Redis與MySQL數據同步:從“雙寫一致性”到實戰方案
在分布式系統中,Redis作為高性能緩存被廣泛使用——它能將熱點數據從MySQL中“搬運”到內存,大幅降低數據庫壓力、提升接口響應速度。但隨之而來的核心問題是:當MySQL數據更新時,如何保證Redis緩存與數據庫的數據一致? 這就是“雙寫一致性”問題,處理不好可能導致緩存返回舊數據(臟讀)、業務邏輯異常,甚至引發資損。
本文將從“為什么需要同步”出發,拆解雙寫一致性的核心挑戰,再通過6種主流方案的原理、優缺點及實戰建議,幫你找到適合業務的同步策略。
一、為什么要做數據同步?先搞懂“緩存的本質”
在討論同步前,我們先明確一個前提:緩存是MySQL數據的“臨時副本”,它的存在是為了“加速讀取”,而非存儲核心數據。這意味著:
- 緩存中的數據必須以MySQL為準(數據庫是“真理源”);
- 當MySQL數據變更時,緩存必須隨之更新或失效,否則會出現“緩存數據≠數據庫數據”的不一致問題。
舉個例子:用戶A在電商平臺修改了昵稱(MySQL中已更新為“新昵稱”),但Redis中仍緩存著“舊昵稱”。此時其他用戶查詢A的信息時,Redis返回舊數據——這就是典型的“緩存臟讀”,會直接影響用戶體驗。
因此,數據同步的核心目標是:在保證業務性能的前提下,盡可能減少緩存與數據庫的不一致窗口(不一致持續的時間)。
二、雙寫一致性的3個核心挑戰
數據同步的難點不在于“單線程場景”(單線程下按順序操作即可),而在于分布式系統的“并發、延遲、故障”三大不可控因素:
- 并發更新沖突:兩個請求同時更新同一條數據,可能導致“后更新的數據庫操作,卻先更新了緩存”,最終緩存存舊值。
- 網絡延遲/故障:更新數據庫后,同步緩存時發生網絡超時,導致緩存未更新,數據不一致。
- 緩存失效機制:緩存過期時間設置不合理(太短頻繁查庫、太長臟數據久存),或主動刪除緩存失敗,都會放大不一致問題。
三、6種主流同步方案:從基礎到進階
方案1:Cache Aside Pattern(緩存旁路模式)——最經典的“讀走緩存,寫走數據庫”
Cache Aside是業界最常用的基礎方案,核心邏輯是“讀操作優先查緩存,寫操作直接更新數據庫+刪除緩存”,具體流程如下:
讀操作流程:
- 先查詢Redis緩存;
- 若緩存存在(命中),直接返回數據;
- 若緩存不存在(未命中),查詢MySQL數據庫;
- 將數據庫查詢結果寫入Redis(緩存預熱),再返回數據。

寫操作流程:
- 先更新MySQL數據庫;
- 再刪除Redis中對應的緩存(而非更新緩存);
- 后續讀請求會從數據庫加載新數據到緩存。
為什么是“刪除緩存”而非“更新緩存”?
假設兩個并發寫請求:
- 請求1:更新MySQL(新值A)→ 準備更新緩存;
- 請求2:更新MySQL(新值B)→ 先更新緩存(寫入B);
