(一)list的了解
(1)簡單了解
list的文檔介紹
list是基于雙向鏈表的序列式容器,支持雙向迭代和任意位置的常數時間插入刪除,相比 array、vector 等容器在這類操作上更高效,但不支持隨機訪問(訪問需線性遍歷)且因額外空間存儲節點關聯信息,與 forward_list(單鏈表)相比功能更全但略復雜。對雙鏈表忘記的可以去查看博主的文章——雙鏈表。
樣子如下:(博主借用了老師的課件)
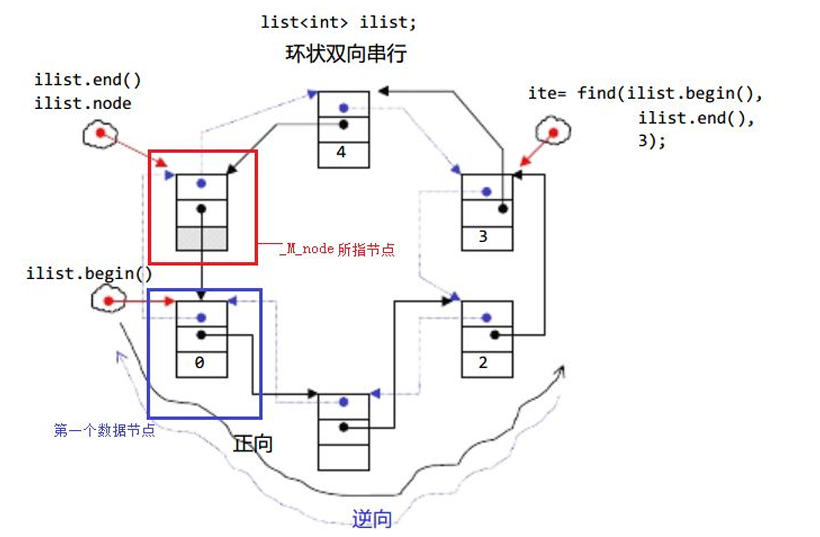
(2)常用接口
博主把解釋直接寫在圖片中了。
(1) 構造函數
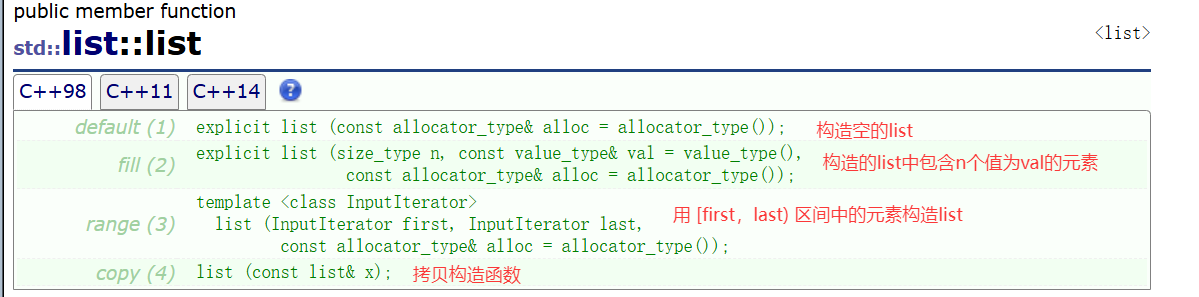
與之前的構造函數沒什么區別就不再介紹了?
(2) 迭代器
博主花了個簡易版方便大家查看
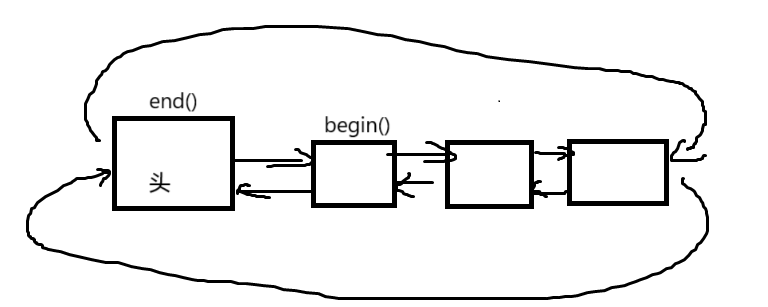
注意
- begin與end為正向迭代器,對迭代器執行++操作,迭代器向后移動
- ?rbegin(end)與rend(begin)為反向迭代器,對迭代器執行++操作,迭代器向前移動?
