目錄
1 MLP
2 LeNet簡介
3 Minst數據集
3.1 MINST數據集簡介
3.2 MNIST數據集的預處理
4 LeNet手寫數字識別
LeNet由Yann Lecun 提出,是一種經典的卷積神經網絡,是現代卷積神經網絡的起源之一。Yann將該網絡用于郵局的郵政的郵政編碼識別,有著良好的學習和識別能力。LeNet又稱LeNet-5,具有一個輸入層,兩個卷積層,兩個池化層,3個全連接層(其中最后一個全連接層為輸出層)。
1 MLP
多層感知機MLP(Multilayer Perceptron),也是人工神經網絡(ANN,Artificial Neural Network),是一種全連接(全連接:MLP由多個神經元按照層次結構組成,每個神經元都與上一層的所有神經元相連)的前饋神經網絡模型。
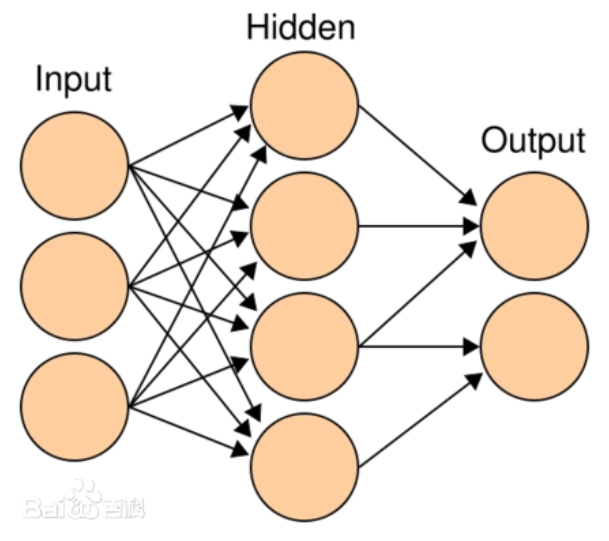
多層感知機(Multilayer Perceptron, MLP)是一種前饋神經網絡,它由輸入層、若干隱藏層和輸出層組成。每一層都由多個神經元(或稱為節點)組成。
-
輸入層(Input Layer):輸入層接收外部輸入的數據,將其傳遞到下一層。每個輸入特征都對應一個神經元。
-
隱藏層(Hidden Layer):隱藏層是位于輸入層和輸出層之間的一層或多層神經元。每個隱藏層的神經元接收上一層傳來的輸入,并通過權重和激活函數進行計算,然后將結果傳遞到下一層。隱藏層的存在可以使多層感知機具備更強的非線性擬合能力。
-
輸出層(Output Layer):輸出層接收隱藏層的輸出,并產生最終的輸出結果。輸出層的神經元數目通常與任務的輸出類別數目一致。對于分類任務,輸出層通常使用softmax激活函數來計算每個類別的概率分布;對于回歸任務,輸出層可以使用線性激活函數。
多層感知機的各層之間是全連接的,也就是說,每個神經元都與上一層的每個神經元相連。每個連接都有一個與之相關的權重和一個偏置。
2 LeNet簡介
LeNet-5模型是由楊立昆(Yann LeCun)教授于1998年在論文Gradient-Based Learning Applied to Document Recognition中提出的,是一種用于手寫體字符識別的非常高效的卷積神經網絡,其實現過程如下圖所示。
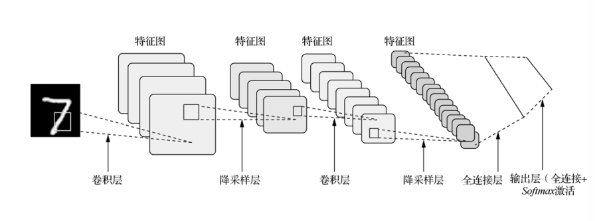
原論文的經典的LeNet-5網絡結構如下:
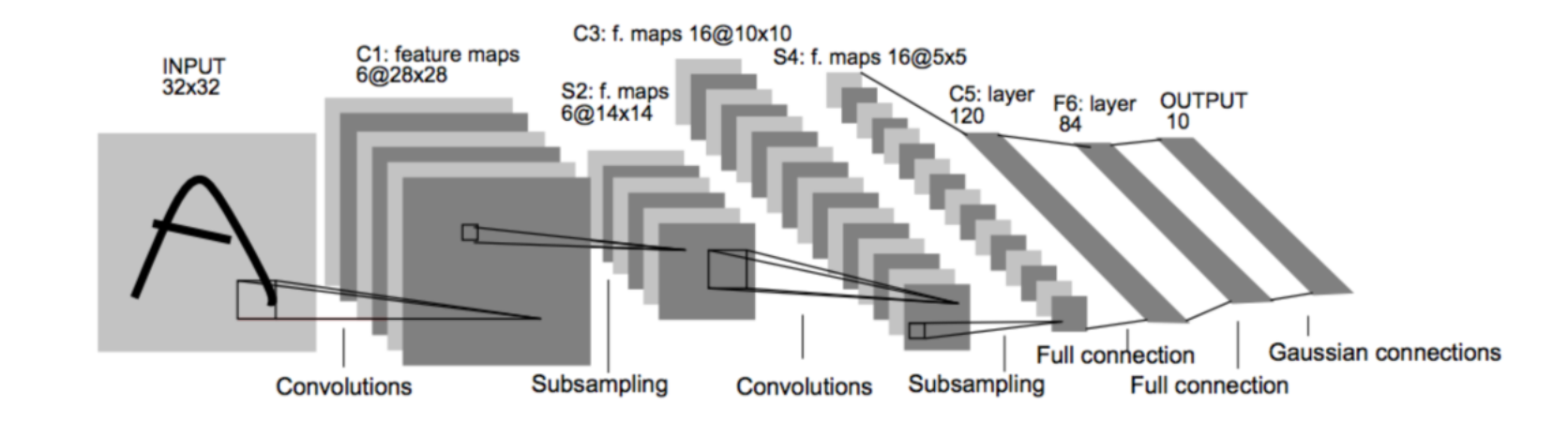
各個結構作用:
卷積層:提取特征圖的特征,淺層的卷積提取的是一些紋路、輪廓等淺層的空間特征,對于深層的卷積,可以提取出深層次的空間特征。
池化層: 1、降低維度 2、最大池化或者平均池化,在本網絡結構中使用的是最大池化。
全連接層: 1、輸出結果 2、位置:一般位于CNN網絡的末端。 3、操作:需要將特征圖reshape成一維向量,再送入全連接層中進行分類或者回歸。
下來我們使用代碼詳解推理一下各卷積層參數的變化:
import torch
import torch.nn as nn# 定義張量x,它的尺寸是1×1×28×28
# 表示了1個,單通道,32×32大小的數據
x = torch.zeros([1, 1, 32, 32])
# 定義一個輸入通道是1,輸出通道是6,卷積核大小是5x5的卷積層
conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
# 將x,輸入至conv,計算出結果c
c1 = conv1(x)
# 打印結果尺寸程序輸出:
print(c1.shape)# 定義最大池化層
pool = nn.MaxPool2d(2)
# 將卷積層計算得到的特征圖c,輸入至pool
s1 = pool(c1)
# 輸出s的尺寸
print(s1.shape)# 定義第二個輸入通道是6,輸出通道是16,卷積核大小是5x5的卷積層
conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 將x,輸入至conv,計算出結果c
