1.文本預處理
????????分詞,詞性標注,命名實體識別
1.1分詞:jieba
jieba.lcut(content,cut_all=true) 全模式
jieba.lcut(content,cut_all=false) 精確模式
jieba.lcut_for_search(content)?搜索引擎模式
lcut和cut的區別:cut返回的是一個生成器Generator,lcut返回的是列表
生成器調用的幾種方式
變量=next(generater) 第n次調用取第n個生成器的值,可以多次調用或者循環調用
for i in generater i就是每次生成器生成的值
變量= generater.send(value) value傳給生成器,生成器傳值出來
變量= list(generater) 將生成器所有的數據轉換成列表
1.2詞性標注 詞性:語言中對詞的一種分類方法
使用jieba.posseg ss pseg
pseg.lcut(content)
1.3命名實體識別
????????命名實體: 通常我們將人名, 地名, 機構名等專有名詞統稱命名實體. 如: 周杰倫, 黑山縣, 孔子學院, 24輥方鋼矯直機.
? ? ? ? 一般使用訓練好的模型來進行命名實體識別
在遷移學習中使用模型:chinese_pretrain_mrc_roberta_wwm_ext_large
1.4文本的張量表示方法:one-hot,word2vec:cbow,skipgram,word-embedding
????????one-hot又稱獨熱編碼,將每個詞表示成具有n個元素的向量,這個詞向量中只有一個元素是1,其他元素都是0,不同詞匯元素為0的位置不同,其中n的大小是整個語料中不同詞匯的總數.
????????實現簡單但完全割裂了詞語詞之間的關系
????????word2vec::構建神經網絡模型, 將網絡參數作為詞匯的向量表示
????????捕捉詞語之間的語義和語法關系,但無法處理多義詞切忽略詞序,同時依賴大數據
????????cbow 上下文預測中間
????????skipgram 中間預測上下文
????????使用fasttext工具訓練詞向量
????????word embedding:通過一定方式將詞匯映射到指定維度
????????torch.nn.Embedding(vocab_size, embedding_dim=8) 傳入的時候索引不能大于vocab_size不然會索引越界報錯
文本數據分析:標簽數量分布,句子長度分布,詞頻統計,關鍵詞詞云
? ? ? ? 詞云模組: from wordcloud import WordCloud
? ? ? ? 詞性識別?import jieba.posseg as pseg
文本特征處理:n-gram,文本長度規范
? ? ? ? n-gram?set(zip(*[input_list[i:] for i in range(ngram_range)]))
? ? ? ? zip作用是把多個可迭代對象打包
a = [1, 2, 3]
b = ['a', 'b', 'c']
print(list(zip(a, b))) ?# 輸出: [(1, 'a'), (2, 'b'), (3, 'c')][1,3,5](@ref)
? ? ? ? 文本長度規范
? ? ? ? 一般使用padding進行補齊,截斷的方式可以采用切片
????????隨機森林的截斷方式 df_data['text'].apply(lambda x: " ".join(jieba.lcut(x)[:30]))
????????bert的補齊與截斷
????????text_tokens = conf.tokenizer.batch_encode_plus(texts,add_special_tokens=True,padding='max_length', #補齊max_length=conf.pad_size,truncation=True, #截斷return_attention_mask=True)
文本數據增強:回譯數據增強(寫論文)
? ? ? ? 翻譯成另一種語言在翻譯回來,或者a-b-c-d-a
RNN及其變體
傳統rnn模型:優勢簡單:劣勢 梯度更新序列太長容易消失(梯度無法更新訓練失敗)或者爆炸(溢出nan)
????????把當前步的輸入x(t)和上一步的輸出h(t-1)拼起來經過一個全連接層使用tanh作為激活函數得到下一步時間步ht(t)與下一個時間步輸入x(t+1)重復這個過程
? ? ? ? 如果是x是第一個則拼接的是初始化的隱藏層h0
? ? ? ? 最終輸出
????????output 包含所有隱藏輸出h0-hn????????
