非關系型數據庫的分類與特點
隨著數據量呈指數級增長和數據類型日益多樣化,傳統關系型數據庫在處理海量非結構化數據時面臨著嚴峻挑戰。非關系型數據庫(NoSQL)應運而生,它摒棄了傳統關系模型的約束,采用更靈活的數據存儲方式,為大數據時代的多樣化需求提供了解決方案。
2025 年,非關系型數據庫已經發展成為數據基礎設施的重要組成部分,根據其數據模型和存儲特點,可以將非關系型數據庫分為以下幾大類型:

鍵值(Key-Value)數據庫
鍵值數據庫是最簡單直觀的非關系型數據庫類型,它將數據存儲為鍵值對的集合,類似于哈希表結構。每個鍵都與一個且僅一個值相關聯,通過鍵可以快速訪問對應的值。
主要特點:
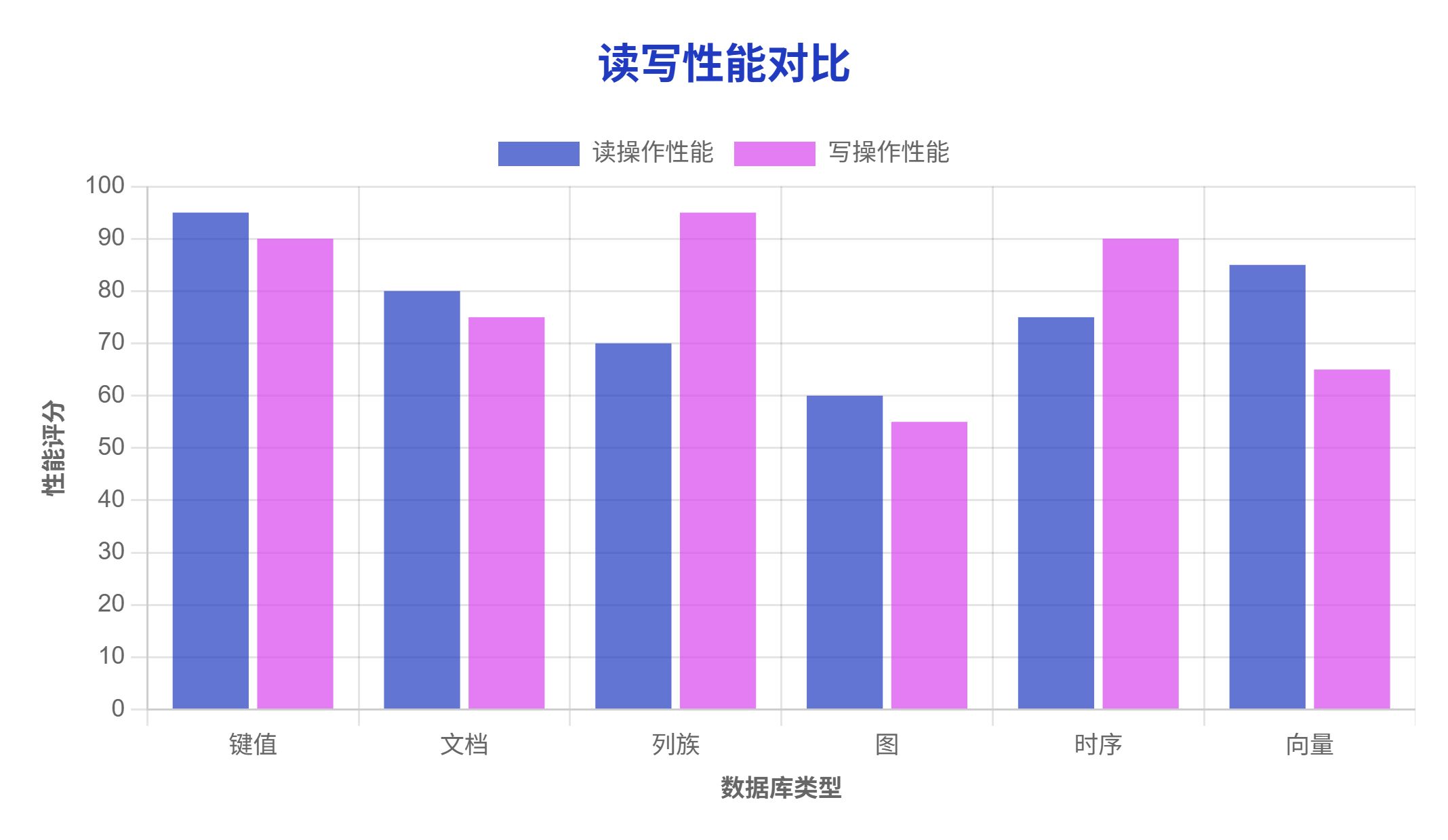
- 高性能:提供極快的讀寫速度,通常是 O(1)復雜度的操作
- 高擴展性:易于水平擴展,支持分布式架構
- 簡單靈活:無需預定義模式,可存儲任意類型的值
- 適合緩存場景:常用于會話管理、用戶配置存儲等
代表產品:
- Redis、DynamoDB、Riak、Memcached
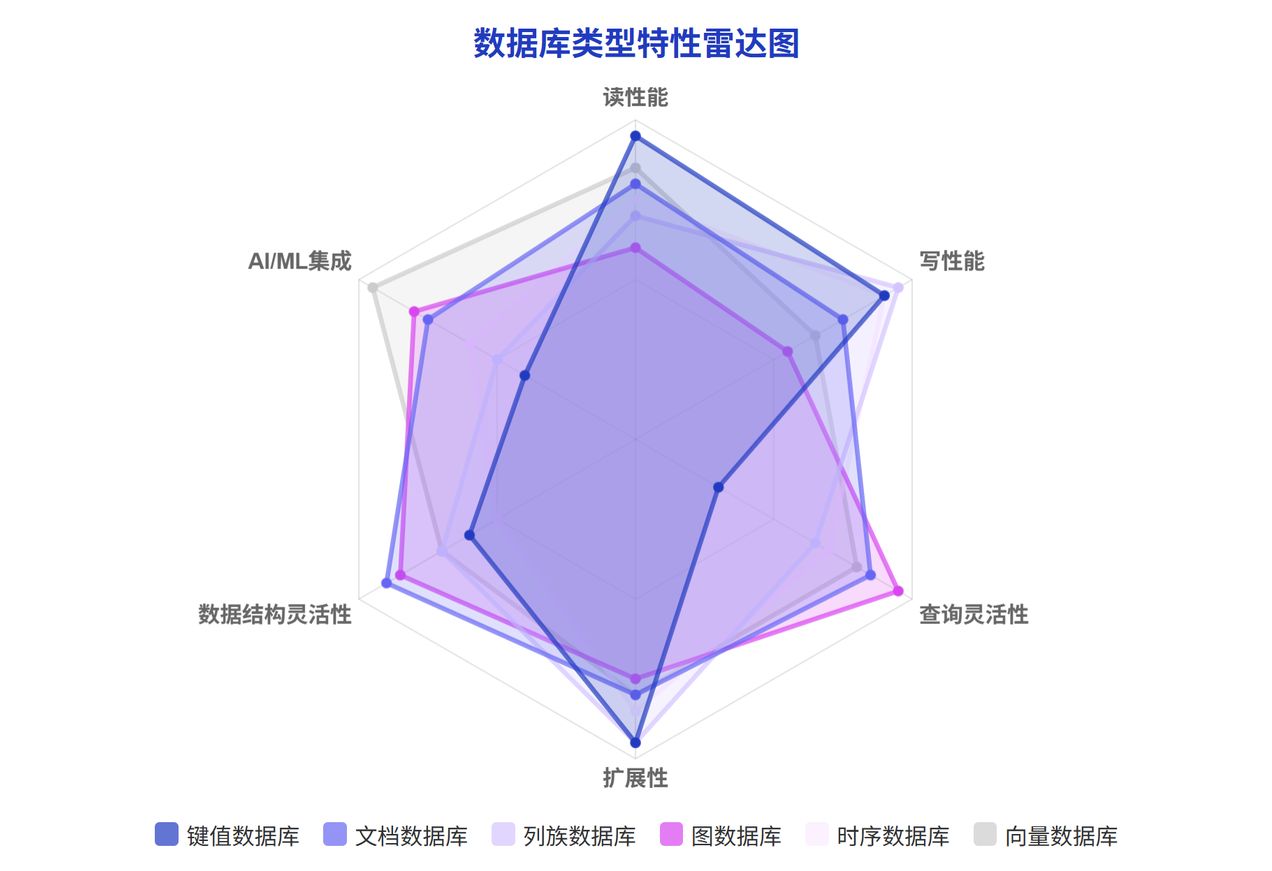
文檔(Document)數據庫
文檔數據庫將數據存儲在靈活的、類似 JSON 的文檔中,每個文檔可以有不同的結構,字段可以隨時添加、刪除或修改,無需預先定義模式。
主要特點:
- 模式靈活:無需預定義結構,可存儲半結構化數據
- 層次化數據:支持嵌套文檔和數組,適合表示復雜關系
- 豐富的查詢能力:支持字段、全文和地理空間查詢
- 開發友好:文檔結構通常與應用程序對象模型一致
代表產品:
- MongoDB、CouchDB、Elasticsearch、Azure?Cosmos DB
