常用pip源
(1)阿里云
http://mirrors.aliyun.com/pypi/simple/
(2)豆瓣
http://pypi.douban.com/simple/
(3)清華大學
https://pypi.tuna.tsinghua.edu.cn/simple/
(4)中國科學技術大學
http://pypi.mirrors.ustc.edu.cn/simple/
(5)華中科技大學
http://pypi.hustunique.com/
第一講 基礎知識
# ctrl+/ 添加注釋
# ctrl+alt+l 三鍵實現格式規范
# \+特定字符 產生一個新的含義,就是轉義字符(# \\ \t)
#\\ 表示一個反斜杠
#\n 是換行符
變量
# 變量
# 1.嚴格區分大小寫
# 2.由數字,字母,下劃線組成,數字不能開頭
# 3.不能使用關鍵字
name = '張三'
print(name)
# input()表示輸入,在括號里面加入''可加入提示\
input('請輸入您的密碼')
輸入輸出
# 格式化輸出
age=18
name="zxy"
print("我的姓名是%s,年齡是%d"%(name,age))print(666)
print('我愛編程')
# sep=','指定,為分隔變量的符號
print('唐三', '小舞', '張三', sep=',')
print('唐三', '小舞', sep=' ')# end='\n'指定換行結尾
print('唐三', '小舞', end='*')
print('唐三', '小舞', end='\n') #這個是輸出換行,其實py默認有
print('唐三', '小舞', end=' ') #輸出不換行
input()函數接收的用戶輸入始終是字符串類型(str)
遵循命名規范:大駝峰命名法和小駝峰命名法

第二講 數據類型
- 基本數據類型:
# 整型 int
age=19# 浮點型 float
money=15.1# 布爾型 boolean
sex=True #男
gender =False #女# String 字符串
a='A'
s="我愛python"
# '''中間可以放幾段話'''
name = '''
啦啦啦
啦啦啦
啦啦啦
'''
print(name)
定義字符串不要單引號和雙引號混用,顯得你不專業
- 復合數據類型
# list 列表
name_list['周總','王哥']
# tuple 元組
tuple=(1,2,3,4,5)
# dict 字典 {key:value,key1:value1}
person={'name':'小張','age':18}
- 用法:
# type函數,查看變量的類型
name = '漩渦鳴人'
print(type(name)) #<class 'str'>
# 運算注意優先級以及從左向右計算
轉義字符:
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\n</font>**:換行**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\t</font>**:制表符**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\\</font>**:反斜杠本身**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\'</font>**或**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\"</font>**:單引號/雙引號
- 類型轉換
# 字符不能和整數類型相加,但可以變換
name = '張三'
age = 48
print(name + str(age))
同理整型和浮點類型也可以相互轉換,但有非數字的字符不能轉換為整數,也不能是浮點類型結構
| 函數 | 說明 |
|---|---|
| int(x) | 把x轉換為一個整數 |
| float(x) | 把x轉換為一個浮點數 |
| str(x) | 把x轉換為一個字符串 |
| bool(x) | 把x轉換為一個布爾值 |
轉換為整型
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">int()</font>** 只能轉換 整數字符串(如 **<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">"123"</font>**)或 浮點數(如 **<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">123.456</font>**)
print(int("123")) #123將字符串轉換成為整款
print(int(123.78)) #123將浮點數轉換成為整數
print(int(true)) #布爾值true轉換成為整數是1
print(int(false)) #布爾值false轉換成為整數是
#以下兩種情況將會轉換失敗
123.456和12ab是字符串,一個是浮點數一個含字母,不能被轉換成為整數,會報措
print(int("123.456"))
print(int("12ab"))
轉換為浮點數
f1=float("12.34")
print(f1) #12.34
print(type(f1)) #f1oat將字符串的"12.34"轉換成為浮點數12.34
f2=float(23)
print(f2) #23.0
print(type(f2)) #float將整數轉換成為了浮點數
轉換為字符串
str1=str(45)
str2=str(34.56)
str3=str(True)
print(type(str1),type(str2),type(str3))
轉換為布爾類型(應用:常用于條件判斷,檢查變量是否為空或有效)
print(bool('')) # False(空字符串)
print(bool("")) # False(空字符串)
print(bool(0)) # False(整數 0)
print(bool({})) # False(空字典)
print(bool([])) # False(空列表)
print(bool(())) # False(空元組)
對于非0的整數進行布爾類型的轉換,都是True
第三講 運算符
- 算數運算符
-
-
- / 加減乘除
-
% 取余
// 取整除
** 指數
優先級 *高于/%//高于±
number = input('請輸入數字')
number = int(number) # 輸入的是字符類型,用int轉換為整數類型進行運算
result = number % 2
print(result)# //表示整除運算
bounty = 5000
print(bounty/280) # 結果是17.86
print(bounty//280) # 結果是17print(2**3) #輸出8# += *= /= -= 運算符
# 關系運算符返回值類型是布爾類型# ord()函數可以查看字符對應的整數數值
print(ord('a'))
- 賦值運算符
a,b,c=1,2,3
多變量賦值用逗號分隔
- 比較運算符
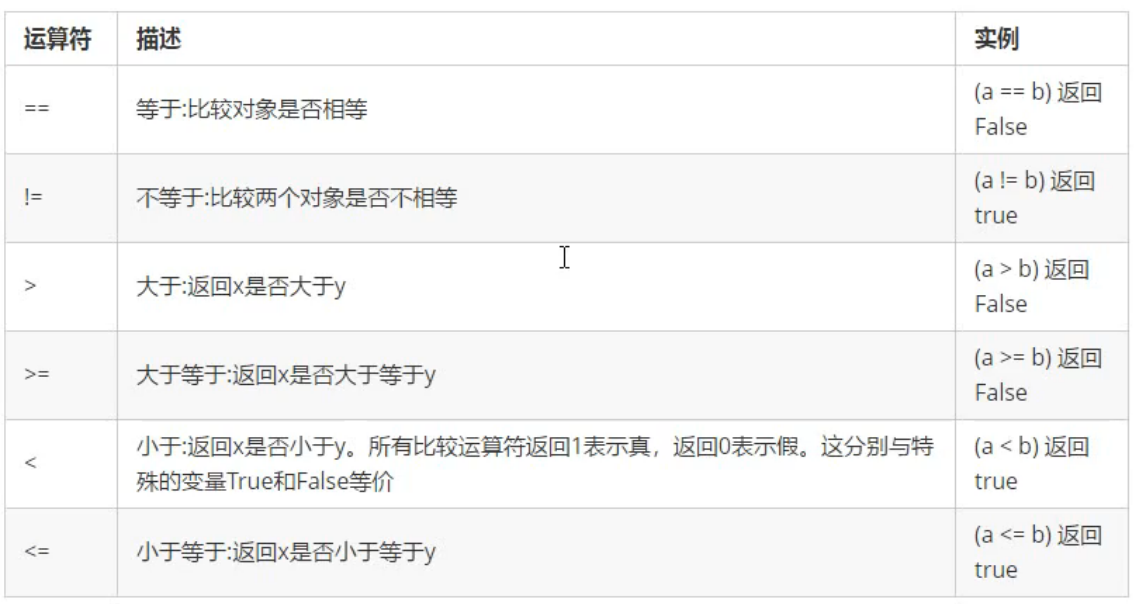
- 邏輯運算符

and的性能優化:當and前面的結果是fa1se的情況下 那么后面的代碼就不再執行了
or:只要有一方為true 那么結果就是true
第四講 條件語句
- if語句的使用
- if…else語句的使用
- 多重if語句的使用
- if嵌套
# if 要判斷的條件: (標準結構)
# 條件成立時要做的事情
# else:
# 條件成立時要做的事情
money = input('請輸入您的錢數')
money = int(money) # 注意轉換
things1 = '盲盒'
if money>35:print('拿下{}'.format(things1))
# 用{}進行占位,用.format()函數填充占位
else:print('買不起')
# elif語句
# if 條件1:
# 事情1
# elif 條件2:
# 事情2
# else:
# 事情3
choice1 = input('請輸入你要選的品牌')
choice2 = input('請輸入你要選的衣服類型')
money = input('請輸入你手中有多少錢')
money = int(money)
if choice1 == '安踏' and choice2 == '短袖' and money > 60 :print('您購買了{}品牌的{}'.format(choice1,choice2), '您還有{}元錢'.format(money-60) , sep = '\n')
