一.現狀分析
現有任務的資源配置如下,根據ui監控中Garbage Collection可以發現,此任務頻繁的發生GC,且老年代GC時間較久
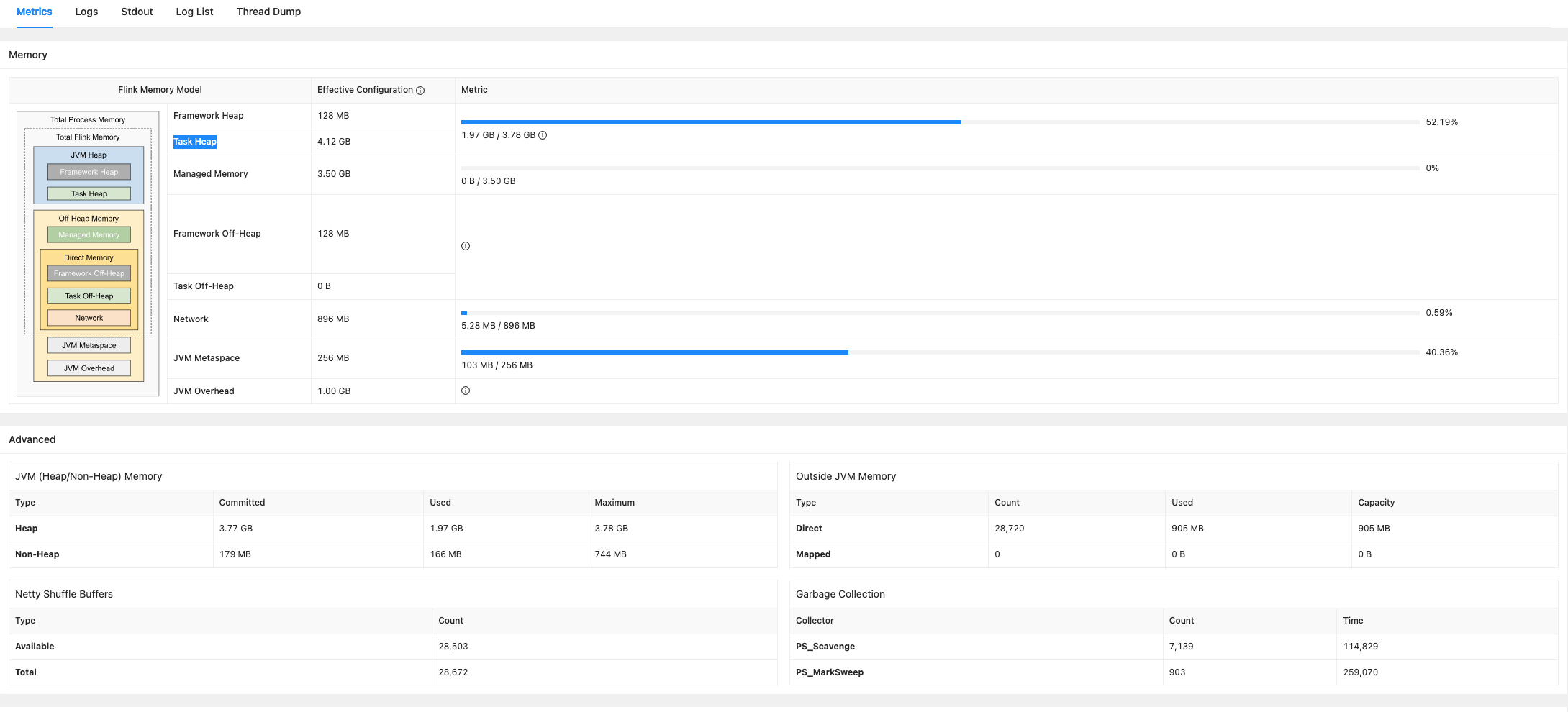
二.整體memory使用分析如下
-
Framework Heap(框架堆內存)用于Flink框架自身的堆內存(如JobManager和TaskManager的元數據管理、調度器等)。
-
Task Heap(任務堆內存) 指標值:4.12GB / 76% 使用(3.14GB/4.12GB) 作用: 用于Flink任務執行時的堆內存(如Kafka消費者、Paimon寫入算子、狀態后端緩存等)。
當前分析: 使用率接近高風險閾值(>70%),導致頻繁Full GC,出現OutOfMemoryError問題 -
Managed Memory(托管內存) 指標值:3.50GB / 0% 使用(0B/3.50GB) 作用: Flink管理的堆外內存,用于狀態后端(如RocksDB的緩存)和批處理操作。
當前分析:狀態后端使用的是FsStateBackend,占用的是Task Heap,此處未被使用 -
Framework Off-Heap(框架堆外內存) 指標值:128MB / N/A 作用: Flink框架使用的堆外內存(如Netty網絡緩沖區元數據)。
當前分析: 默認配置足夠,無需調整。 -