c2 = conv2(s1)
# 打印結果尺寸程序輸出:
print(c2.shape)s2 = pool(c2)
# 輸出s的尺寸
print(s2.shape)輸出結果:
torch.Size([1, 6, 28, 28])
torch.Size([1, 6, 14, 14])
torch.Size([1, 16, 10, 10])
torch.Size([1, 16, 5, 5])下面是使用pytorch實現一個最簡單的LeNet模型。、
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()# 定義卷積層self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)# 定義全連接層self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)# 定義激活函數self.relu = nn.ReLU()def forward(self, x):# 卷積層 + 池化層 + 激活函數x = self.relu(self.conv1(x))x = F.avg_pool2d(x, kernel_size=2, stride=2)x = self.relu(self.conv2(x))x = F.avg_pool2d(x, kernel_size=2, stride=2)# 展平特征圖x = torch.flatten(x, 1)# 全連接層x = self.relu(self.fc1(x))x = self.relu(self.fc2(x))x = self.fc3(x)return x# 創建模型實例
model = LeNet()# 打印模型結構
print(model)輸出結果:
LeNet((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)(relu): ReLU()
)3 Minst數據集
MNIST是一個手寫數字集合,該數據集來自美國國家標準與技術研究所, National Institute of Standards and Technology (NIST). 訓練集 (training set) 由來自 250 個不同人手寫的數字構成, 其中 50% 是高中學生, 50% 來自人口普查局 (the Census Bureau) 的工作人員. 測試集(test set) 也是同樣比例的手寫數字數據。
3.1 MINST數據集簡介
-
該數據集包含60,000個用于訓練的示例和10,000個用于測試的示例。
-
數據集包含了0-9共10類手寫數字圖片,每張圖片都做了尺寸歸一化,都是28x28大小的灰度圖。
-
MNIST數據集包含四個部分: 訓練集圖像:train-images-idx3-ubyte.gz(9.9MB,包含60000個樣本) 訓練集標簽:train-labels-idx1-ubyte.gz(29KB,包含60000個標簽) 測試集圖像:t10k-images-idx3-ubyte.gz(1.6MB,包含10000個樣本) 測試集標簽:t10k-labels-idx1-ubyte.gz(5KB,包含10000個標簽)
3.2 MNIST數據集的預處理
這里我們可以觀察訓練集、驗證集、測試集分別有50000,10000,10000張圖片,并且讀取訓練集的第一張圖片看看。
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import struct# 圖像預處理:將圖像轉換為 (784, 1) 的張量
transform = transforms.Compose([transforms.ToTensor(), # 轉為 [0,1] 范圍的 Tensortransforms.Lambda(lambda x: x.view(-1, 1)) # 展平為 (784, 1)