elif choice1 == '李寧' and choice2 == '短袖' and money > 60 :print('您購買了{}品牌的{}'.format(choice1,choice2), '您還有{}元錢'.format(money-60) , sep = '\n')
elif choice1 == '耐克' and choice2 == '短袖' and money > 60:print('您購買了{}品牌的{}'.format(choice1, choice2), '您還有{}元錢'.format(money - 60), sep='\n')
else:print('您要的我們沒有或者您的錢不足以支付請重試')# if下語句可繼續嵌套if
第五講 循環語句
- while的使用
- for的使用
- break和continue的使用
- while或者for與else結合使用
循環的核心在于減少重復代碼,條件要盡量通用化
# while 循環條件:(當循環條件不成立時結束)
# 循環執行的代碼
# break,整個循環會立即終止,不再執行后續的循環體代碼,直接跳出循環
# continue 跳過本次循環,后面語句不執行,繼續執行下一次循環
i = input('請輸入數字')
i = int(i)
while i <= 5:i += 1print(i)
# 需求:限制登陸次數
i = 3
while i >= 1:username = input('請輸入用戶名')password = input('請輸入密碼')if username == 'admin' and password == '123456' :print('登錄成功')break # 作用在于登錄成功后退出循環else:print('登錄失敗')i -= 1print('還有{}次機會' .format(i))continue # 繼續循環
# for 變量 in 序列:
# 循環體
# 變量:自定義變量名,要求和單獨定義時候一樣
# 序列:容器型數據類型的數據,比如字符串,布爾,列表,元組,集合
# 循環體:需要重復執行的代碼
for x in range(1,11):print('今天你直播下單{}次'.format(x))# range()函數作用是產生一個序列,從0開始# range(1,11)則表示從1開始11結束但是不包括11# range(1,6,2)表示135的序列,即2為步長(可以是負數)
# 需求:限制登陸次數
for i in range(3):username = input('請輸入用戶名')password = input('請輸入密碼')if username == 'admin' and password == '123456' :print('登錄成功')break # 作用在于登錄成功后退出循環else:print('登錄失敗')print('還有{}次機會' .format(2-i))continue # 繼續循環# 需求:打印1-12數字,除了8不打印
# 方法一
for i in range(1,13):if i == 8:continueelse:print(i)
# 方法二
i = 1
while i <12:i += 1if i == 8 :continueprint(i)
# else可以和while,for進行配合
# 案例一
i = 13
while i <12:print('驗證失敗')
else:print('驗證成功')
# 案例二
for i in range(8):print(i , end=' ')
else:print('\n')print('結束')
第六講 數據類型列表
列表類似數組,字典類似結構體
列表的使用
# 以前介紹的int bool str float都只能存放一個值,需要列表存放一堆值
# 變量名字 = [元素,元素,元素]
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
print(type(heros))
輸出結果是<class ‘list’>,即構成了一種新的數據類型列表
列表索引
# 編號從0開始,相關方式類比數組
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
print(heros[1])
即可獲取張四,同理可以獲取其他元素
若要同時獲取多個元素,則要使用列表切片的辦法

# 1:3表示索引的一個左閉右開區間,只包含左邊不包含右邊
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
print(heros[0:6])
# [3:]若省去終止位置,則表示從標明的初始位置一直索引到終止位置
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
print(heros[0:])
這樣就可以把上述元素全部輸出出來了(倆個方法結果一樣)
但是顯然不可能所有的取法步長都為一也不可能都是順序取元素
# 完整格式 print(列表名(初始位置:終止位置:步長)) 默認步長為+1
#輸出從第一個元素開始的所有奇數項元素
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
print(heros[0::2])
我們在長數據超大數據時,往往不方便一次看出到底有多少個元素
# len()函數可以獲取列表的長度
print(len(heros))
我們往往需要增刪改查,實現列表元素動態管理
增:
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
# append可以實現列表元素增加
heros.append('張九')# insert方法定向插入元素,原來在此位置以及之后的元素全體后移
heros.insert(3, '張六plus')# extend合并兩個列表
num_list=[1,2,3]
num1_list=[4,5,6]
num_list.extend(num1_list)
print(num_list)
刪:
# del根據下標進行刪除
fruits = ['apple', 'banana', 'orange', 'pear']
# 刪除索引為1的元素('banana')
del fruits[1]
print(fruits) # 輸出: ['apple', 'orange', 'pear']# pop刪除最后一個元素
last_fruit = fruits.pop()
print(last_fruit) # 輸出: 'pear'
print(fruits) # 輸出: ['apple', 'banana', 'orange']# remove根據元素的值刪除元素
# 刪除第一個匹配到的'banana'
fruits.remove('banana')print(fruits) # 輸出: ['apple', 'orange', 'banana']# 如果要刪除的元素不存在會報錯
# fruits.remove('peach') # 會引發 ValueError
改:
改
heros[0] = '張三plus' # 實現修改定向位置的元素
查:
# index函數可以實現查找某一元素具體位置,并通過變量存儲,在案例實現的時候有奇效
number1 = heros.index('張三')
print(number1)# 可以利用 in 來判斷元素在不在列表內
# 格式 查找的元素 in 列表名 返回值是布爾類型,可以用int轉換后用變量儲存下來
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
number3 = int('張2' in heros)
print(number3) #輸出1或0
index 和 in 可以相互補充相互協調,index返回具體位置,in判斷在不在,還可以配合后面的count來判斷在不在
計數:
# 列表名.count(要查詢的元素) 返回值為元素個數
heros = ['張三', '張四', '張五', '張六', '張七', '張八']
heros.append('張三')
heros.append('張三')
heros.append('張三')
heros.append('張三')
number2 = heros.count('張三')
print(number2)
字典的使用
# 基礎格式: 變量名字 = {key1:value1,key2:value2}
hero = {'姓名': '孫悟空','性別': '男', '定位':'戰士' }
print(hero)
print(type(hero))
得到的結果是<class ‘dict’>即構成了一種新的數據類型列表
字典還可以和列表搭配使用
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
print(hero)
print(type(hero))
# 那如何獲取里面中的東西呢
print(hero['性別'])