?迭代器分類(按照功能分類,即性質(底層結構決定))
1.單向向迭代器
- 核心功能:只能從容器到尾單向移動,支持讀取(部分支持修改)
- 支持的操作:++(前置 / 后置)、*(解引用讀)、->;不支持--、+=n等
- 典型容器:forward_list(單鏈表)、unordered_map/unordered_set(哈希容器)
2.雙向迭代器
- 核心功能:可雙向移動(支持
++和--),功能強于單向迭代器- 支持的操作:繼承單向向迭代器的所有操作,新增--(前置 / 后置);不支持隨機訪問(+=n等)
- 典型容器:list(雙向鏈表)、map/set(紅黑樹)
3.隨機訪問迭代器
- 核心功能:支持任意位置跳轉(隨機訪問),功能最強
- 支持的操作:繼承雙向迭代器的所有操作,新增+=n、-=n、[]、</>等關系運算
- 典型容器:vector、deque、array
總結:
功能繼承關系:隨機訪問迭代器 ? 雙向迭代器 ? 單向迭代器。即功能強的迭代器支持功能弱的迭代器的所有操作。
迭代器的分類本質是對移動和訪問能力的標準化,理解不同迭代器的功能邊界,能幫助我們正確選擇容器和算法,避免因迭代器功能不足導致的編譯錯誤。
?
(3) 容量

?因為他是鏈表,沒有提前擴容,也就沒有capacity了。
(4) 元素訪問

(5) 一些重要的函數?
?與vector不同的是,list有頭插和頭刪,vector沒頭插和頭刪因為效率太低但可以用insert和erase來進行頭插和頭刪)
(6) 操作/運行
這些能幫助我們快速寫一些題目

小細節:
1. splice 拼接
- 元素所有權轉移:將元素從一個鏈表移到另一個鏈表,原鏈表中被移動的元素會被移除(并非復制)。
- 迭代器有效性:被移動元素的迭代器仍有效,但歸屬權轉移到新鏈表。
- 自操作風險:若源鏈表和目標鏈表是同一個,需確保插入位置不在被移動元素范圍內,否則可能導致循環引用。
2. remove / remove_if 移除
- 值語義依賴:remove 依賴==運算符重載,remove_if 依賴自定義條件的正確性。
- 迭代器失效:被刪除元素的迭代器會失效,其他元素迭代器不受影響。
- 性能:會遍歷整個鏈表,時間復雜度為 O (n)。
3. unique 去重
- 僅刪除連續重復元素:需先通過sort使重復元素相鄰,否則無法刪除非連續的重復項。
4. merge 合并
- 前提條件:兩個鏈表必須已排序(默認升序),否則合并后結果無序。
- 破壞性合并:合并后源鏈表會被清空(元素全部轉移到目標鏈表)。
5. sort 排序
- 鏈表專屬排序:list 不支持標準庫std::sort(需隨機訪問迭代器),必須使用自身的sort成員函數。
- 穩定性:list::sort 是穩定排序(相同元素保持原有相對順序)。
- 性能:時間復雜度為 O (n log n),但因鏈表特性,實際效率略低于vector的排序。
6. reverse 逆置
- 僅反轉順序:不改變元素本身,僅調整節點間的指針關系,時間復雜度 O (n)。
使用:
#include <iostream>
#include <list>
using namespace std;void Print(const list<int>& lt)
{auto it = lt.begin();while (it != lt.end()){cout << *it << " ";++it;}cout << endl;
}void test_splice(list<int> l1, list<int> l2)
{cout << "l1 splice后:";l1.splice(l1.begin(), l2);Print(l1);cout << "此時l2后:";Print(l2);
}void test_remove(list<int> l1)
{cout << "l1 remove后:";l1.remove(5);Print(l1);
}void test_remove_if(list<int> l1)
{cout << "l1 刪除所有偶數后:";l1.remove_if([](int x) { return x % 2 == 0; });Print(l1);
}void test_unique(list<int> l2)
{cout << "l2 去掉重復后:";l2.unique();Print(l2);
}void test_reverse(list<int> l1)
{cout << "l1 reverse后:";l1.reverse();Print(l1);
}void test_merge(list<int> l1, list<int> l2)