- 此時請求1繼續執行,將緩存更新為A——最終緩存是舊值A,與數據庫的B不一致。
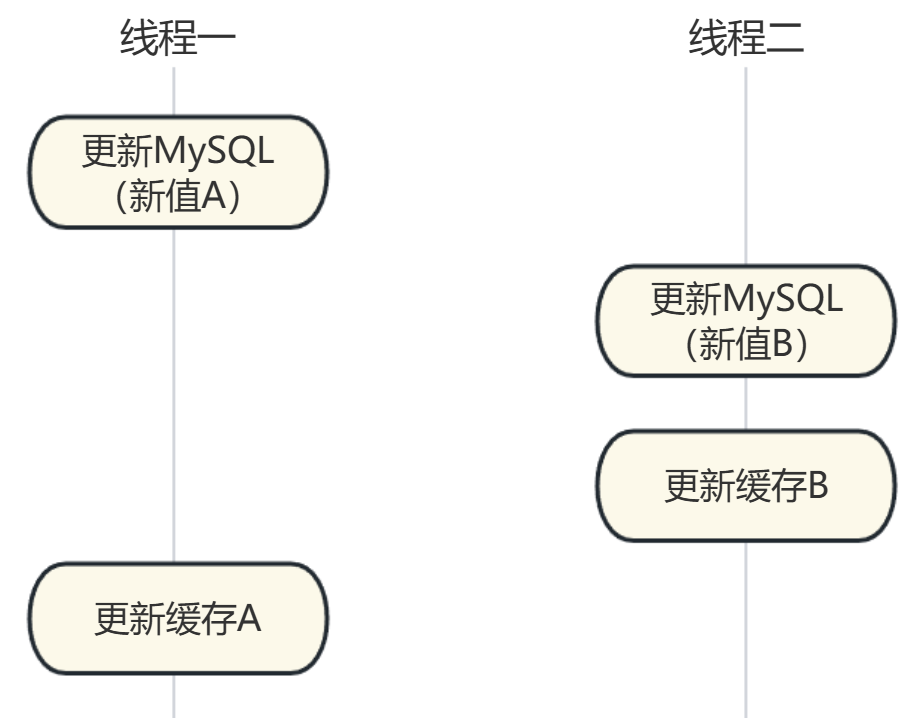
- 而“刪除緩存”能避免這種問題:無論寫請求順序如何,最終緩存都會被刪除,后續讀請求會從數據庫加載最新值,從根源上減少舊值覆蓋新值的風險。
優點:
- 邏輯簡單,易實現;
- 對緩存依賴低(緩存故障不影響寫操作);
- 避免“更新緩存”的并發沖突。
缺點:
- 首次讀(緩存未命中)會有“查庫+寫緩存”的耗時(可通過預熱緩解);
- 寫操作后若有讀請求并發,可能出現“讀請求查庫時,緩存還未刪除”的短暫不一致(窗口極短)。
適用場景:大部分中小規模業務,讀寫頻率中等,對一致性要求不極致(允許毫秒級不一致)。
方案2:雙寫模式(更新數據庫+更新緩存)——不推薦,但要知道為什么坑
雙寫模式的邏輯是“寫操作時同時更新數據庫和緩存”,流程為:
- 先更新MySQL數據庫;
- 再更新Redis緩存(寫入新值)。
看似合理,實則坑多:
- 并發更新時,若“更新緩存”順序與“更新數據庫”順序不一致,會導致緩存舊值。例如:
請求1:更新MySQL(值A)→ 未更新緩存;
請求2:更新MySQL(值B)→ 先更新緩存(B);
請求1繼續更新緩存(A)→ 緩存為A,數據庫為B,不一致。 - 若緩存更新失敗(如網絡問題),會直接導致不一致(數據庫已更新,緩存未更新)。
結論:僅適合“單線程寫+低并發”場景(幾乎不存在),生產環境慎用。
方案3:讀寫穿透(Read/Write Through)——緩存作為“數據庫代理”
讀寫穿透模式中,應用不直接操作MySQL,而是通過緩存中間件(如Redis、MQ)統一處理讀寫:
- 讀穿透:緩存未命中時,由Redis主動查詢MySQL并加載數據;
- 寫穿透:寫操作時,Redis先更新自身緩存,再異步同步到MySQL。
優點:應用層無需關心數據庫操作,簡化邏輯。
缺點:
- 依賴Redis中間件的同步能力(如Redis Module、MQ);
- 若緩存同步MySQL失敗,會導致“緩存有新值,數據庫無”的不一致(需額外重試機制)。
適用場景:有成熟中間件支持的場景(如阿里云Redis企業版),適合對代碼簡潔性要求高的團隊。
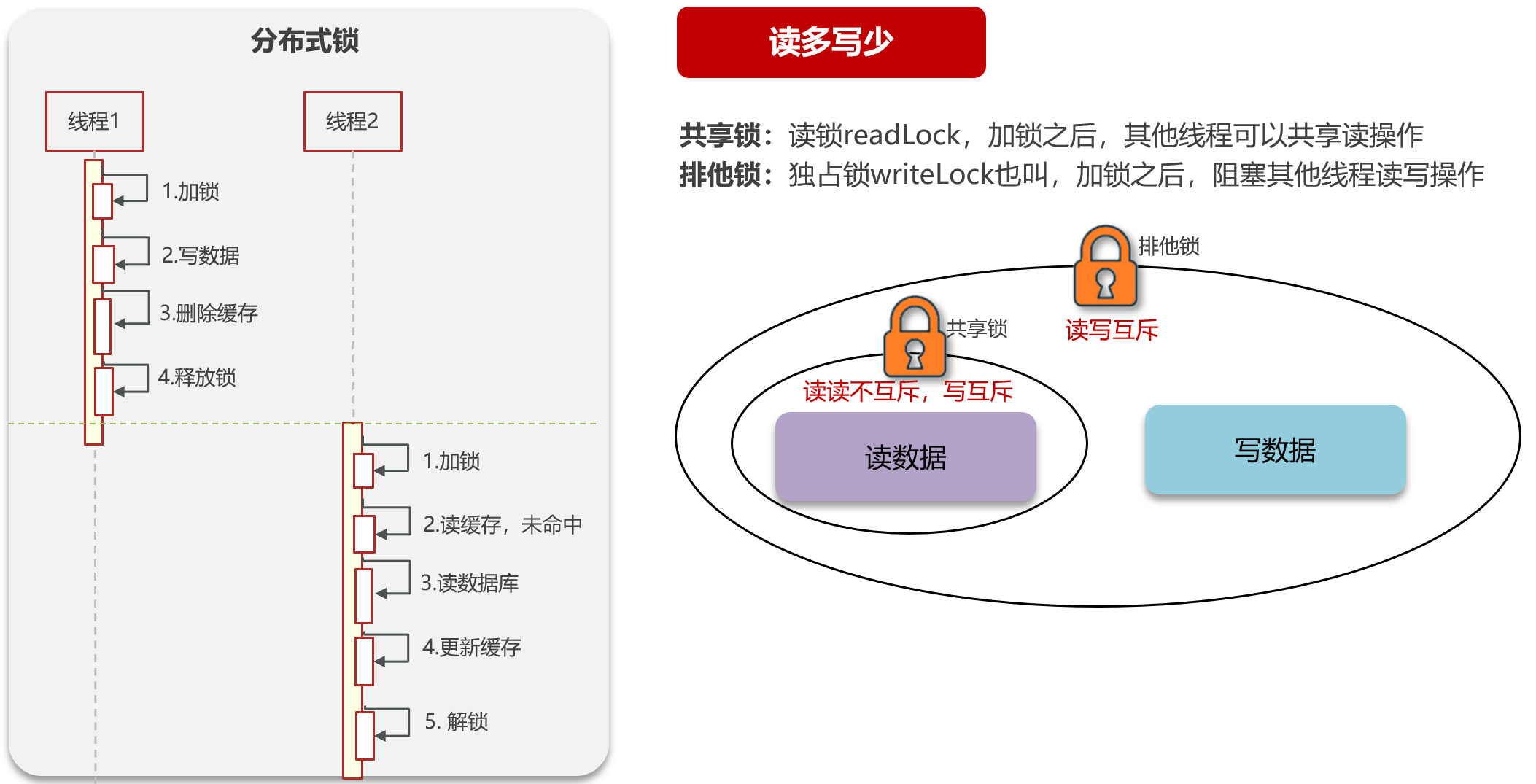
方案4:加鎖(解決并發沖突)——給同步過程“上保險”
針對并發更新導致的不一致,可通過“加鎖”縮小不一致窗口。核心邏輯是:對同一條數據的寫操作加鎖,保證“更新數據庫+同步緩存”的原子性。
實現方式:
- 用Redis的
SET NX實現分布式鎖(如SET lock:user:1 1 EX 10 NX); - 寫操作前先獲取鎖,執行“更新MySQL+刪除緩存”后釋放鎖;
- 未獲取到鎖的請求等待或重試。