# 如何判斷字典里面是否有我們查找的鍵呢
# print(字典名.get(查找的鍵,如果找不到返回的東西))
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
print(hero.get('定位', '未知'))
# 我們用get的時候,如果鍵存在則返回鍵的值,如果鍵不存在則返回設定的返回值,如果我們沒有設定返回值,則返回NONE
字典同樣支持增刪改查操作,實現動態管理
增:
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
hero['血量'] = 4399 # 對于一個原來沒有的鍵進行操作會添加
刪:
# 1.del - 直接刪除鍵值對
my_dict = {'a': 1, 'b': 2, 'c': 3}
del my_dict['b'] # 刪除鍵'b'對應的鍵值對
print(my_dict) # 輸出: {'a': 1, 'c': 3}
# 注意:鍵不存在會引發KeyError
# del my_dict['x'] # 會報錯 KeyError: 'x'特點:
- 最簡單直接的刪除方式
- 不返回被刪除的值
- 鍵不存在時會引發錯誤# 2. pop() - 刪除并返回值
my_dict = {'a': 1, 'b': 2, 'c': 3}
value = my_dict.pop('b') # 刪除并返回'b'對應的值
print(value) # 輸出: 2
print(my_dict) # 輸出: {'a': 1, 'c': 3}特點:
- 刪除指定鍵并返回對應的值
- 可以設置默認值避免KeyError
- 需要知道確切的鍵名# 3. clear() - 清空字典
my_dict = {'a': 1, 'b': 2, 'c': 3}
my_dict.clear() # 清空字典
print(my_dict) # 輸出: {}- 字典對象仍然存在,只是變為空字典
改:
hero['性別'] = '未知' # 對于一個原來有的鍵進行操作會修改
print(hero)
查:
# 可以利用 in 來判斷元素在不在字典內
# 格式 查找的鍵 in 字典 返回值是布爾類型,可以用int轉換后用變量儲存下來
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
number4 = int('姓名' in hero)
print(number4)# value函數可以輸出字典的所有值
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
print(hero.values())
# 結果為: dict_values(['孫悟空', '男', '戰士', ['八戒', '沙僧', '唐僧']])
# value的作用不光只是顯示,還可以配合in進行邏輯判斷
hero = {'姓名': '孫悟空', '性別': '男', '定位': '戰士', '最佳搭檔': ['八戒', '沙僧', '唐僧']}
print(int('孫尚香' in hero.values())) # 返回值為布爾類型
遍歷:
person={'name':'zxy','age':18,'sex':'男'}
#(1) 遍歷字典的key
# 方法1:直接遍歷字典(默認遍歷鍵)
for key in person:print(key) # 依次輸出:name → age → sex# 方法2:使用keys()方法(更明確)
for key in person.keys():print(key)#(2) 遍歷字典的value
for value in person.values():print(value)#(3) 遍歷字典的key和value
for key, value in person.items():print(f"{key}: {value}") #name: zxy#(4) 遍歷字典的項/元素
# 方法1:直接遍歷字典項(實際就是遍歷鍵值對)
for item in person.items():print(f"字典項: {item}") #字典項: ('name', 'zxy')
字符串的使用
# 單引號,雙引號,三引號三種聲明方式,三引號的優點在于可以原樣輸出,空格空行都會被保留
hero1 = 'hello'
hero2 = "hi"
hero3 = '''hellohi'''
print(hero1, hero2, hero3)
字符串和列表一樣,也有切片和索引的訪問形式
把字符串當成字符的列表

函數怎么用:
text = "Hello World"
print(len(text)) # 輸出: 11text = "Hello World"
print(text.find("World")) # 輸出: 6 (找到的位置)
print(text.find("Python")) # 輸出: -1 (未找到)filename = "document.txt"
print(filename.startswith("doc")) # 輸出: True
print(filename.endswith(".txt")) # 輸出: Truetext = "I like apples"
new_text = text.replace("apples", "bananas")
print(new_text) # 輸出: "I like bananas"data = "apple,banana,orange"
fruits = data.split(",")
print(fruits) # 輸出: ['apple', 'banana', 'orange']text = "Python"
print(text.upper()) # 輸出: "PYTHON"
print(text.lower()) # 輸出: "python"text = " hello "
print(text.strip()) # 輸出: "hello"words = ["Hello", "World", "Python"]
sentence = " ".join(words)
print(sentence) # 輸出: "Hello World Python"
message = '王者榮耀'
print(message[0])
print(message[:2]) # 從初始位置到2這個位置
# 案例 在任意一個輸入字符串中,查找是否有英雄這個子串
string = input('請輸入一個字符串')
lenstr = int(len(string))
for x in range(0, lenstr):if string.find('英雄') >= 0:# find函數可以查找,如果找到顯示第一個字符的位置,如果沒找到會返回-1print('有英雄這個子串')breakelse:if x == lenstr - 1 :print('沒有英雄這個子串')else:continue
print(string.startswith('王者'))
print(string.endswith('王者'))
# startswitch函數可以判斷是否以某某字符或字符串開頭,返回值為布爾類型
# endswitch函數可以判斷是否以某某字符或字符串結尾,返回值為布爾類型
字符串與列表相互轉換方法
一、字符串轉換為列表
- 使用
split()方法按分隔符拆分
text = "apple,banana,orange"
fruit_list = text.split(",") # 按逗號分隔
print(fruit_list) # 輸出: ['apple', 'banana', 'orange']
- 直接使用
list()函數將字符串轉為字符列表
text = "hello"
char_list = list(text)
print(char_list) # 輸出: ['h', 'e', 'l', 'l', 'o']
- 使用列表推導式處理復雜字符串
text = "1,2,3,4,5"
num_list = [int(x) for x in text.split(",")]
print(num_list) # 輸出: [1, 2, 3, 4, 5]
二、列表轉換為字符串
- 使用
join()方法連接列表元素
word_list = ['Hello', 'World', 'Python']
sentence = " ".join(word_list) # 用空格連接
print(sentence) # 輸出: "Hello World Python"
- 使用
str()和字符串方法處理
num_list = [1, 2, 3, 4]
num_str = str(num_list) # 直接轉為字符串表示
print(num_str) # 輸出: "[1, 2, 3, 4]"
- 使用
map()和join()處理非字符串列表
num_list = [1, 2, 3, 4]
num_str = ",".join(map(str, num_list))