])# 加載 MNIST 訓練集和測試集
train_dataset = datasets.MNIST(root='./dataset',train=True,transform=transform,download=True
)test_dataset = datasets.MNIST(root='./dataset',train=False,transform=transform,download=True
)# 使用 DataLoader 批量加載
train_loader = DataLoader(dataset=train_dataset,batch_size=64,shuffle=True
)test_loader = DataLoader(dataset=test_dataset,batch_size=64,shuffle=False
)# ? 打印訓練集和測試集的樣本數量
print(f"訓練集樣本數量: {len(train_dataset)}")
print(f"測試集樣本數量: {len(test_dataset)}")# ? 控制臺輸出矩陣的代碼
print("=" * 140)
print("圖像矩陣的十六進制表示(非零值用紅色標出):")
data = train_dataset[0][0].squeeze().numpy() # 獲取第一張圖像并轉換為 numpy 數組
rows = 28
columns = 28counter = 0
for i in range(rows):row = data[i * columns: (i + 1) * columns]for value in row:integer_part = int(value * 100)# 防止溢出 unsigned short (0~65535)integer_part = max(0, min(65535, integer_part))hex_bytes = struct.pack('H', integer_part)hex_string = hex_bytes.hex()if hex_string == '0000':print(hex_string + ' ', end="")else:print(f'\033[31m{hex_string}\033[0m' + " ", end="")counter += 1if counter % 28 == 0:print() # 換行
print("=" * 140)# 示例:取出第一個 batch 的數據
for images, labels in train_loader:print("Batch Images Shape:", images.shape) # [batch_size, 784, 1]print("Batch Labels Shape:", labels.shape) # [batch_size]# 顯示第一張圖像img = images[0].reshape(28, 28).numpy()plt.imshow(img, cmap='gray')plt.title(f"Label: {labels[0].item()}")plt.axis('off')plt.show()break # 只顯示一個 batch輸出結果:
訓練集樣本數量: 60000
測試集樣本數量: 10000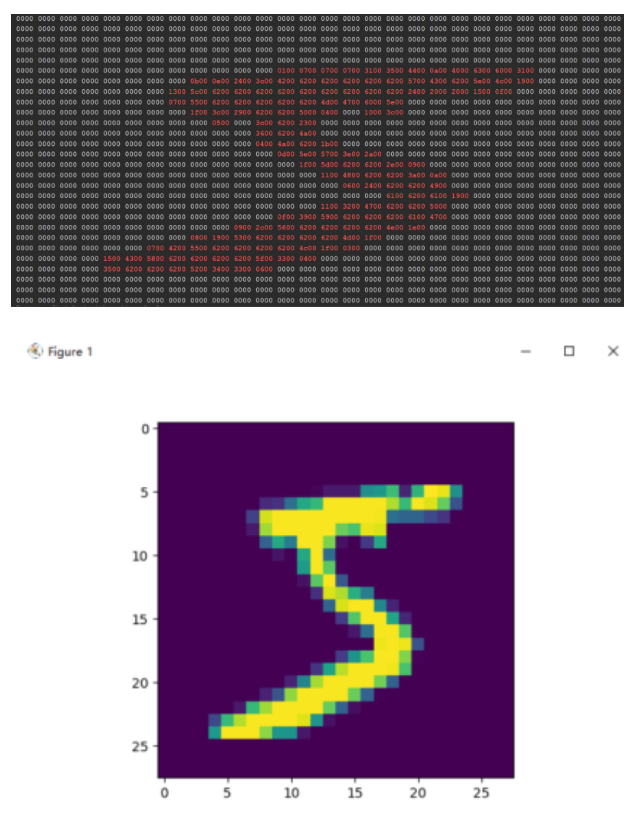
4 LeNet手寫數字識別
代碼實現如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import time