{cout << "l1和l2排序后合并:";l1.sort(), l2.sort();l1.merge(l2);Print(l1);}int main() {list<int> l1 = { 1,4,6,9,2 };list<int> l2 = { 3,7,8,7,8,5,10 };cout << "原l1::";Print(l1);cout << "原l2::";Print(l2);test_splice(l1, l2);test_remove(l1); test_remove_if(l1);test_unique(l2); test_reverse(l1);test_merge(l1, l2);return 0;
}運行結果:
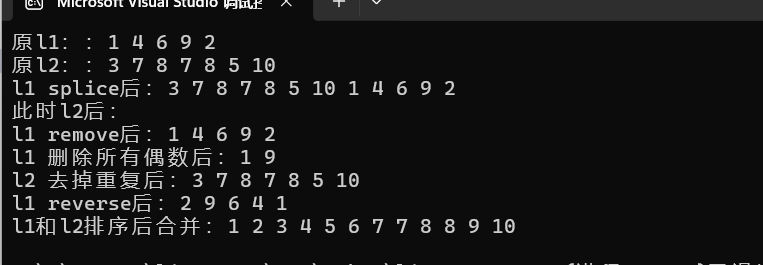 ?
?
(二)list的模擬
如上幾篇文章的模擬一樣,首先需要定義一個專屬命名空間。這次的準備工作博主就不細寫了。
(1) list的節點的實現
由上面了解可知list為帶頭雙向循環列表,那我們先來處理一下他的節點代碼吧。每個節點有兩個指針,一個指向上一個節點,一個指向下一個節點,然后還要儲存該節點空間。又因為不知道節點類型是什么所以我們使用類模板,類模板需要初始化。
template <class T>
struct list_node
{list_node<T>* _next;list_node<T>* _prev;T _val;list_node(const T& val = T()):_next(nullptr),_prev(nullptr),_val(val){}
};小細節:
struct list_node:
C++ 中 struct 默認成員訪問權限為 public,而 class 默認是 private
且節點的指針(_next、_prev)和數據(_val)需要被鏈表類(list)直接訪問,雖然這里節點主要被 list 類使用,但用 struct 可以省去顯式聲明 public 的步驟,使代碼更簡潔
list_node(const T& val = T()):
- const T& val:使用 const 引用接收參數,避免傳遞大型對象時的拷貝開銷,同時保證參數不會被修改
- 默認參數 T():當不提供初始值時,會調用 T 類型的默認構造函數生成一個臨時對象作為初始值(對于內置類型如 int,T() 會生成 0)
(2) list的鏈表的實現
?知道節點后我們就可以模擬list鏈表了,我們又由上幾篇模擬可知,代碼如下:
namespace Yu
{template <class T>struct list_node{//博主省空間這代碼就是上面的代碼};template <class T>class list{typedef list_node<T> Node;public://list實現內容private:Node* _head;size_t _size;};}小細節:
size_t _size:
方便快速獲取鏈表中有效元素的個數,避免每次需要獲取長度時都要遍歷整個鏈表。
(3) 構造函數
list()
{_head = new Node; // 創建哨兵位頭節點,并初始化_head->_next = _head; _head->_prev = _head; _size = 0; // 初始化元素個數為0
}(4) 迭代器
在鏈表(如list)中,我們無法像數組(如vector)那樣通過原生指針的++直接移動到下一個元素,因為鏈表的節點在內存中是非連續存儲的,節點之間通過指針(_next、_prev)關聯。此時,迭代器的作用就是模擬指針的行為,讓用戶可以用統一的方式(如*it訪問元素、++it移動位置)遍歷鏈表,而無需關心底層的存儲結構。細節解釋:
1.原生指針的局限性
- 鏈表的節點是分散存儲的,原生指針的++操作只會按固定字節(如 4/8 字節)移動,無法根據鏈表的_next指針找到下一個節點,因此內置類型的指針無法直接作為鏈表的迭代器。
2.迭代器的封裝思想
- 迭代器本質是一個封裝了節點指針的自定義類型(如list_iterator),它內部存儲了指向鏈表節點的指針(_node),通過重載運算符(*、->、++、--等),將鏈表節點的訪問和移動邏輯 “隱藏” 在運算符中
簡言之,迭代器是 “行為類似指針的自定義類型”,通過封裝節點指針和重載運算符,將鏈表的底層指針操作轉化為直觀的 “指針式” 接口,既適配了鏈表的非連續存儲特性,又保證了容器操作的統一性。C++可以用一個類去封裝這個內置類型,然后去重載運算符,就可以控制他的行為,達到我們的要求。
1.普通迭代器
template<class T>
struct list_iterator