print(num_str) # 輸出: "1,2,3,4"
元組
元組的元素不可修改
訪問元組
tuple=(1,2,3,4)
print(tuple[1])
定義只有一個元素的元組,必須在元素后面加個逗號
a=(11,)
第七講 函數
- 函數的作用與定義
# 函數格式(定義)
def sum(num):
# def關鍵字表示定義一個函數 sum是函數名 num是形參可以有多個result = 0for x in range(1, num+1):result += xprint(result)
# 要注意縮進,以及分號的使用
# 函數調用
# 調用格式: 函數名(參數)這里參數是實參
def sum(num):result = 0for x in range(1, num+1):result += xprint(result)
number = 1
sum(number) #函數名調用
案例
定義一個函數來實現用戶的登錄
def login():username = input('輸入用戶名')password = input('輸入密碼')if username == 'admin' and password == '123456':print('登錄成功')else:print('登錄失敗')login()
定義時小括號中的參數,用來接收參數用的,稱為"形參"
調用時小括號中的參數,用來傳遞給函數用的,稱為"實參"
- 函數的參數
# 有參傳參,無參空著,順序一致
def milk_tea(n,kind='波霸奶茶'): # n表示奶茶數量,kind表示奶茶種類# 默認參數一定要在普通參數后,默認參數可以不傳參使用默認值# 可以有很多默認參數但一定要在所有普通參數結束后再寫默認參數for i in range(n):print('正在制作第{}杯奶茶'.format(i+1))print('放入{}的原材料'.format(kind))print('調制奶茶')print('倒入奶茶')print('封口')
milk_tea(5)
milk_tea(1, '珍珠奶茶')
milk_tea(4, '椰果奶茶')
milk_tea(5, '黑糖珍珠奶綠')
關鍵字參數
def milk_tea(n, kind='波霸奶茶',price=15): # n表示奶茶數量,kind表示奶茶種類print('顧客您需要的{},每杯{}元,應收{}元'.format(kind,price,n*price))for i in range(n):print('正在制作第{}杯奶茶'.format(i+1))print('放入{}的原材料'.format(kind))print('調制奶茶')print('倒入奶茶')print('封口')
milk_tea(1)
milk_tea(2, '原味奶茶')
milk_tea(n=4, kind='原味奶茶',price=18) # 關鍵字參數可以自定義傳輸
- 返回值
# 計算從1到num的和
def ger_sum(num):total = 0for i in range(1, num + 1): # 直接從1開始遍歷total += ireturn total
num=5
num1 = int(num)
result = ger_sum(num1)
print('result = {}'.format(result))
關鍵字是return,存在函數中
- 局部變量和全局變量
局部變量:在函數內部定義的變量,稱為局部變量,只能在函數內部使用
全局變量:函數外部定義的
第八講 面向對象基礎
知識講解
一類人或一類車等的定義方法用列表太過復雜,所以抽象出類這一概念
面向過程編程(把大象放進冰箱需要幾步)
- 把冰箱門打開
- 把大象裝進去
- 把冰箱門關上
面向對象編程(大象,冰箱的種類,具象化目標具象化實現)
- 類的定義
# class 類名:
# 屬性
# 方法
要求
-
類的首字母必須大寫
-
類名后面必須有冒號
-
類體有縮進
-
類的方法:類中定義的函數稱為方法
類中的方法定義與函數定義基本相同,區別有:
-
方法中的第一個參數必須是self,而且不能省略
-
方法的調用實例化類,并以“實例名.方法名”形式調用
-
整體進行一個單位的縮進,表示其屬于類中的內容
-
面向對象三大特征:
- 多態:同一個方法調用由于對象不同會產生不同的方法
- 封裝:隱藏對象的屬性和實現細節,只對外提供必要的方法。通過私有屬性,私有方法的方式,實現封裝
- 繼承:繼承可以讓子類具有父類的特性,提高代碼的重用性
代碼示例:
- 類的定義
class Phone:pass
# 在python中 pass是空語句,是為了保持程序結構的完整性。pass不做任何事情,一般用于占位有語句,支撐結構
class Phone:brand = '華為'color = '黑色'type = 'Mate30 pro'price = 9999
# 定義行為和函數相似,只是必須帶上一個參數selfdef call(self):print('打電話')def send_message(self):print('可以發信息')
class Saiya:name = '悟空'hair = '固定'has_tail = Trueappetite = '大'def fight(self):print('我們賽亞人就是喜歡戰爭')
- 類的使用類的定義主要用途是把一個類的所有特征抽象出來,而用到具體對象時則需要講抽象的特征一一賦值一一對應
# 對象名 = 類名(參數),其中參數是可選參數,可有可無
phone1 = Phone()
phone2 = Phone()
phone3 = Phone()
print(phone1)
print(phone2)
print(phone3)
# 訪問方式 對象名.屬性名 or 對象名.方法名
print(phone1.price)
- 屬性添加的方式
# __init__魔術構造方法也就是構造函數,會在開始時自動調用
class Person:country = '中國'def __init__(self,name):
# self表示對象本身,self.name = name表示在當前對象中增加一個屬性并且賦值(在這里也就是Person)print('我是一個__init__方法')self.name =namedef eat(self):print('我是一個吃貨')
p1 = Person('龜龜')
p2 = Person(name = '兔兔')
p1.eat()
p2.eat()
1. 通過外層的對象動態添加
2. 使用構造函數添加
- 類的方法的定義與調用
class Person:name = '悟空'def __init__(self,name):self.name =namedef eat(self):print('我是一個吃貨')def sprot(self, time):if time < 6:print(self.name + '你怎么這么勤快,這么早就起床了')else:print(self.name + '怎么這么愛睡懶覺!')self.eat()
p1 = Person(name = '龜龜')
p2 = Person(name = '兔兔')
p1.sprot(time=3)
p2.sprot(time=7)
- 類的封裝
#前面加雙下劃線"__"使其變成私有
class Dog:#設置私有屬性__legs=4
# 內部設置方法def print_legs_count(self):print(f'狗有{self.__legs}條腿')# 實例化小狗
my_dog=Dog()
my_dog.print_legs_count()
用get/set方法
class Dog:__legs=4def get_legs(self):return self.__legsdef set_legs(self,legs):self.__legs=legsmy_dog=Dog()
print(my_dog.get_legs())
my_dog.set_legs(2)
print(my_dog.get_legs())
- 類的繼承
class Person:def __init__(self, name):self.name = namedef eat(self):print(self.name + '我是一個吃貨')class Saiya(Person): # Saiya 繼承 Persondef sport(self, time):if time < 6:print(self.name + '你怎么這么勤快,這么早就起床了')else:print(self.name + '怎么這么愛睡懶覺!')self.eat() # 調用父類的 eat() 方法# 實例化 Saiya 并測試方法
saiya1 = Saiya("悟空") # 創建對象,自動調用 __init__
saiya1.eat() # 調用繼承自 Person 的方法
saiya1.sport(4) # 調用 Saiya 新增的方法(早睡情況)