應用場景:
文檔數據庫特別適合存儲和管理半結構化數據,如:內容管理系統、用戶檔案、產品目錄、實時分析應用等。2025 年,隨著 AI 應用的普及,文檔數據庫在存儲和檢索非結構化內容方面發揮著關鍵作用,特別是在 RAG(檢索增強生成)系統中作為知識庫的基礎設施。
列族(Column-Family)數據庫
列族數據庫采用列式存儲模式,將相關的列組織在一起形成列族,適合處理大規模稀疏數據。這種設計使得列族數據庫在讀取特定列時非常高效,特別適合分析型工作負載。
主要特點:
- 高擴展性:設計用于處理 PB 級數據,易于水平擴展
- 列式存儲:按列而非按行存儲數據,適合分析查詢
- 高寫入吞吐量:優化的寫入路徑,適合高頻寫入場景
- 靈活的數據模型:同一表中不同行可以有不同的列
代表產品:
- Apache Cassandra、HBase、ScyllaDB、Google?Bigtable
應用場景:
列族數據庫特別適合時間序列數據、推薦系統、風險檢測、IoT 數據存儲等需要處理大量寫入并按特定維度進行分析的場景。在 2025 年的數據湖架構中,列族數據庫常作為原始數據的高效存儲層,為上層分析提供基礎。
圖(Graph)數據庫
圖數據庫專為存儲和查詢高度互聯的數據而設計,它使用節點、邊和屬性來表示和存儲數據,使復雜關系的查詢變得簡單高效。
主要特點:
- 關系優先:原生支持復雜關系的存儲和查詢
- 高性能關系查詢:相比關系型數據庫,在多級關系查詢上性能優越
- 直觀的數據模型:數據結構與現實世界的關系模型一致
- 靈活性:易于添加新類型的關系和節點
代表產品:
- Neo4j、Amazon Neptune、JanusGraph、OrientDB
