貼心小梗概
本文將介紹使用LazyLLM搭建最基礎的RAG的流程。首先介紹使用LazyLLM搭建RAG系統的必要環境配置,然后簡單回顧RAG的基本流程,接下來分別介紹RAG中文檔加載、檢索組件、生成組件三個關鍵部分的參數和基本使用方法,最后利用LazyLLM實現最簡單的RAG,并展示相關效果。
環境準備
在使用LazyLLM搭建RAG系統之前,我們需要配置好相關的環境,包括“開發環境搭建”和“環境變量配置”兩個步驟。
1.開發環境搭建
您可以用以下任一方式搭建 LazyLLM 開發環境。
📌手動配置
LazyLLM 基于 Python 開發,我們需要保證系統中已經安裝好了 Python,?Pip?和 Git。在Macbook上安裝這些比較復雜,安裝方式見附錄。
首先準備一個名為 lazyllm-venv 的虛擬環境并激活:
python -m venv lazyllm-venv
source lazyllm-venv/bin/activate如果運行正常,你可以在命令行的開頭看到 (lazyllm-venv) 的提示。接下來我們的操作都在這個虛擬環境中進行。
從 GitHub 下載 LazyLLM 的代碼:
git clone https://github.com/LazyAGI/LazyLLM.git并切換到下載后的代碼目錄:
cd?LazyLLM安裝基礎依賴:
pip3?install -r requirements.txt把 LazyLLM 加入到模塊搜索路徑中:
export?PYTHONPATH=$PWD:$PYTHONPATH這樣我們在任意目錄下都可以找到它。
📌拉取鏡像
我們提供了包含最新版本的 LazyLLM 的 docker 鏡像,開箱即用:
docker pull lazyllm/lazyllm也可以從?https://hub.docker.com/r/lazyllm/lazyllm/tags?查看并拉取需要的版本。
📌從Pip安裝
LazyLLM 支持用 pip 直接安裝,下面三種安裝方式分別對應不同功能的使用。
安裝 LazyLLM 基礎功能的最小依賴包。可以支持線上各類模型的微調和推理。
pip3?install lazyllm安裝 LazyLLM 的所有功能最小依賴包。不僅支持線上模型的微調和推理,而且支持離線模型的微調(主要依賴 LLaMA-Factory)和推理(大模型主要依賴 vLLM,多模態模型依賴LMDeploy,Embedding模型依賴Infinity)。
pip3 install lazyllm
lazyllm install standard安裝 LazyLLM 的所有依賴包,所有功能以及高級功能都支持,比如自動框架選擇(AutoFinetune、AutoDeploy 等)、更多的離線推理工具(如增加?LightLLM?等工具)、更多的離線訓練工具(如增加 AlpacaloraFinetune、CollieFinetune 等工具)。
pip3 install lazyllm
lazyllm install full2.API Key配置
調用大模型主要分為線上調用和本地調用兩種方式。對于線上調用,您需要提供相應平臺的API Key。如果您還沒有對應平臺的賬號,首先需要在平臺上注冊一個賬號。LazyLLM框架提供了自動調用平臺API Key的功能,只需將您的API Key設置為環境變量,并在調用時指定平臺和模型名稱,即可實現線上模型的調用。
