C++擴展 --- 并發支持庫(下)![]() https://blog.csdn.net/Small_entreprene/article/details/149606406?fromshare=blogdetail&sharetype=blogdetail&sharerId=149606406&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link?
https://blog.csdn.net/Small_entreprene/article/details/149606406?fromshare=blogdetail&sharetype=blogdetail&sharerId=149606406&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link?
atomic
為什么需要原子操作的概念?這是因為在多線程中,可能會存在兩個線程同時去對同一個對象/變量進行讀或寫,同時讀是沒有問題的,同時寫/一讀一寫就會有線程安全的問題,前面講過了解決線程安全問題的一種方式 --- 加互斥鎖!
但是有時候加互斥鎖是一種比較重的操作,加鎖會有這樣的問題:
一個線程獲取到鎖之后,進來了,其他想要獲取受該鎖保護資源的話,就需要在解鎖之前進行阻塞等待,然而由運行變阻塞,由阻塞變運行,這其實就是進程調度,是需要進行保存上下文,恢復上下文等操作的!這些都是需要付出代價的,如果臨界區非常的端們也就是保護的資源很少,就不如僅僅是對一個整型變量做++操作,加鎖解鎖就非常的不劃算!
我們就可以使用原子操作 --- atomic
atomic 是一個模板的實例化和全特化均定義的原子類型,它可以保證對一個原子對象的操作是線程安全的。--- 對原子對象的操作是不需要加鎖的!!!
對 T 類型的要求:模板可用任何滿足可復制構造(CopyConstructible)及可復制賦值(CopyAssignable)的可平凡復制(TriviallyCopyable)類型 T 實例化。簡單點就是拷貝賦值的實現不是深拷貝的,并不是說拿一個 vector 的類放進去就可以實現后面對 vector 的操作都是原子的了!
T 類型用以下函數判斷時,如果一個返回 false,則用于 atomic 不是原子操作:
-
std::is_trivially_copyable<T>::value -
std::is_copy_constructible<T>::value -
std::is_move_constructible<T>::value -
std::is_copy_assignable<T>::value -
std::is_move_assignable<T>::value -
std::is_same<T, typename std::remove_cv<T>::type>::value
struct Date
{int _year = 1;int _month = 1;int _day = 1;
};template<class T>
void check()
{cout << typeid(T).name() << endl;cout << std::is_trivially_copyable<T>::value << endl;cout << std::is_copy_constructible<T>::value << endl;cout << std::is_move_constructible<T>::value << endl;cout << std::is_copy_assignable<T>::value << endl;cout << std::is_move_assignable<T>::value << endl;cout << std::is_same<T, typename std::remove_cv<T>::type>::value << endl<< endl;
}int main()
{check<int>();check<double>();check<int*>();check<Date>();check<Date*>();check<string>();check<string*>();return 0;
