前言
博主因為這個數據集踩了好多坑,浪費了好幾天時間,最近終于找到了高效的辦法,寫此篇文章來記錄具體操作方法,也希望可以幫助到有需要的人。(主要是在云服務器是使用)
下載數據集
一共下載三個文件,力求高效,也不要糾結在官網下載了(官網需要學校郵箱),下載的文件和官網一樣的。
在Linux上直接用命令行進行下載:
1.訓練集(ILSVRC2012_img_train.tar):【費時3h+】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar --no-check-certificate
2.驗證集(ILSVRC2012_img_val.tar):【費時40min+】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar --no-check-certificate
3.標簽映射文件(ILSVRC2012_devkit_t12.tar.gz):【費時幾秒】
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_devkit_t12.tar.gz --no-check-certificate
下載好后是這樣的

解壓數據集
1.在當前目錄下執行命令,解壓ILSVRC2012_devkit_t12.tar.gz這個文件:
tar -xzf ILSVRC2012_devkit_t12.tar.gz
會得到文件夾ILSVRC2012_devkit_t12,該文件中記錄著驗證集中的圖像名及其類別標簽之間的映射關系。
2.在當前目錄下創建val文件夾,使用命令解壓。執行命令,將驗證集圖像解壓到 val 目錄下:
tar xvf ILSVRC2012_img_val.tar -C ./val
此時 val 目錄下是50000張圖像,并沒有被分類到1000個文件夾下。因此需要將驗證集中的圖像進行分類存放。【稍后會講怎么操作】
3.在當前目錄下創建img文件夾,存ILSVRC2012_img_train.tar解壓后的1000個.tar文件。執行命令,將訓練集解壓到文件夾 img目錄下:
tar xvf ILSVRC2012_img_train.tar -C ./img
用腳本檢查是不是有1000個.tar文件,執行腳本代碼如下【將代碼保存為.py文件】(可選)
import osdef count_tar_files():count = 0for root, dirs, files in os.walk('.'):for file in files:if file.endswith('.tar'):count += 1return countif __name__ == "__main__":tar_file_count = count_tar_files()print(f"當前目錄及其子目錄下共有 {tar_file_count} 個.tar 文件。")在當前目錄下創建train文件夾,存1000個.tar文件解壓后的圖片。
執行腳本代碼如下【將代碼保存為.py文件】
import os
import tarfile
from pathlib import Pathdef batch_extract_tar():"""批量解壓目錄下的所有.tar文件解壓后的文件將保存到知道目錄中"""# 指定絕對路徑【換成你自己的】source_dir = "/root/lanyun-tmp/img"target_dir = "/root/lanyun-tmp/train"# 驗證源目錄是否存在source_path = Path(source_dir)if not source_path.exists() or not source_path.is_dir():print(f"錯誤: 源目錄 '{source_dir}' 不存在或不是目錄")return# 創建目標目錄(如果不存在)target_path = Path(target_dir)target_path.mkdir(parents=True, exist_ok=True)# 統計解壓的文件數量extracted_count = 0failed_count = 0# 直接遍歷源目錄中的所有文件for item in source_path.iterdir():if item.is_file() and item.suffix.lower() == '.tar':try:print(f"正在解壓: {item}")# 獲取tar文件名(不含擴展名),用于創建子目錄tar_name = item.stem # 例如:n01440764.tar → n01440764target_subdir = target_path / tar_nametarget_subdir.mkdir(exist_ok=True)# 打開tar文件并解壓到目標子目錄with tarfile.open(item, 'r') as tar:tar.extractall(path=target_subdir)print(f"成功解壓到: {target_subdir}")extracted_count += 1except Exception as e:print(f"錯誤: 解壓文件 '{item}' 失敗: {e}")failed_count += 1print(f"解壓完成: 成功 {extracted_count} 個,失敗 {failed_count} 個")if __name__ == "__main__":# 直接調用函數,無需解析命令行參數batch_extract_tar()
