深度學習硬件:
CPU:
CPU有數個核心,每個核心可以獨立工作,同時進行多個線程,內存與系統共享
GPU:
GPU有上千個核心,但每個核心運行速度很慢,適合并行做類似的工作,不能獨立工作,自帶內存和緩存
TPU:
專門用于深度學習的硬件,運行速度非常快
GPU的優勢:
GPU在大矩陣的乘法運算中有很大的優勢,因為矩陣乘法結果中的每一個元素都是原始矩陣某一行與某一列的點積,因此并行進行所有元素的點積運算速度會很快。同樣的,卷積核與輸入進行卷積運算也可以是并行運算
CUDA:
使用NVIDIA自帶的CUDA,可以寫出類似于C的代碼,直接在GPU上運行。直接寫CUDA是一件困難的事,我們可以使用已經NVIDIA已經高度優化且開元的API
深度學習軟件:
常見的深度學習框架:
Caffe,PyTorch,TensorFlow
使用深度學習框架的原因:
可以很容易地構建大的計算圖,快速地開發及測試new idea
只需要寫出前向傳播代碼,框架可以自動計算梯度
框架的運算可以在GPU上高效地運行
例子:
比如下面的計算圖,我們只使用numpy自己編寫的正向以及反向傳播代碼如下:

使用深度學習框架:
TensorFlow版本:
我們只需要把x,y,z設置成3個占位符,并寫出它們的正向傳播公式,那么使用tf.gradients就可以自動計算出相關的梯度
import numpy as np
np.random.seed(0)
import tensorflow as tf
N, D = 3, 4
# 創建前向計算圖
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
z = tf.placeholder(tf.float32)
a = x * y
b = a + z
c = tf.reduce_sum(b)
# 計算梯度
grad_x, grad_y, grad_z = tf.gradients(c, [x, y, z])
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),z: np.random.randn(N, D),}out = sess.run([c, grad_x, grad_y, grad_z], feed_dict=values)c_val, grad_x_val, grad_y_val, grad_z_val = outprint(c_val)print(grad_x_val)PyTorch版本:
import torch
device = 'cuda:0' # 在GPU上運行,即構建GPU版本的矩陣
# 前向傳播與Numpy類似
N, D = 3, 4
x = torch.randn(N, D, requires_grad=True, device=device)
# requires_grad要求自動計算梯度,默認為True
y = torch.randn(N, D, device=device)
z = torch.randn(N, D, device=device)
a = x * y
b = a + z
c = torch.sum(b)
c.backward() # 反向傳播可以自動計算梯度
print(x.grad)
print(y.grad)
print(z.grad)TensorFlow:
我們以搭建兩層神經網絡,隱藏層激活函數采用ReLU,采用L2距離作為loss,來介紹TensorFlow的大概框架
實現代碼如下:
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 創建前向計算圖
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
w1 = tf.placeholder(tf.float32, shape=(D, H))
w2 = tf.placeholder(tf.float32, shape=(H, D))
h = tf.maximum(tf.matmul(x, w1), 0) # 隱藏層使用折葉函數
y_pred = tf.matmul(h, w2)
diff = y_pred - y # 差值矩陣
loss = tf.reduce_mean(tf.reduce_sum(diff ** 2, axis=1)) # 損失函數使用L2范數
#另一種更好的計算方法
#loss = tf.losses.mean_squared_error(y_pred, y)
# 計算梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])
# 多次運行計算圖
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),w1: np.random.randn(D, H),w2: np.random.randn(H, D),}out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)loss_val, grad_w1_val, grad_w2_val = out整個過程分為兩個部分,with前面的部分定義計算圖,with部分多次運行計算圖
1.我們創建了x,y,w1,w2四個tf.placeholder對象,這四個變量作為輸入槽
2.之后我們使用這四個變量創建計算圖,tf.matmul是矩陣乘法,tf.maximum是取最大值函數,也就是ReLU,h與w2作矩陣乘法算出y_pred,最后計算L2的Loss
3.通過下列代碼指定出要求哪個變量關于哪幾個變量的梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])這里指定了求loss關于w1,w2的梯度
4.完成計算圖的構建后,我們創建一個會話Session來運行計算圖和輸入數據,在這里,我們需要創建一個字典映射,把上面定義為placeholder的變量名與輸入數據的numpy數組作字典,輸入進feed_dict參數
5.最后兩行代碼是運行代碼,執行sess.run,指定out接收[loss, grad_w1, grad_w2],進而解包獲得
上述的正向+反向傳播只進行了一次,需要迭代多次:
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),w1: np.random.randn(D, H),w2: np.random.randn(H, D),}learning_rate = 1e-5for t in range(50):out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)loss_val, grad_w1_val, grad_w2_val = outvalues[w1] -= learning_rate * grad_w1_valvalues[w2] -= learning_rate * grad_w2_val最后兩行即梯度下降