Task Off-Heap(任務堆外內存) 指標值:0B / N/A 作用: 任務執行時的堆外內存(如自定義算子的Native庫)。
當前分析: 未啟用,說明任務未使用堆外狀態或自定義算子。無需調整 -
Network(網絡內存) 指標值:896MB / 0.59% 使用(5.28MB/896MB) 作用: 用于任務之間的網絡數據傳輸(如Shuffle、廣播等)。
當前分析: 問題:使用率過低(<1%),存在資源浪費。 -
JVM Metaspace(元空間) 指標值:256MB / 40.23% 使用(103MB/256MB) 作用: 存儲JVM類元數據(如加載的類、方法信息)。
當前分析: 使用率正常,無需調整。保持默認,除非出現Metaspace OOM。 -
JVM Overhead(JVM開銷內存) 指標值:1.00GB / N/A 作用: 預留的JVM內部開銷內存(如線程棧、JNI等)。
當前分析: 默認配置足夠,無需調整。
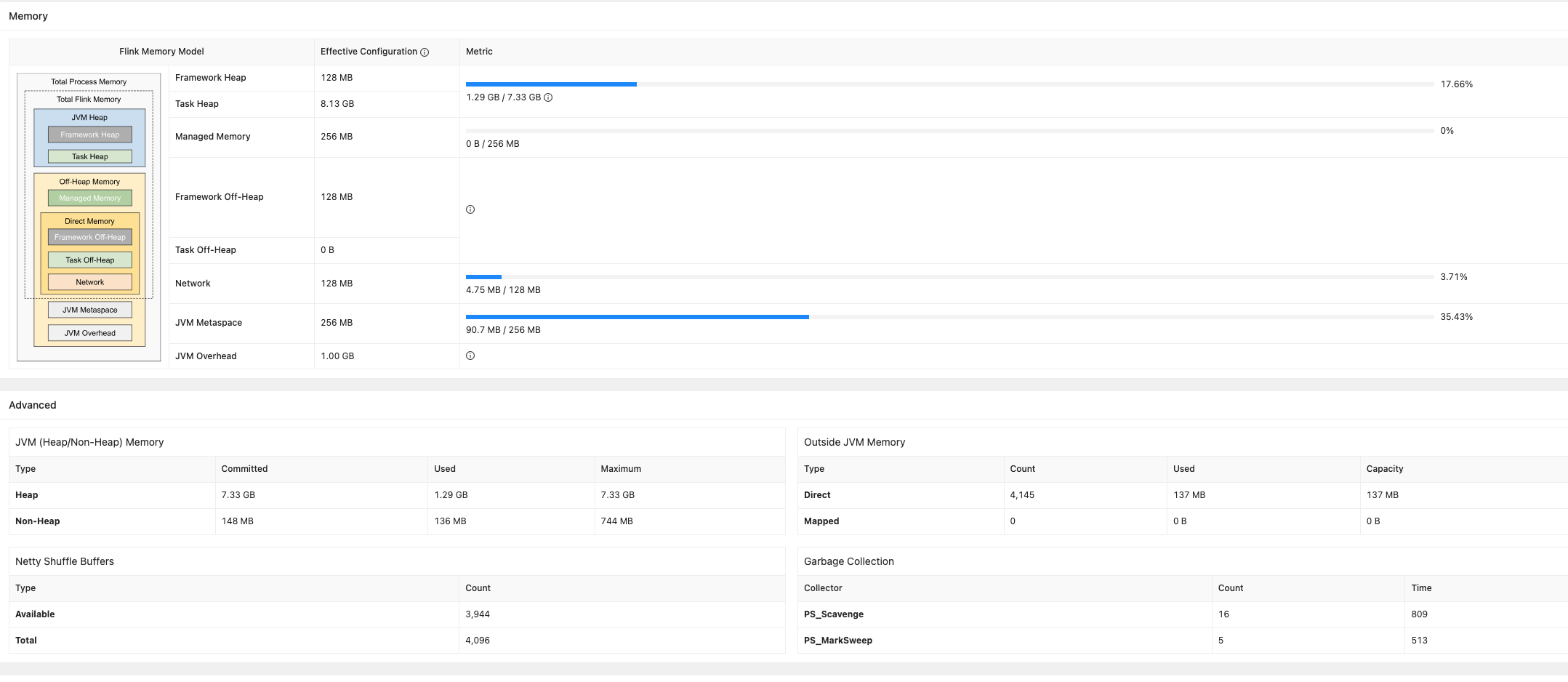
三.最終優化措施
減少了Managed Memory和Network內存,增大Task Heap內存,效果如下圖監控所示,大大減少了GC的數量,留有足夠的Task Heap內存保證任務正常運行


?)

python+playwright自動化處理單選和多選按鈕-中)