from matplotlib import pyplot as pltpipline_train = transforms.Compose([# 隨機旋轉圖片# MNIST 是手寫數字數據集,左右翻轉可能造成語義錯誤(例如,6 和 9 會被混淆)。所以不建議使用# transforms.RandomHorizontalFlip(),# 將圖片尺寸resize到32x32transforms.Resize((32, 32)),# 將圖片轉化為Tensor格式transforms.ToTensor(),# 正則化(當模型出現過擬合的情況時,用來降低模型的復雜度)transforms.Normalize((0.1307,), (0.3081,))
])
pipline_test = transforms.Compose([# 將圖片尺寸resize到32x32transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])
# 下載數據集
train_set = datasets.MNIST(root="./dataset", train=True, download=True, transform=pipline_train)
test_set = datasets.MNIST(root="./dataset", train=False, download=True, transform=pipline_test)
# 加載數據集
trainloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(test_set, batch_size=32, shuffle=False)# 構建LeNet模型
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.relu = nn.ReLU()self.maxpool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.maxpool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 創建模型,部署gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LeNet().to(device)
# 定義優化器
optimizer = optim.Adam(model.parameters(), lr=0.001)def train_runner(model, device, trainloader, optimizer, epoch):model.train()total_loss = 0total_correct = 0total_samples = 0for i, (inputs, labels) in enumerate(trainloader):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = F.cross_entropy(outputs, labels)predict = outputs.argmax(dim=1)correct = (predict == labels).sum().item()loss.backward()optimizer.step()total_loss += loss.item()total_correct += correcttotal_samples += labels.size(0)if i % 100 == 0:print(f"Epoch {epoch}, Batch {i}, Loss: {loss.item():.6f}, Accuracy: {correct / labels.size(0) * 100:.2f}%")avg_loss = total_loss / len(trainloader)avg_acc = total_correct / total_samplesprint(f"Epoch {epoch} - Average Loss: {avg_loss:.6f}, Accuracy: {avg_acc * 100:.2f}%")return avg_loss, avg_accdef test_runner(model, device, testloader):# 