應用場景:
圖數據庫特別適合社交網絡分析、推薦引擎、欺詐檢測、知識圖譜、網絡拓撲等需要處理復雜關系的場景。
時序(Time Series)數據庫
時序數據庫專為高效存儲、檢索和分析按時間索引的數據而設計,它針對時間戳數據進行了特殊優化,提供高效的寫入和查詢性能。
主要特點:
- 時間優化:針對時間序列數據的存儲和查詢進行優化
- 高寫入吞吐量:設計用于處理高頻率的數據點寫入
- 高效壓縮:針對時間序列數據的特點提供高效壓縮算法
- 專用函數:提供時間聚合、降采樣等專用分析功能
代表產品:
- InfluxDB、TimescaleDB、Prometheus、QuestDB
應用場景:
時序數據庫特別適合 IoT 數據存儲、應用監控、金融市場數據、傳感器數據分析等場景
向量(Vector)數據庫
向量數據庫是 2025 年最受關注的新興數據庫類型之一,它專為存儲和檢索高維向量數據而設計,主要用于支持機器學習和 AI 應用中的相似性搜索。
主要特點:
- 向量相似性搜索:高效執行 K 最近鄰(KNN)搜索
- 高維數據索引:針對高維向量的特殊索引結構
- AI?友好:與機器學習和深度學習模型無縫集成
- 多模態支持:可處理文本、圖像、音頻等多種數據類型的向量表示
代表產品:
- Pinecone、Milvus、Weaviate、Qdrant
應用場景:
向量數據庫在 2025 年的 AI 應用中扮演著核心角色,主要應用于語義搜索、推薦系統、圖像識別、異常檢測、RAG 系統等場景。
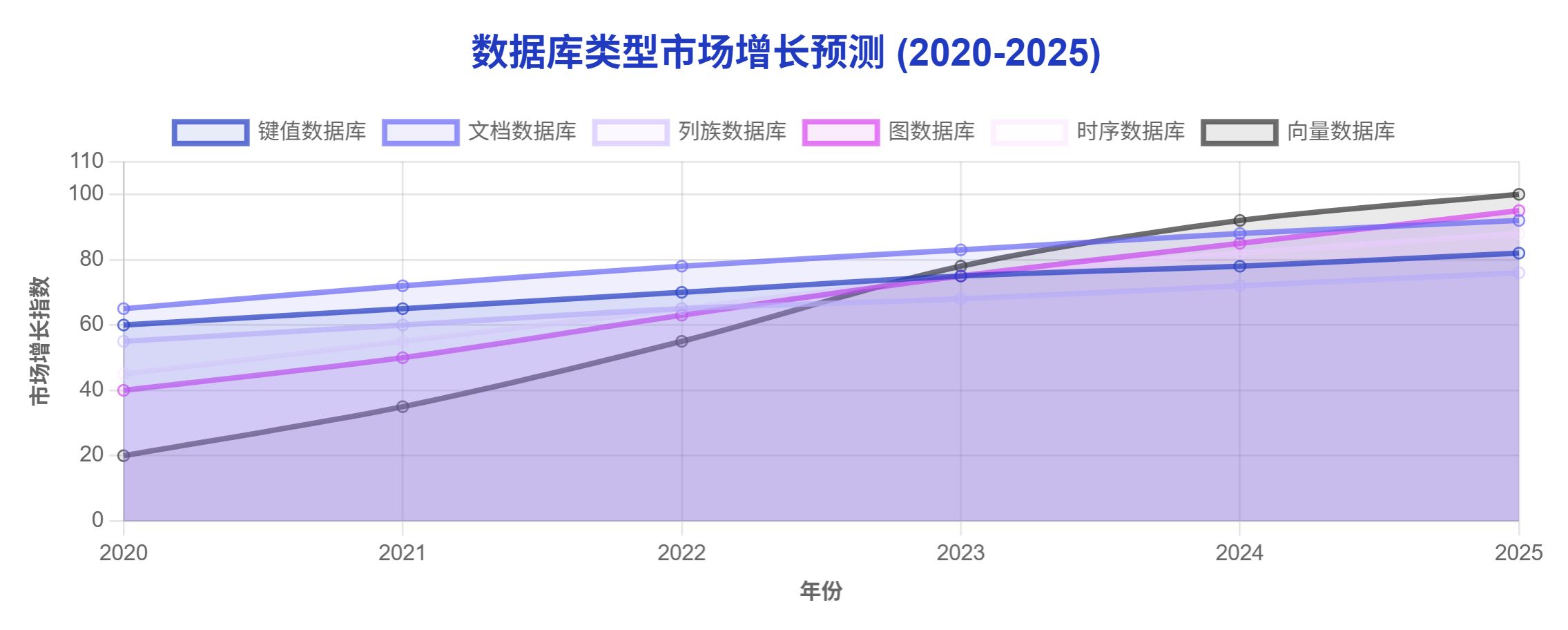
2025 年非關系型數據庫發展趨勢
隨著數據量的爆炸性增長和應用場景的多樣化,非關系型數據庫技術在 2025 年呈現出幾個明顯的發展趨勢:
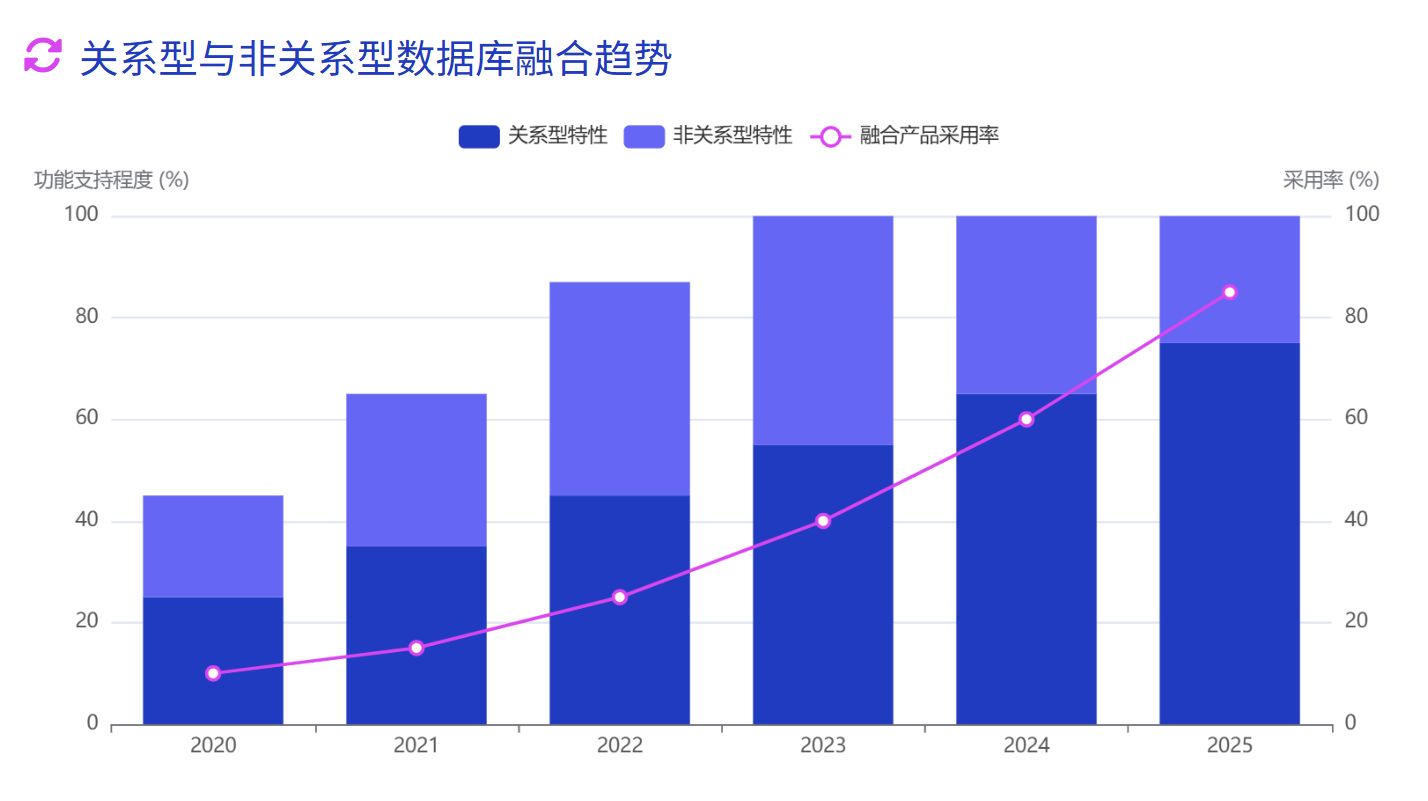
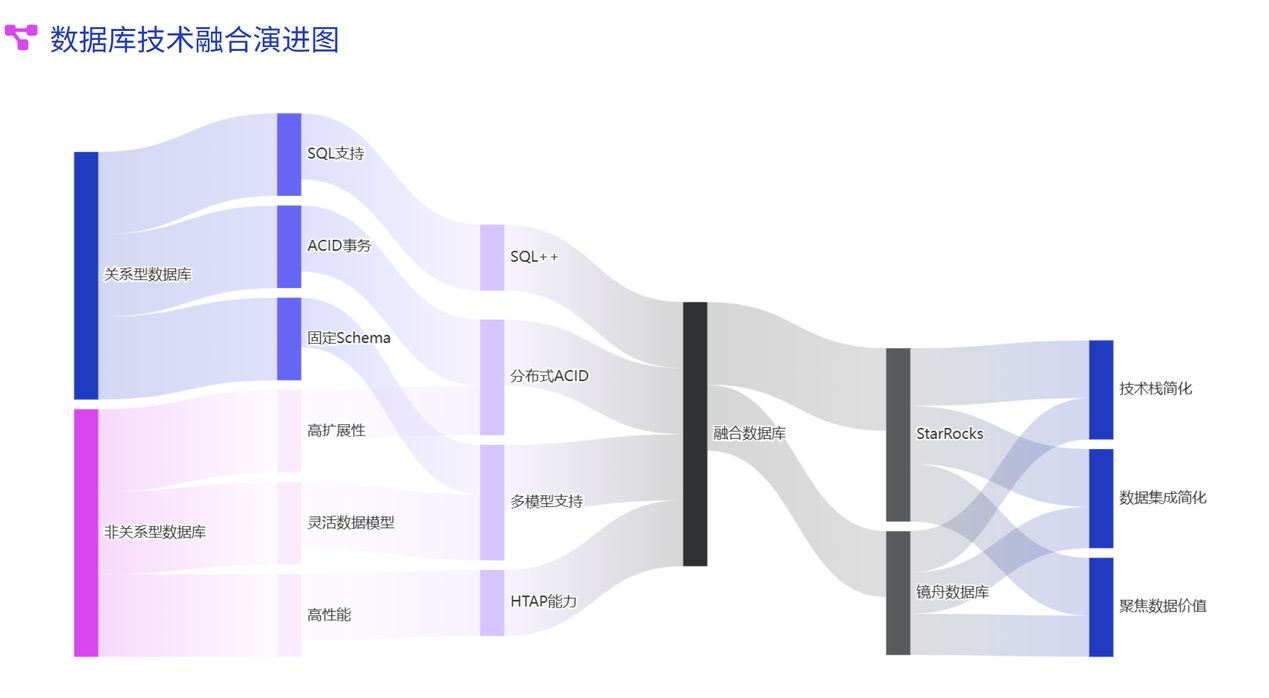
邊界模糊:關系型與非關系型的融合
2025 年,傳統的關系型與非關系型數據庫之間的界限正在逐漸模糊。一方面,傳統關系型數據庫如 PostgreSQL、MySQL 等不斷增強對 JSON、空間數據等非結構化數據的支持;另一方面,非關系型數據庫也在不斷增強對事務、ACID 特性和 SQL 查詢的支持。
這種融合趨勢催生了一批新型數據庫產品,如 StarRocks、鏡舟數據庫等,它們既保留了關系型數據庫的強一致性和 SQL 查詢能力,又具備非關系型數據庫的高擴展性和靈活性,為企業提供了更全面的數據管理解決方案。
融合的關鍵技術突破:
- 多模型支持:單一數據庫同時支持多種數據模型(文檔、圖、關系等)
- SQL++:擴展 SQL 以支持半結構化和非結構化數據查詢
- 分布式?ACID:在保持高擴展性的同時提供強一致性保證
- 混合事務分析處理(HTAP):同時支持事務處理和分析查詢工作負載
這種融合不僅簡化了企業的技術棧,還大大降低了數據集成的復雜性,使企業能夠更加專注于數據價值的挖掘而非底層技術的整合。
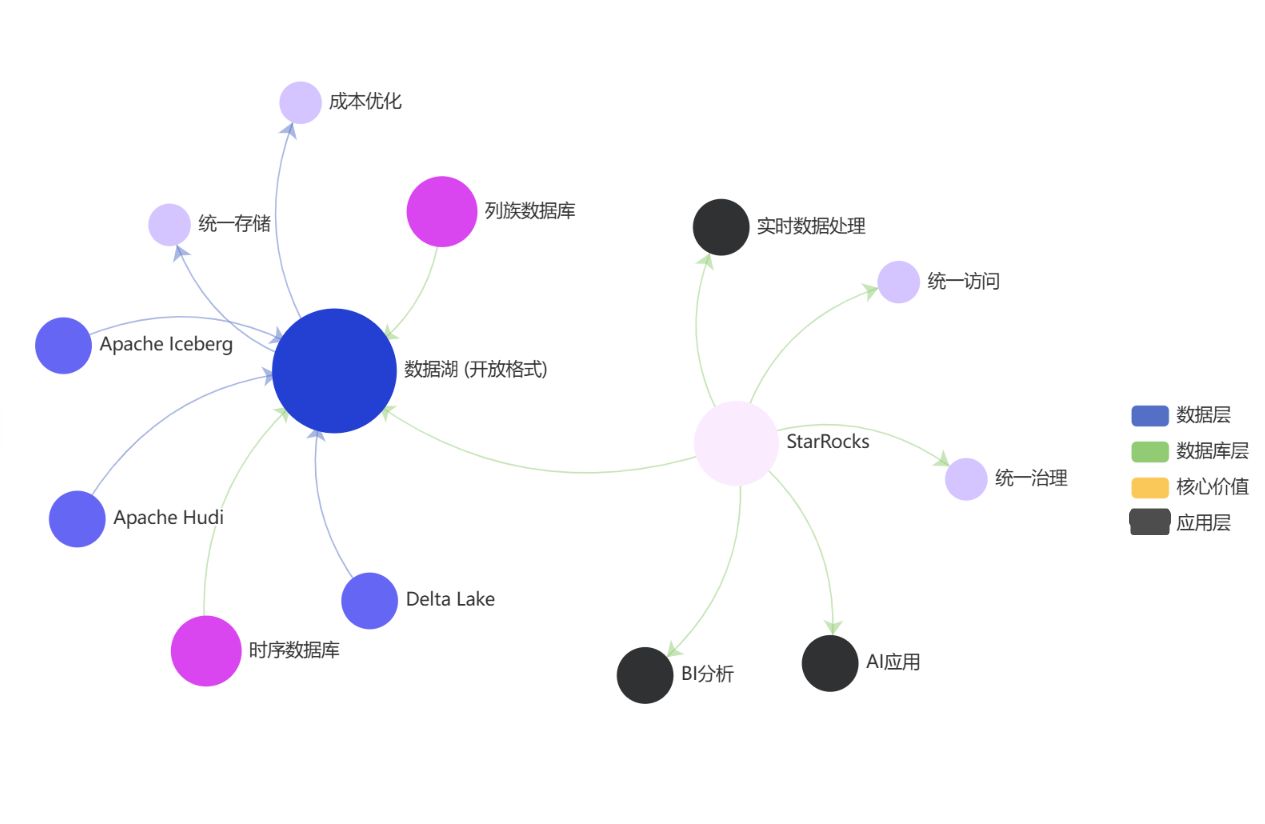
湖倉一體:數據湖與數據倉庫的統一
2025 年,湖倉一體(Lakehouse)架構已成為企業數據基礎設施的主流選擇。這種架構結合了數據湖的靈活性和低成本與數據倉庫的高性能和數據質量保證,為企業提供了統一的數據管理平臺。