saiya1.sport(8) # 調用 Saiya 新增的方法(懶睡情況)
super()實現
class Person:def __init__(self, name):self.name = namedef eat(self):print(self.name + '我是一個吃貨')class Saiya(Person):def __init__(self, name):super().__init__(name) # 調用父類的 __init__def sport(self, time):if time < 6:print(self.name + '你怎么這么勤快,這么早就起床了')else:print(self.name + '怎么這么愛睡懶覺!')super().eat() # 顯式調用父類的 eat()# 測試
saiya1 = Saiya("悟空")
saiya1.eat() # 輸出: 悟空我是一個吃貨
saiya1.sport(4) # 輸出: 悟空你怎么這么勤快... \n 悟空我是一個吃貨
saiya1.sport(8) # 輸出: 悟空怎么這么愛睡懶覺! \n 悟空我是一個吃貨
多繼承語法格式
class A:pass
class B:pass
class C(A,B):pass
class Dog:def __init__(self,name):self.name=namedef show_info(self):print(f'狗的名字叫做{self.name}')def run(self):print('狗跑的很快')
class Husky:def __init__(self,name):self.name=namedef show_info(self):print(f'哈市其的名字叫:{self.name}')def run(self):print("哈士奇跑得快")def sofa(self):print("哈士奇咬沙發")class MyDog(Dog,Husky):def __init__(self,name,age):super().__init__(name)self.age=agedef show_info(self):print(f'MyDog的名字叫:{self.name}')my_dog=MyDog('小嘎',4)
my_dog.run() #輸出狗跑的很快
my_dog.sofa() #輸出哈士奇咬沙發
my_dog.show_info() #輸出:MyDog的名字叫:小嘎
第九講 模塊
- 模塊簡介與導入
#創建一個文件test_module_1.py
#創建一個自定義模塊
#自定義模塊
test_name='自定義模塊test_module_1的變量'
def test_function():print("自定義模塊test_module_1的函數")
編寫主程序
import test_module_1
print(test_module_1.test_name)
test_module_1.test_function()
當導入多個模塊的時候,并且模塊內有同名的功能,這時候調用同名功能用的是后導入的功能查看模塊位置
import sys
print(sys.path)
輸出:
['E:\\python', 'E:\\python', 'D:\\Program Files\\JetBrains\\PyCharm 2023.3.7\\plugins\\python\\helpers\\pycharm_display', 'D:\\Program Files\\Python312\\python312.zip', 'D:\\Program Files\\Python312\\DLLs', 'D:\\Program Files\\Python312\\Lib', 'D:\\Program Files\\Python312', 'C:\\Users\\ASUS\\AppData\\Roaming\\Python\\Python312\\site-packages', 'D:\\Program Files\\Python312\\Lib\\site-packages', 'D:\\Program Files\\JetBrains\\PyCharm 2023.3.7\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
- 自定義包包就是一個文件夾其中必須包含一個__init__.py 的文件。這個可以是一個空文件,僅表示該目錄是個包。包可以嵌套,即把子包放在某個包中包可以看作同一目錄中的模塊在Python中首先需要先使用目錄名,然后使用模塊名導入需要的模塊舉個例子:建包:my_package建完自動生成__init__.py空文件
#在包下創立文件package_module_1.py
def print_info():print("my_package中的模塊1的函數")
#在包下創立文件package_module_2.py
def print_info():print("my_package中的模塊2的函數")
在demo.py調用這兩個模塊:
from my_package import package_module_1,package_module_2
package_module_1.print_info()
package_module_2.print_info()
- 系統內置模塊
- time模塊
- random模塊
- os模塊
# 可以獲取當前的時間戳
import time
t1 = time.time()
print(time.ctime(t1))
# 利用sleep函數進行每隔一秒循環進行一次
import time
for i in range(5):print(i)time.sleep(1)
# datetime
# datetime中封裝了date,time,datetime,timedelta其中timedelta是值時間差
from datetime import *
print(datetime.now())
dt = datetime.now()
dt1 = dt + timedelta(days=-1) # 表示日期-1
print(dt, dt1, sep='\n')
import random
print(random.random()) # 表示從0到1的隨機小書
print(random.randint(1, 10))
# 表示從1到10的隨機整數(包括1和10)
print(random.randrange(1, 10))
# 表示從1到10的隨機整數(不包括10)
print(random.choice(range(10)))
# random.choice(列表或數據集),表示從列表或數據集中隨機獲取一個元素,起到定范圍而又隨機的作用
import os
# 查看當前工作目錄
result1 = os.getcwd()
print(result1)
# 在當前文件夾中創建一個文件夾
# os.mkdir()只能創建一級目錄。而os.makedirs()可以創建多級目錄。
os.mkdir('images')
# 獲取當前環境變量
print(os.environ)
# 獲取絕對路徑
result = os.path.abspath('harry.py')
print(result)
# os.listdir('package')查看文件列表
# os.remove('package/text.py')刪除某個模塊
注意以下操作只能針對同級或下級文件,如harry.py中使用下面代碼則會報錯,一定要在與package同級的.py文件中操作才有用
result = os.listdir('package')
print(result)
os.remove('package/text.py')
# 查看文件大小
path = './package/harry.py' # .表示當前目錄下
result = os.path.getsize(path)
print(result)
# 查看是否為文件
result1 = os.path.isfile('path')
print(result1)
# 查看是否為文件夾
result1 = os.path.isdir('path')
print(result1)
第十講 文件操作和異常處理
文件操作
文件的打開與關閉
打開文件/創建文件
open(文件路徑,訪問模式)
f=open('test.txt','w')

訪問模式:w 可寫 r 可讀

fp=open('test.txt','w')
fp.write('hello world
fp.close()
文件的讀寫
文件的序列化和反序列化
文件的異常處理
# 格式
try:可能會有異常的代碼
except:發生異常的時候要執行的代碼
finally:無論是否有異常都要執行的代碼
# 方法1
content = None