}atomic 的功能
-
基本運算支持:對于整形和指針,atomic 支持基本加減運算和位運算。
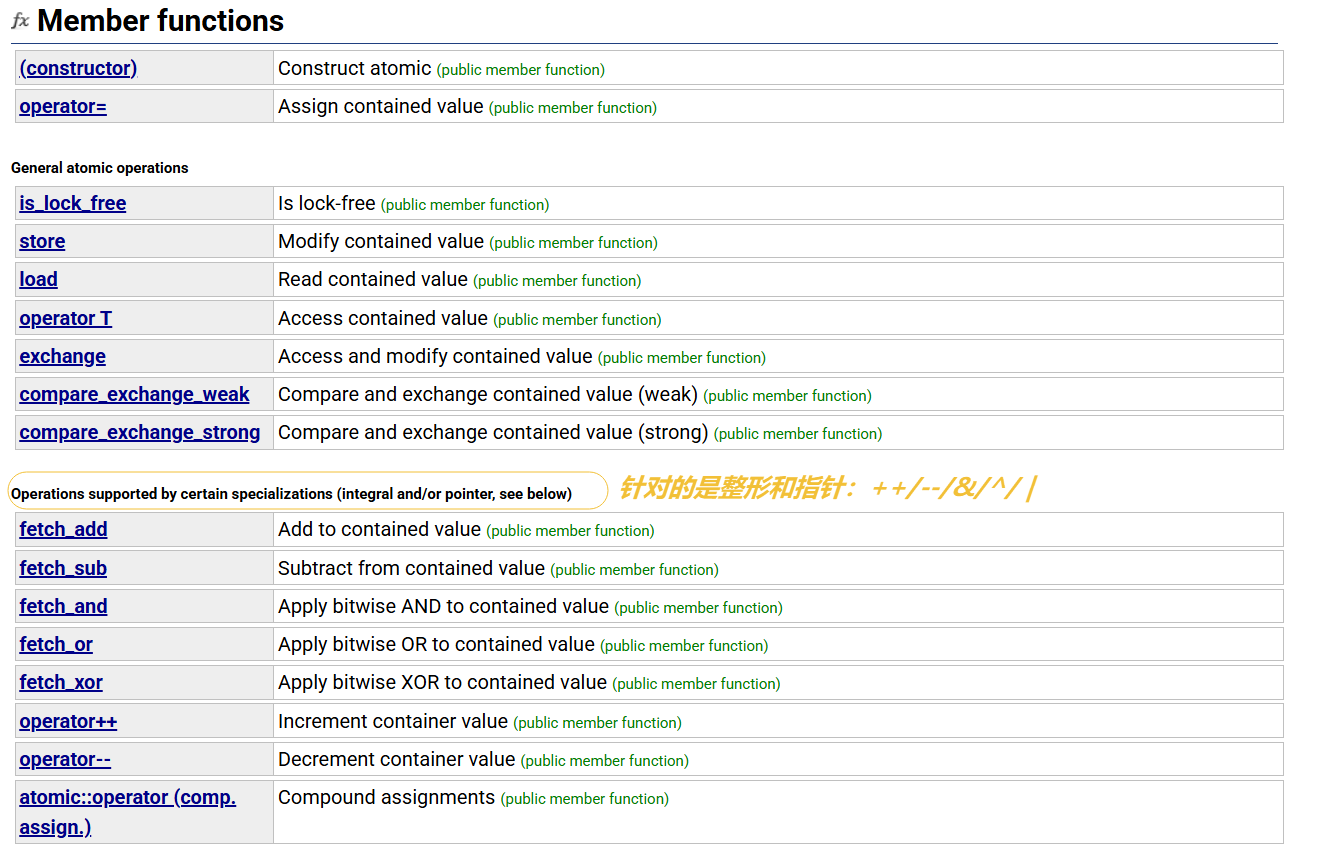
-
load 和 store:可以原子地讀取和修改 atomic 封裝存儲的 T 對象。
-
原理:atomic 的原理主要是硬件層面的支持。現代處理器提供了原子指令來支持原子操作,例如在 x86 架構中有 CMPXCHG(比較并交換)指令。這些原子指令能夠在不可分割的操作中完成對內存的讀取、比較和寫入操作,簡稱 CAS(Compare And Set 或 Compare And Swap)。為了處理多個處理器緩存之間的數據一致性問題,硬件采用了緩存一致性協議。當一個 atomic 操作修改了一個變量的值時,緩存一致性協議會確保其他處理器緩存中的相同變量副本被正確地更新或標記為無效。
-
實踐當中最多還是針對整形和指針,C++20之后還針對了智能指針!對浮點數的支持也是在C++20以后才有被更好的支持的
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;atomic_int acnt;int cnt;void f()
{for (int n = 0; n < 100000; ++n){++acnt;++cnt;}
}int main(){std::vector<thread> pool;for (int n = 0; n < 4; ++n)pool.emplace_back(f);for (auto& e : pool)e.join();cout << "原子計數器為 " << acnt << '\n'<< "非原子計數器為 " << cnt << '\n';return 0;} .section .text.startup,"ax",@progbits.p2align 4,,15.globl main.type main, @function
main:
.LFB0:.cfi_startprocpushq %rbp # 保存基指針寄存器.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp # 設置基指針寄存器.cfi_def_cfa 6, 16andq $-16, %rsp # 對齊棧指針subq $32, %rsp # 為局部變量分配棧空間movl $4, -4(%rbp) # 初始化線程數量為4xorl %eax, %eax # 清零寄存器eaxmovl %eax, -8(%rbp) # 初始化線程索引為0movl %eax, -12(%rbp) # 初始化線程池指針為nullptrmovl %eax, acnt(%rip) # 初始化原子計數器為0movl $0, cnt(%rip) # 初始化非原子計數器為0.L2:movl -8(%rbp), %eax # 加載線程索引cmpl $4, %eax # 比較線程索引是否小于4jae .L3 # 如果不小于4,跳轉到.L3movq -12(%rbp), %rdx # 加載線程池指針leaq 8(%rdx), %rax # 計算下一個線程對象的地址movq %rax, -12(%rbp) # 更新線程池指針movl $0, (%rdx) # 初始化線程對象movq -12(%rbp), %rdx # 加載線程對象地址movq %rdx, %rdi # 將線程對象地址傳給f函數call f # 調用f函數movl -8(%rbp), %eax # 加載線程索引addl $1, %eax # 增加線程索引movl %eax, -8(%rbp) # 更新線程索引jmp .L2 # 跳轉回.L2繼續循環.L3:movq -4(%rbp), %rax # 加載線程數量testq %rax, %rax # 測試線程數量是否為0je .L5 # 如果為0,跳轉到.L5