在這一趨勢下,非關系型數據庫,特別是列族數據庫和時序數據庫,正在與開放數據格式(如 Apache Iceberg、Apache Hudi 和 Delta Lake)深度集成,形成新一代數據分析解決方案。
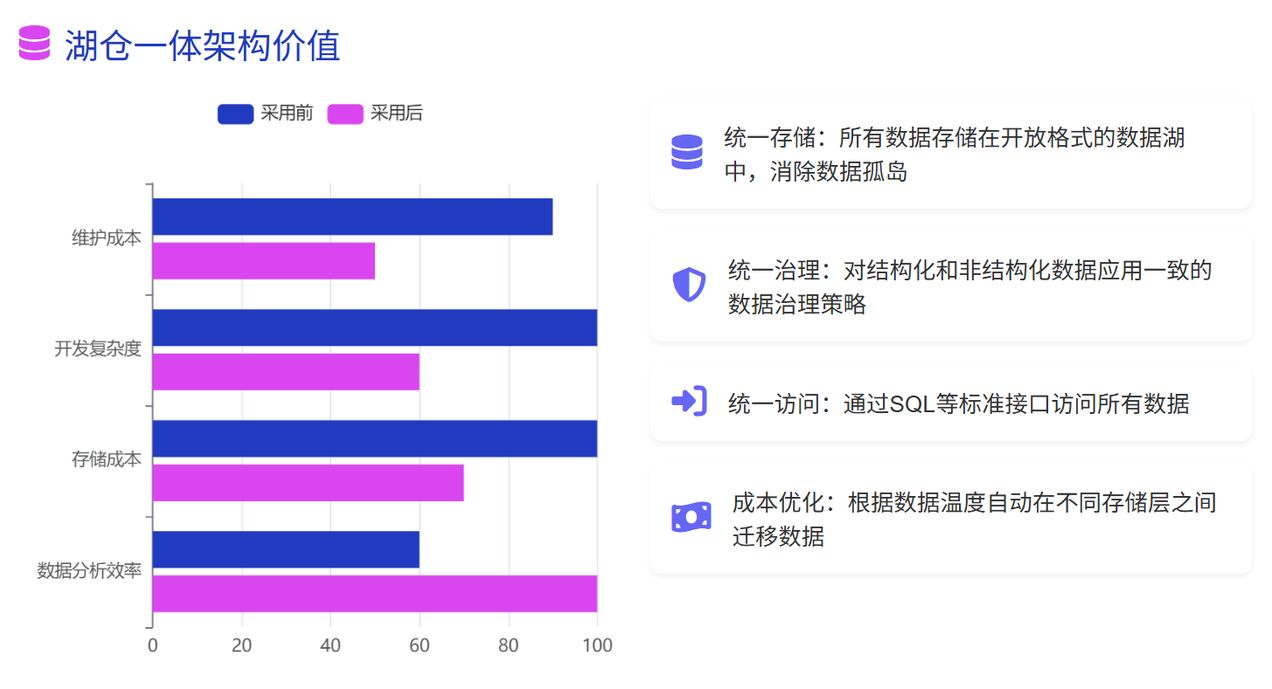
湖倉一體的核心優勢:
- 統一存儲:所有數據存儲在開放格式的數據湖中,消除數據孤島
- 統一治理:對結構化和非結構化數據應用一致的數據治理策略
- 統一訪問:通過 SQL 等標準接口訪問所有數據
- 成本優化:根據數據溫度自動在不同存儲層之間遷移數據
根據最新研究,采用湖倉一體架構的企業在數據分析效率上平均提升了 40%,同時將數據存儲成本降低了 30%以上。StarRocks 作為這一領域的創新者,通過其獨特的技術優勢,正在引領湖倉一體架構的實踐與發展。
AI 驅動的數據庫創新
2025 年,AI 技術與數據庫系統的深度融合已成為行業焦點。一方面,數據庫系統為 AI 應用提供數據存儲和檢索服務;另一方面,AI 技術也在重塑數據庫系統本身,從查詢優化到自動索引,從資源調度到異常檢測,AI 正在改變數據庫的設計和運行方式。
AI?與數據庫融合的主要方向:
- 自適應查詢優化:利用機器學習自動選擇最優查詢計劃
- 智能資源管理:預測工作負載并動態調整資源分配
- 自動化運維:AI 驅動的性能監控、故障預測和自愈能力
- 自然語言查詢:通過 Text-to-SQL 技術實現自然語言數據查詢
- 向量檢索能力:支持大規模向量相似性搜索,為 RAG 系統提供基礎
在這一趨勢下,StarRocks 已經在 AI 場景相關能力上持續提升,不僅支持向量檢索能力,還通過 Lakehouse 架構實現了一份開放格式的數據同時服務 AI 和 BI 等應用場景。
StarRocks:突破非關系型與關系型邊界的創新實踐