{typedef list_node<T> Node;typedef list_iterator<T> Self;Node _node;list_iterator(Node* node):_node(node){}T& operator*(){return _node->_val;}T* operator->(){return &_node->val;}//前置++Self& operator++(){_node = _node->_next;return *this;}//后置++Self operator++(int){Self tmp(*this);_node = _node->_next;return tmp;}//前置--Self& operator--(){_node = _node->_prev;return *this;}//后置--Self operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}bool operator!=(const Self& x)const{return _node != x._node;}bool operator==(const Self& x)const{return _node == x._node;}};小細節:
T& operator*()
滿足*it通過解引用運算符,返回節點中儲存的數據(val)。模擬指針訪問值的行為
Self& operator++()
利用節點的_next指針(_node = _node->_next)移動到下一個節點,模擬指針向后移動的行為
Self& operator--()
利用_prev指針實現向前移動,適配雙向鏈表的特性。
這種設計讓鏈表的遍歷方式與數組、vector 等連續容器保持一致(都可以用for (auto it = begin(); it != end(); ++it)),符合 C++ 的 “泛型編程” 思想 —— 用戶無需區分容器類型,只需通過迭代器接口即可操作不同容器,降低了使用成本。
此時list類里面的調用:
//放在list類中 typedef list_iterator<T> iterator;//迭代器 iterator begin() {return iterator(_head->_next); }iterator end() {return iterator(_head); }小細節:
return iterator(_head->_next);節點為何能返回迭代器?
直接調用迭代器的構造函數創建臨時對象并返回
- iterator 是 list_iterator<T> 的別名,因此 iterator(_head->_next) 是顯式調用 list_iterator<T> 的構造函數,創建一個臨時的迭代器對象。
- 構造函數的參數 _head->_next 是 Node* 類型(即 list_node<T>*),而 list_iterator 的構造函數正好接受 Node* 作為參數:
2. const迭代器?
既然知道普通的迭代器,那是不是應該在考慮一下const成員的迭代器,因為普通迭代器調用const成員會權限放大,導致報錯,那const迭代器怎么寫了?
有人可能想到這樣
const list_iterator<T> const_iterator這樣是不對的,我們先來了解一下const的兩種改變:
1. const T* ptr1:
- const 修飾 T(在 * 左側),表示 ptr1 指向的 T 類型對象內容不可修改(*ptr1 = value 會報錯),但指針本身可以移動(ptr1++ 合法)。這是 “指向常量的指針”。
2. T* const ptr2:
- const 修飾 ptr2(在 * 右側),表示指針本身不可修改(ptr2++ 會報錯),但指向的對象內容可以修改(*ptr2 = value 合法)。這是 “常量指針”。
即const在*之前為指向內容不變,*之后為指向對象不可變
而const 迭代器的核心需求是:迭代器可以移動(類似 ptr1++),但通過迭代器訪問的內容不可修改(類似 *ptr1 為 const)。這正是與形式 1 更符合。
故正確的方法是:(跟普通迭代器類似就有幾個地方要改)
//這里博主就列出了改變的
struct __list_const_iterator
{typedef __list_const_iterator<T> Self;__list_const_iterator(Node* node):_node(node){}const T& operator*(){return _node->_val;}const T* operator->(){return &_node->_val;}// 下面為一樣內容
}在list里面調用:
//在list類里面 typedef __list_const_iterator<T> const_iterator; //迭代器 const_iterator begin() const {return const_iterator(_head->_next); }const_iterator end() const {return const_iterator(_head); }
3. 迭代器
我們發現普通迭代器和const迭代器有很多是一樣的,若兩個都寫太冗雜了,有什么好方法了?增加模板參數!
