論文信息
論文題目:Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion(Text-IF:利用語義文本指導退化感知和交互式圖像融合)
會議:CVPR2024
摘要:圖像融合的目的是將不同源圖像的信息結合在一起,形成具有綜合代表性的圖像。現有的融合方法在處理低質量源圖像的退化和對多種主客觀需求的非交互性方面通常是無能的。為了解決這些問題,我們引入了一種新的方法,利用語義文本引導圖像融合模型進行退化感知和交互式圖像融合任務,稱為TextIF。它創新性地將經典圖像融合擴展到文本引導下的圖像融合,并能夠協調地解決融合過程中的退化和交互問題。通過文本語義編碼器和語義交互融合解碼器,實現了一體化的紅外和可見光圖像降解感知處理和交互式柔性融合結果。這樣,Text-IF不僅實現了多模態圖像融合,而且實現了多模態信息融合。大量的實驗證明,本文提出的文本引導圖像融合策略在圖像融合性能和退化處理方面都比SOTA方法有明顯的優勢。
源碼鏈接:https://github.com/XunpengYi/Text-IF
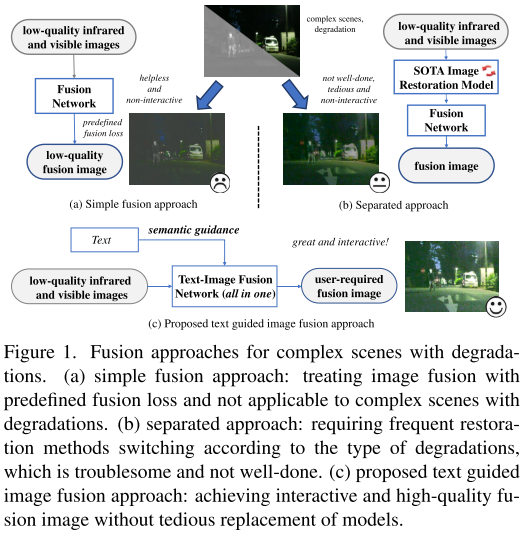
研究背景與問題
傳統的圖像融合方法,特別是紅外和可見光圖像融合,面臨著兩個關鍵挑戰:
退化處理困難:當源圖像存在低光照、過曝、噪聲、低對比度等退化問題時,現有融合方法無法有效處理,導致融合質量低下。
缺乏交互性:現有方法只能產生相對固定的融合結果,無法根據用戶的主觀需求和客觀應用任務進行靈活調整。
現有的解決方案通常需要先使用不同的圖像修復模型處理各種退化,再進行融合,這種分離式方法不僅繁瑣,還難以在增強和融合之間達到和諧統一。
核心創新點
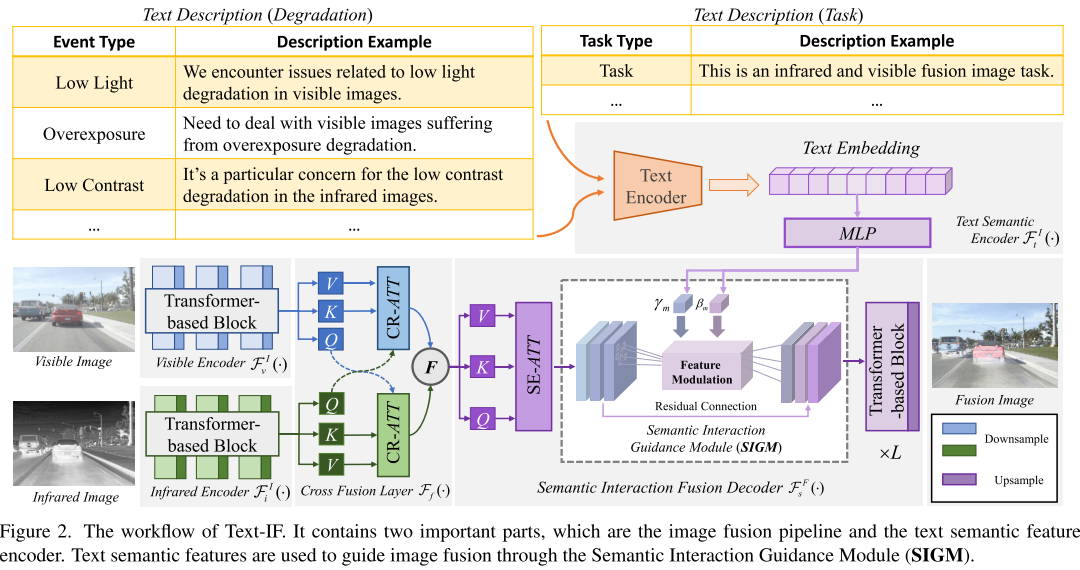
1. 首次引入文本引導的圖像融合范式
Text-IF開創性地將傳統的圖像融合任務擴展為文本引導的圖像融合,將融合公式從:
![]()
擴展為:
![]()
這種范式轉變使得用戶可以通過簡單的文本描述來指定融合需求和處理退化類型。I表示為圖像(可見與紅外),θ為網絡,F為函數。
2. 一體化退化感知處理
與需要針對不同退化類型切換多個修復模型的傳統方法不同,Text-IF使用相同的模型參數處理所有退化場景,包括:
- 可見光圖像的低光照、過曝問題
- 紅外圖像的噪聲、低對比度問題
3. 語義交互引導模塊(SIGM)
設計了專門的語義交互引導模塊,通過特征調制將文本語義信息與圖像融合特征耦合:
![]()
其中γ_m和β_m是從文本語義中提取的語義參數。
4. 基于Transformer的融合架構
采用Transformer/Restormer作為基礎特征提取器,結合交叉融合層和語義交互融合解碼器,實現高質量的多模態信息融合。
實驗結果與性能表現
數據集和實驗設置
- 使用MSRS、MFNet、RoadScene、LLVIP等主流數據集
- 訓練集:3618個圖像對,測試集:1135個圖像對
- 評估指標:SCD、SD、EN、VIF、QAB/F、CLIP-IQA、NIQE、MUSIQ、BRISQUE、SF