上述實現沒有語法問題,但有很大的效率問題,因為每次run的時候,都要把同樣的w1和w2傳入,而從CPU傳數據到GPU是非常慢的,導致計算速度局限于傳輸速度,因此我們希望w1和w2能一直保存在計算圖中,不需要我們每次run都傳進去
1.修改w1和w2的聲明方式
w1 = tf.Variable(tf.random_normal((D, H)))
w2 = tf.Variable(tf.random_normal((H, D)))由于不再從外部傳入初始化,因此我們需要在聲明時就初始化
2.將梯度下降步驟也添加到計算圖中
這里使用assign更新w1和w2,若后續步驟不需要用到new_w1和new_w2,=賦值可省略
learning_rate = 1e-5
new_w1 = w1.assign(w1 - learning_rate * grad_w1)
new_w2 = w2.assign(w2 - learning_rate * grad_w2)3.run之前,要先運行參數的初始化tf.global_variables_initializer()
with tf.Session() as sess:sess.run(tf.global_variables_initializer())values = {x: np.random.randn(N, D),y: np.random.randn(N, D),}for t in range(50):loss_val, = sess.run([loss], feed_dict=values)但是上述的代碼會有一個問題,實際上梯度不會進行更新。為什么呢?因為我們在run的時候,只要求接收loss,所以tensorflow會自己作優化,只計算loss相關的步驟,將w1,w2的更新步驟忽略不算
解決方法1:
在計算圖中加入兩個參數的依賴,在執行時需要計算這個依賴(使用tf.group),這樣就會讓參數更新,然后run時返回group的結果(為空)
具體修改如下:
#計算圖構建中加入
updates = tf.group(new_w1,new_w2)#run時改為
loss_val, _ = sess.run([loss, updates], feed_dict=values)解決方法2:
使用tensorflow自帶的優化器
#構建計算圖時
optimizer = tf.train.GradientDescentOptimizer(1e-5) #學習率
updates = optimizer.minimize(loss) #使loss下降#run時代碼
loss_val, _ = sess.run([loss, updates], feed_dict=values)進一步的優化:
上述的w1,w2所代表的神經元層我們可以使用tf自帶的api去定義
N, D , H = 64, 1000, 100
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
init = tf.variance_scaling_initializer(2.0) # 定義權重初始化方法,使用He初始化
#定義第一層的輸出h
#輸入是x,輸出列數為H,激活函數是relu,權重初始化器選擇剛剛定義的init
h = tf.layers.dense(inputs=x, units=H, activation=tf.nn.relu, kernel_initializer=init)
#定義第二層的輸出y_pre,輸入為h,輸出列數為D,初始化為init
y_pred = tf.layers.dense(inputs=h, units=D, kernel_initializer=init)
loss = tf.losses.mean_squared_error(y_pred, y) # 損失函數使用L2范數
optimizer = tf.train.GradientDescentOptimizer(1e-5)
updates = optimizer.minimize(loss)
with tf.Session() as sess:sess.run(tf.global_variables_initializer())values = {x: np.random.randn(N, D),y: np.random.randn(N, D),}for t in range(50):loss_val, _ = sess.run([loss, updates], feed_dict=values)更高級的封裝:tensorflow.keras
Keras是更高層次的封裝,使用方式如下:
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 創建模型,添加層
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(D))
# 配置模型:損失函數、參數更新方式
model.compile(optimizer=tf.keras.optimizers.SGD(lr=1e-5), loss=tf.keras.losses.mean_squared_error)
x = np.random.randn(N, D)
y = np.random.randn(N, D)
# 訓練
history = model.fit(x, y, epochs=50, batch_size=N)PyTorch:
PyTorch不再使用numpy的ndarray作為數據載體,而是使用tensor對象
自動計算梯度:
import torch
# 創建隨機tensors
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
learning_rate = 1e-6
for t in range(500):# 前向傳播y_pred = x.mm(w1).clamp(min=0).mm(w2)loss = (y_pred - y).pow(2).sum()# 反向傳播loss.backward()# 參數更新with torch.no_grad():w1 -= learning_rate * w1.gradw2 -= learning_rate * w2.gradw1.grad.zero_()w2.grad.zero_()x.mm即矩陣乘法,clamp將小于0的值設置為0,(使最小值為0)