try:stream = open('records.txt', mode='r', encoding='utf-8')content = stream.read()
except:print('文件找不到')
finally:print(content)# 這段代碼邏輯就是,設置變量為空,如果文件可以找到并打開,將改空代碼重新賦值并且輸出,如果文件無法找到并打開,則會輸出except的提示語句,并且輸出空。這樣就可以避免了報錯導致程序異常終止
輸出:
文件找不到
None
# with關鍵字的使用
with 表達式 as 變量:語句
with open('records.txt',mode='r',encoding='utf-8') as stream: content = stream.read() print(content)
第十一講 多任務的介紹
想要實現多個函數同時執行就要使用多任務,充分利用CPU資源
多任務就是電腦同一時間內執行多個任務
兩種表現形式:并發和并行
進程的介紹
進程是資源分配的最小單位,它是操作系統進行資源分配和調度運行的基本單位
說白了:一個正在運行的程序就是進程
def func_a():print("任務A")
def func_b():print("任務B")
func_a()
func_b()
是否可以讓func_a和func_b同時運行呢?用多進程就可以
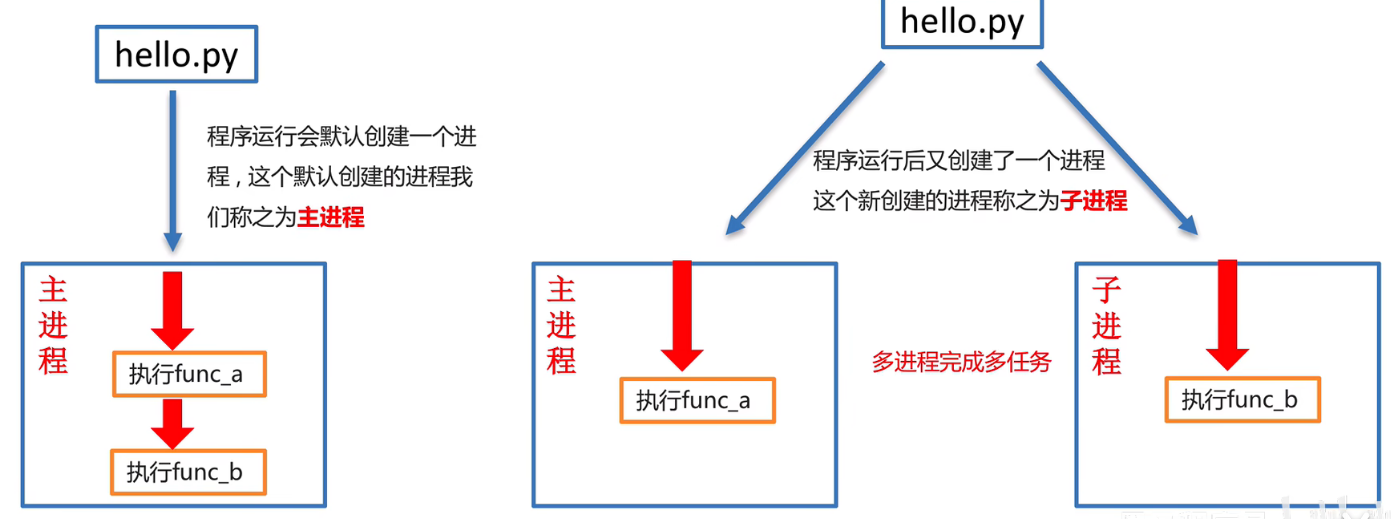
多進程是python實現多任務的一種方式
多進程完成多任務
進程創建步驟
- 導入進程包。import multiprocessing
- 通過進程類創建進程對象。 進程對象=multiprocessing.Process(target=任務名)
- 啟動進程執行任務。 進程對象.start()
注意第二步,括號里面歧視有很多參數
| 參數 | 說明 |
|---|---|
| target | 執行的目標任務名,這里指的是函數名(方法名) |
| name | 進程名,一般不用設置 |
| group | 進程組,目前只能用None |
# 創建子進程
coding_process=multiprocessing.Process(target=coding)
# 創建子進程
music_process=multiprocessing.Process(target=music)
#啟動進程
coding_process.start()
music_process.start()
舉個例子:
單任務
import time
def coding():for i in range(3):print("coding...")time.sleep(0.2)
#聽音樂
def music():for i in range(3):print("music...")time.sleep(0.2)if __name__=='__main__':coding()music()改進成多任務:
import time
import multiprocessingdef coding():for i in range(3):print("coding...")time.sleep(0.2)
#聽音樂
def music():for i in range(3):print("music...")time.sleep(0.2)if __name__=='__main__':# 創建子進程coding_process = multiprocessing.Process(target=coding)# 創建子進程music_process = multiprocessing.Process(target=music)# 啟動進程coding_process.start()music_process.start()
程序運行起來就默認創建一個主進程,兩個子進程是主進程創建的,兩個子進程是2個主進程啟動的
進程執行帶參數的任務
| 參數名 | 說明 |
|---|---|
| args | 以元組的方式給執行任務傳參,一i的那個要和參數的順序保持一致 |
| kwargs | 以字典的方式給執行任務傳參,傳參字典中的key一定要與參數名保持一致 |
args參數的使用
coding_process = multiprocessing.Process(target=coding,args=(3,))
coding_process.start()
kwargs參數的使用
#kwargs:表示以字典的方式給函數傳參
coding_process = multiprocessing.Process(target=coding,kwargs={"num":3})
coding_process.start()
舉個例子:
import time
import multiprocessingdef coding(num,name):for i in range(num):print("coding...")print(name)time.sleep(0.2)
#聽音樂
def music(count):for i in range(count):print("music...")time.sleep(0.2)if __name__=='__main__':# 創建子進程coding_process = multiprocessing.Process(target=coding,args=(3,"zxy"))# 創建子進程music_process = multiprocessing.Process(target=music,kwargs={"count":2})# 啟動進程coding_process.start()music_process.start()獲取進程編號
當程序中的進程越來越多,就無法區分主進程和子進程和不同的子進程。實際上為了方便管理,每個進程都是有自己的編號的,通過獲取編號就可以快速區分不同的進程
- 獲取當前進程編號 getpid()方法
- os.getpid()的使用
import os
def work():#獲取當前進程的編號print("work進程編號:",os.getpid())
- 獲取當前父進程編號 gerppid()方法
- os.getppid()的使用
if __name__=='__main__':#獲取主進程print("主進程>>>%d"%os.getppid())# 創建子進程coding_process = multiprocessing.Process(target=coding)# 創建子進程music_process = multiprocessing.Process(target=music)# 啟動進程coding_process.start()music_process.start()
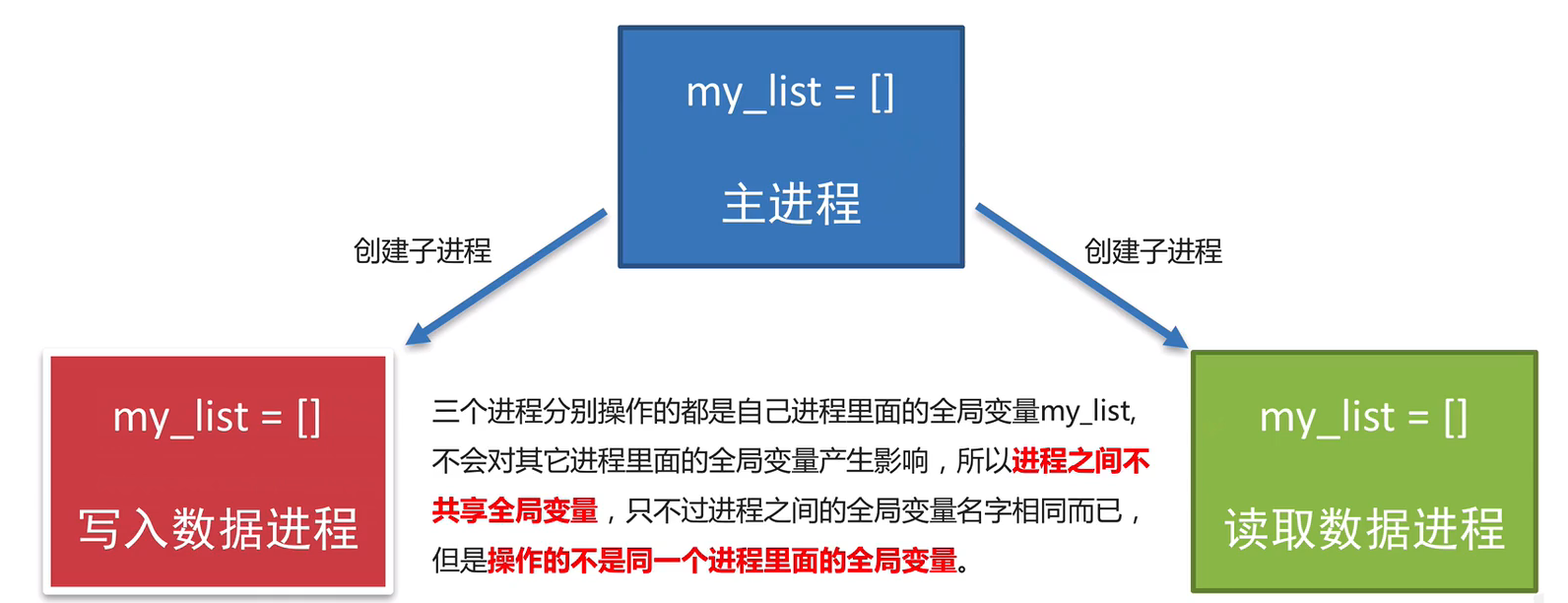
進程間不共享全局變量
進程間是不共享全局變量的
實際上創建一個子進程就是把主進程的資源進行拷貝產生了一個新的進程,這里主進程和子進程是相互獨立的
也就是說操作的不是一個進程里面的全局變量,只不過是不同進程里面的全局變量名字相同而已
驗證:
#定義全局變量
import multiprocessingmy_list=[]#寫入數據函數
def write_data():for i in range(3):my_list.append(i)print("add:",i)print(my_list)#讀取數據函數
def read_data():print(my_list)if __name__=='__main__':# 創建寫入數據的進程write_process=multiprocessing.Process(target=write_data)#創建讀取數據進程read_process = multiprocessing.Process(target=read_data)write_process.start()read_process.start()
運行結果:
add: 0
add: 1
add: 2
[0, 1, 2]
[]
主進程和子進程的結束順序
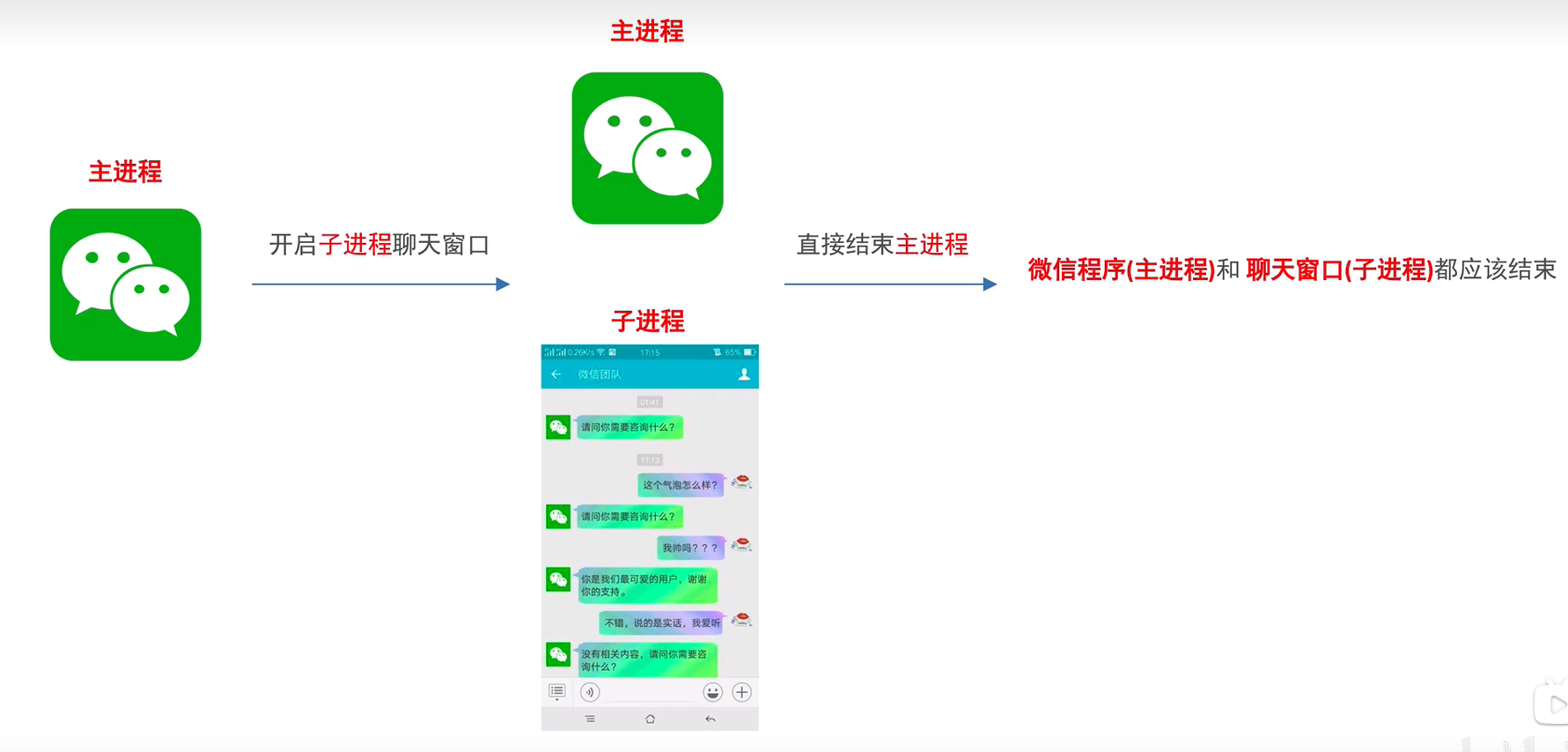
主進程會等待所有的子進程執行結束再結束
import multiprocessing
import time
#工作函數
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#創建子進程work_process=multiprocessing.Process(target=work)#啟動子進程work_process.start()#延時一秒time.sleep(1)print("主程序執行完畢")
結果:
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
主程序執行完畢
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
如何保證主進程銷毀之后子進程也直接銷毀?