.L4:movq -4(%rbp), %rdx # 加載線程數量decq %rdx # 減少線程數量movq %rdx, -4(%rbp) # 更新線程數量movq (%rdx), %rdx # 加載線程對象地址movq %rdx, %rdi # 將線程對象地址傳給join函數call *%rdx # 調用join函數jmp .L4 # 跳轉回.L4繼續循環.L5:movl acnt(%rip), %eax # 加載原子計數器的值movl %eax, -16(%rbp) # 保存原子計數器的值movl cnt(%rip), %eax # 加載非原子計數器的值movl %eax, -20(%rbp) # 保存非原子計數器的值movl -16(%rbp), %eax # 加載保存的原子計數器的值movl %eax, -24(%rbp) # 保存原子計數器的值到輸出緩沖區movl -20(%rbp), %eax # 加載保存的非原子計數器的值movl %eax, -28(%rbp) # 保存非原子計數器的值到輸出緩沖區movl $0, %eax # 清零寄存器eaxmovq -24(%rbp), %rsi # 加載原子計數器的值到rsimovq %rsi, (%rsp) # 將原子計數器的值放入棧中movl $.LC0, %edi # 加載格式化字符串地址到edimovq %rsp, %rsi # 將棧頂地址傳給printf函數movq %rsp, %rdx # 再次將棧頂地址傳給printf函數subq $32, %rsp # 為printf函數分配棧空間call std::cout@plt # 調用cout函數輸出原子計數器的值addq $32, %rsp # 恢復棧空間movl -28(%rbp), %eax # 加載非原子計數器的值movl %eax, -32(%rbp) # 保存非原子計數器的值到輸出緩沖區movl $0, %eax # 清零寄存器eaxmovq -32(%rbp), %rsi # 加載非原子計數器的值到rsimovq %rsi, (%rsp) # 將非原子計數器的值放入棧中movl $.LC1, %edi # 加載格式化字符串地址到edimovq %rsp, %rsi # 將棧頂地址傳給printf函數movq %rsp, %rdx # 再次將棧頂地址傳給printf函數subq $32, %rsp # 為printf函數分配棧空間call std::cout@plt # 調用cout函數輸出非原子計數器的值addq $32, %rsp # 恢復棧空間movq %rbp, %rsp # 恢復棧指針popq %rbp # 恢復基指針寄存器ret # 返回調用者.cfi_endproc
.LFE0:.size main, .-mainCAS 接口
-
gcc 支持的 CAS 接口:
bool __sync_bool_compare_and_swap (type *ptr, type oldval, type newval); type __sync_val_compare_and_swap (type *ptr, type oldval, type newval); -
Windows 支持的 CAS 接口:
InterlockedCompareExchange ( __inout LONG volatile *Target, __in LONG Exchange, __in LONG Comperand); -
C++11 支持的 CAS 接口:封裝就是為了跨平臺了!!!
template <class T> bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val) noexcept; template <class T> bool atomic_compare_exchange_strong (atomic<T>* obj, T* expected, T val) noexcept; -
C++11 中 atomic 類的成員函數:
bool compare_exchange_weak (T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept; bool compare_exchange_strong (T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept;
代碼樣例:?