在數據庫技術邊界日益模糊的 2025 年,StarRocks 作為一款新一代分析型數據庫,正在重新定義數據庫的分類和應用邊界。雖然 StarRocks 基于關系模型設計,但它融合了多種非關系型數據庫的優勢特性,為企業提供了統一的數據分析解決方案。
融合非關系型數據庫的優勢特性
StarRocks 雖然基于關系模型設計,但它融合了多種非關系型數據庫的優勢特性,突破了傳統數據庫的邊界限制:
1.?列族數據庫的高性能分析能力
StarRocks 采用列式存儲引擎,類似于列族數據庫(如 Cassandra、HBase),但進一步優化了查詢性能:
- 向量化執行引擎,批量處理數據,充分利用現代 CPU 的 SIMD 指令
- 高效的數據壓縮算法,顯著降低存儲成本和 I/O 開銷
- 延遲物化技術,減少不必要的數據處理
2. 文檔數據庫的靈活模式支持
StarRocks 支持半結構化數據類型,如 ARRAY、MAP、STRUCT 和 JSON,使其能夠像文檔數據庫一樣靈活處理復雜數據結構:
- 生成列功能,可以百倍提速半結構化數據分析
- JSON 函數和操作符,支持復雜 JSON 數據的查詢和處理
- 靈活的模式演化,支持動態添加和修改列
3. 向量數據庫的?AI?支持能力
2025 年,StarRocks 已經增強了對 AI 應用的支持,特別是在向量檢索方面:
- 支持向量索引,用于高效的相似性搜索
- 與大語言模型集成,支持構建 RAG 應用
- 數據加工處理和部分列更新能力,提升模型數據準備和訓練效率
通過融合這些非關系型數據庫的優勢特性,StarRocks 為企業提供了一站式的數據分析解決方案,無需在不同類型的數據庫之間遷移和轉換數據。
鏡舟數據庫:StarRocks 的企業級實踐