LazyLLM目前支持以下平臺(api key鏈接見附件):
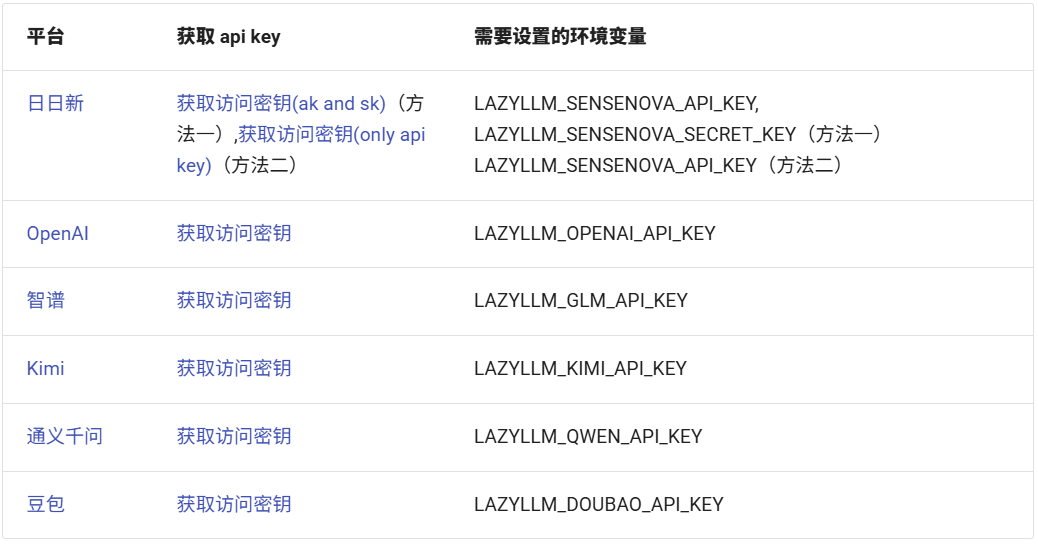
要配置平臺的API Key為環境變量,請按照以下步驟操作:
1??根據您使用的平臺,獲取相應的API Key(注意:SenseNova平臺需要獲取兩個Key)。
2??使用以下命令設置對應的環境變量:
export?LAZYLLM_<使用的平臺環境變量名稱,大寫>_API_KEY=<申請到的api key>例如,如果您需要訪問SenseNova平臺,如果您通過方法一獲得密鑰,您需要設置以下環境變量:
export LAZYLLM_SENSENOVA_API_KEY="您的Access Key ID"
export LAZYLLM_SENSENOVA_SECRET_KEY="您的Access Key Secret"如果您通過方法二獲得密鑰,您需要設置以下環境變量:
export?LAZYLLM_SENSENOVA_API_KEY="您的API-Key"在配置好環境變量后,當您實例化OnelineChatModule并指定模型來源時,LazyLLM會自動根據配置的環境變量調用相應的API Key。
通過這種方式,您可以輕松管理和調用不同平臺的API Key,簡化了模型調用的流程。
RAG 實踐剖析
1.原理回顧
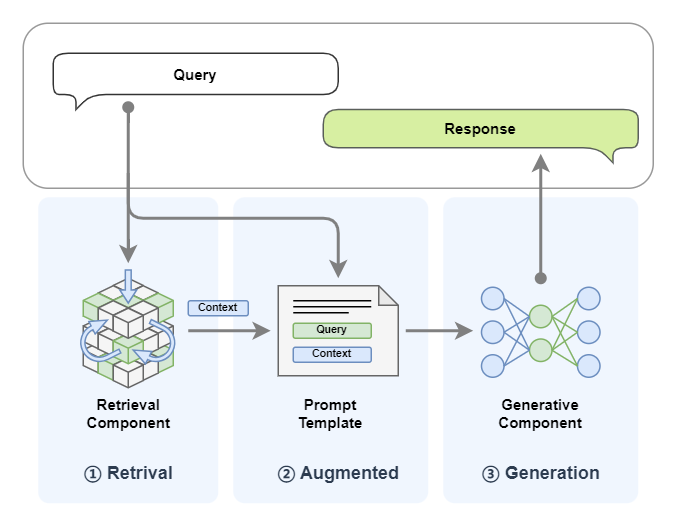
在準備好LazyLLM的環境和配置后,讓我們快速回顧一下RAG(Retrieval-augmented Generation,RAG,檢索增強生成)的基本原理。RAG的工作原理是當模型需要生成文本或回答問題時,首先會從一個龐大的文檔集合中檢索出相關的信息,這些檢索到的信息隨后會被用于指導生成過程,從而顯著提高生成文本的質量和準確性。RAG 的整體結構可以用下圖標識,系統接收一個用戶 Query, 首先通過檢索器(Retriever)從外部文檔中檢索出與給定 Query 相似的內容,然后將其與 Query 一同輸入到 LLM ,LLM 給出最終答案:
RAG的離線工作流程可以歸納成以下三步:
1??文檔讀取和解析(Reader)
把各種格式的文檔加載到系統中,可以借助開源工具(如MinerU)來提高解析的準確率。
2??分塊和向量化(Transform and Vectorize)
對收集到的原始數據進行清洗、去重、分塊等預處理工作,然后進行向量化。
3??索引和存儲(Indexing and Store)
利用向量數據庫或其他高效的向量檢索工具,將處理后的文本數據進行高效的存儲和索引。
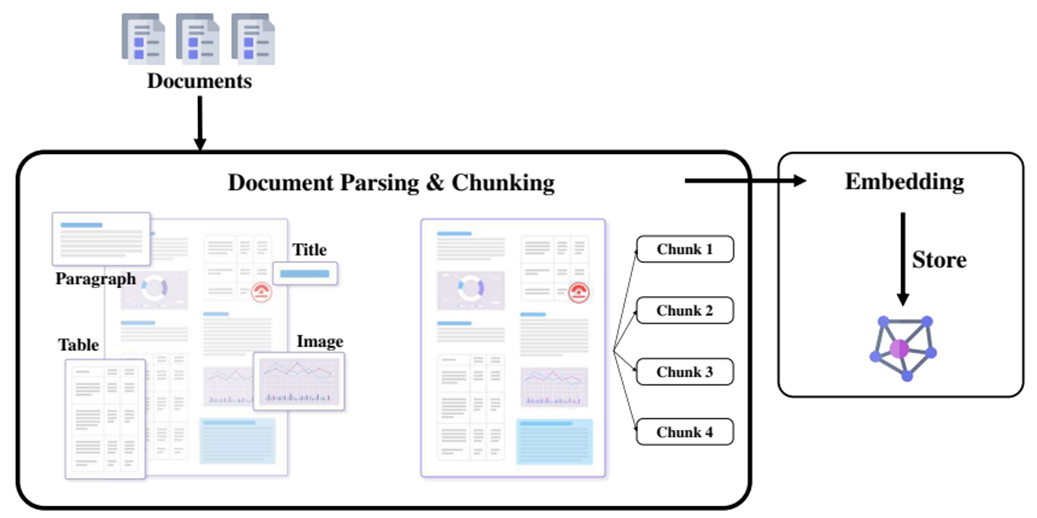
小結
RAG的工作流程可以歸納成以下三步:
1??檢索(Retrieval)
用戶輸入問題后,系統會基于該輸入在知識庫中檢索相關內容。
2??增強(Augmented)
檢索到的文本內容會作為額外的上下文,與用戶輸入一起提供給大模型。
3??生成(Generatation)
大模型結合檢索到的信息和自身的預訓練知識,生成最終的回答。
接下來我們將按照順序,依次介紹LazyLLM中的文檔管理、檢索組件和生成組件。