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;atomic<int> acnt;
//atomic_int acnt;
int cnt;void Add1(atomic<int>& cnt)
{int old = cnt.load();// 如果cnt的值跟old相等,則將cnt的值設置為old+1,并且返回true,這組操作是原子的。// 那么如果在load和compare_exchange_weak操作之間cnt對象被其他線程改了// 則old和cnt不相等,則將old的值改為cnt的值,并且返回false。//while (!atomic_compare_exchange_weak(&cnt, &old, old + 1));while (!cnt.compare_exchange_weak(old, old + 1));//使用成員函數也可以
}void f()
{for (int n = 0; n < 100000; ++n){//++acnt;// Add1的用CAS模擬atomic的operator++的原子操作Add1(acnt);++cnt;}
}int main()
{std::vector<thread> pool;for (int n = 0; n < 4; ++n)pool.emplace_back(f);for (auto& e : pool)e.join();cout << "原子計數器為 " << acnt << '\n'<< "非原子計數器為 " << cnt << '\n';return 0;
}atomic<int> acnt;
int cnt;-
acnt是一個原子整數,用于線程安全的計數。 -
cnt是一個普通整數,用于非線程安全的計數。
void Add1(atomic<int>& cnt)
{int old = cnt.load();while (!cnt.compare_exchange_weak(old, old + 1));
}cnt.load() 獲取當前原子變量的值。
compare_exchange_weak 是一個弱比較交換操作,它會將 cnt 的值與 old 比較:
-
如果相等,則將
cnt的值更新為old + 1,并返回true。 -
如果不相等,則將
old更新為當前的cnt值,并返回false。因為這個cnt在這個時刻已經被別的線程操作了 -
使用
while循環確保操作最終成功。
void f()
{for (int n = 0; n < 100000; ++n){Add1(acnt); // 原子操作++cnt; // 非原子操作}
}每個線程執行 100,000 次計數操作:
-
原子計數器
acnt使用Add1函數進行線程安全的遞增。 -
非原子計數器
cnt使用普通遞增操作。
int main()
{vector<thread> pool;for (int n = 0; n < 4; ++n)pool.emplace_back(f);for (auto& e : pool)e.join();cout << "原子計數器為 " << acnt << '\n'<< "非原子計數器為 " << cnt << '\n';return 0;
}-
創建 4 個線程,每個線程執行
f函數。 -
等待所有線程完成。
-
輸出原子計數器和非原子計數器的值。
運行結果:
-
原子計數器 (
acnt):由于使用了原子操作,最終值應為400,000(4 個線程,每個線程遞增 100,000 次)。 -
非原子計數器 (
cnt):由于沒有線程同步,多個線程同時遞增cnt,可能會導致數據競爭,最終值通常小于400,000。
CAS 操作的特性 --- 讀取-比較-寫入
操作邏輯:atomic 對象跟 expected 按位比較相等,則用 val 更新 atomic 對象并返回值 true;若 atomic 對象跟 expected 按位比較不相等,則更新 expected 為當前的 atomic 對象并返回值 false。
compare_exchange_weak 和 compare_exchange_strong 的區別:
-
compare_exchange_weak在某些平臺上,即使原子變量的值等于 expected,也可能“虛假地”失敗(即返回 false)。這種失敗是由于底層硬件或編譯器優化導致的,但不會改變原子變量的值。 -
compare_exchange_strong保證在原子變量的值等于 expected 時不會虛假地失敗。只要原子變量的值等于 expected,操作就會成功。 -