? ? ? ? hn (能代表這個語句)
? ? ? ? 隱藏層創建rnn = nn.RNN(input_size, hidden_size, num_layer)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?x的維度? ?隱藏層輸出維度 隱藏層層數
????????????????
lstm
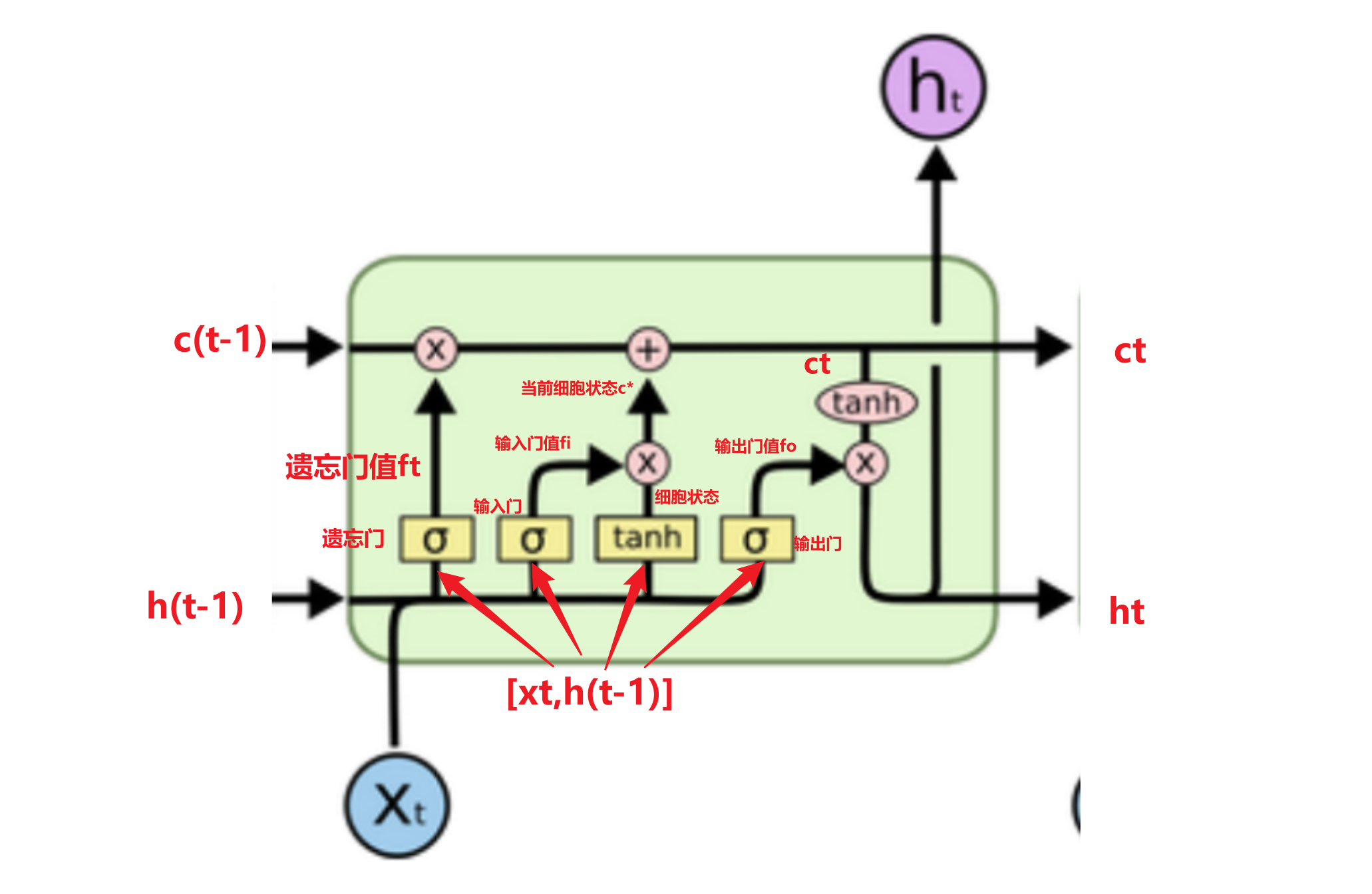
gru
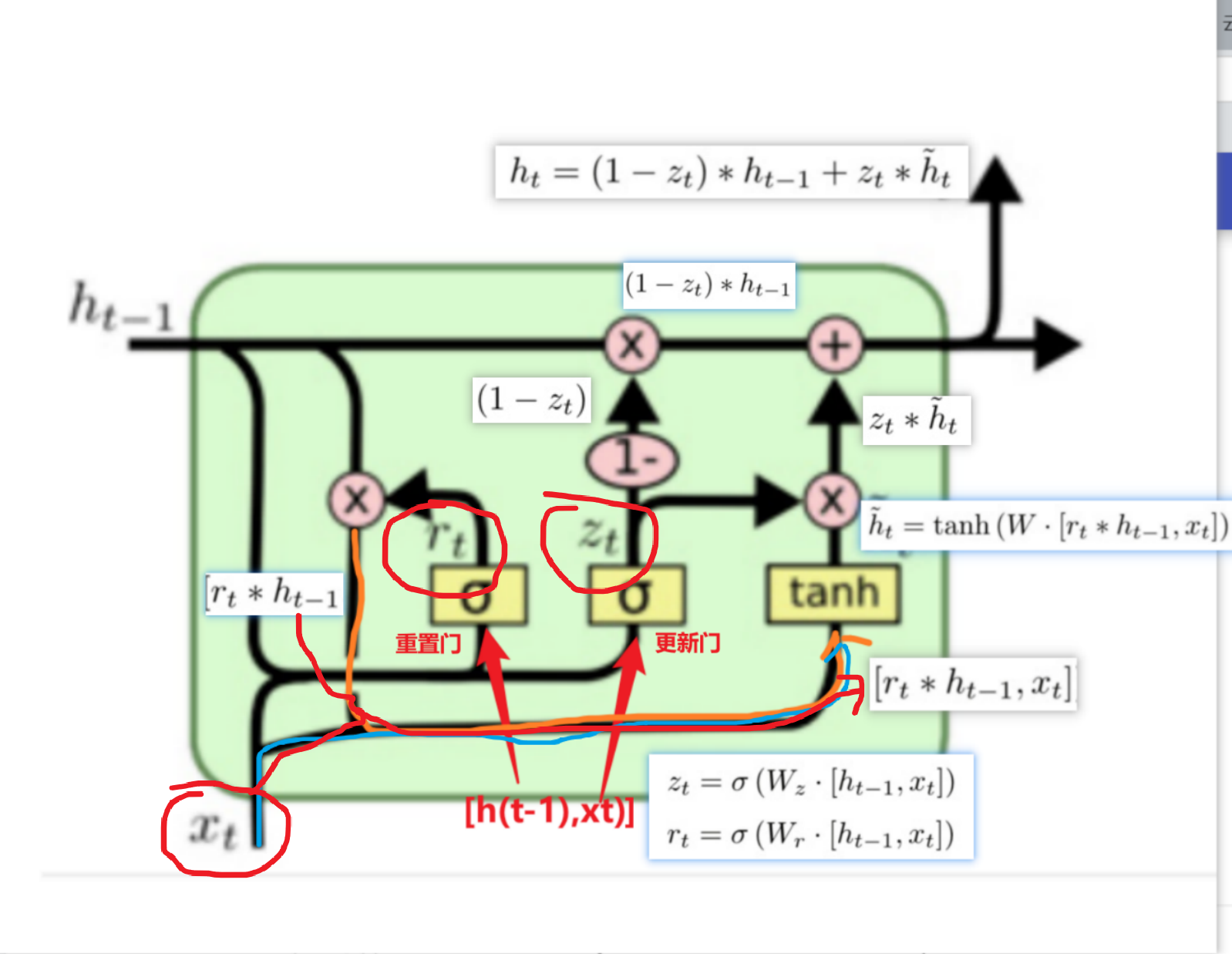
?GRU和LSTM作用相同, 在捕捉長序列語義關聯時, 能有效抑制梯度消失或爆炸, 效果都優于傳統RNN且計算復雜度相比LSTM要小.