template<class T, class Ref, class Ptr>
struct __list_iterator
{typedef list_node<T> Node;typedef __list_iterator<T, Ref, Ptr> self;Node* _node;__list_iterator(Node* node):_node(node){}Ref operator*() const{return _node->_val;}Ptr operator->() const{return &_node->_val;}self& operator++(){_node = _node->_next;return *this;}self operator++(int){self tmp(*this);_node = _node->_next;return tmp;}self& operator--(){_node = _node->_prev;return *this;}self operator--(int){self tmp(*this);_node = _node->_prev;return tmp;}bool operator!=(const self& it) const{return _node != it._node;}bool operator==(const self& it) const{return _node == it._node;}
};小細節:?
template<class T, class Ref, class Ptr>
- T:節點中存儲的元素類型(基礎類型)。
- Ref:迭代器解引用(operator*)的返回類型(引用類型)。
- Ptr:迭代器箭頭運算符(operator->)的返回類型(指針類型)。
通過這三個參數,可靈活控制迭代器訪問元素的權限(是否為 const)。
在list里面調用:
typedef __list_iterator<T, T&, T*> iterator; typedef __list_iterator<T, const T&, const T*> const_iterator;后面的begin和end就如上面一樣
(5) push_back
博主為了方便測試上面迭代器是否對,使用先寫了一個push_back,其中這個可以在后面用insert復用的。后續的插入和刪除可以參考博主的數據結構的雙鏈表里面有圖片解釋。
void push_back(const T& val)
{Node* newNode = new Node(val);Node* _tail = _head->_prev;_head->_prev = newNode;newNode->_next = _head;_tail->_next = newNode;newNode->_prev = _tail;_size++;
}測試結果:
void test1()
{Yu::list<int> l1;l1.push_back(10);l1.push_back(20);l1.push_back(30);l1.push_back(40);for (auto it = l1.begin(); it != l1.end(); ++it){cout << *it << " ";}cout << endl;}
//測試結果:10 20 30 40(5) 拷貝構造
因為拷貝構造是將一個list復制到另一個list,使用先得初始化一下另一個list發現重復了,于是我們可以將初始化單獨列一個函數
void empty_Init()
{_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;
}此時構造函數和拷貝函數
//構造函數
list()
{empty_Init();
}//拷貝構造
list(const list<T>& lt)
{empty_Init();for (auto& e : lt){push_back(e);}
}小細節:
for (auto& e : lt)
1. 避免不必要的拷貝,提高效率
lt 是源鏈表中的元素集合,當遍歷 lt 時:
- 如果用 auto e,每次迭代都會對元素進行值拷貝(創建一個與原元素值相同的新對象)。如果元素類型是復雜類型(如自定義類、大型結構體),值拷貝可能會調用拷貝構造函數,產生額外的內存分配和數據復制開銷,降低效率。
- 而使用 auto& e 時,e 是原元素的引用(別名),不會創建新對象,直接訪問原元素,避免了不必要的拷貝操作,尤其對于大型數據或復雜類型,能顯著提升性能。
2. 保證 const 正確性(配合 const 引用更嚴謹)
- 在拷貝構造函數中,lt 是 const list<T>& 類型(常量引用),表示源鏈表不能被修改。
- 更規范的寫法其實是 for (const auto& e : lt),其中 const 修飾確保不會通過 e 意外修改源鏈表的元素,符合 "只讀取不修改" 的拷貝語義。如果寫成 auto e,雖然也能完成拷貝,但缺少 const 約束,理論上可以通過修改 e 影響原元素(雖然這里 e 是拷貝,實際不影響,但邏輯上不嚴謹)。
總結
auto& e(通常更推薦 const auto& e)的核心作用是:在保證不修改源數據的前提下,避免元素拷貝帶來的性能損耗,同時符合 const 正確性原則。
這是 C++ 中遍歷容器時的最佳實踐,尤其適用于拷貝成本高的元素類型。
(6) insert
iterator insert(iterator pos, const T& x)
{Node* cur = pos._node;Node* prev = cur->_prev;Node* newNode = new Node(x);prev->_next = newNode;newNode->_prev = prev;newNode->_next = cur;cur->_prev = newNode;++_size;return newNode;
}小細節:
return newNode;
insert函數返回新插入元素的迭代器,這是 C++ 標準庫中鏈表(std::list)的設計規范

主要有以下幾個原因:
1. 符合迭代器失效規則
- 插入操作不會導致其他迭代器失效,但用戶可能需要繼續操作新插入的元素。返回新節點的迭代器可以直接獲取這個位置,避免用戶重新遍歷查找。
為什么不會導致迭代器失效?