backward()進行反向傳播,之后調用變量的grad屬性即可獲得梯度,最后調用grad.zero_()清空梯度,為下一次梯度傳播做準備
torch.no_grad()的意思是在這次計算中不需要計算梯度,因為pytorch是每次運算時才動態構建計算圖,為計算梯度做準備,no_grad()的意思就是讓它在這次計算中不需要構建計算圖。這是pytorch與tensorflow的區別,tf是靜態地構建好一個計算圖,然后重復運行這個計算圖即可
更高級的封裝:NN
可以使用nn還有自帶的optimizer進一步封裝代碼
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 定義模型
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),torch.nn.ReLu(),torch.nn.Linear(H, D_out))
# 定義優化器
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 迭代
for t in range(500):y_pred = model(x)loss = torch.nn.functional.mse_loss(y_pred, y)loss.backward()# 更新參數optimizer.step()optimizer.zero_grad()模塊定義:
PyTorch中一個模塊就是一個神經網絡層,輸入和輸出都是tensor,模塊中可以包含權重和其他模塊,比如把上面代碼中的兩層神經網絡改為一個模塊:
import torch
# 定義上文的整個模塊為單個模塊
class TwoLayerNet(torch.nn.Module):# 初始化兩個子模塊,都是線性層def __init__(self, D_in, H, D_out):super(TwoLayerNet, self).__init__()self.linear1 = torch.nn.Linear(D_in, H)self.linear2 = torch.nn.Linear(H, D_out)# 使用子模塊定義前向傳播,不需要定義反向傳播,autograd會自動處理def forward(self, x):h_relu = self.linear1(x).clamp(min=0)y_pred = self.linear2(h_relu)return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 構建模型與訓練和之前類似
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for t in range(500):y_pred = model(x)loss = torch.nn.functional.mse_loss(y_pred, y)loss.backward()optimizer.step()optimizer.zero_grad()又比如定義一個模塊作為模型的一部分:
class ParallelBlock(torch.nn.Module):def __init__(self, D_in, D_out):super(ParallelBlock, self).__init__()self.linear1 = torch.nn.Linear(D_in, D_out)self.linear2 = torch.nn.Linear(D_in, D_out)def forward(self, x):h1 = self.linear1(x)h2 = self.linear2(x)return (h1 * h2).clamp(min=0)model = torch.nn.Sequential(ParallelBlock(D_in, H),ParallelBlock(H, H),torch.nn.Linear(H, D_out))DataLoader:
DataLoader可以包裝數據集,并提供獲取小批量數據、重新排列、多線程讀取,當需要加載自定義數據集時,只需要編寫自己的數據集類
import torch
from torch.utils.data import TensorDataset, DataLoader
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
loader = DataLoader(TensorDataset(x, y), batch_size=8)
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
for epoch in range(20):for x_batch, y_batch in loader:y_pred = model(x_batch)loss = torch.nn.functional.mse_loss(y_pred, y_batch)loss.backward()optimizer.step()optimizer.zero_grad()靜態圖與動態圖:
tensorflow使用的是靜態圖,構建靜態圖來描述計算,包括找到反向傳播的路徑,然后每次迭代執行計算的時候,都使用同一張就按圖
pytorch使用的是動態圖,在每次計算過程中構建計算圖,尋找參數梯度路徑,每次迭代都拋出計算圖,然后再重建
靜態圖的優勢:
由于一張計算圖需要反復運行多次,這樣框架就會有機會再計算圖上進行優化,比如說把下圖左側的計算圖優化成右側
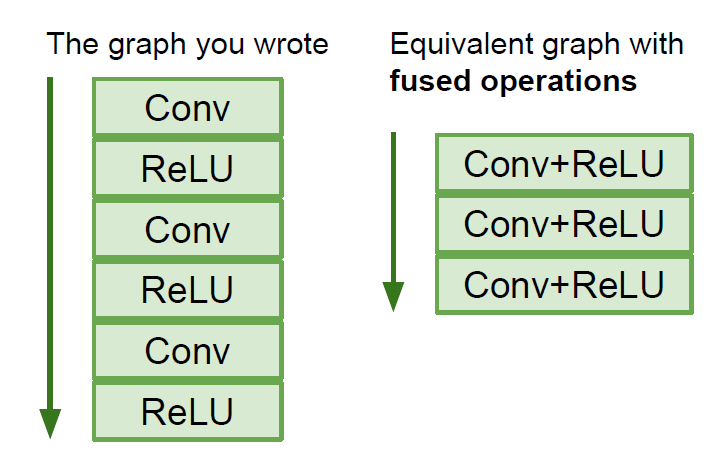
靜態圖只需要構建一次計算圖,所以只要構建好了,即使源碼是使用python寫的,也可以部署在C++環境,不需要依賴python,而動態圖每次迭代都要使用源碼
動態圖的優勢:
動態圖的代碼比較簡潔,很像python操作
比如說在條件判斷邏輯中,pytorch可以動態構建計算圖,因此可以直接使用python的條件判斷流語句,但tensorflow一次性構建靜態計算圖,因此需要考慮到所有情況,只能使用tensorflow流操作

循環結構也是如此,pytorch直接使用python循環即可,tensorflow需要使用自己的控制流(tf.fold1)


)









![[echarts]橫向柱狀圖](http://pic.xiahunao.cn/[echarts]橫向柱狀圖)