2.文檔管理
RAG的核心是從文檔集合進行文檔檢索,文檔集合中可以有各種各樣的文檔格式:可以是?DOCX,PDF,PPT 等富文本或者 Markdown 這樣的純文本,也可能是從某個 API 獲取的內容(如通過搜索引擎檢索得到的相關信息)等等。
由于集合內的文檔格式各異,針對這些不同格式的文檔,我們需要特定的解析器來提取其中有用的文本、圖片、表格、音頻和視頻等內容。在 LazyLLM 中,這些用于提取特定內容的解析器被抽象為Document類,目前 LazyLLM 內置的 Document可以支持 DOCX,PDF,PPT,EXCEL 等常見的富文本內容提取,您也可以自定義 Reader 讀取特定格式的文檔(在后續的教程中我們會進行詳細介紹)。Document的主要參數如下:
Parameters:
dataset_path (str) – 數據集目錄的路徑。此目錄應包含要由文檔模塊管理的文檔(注意:暫不支持指定單個文件)。
embed (Optional[Union[Callable, Dict[str, Callable]]], default: None ) – 用于生成文檔 embedding 的對象。如果需要對文本生成多個 embedding,此處需要通過字典的方式指定多個 embedding 模型,key 標識 embedding 對應的名字, value 為對應的 embedding 模型。
manager (bool, default: False ) – 指示是否為文檔模塊創建用戶界面的標志。默認為 False。
launcher (optional, default: None ) – 負責啟動服務器模塊的對象或函數。如果未提供,則使用 lazyllm.launchers 中的默認異步啟動器 (sync=False)。
store_conf (optional, default: None ) – 配置使用哪種存儲后端和索引后端。
doc_fields (optional, default: None ) – 配置需要存儲和檢索的字段繼對應的類型(目前只有 Milvus 后端會用到)。
在此處我們僅介紹Document最基礎的使用方法,embed、manager等參數的使用,我們將在后續章節進行介紹。對于最基礎的使用,我們只需要傳入數據集目錄的路徑即可:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L19)
# RAG 文檔讀取from?lazyllm?import?Document# 傳入絕對路徑doc = Document("path/to/content/docs/")print(f"實際傳入路徑為:{}")# 傳入相對路徑doc = Document("/content/docs/")
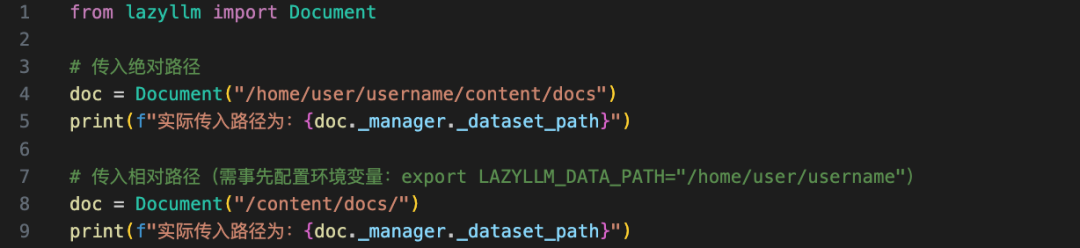
注意,您需要在此處傳入絕對路徑,或者是以當前目錄為基礎的相對路徑,其他情況下需要您通過環境變量 LAZYLLM_DATA_PATH 指定您的文檔所在目錄再傳入相對路徑,效果如下圖所示:
![]()
上述代碼中我們通過doc._manager._dataset_path來訪問最終傳給doc的路徑,可以看到上述兩種方式的輸出完全相同。