模型驗證, 必須要寫, 否則只要有輸入數據, 即使不訓練, 它也會改變權值# 因為調用eval()將不啟用 BatchNormalization 和 Dropout, BatchNormalization和Dropout置為Falsemodel.eval()# 統計模型正確率, 設置初始值correct = 0.0test_loss = 0.0total = 0# torch.no_grad將不會計算梯度, 也不會進行反向傳播with torch.no_grad():for data, label in testloader:data, label = data.to(device), label.to(device)output = model(data)test_loss += F.cross_entropy(output, label).item()predict = output.argmax(dim=1)# 計算正確數量total += label.size(0)correct += (predict == label).sum().item()# 計算損失值print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss / total, 100 * (correct / total)))# 調用
epoch = 5
Loss = []
Accuracy = []
for epoch in range(1, epoch + 1):print("start_time", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))loss, acc = train_runner(model, device, trainloader, optimizer, epoch)Loss.append(loss)Accuracy.append(acc)test_runner(model, device, testloader)print("end_time: ", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), '\n')print('Finished Training')plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(Loss)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')plt.subplot(1, 2, 2)
plt.plot(Accuracy)
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.tight_layout()
plt.show()輸出效果:
?
start_time 2025-07-21 23:55:06
Epoch 1, Batch 0, Loss: 2.289716, Accuracy: 10.94%
Epoch 1, Batch 100, Loss: 0.193995, Accuracy: 96.88%
Epoch 1, Batch 200, Loss: 0.182066, Accuracy: 93.75%
Epoch 1, Batch 300, Loss: 0.188292, Accuracy: 95.31%
Epoch 1, Batch 400, Loss: 0.124157, Accuracy: 95.31%
Epoch 1, Batch 500, Loss: 0.034723, Accuracy: 100.00%
Epoch 1, Batch 600, Loss: 0.008845, Accuracy: 100.00%
Epoch 1, Batch 700, Loss: 0.085703, Accuracy: 98.44%
Epoch 1, Batch 800, Loss: 0.043274, Accuracy: 100.00%