注意力機制
引入Attention的原因1:長距離的信息會被弱化,就好像記憶能力弱的人,記不住過去的事情是一樣的。原因2 :好使
深度學習中的注意力機制通常可分為三類: 軟注意(全局注意)、硬注意(局部注意)和自注意(內注意)
- 軟注意機制(Soft/Global Attention: 對每個輸入項的分配的權重為0-1之間,也就是某些部分關注的多一點,某些部分關注的少一點,因為對大部分信息都有考慮,但考慮程度不一樣,所以相對來說計算量比較大。
- 硬注意機制(Hard/Local Attention,[了解即可]): 對每個輸入項分配的權重非0即1,和軟注意不同,硬注意機制只考慮那部分需要關注,哪部分不關注,也就是直接舍棄掉一些不相關項。優勢在于可以減少一定的時間和計算成本,但有可能丟失掉一些本應該注意的信息。
- 自注意力機制( Self/Intra Attention): 對每個輸入項分配的權重取決于輸入項之間的相互作用,即通過輸入項內部的"表決"來決定應該關注哪些輸入項。和前兩種相比,在處理很長的輸入時,具有并行計算的優勢。
注意力計算規則:
* 它需要三個指定的輸入Q(query), K(key), V(value), 然后通過計算公式得到注意力的結果, 這個結果代表query在key和value作用下的注意力表示. 當輸入的Q=K=V時, 稱作自注意力計算規則.

注意力機制的作用?
- 在解碼器端的注意力機制: 能夠根據模型目標有效的聚焦編碼器的輸出結果, 當其作為解碼器的輸入時提升效果. 改善以往編碼器輸出是單一定長張量, 無法存儲過多信息的情況.
- 在編碼器端的注意力機制: 主要解決表征問題, 相當于特征提取過程, 得到輸入的注意力表示. 一般使用自注意力(self-attention).
transformer
核心架構
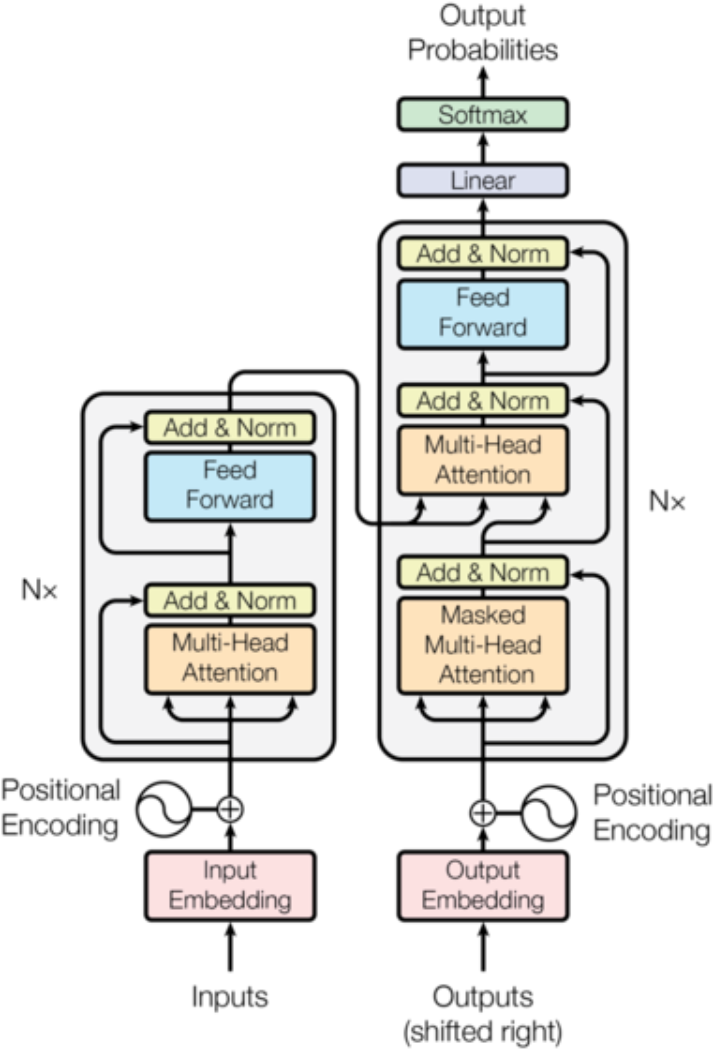
?輸入部分構成:input(output)embedding+position encoding
? ? ? ? embedding作用是將文本中詞匯的數量表示轉換為更高維度的向量表示
? ? ? ? position encoding的作用將詞匯位置不同可能會產生不同語義的信息加入到詞嵌入張量中, 以彌補位置信息的缺失.