3.檢索組件
文檔集合中的文檔不一定都和用戶要查詢的內容相關,因此需要通過檢索組件從文檔中篩選出和用戶查詢相關的文檔。LazyLLM 中執行檢索功能的是 Retriever 組件, Retriever 組件可以創建一個用于文檔查詢和檢索的檢索模塊。此構造函數初始化一個檢索模塊,該模塊根據指定的相似度度量配置文檔檢索過程。主要參數如下:
Parameters:
doc (object) – 文檔模塊實例。該文檔模塊可以是單個實例,也可以是一個實例的列表。如果是單個實例,表示對單個Document進行檢索,如果是實例的列表,則表示對多個Document進行檢索。
group_name (str) – 在哪個 node group 上進行檢索。
group_name 有三種內置切分策略,都是用 SentenceSplitter 切分,區別在于塊大小不同:
? CoarseChunk: 塊大小為 1024,重合長度為 100
? MediumChunk: 塊大小為 256,重合長度為 25
? FineChunk: 塊大小為 128,重合長度為 12
similarity (Optional[str], default: None ) – 用于設置文檔檢索的相似度函數。默認為 'dummy'。候選集包括 ["bm25", "bm25_chinese", "cosine"]。
similarity_cut_off (Union[float, Dict[str, float]], default: float('-inf') ) – 當相似度低于指定值時丟棄該文檔。在多 embedding 場景下,如果需要對不同的 embedding 指定不同的值,則需要使用字典的方式指定,key 表示指定的是哪個 embedding,value 表示相應的閾值。如果所有的 embedding 使用同一個閾值,則只指定一個數值即可。
index (str, default: 'default' ) – 用于文檔檢索的索引類型。目前僅支持 'default'。
topk (int, default: 6 ) – 表示取相似度最高的多少篇文檔。
embed_keys (Optional[List[str]], default: None ) – 表示通過哪些 embedding 做檢索,不指定表示用全部 embedding 進行檢索。
target:目標組名,將結果轉換到目標組。
output_format: 代表輸出格式,默認為None,可選值有 'content' 和 'dict',其中 content 對應輸出格式為字符串,dict 對應字典。
join: 是否聯合輸出的 k 個節點,當輸出格式為 content 時,如果設置該值為 True,則輸出一個長字符串,如果設置為 False 則輸出一個字符串列表,其中每個字符串對應每個節點的文本內容。當輸出格式是 dict 時,不能聯合輸出,此時join默認為False, 將輸出一個字典,包括'content、'embedding'、'metadata'三個key。
kwargs: 其他關鍵字參數。