Epoch 1, Batch 900, Loss: 0.081251, Accuracy: 96.88%
Epoch 1 - Average Loss: 0.204190, Accuracy: 93.77%
test_avarage_loss: 0.001810, accuracy: 98.210000%
end_time: 2025-07-21 23:55:36 start_time 2025-07-21 23:55:36
Epoch 2, Batch 0, Loss: 0.007833, Accuracy: 100.00%
Epoch 2, Batch 100, Loss: 0.026923, Accuracy: 98.44%
Epoch 2, Batch 200, Loss: 0.055813, Accuracy: 98.44%
Epoch 2, Batch 300, Loss: 0.021718, Accuracy: 98.44%
Epoch 2, Batch 400, Loss: 0.044155, Accuracy: 98.44%
Epoch 2, Batch 500, Loss: 0.078634, Accuracy: 98.44%
Epoch 2, Batch 600, Loss: 0.077378, Accuracy: 98.44%
Epoch 2, Batch 700, Loss: 0.024615, Accuracy: 98.44%
Epoch 2, Batch 800, Loss: 0.065229, Accuracy: 95.31%
Epoch 2, Batch 900, Loss: 0.105533, Accuracy: 96.88%
Epoch 2 - Average Loss: 0.058598, Accuracy: 98.17%
test_avarage_loss: 0.001409, accuracy: 98.510000%
end_time: 2025-07-21 23:56:09 start_time 2025-07-21 23:56:09
Epoch 3, Batch 0, Loss: 0.008086, Accuracy: 100.00%
Epoch 3, Batch 100, Loss: 0.007276, Accuracy: 100.00%
Epoch 3, Batch 200, Loss: 0.026653, Accuracy: 98.44%
Epoch 3, Batch 300, Loss: 0.013348, Accuracy: 100.00%
Epoch 3, Batch 400, Loss: 0.051161, Accuracy: 98.44%
Epoch 3, Batch 500, Loss: 0.011193, Accuracy: 100.00%
Epoch 3, Batch 600, Loss: 0.018030, Accuracy: 100.00%
Epoch 3, Batch 700, Loss: 0.031486, Accuracy: 98.44%
Epoch 3, Batch 800, Loss: 0.040127, Accuracy: 96.88%
Epoch 3, Batch 900, Loss: 0.003004, Accuracy: 100.00%
Epoch 3 - Average Loss: 0.041799, Accuracy: 98.73%
test_avarage_loss: 0.001054, accuracy: 98.890000%
end_time: 2025-07-21 23:56:42 start_time 2025-07-21 23:56:42
Epoch 4, Batch 0, Loss: 0.005576, Accuracy: 100.00%
Epoch 4, Batch 100, Loss: 0.004955, Accuracy: 100.00%
Epoch 4, Batch 200, Loss: 0.025697, Accuracy: 98.44%