鏡舟數據庫是 StarRocks 的商業化版本,在開源版本的基礎上提供了更多企業級特性和服務支持。作為 StarRocks 商業化公司,鏡舟科技推動社區持續迭代,同時與阿里云、騰訊、火山引擎等業界知名企業合作,共同推動 StarRocks 技術的發展和應用。
鏡舟數據庫的企業級增強:
鏡舟數據庫提供全面的企業級安全和管理功能:
- 細粒度的訪問控制和權限管理
- 數據加密和安全審計
- 多租戶資源隔離
- 完善的監控和告警系統
通過這些企業級增強,鏡舟數據庫為企業提供了更加可靠、安全和高效的數據分析解決方案,滿足企業在生產環境中的嚴苛需求。
企業實踐案例:StarRocks 打破數據孤島
在 2025 年的數據驅動型企業中,StarRocks 已成為打破數據孤島、實現統一分析的關鍵技術。以下是幾個典型的企業實踐案例,展示了 StarRocks 如何在實際應用中解決非關系型和關系型數據庫割裂的問題。
京東物流:統一分析平臺 Udata
京東物流基于 StarRocks 構建了服務分析一體化平臺 Udata,成功解決了多種數據源割裂的問題。在實施前,京東物流面臨多套實時存儲方案并存的挑戰,包括 ElasticSearch、ClickHouse 等多種非關系型數據庫,導致運維成本高昂、數據孤島嚴重。
實施方案:
京東物流采用 StarRocks 作為統一的分析引擎,逐步替換原有的 ElasticSearch 和 ClickHouse,實現實時層的存儲統一。同時,通過 StarRocks 的外部表功能,實現對 MySQL、Elasticsearch、Apache Hive 等多種數據源的聯邦查詢,打破數據隔離。
成果與價值:
- 實現了實時層存儲的統一,顯著降低了運維成本