設置守護主進程 : 主進程.daemon=True
import multiprocessing
import time
#工作函數
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#創建子進程work_process=multiprocessing.Process(target=work)#設置守護主進程,主進程退出后子進程直接銷毀,不再執行子進程中的代碼work_process.daemon=True#啟動子進程work_process.start()#延時一秒time.sleep(1)print("主程序執行完畢")
輸出:
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
主程序執行完畢
另外一種方式:手動銷毀子進程 子進程.terminate()
import multiprocessing
import time
#工作函數
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#創建子進程work_process=multiprocessing.Process(target=work)#啟動子進程work_process.start()#延時一秒time.sleep(1)#讓子進程直接銷毀,表示終止運行,主進程退出之前,把所有的子進程直接銷毀就可以了work_process.terminate()print("主程序執行完畢")
第十二講 網絡
網絡是將具有獨立功能的多臺計算機通過通信線路和通信設備連接起來,在網絡管理軟件及網絡通信協議下,實現資源共享和信息傳遞的虛擬平臺
學習網絡的目的是編寫基于網絡通信的軟件或程序,通常來說就是網絡編程
IP地址介紹
IP地址是分配給網絡設備上網使用的數字標簽,它能夠標識網絡中唯一的一臺設備
IP地址分為兩類:IPv4(目前使用的)和IPv6
ifconfig和ping命令
ifconfig:查看網卡信息
127.0.0.1代表本機(也稱localhost)
ping:檢查網絡是否正常
ping 本機通了說明本機網絡沒問題
端口和端口號
每個運行的程序都有一個端口,想要給對應程序發送數據,找到對應的端口即可
端口就是傳輸數據的通道,想要找到端口找到端口號即可
端口號就是一個數字
端口號有65536個
用IP地址找到對應的設備,通過端口號找到對應的端口,然后通過端口把數據給應用程序
端口號可分為:知名端口號(0到1023,這些端口號通常分配給一些固定的任務,比如21端口分配給FTP服務,25端口分配給SMTP服務,80端口分配給HTTP服務)和動態端口號(1024到65536,開發過程若為指定則操作系統在這個范圍內隨機生成一個給開發的應用程序使用)
socket分類
socket(套接字)是程序之間網絡通信的一個工具,好比知道對方的電話號碼才能給對方打電話,程序之間想要進行通信需要基于這個socket
程序之間網絡數據的傳輸可以通過socket來完成
TCP
數據不能亂發送,發送之前要選擇網絡傳輸方式(傳輸協議),保證程序之間按照指定的傳輸規則進行數據的通信
TCP簡稱傳輸控制協議,面向連接的,可靠的,基于字節流的傳輸層通信協議
通信步驟:創建連接,傳輸數據,關閉連接。


python3編碼轉換
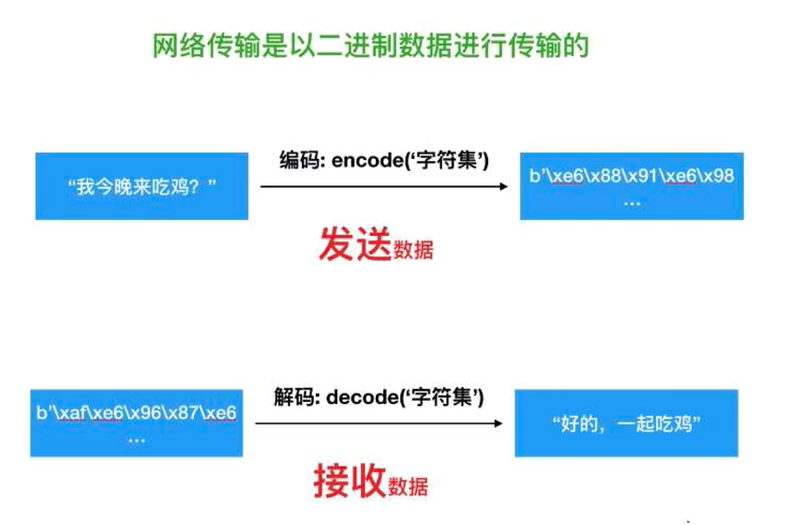
數據轉化用到了:
| 函數名 | 說明 |
|---|---|
| encode | 編碼 將字符串轉換為字節碼 |
| decode | 解碼 將字節碼轉化為字符串 |
encode()和decode()函數可以接受參數,encoding是指在編解碼過程中使用的編碼方案
bytes.decode(encoding=“utf-8”)
str.encode(encoding=“utf-8”)
TCP客戶端程序開發
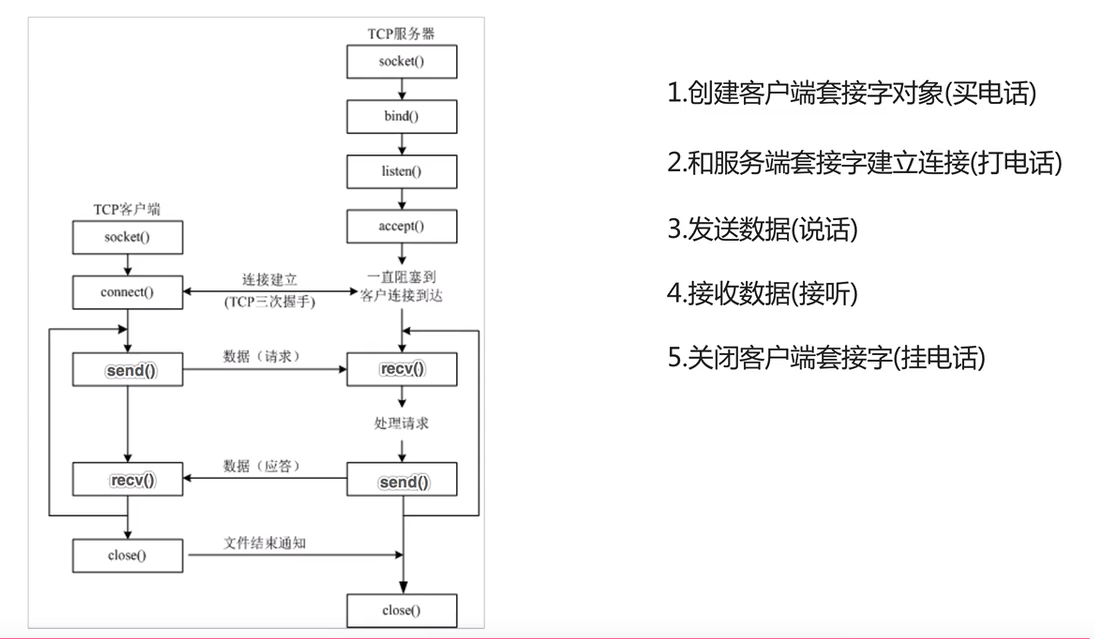
主動發起建立連接請求的是客戶端程序
等待接受連接請求的是服務端程序
客戶端socket類的參數和方法說明:
| 參數名 | 說明 |
|---|---|
| AddressFamily | IP地址類型,分為IPv4(AF_INET)和IPv6 |
| Type | 傳輸協議類型(SOCK_STREAM) |
要用到的函數
| 方法名 | 說明 |
|---|---|
| connect | 和服務端套接字建立連接 |
| send | 發送數據 |
| recv | 接收數據 |
| close | 關閉連接 |
# 模板
# 導入socket模塊
import socket
#創建客戶端socket對象使用socket類
socket.socket(AddressFamily,Type)
舉個例子:
客戶端:client.py
import socketif __name__ == '__main__':try:# 1. 創建 sockettcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2. 連接 Node.js 服務器tcp_client_socket.connect(("127.0.0.1", 8080)) # 確保端口一致# 3. 發送數據tcp_client_socket.send("Hello Node.js Server!".encode("utf-8"))# 4. 接收服務器回復,,rece阻塞等待數據的到來recv_data = tcp_client_socket.recv(1024)print("服務器回復:", recv_data.decode("utf-8"))# 5. 關閉連接tcp_client_socket.close()except Exception as e:print("發生錯誤:", e)