為什么embedding之后要乘以根號下d_model
原因1:為了防止position encoding的信息覆蓋我們的word embedding,所以進行一個數值增大
原因2:符合標準正態分布
位置編碼器實現方式:三角函數來實現的,sin\cos函數
為什么使用三角函數來進行位置編碼:
保證同一詞匯隨著所在位置不同它對應位置嵌入向量會發生變化
正弦波和余弦波的值域范圍都是1到-1這又很好的控制了嵌入數值的大小, 有助于梯度的快速計算
三角函數能夠很好的表達相對位置信息
編碼器部分
1、N個編碼器層堆疊而成
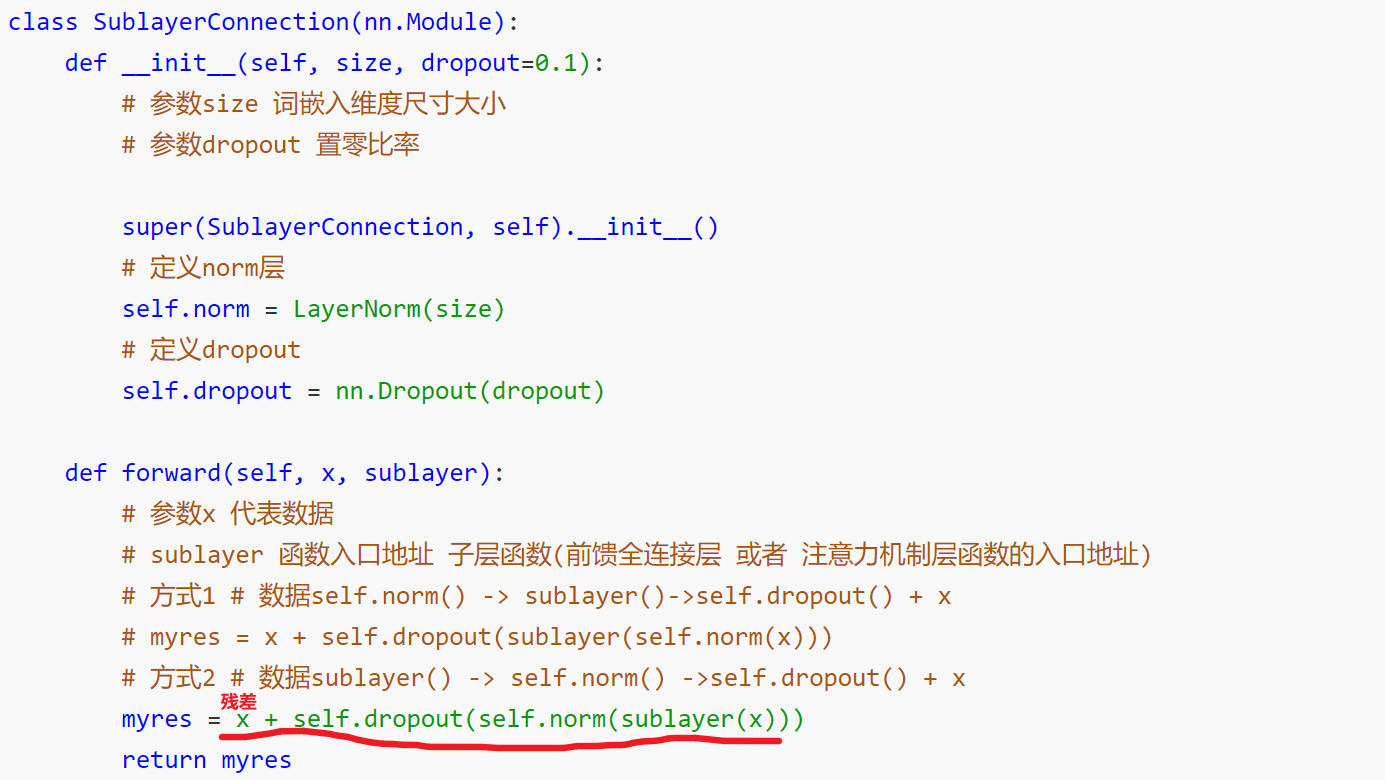
2、每個編碼器有兩個子層連接結構構成
3、第一個子層連接結構:多頭自注意力層+規范化層+殘差連接層
4、第二個子層連接結構:前饋全連接層+規范化層+殘差連接層
????????掩碼:掩就是遮掩、碼就是張量。掩碼本身需要一個掩碼張量,掩碼張量的作用是對另一個張量進行數據信息的掩蓋。一般掩碼張量是由0和1兩種數字組成,至于是0對應位置或是1對應位置進行掩碼,可以自己設定
????????掩碼分類:
????????PADDING MASK: 句子補齊的PAD,去除影響 ,位置:編碼器的自注意力層(Self-Attention),編碼器-解碼器注意力層
????????SETENCES MASK:防止未來信息被提前利用,位于解碼器的自注意力層
多頭自注意力機制
????????將模型分為多個頭, 可以形成多個子空間, 讓模型去關注不同方面的信息, 最后再將各個方面的信息綜合起來得到更好的效果.