先了解鏈表的存儲特點和迭代器的本質
鏈表的存儲特點:
- 鏈表的節點在內存中是離散存儲的,節點之間通過指針(_next和_prev)關聯,而非像數組那樣連續占用一塊內存。插入新節點時,只需要修改相鄰節點的指針指向,不會移動其他已有節點的位置。
迭代器的本質:
- 鏈表的迭代器本質上是指向節點的指針封裝(代碼中_node成員就是節點指針)。只要迭代器指向的是某個具體節點,只要這個節點沒被刪除,指針就始終有效。
而插入操作的影響范圍
插入新節點時,只會修改插入位置前后兩個節點的指針(前節點的_next和后節點的_prev),但這兩個節點本身并沒有被移動或刪除:原迭代器如果指向這兩個節點,仍然有效(只是它們的指針成員被修改了)其他節點的指針和迭代器完全不受影響?
故insert操作僅通過局部指針調整完成插入,既不影響已有節點的存在,也不破壞原有迭代器與節點的對應關系,因此不會導致任何已有迭代器失效,且能通過返回值直接獲取新元素的迭代器
2. 支持鏈式操作
允許連續插入操作,例如:
auto it = l.insert(pos, 1);
l.insert(it, 2); // 在剛插入的元素前再插入3. 與標準庫行為一致
遵循 C++ 標準容器的設計習慣,這樣用戶切換容器時不需要修改使用習慣。
?(7)?erase
iterator erase(iterator pos)
{assert(pos != end());Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;prev->_next = next;next->_prev = prev;delete cur;--_size;return next;
}小細節:
?return next;
erase函數返回新插入元素的迭代器,這是 C++ 標準庫中鏈表(std::list)的設計規范

主要有以下幾個原因:
1. 被刪除節點的迭代器已失效
- 刪除操作中,delete cur會釋放被刪除節點的內存,因此傳入的參數pos(指向cur的迭代器)會變成野指針,徹底失效。如果不返回新的迭代器,用戶后續無法基于原位置繼續操作(比如繼續遍歷鏈表)。?
為什么會導致迭代器失效?
在鏈表的刪除操作(erase)中,只有被刪除節點的迭代器會失效,其他迭代器通常不會失效。
1. 為什么被刪除節點的迭代器會失效?
- 鏈表的迭代器本質是對節點指針的封裝(如pos._node指向具體節點)。刪除操作中,被刪除的節點(cur)會被delete釋放內存,此時指向該節點的迭代器(pos)所關聯的指針就變成了野指針(指向已釋放的內存)。野指針無法安全訪問,也不允許被使用(如解引用、遞增),因此這個迭代器徹底失效。
注意:
刪除操作后,被刪除節點的迭代器(pos)絕對不能再使用(如繼續解引用或遞增),否則會導致未定義行為(程序崩潰、數據錯誤等)。
因此,erase函數會返回被刪除節點的下一個節點的迭代器(next),用于替代失效的pos,保證后續操作的安全性(如繼續遍歷)。
后面兩點如上支持鏈式操作和與標準庫行為一致
小復用:
//尾插 void push_back(const T& val) {insert(end(), val); }//頭插 void push_front(const T& val) {insert(begin(), val); }//尾刪 void pop_back() {erase(--end()); }//頭刪 void pop_front() {erase(begin()); }這樣可以提高效率
測試結果:
void test2()
{Yu::list<int> l;l.push_back(1);l.push_back(2);l.push_back(3);auto it = l.begin();++it; l.insert(it, 4);cout << "插入后: ";for (auto e : l) {cout << e << " ";}cout << endl;it = l.begin();++it;++it; l.erase(it); cout << "刪除后: ";for (auto e : l) {cout << e << " ";}cout << endl;
}//運行結果:
//插入后: 1 4 2 3