服務端 server.js
const net = require('net');// 創建 TCP 服務器
const server = net.createServer((socket) => {console.log(`客戶端已連接: ${socket.remoteAddress}:${socket.remotePort}`);// 接收客戶端數據socket.on('data', (data) => {console.log(`收到客戶端消息: ${data.toString()}`);socket.write("你好,我是Node.js服務器!"); // 回復客戶端});// 客戶端斷開連接socket.on('end', () => {console.log('客戶端已斷開連接');});
});// 監聽 8080 端口
server.listen(8080, '0.0.0.0', () => {console.log('服務器已啟動,等待客戶端連接...');
});
先運行服務端再運行客戶端
TCP服務端程序開發
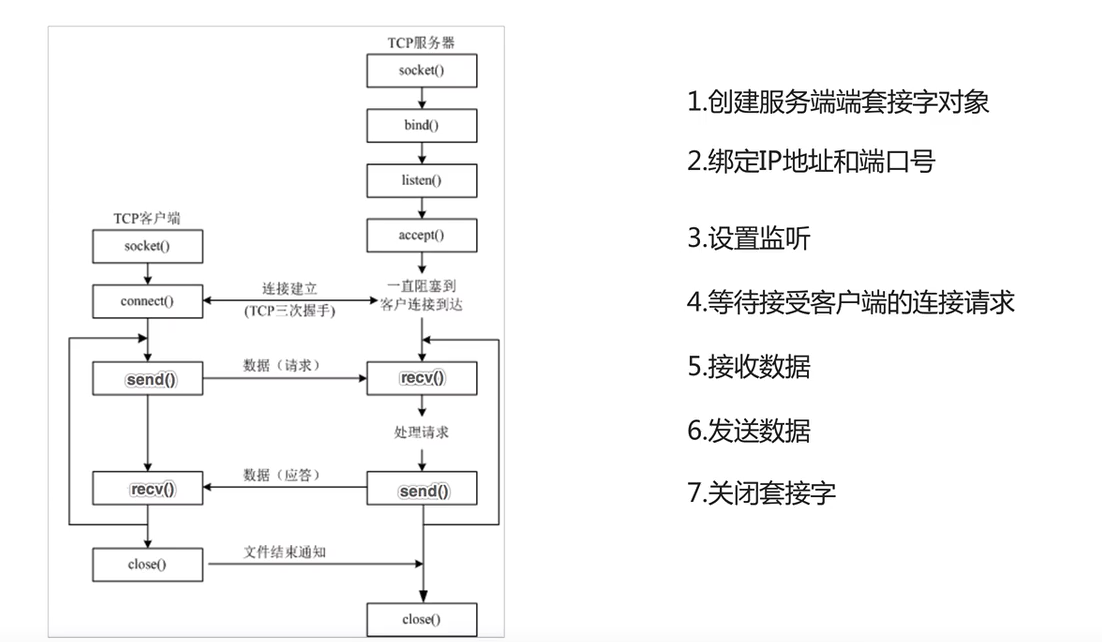
TCP服務端程序開發相關函數:
| 方法名 | 說明 |
|---|---|
| bind | 綁定IP地址和端口號,參數1:元組,如:(’ ',端口號),元組里面第一個元素是IP地址,一般不需要設置。第二個元素是啟動程序后使用的端口號 |
| listen | 設置監聽,參數1:最大等待連接數 |
| accept | 等待接收客戶端的連接請求 |
| send | 發送數據,參數1:要發送的二進制數據,注意:字符串要用encode()方法進行編碼 |
| recv | 接收數據,參數1:表示每次接收數據的大小,單位是字節,注意:解碼成字符串使用decode()方法 |
舉個例子:
服務端 server.py
import socket
if __name__=='__main__':# 創建服務端套接字對象。tcp_server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)# 綁定IP地址和端口號#如果bind中的第一個參數IP地址元素設置為"",默認為本機IP地址tcp_server_socket.bind(("",8080))# 設置監聽128:代表服務端等待連接排隊的最大數量tcp_server_socket.listen(128)# 等待接受客戶端的連接請求 accept阻塞等待conn_socket,ip_port=tcp_server_socket.accept()print("客戶端地址:",ip_port)# 接收數據recv_data=conn_socket.recv(1024)print("接收到的數據是:",recv_data.decode())# 發送數據conn_socket.send("客戶端你的數據我收到了".encode())# 關閉套接字conn_socket.close()tcp_server_socket.close()# 輸出:
# 客戶端地址: ('127.0.0.1', 57402)
# 接收到的數據是: 你好,服務端!
客戶端 client.py
import socketif __name__ == '__main__':try:# 1. 創建客戶端套接字(IPv4, TCP)tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2. 連接服務端(假設服務端運行在本機 8080 端口)server_ip = "127.0.0.1" # 本機回環地址server_port = 8080tcp_client_socket.connect((server_ip, server_port))print("已連接到服務端...")# 3. 發送數據到服務端send_data = "你好,服務端!".encode("utf-8") # 編碼為字節流tcp_client_socket.send(send_data)print(f"已發送數據: {send_data.decode('utf-8')}")# 4. 接收服務端的回復recv_data = tcp_client_socket.recv(1024) # 最大接收 1024 字節print(f"服務端回復: {recv_data.decode('utf-8')}")except ConnectionRefusedError:print("連接被拒絕,請檢查服務端是否啟動!")except Exception as e:print(f"發生錯誤: {e}")finally:# 5. 關閉套接字tcp_client_socket.close()print("客戶端已關閉")# 輸出:
# 已連接到服務端...
# 已發送數據: 你好,服務端!
# 服務端回復: 客戶端你的數據我收到了
# 客戶端已關閉
注意的點:

socket之send和recv原理剖析
當創建一個TCP socket對象的時候會有一個發送緩沖區和接收緩沖區,這個發送和接收緩沖區指的就是內存中的一片空間
send原理剖析:
send想發送數據,必須得通過網卡發送數據,應用程序是無法直接通過網卡發送數據的,它需要調用操作系統接口,也就是說,應用程序把發送的數據先寫入到發送緩沖區(內存中的一片空間),再由操作系統控制網卡把發送緩沖區的數據發送給服務端網卡
rece原理剖析:
應用程序是無法直接通過網卡接收數據的,它需要調用操作系統接口,由操作系統通過網卡接收數據,把接收的數據寫入到接收緩沖區(內存中的一片空間),應用程序再從接收緩沖區獲取客戶端發送的數據
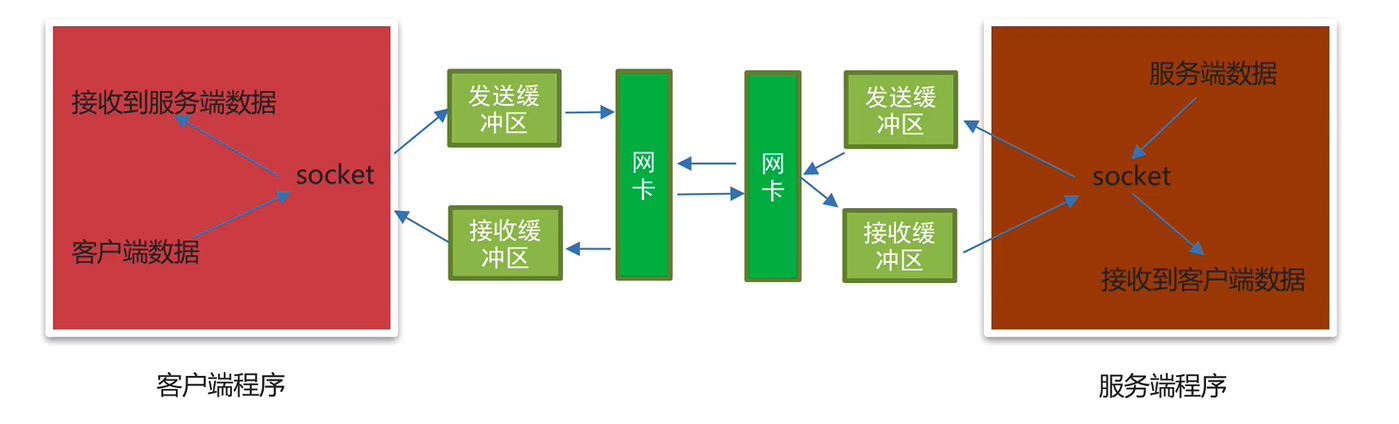



)














事件系統)
)