優點:幾乎能避免并發更新導致的不一致。
缺點:
- 加鎖會降低并發性能(鎖競爭耗時);
- 需處理鎖超時、死鎖問題(如設置合理的鎖過期時間)。
適用場景:核心業務數據(如訂單、庫存),對一致性要求高,可接受一定性能損耗。
強一致性需求可采用讀寫鎖來保證
讀鎖 Java 代碼示例:
public Item getById(Integer id) {RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");// 讀之前加讀鎖,讀鎖的作用就是等待寫鎖釋放以后再讀RLock readLock = readWriteLock.readLock();try {// 開鎖readLock.lock();System.out.println("readLock...");Item item = (Item) redisTemplate.opsForValue().get("item:" + id);if (item != null) {return item;}// 查詢業務數據item = new Item(id, "華為手機", "華為手機", 5999.00);// 寫入緩存redisTemplate.opsForValue().set("item:" + id, item);// 返回數據return item;} finally {readLock.unlock();}
}
寫鎖 Java 代碼示例:
public void updateById(Integer id) {RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");// 寫之前加寫鎖,寫鎖加鎖成功,讀鎖只能等待RLock writeLock = readWriteLock.writeLock();try {// 開鎖writeLock.lock();System.out.println("writeLock...");// 更新業務數據Item item = new Item(id, "華為手機", "華為手機", 5299.00);try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}// 刪除緩存redisTemplate.delete("item:" + id);} finally {writeLock.unlock();}
}
方案5:延遲雙刪(解決“緩存刪除失敗”)——給緩存“補一刀”
延遲雙刪是針對“更新數據庫后,緩存刪除失敗”的補救方案,流程如下:
- 先刪除Redis緩存(預刪除,避免舊值被讀取);
- 更新MySQL數據庫;
- 延遲N毫秒(如500ms)后,再次刪除Redis緩存。
為什么要“延遲+雙刪”?