Epoch 4, Batch 300, Loss: 0.060617, Accuracy: 98.44%
Epoch 4, Batch 400, Loss: 0.011967, Accuracy: 100.00%
Epoch 4, Batch 500, Loss: 0.006767, Accuracy: 100.00%
Epoch 4, Batch 600, Loss: 0.060184, Accuracy: 98.44%
Epoch 4, Batch 700, Loss: 0.018019, Accuracy: 98.44%
Epoch 4, Batch 800, Loss: 0.052307, Accuracy: 98.44%
Epoch 4, Batch 900, Loss: 0.002293, Accuracy: 100.00%
Epoch 4 - Average Loss: 0.033747, Accuracy: 98.92%
test_avarage_loss: 0.001589, accuracy: 98.420000%
end_time: 2025-07-21 23:57:15 start_time 2025-07-21 23:57:15
Epoch 5, Batch 0, Loss: 0.028971, Accuracy: 98.44%
Epoch 5, Batch 100, Loss: 0.002826, Accuracy: 100.00%
Epoch 5, Batch 200, Loss: 0.001654, Accuracy: 100.00%
Epoch 5, Batch 300, Loss: 0.021051, Accuracy: 100.00%
Epoch 5, Batch 400, Loss: 0.122267, Accuracy: 95.31%
Epoch 5, Batch 500, Loss: 0.011313, Accuracy: 100.00%
Epoch 5, Batch 600, Loss: 0.007512, Accuracy: 100.00%
Epoch 5, Batch 700, Loss: 0.029513, Accuracy: 98.44%
Epoch 5, Batch 800, Loss: 0.006132, Accuracy: 100.00%
Epoch 5, Batch 900, Loss: 0.015854, Accuracy: 98.44%
Epoch 5 - Average Loss: 0.027342, Accuracy: 99.14%
test_avarage_loss: 0.001210, accuracy: 98.840000%
end_time: 2025-07-21 23:57:47 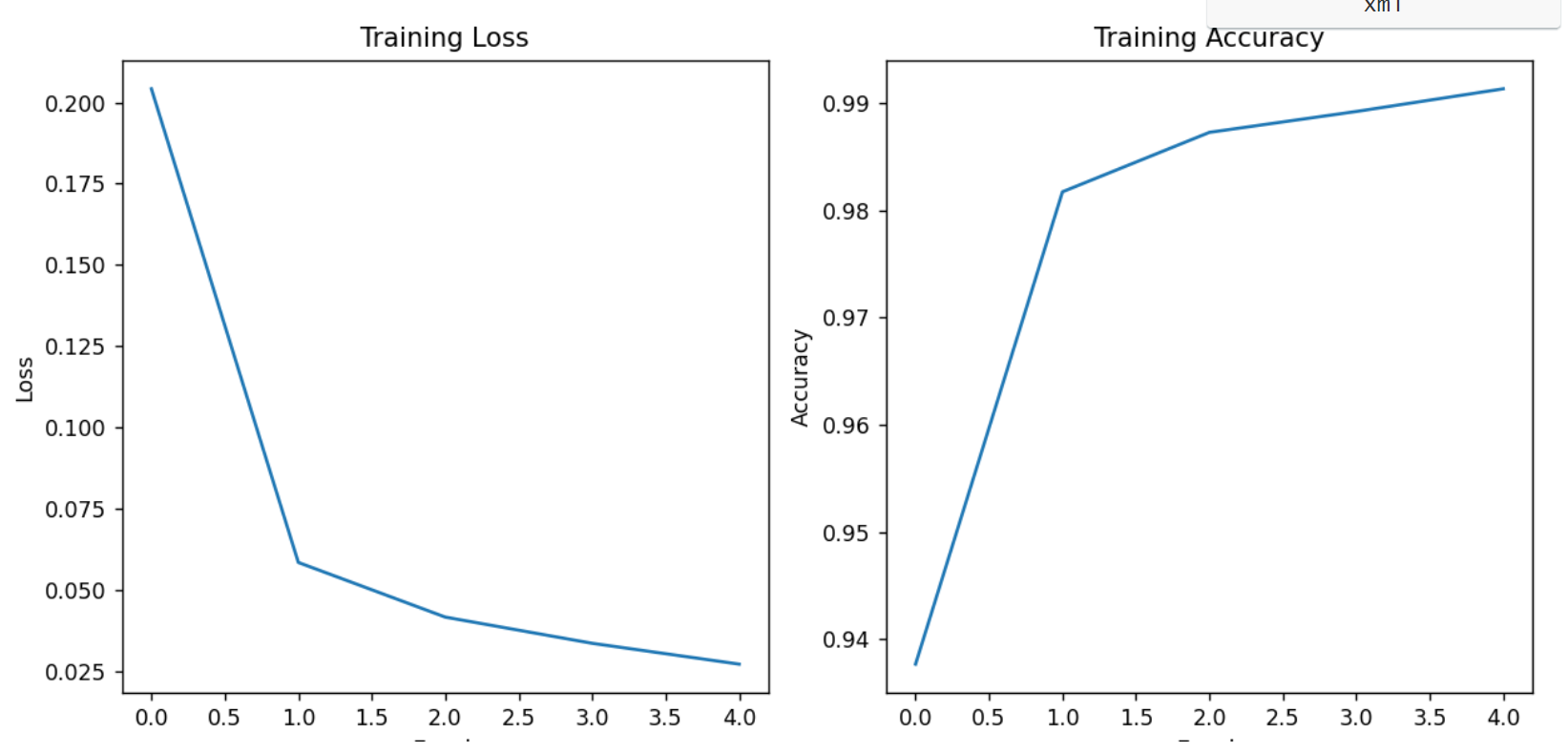
增加模型預測功能:
model.load_state_dict(torch.load('./mymodel.pt'))
print("成功加載模型....")index = random.randint(0,100)
image, label = train_set[index] # 從 test_set 中直接獲取圖像和標簽
image = image.unsqueeze(0).to(device)# 進行預測
model.eval()
with torch.no_grad():output = model(image)predicted_label = output.argmax(dim=1, keepdim=True)print("Predicted label:", predicted_label[0].item())
print("Actual label:", label)運行效果:
成功加載模型....Predicted label: 9
Actual label: 9



)














事件系統)