compare_exchange_weak在某些平臺上可能比compare_exchange_strong更快,但可能會因為硬件層間的緩存一致性或編譯器優化等問題而虛假失敗。compare_exchange_strong要避免這些原因,需要付出一定的代價,比如使用硬件的緩存一致性協議(如 MESI 協議)。
在多核處理器系統中,CPU核心通過緩存快速訪問數據,而寄存器用于存儲當前處理的數據。緩存一致性問題是指當一個核心修改了緩存中的數據時,其他核心緩存中的相同數據副本需要及時更新或標記為無效,否則會導致數據不一致。硬件通過緩存一致性協議(如MESI協議)解決這一問題,確保所有核心的緩存和寄存器中的數據始終保持同步,從而維持系統的正確性和性能。
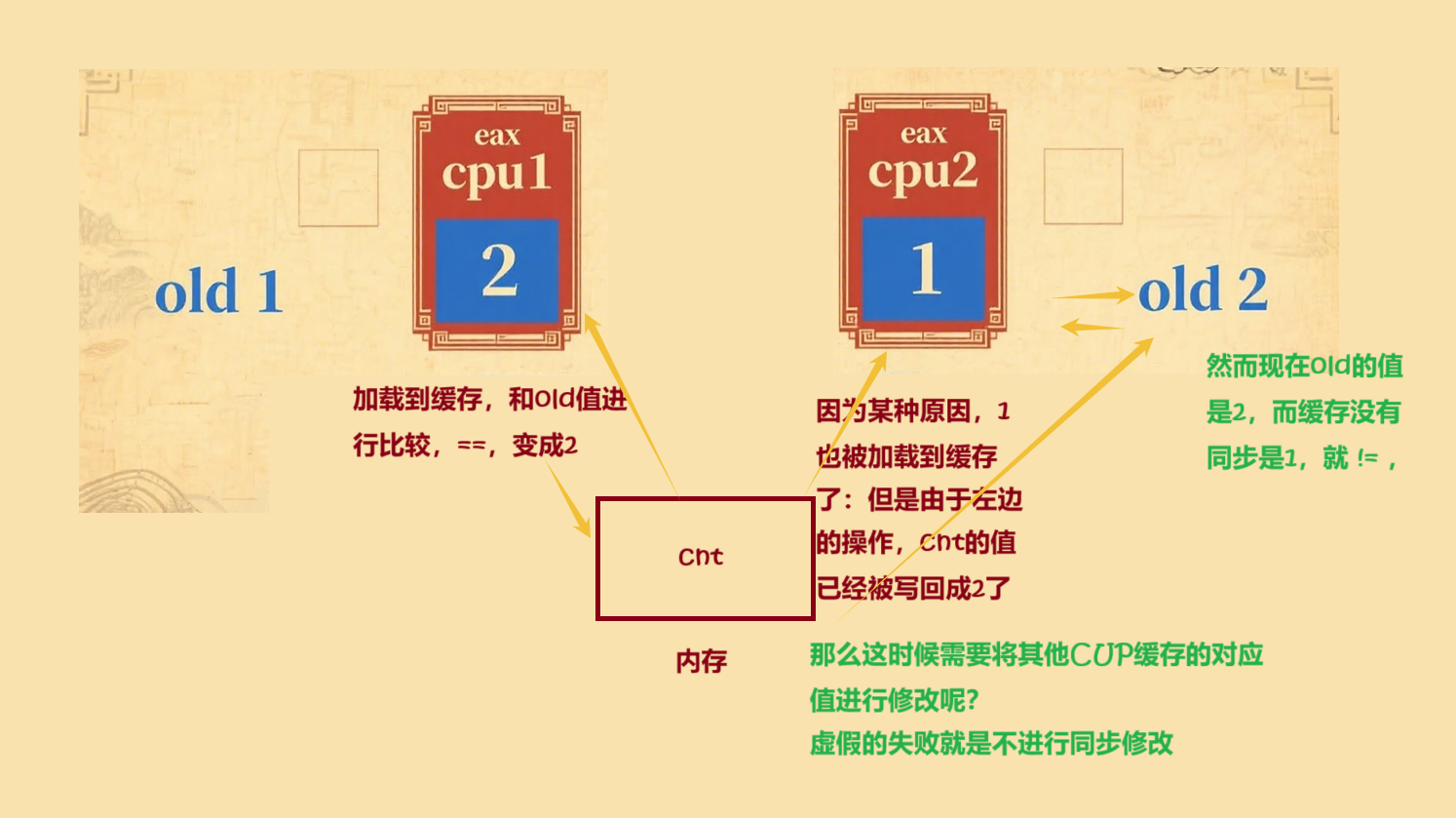
在這個過程中,CPU1和CPU2都試圖修改共享內存中的變量Cnt。CPU1首先加載Cnt的值到其緩存,與預期值old(1)比較,相等后將其改為2。幾乎同時,CPU2也加載了Cnt的值到其緩存,此時Cnt已被CPU1修改為2,但CPU2緩存未同步,仍為old(1)。當CPU2執行比較時,發現其緩存值(1)與預期值old(1)相等,也將其改為2,但這個操作是基于舊數據的,因此是無效的。這就是所謂的“虛假失敗”,需要通過緩存一致性協議來解決,以確保所有CPU核心的緩存和寄存器中的數據保持同步。
我們看一個示例:原子的去對一個鏈表添加節點:
#include <atomic> // 包含 std::atomic 的頭文件
#include <thread> // 包含 std::thread 的頭文件
#include <vector> // 包含 std::vector 的頭文件
#include <iostream> // 包含 std::cout 的頭文件
#include <chrono> // 包含 std::this_thread::sleep_for 的頭文件// 定義一個簡單的全局鏈表結構
struct Node { int value; // 節點的值Node* next; // 指向下一個節點的指針
};
std::atomic<Node*> list_head(nullptr); // 使用原子操作的鏈表頭指針,初始值為 nullptr// 向鏈表中追加一個元素的函數
void append(int val) { std::this_thread::sleep_for(std::chrono::seconds(1)); // 模擬耗時操作,讓線程暫停 1 秒Node* oldHead = list_head.load(); // 加載當前鏈表頭指針的值Node* newNode = new Node{ val, oldHead }; // 創建一個新節點,其值為 val,指向當前的鏈表頭// 使用原子操作安全地更新鏈表頭指針// 相當于:list_head = newNode,但以線程安全的方式實現while (!list_head.compare_exchange_weak(oldHead, newNode)) {newNode->next = oldHead; // 如果更新失敗,重新設置新節點的 next 指針oldHead = list_head.load(); // 重新加載當前鏈表頭指針的值}
}int main()
{// 創建 10 個線程來填充鏈表std::vector<std::thread> threads;for (int i = 0; i < 10; ++i) threads.push_back(std::thread(append, i)); // 啟動線程,每個線程調用 append 函數,傳入不同的值// 等待所有線程完成for (auto& th : threads)th.join();// 打印鏈表的內容for (Node* it = list_head; it != nullptr; it = it->next)std::cout << ' ' << it->value;std::cout << '\n';// 清理鏈表,釋放內存Node* it; while (it = list_head) { list_head = it->next; // 將鏈表頭指針移動到下一個節點delete it; // 刪除當前節點}return 0;
}兩個線程同時進行尾插一個節點,同時將next指向,就有可能一個將另一個覆蓋了,導致節點丟失!
weak和weak的區別:
- 是否要控制內存序列 --- 要控制就自己傳入,不需要就使用缺省值!