? ? ? ? 在模擬transformer中qkv分別經過一個線性層
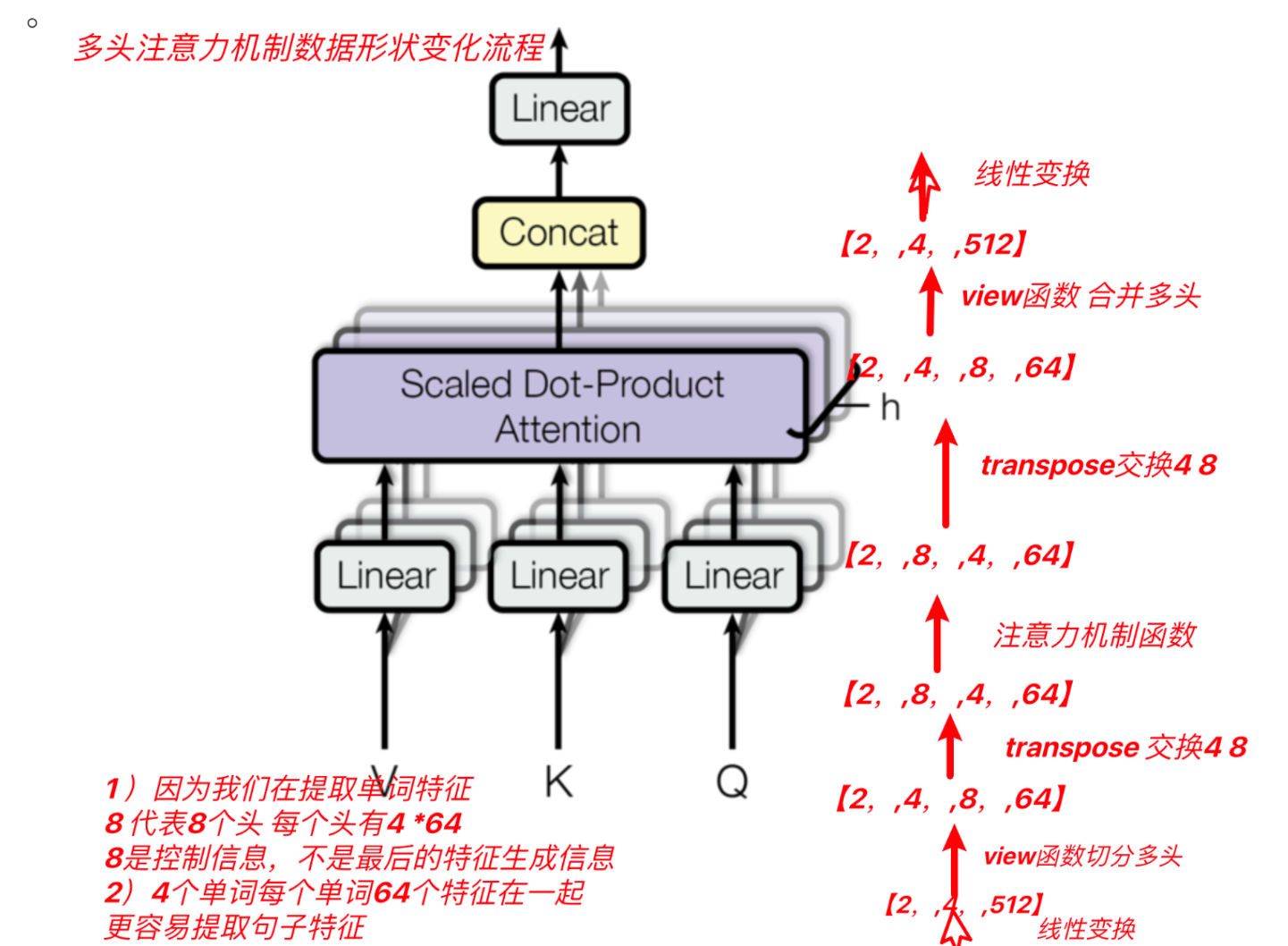
前饋全連接層:作用:增強模型的擬合能力(兩個線性層)
規范化層:作用:隨著網絡深度的增加,模型參數會出現過大或過小的情況,進而可能影響模型的收斂,因此進行規范化,將參數規范致某個特征范圍內,輔助模型快速收斂。
殘差鏈接:作用:引入加法防止梯度消失
?解碼器部分
1、N個解碼器堆疊而成
2、每個解碼器有三個子層連接結構構成
3、第一個子層連接結構:多頭自注意力層+規范化層+殘差連接層
SETENCES MASK:解碼器端,防止未來信息被提前利用
4、第二個子層連接結構:多頭注意力層+規范化層+殘差連接層
這里的Q查詢張量是上一個子層輸入,K和V是編碼器的輸出
5、第三個子層連接結構:前饋全連接層+規范化層+殘差連接層
輸出部分:作用:通過線性變化得到指定維度的輸出
遷移學習
預訓練模型:
????????定義: 簡單來說別人訓練好的模型。一般預訓練模型具備復雜的網絡模型結構;一般是在大量的語料下訓練完成的????????
預訓練模型的分類:
自回歸語言模型Auto Regressive Language Model AR)(做文本語言生成)
概念:根據上文內容預測下一個可能的單詞
優點:從左向右的處理文本,天然文本生成
缺點:只能利用上文或者下文的信息,不能同時利用上文和下文的信息
代表模型:GPT、GPT2、Transformer-XL、XLNET
自編碼語言模型(Auto Encoder Language Model AE)(適合做語言理解)
概念:對輸入的句子隨機Mask其中的單詞,根據上下文單詞來預測這些被Mask掉的單詞
優點:融入雙向語言模型,同時看到被預測單詞的上文和下文
缺點:訓練時使用[Mask]標記,導致預訓練階段和Fine-tuning階段不一致的問題
代表模型:BERT、ALBERT、RoBERTa、ELECTRA
遷移學習的兩種方式
????????開箱即用: 當預訓練模型的任務和我們要做的任務相似時,可以直接使用預訓練模型來解決對應的任務