下面這行代碼聲明檢索組件需要在 doc 這個文檔中的 Coarse chunk 節點組利用 bm25_chinese 相似度進行檢索,最終返回相似度最高的 3 個節點。此處只簡單介紹如何使用 Retriever 組件,相關算法原理及更多檢索組件相關細節我們將在后續章節介紹。
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L28)
from lazyllm import Retriever
# 傳入絕對路徑
doc = Document("/path/to/content/docs/")
# 使用Retriever組件,傳入文檔doc,節點組名稱這里采用內置切分策略"CoarseChunk",相似度計算函數bm25_Chinese
retriever = Retriever(doc, group_name=Document.CoarseChunk, similarity="bm25_chinese", topk=3)
# 調用retriever組件,傳入query
retriever_result = retriever("your query")
# 打印結果,用get_content()方法打印具體的內容
print(retriever_result[0].get_content())4.生成組件
有了檢索到的內容,結合我們提問的問題,將二者共同輸入給生成組件,即可得我們想要的答案。這里的生成組件就是大模型,接下來我們將以線上大模型為例說明lazyllm是如何調用大模型的。
LazyLLM 通過 OnlineChatModule 統一調用線上大模型接口,不管您使用的OpenAPI接口還是SenseNova接口,或者是其他平臺提供的接口,LazyLLM均為您進行了規范的參數封裝,您只需要根據自己的需求將平臺和模型名稱等參數傳給對應的模塊即可:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L42)
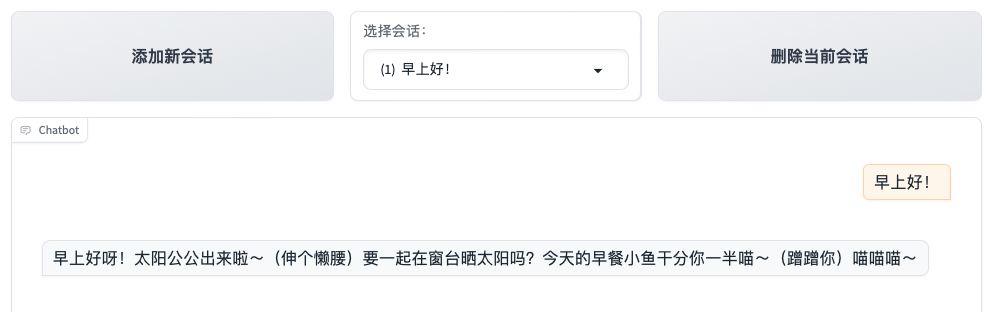
llm_prompt = "你是一只小貓,每次回答完問題都要加上喵喵喵"
llm = lazyllm.OnlineChatModule(source="sensenova", model="SenseChat-5-1202").prompt(llm_prompt)
print(llm("早上好!"))
# >>> 早上好呀!太陽公公出來啦~(伸個懶腰)要一起在窗臺曬太陽嗎?今天的早餐小魚干分你一半喵~(蹭蹭你) 喵喵喵~僅用上述三行代碼,就可以調用大模型。首先我們定義了一個prompt,作為大模型的提示詞,后續大模型的輸出都會遵循這里給出的提示。
然后我們定義了要調用的大模型,通過OnlineChatModule傳入平臺source以及模型名稱model,通過.prompt傳入定義好的prompt。
最后,調用定義好的大模型llm,輸入我們的問題就可以和大模型實現對話啦!
當然,您還可以將上述第4行代碼替換成以下代碼來實現一個對話窗口:
lazyllm.WebModule(llm, port=23466,?history=[llm]).start().wait()這里我們通過lazyllm.WebModule啟動了一個網頁端,將地址和端口輸入到瀏覽器就可以得到一個簡單的對話系統啦~
RAG 知識庫構建?
