到這就不往下學習 MyCat 了.........TMD
?








- 繪制子圖)