//刪除后: 1 4 3(8) 析構函數
鏈表的節點是獨立分配的離散內存塊,必須逐個釋放,所以我們先寫一個clear函數
void clear()
{iterator it = begin();while (it != end()){it = erase(it);}_size = 0;
}作用:刪除鏈表中所有有效數據節點(不包括哨兵位頭節點_head),使鏈表回到 “空鏈表但可復用” 的狀態。
再寫一個鏈表是否為空的函數empty
bool empty()const
{return _size == 0;
}作用:快速判斷鏈表中是否包含有效數據節點(不含哨兵位)。
最后的析構函數
~list()
{if (!empty()){clear();}if (_head != nullptr){delete _head;_head = nullptr;}
}三者配合確保了鏈表在 “清空 - 復用 - 銷毀” 全生命周期中的內存安全,邏輯嚴謹且高效。
(9) operator=
我們繼續采用現代寫法因為他很方便
void swap(list<T>& lt)
{std::swap(_head, lt._head);std::swap(_size, lt._size);
}list<T>& operator=(list<T> lt)
//list& operator=(list lt)
{swap(lt);return *this;
}小細節:
list<T>& operator=(list<T> lt)和list& operator=(list lt)
這兩個都可以使用
list<T>& operator=(list<T> lt)
- 為完整寫法,顯式指定模板參數,這種寫法更完整和明確,博主還認為更好理解
list& operator=(list lt)
- 簡寫形式,省略模板參數,這里省略了<T>,直接使用list。在模板類的成員函數中,編譯器會自動將list解析為list<T>(當前模板實例化的類型)。這是 C++ 的語法簡化,在模板類內部可以省略模板參數,編譯器會根據上下文自動推導。
還有一些代碼沒有介紹,完整代碼——gitee
(三) list與wvctor的比較
| 特性 | vector | list |
|---|---|---|
| 隨機訪問 | 支持([]或at(),時間復雜度O(1)) | 不支持(需從頭 / 尾遍歷,時間復雜度O(n)) |
| 插入 / 刪除效率 | 頭部 / 中間插入 / 刪除:O(n)(需移動后續元素) 尾部插入 / 刪除:O(1)(未擴容時) | 任意位置插入 / 刪除:O(1)(只需修改指針,無需移動元素) |
| 內存占用 | 額外內存少(僅需存儲元素和少量管理信息),但可能有內存浪費(擴容預留空間) | 額外內存多(每個節點需存儲兩個指針),無預留空間浪費 |
| 迭代器穩定性 | 插入 / 刪除元素可能導致迭代器失效(如擴容后原指針指向舊內存) | 插入元素時迭代器不失效(僅修改指針);刪除元素時,只有被刪除節點的迭代器失效 |
| 遍歷效率 | 高(連續內存,緩存友好,CPU 緩存命中率高) | 低(分散內存,緩存不友好,頻繁換頁) |
| 擴容成本 | 可能觸發擴容(復制元素,時間復雜度O(n)) | 無擴容概念(按需分配節點) |
總結
- vector 是 “以空間換時間” ,適合隨機訪問和尾部操作,遍歷效率高,但中間操作成本高。
- list 是 “以時間換空間” ,適合頻繁插入 / 刪除(尤其是中間位置),迭代器穩定,但隨機訪問和遍歷效率低。
實際開發中,需根據操作類型(隨機訪問 / 插入刪除)、數據規模和性能需求選擇:多數場景下vector更常用(因其綜合性能更優),僅在頻繁中間操作時考慮list。
以上就是list的知識點了,后續的完善工作我們將留待日后進行。希望這些知識能為你帶來幫助!如果覺得內容實用,歡迎點贊支持~ 若發現任何問題或有改進建議,也請隨時與我交流。感謝你的閱讀
?
:建容器需要進一步了解的概念)
)





: 存儲引擎》)


:運算)




![Agents-SDK智能體開發[4]之集成MCP入門](http://pic.xiahunao.cn/Agents-SDK智能體開發[4]之集成MCP入門)