????????微調: 進行垂直領域數據的微調,一般在預訓練網絡模型后,加入自定義網絡,自定義網絡模型的參數需要訓練,但是預訓練模型的參數可以全部微調或者部分微調或者不微調。????????
fasttext
作為NLP工程領域常用的工具包, fasttext有兩大作用:
- 進行文本分類
- 訓練詞向量
Fasttext模型架構
- FastText 模型架構和 Word2Vec 中的 CBOW 模型很類似, 不同之處在于, FastText 預測標簽, 而 CBOW 模型預測中間詞.
- FastText的模型分為三層架構:
- 輸入層: 是對文檔embedding之后的向量, 包含N-gram特征
- 隱藏層: 是對輸入數據的求和平均
- 輸出層: 是文檔對應的label
fasttext的數據要求:
__label__fish arctic char available in north-america
?模型調優的手段:
原始數據處理:
數據處理后進行訓練并測試:
增加訓練輪數:
調整學習率:
增加n-gram特征:
修改損失計算方式:
自動超參數調優:
模型的保存與加載
????????# 使用model的save_model方法保存模型到指定目錄
????????# 你可以在指定目錄下找到model_cooking.bin文件 >>>
model.save_model("data/model/model_cooking.bin")
????????# 使用fasttext的load_model進行模型的重加載 >>>
model = fasttext.load_model("data/model/model_cooking.bin")
常見的預訓練模型
Bert

GPT
 ?
?
)








)




![Nacos中feign.FeignException$BadGateway: [502 Bad Gateway]](http://pic.xiahunao.cn/Nacos中feign.FeignException$BadGateway: [502 Bad Gateway])



 ---驅動與內核交互)
)