- 還有有無 volatile 修飾:
volatile是一個C++關鍵字,用于防止編譯器對變量的訪問進行優化,常用于硬件寄存器訪問或中斷處理,但它不保證線程安全,也不提供原子操作。而std::atomic是C++11引入的類模板,專門用于實現線程安全的原子操作,能夠防止數據競爭,并且可以通過內存順序參數控制操作的同步行為。簡而言之,volatile主要用于防止編譯器優化,而std::atomic用于多線程編程中的線程安全和原子操作。
CPU 緩存與無鎖編程
-
CPU 緩存相關知識:可以參考陳皓的博客 與程序員相關的 CPU 緩存知識 | 酷殼 - CoolShell
-
無鎖編程知識:可以參考陳皓的博客 無鎖隊列的實現 | 酷殼 - CoolShell
-
如果相關鏈接失效(文章因為平臺等等原因),可以去 我的gitee 中查找!
std::atomic 的內存順序選項
-
memory_order_relaxed:最寬松的內存順序,僅保證原子操作的原子性,不提供任何同步或順序約束。適用于不需要同步的場景,例如計數器或統計信息。
std::atomic<int> x(0); x.store(42, std::memory_order_relaxed); // 僅保證原子性 -
memory_order_consume:限制較弱的內存順序,僅保證依賴于當前加載操作的數據的可見性。通常用于數據依賴的場景,實際使用較少。
std::atomic<int*> ptr(nullptr); int* p = ptr.load(std::memory_order_consume); if (p) {int value = *p; // 保證 p 指向的數據是可見的 } -
memory_order_acquire:保證當前操作之前的所有讀寫操作(在當前線程中)不會被重排序到當前操作之后。通常用于加載操作,適用于實現鎖或同步機制中的“獲取”操作。
std::atomic<bool> flag(false); int data = 0; // 線程 1 data = 42; flag.store(true, std::memory_order_release); // 線程 2 while (!flag.load(std::memory_order_acquire)) {} std::cout << data; // 保證看到 data = 42 -
memory_order_release:保證當前操作之后的所有讀寫操作(在當前線程中)不會被重排序到當前操作之前。通常用于存儲操作,適用于實現鎖或同步機制中的“釋放”操作。
std::atomic<bool> flag(false); int data = 0; // 線程 1 data = 42; flag.store(true, std::memory_order_release); // 保證 data = 42 在 flag = true 之前可見 // 線程 2 while (!flag.load(std::memory_order_acquire)) {} std::cout << data; // 保證看到 data = 42 -
memory_order_acq_rel:結合了 memory_order_acquire 和 memory_order_release 的語義,適用于讀 - 修改 - 寫操作(如 fetch_add 或 compare_exchange_strong),用于需要同時實現“獲取”和“釋放”語義的操作。
std::atomic<int> x(0); x.fetch_add(1, std::memory_order_acq_rel); // 保證前后的操作不會被重排序 -
memory_order_seq_cst:最嚴格的內存順序,保證所有線程看到的操作順序是一致的(全局順序一致性)。默認的內存順序,適用于需要強一致性的場景,但性能開銷較大。
std::atomic<int> x(0); x.store(42, std::memory_order_seq_cst); // 全局順序一致性 int value = x.load(std::memory_order_seq_cst);
內存順序的關系:
-
寬松到嚴格:
memory_order_relaxed < memory_order_consume < memory_order_acquire < memory_order_release < memory_order_acq_rel < memory_order_seq_cst。 -
寬松的內存順序(如
memory_order_relaxed)性能最好,但同步語義最弱;嚴格的內存順序(如memory_order_seq_cst)性能最差,但同步語義最強。
| 內存順序 | 適用操作 | 語義描述 |
|---|---|---|
| memory_order_relaxed | 任意操作 | 僅保證原子性,無同步或順序約束。 |
| memory_order_consume | 加載操作 | 保證依賴鏈的可見性,實際使用較少。 |
| memory_order_acquire | 加載操作 | 保證當前操作之前的讀寫不會被重排序到之后。 |
| memory_order_release | 存儲操作 | 保證當前操作之后的讀寫不會被重排序到之前。 |
| memory_order_acq_rel | 讀-修改-寫操作 | 同時具有 acquire 和 release 語義。 |
| memory_order_seq_cst | 任意操作 | 全局順序一致性,保證所有線程看到的操作順序一致。 |
atomic_flag
對于線程安全,我們可以通過互斥鎖或者原子操作/無鎖來解決,還有一種方式就是自旋鎖,當然還有其他的鎖,讀寫鎖等等。
自旋鎖主要對比互斥鎖,都可以保證線程安全,都是加鎖解鎖,但是和互斥鎖的區別就是:
互斥鎖會在已經有線程獲取到鎖了,其他想要獲取鎖的線程進入阻塞狀態,對于很小的臨界區,就會有消耗,有代價!