RAG在LazyLLM中的基本組件我們已經介紹完成了,下面我就可以用這幾部分關鍵組件搭建完整的RAG工作流了。但是在此之前,我們首先需要選擇一些文檔作為RAG的語料庫,下面我們將從cmrc2018(https://huggingface.co/datasets/hfl/cmrc2018)原始數據集開始,為大家講解如何基于此數據集構建我們的RAG知識庫。在接下來的教程中,我們將介紹RAG改進和優化的各種方法,若無特殊說明,將始終使用此知識庫。
1.數據集簡介
CMRC 2018(Chinese Machine Reading Comprehension 2018)[1] 數據集是一個中文閱讀理解數據集,用于中文機器閱讀理解的跨度提取數據集,以增加該領域的語言多樣性。數據集由人類專家在維基百科段落上注釋的近20,000個真實問題組成。
旨在推動中文機器閱讀理解(MRC)任務的發展。其數據集的基本格式如下圖所示:
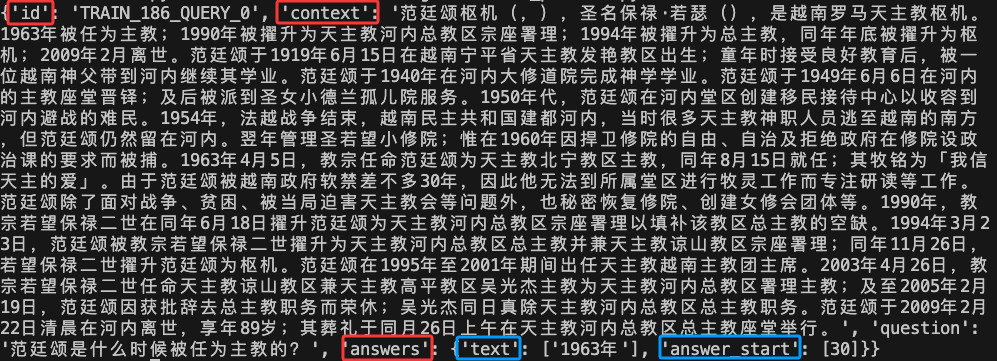
對于每條數據,包括id,context,question以及answers四個字段,其中id是當前數據的編號,context是一段文字性描述,涉及歷史、新聞、小說等各領域,answer包括兩部分,一部分是answer_start,標志答案從哪個context中的token開始,另一部分是text,代表了針對question給出的答案,此答案由人類專家給出,上圖中有兩個答案,代表人類專家1和人類專家2分別給出,以此來保證答案的準確性。
首先我們要將此數據集下載到本地,這里我們采用datasets庫進行下載(如果您沒有安裝datasets庫,請先利用pip install datasets進行安裝),代碼如下:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L54)
from datasets import load_dataset
dataset = load_dataset('cmrc2018') # 加載數據集
# dataset = load_dataset('cmrc2018', cache_dir='path/to/datasets') # 指定下載路徑
print(dataset)上述代碼會將數據集自動下載到.cache/huggingface/datasets目錄下,如果您希望指定下載路徑,可以通過cache_dir參數來指定。下載成功后我們將看到如下格式的輸出:
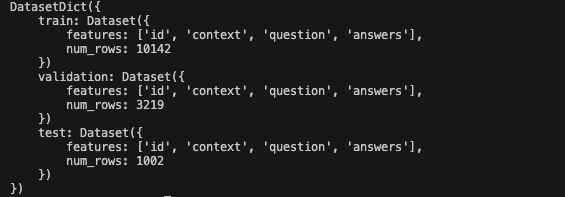
里面標著了當前datasets中包括train、validation以及test三部分數據。
2.構建知識庫
在這里,我們僅使用test數據集構建RAG的知識庫,該數據集的其他部分將在后續章節微調模型時使用(到相應章節會說明原因)。
具體構建思路如下:考慮到每條數據中有id,context,question以及answers四個字段,我們僅使用context部分內容作為知識庫,這樣在后續評測RAG的效果時,我們就可以選擇同一條數據當中context對應的question作為query輸入,通過比較RAG中檢索組件根據question召回的結果與RAG中生成組件與原本的answers,就可以對RAG系統的好壞做出評價。
在后續的章節中我們會進行詳細的介紹,在這里我們僅作為一個鋪墊。本章您只需要明白“我們將text數據集中的context部分構建RAG數據庫”即可。這里我們直接給出相應的代碼:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L59)
def create_KB(dataset):'''基于測試集中的context字段創建一個知識庫,每10條數據為一個txt,最后不足10條的也為一個txt'''Context = []for i in dataset:Context.append(i['context'])Context = list(set(Context)) # 去重后獲得256個語料# 計算需要的文件數chunk_size = 10total_files = (len(Context) + chunk_size - 1) // chunk_size # 向上取整# 創建文件夾data_kb保存知識庫語料os.makedirs("data_kb", exist_ok=True) # 按 10 條數據一組寫入多個文件for i in range(total_files):chunk = Context[i * chunk_size : (i + 1) * chunk_size] # 獲取當前 10 條數據file_name = f"./data_kb/part_{i+1}.txt" # 生成文件名with open(file_name, "w", encoding="utf-8") as f:f.write("\n".join(chunk)) # 以換行符分隔寫入文件# print(f"文件 {file_name} 寫入完成!") # 提示當前文件已寫入上述代碼中:
第2-3行:這部分代碼循環遍歷 data 中的每個字典,提取每個字典中的 context 字段的值,并將其添加到 Context 列表中。最終,Context 將包含所有的 context 數據。
第6行:通過使用 set(),該行代碼去除了 Context 中的重復項,確保每個 context 只出現一次。然后,使用 list() 將去重后的 set 轉換回列表。
第9-10行:chunk_size 設置為10,表示每個文件將包含最多10條 context 數據。為了計算需要生成多少個文件,total_files 通過將 Context 列表的長度除以 chunk_size 進行計算,且使用了向上取整的技巧 (len(Context) + chunk_size - 1) // chunk_size。這確保了即使 Context 的長度不是10的整數倍,最后一部分數據也會被單獨寫入一個文件。
第15-20行:將 Context 列表按每10條數據一組進行拆分,并將每組數據寫入一個獨立的文本文件。具體操作如下:
👉for i in range(total_files):循環遍歷需要創建的文件數量。
👉chunk = Context[i * chunk_size : (i + 1) * chunk_size]:從 Context 中獲取當前批次的10條數據(即每個文件包含10條數據)。
👉file_name = f"./data_kb/part_{i+1}.txt":為每個文件生成一個唯一的文件名,例如 part_1.txt, part_2.txt 等。
👉with open(file_name, "w", encoding="utf-8") as f::以寫模式打開(或創建)對應的文本文件,并確保使用 UTF-8 編碼。
👉f.write("\n".join(chunk)):將當前批次的10條數據通過換行符 \n 拼接起來,并寫入文件。
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L82)???????
# 調用create_KB()創建知識庫
create_KB(dataset['test'])
# 展示其中一個txt文件中的內容
with open('data_kb/part_1.txt') as f:print(f.read())上述代碼執行完成后,您的當前目錄下將多出一個data_kb文件夾,里面包括若干個txt文件:

文件中的內容大致如下:

🚨請注意:上述data_kb文件夾的路徑,在后續的RAG系統搭建中,若無特殊說明,我們將始終以此路徑下的文件作為RAG的知識庫。
3.環境檢查
檢查你環境中的數據庫(sqlite)是否支持多線程:
from lazyllm.common.queue import sqlite3_check_threadsafety
print(sqlite3_check_threadsafety())如果結果為False,則你需要先重裝sqlite,使之支持多線程。以macbook為例:
brew update
brew install sqlite
which sqlite3如果結果不是homebrew下的sqlite,則你需要設置如下環境變量,并重裝python:
brew uninstall python
export PATH="/opt/homebrew/opt/sqlite/bin:$PATH"
export LDFLAGS="-L/opt/homebrew/opt/sqlite/lib"
export CPPFLAGS="-I/opt/homebrew/opt/sqlite/include”
brew install python實現基礎的 RAG
我們已經介紹了LazyLLM中最常用的三個RAG 組件,準備好了知識庫,接下來就讓我們實現最簡單的RAG吧!