處理val文件夾
解壓后的val文件夾是全部圖片在一個文件夾,需要把他們按類別分開,分類后是和訓練集train一樣的顯示格式,1000個文件夾的名字和順序都是完全一致的。
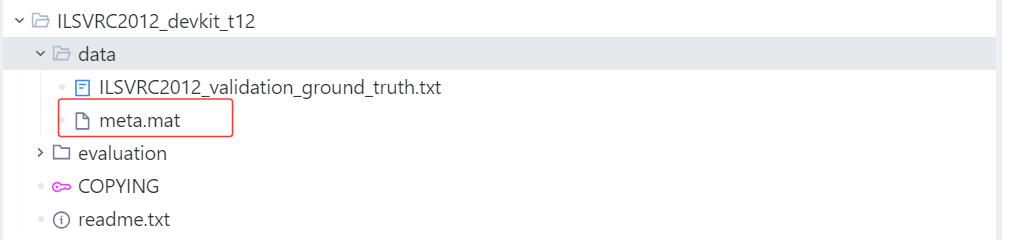
具體是需要用到文件夾ILSVRC2012_devkit_t12下的文件
先執行命令安裝scipy包
pip install scipy # 用于解析 .mat 文件
執行腳本代碼如下【將代碼保存為.py文件】
from scipy import io
import os
import shutildef move_valimg(val_dir='./val', devkit_dir='./ILSVRC2012_devkit_t12'):"""move valimg to correspongding folders.val_id(start from 1) -> ILSVRC_ID(start from 1) -> WINDorganize like:/val/n01440764images/n01443537images....."""# load synset, val ground truth and val images listsynset = io.loadmat(os.path.join(devkit_dir, 'data', 'meta.mat'))ground_truth = open(os.path.join(devkit_dir, 'data', 'ILSVRC2012_validation_ground_truth.txt'))lines = ground_truth.readlines()labels = [int(line[:-1]) for line in lines]root, _, filenames = next(os.walk(val_dir))for filename in filenames:# val image name -> ILSVRC ID -> WINDval_id = int(filename.split('.')[0].split('_')[-1])ILSVRC_ID = labels[val_id-1]WIND = synset['synsets'][ILSVRC_ID-1][0][1][0]print("val_id:%d, ILSVRC_ID:%d, WIND:%s" % (val_id, ILSVRC_ID, WIND))# move val imagesoutput_dir = os.path.join(root, WIND)if os.path.isdir(output_dir):passelse:os.mkdir(output_dir)shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))if __name__ == '__main__':move_valimg()
到此,恭喜你已經完成了全部工作。
尾聲
一些碎碎念念。博主一開始在官網下載不了數據集,在咸🐟上花幾塊錢買了百度網盤資源,先把資源下載在本地之后又通過FileZilla來把資源上傳到云服務器上【因為網絡傳輸的不穩定,FileZilla還經常傳輸失敗】,花了好幾天終于完成了數據集的下載與上傳工作,結果處理val驗證集成功之后發現他的1000個文件夾與train的1000個文件夾名有一些對不上【具體來說就是train文件夾中有兩個文件夾是完全重復的一個是XXX.tar文件另外一個是XXX(1).tar文件,然后val中的最后一個文件,train中沒有。】,博主的心情五味雜陳,這證明train文件有錯,博主前面的工作都白費了那些資源根本用不了,咸魚上的ImageNet的網盤資源大家還是不要隨便相信了。

![Nacos中feign.FeignException$BadGateway: [502 Bad Gateway]](http://pic.xiahunao.cn/Nacos中feign.FeignException$BadGateway: [502 Bad Gateway])



 ---驅動與內核交互)
)


 函數在 Java、JavaScript 和 Python 區別)


)
![[每日隨題15] 前綴和 - 拓撲排序 - 樹狀數組](http://pic.xiahunao.cn/[每日隨題15] 前綴和 - 拓撲排序 - 樹狀數組)


 如何遷移數據庫到新服務器?)