- 打破了數據孤島,支持跨數據源的聯合分析
- 提升了查詢性能,滿足高并發、低延遲的業務需求
- 簡化了技術棧,降低了技術復雜度
58 集團:全業務線的深度實踐
58 集團作為中國領先的分類信息平臺,數據量龐大且類型多樣。在采用 StarRocks 之前,58 集團面臨著多種數據庫并存、查詢性能不足、運維復雜等挑戰。
實施方案:
58 集團基于 StarRocks 構建了統一的數據分析平臺,覆蓋全業務線的數據分析需求。他們充分利用 StarRocks 的多種數據模型(明細模型、聚合模型、主鍵模型)和多種導入方式,整合和接入了多種現有系統,包括 Apache Spark、Apache Flink、Apache Hive 和 ElasticSearch 等。
技術架構:
StarRocks 在 58 集團的應用中采用了分布式架構,對表進行水平劃分并以多副本存儲。集群規模可以靈活伸縮,支持 10PB 級別的數據分析,同時支持 MPP 并行加速計算和多副本容錯。
成果與價值:
- 統一了數據分析平臺,簡化了技術棧
- 顯著提升了查詢性能,支持更復雜的分析需求
- 增強了數據的可用性和可靠性
- 降低了總體擁有成本(TCO)
未來展望
2025 年,非關系型數據庫已經發展成為企業數據基礎設施的重要組成部分,與關系型數據庫一起,共同構成了現代數據管理的兩大支柱。然而,隨著技術的發展和業務需求的變化,傳統的數據庫分類邊界正在逐漸模糊,融合型數據庫解決方案正成為新的趨勢。
無論是傳統的非關系型數據庫還是新興的融合型解決方案,選擇適合的數據庫技術都應該以業務需求為導向,以數據價值為中心,為企業的數字化轉型和數據驅動決策提供堅實的技術基礎。





)




)



)