下面我們再來簡單回顧下上文提到的 RAG 核心組件Document,Retriever,大模型:
Document 組件:負責文檔加載與管理,使用時只需指定文檔地址即可實現加載和存儲文檔。
Retriever 組件:負責實現 RAG 系統的檢索功能,使用時需要指定在哪個文檔庫進行檢索,以何種方式進行檢索以及返回多少條檢索結果等。
大模型(LLM):負責根據檢索到的文檔進行答復,簡單情況下只需輸入用戶查詢和檢索組件檢索到的文檔即可。LazyLLM 提供了 TrainableModule 和 OnlineChatModule 分別支持本地模型和在線模型的統一調用,用戶無需關注內部細節,可以自由切換不同模型。
將這三個組件的使用串聯在一起,我們就得到了最簡單的RAG,代碼如下:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter2/%E5%AE%9E%E6%88%981%EF%BC%9A%E6%9C%80%E5%9F%BA%E7%A1%80%E7%9A%84RAG.py#L89)???????
import lazyllm
# 文檔加載
documents = lazyllm.Document(dataset_path="/content/docs")
# 檢索組件定義
retriever = lazyllm.Retriever(doc=documents, group_name="CoarseChunk", similarity="bm25_chinese", topk=3)
# 生成組件定義
llm = lazyllm.OnlineChatModule(source="sensenova", model="SenseChat-5-1202")
# prompt 設計
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# 推理
query = "為我介紹下玉山箭竹"
# 將Retriever組件召回的節點全部存儲到列表doc_node_list中
doc_node_list = retriever(query=query)
# 將query和召回節點中的內容組成dict,作為大模型的輸入
res = llm({"query": query, "context_str": "".join([node.get_content() for node in doc_node_list])})
print(f'With RAG Answer: {res}')上述代碼思路梳理:
1??我們首先按照上面的介紹分別定義了文檔加載組件document(第4行代碼)、檢索組件retriever(第7行代碼)以及生成組件(第10行代碼)。
2??然后設計了大模型的prompt(第13行代碼),所謂prompt,就是指對大模型扮演角色/要執行任務的一個事先指定,然后我們通過llm.prompt方法將prompt和下文的附加信息"context_str"傳給大模型)。里面使用了內置的ChatPrompter方法,其具體含義為:
ChatPrompter:負責提示詞模板化,RAG 需要大模型基于提供的文檔回答相應問題,因此在輸入大模型時需要告訴大模型哪些是參考資料,哪個是問題。除此之外,在線模型往往需要將提示詞按照規定的格式傳給在線服務,ChatPrompter 可以幫助用戶實現這個過程,而無需用戶自行轉換。
3??接下來我們輸入自己的query(17行),并調用retriever的得到檢索結果(19行)存儲在列表doc_mode_list中。
4??最后我們調用大模型llm(21行),這里傳入了一個字典,字典包括兩部分,一部分是我們提出的問題query,另一部分是參考信息即retriever檢索到的結果content_str,這里我們從doc_mode_list取出各個檢索節點,并通過.get_content方法和"".join方法拼接為一個完整的內容。
我們對比一下在沒有使用RAG直接調用大模型的情況下的結果:???????
# 生成組件定義
llm_without_rag = lazyllm.OnlineChatModule(source="sensenova", model="SenseChat-5-1202")
query = "為我介紹下玉山箭竹"
res = llm_without_rag(query)
print(f'Without RAG Answer: {res}')參考文獻:
[1] A Span-Extraction Dataset for Chinese Machine Reading Comprehension
附錄
mac安裝 Python, Pip 和 Git
1.先安裝xcode:
并且接受許可協議,然后安裝xcode的命令行工具:
sudo xcode-select -s /Applications/Xcode.app/Contents/Developer # 確保路徑正確
sudo xcodebuild -license accept # 接受許可證協議
xcode-select --install # 安裝 Xcode 命令行工具2.安裝homebrew,并并通過homebrew安裝python和pip:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zshrc
source ~/.zshrc
brew install pyenv
pyenv install 3.10.03.安裝python3.10。注意不能安裝python3.13,因為我們依賴的spacy包不支持python3.13:
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init --path)"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
pyenv global 3.10.0
python3 -m venv lazyllm
source lazyllm/bin/activateapi key鏈接
日日新:
方法1:https://console.sensecore.cn/help/docs/model-as-a-service/nova/
方法2:https://console.sensecore.cn/aistudio/management/api-key
OpenAI:
https://platform.openai.com/api-keys
智譜AI:
https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
Kimi:
https://platform.moonshot.cn/console/api-keys
通義千問:
https://help.aliyun.com/zh/model-studio/obtain-api-key-app-id-and-workspace-id
豆包:
https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey??apikey=%7B%7D
更多技術交流,歡迎移步 “LazyLLM” gzh!










新特性)
)







)