自旋鎖就是第一個線程來了往下走,第二個線程來了不進入到阻塞狀態,而是在自旋,就是不斷的去檢查一個值,進行空轉行為,不斷訪問鎖本身的標志,不切換上下文!
但是如果臨界區比較到的話,自旋鎖就比較不適合了!因為會過分占用?CPU !
-
特性:
atomic_flag是一種原子布爾類型,與所有 atomic 的特化不同,它保證是免鎖的。與atomic<bool>不同,atomic_flag不提供加載或存儲操作,主要提供test_and_set操作將 flag 原子地設置為 true 并返回之前的值,clear原子地將 flag 設置為 false。 -
示例:使用
atomic_flag實現自旋鎖。#include <atomic> #include <iostream> #include <thread> #include <vector> using namespace std; atomic<int> acnt; int cnt; void Add1(atomic<int>& cnt) {int old = cnt.load();while (!atomic_compare_exchange_weak(&cnt, &old, old + 1)); } void f() {for (int n = 0; n < 100000; ++n) {++acnt;++cnt;} } int main() {vector<thread> pool;for (int n = 0; n < 4; ++n)pool.emplace_back(f);for (auto& e : pool)e.join();cout << "原子計數器為 " << acnt << '\n'<< "非原子計數器為 " << cnt << '\n';return 0; }
檢查類型特性
-
代碼示例:
template<class T> void check() {cout << typeid(T).name() << endl;cout << std::is_trivially_copyable<T>::value << endl;cout << std::is_copy_constructible<T>::value << endl;cout << std::is_move_constructible<T>::value << endl;cout << std::is_copy_assignable<T>::value << endl;cout << std::is_move_assignable<T>::value << endl;cout << std::is_same<T, typename std::remove_cv<T>::type>::value << endl << endl; }
atomic::compare_exchange_weak 示例
-
代碼示例:
#include <iostream> // std::cout #include <atomic> // std::atomic #include <thread> // std::thread #include <vector> // std::vector struct Node { int value; Node* next; }; std::atomic<Node*> list_head(nullptr); void append(int val, int n) { for (int i = 0; i < n; i++) {Node* oldHead = list_head;Node* newNode = new Node{ val+i,oldHead };while (!list_head.compare_exchange_weak(oldHead, newNode))newNode->next = oldHead;} } int main() {vector<thread> threads;threads.emplace_back(append, 0, 10);threads.emplace_back(append, 20, 10);threads.emplace_back(append, 30, 10);threads.emplace_back(append, 40, 10);for (auto& th : threads)th.join();for (Node* it = list_head; it != nullptr; it = it->next)cout << ' ' << it->value;cout << '\n';Node* it; while (it = list_head) { list_head = it->next;delete it;}return 0; }
鎖與無鎖棧的性能對比
-
代碼示例:
#include <iostream> // 包含 std::cout #include <atomic> // 包含 std::atomic #include <thread> // 包含 std::thread #include <mutex> // 包含 std::mutex #include <vector> // 包含 std::vector #include <ctime> // 包含 clock 函數// 定義一個通用的鏈表節點模板 template<typename T> struct node {T data; // 節點存儲的數據node* next; // 指向下一個節點的指針node(const T& data) : data(data), next(nullptr) {} // 構造函數 };// 無鎖棧的命名空間 namespace lock_free {// 無鎖棧模板類template<typename T>class stack{public:std::atomic<node<T>*> head = nullptr; // 使用原子操作的頭指針public:// 向棧中壓入數據void push(const T& data){node<T>* new_node = new node<T>(data); // 創建一個新節點// 將 head 的當前值放到 new_node->next 中new_node->next = head.load(std::memory_order_relaxed);// 現在令 new_node 為新的 head ,但如果 head 不再是// 存儲于 new_node->next 的值(某些其他線程必須在剛才插入結點)// 那么將新的 head 放到 new_node->next 中并再嘗試while (!head.compare_exchange_weak(new_node->next, new_node,std::memory_order_release, // 成功時的內存順序std::memory_order_relaxed)) // 失敗時的內存順序; // 循環體為空// 成功失敗使用的模型相對應是有要求的: failure 強于 success 是未定義的!