定量性能結果
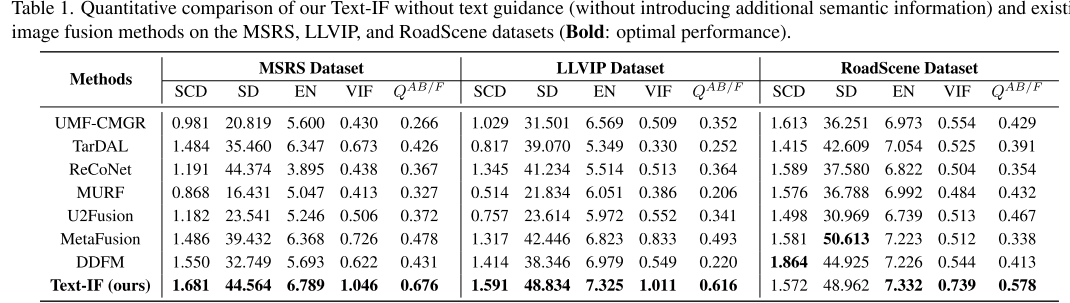
1. 無文本引導的性能比較 在MSRS數據集上,Text-IF在所有5個指標上都達到最佳性能:
- SCD: 1.681(最高)
- SD: 44.564(最高)
- EN: 6.789(最高)
- VIF: 1.046(最高)
- QAB/F: 0.676(最高)
在LLVIP數據集上同樣表現優異:
- SCD: 1.591, SD: 48.834, EN: 7.325, VIF: 1.011, QAB/F: 0.616
2. 文本引導下的退化處理性能 在各種退化場景下,Text-IF都顯著優于"SOTA修復方法+融合方法"的組合:
- 在MSRS低光照場景:CLIP-IQA達到0.132(最高)
- 在RoadScene過曝場景:SF指標達到17.766
- 在MFNet低對比度場景:MUSIQ達到48.625
高級任務性能驗證
在LLVIP數據集上進行的目標檢測實驗中,使用YOLOv8作為檢測backbone,Text-IF融合結果取得了最佳檢測性能:
- mAP@0.50: 0.941
- mAP@0.75: 0.676
- mAP@0.50:0.95: 0.602
定性結果分析
實驗結果顯示Text-IF在以下三個方面表現突出:
- 熱目標突出顯示:融合結果中熱目標的像素強度最高,目標最為突出
- 亮度和細節處理:展現更合適的亮度并提供更多細節信息
- 色彩保真度:呈現更生動自然的顏色,更符合視覺感知
消融實驗結果
論文對損失函數的各個組成部分進行了消融實驗:
- 強度損失:保持熱輻射目標的顯著性
- 顏色損失:保持色彩一致性
- 最大梯度損失:提供清晰的紋理信息
- 結構相似性損失:確保結構保真度
完整的損失函數組合取得最佳的定性和定量評估結果,驗證了方法的有效性。
技術優勢與意義
- 實用性強:用戶只需提供簡單的文本描述就能處理復雜的退化場景
- 通用性好:一個模型處理多種退化類型,避免模型切換的繁瑣
- 交互性強:支持用戶自定義融合需求,提供靈活的融合控制
- 性能優異:在多個數據集和評估指標上都達到了最先進的性能
結論
Text-IF成功地將文本語義引導引入圖像融合領域,不僅解決了現有方法在處理退化圖像時的困難,還實現了用戶交互式的個性化融合。這項工作為后續的文本引導圖像融合研究提供了可行的方向,在實踐應用和理論研究中都具有重要的促進作用。
該方法的創新性在于將多模態信息融合從傳統的圖像層面擴展到了文本-圖像的跨模態層面,為圖像融合技術的發展開辟了新的研究路徑。

)





![[學習筆記-AI基礎篇]03_Transfommer與GPT架構學習](http://pic.xiahunao.cn/[學習筆記-AI基礎篇]03_Transfommer與GPT架構學習)