- 第一次刪除:避免更新數據庫期間,有讀請求加載舊值到緩存;
- 延遲N毫秒:等待數據庫更新完成(如:主從同步)、可能的并發讀請求結束(避免剛更新完數據庫,讀請求又加載舊值);
- 第二次刪除:兜底刪除可能殘留的舊緩存(比如第一次刪除失敗,第二次補刪)。
關鍵:N毫秒如何設置?
N需大于“數據庫更新耗時+并發讀請求加載緩存的最大耗時”,可通過壓測確定(一般建議500ms~1s,不宜過長影響性能)。
優點:簡單有效,能解決大部分“緩存刪除失敗”場景。
缺點:延遲刪除會占用線程資源(需用異步線程執行,如Java的ThreadPool)。
適用場景:高并發寫場景(如商品庫存更新),需兜底保證緩存失效。
方案6:版本號+緩存失效(解決“舊值覆蓋新值”)——給數據“貼標簽”
通過給數據加“版本號”,避免舊的寫操作覆蓋新的緩存。流程如下:
- MySQL表中新增
version字段(每次更新+1); - 寫操作:更新MySQL時同步更新version(如
UPDATE user SET name='新名', version=3 WHERE id=1 AND version=2); - 同步緩存時,將數據和version一起存入Redis(如
user:1 {name: '新名', version:3}); - 讀操作時,若緩存version小于數據庫version,直接刪除緩存并加載新數據。
優點:通過版本號判斷數據新舊,避免舊操作覆蓋新緩存。
缺點:需修改表結構(加version字段),增加業務邏輯復雜度。
適用場景:對一致性要求極高的核心數據(如金融賬戶余額)。
四、實戰建議:如何選擇適合的方案?
沒有“萬能方案”,需結合業務的“一致性要求”“并發量”“性能成本”綜合選擇:
| 業務場景 | 推薦方案 | 核心目標 |
|---|---|---|
| 普通業務(如用戶信息) | Cache Aside + 合理過期時間 | 平衡性能與一致性(允許毫秒級不一致) |
| 高并發寫(如商品庫存) | Cache Aside + 延遲雙刪 + 分布式鎖 | 優先保證一致性,容忍輕微性能損耗 |
| 核心金融數據(如賬戶余額) | Cache Aside + 版本號 + 事務 | 強一致性,性能可適當讓步 |
| 代碼簡潔優先(中小團隊) | 讀寫穿透(依賴中間件) | 減少開發成本,依賴中間件可靠性 |
五、最后:雙寫一致性的“黃金原則”
- 緩存是臨時存儲,永遠以數據庫為準:所有同步邏輯都應圍繞“數據庫更新后,緩存必須最終一致”設計;
- “刪除緩存”比“更新緩存”更安全:刪除能避免并發覆蓋,后續讀請求會自動修復緩存;
- 不一致是“概率問題”,目標是“縮小窗口”:完全消除不一致需要犧牲大量性能(如分布式事務),實際中更應關注“不一致是否影響業務”(如商品描述允許5分鐘不一致,庫存不允許)。
數據同步的本質是“權衡”——在一致性、性能、復雜度之間找到平衡點。掌握上述方案后,可先從Cache Aside模式入手,再根據業務問題逐步疊加“延遲雙刪”“加鎖”等優化,最終形成適合自己的同步策略。






新特性)
)







)


 GPIO輸出demo:LED閃爍)