}}; }// 有鎖棧的命名空間 namespace lock {// 有鎖棧模板類template<typename T>class stack{public:node<T>* head = nullptr; // 普通的頭指針// 向棧中壓入數據void push(const T& data){node<T>* new_node = new node<T>(data); // 創建一個新節點new_node->next = head; // 新節點指向當前的頭節點head = new_node; // 更新頭節點為新節點}}; }int main() {// 創建無鎖棧和有鎖棧實例lock_free::stack<int> st1;lock::stack<int> st2;std::mutex mtx; // 用于有鎖棧的互斥鎖int n = 1000000; // 每個線程要插入的數據量// 無鎖棧的線程任務auto lock_free_stack = [&st1, n] {for (size_t i = 0; i < n; i++) // 插入 n 個數據{st1.push(i); // 使用無鎖方式壓入數據}};// 有鎖棧的線程任務auto lock_stack = [&st2, &mtx, n] {for (size_t i = 0; i < n; i++) // 插入 n 個數據{std::lock_guard<std::mutex> lock(mtx); // 加鎖st2.push(i); // 使用有鎖方式壓入數據}};// 4個線程分別使用無鎖方式和有鎖方式插入n個數據到棧中對比性能size_t begin1 = clock(); // 記錄無鎖棧操作的開始時間std::vector<std::thread> threads1;for (size_t i = 0; i < 4; i++) // 創建 4 個線程{threads1.emplace_back(lock_free_stack); // 啟動線程,使用無鎖棧}for (auto& th : threads1)th.join(); // 等待所有線程完成size_t end1 = clock(); // 記錄無鎖棧操作的結束時間std::cout << end1 - begin1 << std::endl; // 輸出無鎖棧操作的耗時size_t begin2 = clock(); // 記錄有鎖棧操作的開始時間std::vector<std::thread> threads2;for (size_t i = 0; i < 4; i++) // 創建 4 個線程{threads2.emplace_back(lock_stack); // 啟動線程,使用有鎖棧}for (auto& th : threads2)th.join(); // 等待所有線程完成size_t end2 = clock(); // 記錄有鎖棧操作的結束時間std::cout << end2 - begin2 << std::endl; // 輸出有鎖棧操作的耗時return 0; }
自旋鎖示例
-
代碼示例:
#include <atomic> // 包含 std::atomic 和 std::atomic_flag #include <thread> // 包含 std::thread #include <iostream> // 包含 std::cout #include <vector> // 包含 std::vector// 自旋鎖(SpinLock)是一種忙等待的鎖機制,適用于鎖持有時間非常短的場景。 // 在多線程編程中,當一個線程嘗試獲取已被其他線程持有的鎖時,自旋鎖會讓該 // 線程在循環中不斷檢查鎖是否可用,而不是進入睡眠狀態。這種方式可以減少上 // 下文切換的開銷,但在鎖競爭激烈或鎖持有時間較長的情況下,會導致CPU資源的浪費。 // 以下是使用C++11實現的一個簡單自旋鎖示例: class SpinLock { private:// ATOMIC_FLAG_INIT默認初始化為falsestd::atomic_flag flag = ATOMIC_FLAG_INIT; // 原子標志,用于表示鎖的狀態 public:// 嘗試獲取鎖void lock(){// test_and_set將內部值設置為true,并且返回之前的值// 第一個進來的線程將值原子地設置為true,返回false// 后面進來的線程將原子的值設置為true,返回true,所以卡在這里空轉,// 直到第一個進去的線程unlock,clear,將值設置為falsewhile (flag.test_and_set(std::memory_order_acquire)); // 使用 acquire 順序保證獲取鎖時的內存可見性}// 釋放鎖void unlock(){// clear將值原子地設置為falseflag.clear(std::memory_order_release); // 使用 release 順序保證釋放鎖時的內存可見性} };// 測試自旋鎖的工作線程函數 void worker(SpinLock& lock, int& sharedValue) {lock.lock(); // 嘗試獲取鎖// 模擬一些工作for (int i = 0; i < 1000000; ++i) {++sharedValue; // 對共享變量進行操作}lock.unlock(); // 釋放鎖 }int main() {SpinLock lock; // 創建一個自旋鎖實例int sharedValue = 0; // 定義一個共享變量std::vector<std::thread> threads; // 用于存儲線程的容器// 創建多個線程for (int i = 0; i < 4; ++i) {threads.emplace_back(worker, std::ref(lock), std::ref(sharedValue)); // 啟動線程,傳入自旋鎖和共享變量}// 等待所有線程完成for (auto& thread : threads) {thread.join(); // 等待每個線程結束}std::cout << "Final shared value: " << sharedValue << std::endl; // 輸出最終的共享變量值return 0; }
測試的時候請在 realease 下進行測試!!!?

)






)




——Bash基礎)





